7.聊天系统离线群聊消息设计
7.1 群聊消息需求
- 在线消息:群内在线成员需在第一时间内收到消息,保证实时性。
- 离线消息:群内离线成员在下次登录时,能够拉取到自己未读的历史消息。
- 挑战:群聊相比单聊,离线消息的存储与投递复杂度更高,需要考虑大群规模、存储冗余、可达性与交互开销等因素。
7.2 消息投递流程
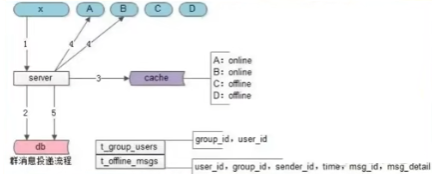
假设群 XXX 有 5 名成员:X、A、B、C、D,其中 A、B 在线,C、D 离线。
在线消息投递流程
假设X向群XXX发送了消息,步骤如下
sequenceDiagram
autonumber
participant X_Client as X
participant Server
participant DB
X_Client->>Server: SendGroupMsg(groupId, content)
Server->>DB: Insert into GroupMessage
Server->>DB: Query all GroupMember by groupId
loop 遍历成员
alt 在线
Server-->>Member: Push message + messageId
else 离线
Server->>DB: Insert into GroupOfflineIndex(memberId, messageId)
end
end
- 落库消息实体:X向Server发出了群消息。所有群消息先写入
GroupMessage。 - 查询群成员列表:Server去DB中查询群中的所有用户,批量获取群内所有成员。
- 群成员在线状态查询:Server去Cache中查询用户的在线状态。
- 实时推送:对在线的用户A和B进行实时的消息推送。
- 离线索引:对离线的用户C和D进行离线消息存储。写入离线消息表。
离线消息拉取流程
假设C重新登录后,步骤如下

- C重新登录的时候,向Server拉取XXX群中属于C的离线消息。
- Server从DB中拉取XXX群中属于C的离线消息并返回用户C
- Server从DB中删除群用户C中群离线消息。
缺点分析
核心缺点是存储冗余。对于同一份群消息的内容,多个离线用户要存储很多份。假设群中有2000个离线用户,那要冗余2000份。存储压力太大。
7.3 存储冗余优化
- 原方案:不同离线用户的每条离线未读消息都在离线消息表中写入一条记录,即便是相同消息也写入多份,大群场景下冗余严重。
- 优化思路:
- 消息实体只存一份:所有群消息仅写入到一个群消息表中。只有群消息表存储每条消息的实体内容。
- 离线消息表变成离线消息索引表:离线消息索引表只存储离线成员的离线消息的消息ID,大幅降低数据库的存储冗余。
- 删除离线索引表:不再为每个离线成员写入索引,大幅节省存储。
存储冗余优化后在线消息投递流程
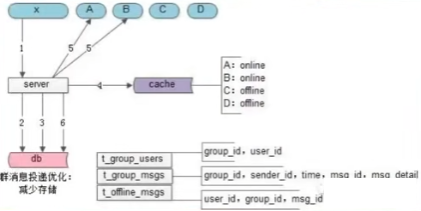
修改后在线用户 X 发消息要分两步存储:
- 步骤三存储的是离线消息实体
- 步骤六存储的是离线成员的离线消息ID,无需为每个离线用户存储消息实体
存储冗余优化后离线消息拉取流程
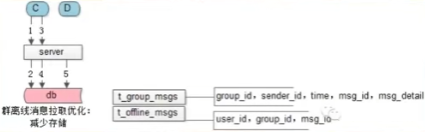
修改后离线用户C上线要分两步拉取:
- 先拉用户C的离线消息id集合
- 再基于离线消息id集合拉用户C的离线消息实体集合,
- 最后Server才从DB中删除群用户C中群离线消息ID。
缺点分析
服务重启、路由丢包、客户端崩溃,在线投递和离线拉取都可能导致用户看不到消息,不能保证消息的可达性。
7.4 应用层 ACK 与可靠性
为防止“服务重启、路由丢包、客户端崩溃”导致消息不可达,在线推送和离线拉取均需应用层 ACK 保障。
加入ACK后在线消息投递流程
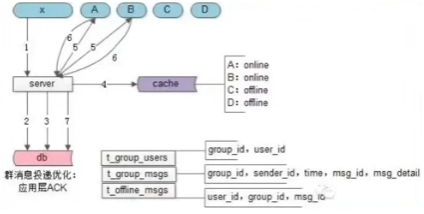
修改后在线用户X发消息,消息要直接存入实体和ID,以及确认后才删除消息ID:
- 步骤三存储消息实体后,也要直接将这个离线消息实体ID写入到所有用户的离线消息索引表中
- 步骤六是在线用户A收到消息后,要返回当前消息的ACK确认,表示消息到达
- 步骤七是收到当前消息的ACK确认后,Server才从DB中删除发送ACK的用户的群离线消息ID。
加入ACK后离线消息拉取流程
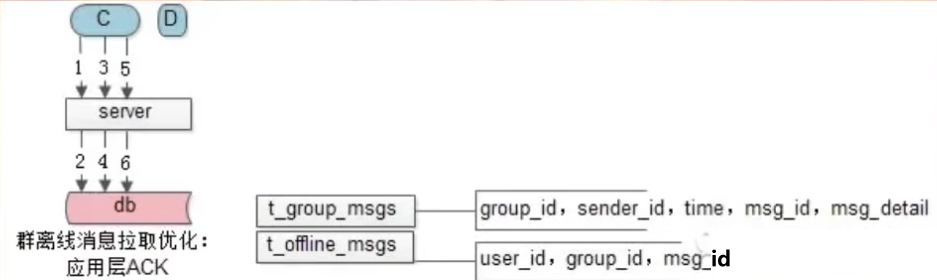
修改后离线用户C上线要分两步拉取和一次确认:
- 先拉用户C的离线消息id集合
- 再基于离线消息id集合拉用户C的离线消息实体集合,
- 发送拉取到的消息的ACK给Server
- Server收到了应用层的ACK后,才从DB中删除群用户C中群离线消息ID。
重复消息问题
问题:
- 由于ACK有可能丢失,所以导致消息ID并没有删除。所以有可能用户收到重复的群消息。
解决方案:
- 客户端自行对MessageID去重。客户端知道自己本地缓存了哪些消息,就知道本地有哪些消息ID。拉取时收到重复的去掉即可。
可优化点分析
当前存储可以进一步优化。对于离线的每一条消息,虽然只存储了消息ID,但是每一个用户的每一条离线消息都要在数据库中保存一条。离线消息ID索引表有没有办法减少离线MessageID的记录数量呢?
7.5 加入最近一条ACK的群消息 减少离线消息索引表记录数量
优化思路
对于一个群用户,在他离线之后,所有的离线消息理论上都收不到。
所以无需每一条离线消息都存储一个消息ID。只需要将最近一条收到的离线消息ID或是时间记录下来即可。
下次登录时,拉取那条消息之后的所有群消息,而不是将所有离线消息 ID 存满整张离线索引表。
群成员表增加一个属性,记录群成员最近一条ACK的群消息。消息ID或者消息时间都可以(lastMessageId / lastMessageTime:)。
加入最近一条ACK的群消息属性后在线消息投递流程
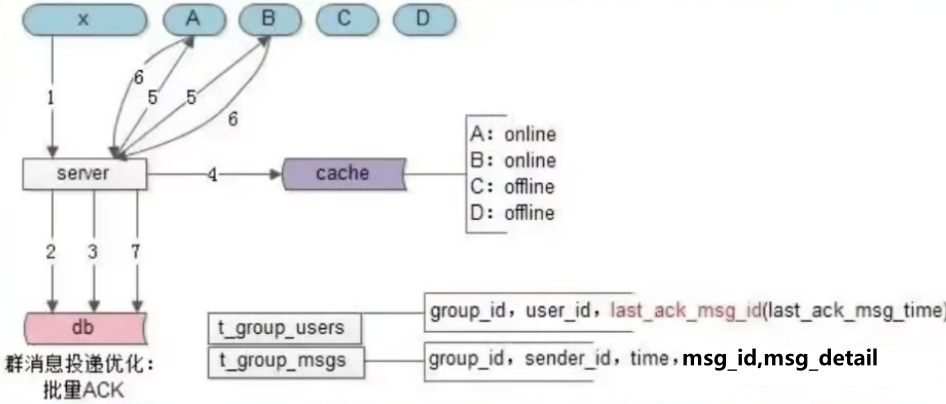
加入lastMessageId之后,群的在线消息投递流程优化为:
- 步骤三在消息实体存储到群消息表之后,不再需要对离线消息索引表进行操作。(之前的思路是会把离线消息实体ID写入到所有用户的离线消息索引表中)
- 而在线用户A和B在应用层ACK之后,只需要将对应群成员的lastMessageId更新即可,也不需要将MessageId从离线消息表删除。
加入最近一条ACK的群消息属性后离线消息拉取流程
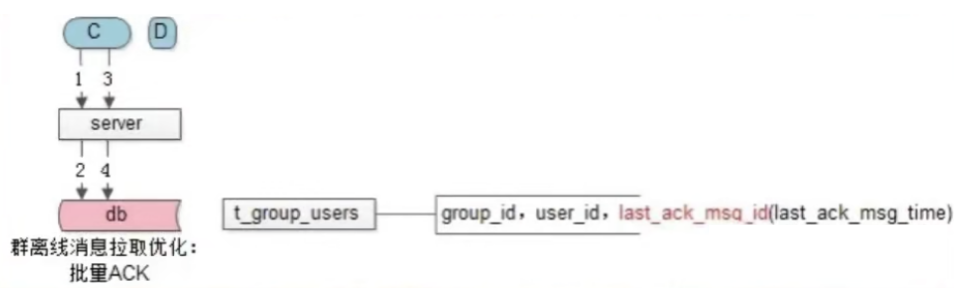
修改后离线用户C上线要分两步拉取和一次确认,但是无需操作离线消息索引表:
- 在ACK离线消息之后,更新lastMessageId即可,而不需要操作离线消息索引表。
群离线索引表是否失效?
改为用 lastMessageId/lastMessageTime 记录成员进度后:
GroupOfflineIndex 表中为每个成员逐条存储 messageId 的做法变得多余。
在线投递阶段,只需写入 GroupMessage;离线拉取阶段,直接用 lastMessageId 筛选新消息。
因此:原先的 GroupOfflineIndex 表可以废弃——所有离线进度均由 GroupMember 表中的最近 ACK 字段承载。
缺点分析
可能产生ACK风暴。
加入ACK机制之后,假设每一个群有500个用户,每条群消息会引入500个应用层ACK。
消息风暴扩散系数非常的大,对服务器造成巨大的冲击。
7.6 批量 ACK 防止风暴
大群场景下,每条消息的 ACK 风暴对服务器压力大,可采取两类批量策略:
按条数批量 ACK
- 收集 N 条消息后,一次性上报 ACK(包含 N 个
messageId)。 - ACK 请求量降为原来的 1/N。
- 收集 N 条消息后,一次性上报 ACK(包含 N 个
按时间间隔批量 ACK
- 每隔 T 毫秒(如 200 ms)统一上报已接收消息的 ACK。
- 平滑 ACK 高峰,降低瞬时并发。
7.7 数据结构优化演进
flowchart LR
subgraph 未优化数据结构
A1["GroupMember
- groupId
- memberId"]
A2["GroupMessage
- messageId
- groupId
- senderId
- content
- timestamp"]
A3["GroupOfflineIndex
- groupId
- memberId
- messageId"]
end
subgraph 优化后数据结构
B1["GroupMember
- groupId
- memberId
- lastMessageId
- lastMessageTime"]
B2["GroupMessage
- messageId
- groupId
- senderId
- content
- timestamp"]
end
A1 -->|"添加 lastMessageId/Time,替代离线索引"| B1
A2 -->|"保持不变"| B2
A3 -->|"废弃"| B1
初始数据结构(未优化)
在没有任何优化之前,离线群聊消息需要针对每个离线成员、每条消息都在数据库中写入一条索引记录,因此会涉及三张表:
- GroupMember(群成员表)
GroupMember {
groupId: String, // 群组唯一标识
memberId: String, // 成员唯一标识
-- 无 lastMessageId/Time --
}
- 只用于维护群成员关系,不记录进度。
- GroupMessage(群消息表)
GroupMessage {
messageId: String, // 消息唯一标识
groupId: String, // 所属群组
senderId: String, // 发送者
content: String, // 消息内容
timestamp: DateTime, // 发送时间
}
- 存储所有群聊消息的完整实体。
- GroupOfflineIndex(群离线索引表)
GroupOfflineIndex {
groupId: String, // 群组唯一标识
memberId: String, // 离线成员唯一标识
messageId: String, // 待拉取的离线消息 ID
}
- 当群消息到达时,对每个离线成员写入一条记录
- 拉取并 ACK 后,再删除对应记录
最终数据结构(优化后)
经过删除冗余索引表、进度集中在成员表的优化后,只需要两张表即可支撑在线+离线拉取:
- GroupMember(群成员表 — 优化后)
GroupMember {
groupId: String, // 群组唯一标识
memberId: String, // 成员唯一标识
lastMessageId: String, // 最近一次已确认(ACK)的消息 ID
lastMessageTime: DateTime, // 最近一次已确认(ACK)的消息时间
}
- 新增
lastMessageId/lastMessageTime字段 - 用于替代原先
GroupOfflineIndex中的多条记录,集中记录成员拉取进度
- GroupMessage(群消息表 — 优化后)
GroupMessage {
messageId: String, // 消息唯一标识
groupId: String, // 所属群组
senderId: String, // 发送者
content: String, // 消息内容
timestamp: DateTime, // 发送时间
}
- 与初始结构一致,仍存储所有消息实体
- 离线拉取直接基于
lastMessageId筛选,不再访问索引表
对比总结
- 索引表:从「每条消息 × 每个离线成员」的多条写入 → 废弃该表
- 成员表:从只存成员关系 → 增加进度字段,一条记录即可代表该成员所有未读消息区间
- 消息表:保持不变,消息实体只存一份,避免冗余
通过上述变化,既消除了大群场景下的存储冗余,又实现了离线消息的高效分页拉取和端到端可靠性。
7.8 总结
应用层 ACK 保证可达性
无论是在线推送还是离线拉取,都必须在客户端发送 ACK 后才更新或删除消息进度,才能确保“先送达、后确认”,避免网络抖动、服务重启或路由丢包导致的消息丢失。消息实体零冗余存储
群聊消息的内容只在GroupMessage表中存储一份,不再为每个离线成员写多份离线索引,通过GroupMember.lastMessageId/lastMessageTime跟踪进度,从而大幅降低数据库存储压力。批量 ACK 防止风暴
对于大群场景,可采用“按条数”或“按时间间隔”批量上报 ACK,将 ACK 请求量从每条消息一次,降至每 N 条或每 T 毫秒一次,平滑峰值,减轻服务器压力。客户端去重无感知
由于 ACK 可能丢失,客户端需要根据messageId本地去重,确保重复消息不被展示,用户体验不受影响。按需分页拉取
当离线消息量过大时,支持基于lastMessageId的分页拉取,既能控制单包大小,又能渐进式加载历史消息,兼顾性能与用户体验。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

