4.游戏引擎中的渲染实践
4.1 渲染概述
渲染是现代游戏引擎中最核心、最复杂的模块之一。它就像游戏的“画笔”,将开发者构建的虚拟世界转化为玩家屏幕上的2D画面。随着游戏场景从简单的线性关卡发展到广阔的开放世界,渲染系统面临的挑战也日益严峻:它需要在有限的硬件资源下,平衡画质与性能,处理海量的物体和复杂的光照效果,并稳定地输出高帧率、高分辨率的图像。
游戏渲染与计算机图形学
游戏渲染的理论根基源于计算机图形学,但二者侧重点截然不同。计算机图形学更侧重于算法的正确性、数学上的完美表示以及各种渲染效果的实现,对实时性能没有严格要求(例如,电影特效渲染一帧可能需要数小时)。而游戏渲染则是一门“带着镣铐跳舞”的艺术,它首先是一门工程学科。
- 目标不同:图形学追求“效果能否实现”,游戏渲染追求“效果能否在1/30秒(或更短)内实现”。
- 约束不同:游戏渲染必须在严格的性能预算(如33ms/帧对应30FPS)下运行,同时还需与游戏逻辑、物理、网络等系统共享CPU和内存资源。
- 数学算法正确性要求不同:计算机图形学更多关注算法的正确性,游戏渲染保证“看起来对”。

核心挑战与目标
游戏引擎中的渲染系统主要面临四大核心挑战:
- 复杂度挑战:现代游戏场景包含数万个对象,每个对象可能涉及数十种不同的材质和渲染效果(如皮肤、金属、水体、毛发等),管理并高效渲染这些对象是巨大挑战。

- 硬件架构挑战:渲染必须深度适配现代CPU+GPU的异构计算架构。理解数据如何在CPU和GPU之间流动,如何避免瓶颈,是优化的关键。
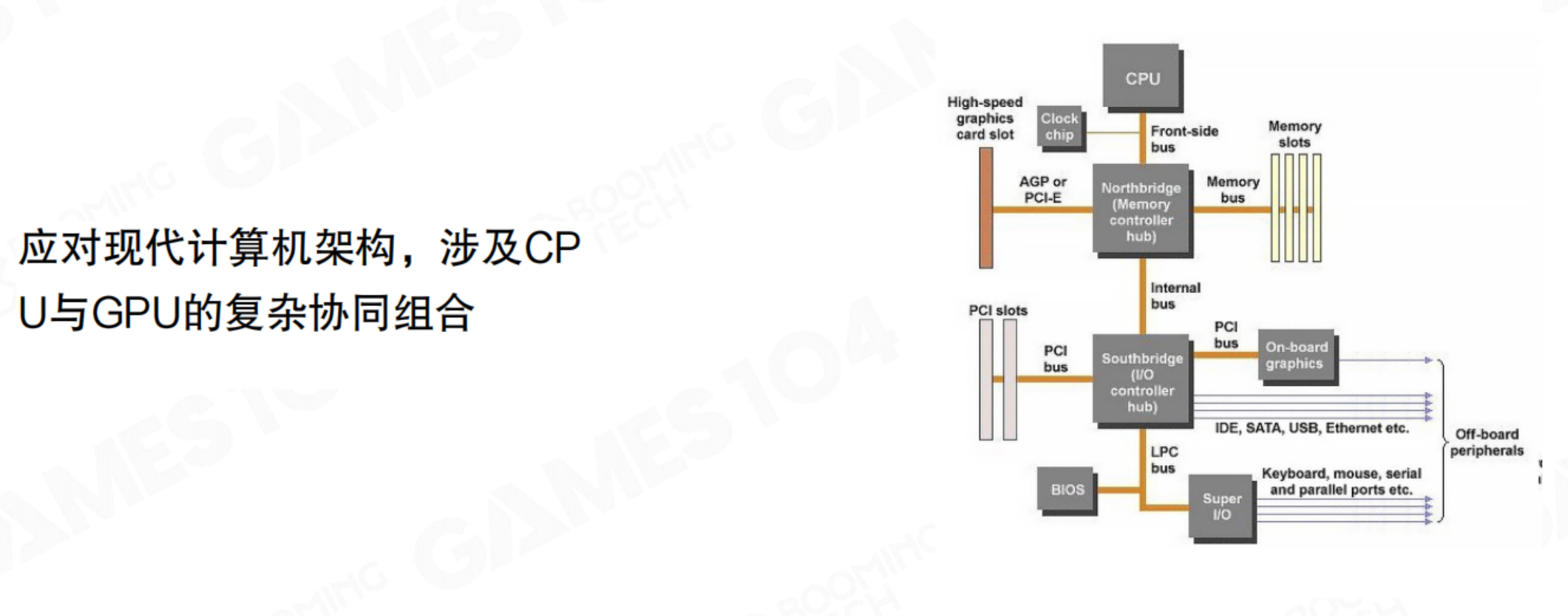
- 性能与画质挑战:玩家对帧率(从30FPS到120FPS+VR)和分辨率(从1080P到4K/8K)的要求越来越高,渲染系统必须提供“防弹”级别的稳定性。

- 资源竞争挑战:CPU的算力和内存带宽是稀缺资源。渲染系统通常只能占用10%-20%的CPU资源,其余需留给游戏逻辑、AI、动画、物理和网络等系统。

- 总结:一款高度优化的实用软件框架,旨在满足现代硬件(PC、主机和移动设备)上游戏的关键渲染需求。

游戏引擎渲染大纲
- 渲染基础:硬件架构、渲染数据组织、可见性剔除。
- 材质、着色器与光照:基于物理的渲染(PBR)、着色器变体、点光/方向光、基于图像的光照(IBL)。
- 特殊渲染:地形、天空/雾、后处理。
- 渲染管线:前向渲染、延迟渲染、前向+、实际管线混合、环形缓冲区与垂直同步、基于瓦片的渲染。
渲染是一个极其庞大的主题,细讲可以讲的非常细。暂时先聚焦以上四块内容
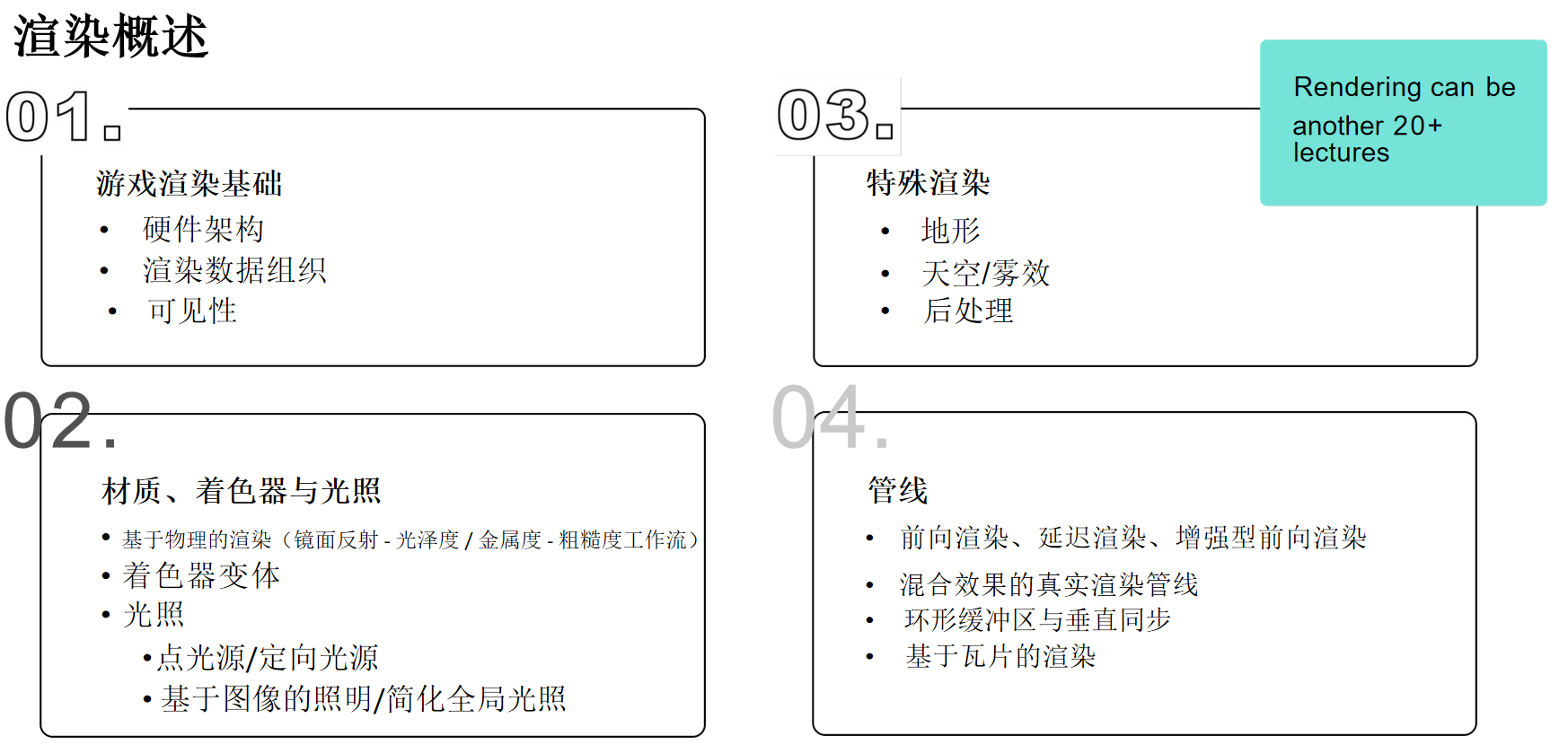
不涉及游戏引擎渲染的模块
由于篇幅和重点所限,不会涵盖卡通渲染、专门的2D渲染引擎、次表面散射(如皮肤)、头发/毛发渲染等高级专题。

4.2 渲染系统的对象
渲染系统的核心任务,是处理一系列定义了场景外观的“对象”,并将它们转换为屏幕上的最终图像。这些“对象”主要包括几何数据、材质属性和纹理,而转换过程则依赖于一系列精心设计的计算阶段。
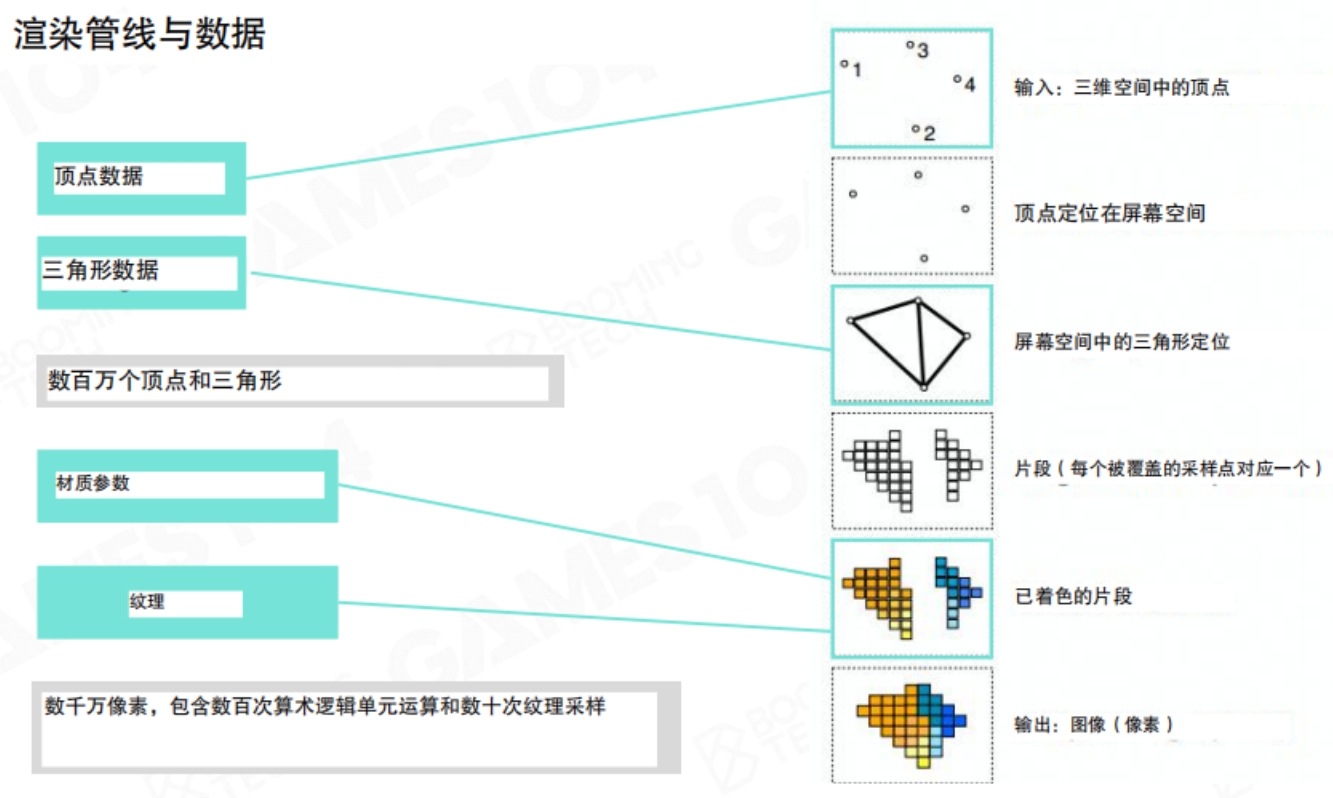
渲染管线与数据流
渲染过程可以看作一个有序的数据处理管线(Pipeline)。这个管线的输入是三维空间中的顶点数据,最终输出则是二维像素图像。
输入(Input):管线起始于海量的原始数据,包括:
- 顶点数据(Vertex Data):定义了几何体的形状,包含数百万个顶点。
- 三角形数据(Triangle Data):定义了如何将顶点连接成三角面片。
- 材质参数(Material Parameters):定义了物体表面的光学属性(如颜色、光滑度)。
- 纹理(Textures):提供了表面的细节图案,需要进行数千万次的像素计算和纹理采样。
处理过程:
- 顶点变换:首先,3D空间中的顶点通过投影变换被定位到屏幕空间。
- 图元组装与光栅化:变换后的顶点被组装成三角形,然后通过光栅化过程,确定哪些像素被这些三角形覆盖,从而生成片段。
- 片段着色:对每个片段(可以粗略理解为潜在的像素)执行着色计算,应用材质和光照,决定其最终颜色。
输出(Output):所有着色后的片段经过混合等操作,最终形成我们看到的图像。
这个过程清晰地展示了渲染的本质:将大量的几何和材质数据,通过GPU的并行计算能力,转化为海量的像素。
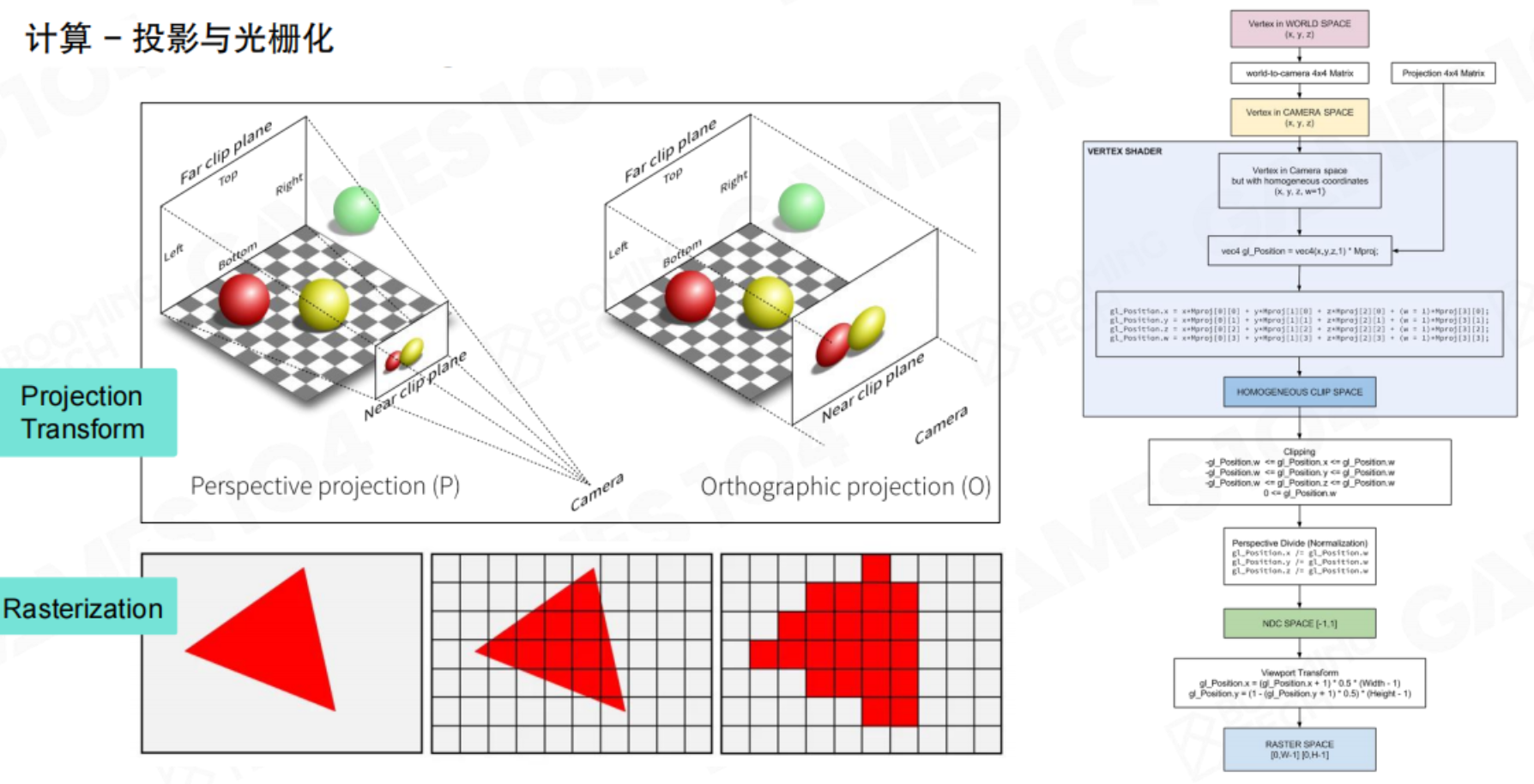
投影与光栅化
这是将3D世界映射到2D屏幕的关键几何阶段。主要包括两种投影方式:
- 透视投影:模拟人眼视觉,远处的物体看起来更小,能产生强烈的深度感,是游戏中最常用的投影方式。
- 正交投影:物体的大小不受距离影响,通常用于CAD或2D游戏界面。
投影变换后,3D三角形被转换到屏幕上的2D坐标。接着进行光栅化,即确定这个2D三角形覆盖了屏幕上的哪些像素(或更精确地说,采样点),并为每个被覆盖的样本生成一个片段。这是后续着色计算的基本单位。
着色计算
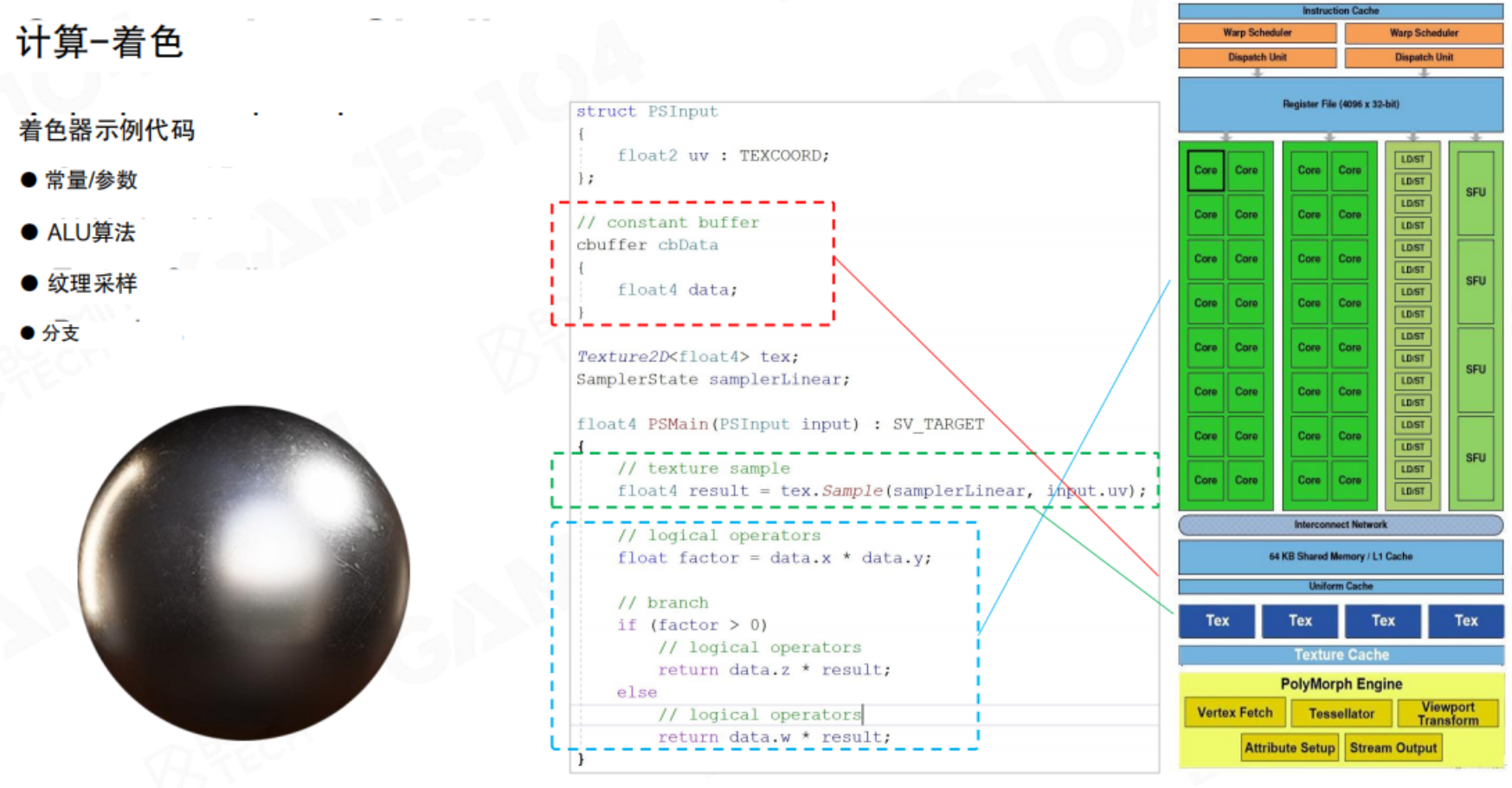
着色是赋予物体颜色和质感的核心步骤,由着色器程序完成。一段典型的着色器代码(如像素着色器)包含以下关键元素:
- 常量/参数:从CPU传递来的全局数据,如灯光位置、颜色。
- ALU算法:算术逻辑运算,执行数学计算来模拟光照模型(如漫反射、镜面高光)。
- 纹理采样:从纹理中获取指定坐标的颜色值。
- 分支:条件判断语句,用于实现复杂的、动态的材质效果。
着色器的执行与GPU的硬件架构紧密耦合。GPU包含大量的计算核心、专用的纹理单元、高速缓存和复杂的调度器(如Warp Scheduler),以确保成千上万的着色器调用能够高效并行执行。
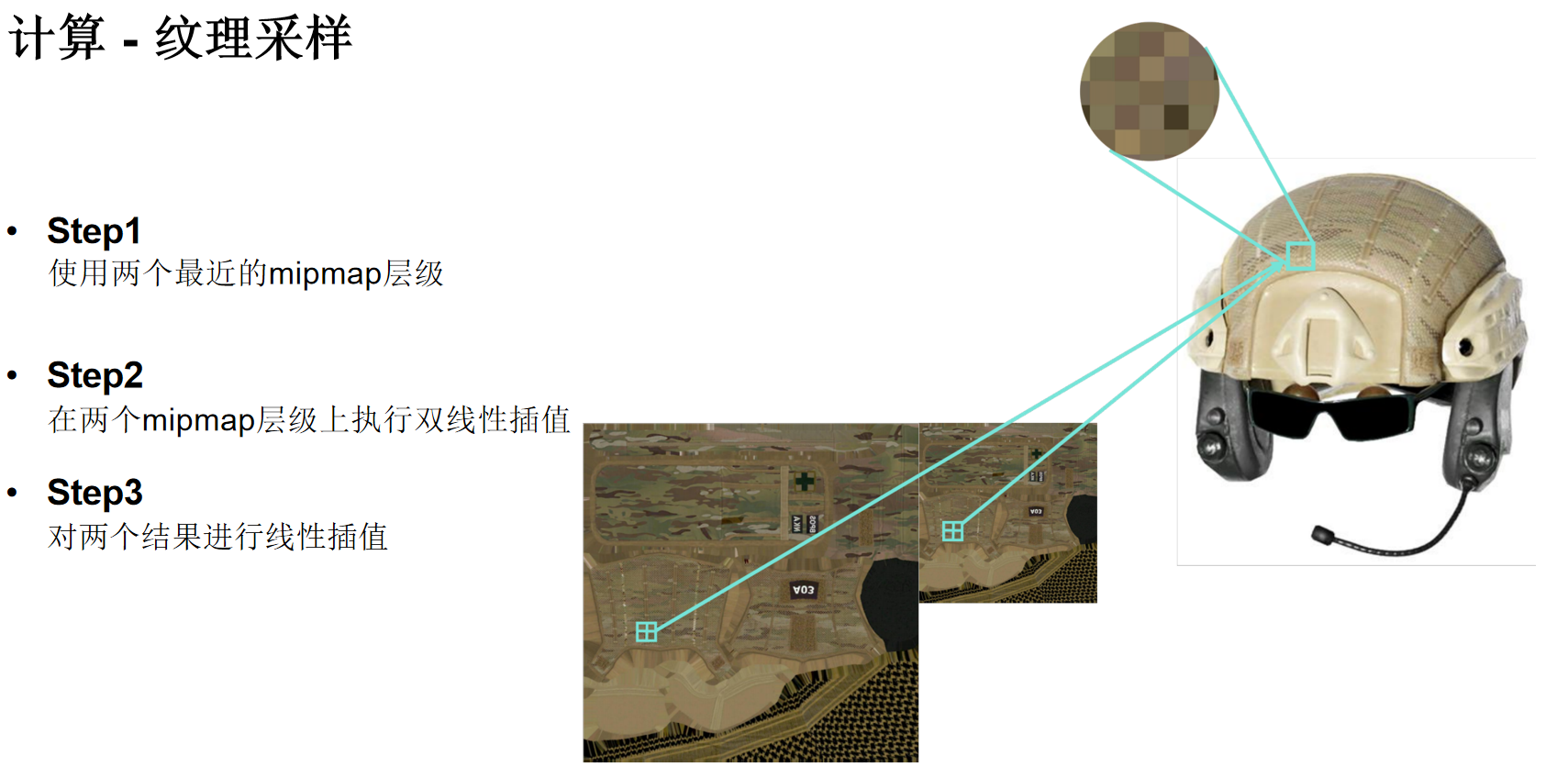
纹理采样
纹理采样不是简单的“取像素点”。为了在放大、缩小纹理时避免出现锯齿或闪烁等走样问题,需要进行复杂的滤波处理。一个高质量的纹理采样(如三线性过滤)通常包含三个步骤:
- 选择Mipmap层级:根据片段在纹理上的覆盖范围,选择两个最合适的预先生成的低分辨率纹理(Mipmap级别)。
- 双线性插值:在选定的每个Mipmap层级上,对目标点周围的2x2纹素进行加权平均(双线性插值),得到两个中间结果。
- 层级间插值:最后,在两个Mipmap层级得到的中间结果之间再进行一次线性插值,从而得到平滑的最终采样颜色。
这个过程确保了无论物体远近,纹理都能呈现出相对平滑和高质量的视觉效果。
渲染系统的对象总结
渲染系统的处理对象是一条从顶点到像素的数据流。它通过投影和光栅化解决“画什么位置”的几何问题,再通过着色和纹理采样解决“画什么颜色”的外观问题。理解这个完整的流程是掌握游戏引擎渲染基础的关键。
4.3 了解硬件架构:GPU
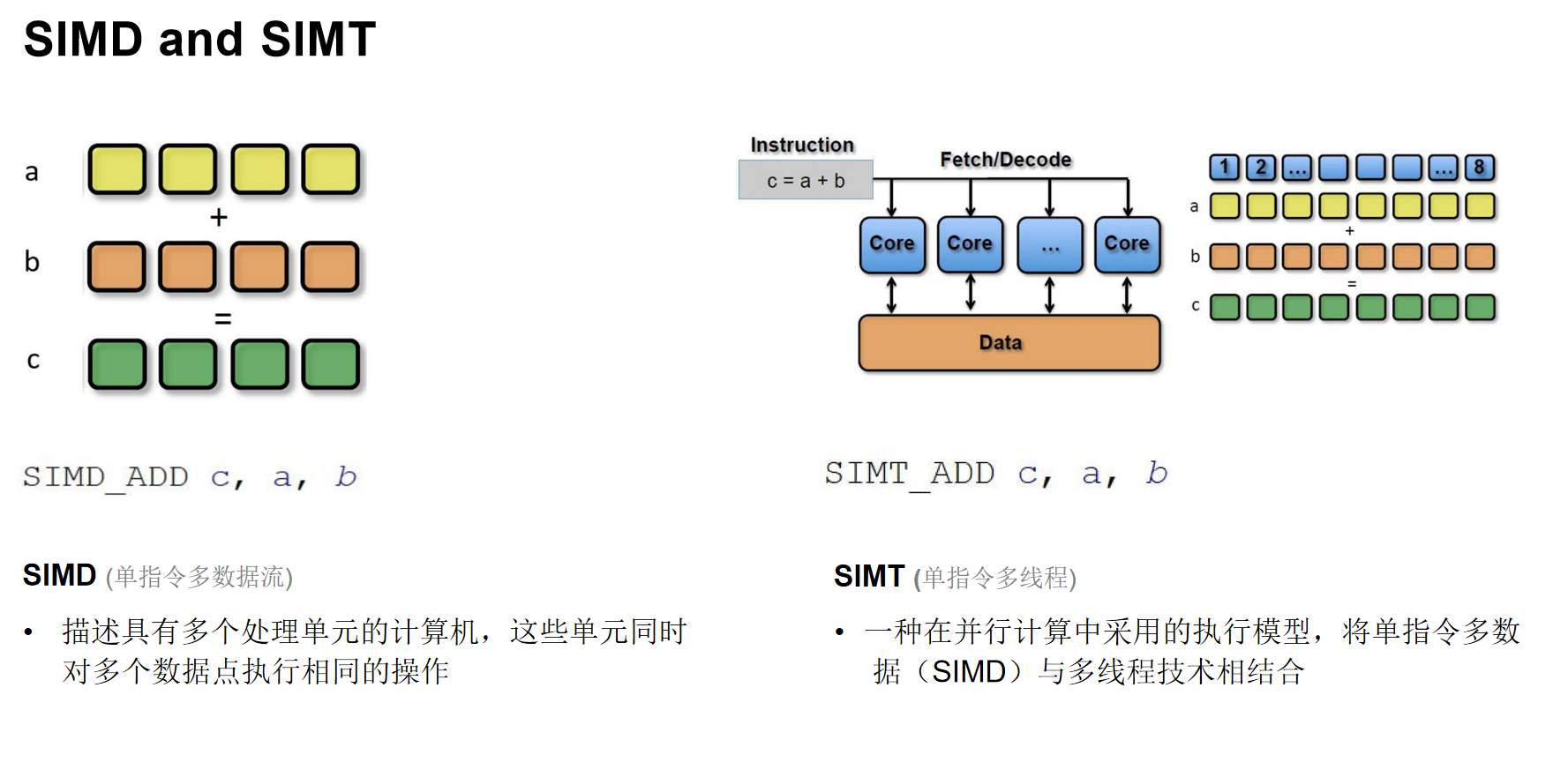
SIMD 与 SIMT 并行模型
理解GPU的并行计算模型是理解其高性能的关键。
- SIMD(单指令多数据):一条指令可以同时对多个数据点执行相同操作。例如,一个指令完成一个四维向量的加法。现代CPU也支持SIMD指令集(如SSE, AVX)。
- SIMT(单指令多线程):这是GPU采用的模型。它将一条指令分配给大量线程(通常是32个线程一组,称为Warp)同时执行。每个线程处理自己的数据,线程之间可以有自己的独立执行路径(支持分支),但效率可能因分支分歧而降低。
核心思想:在编写着色器(Shader)代码时,应尽量让同一Warp内的线程执行相同的代码路径,以最大化并行效率。
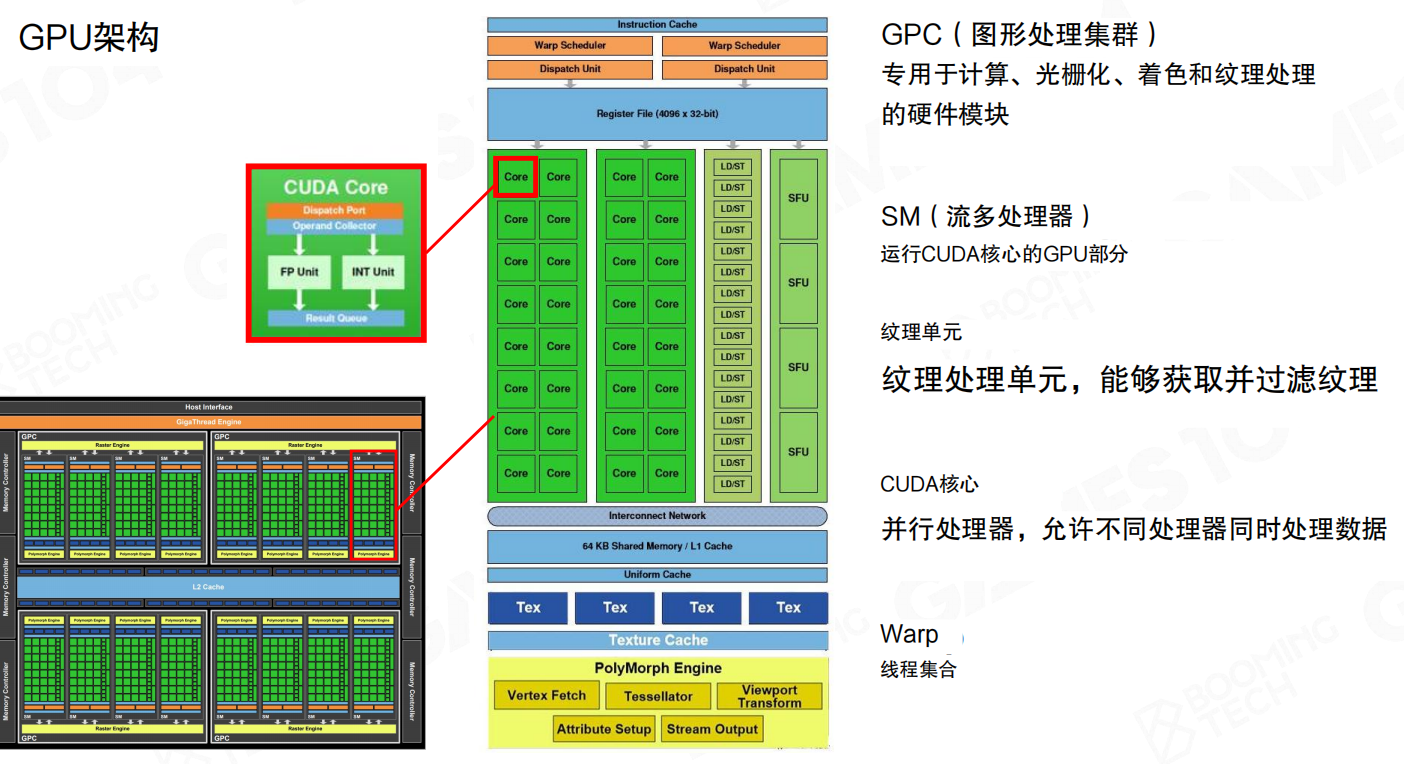
现代 GPU 架构剖析(以 Fermi 为例)
GPU是一个专为大规模并行计算设计的硬件。以经典的Fermi架构为例:
- GPC(图形处理集群):GPU的高级处理模块,一个GPU包含多个GPC。
- SM(流多处理器):GPC的核心组成部分,负责执行CUDA核心(计算单元)的指令。大量SM的并行工作构成了GPU的强大算力。
- CUDA Core:基本的计算单元,用于执行浮点或整数运算。
- Texture Units(纹理单元):专用于纹理采样和过滤的硬件单元。
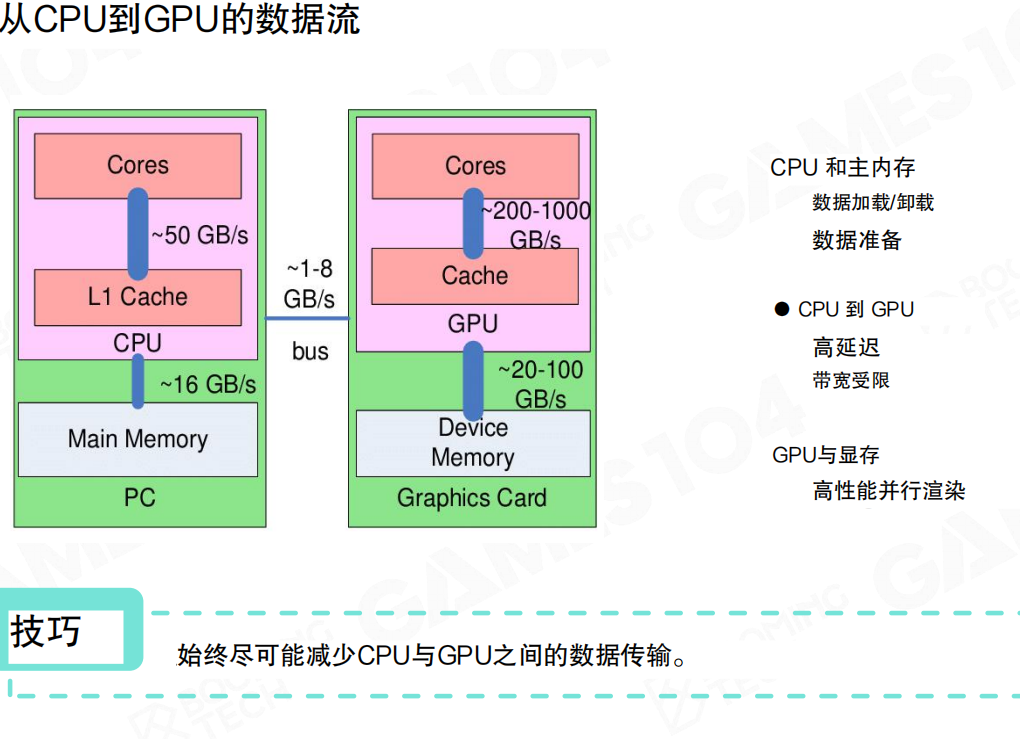
CPU 到 GPU 的数据流与优化原则
CPU和GPU可以看作是两台独立的“机器”,它们之间的数据通信(通过PCIe总线)具有高延迟、有限带宽的特点。。现代CPU的架构是冯诺依曼架构:数据与计算分离,这种架构的问题就是计算式需要准备好数据。因此,优化数据传输是渲染性能的关键。
- 原则一:最小化数据传输。尽量避免在CPU和GPU之间来回拷贝数据。理想的模式是CPU准备数据,单向提交给GPU,由GPU进行大规模并行计算。
- 原则二:警惕“读回”操作。从GPU读回数据到CPU(例如,查询渲染结果)会造成流水线停滞,应极力避免。
- 原则三:利用缓存。GPU有多级缓存(L1, L2)。访问缓存的速度远快于访问显存。因此,让数据访问模式具有良好的空间局部性(访问连续内存)可以极大提升性能。
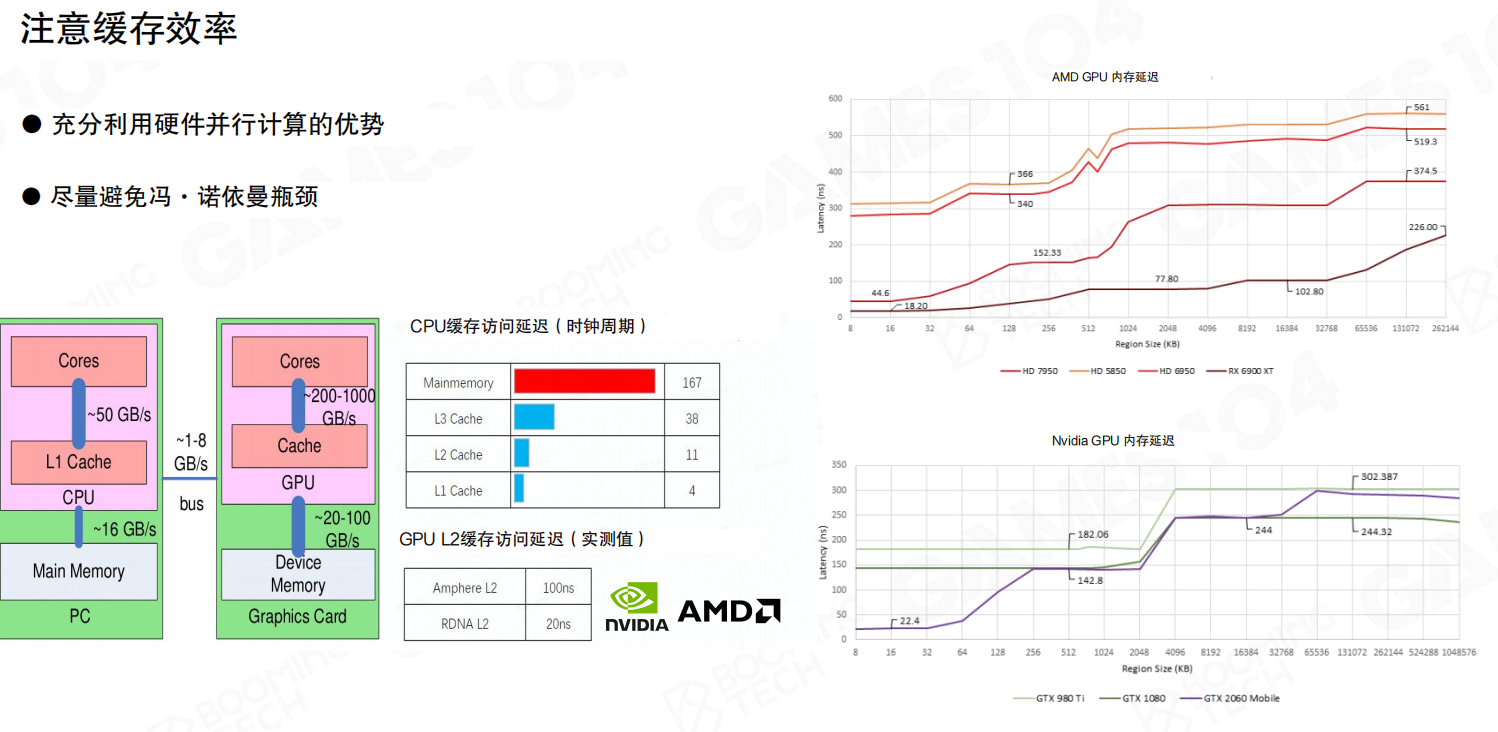

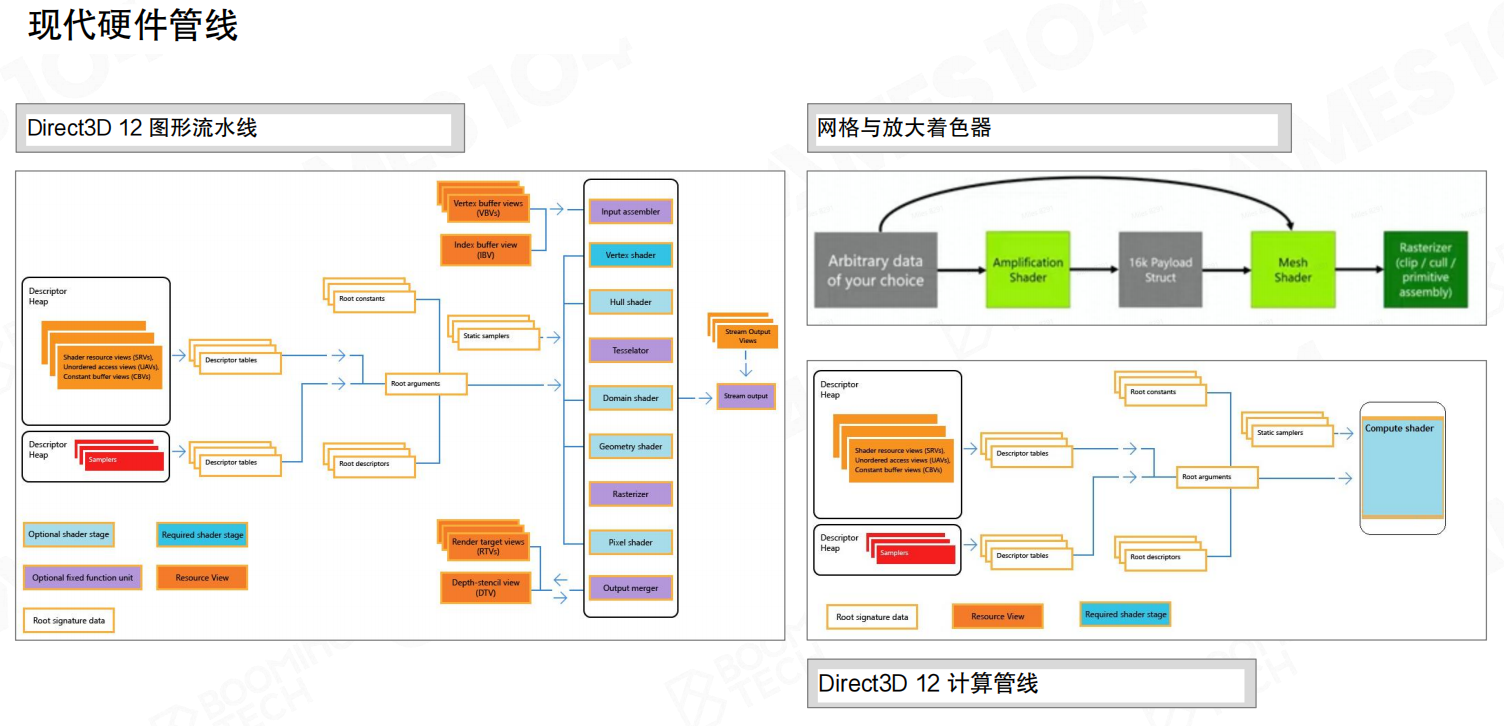
现代硬件管线和其他架构
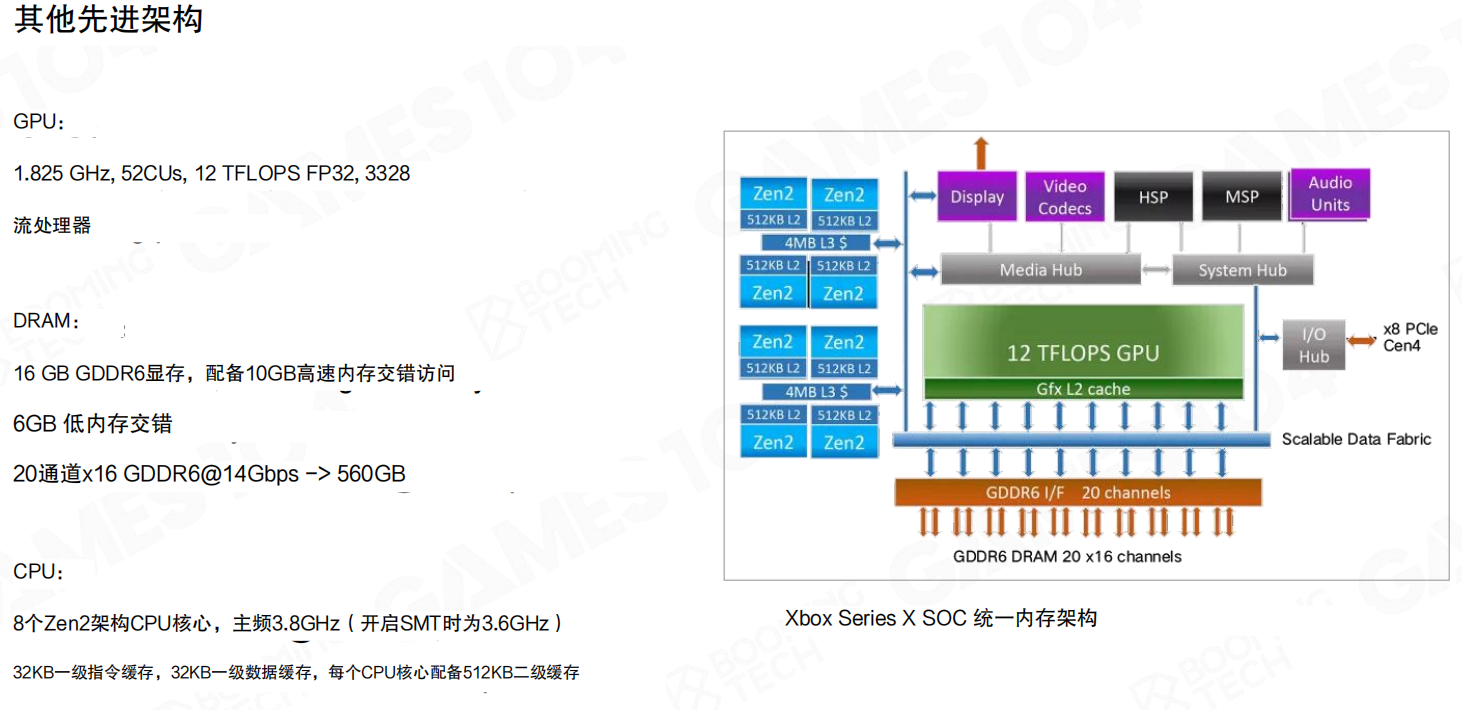
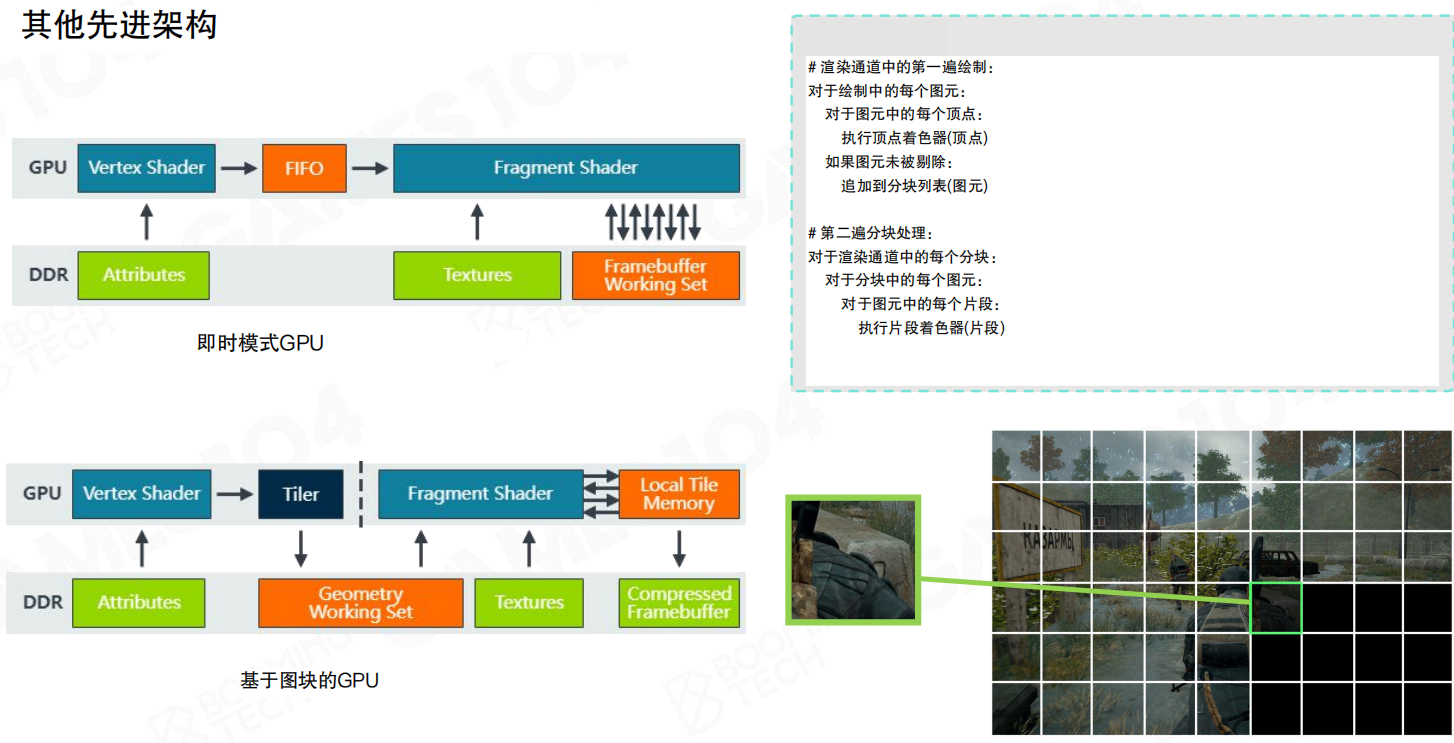
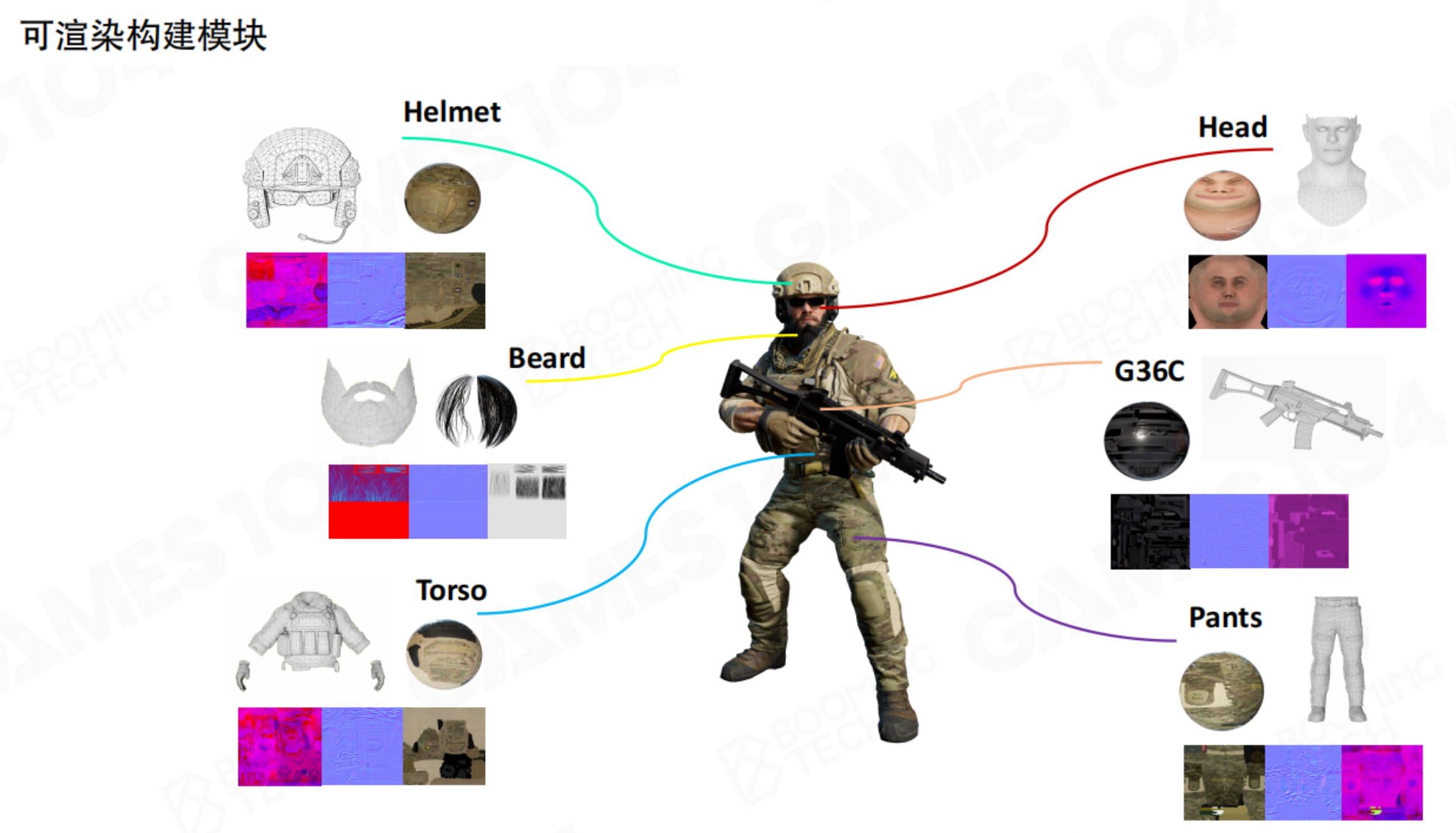
4.4 引擎中的可渲染对象
Renderable 数据构成:网格、材质、变换
在游戏引擎中,场景中的每个可视对象都是一个“可渲染对象”(Renderable)。它通常以组件(Component)的形式挂载在游戏对象(Game Object)上。例如Unity中的Renderer、SkinMeshRenderer组件。其核心数据构成包括:
- 网格(Mesh):定义物体的几何形状,由顶点和三角形构成。
- 材质(Material):定义物体表面的光学属性(如颜色、光滑度、金属度),并引用所需的着色器(Shader)和纹理(Textures)。
- 变换(Transform):定义物体在游戏世界中的位置、旋转和缩放。

- 一个游戏对象可能会分成多个可渲染对象。以一个士兵为例,首先很多网格组成对象的框架;网格的质地各不相同,这就需要材质进行处理;材质中有不同的花纹,需要提供图片数据。
网格数据(决定模型基本形状和结构)
高效存储网格数据是关键。最暴力的表示方法就是,每个三角面都有自生的原始数据,这样的话N个三角面就有N*3个顶点数据。但我们仔细观察就会发现,这样的数据中有很多是重复的的(相邻三角面两个顶点数据相同)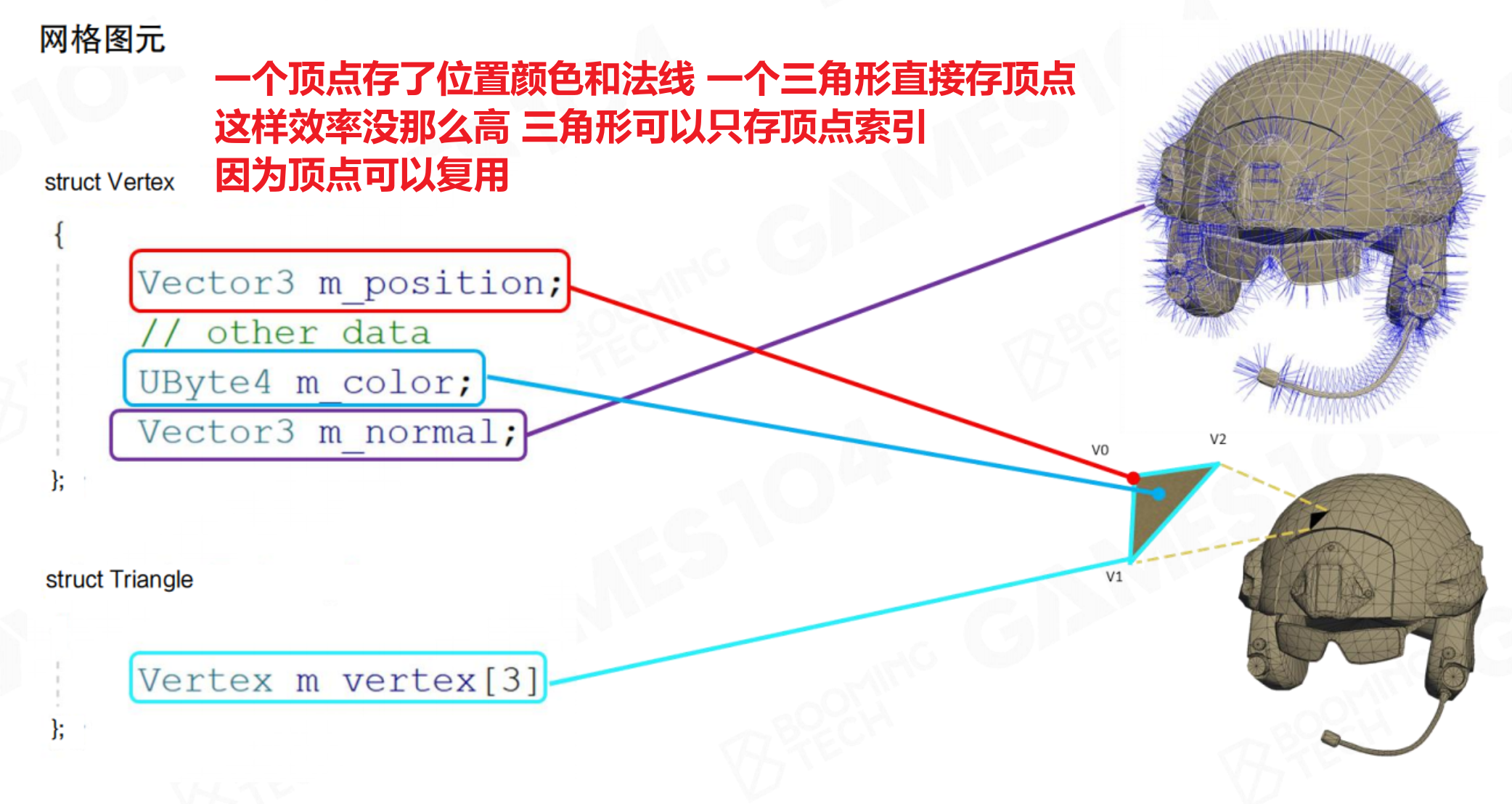
高效一点的方法是以顶点数据为原始数据,通过index索引来组成三角面。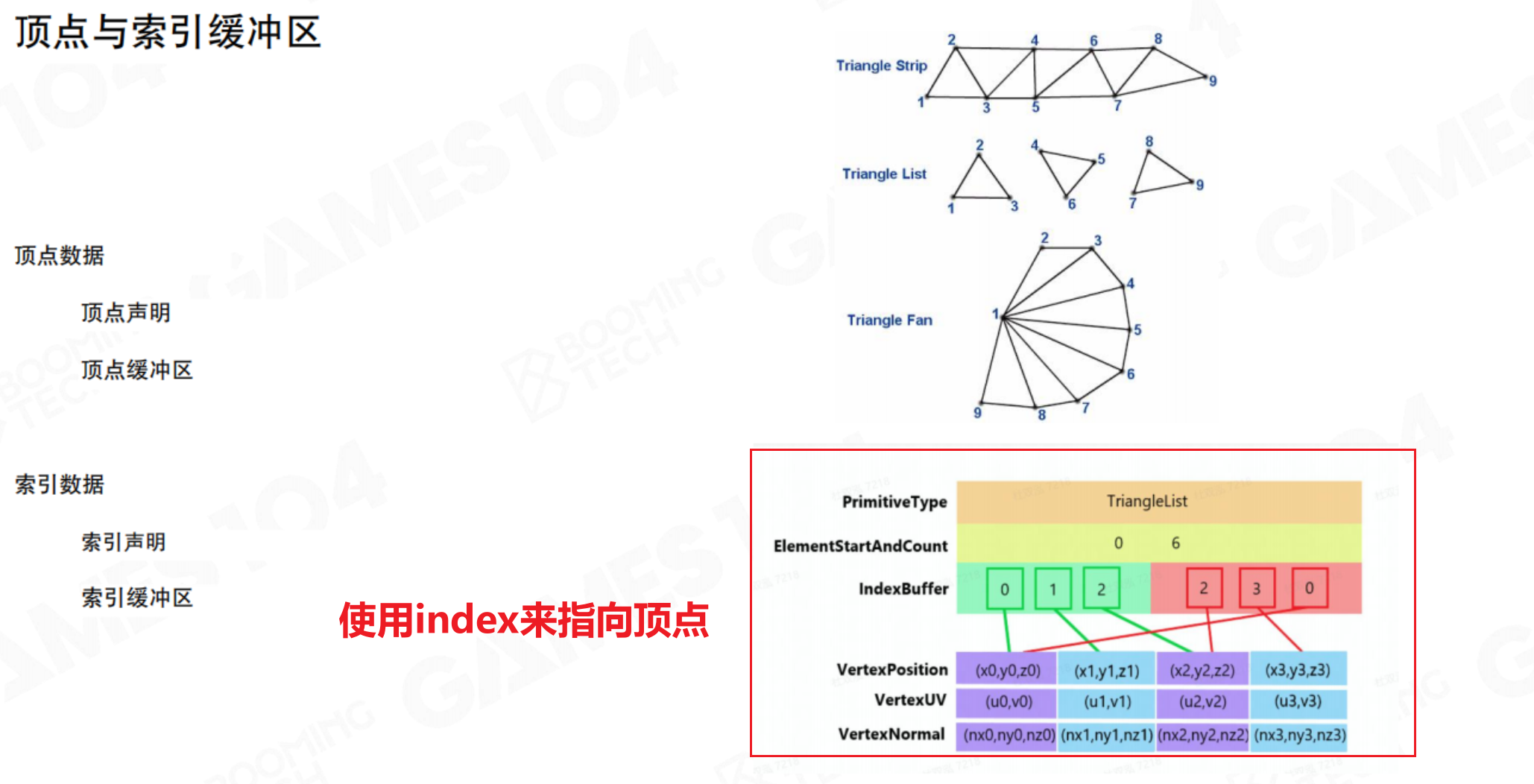
- 顶点缓冲区(Vertex Buffer):存储每个顶点的属性数据,如位置、法线、纹理坐标、切线等。
- 索引缓冲区(Index Buffer):存储构成三角形的顶点索引。通过索引重用顶点,避免了重复存储共享顶点,节省了大量内存。
// 简化的数据结构示例
struct Vertex {
float3 position;
float3 normal;
float2 texCoord;
};
struct Triangle {
int index[3]; // 指向顶点缓冲区的索引
};
除了通过index引用的方式表示,还有Triangle Strip的表示方式:顶点列表中,连续三个顶点表示一个三角面,这样就省去了index数据,并且对缓存友好。
为什么需要每顶点法线? 如果只使用面法线,在渲染平滑曲面(如球体)时会出现明显的棱角。通过为每个顶点存储法线(通常是在建模软件中计算的平均法线),并在光栅化阶段进行插值,才能得到平滑的光照效果。

举例:
想象你要用乐高积木搭一个圆球:**
- 只使用面法线:就像你用的都是标准方形积木。无论你怎么努力,搭出来的永远是一个有棱有角的、像 minecraft 风格的球。
- 使用顶点法线:就像你用了很多特殊形状的、带弧度的积木。虽然近看每一块积木本身也有平面,但拼在一起时,它们的弧度能很好地衔接,从远处看就是一个光滑的球。
游戏引擎做的就是这件事:模型本身(几何形状)还是由“方形积木”(三角形)构成的,但通过巧妙地修改每个“积木角”(顶点)的法线方向,并在渲染时进行混合(插值),最终“欺骗”了你的眼睛,让你看到了一个光滑的曲面。
材质数据(颜料配方单)
需要定义常见材质的渲染模型。 在现代游戏引擎中往往还会集成大量的PBR材质以渲染出更加逼真的图像。


纹理数据(具体的颜料和图案)
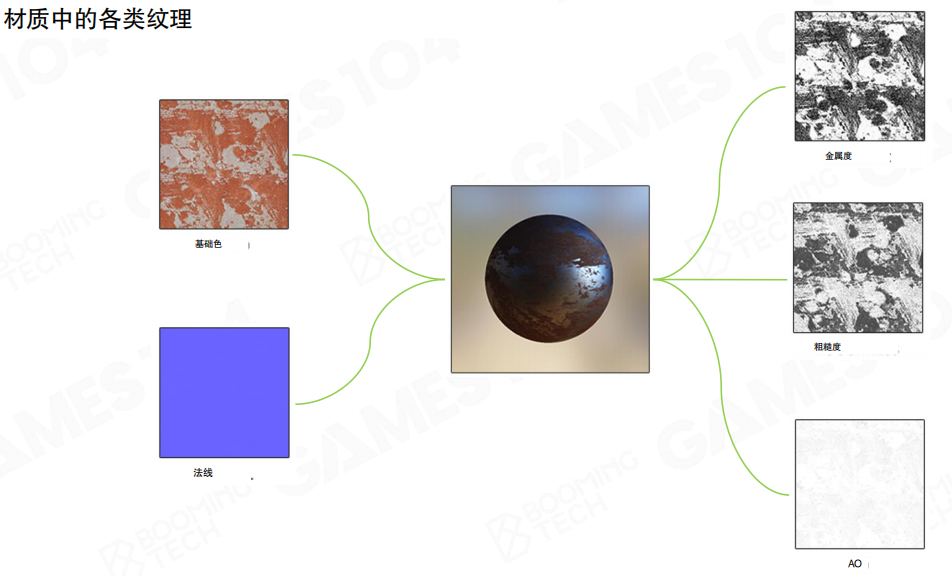
Shader(画师的绘画技法)
进行渲染时需要把编译好的shader连同数据一起提交的GPU上进行计算。
网格、材质、纹理和Shader协同工作
flowchart TD
A[网格 Mesh] --> C[顶点着色器
Vertex Shader]
C --> D[光栅化 Rasterization]
E[材质 Material
(包含Shader代码与参数)] --> D
F[纹理 Texture
(如漫反射/法线贴图)] --> D
D --> H[片元着色器
Fragment Shader]
H --> I[屏幕像素]
- 应用阶段:CPU准备场景数据,包括需要渲染的模型(其网格数据)、使用的材质(包含指向的Shader和参数)、纹理等,并通过Draw Call命令通知GPU开始渲染。
- 几何阶段:GPU读取模型的网格(顶点)数据。顶点着色器(Shader的一部分)开始工作,对每个顶点的位置进行变换(比如从模型自身的坐标系转换到屏幕上的位置),并可以处理一些顶点动画。
- 光栅化阶段:GPU将处理后的三角形转换为屏幕上的像素片元,并为每个片元准备好从顶点插值得到的数据(如纹理坐标、法线等)。
- 像素处理阶段:片元着色器(Shader的另一部分)对每个像素片元进行最终的颜色计算。这时,材质里配置的参数(如颜色、光泽度)和纹理贴图(如漫反射贴图提供的颜色、法线贴图提供的凹凸信息)就会发挥作用。片元着色器根据光照模型等计算出该像素的最终颜色。最终,经过深度测试、混合等操作,像素颜色被写入帧缓冲区,最终显示在屏幕上。
SubMesh
对于一个复杂对象来说,部件的材质各不相同。GPU作为一个状态机,只会保留最后Material所提交的状态进行渲染,那么就不能得到正确的效果。因此就需要引入SubMesh的概念:
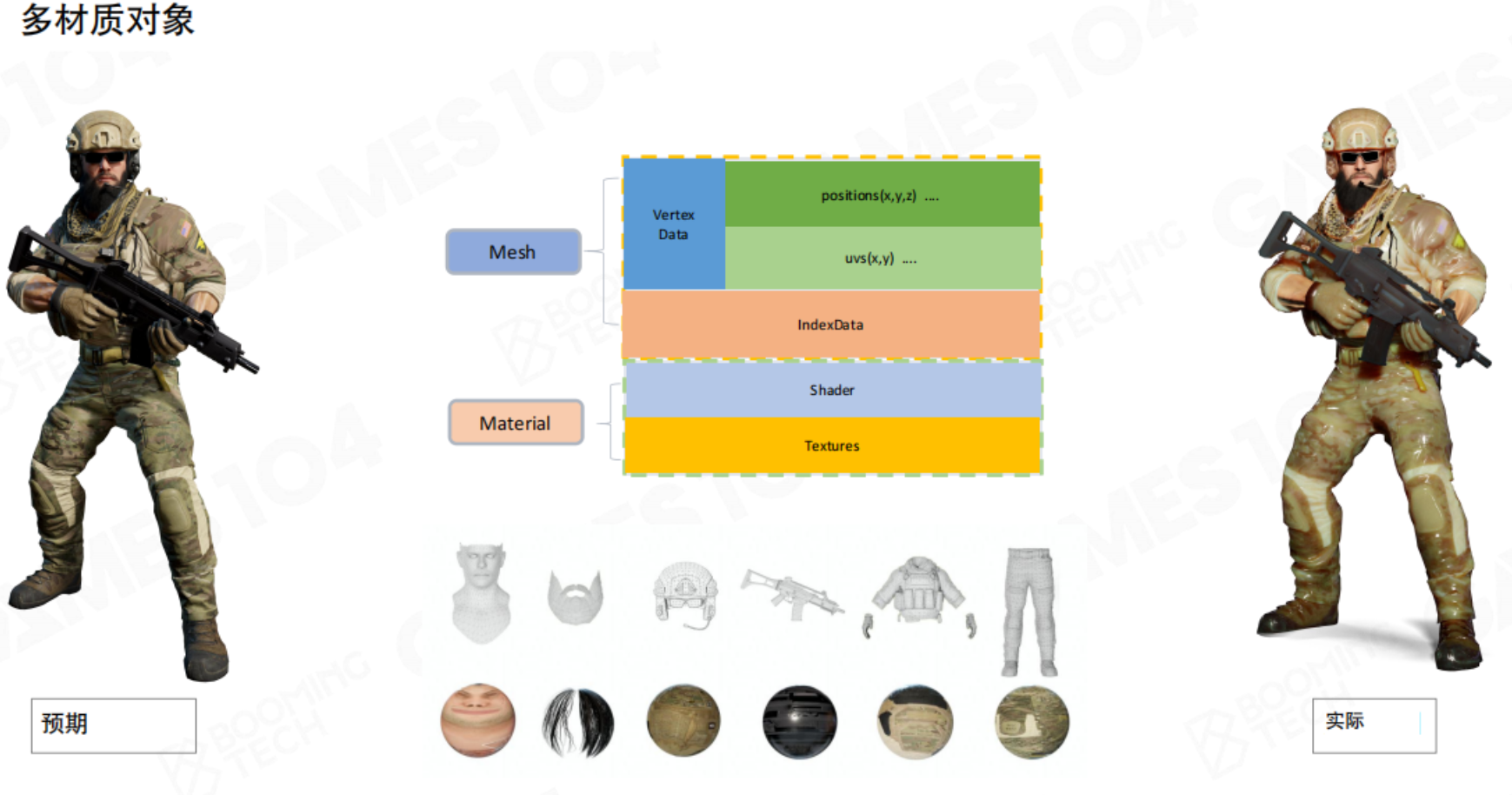
当一个模型需要多种材质时(例如,一个士兵的皮肤、衣服、武器材质不同),我们需要将单个网格划分为多个子网格(Submesh)。每个子网格是顶点/索引缓冲区的一个连续子集,对网格进行切分(通过offset、count确定index),并关联一个独立的材质。这样,一个复杂的模型可以通过多次Draw Call(每个Submesh一次)正确渲染出来。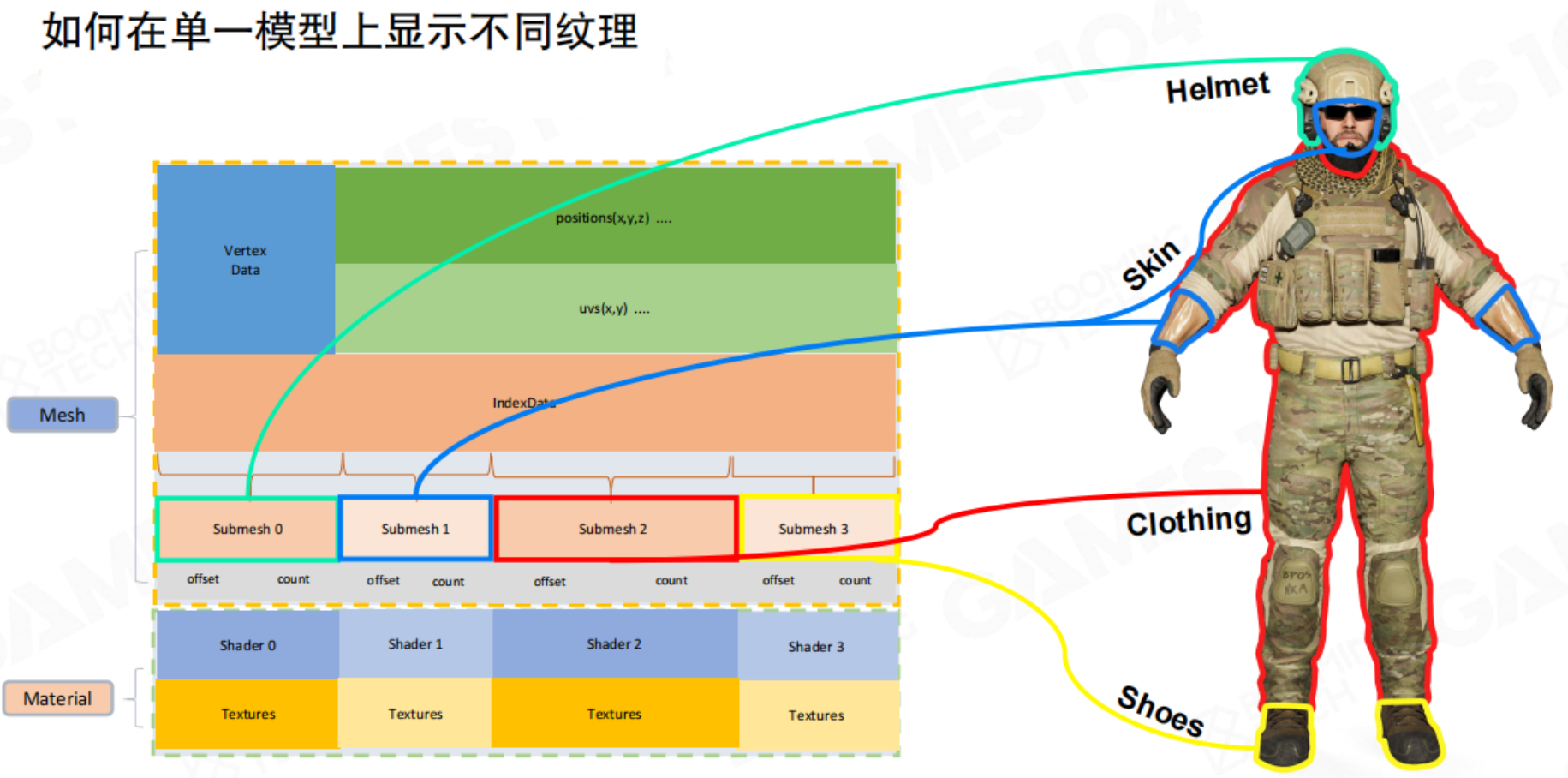
但如果我们需要绘制大量这样的复杂单位,如果每个单位都独立存储一份完整的渲染数据,这样的开销太过巨大。这些单位的材质、Mesh、纹理都有相同部分。
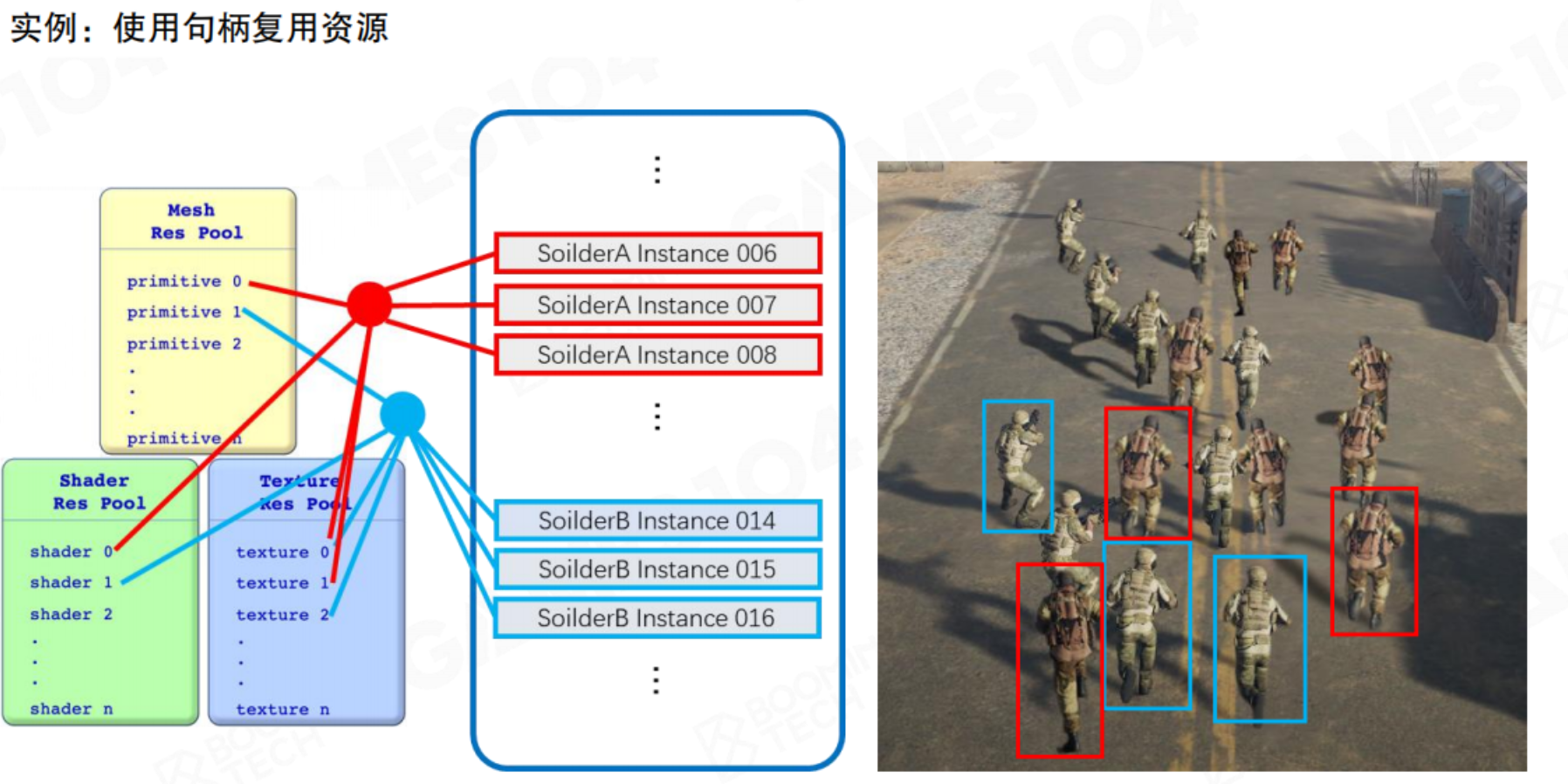
因此较好的数据组织方式是对渲染资源数据创建资源池。当我们在游戏中创建不同的士兵,可以看做资源在场景中的实例化。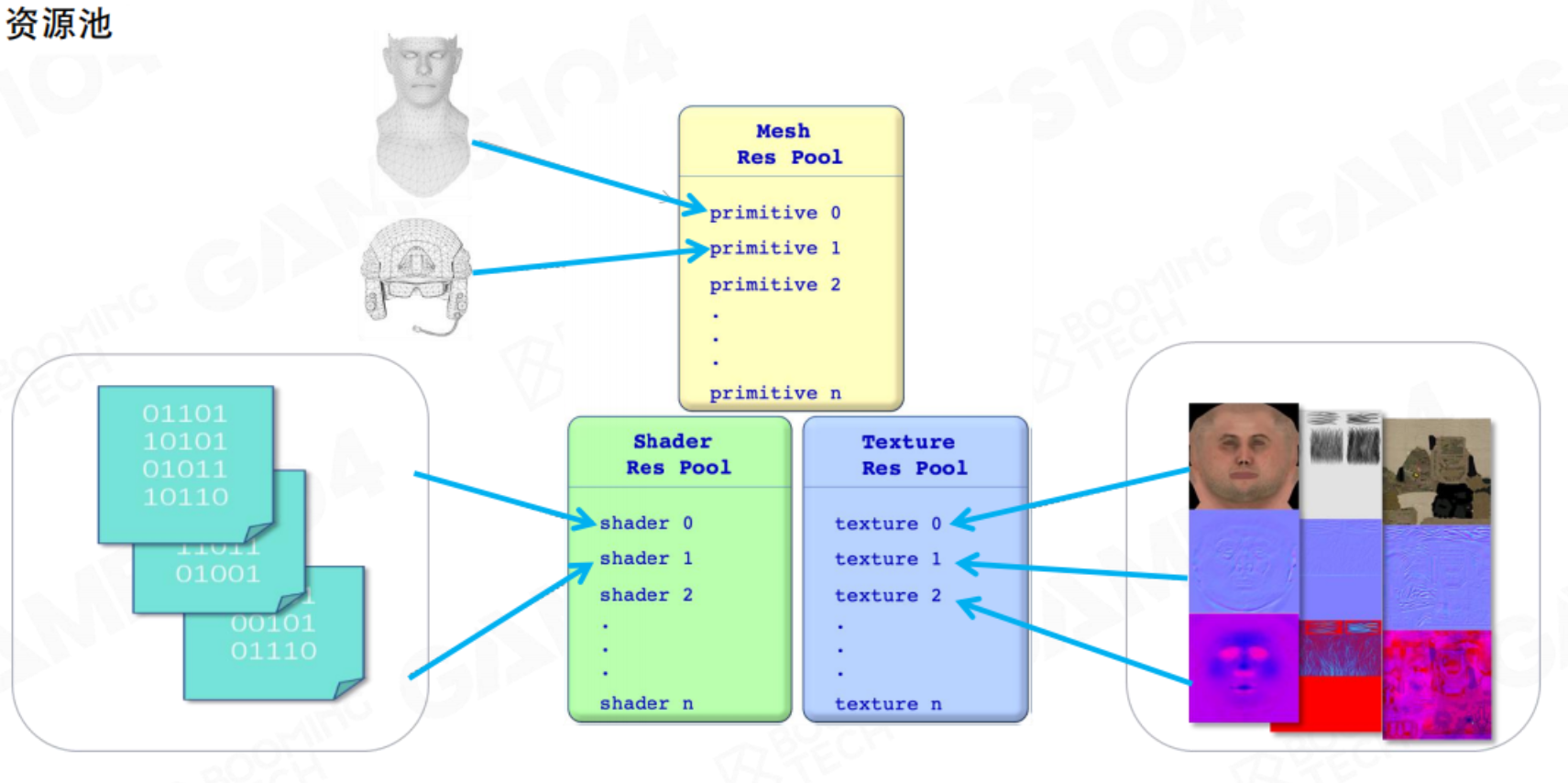
Instance
以上讲的主要都是对象定义,但是对象要在引擎中需要进行实例化。
例如,Unity中Prefab可以理解为一Game Object的定义。但是场景中多个相同物体其实是一个Game Object的实例。
也就是说,场景中的mesh、shader、texture都是存储在各自的资源池内,场景渲染时通过索引值去调用资源,这样可以实现场景中相同资源的复用,降低存储空间。是现代游戏引擎中的重要概念。
GPU渲染优化:按材质排序
在GPU的渲染管线中,频繁切换渲染状态(如材质参数、纹理、着色器程序)会引入显著的性能开销。这可以理解为,GPU在执行大规模并行计算时,其内部的计算单元(如Streaming Multiprocessors)更擅长持续处理一批状态相同的任务。每当CPU指令要求GPU更改当前状态(例如切换纹理或着色器),GPU可能需要进行一系列的上下文切换与数据同步,部分计算单元会进入等待状态,从而导致其强大的并行计算能力无法被充分利用,造成性能瓶颈。
为解决此问题,一项关键的优化策略是按材质排序。
其核心逻辑如下:在提交渲染命令(Draw Call)之前,先将场景中的所有待渲染对象(子网格,SubMesh)按照其使用的材质进行归并与排序。如下图所示,场景中所有使用相同材质的物体(如沙袋、油桶等,均以青绿色轮廓标出)被识别为一组。

优化后的渲染流程变为:
- 遍历排序后的材质列表。
- 对于每一种材质,仅需一次性地向GPU设置其全部相关状态(包括着色器、纹理、各种渲染参数等)。
- 在保持该材质状态不变的情况下,连续提交所有使用该材质的子网格的绘制指令。
通过这种方式,将原本可能散乱无序的状态切换(如绘制一个沙袋后切换为墙体材质,再切换回来绘制另一个沙袋)转变为批次化的高效处理。尽管需要绘制的三角形总数不变,但通过极大限度地减少GPU的状态切换次数,使得GPU能够更持续、高效地运行,从而显著提升整体渲染性能。
这一优化思想在现代图形API(如DirectX 12与Vulkan)中得到了更极致的体现。这些API明确将渲染状态抽象并预编译为不可变的对象(如Pipeline State Objects),强烈建议开发者将状态设置与绘制命令分离开来,并提前完成所有配置。这从设计层面印证了“按材质排序”这一优化策略的根本重要性:最大化GPU的并行计算效率,其关键之一在于保持其工作状态的稳定性与连续性。
GPU批处理渲染
在现代游戏渲染架构中,优化绘制调用(Draw Call)是提升性能的关键环节。基于此,GPU 批处理渲染(GPU Batch Rendering)成为一项核心技术。
其核心思想可概括为:将场景中所有使用相同子网格(SubMesh)和相同材质的物体实例进行分组,通过一次绘制调用,批量完成渲染。
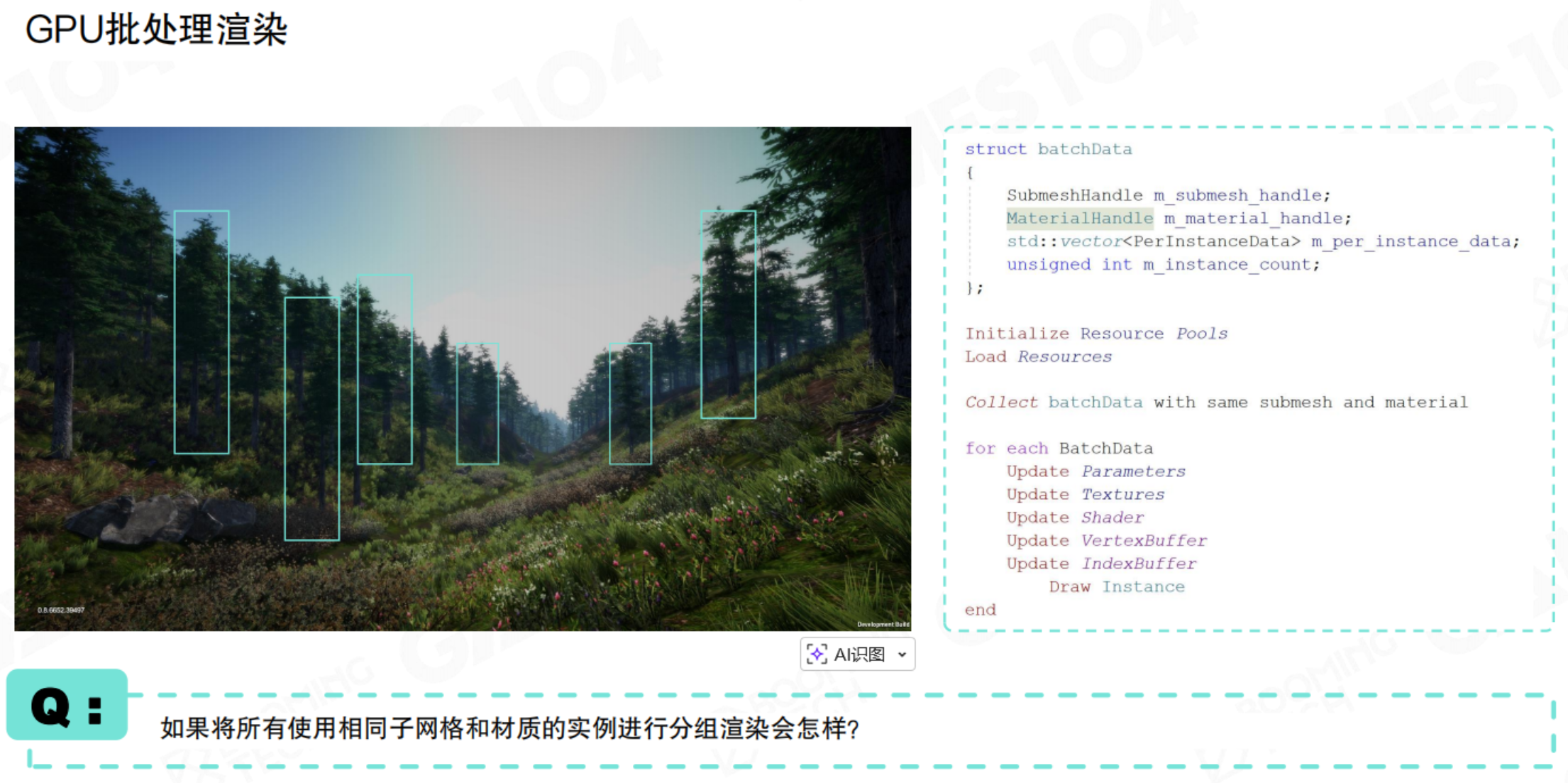
具体流程如图所示,通常包含以下步骤:
- 初始化资源池,准备模型与材质资源。
- 收集批处理数据,将符合条件(相同子网格与材质)的实例信息(如世界矩阵、颜色参数等)整理至特定缓冲区。
- 单次设置,批量渲染:仅需设置一次顶点/索引缓冲区(VB/IB)和材质状态,然后将所有实例的变换等数据(通常以一个数据数组的形式)传入着色器。
- GPU 通过一次绘制指令,即可实例化渲染成百上千个物体,极大减少了 CPU 与 GPU 之间的通信开销。
这种方法的优势在于,它将大量重复的、离散的绘制请求合并为少数几个批量请求,将运算负担从 CPU 转移至更擅长并行处理的 GPU,从而释放了 CPU 资源,显著提升了渲染效率。
这种技术特别适用于需要海量重复对象的场景,例如渲染大范围的植被(树木、草地)、建筑细节、战场中的士兵等。它使得在视野中高效绘制数公里内的成千上万个相似物体成为可能,是构建宏大开放世界的重要技术基石之一。
归根结底,理解物体如何被拆解为网格和材质这两个基本组件,是实施一切高级渲染优化的前提。GPU 批处理渲染正是建立在此基础之上的一项关键优化策略。
4.5 可见性剔除
了解完如何绘制场景对象后,带来了一个新的问题:我们要绘制哪些物体?最暴力的方法是所有对象都绘制一遍,但显然在大世界的游戏中是不行的。我们显然不需要渲染摄像机看不到的物体,这就是可见性剔除。可见性剔除的核心思想就是在提交给GPU前,快速判断并丢弃不可见物体。

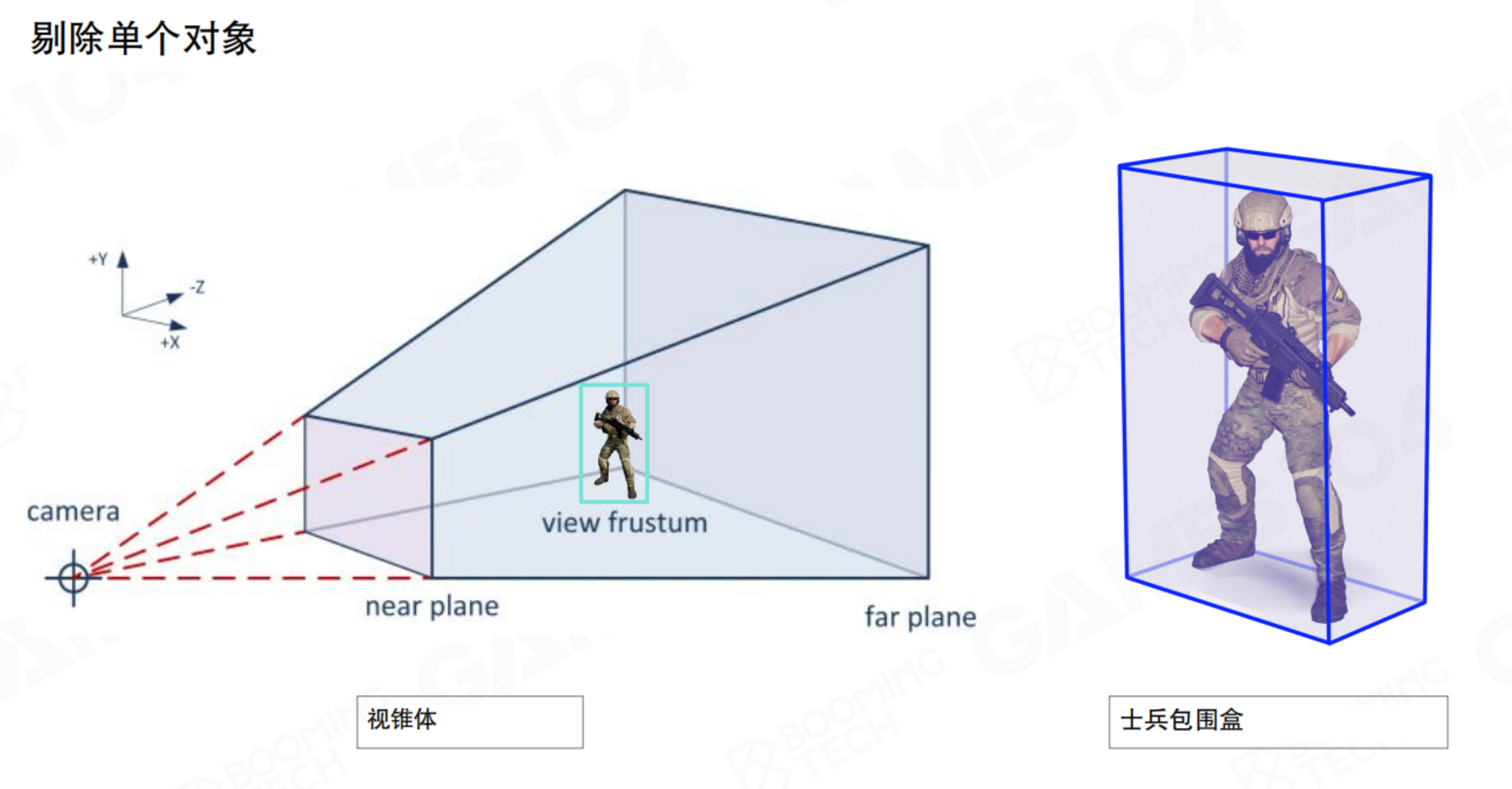
视锥体剔除和包围盒
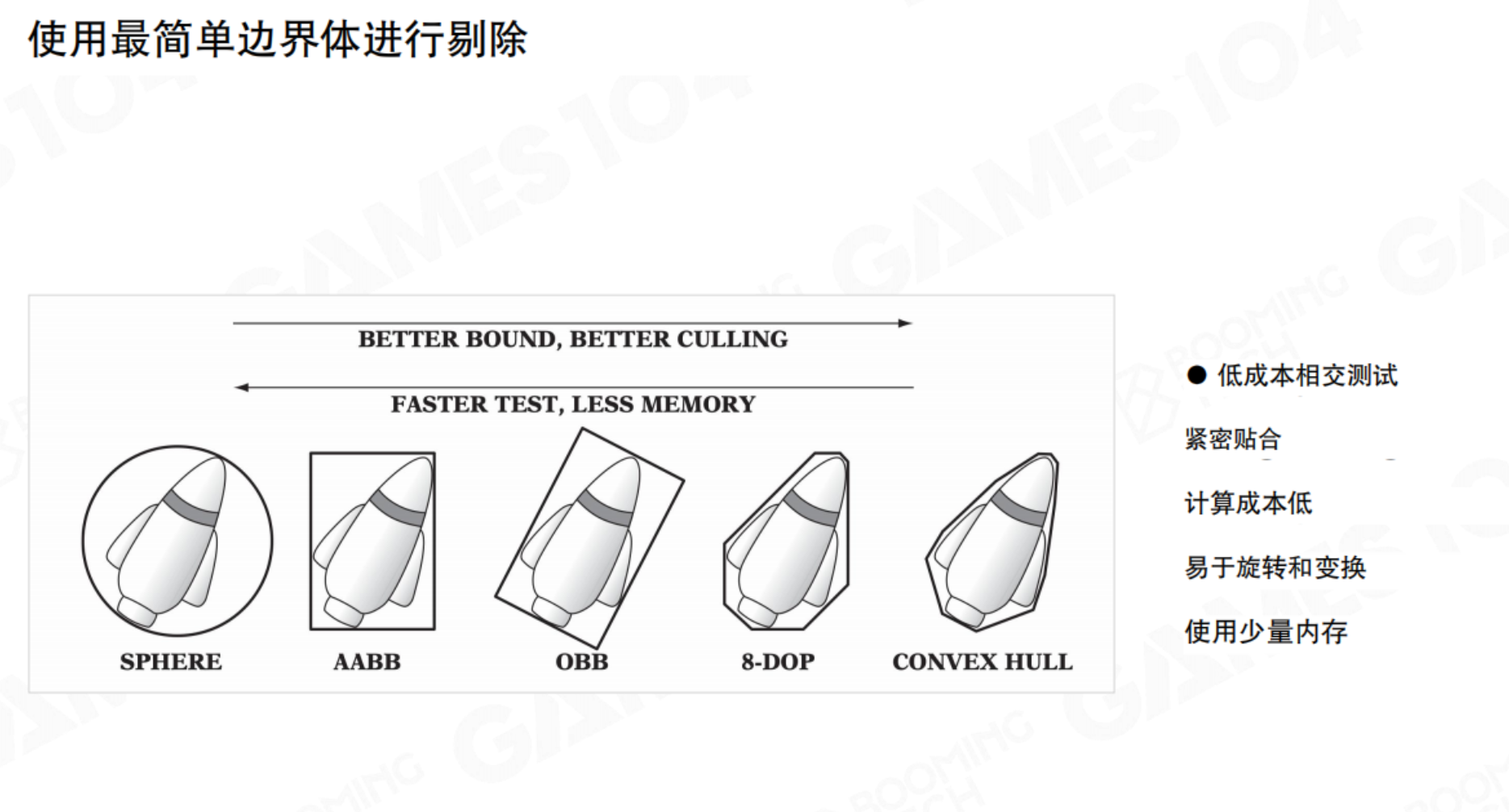
最基本的剔除是视锥体剔除(Frustum Culling)。判断物体的边界体是否与摄像机的视锥体(一个平头截锥体)相交。如果完全在视锥体之外,则整个物体都被剔除。但单位的形状千奇百怪,如何能够将这些Mesh与可视范围进行检测呢?这就需要对物体范围进行简化:包围盒(Bound),规则物体的相交是相对便于计算的。
包围盒的有很多类型:Sphere、AABB、OBB等。
场景图与空间分割加速结构
当场景中有数万个物体时,对每个物体逐一进行视锥体剔除仍然开销很大。我们需要用空间数据结构来组织物体,避免线性遍历。

BVH(包围体层次结构):一种二叉树结构,每个节点存储一个包围体,包围其所有子节点包含的物体。从根节点开始遍历,如果某个节点的包围体不可见,其下所有子节点都可以快速剔除。BVH特别适合动态场景,因为物体移动时,可以增量式地更新树结构,而无需完全重建。(不仅要考虑剔除成本,还要考虑重构二叉树成本)
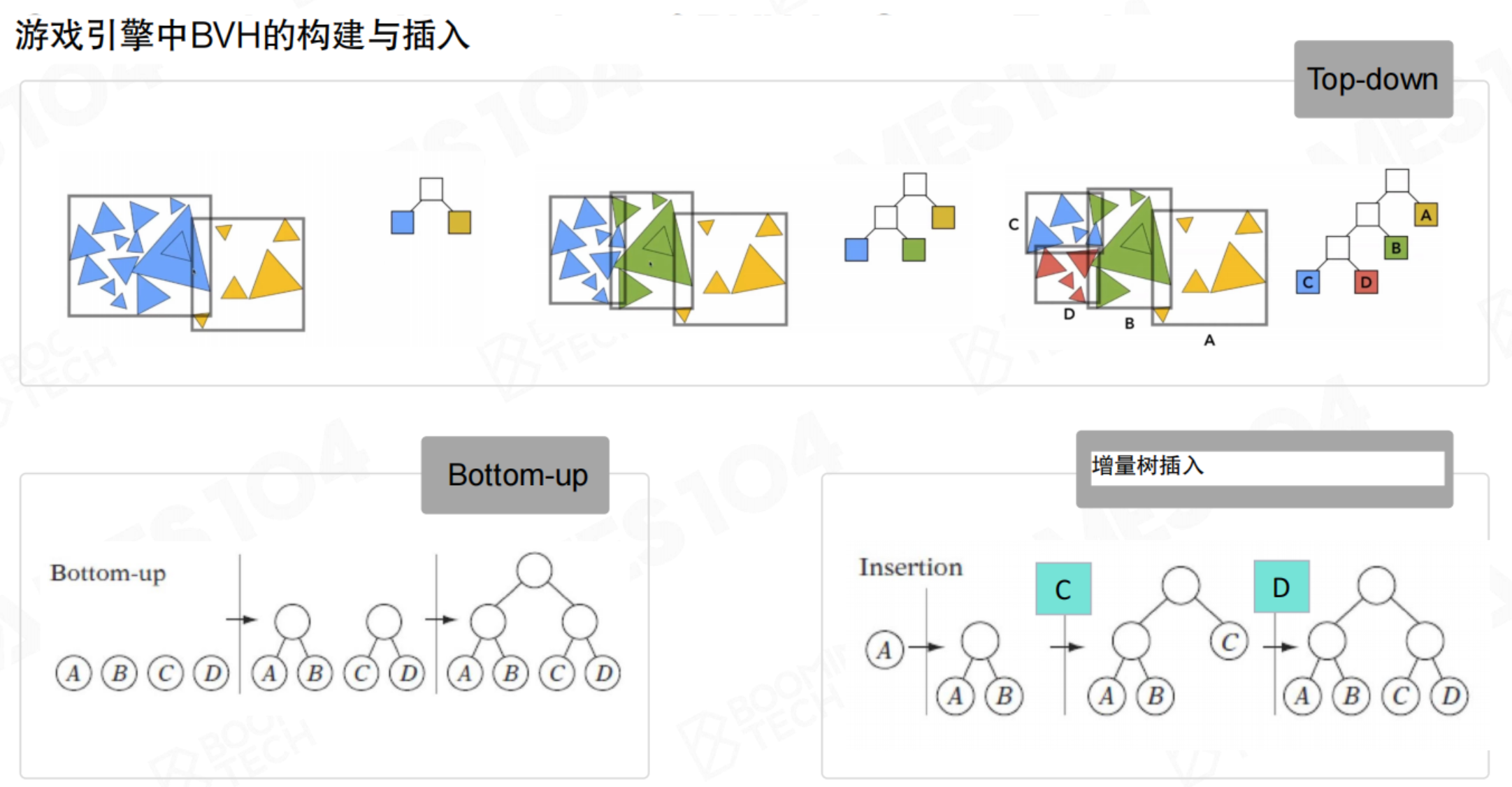
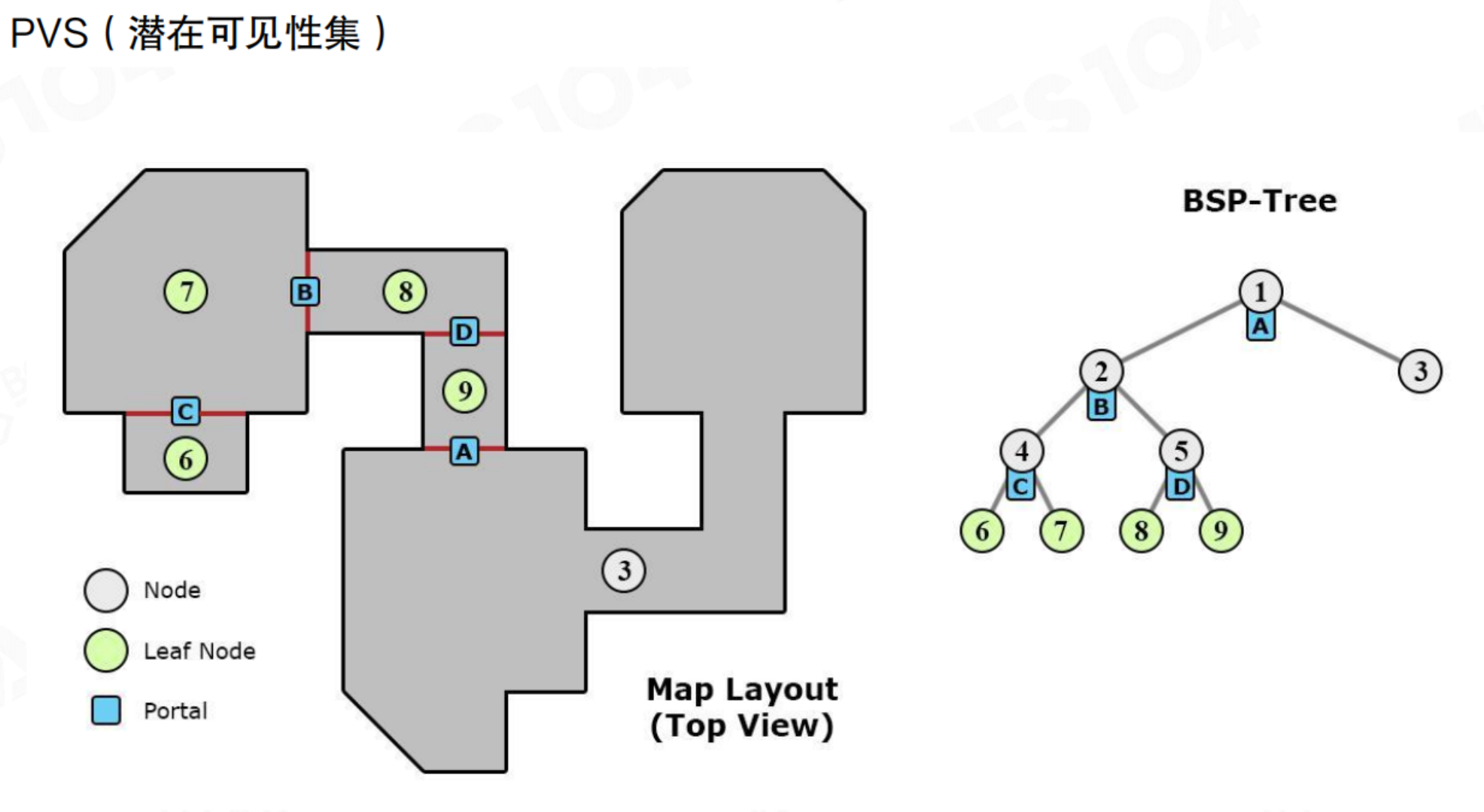
PVS(潜在可见集):常用于室内场景。将场景划分为多个区域(如房间),并预计算每个区域能直接看到哪些其他区域(通过门、窗等Portal)。运行时,根据玩家所在区域,直接加载并渲染其PVS内的区域,极大提升了效率。比如黑神话,过了一个门,可能就才去加载门后面的boss。


高级剔除技术:GPU 剔除与早期 Z 测试
随着GPU计算能力增强,更多剔除工作可以转移到GPU上并行执行。
- GPU 剔除:使用Compute Shader等技术,在GPU上并行计算大量物体的可见性,生成最终需要渲染的物体列表,大大减轻CPU负担。
- 早期 Z 测试(Early-Z):在像素着色器执行之前,先利用深度缓冲区(Z-Buffer)进行深度测试。如果一个片段注定会被前面的物体遮挡,就直接丢弃,避免执行昂贵的光照和材质计算。现代GPU硬件对此有良好支持。
GPU剔除与Early-Z深度测试
随着GPU计算能力的飞速发展,现代游戏引擎的渲染优化已从依赖精巧的CPU算法,转向充分利用GPU的硬件
并行特性。其核心目标极为明确:避免任何不必要的计算。这包含两个层面:一是避免绘制整个不可见的物体(GPU Culling),二是在像素级别避免绘制被遮挡的片段(Early-Z测试)。
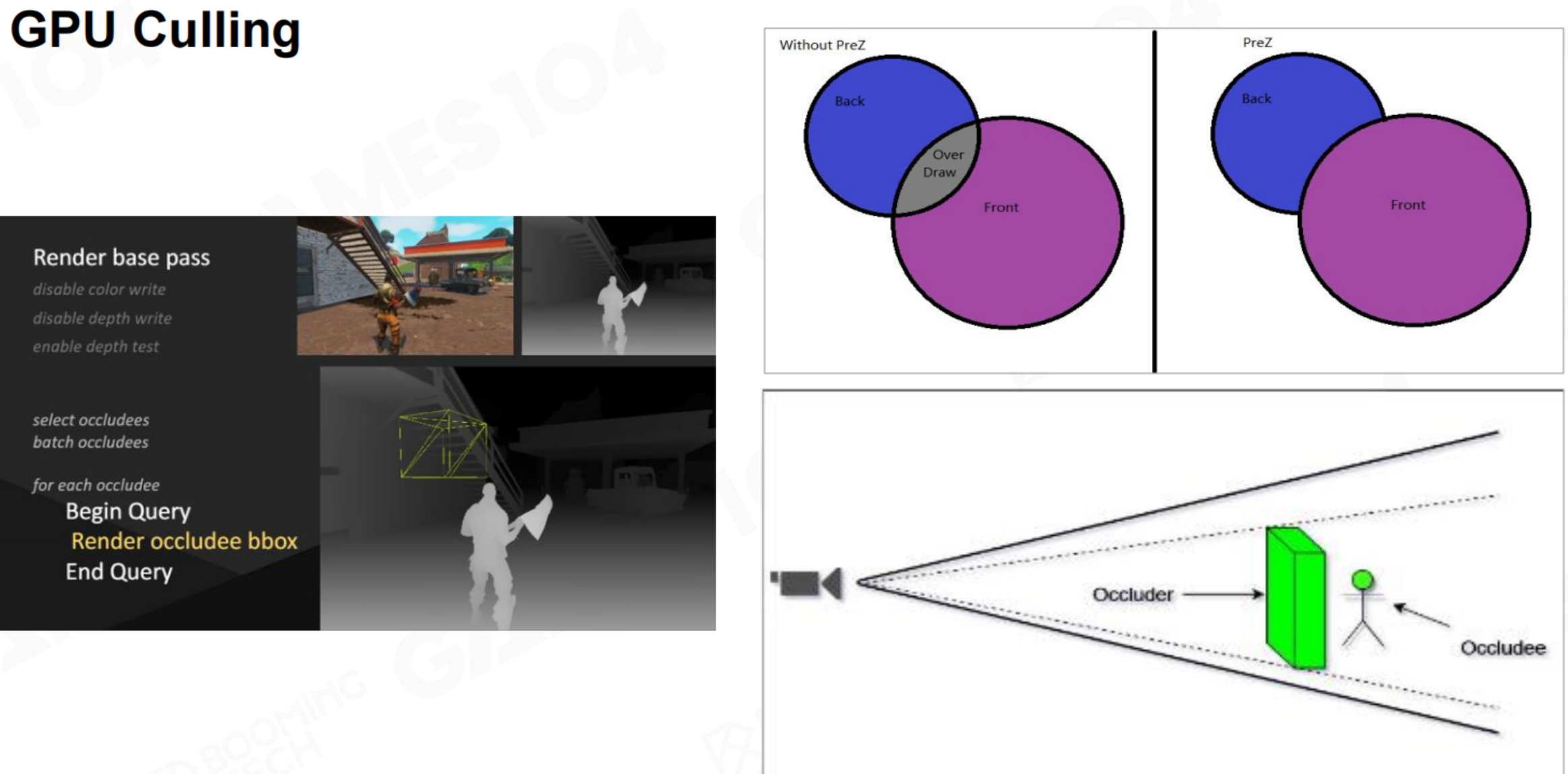
上图清晰地展示了两种协同工作的优化策略:GPU Culling(物体剔除) 和 Early-Z(早期深度测试),其核心哲学是“不绘制任何看不见的东西”。
核心思想:两级过滤,极致优化,渲染效率的提升源于两个层面的筛选:
- 物体层面:直接剔除整个不可见的物体。
- 像素层面:跳过绘制被遮挡的像素。
您提供的图片完美地阐释了这一协同优化流程,下图直观地展示了其核心工作路径:
flowchart TD
A[场景所有物体] --> B{GPU Culling}
subgraph B [物体级过滤:GPU Culling]
B1[预渲染深度图
(Pre-Z Pass)] --> B2[并行查询可见性
(Occlusion Query)]
end
B -- 可见物体 --> C[绘制管线]
B -- 不可见物体 --> D[被完全剔除]
C --> E{像素级过滤:Early-Z测试}
E -- 像素被遮挡 --> F[跳过像素着色器]
E -- 像素可见 --> G[执行着色计算
更新画面]
正如流程图所总结,现代高性能渲染依赖于这“两级过滤网”:
- GPU Culling 作为第一道粗筛,在物体层面大幅减少工作量。
- Early-Z 作为第二道精筛,在像素层面避免无效计算。
4.6 纹理压缩
纹理是构成渲染对象视觉细节的基础。虽然日常生活中我们熟悉的JPEG、PNG等图像格式具有出色的压缩率和通用性,但它们的设计目标与游戏引擎的实时渲染需求存在根本差异。
游戏引擎无法直接使用这些通用压缩格式,主要源于两个核心瓶颈:
- 缺乏快速随机访问能力:渲染时,GPU需要根据像素的纹理坐标瞬间获取任意位置的颜色值。JPEG等基于频域的压缩算法,必须解码一大块区域才能获取一个像素点的数据,无法满足这种“随机访问”的低延迟要求。
- 解压计算复杂度高:实时渲染每帧必须在毫秒级内完成,复杂的解压算法会消耗宝贵的CPU/GPU资源,严重影响帧率。

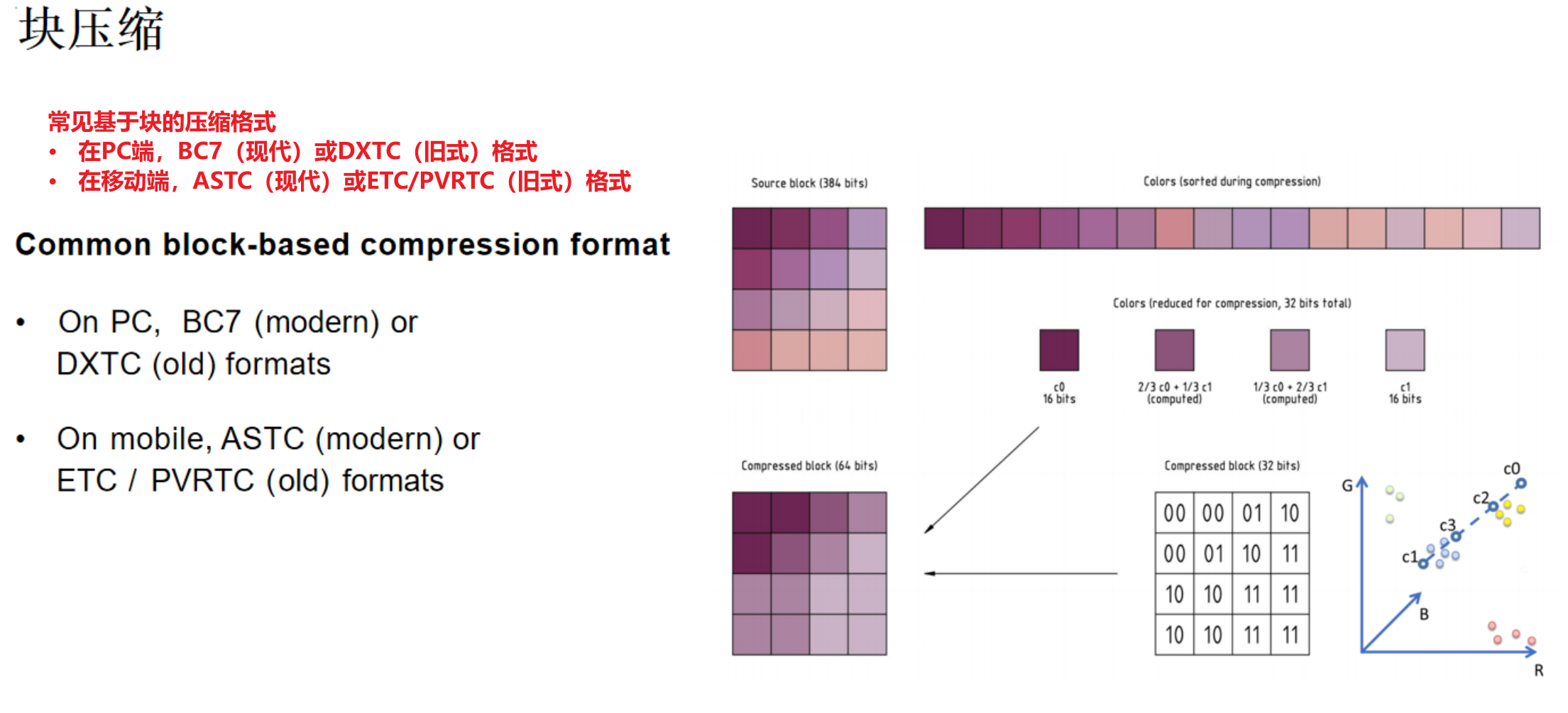
因此,游戏引擎普遍采用专为实时渲染设计的块压缩格式。其核心思想是将纹理划分为固定大小的像素块(如4x4),并对每个块进行独立压缩。以经典的DXTC(BC系列)格式为例:
- 压缩时,算法会找到块内两个最具代表性的颜色(最亮与最暗)。
- 其余像素的颜色则通过在这两个颜色之间进行插值来表示,并仅存储极少的索引位。
这种方式牺牲了一定的压缩率和图像质量,但换来了两大关键优势:
- 极速解码:GPU硬件可直接、并行地解压每个小块,速度极快。
- 精准定位:通过简单的数学计算即可定位到任意像素所在的压缩块,并瞬间解压,完美支持随机访问。
4.7 建模工具
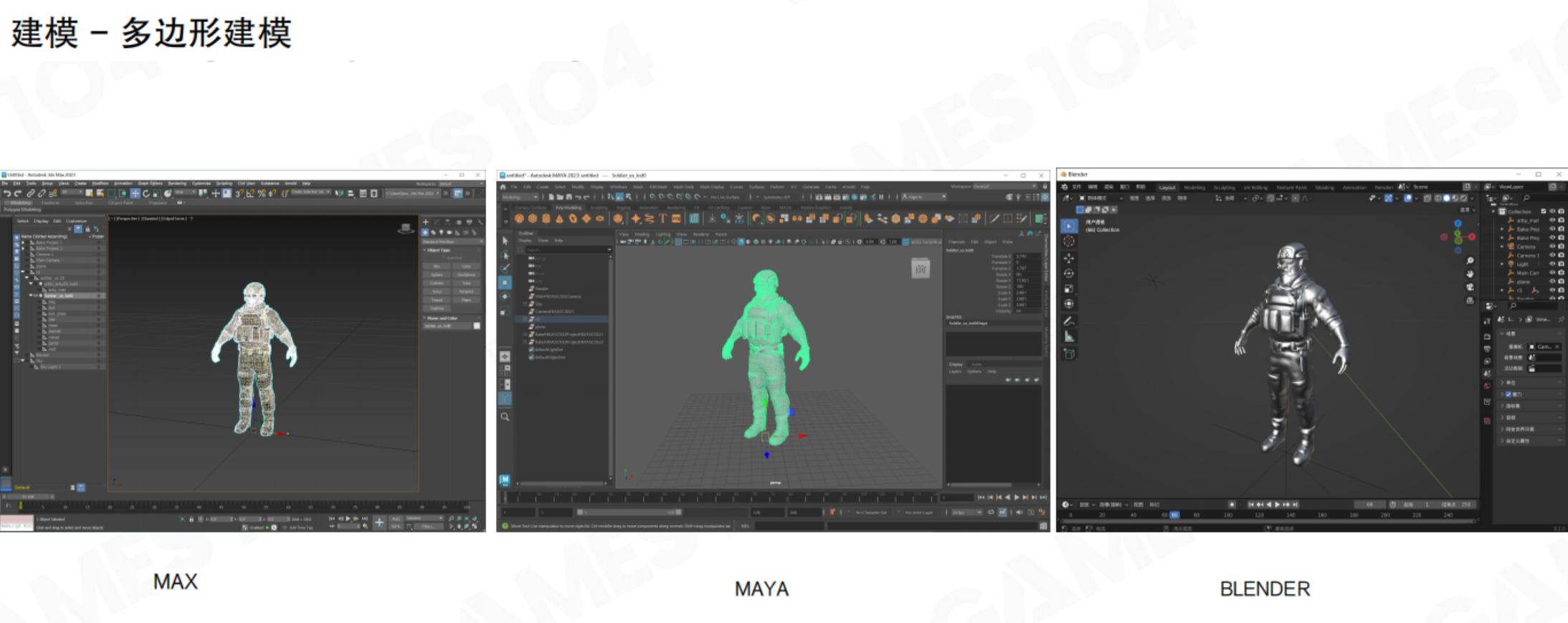
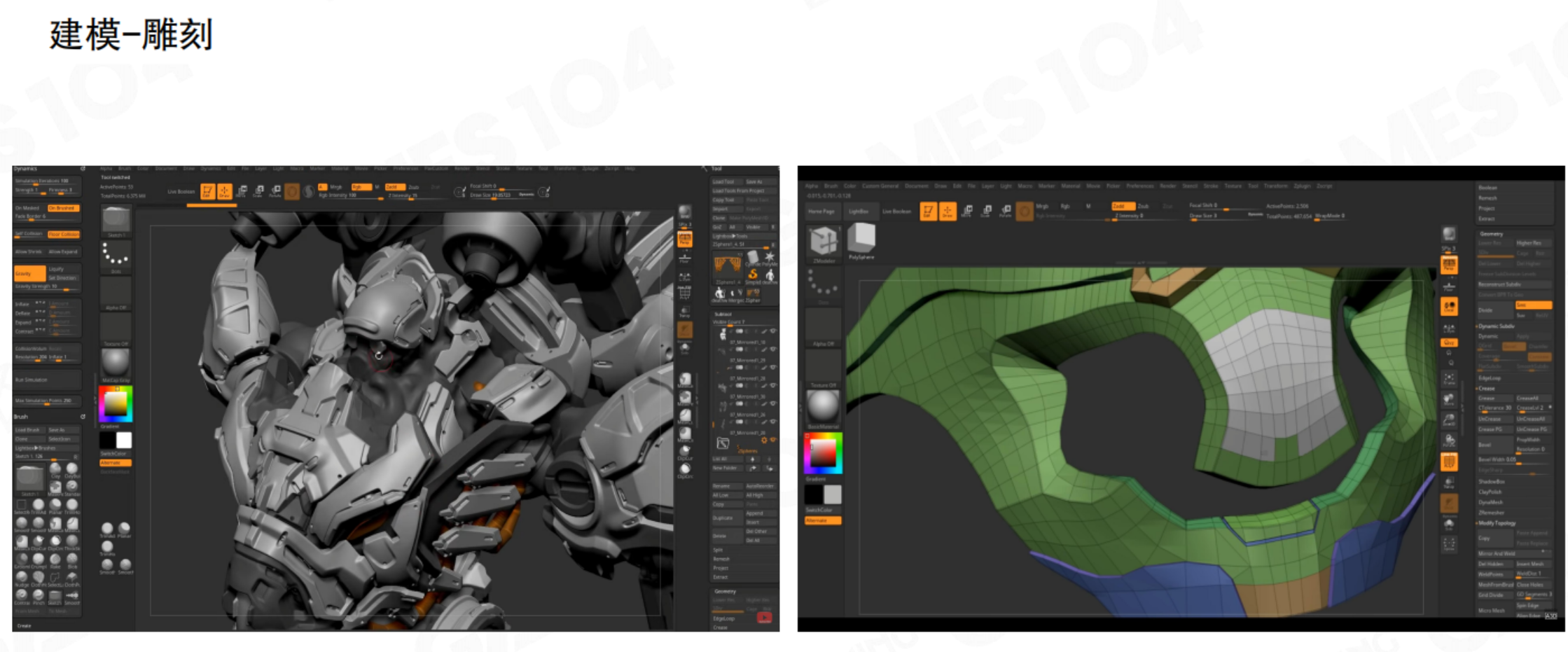

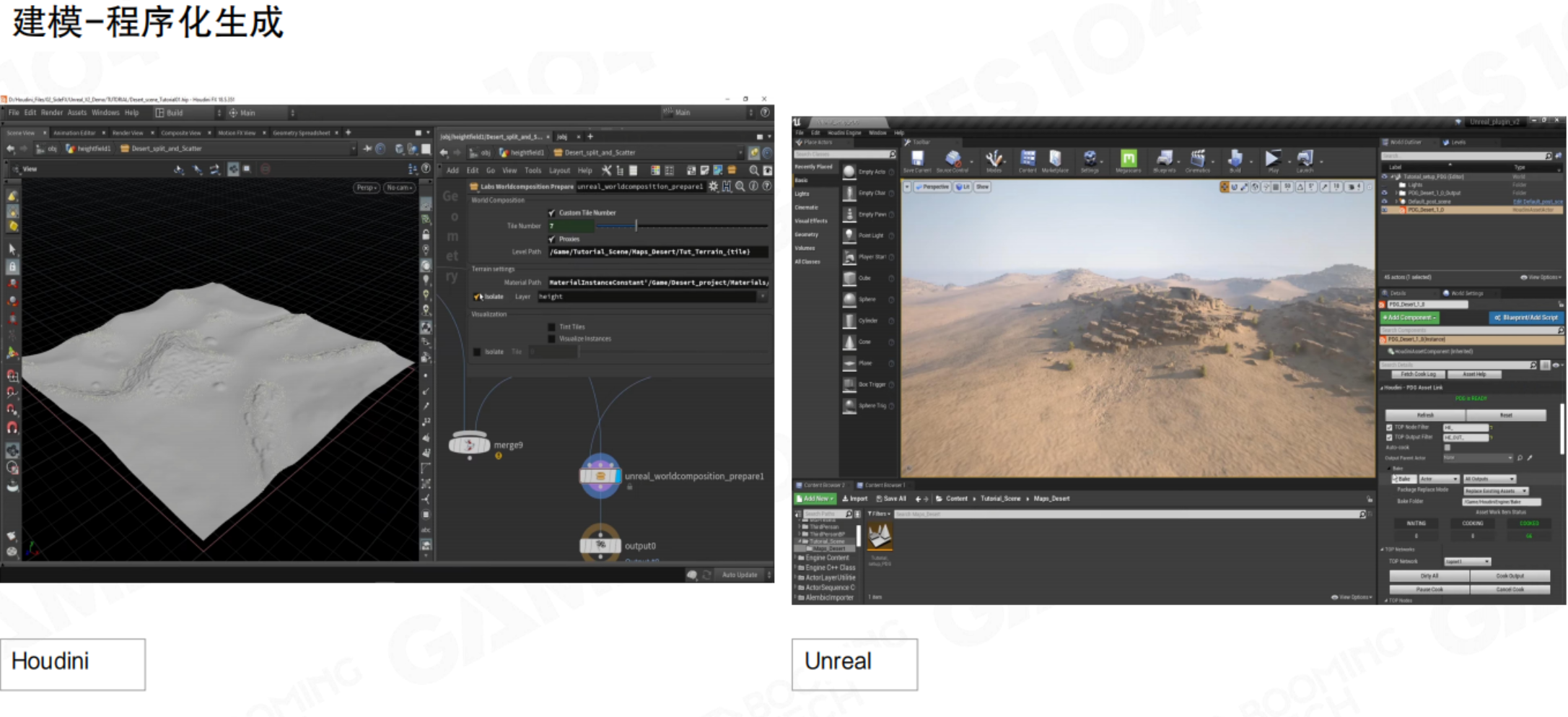

| 对比项 | 多边形建模 | 数字雕刻 | 扫描建模 | 程序化建模 |
|---|---|---|---|---|
| 优势 | 灵活 | 富有创意 | 逼真 | 智能 |
| 劣势 | 工作量大 | 数据量大 | 数据量大 | 实现困难 |
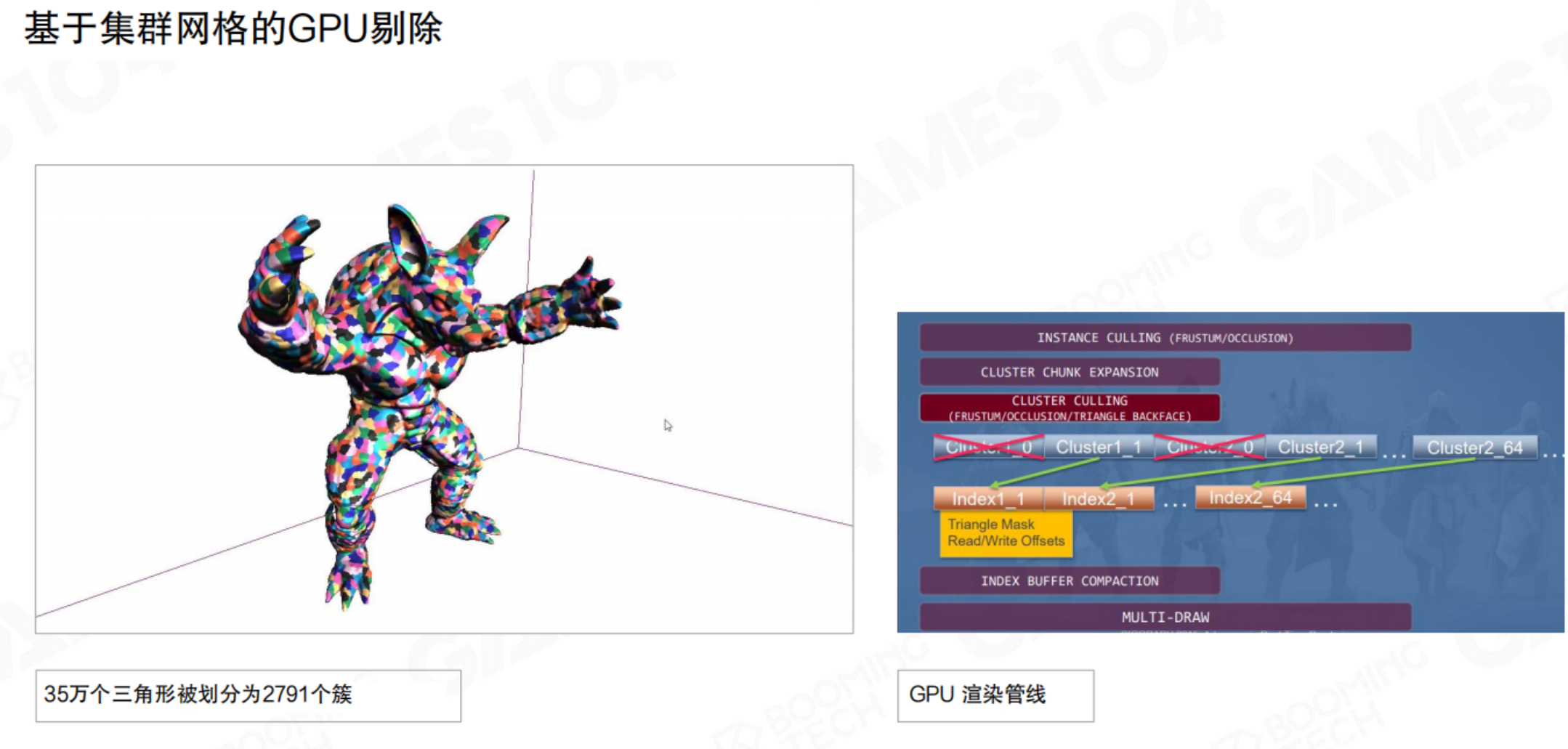
4.8 现代渲染管线:Cluster-Based Mesh Pipeline
传统管线的瓶颈
传统渲染管线中,CPU需要准备每个对象的渲染数据并提交Draw Call。当场景中物体数量极多(如开放世界)、单个模型面数极高(数百万三角形)时,CPU会成为瓶颈。同时,大量细碎的Draw Call也限制了GPU的发挥。想要在游戏中实现影视级效果,那就得上点新技术了。

基于集群的网格管线原理
基于集群的网格管线原理这近年来3A游戏引擎(如Unreal 5的Nanite)采用的核心技术,旨在实现“电影级”几何细节的实时渲染。
其核心思想是GPU驱动渲染(GPU-Driven Rendering)。该管线的根本思路,是将传统意义上作为一个整体处理的复杂模型,打散为大量规模固定、结构统一的小型几何单元,称为“集群”。
该思想早在2015年左右由育碧在《刺客信条:大革命》等作品中率先实践,用于处理城市中极其密集的建筑与装饰细节。随着硬件支持日益成熟,目前已有越来越多引擎转向这一新型管线架构。
- 集群(Cluster):将模型的三角形网格预先分割成许多小的、固定三角形数量(如64或128个三角形)的集群(Cluster)。
- GPU端剔除与LOD:在GPU上(通过Compute Shader或Mesh Shader)并行地对成千上万个Cluster进行视锥剔除和细节层次(LOD)选择。离相机近的Cluster使用高精度渲染,远的则被剔除或使用低精度。
- 减少CPU干预:CPU只需提交整个模型或场景的粗略表示,具体的渲染决策(画什么,画多细)完全由GPU并行计算决定,彻底解放了CPU。

现代可编程网格管线(Programmable Mesh Pipeline)
核心转变:从“固定流水线”到“GPU自主计算”
传统管线(左侧流程)是顺序固定的“流水线”,数据需逐步经过顶点着色器、曲面细分、几何着色器等预定阶段。
而现代网格管线(右侧流程)代表了根本性变革:它将几何的生成与处理重构为高度并行的GPU计算任务。其核心是两个新阶段:
- 任务着色器(Task Shader):作为调度器,动态决定需要处理的工作量。
- 网格着色器(Mesh Shader):作为核心执行单元,直接并行生成所需的几何图元(如三角形)。
核心优势:此架构将几何处理从固定流程中解放出来,使GPU能够基于计算线程(Thread Group)更灵活、高效地生成和处理几何数据,尤其适合处理极其复杂的场景。这是实现集群化网格(Cluster-Based Mesh)渲染的硬件基础。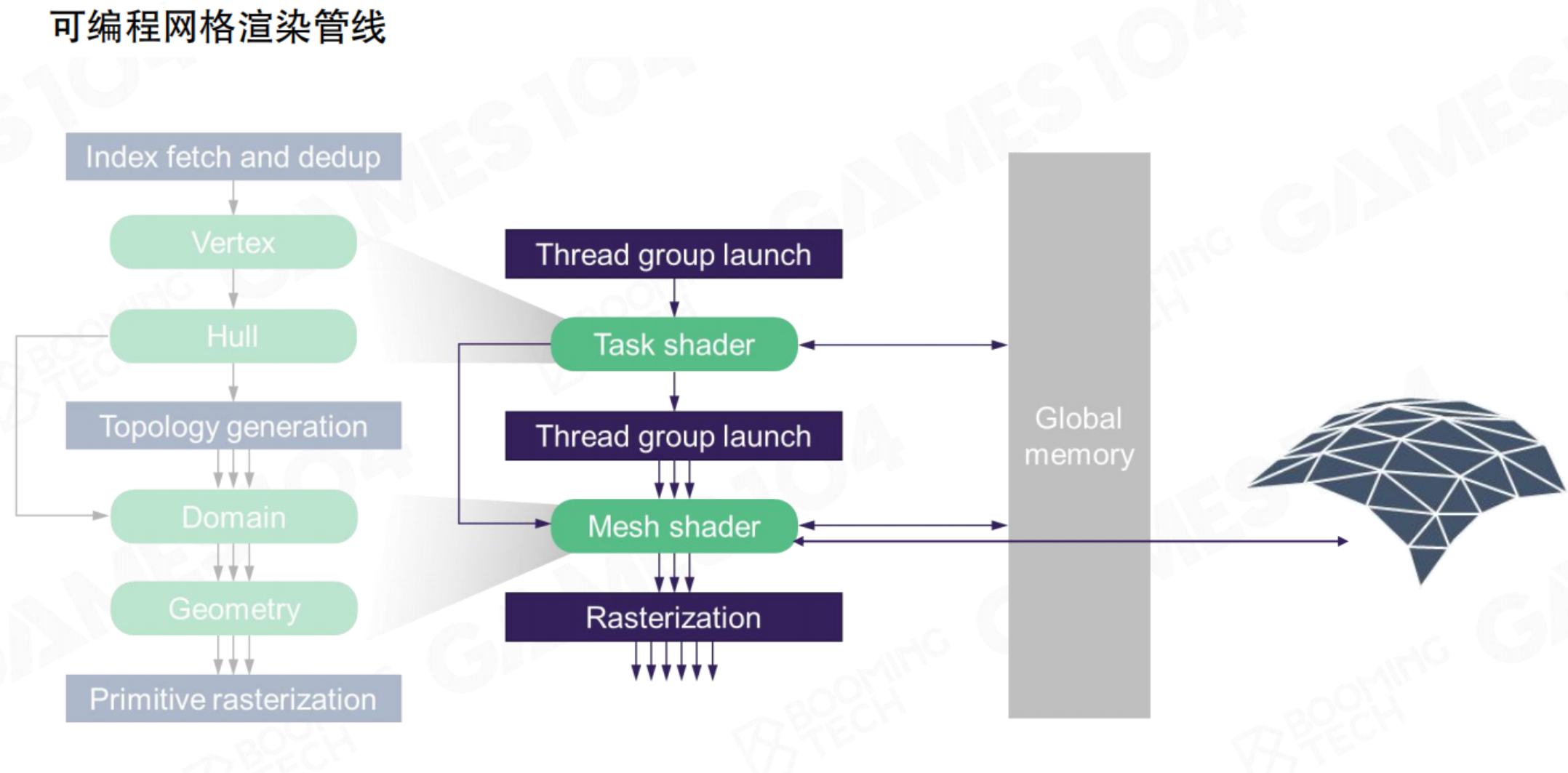

Nanite
Unreal Engine 5的Nanite是此思想的集大成者。它不仅仅是软件算法,还结合了预先计算好的多层次细节的Cluster数据(包含BVH),使得引擎能够无缝流式加载和渲染拥有海量几何细节的场景,而无需手动创建LOD模型。

管线优化总结
从传统管线到Cluster-Based管线的演进,体现了游戏渲染的一个核心趋势:将计算负载从CPU尽可能地向并行效率极高的GPU转移,从而突破性能瓶颈,实现高质量的画面效果。
4.9 核心要点总结

- 游戏引擎的设计与硬件架构设计密切相关要点
- 采用子网格设计以支持多材质模型要点,核心问题是如何组织Mesh、Material、Texture渲染数据
- 使用剔除算法尽可能减少渲染对象数量要点
- 随着GPU性能提升,越来越多的计算任务转移至GPU处理,这被称为GPU驱动架构
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

