11.总结
11.1 知识点

总结主要内容

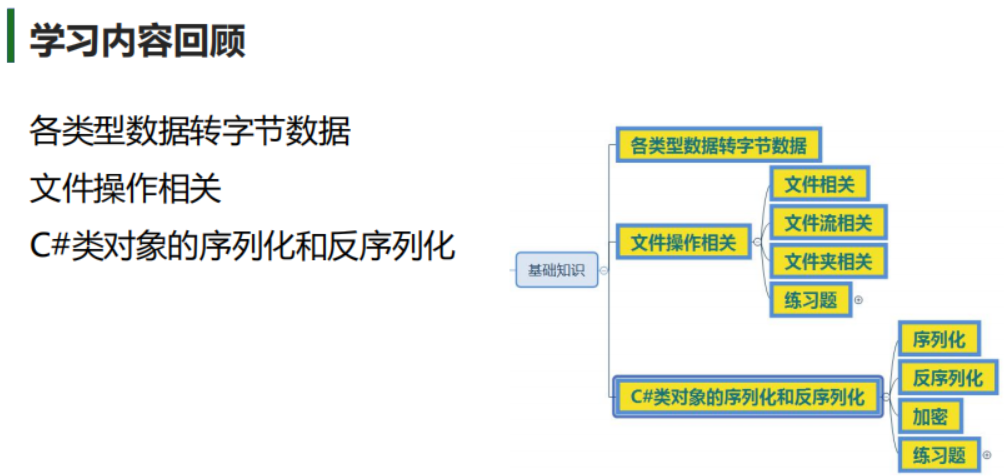
学习内容回顾
优点

缺点

主要用处

11.2 核心要点速览
数据类型 ↔ 字节数组转换
- 写到文件或发出去之前,内存里的东西最后都要变成
byte[]。整型、浮点、bool用BitConverter;字符串用System.Text.Encoding,不要拿BitConverter去硬转中文。 sizeof是编译期运算符,用来扫一眼值类型占几个字节;string不能sizeof,长度运行期才知道。- 字符串、数组这种长度会变的字段,协议里通常前面跟一个固定宽度的长度(本系列练习里用 4 字节
int),读端才知道接下来Read多少字节。
| 操作 | 类/方法 | 代码示例 | 说明 |
|---|---|---|---|
| 数值转字节 | BitConverter.GetBytes |
byte[] b = BitConverter.GetBytes(999); |
PC 上常见为小端;bool 一般 1 字节 |
| 字节转数值 | BitConverter.ToInt32 等 |
int i = BitConverter.ToInt32(b, 0); |
第二参是起始下标;后面凑不满 4 字节会异常 |
| 字符串转字节 | Encoding.UTF8.GetBytes |
byte[] s = Encoding.UTF8.GetBytes("林文韬"); |
项目里默认 UTF-8 最省心;和 GBK、系统 ANSI 混接容易乱码 |
| 字节转字符串 | Encoding.UTF8.GetString |
string t = Encoding.UTF8.GetString(s, 0, s.Length); |
可按偏移和长度从大缓冲区里切一段再解码 |
| 易混点 | 小端 / 长度头 | 先 Write 4 字节长度,再 Write UTF-8 字节 |
对端是大端或网络序时,要么约定清楚,要么自己 Reverse / 手写转换 |
文件操作(File 类)
- 小文件、逻辑简单时,用
File.ReadAllBytes/WriteAllBytes一类 API 一把读完或整包覆盖,代码最短。 - 课程示例里经常写
Application.dataPath,方便在工程里看到文件;发给玩家的存档应落在Application.persistentDataPath。个别平台路径大小写敏感,拼路径时别混。 - 文件还被
FileStream占着的时候去File.Delete,往往会失败,先关流或让using结束。
| 操作 | 方法 | 说明 |
|---|---|---|
| 是否存在 | File.Exists |
避免对不存在路径直接读写 |
| 创建空文件 | File.Create |
返回 FileStream,可接着写 |
| 字节整包写/读 | WriteAllBytes / ReadAllBytes |
覆盖写;体量不大时够用 |
| 文本写/读 | WriteAllText / ReadAllText |
可指定 Encoding;注意 \n 等转义 |
| 按行写/读 | WriteAllLines / ReadAllLines |
string[] 与多行文本互转 |
| 删除 / 复制 | Delete / Copy |
Copy 目标已存在时,第三个参数传 true 才覆盖 |
| 替换 | File.Replace |
第三个参数可做备份路径 |
| 打开为流 | File.Open |
拿到 FileStream 后按字节精细读写 |
文件流操作(FileStream)
- 文件按字节顺序读写:写的时候按协议一段段
Write,读的时候必须严格同顺序Read。中间少读或多读一个字节,后面的字段全部错位。 Read返回本次读到的字节数;流里有一个当前读写位置,连续调用会自动往后挪。FileMode.Open要求文件已在;Create会清空重建;存档常用OpenOrCreate。Append从文件末尾接着写。using (FileStream fs = …)结束时调用Dispose,比到处手写Close稳一些。
| 操作 | 用法 | 说明 |
|---|---|---|
| 打开 | new FileStream(path, mode, access) 或 File.Open |
需要时加 FileShare,避免多进程抢锁 |
| 写入 | Write(byte[] buf, int offset, int count) |
同一个 byte[] 可以分段写多个逻辑字段 |
| 刷新 | Flush() |
把缓冲区里的数据推下去,异常退出前少丢一段 |
| 读一段 | Read(buffer, offset, count) |
典型套路:先读 4 字节得到长度,再按长度读字符串 |
| 一次读完 | 按 Length 分配 byte[] 再 Read |
只合适小文件;大文件应分块,避免一次吃掉太多内存 |
文件夹与信息类(Directory / DirectoryInfo / FileInfo)
Directory的静态方法直接吃路径字符串:Exists、建目录、删目录、枚举。DirectoryInfo绑在某一个目录实例上,方便拿FullName、列子目录、列文件。CreateDirectory在目录已存在时不会把里面东西删掉,只是返回对应信息。Move会把整个文件夹挪走;目标位置如果已经有同名文件夹,调用会失败。
| 能力 | API | 说明 |
|---|---|---|
| 判断 / 创建 / 删目录 | Exists / CreateDirectory / Delete |
Delete(path, false) 只删空目录;true 递归删除 |
| 列子目录 | GetDirectories |
返回子文件夹路径,不含普通文件 |
| 列文件 | GetFiles |
可配通配符和是否递归子目录 |
| 目录详情 | DirectoryInfo:FullName、Name、GetDirectories、GetFiles |
GetFiles 返回 FileInfo[],可看 Length、Extension |
| 上级目录 | Directory.GetParent |
得到父目录的 DirectoryInfo |
手写二进制协议的小例子(Student 存档)
- 写入顺序与 Student 练习一致:
age四个字节 →name的 UTF-8 长度(四个字节)→name的字节 →number四个字节 →sex一个bool。读的时候用index记录当前偏移:读完age后index += 4,读完长度字段后再index += 4 + nameBytesLength,其余字段同理。 - 存档目录没有就先
CreateDirectory。FileStream放在using里,Write完记得Flush。 - 读之前
File.Exists;小练习里可以把整文件读进一个byte[],再按上面的顺序拆字段。正式项目变大后要改成流式或加分块,这里不展开。
BinaryFormatter 与可序列化类型
- 需要交给
BinaryFormatter的类型要标[System.Serializable]。里面再嵌别的引用类型,那些类型也要能序列化,否则运行时要么丢字段要么直接异常。 - 教程示例覆盖基本类型、数组、
List<T>、Dictionary<,>、自定义类/结构;与 Unity / .NET 版本相关的细节以你当前工程实测为准。 BinaryFormatter在新版 .NET 里处境很差:标记过时、部分环境直接没有,而且不能用来吃来路不明的二进制。这套笔记用它,是为了把「对象 → 字节 → 文件」跑通;真项目存档请按组里规范换 Json、MessagePack、自研格式等。
[System.Serializable]
public class Person { … }
[System.Serializable]
public struct StructTest { … }
序列化 vs 反序列化 对比
| 流程 | 流对象 | 使用类 | 关键方法 | 说明 |
|---|---|---|---|---|
| 序列化(内存) | MemoryStream |
BinaryFormatter |
Serialize 后 ToArray() 取字节 |
只要已写入的那一段;别拿 GetBuffer() 整数组去写盘或 XOR,尾部常有废字节 |
| 序列化(文件) | FileStream |
BinaryFormatter |
Serialize(stream, obj) |
对象图直接进文件 |
| 反序列化(文件) | FileStream |
BinaryFormatter |
Deserialize(stream) → 对象 |
从磁盘文件还原 |
| 反序列化(内存) | MemoryStream |
BinaryFormatter |
Deserialize(stream) → 对象 |
byte[] 包一层 MemoryStream,和「收到网络包再反序列化」同一套路 |
序列化流程要点
内存流方式
new MemoryStream()BinaryFormatter.Serialize(memoryStream, obj)memoryStream.ToArray()得到要保存或发送的字节
文件流方式
new FileStream(..., FileMode.OpenOrCreate, FileAccess.Write)- 同一个
BinaryFormatter往文件流里Serialize Flush(),流在using里关掉即可
反序列化流程要点
文件流方式
File.Open或FileStream只读打开Deserialize成目标类型,示例代码里用as Person接
内存流方式
File.ReadAllBytes先拉到内存(课上用来假装网络收包)new MemoryStream(bytes)- 再
Deserialize
加密与异或示例(演示向)
- 序列化得到
byte[]之后,再按你的规则变换;读盘回来先逆运算,再交给Deserialize。他人拿到文件但不知道规则时,难以还原成对象。 - 单字节
key异或两次回到原值,用来理解「对称、可逆」够用了,谈不上密码学安全。真要加密,上 AES,密钥别写死在客户端明文里当唯一防线。 - 正文里点到 MD5、SHA1、HMAC、AES,主要是认名字:谁是哈希、谁做消息认证、谁是对称加密。真要接库,直接用维护中的方案,别自己造轮子。
二进制数据管理器(单例封装)
- 练习题里的写法:静态单例持有一个
SAVE_PATH,指向persistentDataPath下面的子目录。Save里若目录不存在就CreateDirectory。 Save(object, fileName):FileStream打开或创建,只负责写;BinaryFormatter把对象写进去。Load<T>(string fileName) where T : class:没有文件就return default(T),一般是null,外面要判断。有文件则只读打开,Deserialize之后as T。
核心注意事项
| 场景 | 陷阱 | 应对 |
|---|---|---|
| 字节顺序 | BitConverter 在 PC 上常见小端,和 Java 或部分网络字节序相反 |
协议写清楚;必要时对字段做 Reverse |
| 变长字符串 | 只写 UTF-8 内容,没有长度 | 前面写 int 长度,再写 body |
| MemoryStream | GetBuffer() 拿到的数组往往比实际写入长 |
用 ToArray(),或只处理 stream.Length 那么长 |
| 流未释放 | 文件被占用,Delete / 覆盖失败 |
using + 需要时 Flush |
| 编码混用 | 读写两端编码不一致 | 全链路 UTF-8 |
| 非空目录 | Delete(path, false) 对非空目录抛异常 |
true 递归删,或先手动清空 |
| 路径拼接 | 手写 \ / 在换平台时踩坑 |
Path.Combine;玩家数据走 persistentDataPath |
| 短写长留 | OpenOrCreate 复写更短的数据,文件尾部留着旧垃圾 |
写版本号、Create 截断、或删了重建 |
| BinaryFormatter | 来路不明的包、长期演进 | 课内练手;线上换团队认可的序列化方案 |
11.3 面试题精选
基础题
1. BitConverter 的字节序与 ToInt32 起始下标
题目
BitConverter.GetBytes 得到的字节有什么 endian 特点?BitConverter.ToInt32(byte[] bytes, int startIndex) 里 startIndex 用错会怎样?
深入解析
- 常见桌面环境上
BitConverter按小端排字节;跨语言或网络要核对协议。可用BitConverter.IsLittleEndian看当前运行时是否小端。 startIndex表示从数组哪一格开始凑 4 字节;后续长度不够会抛异常。- 多字段共用一个
byte[]时,读写偏移必须成对一致。
答题示例
一般是小端,低位字节在前。
startIndex决定从哪开始读 4 字节,算错或越界就异常或读出垃圾数。
参考文章
- 2.各数据类型转字节数据
2. 字符串写进二进制为什么要带长度
题目
把字符串用 UTF-8 写成二进制时,为什么常先写一段长度?
深入解析
- UTF-8 变长,读端不知道一次该
Read多少字节。 - 典型做法:先
int存 UTF-8 字节数,再写内容;读时先 4 字节再读 body。 - 与
FileStream顺序读写规则一致,错序整档报废。
答题示例
UTF-8 每个字符占的字节数不固定。
先写长度再写内容,读的时候先读长度再读那么多字节,协议才闭合。
参考文章
- 4.文件操作相关-文件流相关
- 6.文件操作相关-综合练习题
3. File 整包读写和 FileStream 的选型
题目
File.ReadAllBytes / WriteAllBytes 和 FileStream 各适合什么场景?
深入解析
File的ReadAllXX/WriteAllXX:代码短,适合小文件、配置、体积不大的快照。FileStream:按块顺序读写,适合自定义协议、大文件分块。- Unity 里注意
persistentDataPath,并用using释放流。
答题示例
小文件一次读完或整包写,用
File就行。要自己控制字段顺序或文件很大,用
FileStream分段读写。
参考文章
- 3.文件操作相关-文件相关
- 4.文件操作相关-文件流相关
进阶题
1. FileStream.Read 的返回值
题目
Stream.Read(byte[] buffer, int offset, int count) 返回值含义是什么?设计协议时要注意什么?
深入解析
- 返回本次读到的字节数,某些流可能小于
count;文件流多数能读满,仍建议按返回值写健壮逻辑。 - 流有当前位置,连续
Read自动后移。 - 定长字段与变长字段交错时,偏移要手算清楚。
答题示例
返回值是这次实际读了多少字节。
协议里 int、带长度字符串要按写的顺序读,offset 跟着挪。
参考文章
- 4.文件操作相关-文件流相关
2. Directory.Delete 的两个参数
题目
Directory.Delete(string path, bool recursive) 里 recursive 为 false 和 true 分别会怎样?
深入解析
false:仅空目录可删。true:整棵子树删掉,危险,生产环境要确认或备份。
答题示例
false目录里一有东西就删不掉。
true递归全删,用之前要想清楚有没有重要文件。
参考文章
- 5.文件操作相关-文件夹相关
3. MemoryStream:ToArray 与 GetBuffer
题目
序列化进 MemoryStream 后,ToArray() 和 GetBuffer() 有何区别?为何和异或加密有关?
深入解析
ToArray()只拷贝当前流里已写入的那一段,长度与流的逻辑长度一致。GetBuffer()拿到的是内部缓冲区引用,buffer.Length往往大于MemoryStream已写入的字节数,尾部可能是未初始化的槽位。- 对
GetBuffer()整数组做 XOR 或WriteAllBytes会把尾部脏字节带进去,解密或反序列化失败;应用ToArray()或只处理前stream.Length字节。
答题示例
ToArray()长度刚好是写入的数据。
GetBuffer()可能后面多一截空的,拿来加密或写入会把脏数据弄进去。
参考文章
- 7.CSharp类对象相关-序列化
- 9.CSharp类对象相关-二进制数据加密
深度题
1. BinaryFormatter 的风险与替代
题目
为何不建议对不可信二进制做 BinaryFormatter 反序列化?Unity 项目里存档你会怎么选型?
深入解析
- 属于典型不安全反序列化:可构造类型链(gadget)在反序列化时执行非预期逻辑;新版本 .NET 限制多或已移除。
- 教学理解对象图可以;线上常见 JSON/MessagePack + 版本号、自研紧凑格式或
ScriptableObject等。 - 迁移要设计旧档兼容。
答题示例
不可信二进制用
BinaryFormatter反序列化,可能触发恶意 gadget 链执行代码。真项目我更倾向带版本头的文本或二进制格式,或用团队定的序列化方案。
参考文章
- 7.CSharp类对象相关-序列化
- 8.CSharp类对象相关-反序列化
2. 手写协议与 BinaryFormatter
题目
像 Student 练习那样手写字段顺序,和直接 BinaryFormatter 序列化对象,各有什么利弊?
深入解析
- 手写:体积、行为可控,易加魔数与版本;改字段要同步改读写。
BinaryFormatter:快但不透明、演进难、安全与跨语言差。
答题示例
手写协议透明、省空间,改结构麻烦。
BinaryFormatter写得快,长期维护和安全性不如显式格式。
参考文章
- 6.文件操作相关-综合练习题
- 7.CSharp类对象相关-序列化
3. 本地加密的现实边界
题目
客户端存档做异或混淆能防什么?密钥放包里会怎样?
深入解析
- 单层异或极易被逆向,只能挡随便看看文件的人。
- 密钥硬编码终会被提取;防作弊常要服务端参与或校验。
- 加密是提高成本,不是绝对安全。
答题示例
异或只能算演示,防不了会调试的人。
密钥在客户端总会被抠;真要保护得服务端和整套方案一起上。
参考文章
- 9.CSharp类对象相关-二进制数据加密
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

