3.注册流程
3.1 注册流程图
注册流程先看整体链路。
这里的注册不是简单地“客户端传用户名和密码,服务端插一条账号记录”。真正落到游戏服务器里,至少要处理几件事:
- 客户端应该请求哪个鉴权服。
- 当前鉴权服是否真的负责这个账号。
- 请求频率是否正常。
- 注册参数是否合法。
- 同一个用户名在高并发下会不会被重复注册。
- 缓存和数据库里是否已经存在该账号。
- 注册结果如何返回给客户端。
可以把注册理解成一次“开户”:
- 客户端先根据用户名找到负责处理这个账号的柜台。
- 鉴权服先做基础检查,比如请求是否过于频繁、用户名密码是否为空。
- 然后鉴权服重新计算账号归属,确认这个请求确实应该由当前节点处理。
- 真正查缓存和查数据库之前,先按用户名加锁,避免两个相同用户名的注册请求同时创建账号。
- 最后确认账号不存在后,创建账号、写入数据库、写入短期缓存,并把结果返回客户端。
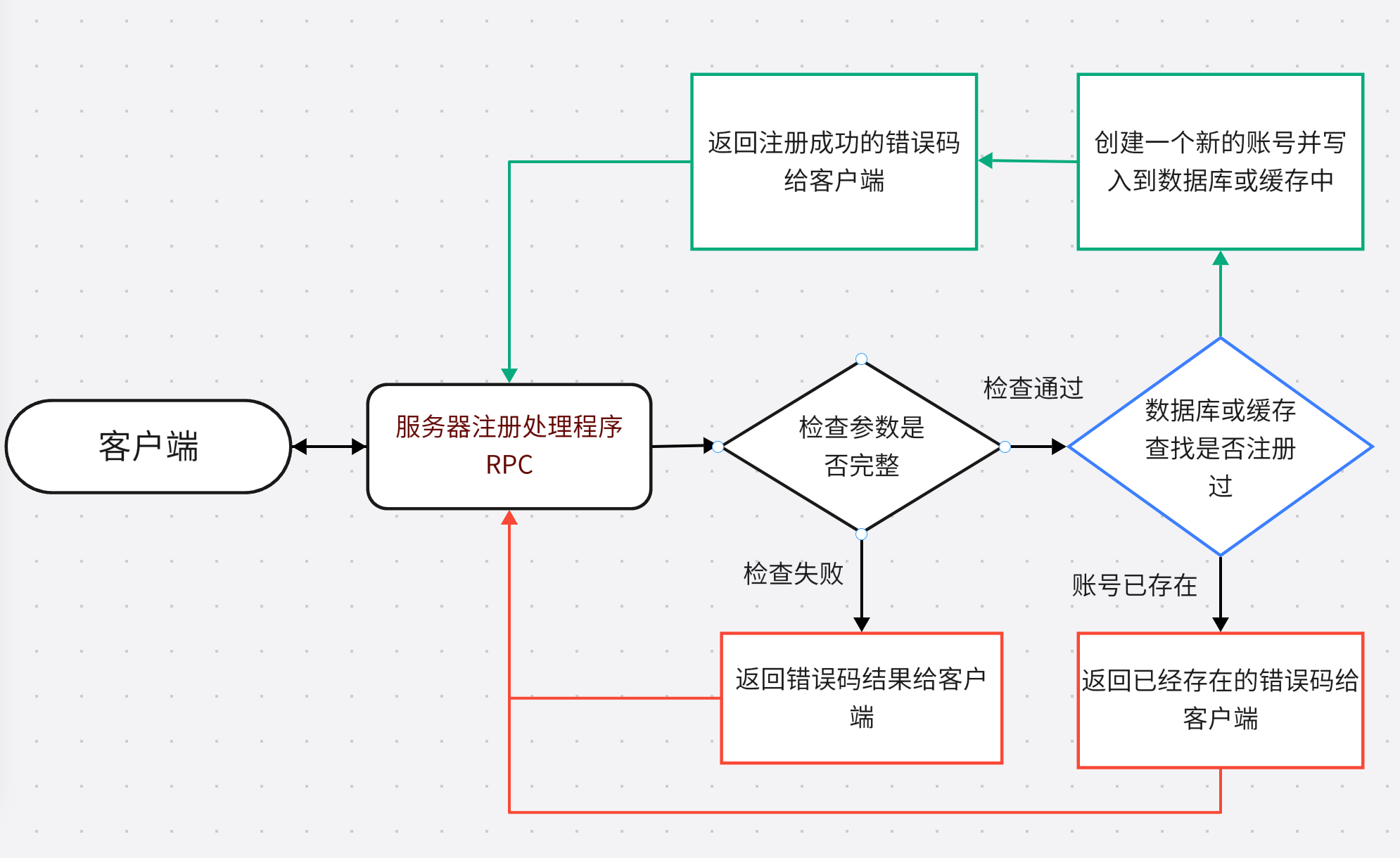
把上面的流程整理成 Mermaid,大概是这样:
flowchart TD
subgraph client_request_auth["客户端请求鉴权服"]
cli_click_register["点击注册按钮"]
cli_select_auth_svr["选择鉴权服务器地址"]
cli_create_session["创建网络会话"]
cli_send_register_request["发送注册请求"]
end
subgraph auth_server_handle["鉴权服处理注册请求"]
svr_handle_register_request["处理注册请求"]
svr_check_request_frequency{"检查请求频率是否正常?"}
svr_return_frequency_error["返回错误:请求过于频繁"]
svr_set_session_timeout["设置会话超时时间"]
svr_invoke_register_method["调用注册方法"]
svr_validate_parameters{"校验参数是否合法?"}
svr_validate_parameters_error["返回错误:参数非法"]
svr_compute_target_position["计算账号对应的目标鉴权服位置"]
svr_check_position_match{"当前鉴权服是否匹配?"}
svr_return_position_error["返回错误:账号不归当前鉴权服处理"]
svr_acquire_coroutine_lock["获取同用户名协程锁"]
svr_check_account_cache{"缓存中是否已有账号?"}
svr_return_account_exists_error["返回错误:账号已存在"]
svr_query_database["查询数据库"]
svr_check_account_exists{"数据库中是否已有账号?"}
svr_create_new_account["创建新账号"]
svr_save_account["保存账号到数据库"]
svr_cache_account_with_timeout["写入注册缓存并设置超时清理"]
svr_return_success["返回注册成功"]
end
subgraph client_receive_response["客户端接收鉴权服响应"]
cli_receive_response["接收注册响应"]
cli_receive_check_error{"检查错误码"}
cli_register_success["注册成功"]
cli_register_fail["注册失败"]
end
cli_click_register --> cli_select_auth_svr
cli_select_auth_svr --> cli_create_session
cli_create_session --> cli_send_register_request
cli_send_register_request --> svr_handle_register_request
svr_handle_register_request --> svr_check_request_frequency
svr_check_request_frequency -- 请求过于频繁 --> svr_return_frequency_error
svr_return_frequency_error --> cli_receive_response
svr_check_request_frequency -- 正常 --> svr_set_session_timeout
svr_set_session_timeout --> svr_invoke_register_method
svr_invoke_register_method --> svr_validate_parameters
svr_validate_parameters -- 参数非法 --> svr_validate_parameters_error
svr_validate_parameters_error --> cli_receive_response
svr_validate_parameters -- 参数合法 --> svr_compute_target_position
svr_compute_target_position --> svr_check_position_match
svr_check_position_match -- 不匹配 --> svr_return_position_error
svr_return_position_error --> cli_receive_response
svr_check_position_match -- 匹配 --> svr_acquire_coroutine_lock
svr_acquire_coroutine_lock --> svr_check_account_cache
svr_check_account_cache -- 已存在 --> svr_return_account_exists_error
svr_return_account_exists_error --> cli_receive_response
svr_check_account_cache -- 不存在 --> svr_query_database
svr_query_database --> svr_check_account_exists
svr_check_account_exists -- 已存在 --> svr_return_account_exists_error
svr_check_account_exists -- 不存在 --> svr_create_new_account
svr_create_new_account --> svr_save_account
svr_save_account --> svr_cache_account_with_timeout
svr_cache_account_with_timeout --> svr_return_success
svr_return_success --> cli_receive_response
cli_receive_response --> cli_receive_check_error
cli_receive_check_error -- 有错误 --> cli_register_fail
cli_receive_check_error -- 无错误 --> cli_register_success
这个流程里有两个点要先分清楚。
客户端选服只是第一层分流
客户端会根据用户名选择鉴权服,但客户端选择不能完全信任。
所以鉴权服收到请求后,仍然要重新计算账号应该落在哪个节点上。
如果请求打错节点,直接返回错误,不继续执行注册逻辑。协程锁要放在查缓存和查数据库之前
同一个用户名可能在很短时间内发起多次注册请求。
如果没有锁,两个请求可能都查到“账号不存在”,然后同时创建账号。
所以真正进入缓存和数据库判断前,需要先按用户名加锁,让同一个账号的注册逻辑串行执行。
3.2 客户端选择鉴权服务器
注册时,客户端不能永远只连一个固定的鉴权服。
单机 Demo 里这么做没问题:客户端点注册,直接连到唯一的鉴权服务器,然后发用户名和密码。
但放到真实项目里,注册和登录都是入口流量,一旦玩家量上来,单个鉴权服很容易变成瓶颈。
所以客户端需要具备一个能力:
根据账号信息选择目标鉴权服务器。
在这里,选择依据用的是用户名。
也就是客户端拿到用户名后,先算一个哈希值,再根据哈希结果把请求分到某个鉴权服节点上。
可以把它理解成银行开户分柜台:
- 所有玩家都挤到一个柜台,柜台压力会很大。
- 多开几个柜台后,需要一个规则决定“这个账号应该去哪个柜台处理”。
- 用户名哈希就是这个分流规则。
- 同一个用户名每次算出来的结果一致,后续注册、登录就能打到同一个目标鉴权服。
客户端侧先挂一个认证服务器选择组件:
// 添加认证服务器选择组件(一致性哈希算法选择服务器)
_scene.AddComponent<AuthenticationSelectComponent>();
这里的组件职责很简单:
在发起注册或登录之前,根据用户名选出一个鉴权服地址。
单鉴权的问题

如果只有一个鉴权服,结构最简单,所有客户端都往这个节点发注册和登录请求。
这种方案前期很好理解,也方便调试,但问题也明显:
- 所有注册和登录请求都会打到同一个节点。
- 节点压力上来后,最先被打满的就是鉴权服。
- 这个节点一旦挂掉,注册登录入口就直接不可用。
- 后续想横向扩展时,需要重新设计请求分流方式。
所以单鉴权更适合本地 Demo 或早期验证流程。
只要开始考虑并发、可用性和扩容,就需要多鉴权服。
多鉴权服务器分流
多鉴权服的核心不是“多起几个进程”这么简单。
真正要解决的问题是:同一个账号的注册和登录请求,应该稳定落到同一个负责节点上。
否则就会出现几个麻烦:
- 第一次注册请求打到鉴权服 1。
- 第二次重试打到鉴权服 2。
- 登录时又打到鉴权服 3。
- 每个节点缓存状态不同,排查问题会很乱。
- 服务端还要频繁转发请求,反而增加复杂度。
比较直接的做法是:客户端拿到鉴权服列表后,根据用户名做哈希分流。
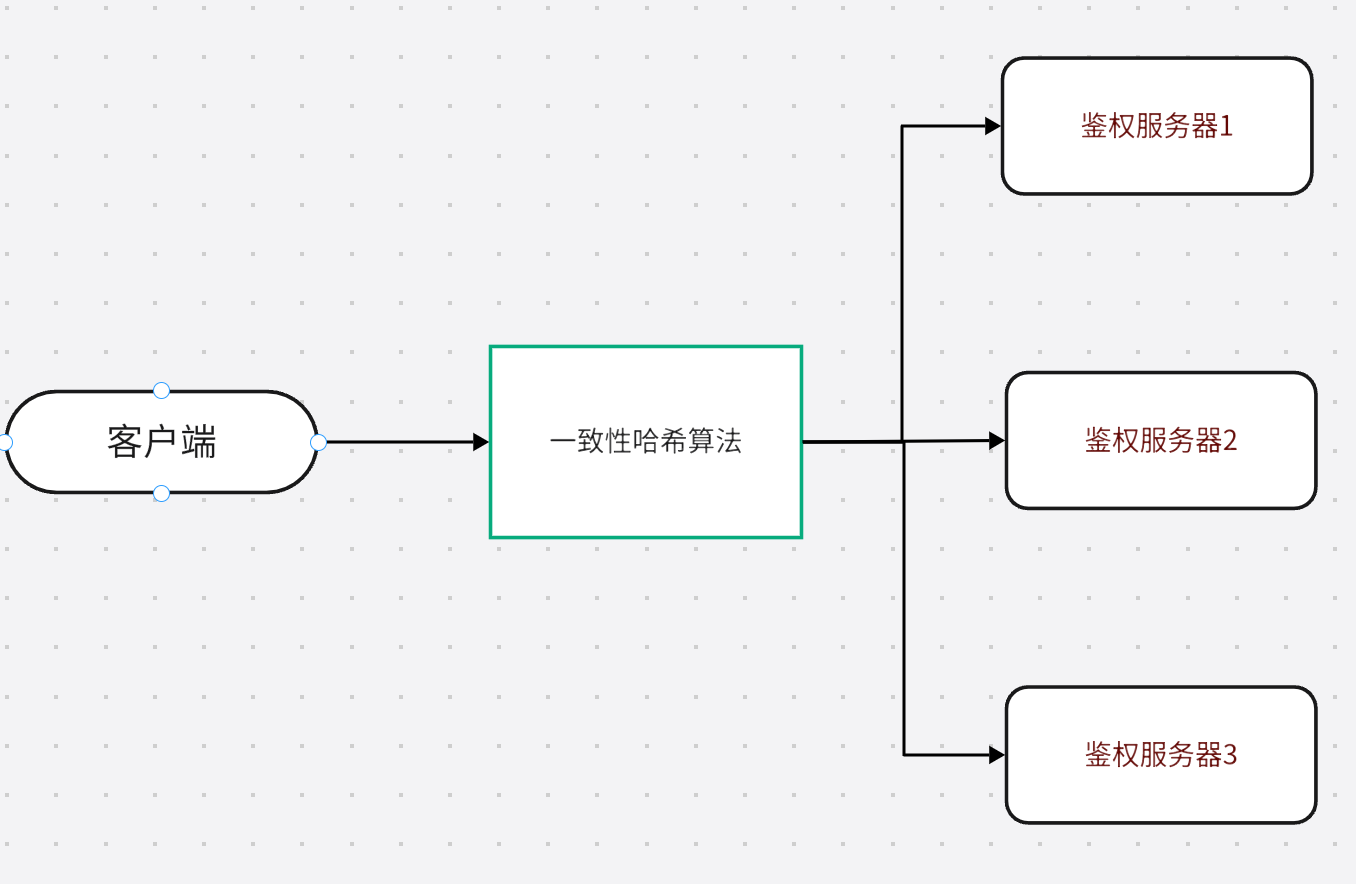
流程大概是:
- 客户端启动时拿到鉴权服列表。
- 注册或登录时,对用户名做哈希。
- 根据哈希结果选择一个鉴权服。
- 请求直接发给这个鉴权服。
这个方案的好处是简单,客户端就能完成第一层分流,不需要额外的中心转发节点。
但这里有一个边界要分清楚:
客户端选服只能作为第一层分流,不能完全信任客户端的选择。
客户端可能拿到的是旧配置,也可能被恶意修改请求目标。
所以服务端收到请求后,仍然要根据同一套规则重新计算一次账号归属。
如果发现这个账号不应该由当前鉴权服处理,就直接返回错误,不继续执行注册逻辑。
去中心化哈希环
一种更完整的做法,是让每个鉴权节点都维护一份相同的哈希环配置。
也就是:
- 每个鉴权服都知道当前有哪些鉴权节点。
- 每个节点都知道哈希空间怎么分布。
- 收到请求后,可以判断当前账号是否应该由自己处理。
- 节点增减时,需要同步新的哈希环配置。
这种方式减少了中心转发节点,但要求节点配置一致。
这里最容易出问题的是节点变更:
- 新增鉴权服后,哪些账号会迁移到新节点?
- 老节点下线后,原来负责的账号应该转到哪里?
- 客户端和服务端的节点列表如何保持一致?
- 灰度发布期间,新旧配置不一致怎么处理?
所以哈希分流本身不难,难的是节点列表、配置版本、服务发现和容错策略。
DHT 这种方案为什么不适合当前注册流程
分布式哈希表,也就是 DHT,常见于 P2P 或更大规模的去中心化系统。
它的特点是每个节点只维护一部分路由信息,通过多跳路由找到目标节点。
这个思路很适合一些真正去中心化的系统,但对普通游戏注册登录来说通常太重。
注册登录链路更看重:
- 请求路径短。
- 故障排查简单。
- 鉴权节点数量可控。
- 配置和服务发现可管理。
所以这里不需要把问题复杂化。
客户端根据用户名选鉴权服,服务端再做归属校验,已经能覆盖大部分注册登录入口分流需求。
哈希算法选择
分流时需要一个哈希函数,把用户名转换成一个数字。
这里可以先区分两个概念:
- 哈希函数:负责把用户名算成一个数字。
- 分流策略:负责把这个数字映射到某个服务器节点。
比如当前代码里就是:
MurmurHash3(username) % AuthenticationList.Count
这表示:
- 用 MurmurHash3 算用户名哈希。
- 再对服务器数量取模。
- 取模结果就是目标鉴权服下标。
这里要特别注意:
这段代码是哈希取模分流,不是严格意义上的一致性哈希环。
哈希取模的优点是简单。
但服务器数量变化时,% Count 的结果会大面积变化,很多用户名会被重新映射到不同节点。
真正的一致性哈希通常会把服务器节点和 Key 都映射到一个哈希环上,并配合虚拟节点减少节点增减时的迁移范围。
如果后面真的要做动态扩缩容,这块需要升级成哈希环或服务端统一路由。
BKDR Hash
BKDR Hash 是一种比较简单的字符串哈希算法。
它的特点是实现短、理解成本低,适合一些轻量场景,比如小规模字符串哈希、简单表结构索引等。
但放到鉴权服分流里,它不是最优选择:
- 分布均匀性一般。
- 大规模数据下碰撞概率相对更高。
- 对恶意构造输入没有防护能力。
- 更适合 Demo 或小规模工具逻辑。
简单说,BKDR 像一个很轻的手工分拣规则。
规则能用,但数据量上来以后,容易出现某些桶特别热,某些桶又比较空。
MurmurHash3
MurmurHash3 是一个常见的非加密哈希算法。
它适合用在:
- 哈希表。
- 缓存 Key。
- 分布式分流。
- 数据库分片辅助计算。
- 服务节点选择。
它的优势是速度快、分布相对均匀,适合把大量用户名分散到不同鉴权服上。
但 MurmurHash3 不是安全哈希。
它不能用于密码存储、签名、Token 防篡改这类安全场景。
这个点要分清楚:
- 用户名分流:可以用 MurmurHash3。
- 密码存储:不能用 MurmurHash3。
- Token 签名:不能用 MurmurHash3。
- 安全摘要:也不能用 MurmurHash3。
它更像是一个“分流用的编号器”,不是“安全用的保险柜”。
MurmurHash3 VS BKDR Hash

代码示例
下面这段是客户端侧根据用户名选择鉴权服的示例。
代码里用的是 MurmurHash3 + 取模,适合本地开发和固定节点数量的简单分流。
如果后续鉴权服节点会频繁增减,就需要进一步改成真正的一致性哈希环,或者把节点选择交给服务发现和网关层处理。
/// <summary>
/// 认证服务器选择组件扩展系统
/// 实现基于一致性哈希的服务器选择逻辑
/// </summary>
public static class AuthenticationSelectComponentSystem
{
// 预定义的认证服务器地址列表(本地开发环境配置)
private static readonly List<string> AuthenticationList = new List<string>()
{
"127.0.0.1:20001", // 认证服务器节点1
"127.0.0.1:20002", // 认证服务器节点2
"127.0.0.1:20003" // 认证服务器节点3
};
/// <summary>
/// 根据用户名选择目标认证服务器地址
/// </summary>
/// <param name="self">组件实例</param>
/// <param name="userName">用户名</param>
/// <returns>选中的认证服务器地址</returns>
public static string Select(this AuthenticationSelectComponent self, string userName)
{
// 使用MurmurHash3算法计算用户名的哈希值
// 特点:高随机性、低碰撞率,适合分布式系统哈希计算
var userNameHashCode = HashCodeHelper.MurmurHash3(userName);
// 通过取模运算确定目标服务器索引
// 计算逻辑:哈希值 % 服务器总数(结果范围:0 到 AuthenticationList.Count-1)
var authenticationListIndex = userNameHashCode % AuthenticationList.Count;
// 在列表长度为 3 时,取模结果范围为 0~2
return AuthenticationList[(int)authenticationListIndex];
}
}
这段代码的重点不在于算法多复杂,而是先把注册入口拆开:
- 客户端不直接固定连某一个鉴权服。
- 客户端根据用户名做第一层分流。
- 服务端收到请求后还要重新校验账号归属。
- 当前实现是简单哈希取模,节点数量固定时够用。
- 如果节点会动态变化,就不能只靠
% Count,需要升级成真正的一致性哈希或服务发现方案。
3.3 鉴权服务器初始化
客户端已经能根据用户名选择鉴权服了,但服务端自己也要知道一件事:
当前这个鉴权服,到底是第几个节点。
如果把多鉴权服理解成多个开户柜台,那每个柜台启动时都要知道:
- 当前一共有几个柜台。
- 自己是第几个柜台。
- 哪些账号应该由自己处理。
- 收到不属于自己的账号请求时,要直接拒绝,而不是继续注册。
所以鉴权服务器启动时,需要把当前节点在鉴权服列表中的位置记录下来。
// 用于鉴权服务器注册和登录相关逻辑的组件
scene.AddComponent<AuthenticationComponent>().UpdatePosition();
AuthenticationComponent 这里不只是挂一个空组件。
它后面要负责注册、登录、账号归属判断、缓存管理等逻辑,所以初始化时先调用 UpdatePosition()。
// 更新当前鉴权服务器在所有鉴权组中的位置和总数
public static void UpdatePosition(this AuthenticationComponent self)
{
// 1、通过远程接口或者本地文件来拿到所有鉴权服务器的配置信息,这里通过 SceneConfigData 获取
var authentications = SceneConfigData.Instance.GetSceneBySceneType(SceneType.Authentication);
// 2、获取当前 Scene 对应的配置文件
var sceneConfig = SceneConfigData.Instance.Get(self.Scene.SceneConfigId);
// 3、在鉴权服务器组中找到当前 Scene 配置的位置索引
self.Position = authentications.IndexOf(sceneConfig);
// 4、设置鉴权服务器的总数量
self.AuthenticationCount = authentications.Count;
// 输出日志,记录当前鉴权服务器的位置和总数
Log.Info($"鉴权服务器启动成功!Position:{self.Position} AuthenticationCount:{self.AuthenticationCount}");
}
这段代码的核心是两个字段:
Position:当前鉴权服在鉴权服列表中的下标。AuthenticationCount:当前一共有多少个鉴权服。
后面判断账号归属时,会重新计算:
Hash(username) % AuthenticationCount
如果算出来的位置等于当前服务器的 Position,说明这个账号应该由当前鉴权服处理。
如果不相等,就说明请求打错节点了。
这里有个工程细节要注意:
客户端选服和服务端归属判断必须使用同一份节点列表、同一套哈希规则。
否则客户端算出来应该打到鉴权服 1,服务端自己算出来却认为应该由鉴权服 2 处理,就会出现正常请求被误拒的情况。
真实项目里,这块通常还要补上:
- 配置版本号。
- 服务发现或配置中心。
- 节点上下线时的灰度策略。
- 客户端节点列表过期后的重试逻辑。
当前这版先用 SceneConfigData 固定配置跑通流程,适合学习和本地 Demo。
3.4 注册请求的前置检查
鉴权服收到注册请求后,不应该一上来就查缓存、查数据库、创建账号。
注册入口是比较容易被刷的地方,所以真正进入核心注册逻辑前,至少要做几层检查:
- 请求频率是否过高。
- 当前 Session 是否需要设置超时。
- 用户名和密码是否为空。
- 当前账号是否应该由当前鉴权服处理。
这些检查就像银行开户前的排队和材料检查。
材料不完整、排队频率异常、跑错柜台,都不应该进入真正的开户流程。
检查请求频率
// 检查客户端请求间隔是否符合要求,以防止用户发送过于频繁的请求
if (!session.CheckInterval(2000))
{
// 如果请求过于频繁,则将错误码设置为3,表示操作过于频繁,然后直接返回
response.ErrorCode = 3;
return;
}
这里限制的是同一个 Session 的请求间隔。
如果客户端在极短时间内重复发注册请求,一般有几种可能:
- 用户连续点击注册按钮。
- 客户端逻辑异常,重复发送请求。
- 恶意脚本在刷接口。
- 网络重试逻辑没有控制好。
这类请求没必要继续走数据库逻辑,直接返回错误更合适。
不过这里有个小问题:
当前示例里错误码 3 既可能表示“请求过于频繁”,后面也可能表示“账号不归当前鉴权服处理”。
Demo 阶段能跑,但正式项目里最好拆成不同错误码,比如:
ErrorCode.RequestTooFrequentErrorCode.InvalidAuthNodeErrorCode.InvalidParameterErrorCode.AccountAlreadyExists
否则客户端和日志排查时会很难判断到底是哪一类错误。
设置会话超时时间
// 为当前会话设置一个超时时间,确保请求在规定时间内完成,否则断开Session
session.SetTimeout(3000);
注册请求不应该长期占着连接。
设置 Session 超时的目的,是防止一些异常连接一直挂在鉴权服上。
比如客户端发起注册后卡住、不继续发送数据、不主动断开,这类连接如果一直保留,会慢慢消耗服务器资源。
可以把它理解成窗口办业务的超时时间。
排到窗口后,如果一直不提交材料,窗口不能无限等下去,到了时间就要释放资源。
当前示例设置的是 3000ms。
这个值适合本地 Demo,真实项目里要结合网络环境、服务器处理耗时、客户端重试策略来调整。
校验注册参数是否合法
if (string.IsNullOrEmpty(username) || string.IsNullOrEmpty(password))
{
// 返回错误码1,表示参数不完整
return 1;
}
最基础的参数校验是用户名和密码不能为空。
正式项目里一般还会继续补:
- 用户名长度限制。
- 密码长度限制。
- 用户名字符集限制。
- 敏感词过滤。
- 保留字过滤。
- 密码复杂度规则。
- 是否允许同一设备短时间大量注册。
这里只做空值判断,属于最小可运行版本。
判断当前账号是否应该由当前鉴权服处理
var position = HashCodeHelper.MurmurHash3(username) % self.AuthenticationCount;
if (self.Position != position)
{
// 返回错误码3,表示该账号不应在当前服务器上进行注册操作
return 3;
}
这一段是服务端的二次校验。
客户端已经根据用户名选择过鉴权服,但客户端不能完全信任。
可能是客户端节点列表过期,也可能是请求被篡改,也可能是测试时手动连错了服务器。
所以鉴权服收到请求后,仍然要自己算一次:
- 用用户名算哈希。
- 对鉴权服数量取模。
- 得到账号应该归属的鉴权服位置。
- 和当前服务器的
Position对比。
如果不匹配,说明这个账号不应该在当前服务器注册,直接返回错误。
这一步很关键。
否则客户端想打哪个鉴权服就打哪个鉴权服,多鉴权分流就失去了意义。
3.5 同用户名注册的并发控制
注册逻辑最怕的不是普通请求,而是同一个用户名在很短时间内发起多次注册。
比如两个请求几乎同时进来:
- 请求 A 查缓存,发现账号不存在。
- 请求 B 也查缓存,发现账号不存在。
- 请求 A 查数据库,发现账号不存在。
- 请求 B 也查数据库,发现账号不存在。
- 两边都开始创建账号。
如果没有额外控制,就可能出现重复创建、数据冲突、缓存状态异常等问题。
所以真正查缓存和查数据库之前,要先按用户名加锁。
锁的粒度不能太大,也不能太小。
- 锁整个注册系统:太粗,会把所有注册请求串行化。
- 锁用户名:比较合适,只让同一个用户名的注册请求串行。
- 不加锁:并发时容易出脏数据。
这里用用户名哈希作为协程锁的 key。
// 获取用户名的哈希码,用于协程锁的键值,防止多个注册请求并发导致数据混乱
var usernameHashCode = HashCodeHelper.MurmurHash3(username);
var scene = self.Scene;
// 使用协程锁确保同一用户名的注册请求是串行执行的
using (var @lock =
await scene.CoroutineLockComponent.Wait((int)LockType.AuthenticationRegisterLock, usernameHashCode))
{
//...
}
这里原来如果写成:
var usernameHashCode = username.GetHashCode();
在单进程、本地临时锁场景下也能跑。
但 string.GetHashCode() 不适合表达跨进程、跨版本、跨平台稳定语义,所以这里更推荐和前面的选服规则保持一致,统一使用 MurmurHash3(username)。
这样至少能保证这一篇里的哈希语义是统一的:
- 客户端选鉴权服用 MurmurHash3。
- 服务端判断账号归属用 MurmurHash3。
- 同用户名协程锁也用 MurmurHash3。
不过这里还要分清楚一个边界:
协程锁只能解决当前服务进程内的并发问题。
如果同一个账号请求可能进入多个鉴权服,或者节点列表不一致导致请求打散,仅靠本地协程锁不够。
这也是为什么前面必须先做“当前鉴权服是否匹配”的归属校验。
真正严谨的最后一道保险,还应该放在数据库层,比如给 Username 建唯一索引。
程序锁是为了减少并发冲突,数据库唯一约束才是防重复数据的最终兜底。
3.6 注册核心逻辑
注册核心逻辑可以拆成三步:
- 先查注册缓存。
- 缓存没有再查数据库。
- 数据库也没有,才创建账号并写库。
这里的顺序不要反过来。
缓存像柜台旁边的一张临时登记表。
刚注册过的账号先放在这张表里,短时间内再来查,就不用马上打到数据库。
数据库才是真正的账本,最终是否存在账号还是要以数据库为准。
// 使用协程锁确保同一用户名的注册请求是串行执行的
using (var @lock =
await scene.CoroutineLockComponent.Wait((int)LockType.AuthenticationRegisterLock, usernameHashCode))
{
// 首先通过缓存判断该用户名是否已经存在,减少对数据库的访问次数
if (self.RegisterAccountCacheDic.TryGetValue(username, out var account))
{
// 返回错误码2,表示该用户已经存在
return 2;
}
// 如果缓存中没有找到,再查询数据库判断账号是否存在
var worldDateBase = scene.World.DateBase;
var isExist = await worldDateBase.Exist<Account>(d => d.Username == username);
if (isExist)
{
// 数据库中存在相同用户名,则返回错误码2,表示账号已存在
return 2;
}
// 执行到此处说明缓存和数据库中都没有该账号信息,需要创建新账号
account = Entity.Create<Account>(scene, true, true);
// 将注册信息写入新创建的账号实体
account.Username = username;
account.Password = password;
account.CreateTime = TimeHelper.Now;
// 将新账号保存到数据库中,持久化存储
await worldDateBase.Save(account);
var accountId = account.Id;
// 将新账号添加到缓存字典中,便于后续快速登录等操作
self.RegisterAccountCacheDic.Add(username, account);
// 为账号添加超时组件,设置缓存失效时间为4000毫秒,自动清理过期账号缓存
account.AddComponent<AccountTimeOut>().TimeOut(4000);
// 记录注册日志,输出注册来源、用户名及账号ID,便于系统运维和问题追踪
Log.Info($"Register source:{source} username:{username} accountId:{accountId}");
// 返回0表示注册成功
return 0;
}
这段代码里有几个点要单独记一下。
先查缓存
if (self.RegisterAccountCacheDic.TryGetValue(username, out var account))
{
return 2;
}
注册成功后,会把账号放进短期缓存。
如果短时间内同一个用户名再次注册,就可以直接返回“账号已存在”,避免重复查数据库。
这个缓存不是账号系统的最终数据源,只是为了减少短时间内的重复查询。
再查数据库
var isExist = await worldDateBase.Exist<Account>(d => d.Username == username);
if (isExist)
{
return 2;
}
缓存没有命中,并不代表账号一定不存在。
可能是缓存刚过期,也可能是服务刚重启,也可能这个账号是很久之前注册的。
所以还要查数据库。
真正判断账号是否存在,最终还是要看数据库。
创建账号并保存
account = Entity.Create<Account>(scene, true, true);
account.Username = username;
account.Password = password;
account.CreateTime = TimeHelper.Now;
await worldDateBase.Save(account);
这里是最小 Demo 写法。
如果只是跑通流程,直接写入 Username、Password、CreateTime 能理解。
但真实项目里不能明文保存密码。
至少要做:
- 每个密码使用独立 salt。
- 使用适合密码存储的慢哈希算法,比如 Argon2id、bcrypt、PBKDF2。
- 不要直接用 MD5、SHA1、SHA256 这类快速哈希保存密码。
- 不要把密码明文写进日志。
也就是说,示例里的:
account.Password = password;
只适合学习流程。
正式项目里这里应该写入的是密码哈希结果,而不是原始密码。
写入短期缓存
self.RegisterAccountCacheDic.Add(username, account);
account.AddComponent<AccountTimeOut>().TimeOut(4000);
注册成功后,把账号写入缓存,并设置超时时间。
这块的作用是处理短时间内的重复请求。
比如玩家点了一次注册,客户端因为网络抖动又重试了一次。
缓存还没过期时,后一次请求就能更快判断账号已存在。
这里缓存时间是 4000ms,比较像本地 Demo 的短期保护。
真实项目里要根据请求重试时间、数据库压力、内存占用来调整。
数据库唯一约束是最后兜底
协程锁和缓存都属于业务层保护。
真正严谨的注册系统,还应该在数据库层给用户名加唯一约束。
原因很简单:
- 服务可能重启。
- 多节点配置可能不一致。
- 程序锁可能只覆盖当前进程。
- 极端情况下可能有并发写入绕过业务判断。
所以数据库层最好保证 Username 唯一。
业务层负责提前拦截,数据库层负责最终兜底。
Account 定义
Account 一般可以先这样定义:
public sealed class Account : Entity
{
public string Username { get; set; }
public string Password { get; set; }
public long CreateTime { get; set; }
public long LoginTime { get; set; }
}
这里也要标注清楚:
Password 字段在 Demo 里可以直接放字符串,方便理解流程。
真实项目里更准确的命名应该是类似:
public string PasswordHash { get; set; }
同时可以根据项目需要补:
- Salt
- Platform
- Channel
- LastLoginIp
- LastLoginDevice
- AccountStatus
- TokenVersion
这些不是注册流程第一版必须有的字段,但后面做登录、封禁、顶号、风控时会用到。
3.7 客户端处理注册响应
客户端收到注册响应后,不应该只看“有没有返回”。
真正要判断的是错误码。
// 发送一个注册的请求消息到目标服务器
var response = (A2C_RegisterResponse)await _session.Call(new C2A_RegisterRequest()
{
Username = UsernameInput.text,
Password = PasswordInput.text
});
// 处理注册结果
if (response.ErrorCode != 0)
{
Log.Error($"注册失败,错误码: {response.ErrorCode}");
return;
}
Log.Debug("注册成功!");
这段逻辑比较简单:
ErrorCode == 0:注册成功。ErrorCode != 0:注册失败。
不过正式项目里客户端不应该直接把数字错误码展示给玩家。
最好在协议层或公共模块里维护一份错误码枚举:
public enum ErrorCode
{
Success = 0,
InvalidParameter = 1,
AccountAlreadyExists = 2,
RequestTooFrequent = 3,
InvalidAuthenticationNode = 4,
}
这样客户端处理时更清楚:
if (response.ErrorCode == (int)ErrorCode.AccountAlreadyExists)
{
// 提示账号已存在
}
数字错误码能跑,但不利于维护。
尤其是前面已经出现过同一个错误码表达多种含义的情况,后面最好拆开。
客户端这里还可以继续补几类处理:
- 注册按钮防连点。
- 注册请求期间显示 Loading。
- 请求超时提示。
- 错误码转本地化文本。
- 注册成功后是否自动跳到登录流程。
- 注册成功后是否断开当前鉴权 Session。
最后这个点要看整体登录设计。
如果注册和登录是两个独立流程,注册成功后可以断开当前注册 Session,再由玩家点击登录重新建立登录流程。
如果产品希望注册后自动登录,也可以在服务端注册成功后直接返回登录凭证,但那就是“注册 + 登录合并流程”,需要额外设计 Token、在线状态和 Gate 绑定。
3.8 总结
注册流程看起来只是创建一个账号,实际拆开后会涉及不少工程细节。
这篇里当前版本的主线是:
- 客户端根据用户名选择鉴权服。
- 鉴权服启动时记录自己的
Position和AuthenticationCount。 - 鉴权服收到请求后,先做频率、超时、参数检查。
- 服务端重新计算账号归属,确认请求确实打到正确节点。
- 对同一个用户名加协程锁,避免并发重复注册。
- 先查缓存,再查数据库。
- 数据库不存在时创建账号、保存账号、写入短期缓存。
- 客户端根据错误码判断注册结果。
这套流程的核心不是“插入一条 Account 数据”,而是保证几个边界:
请求不能乱打
客户端可以做第一层分流,但服务端必须重新校验。
客户端选错节点、配置过期、请求被篡改,都不能直接进入注册核心逻辑。
同用户名不能并发创建
注册最怕两个相同用户名同时查到“不存在”。
所以查缓存和查数据库之前要加锁,让同一个用户名的注册逻辑串行。
缓存不是最终数据源
缓存只是为了减少短时间内重复请求打到数据库。
账号是否真的存在,最终还是要查数据库。
数据库要做最终兜底
业务层锁和缓存都可能因为多节点、重启、配置不一致而失效。
真正不能重复的字段,比如用户名,数据库层最好加唯一索引。
密码不能明文存
示例代码里的 account.Password = password 只是 Demo 写法。
真实项目里必须存密码哈希,不能存明文密码。
错误码要标准化
注册流程里会出现很多失败原因:
- 参数非法。
- 请求太频繁。
- 账号已存在。
- 请求打错鉴权服。
- 数据库写入失败。
- Session 超时。
这些错误不能长期靠 1 / 2 / 3 这种数字硬记。
后面应该统一成枚举或错误码表,客户端和服务端共用。
放到游戏服务器里,可以把注册流程理解成“开户”:
- 客户端先找到负责这个账号的柜台。
- 柜台确认材料完整、请求正常、账号归自己处理。
- 对同一个用户名加锁,避免两个窗口同时开户。
- 查临时登记表和正式账本。
- 都没有记录时,才创建新账号。
- 创建成功后,返回结果给客户端。
到这里,注册流程只是账号系统的第一步。
后面登录流程还要继续处理密码校验、Token 签发、Gate 绑定、顶号、在线状态、重连和强制下线。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

