13.MongoDB模糊查询
13.1 知识点
MongoDB 模糊查询概述
MongoDB 的模糊查询通常是通过正则表达式(Regular Expressions,简称 Regex)来实现的。正则表达式可以帮助我们在查询中实现灵活的字符串匹配,类似于 SQL 中的 LIKE 操作符。
在 MongoDB 中,模糊查询主要通过 $regex 操作符来完成,它允许你对文档中的字符串字段进行模式匹配。
基本模糊查询
最基本的模糊查询使用 $regex 来查找符合正则表达式模式的字符串。
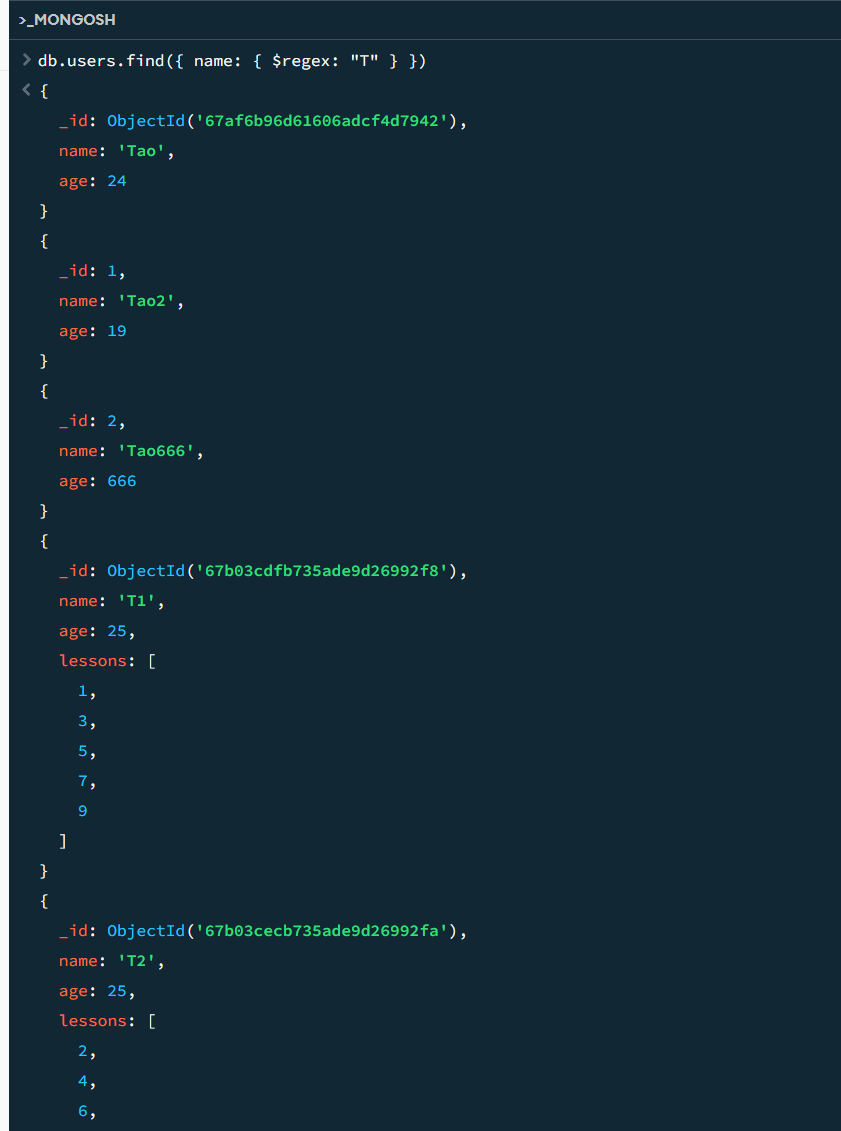
// 查找 name 包含 'T' 的所有数据
db.users.find({ name: { $regex: "T" } })
这个查询将返回名字中包含 “T” 的所有文档。注意:默认情况下,正则表达式是区分大小写的。
忽略大小写
如果你想进行大小写不敏感的模糊查询,可以使用 $options 操作符,设置为 "i",表示忽略大小写。
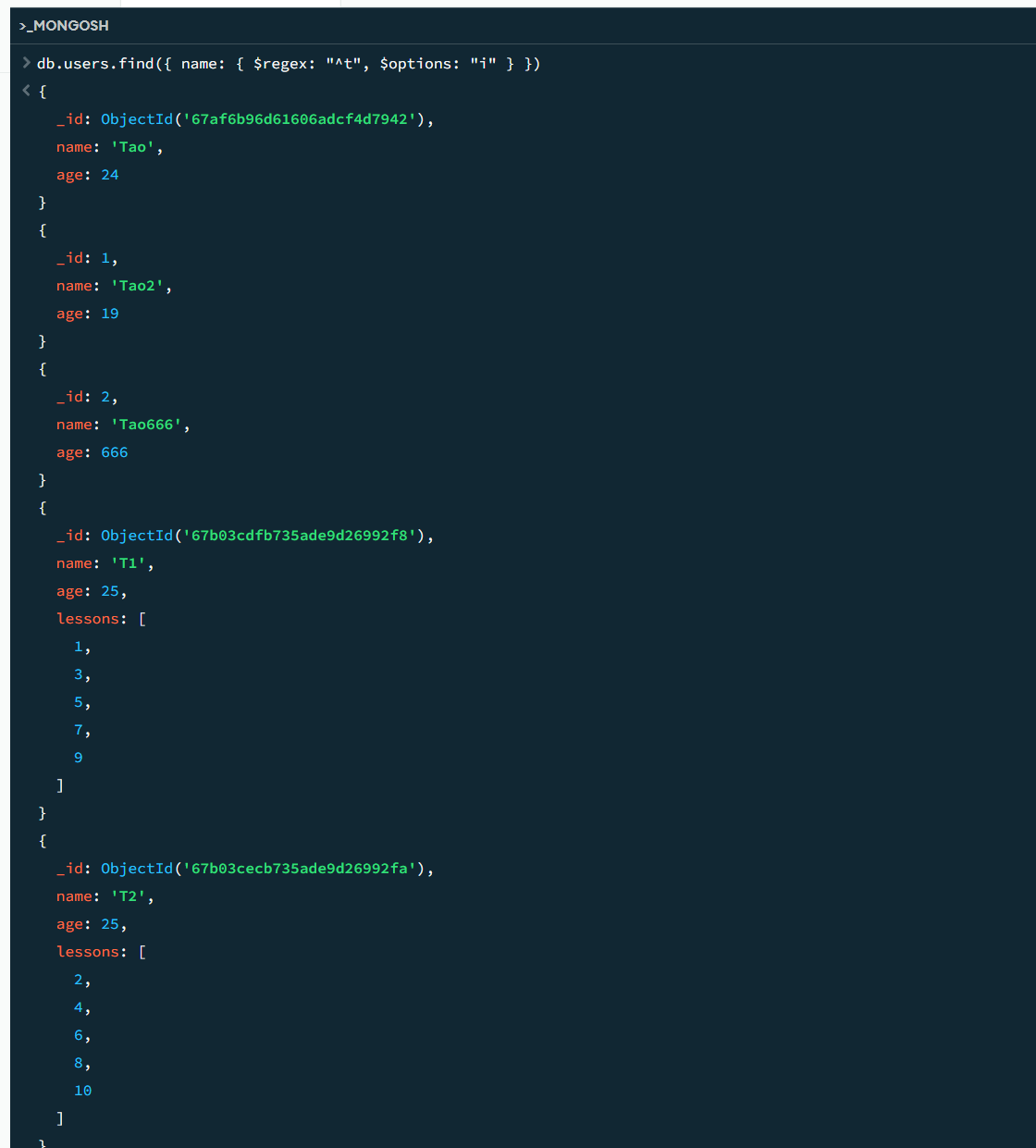
// 查找 name 中包含 't' 的数据,不区分大小写
db.users.find({ name: { $regex: "t", $options: "i" } })
正则表达式的常用模式
正则表达式是非常强大的,支持各种字符串匹配方式,常见的模式包括:
^:匹配字符串开头$:匹配字符串结尾.:匹配任意字符*:匹配前面的字符零次或多次+:匹配前面的字符一次或多次?:匹配前面的字符零次或一次[]:匹配指定字符集中的任意字符|:或运算符,匹配左侧或右侧的模式
// 查找 name 以 't' 开头的数据(不区分大小写)
db.users.find({ name: { $regex: "^t", $options: "i" } })
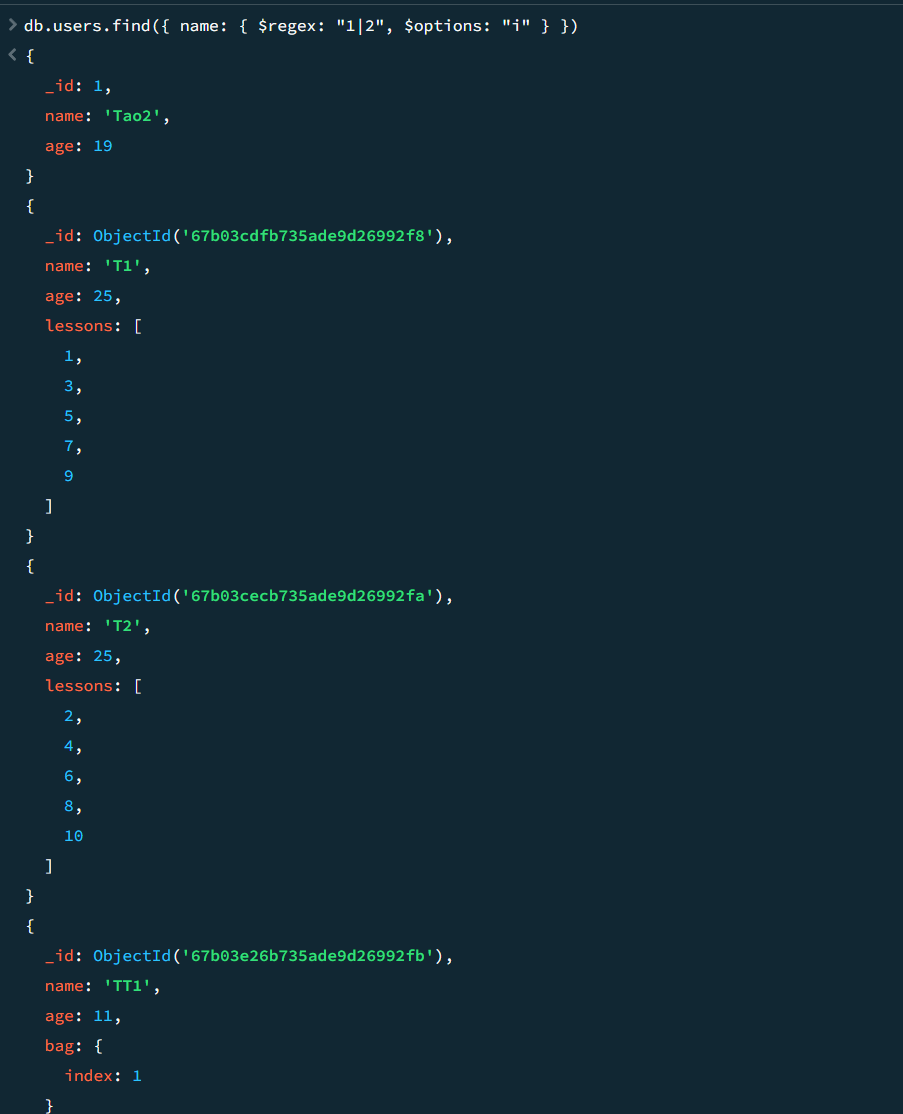
// 查找 name 中包含 '1' 或 '2' 的数据(不区分大小写)
db.users.find({ name: { $regex: "1|2", $options: "i" } })
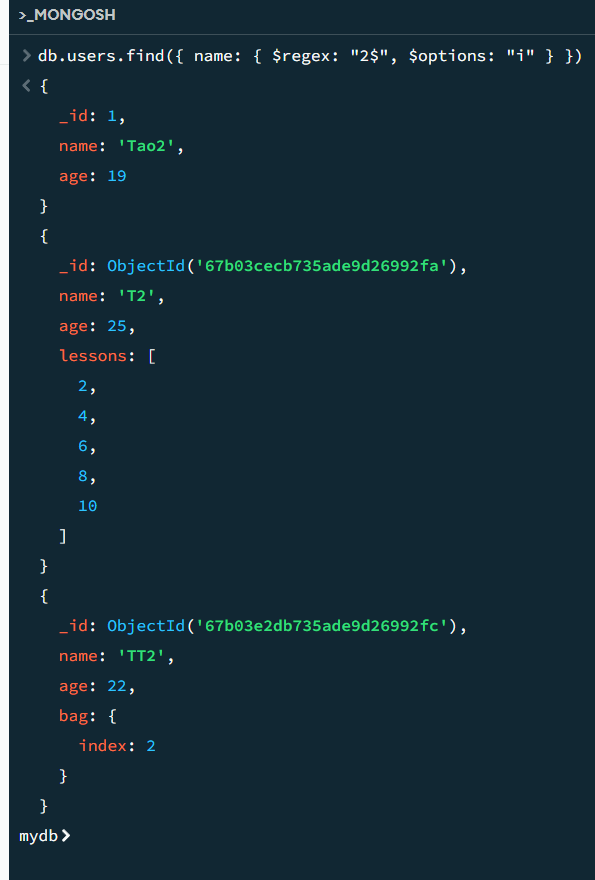
// 查找 name 以 '2' 结尾的数据(不区分大小写)
db.users.find({ name: { $regex: "2$", $options: "i" } })
$options 参数
正则表达式可以带有多个选项,通常使用 $options 来指定:
- **
i**:忽略大小写 - **
m**:多行匹配 - **
s**:单行匹配
m(多行模式,multi-line)
在普通的正则表达式中,^ 和 $ 仅匹配整个字符串的开始和结束。启用多行模式(m)时,^ 和 $ 会匹配每一行的开头和结尾,而不仅仅是整个字符串的开头和结尾。
^匹配每一行的开始。$匹配每一行的结束。
假设我们有如下文本:
Hello Tao
This is a test
- 普通模式(不使用
m):- 正则
^This只会匹配字符串的开始部分。 - 正则
test$会只匹配字符串的末尾。
- 正则
- 多行模式(
m):- 正则
^This会匹配每一行的开始。 - 正则
test$会匹配每一行的结尾。
- 正则
s(单行模式)
在正则表达式中,. 代表匹配除换行符以外的任何字符。启用单行模式(s)时,. 可以匹配包括换行符在内的任何字符。
- 启用单行模式后,
.可以匹配换行符(\n)或者回车符(\r)。 - 默认情况下,
.不会匹配换行符。
假设我们有如下文本:
Hello
world
- 普通模式(不使用
s):- 正则
Hello.world会匹配Hello后面跟着其他字符的情况,但因为.不匹配换行符,所以它不会匹配跨行的字符串。
- 正则
- 单行模式(
s):- 正则
Hello.world会匹配跨越换行符的内容,因为.可以匹配换行符。
- 正则
通过合理使用正则表达式和其选项,可以在 MongoDB 中实现强大的模糊查询功能。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

