7.游戏中渲染管线和后处理及其他
7.1 环境光遮蔽
环境光遮蔽(Ambient Occlusion, AO)是现代游戏必备的渲染技术,通过AO可以获得更加丰富的光影变化以及更加立体的视觉感受。从渲染方程的角度来看,AO的本质是计算网格上每个点在光照下的可见性。



环境光遮蔽能够模拟物体自身局部对光线的遮挡,如人物眼角对皮肤、鼻子对面部的遮挡阴影。虽然这种阴影理论上符合光照方程,但由于其局部遮挡的特性,在统一的光照模型处理中很难得到较好的效果。
环境光遮蔽原理
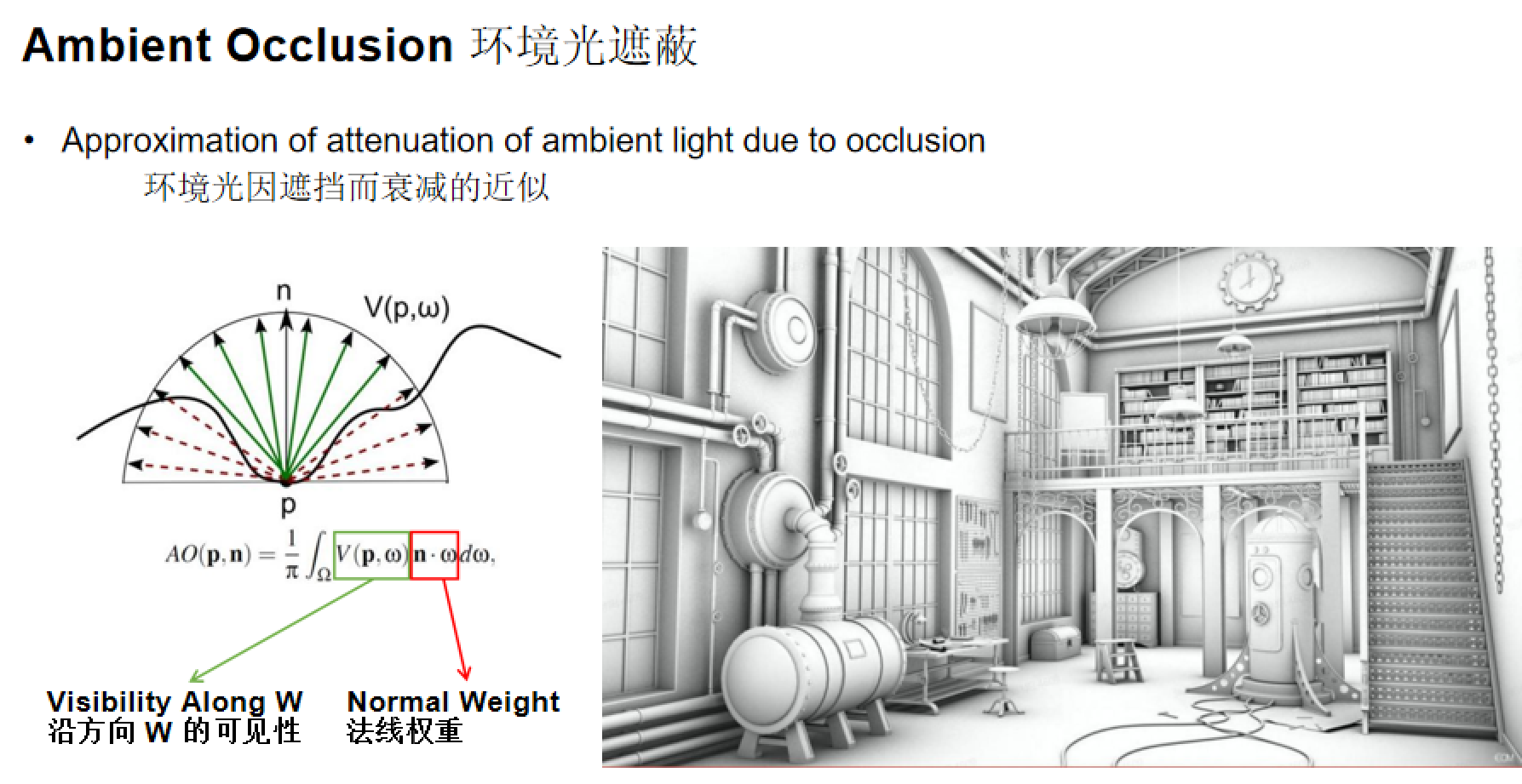
环境光遮蔽方程:AO(p,n) = (1/π) ∫_Ω V(p,ω) n·ω dω
其中:
V(p,ω):沿方向ω的可见性函数- n·ω:法线权重,表示法线方向与采样方向的点积
- Ω:法线方向的半球面
环境光遮蔽方程实际上是在法线方向的半球面上进行的,通过积分计算每个点周围被遮挡的程度。
预计算环境光遮蔽(Precomputed AO)

核心思想:使用光线追踪离线计算环境光遮蔽,并将结果存储到纹理中,广泛用于物体建模过程。
特点:
- 优点:无需几何上的遮蔽关系,即使没有AO真正对应的网格结构也能有较好的AO效果
- 缺点:需要额外的纹理存储信息,仅适用于静态物体
预计算AO将顶点的可见性事先烘焙到网格信息中,实际渲染时直接调用,这是现在很多商业项目使用的方法。
屏幕空间环境光遮蔽(SSAO/SSAO+)

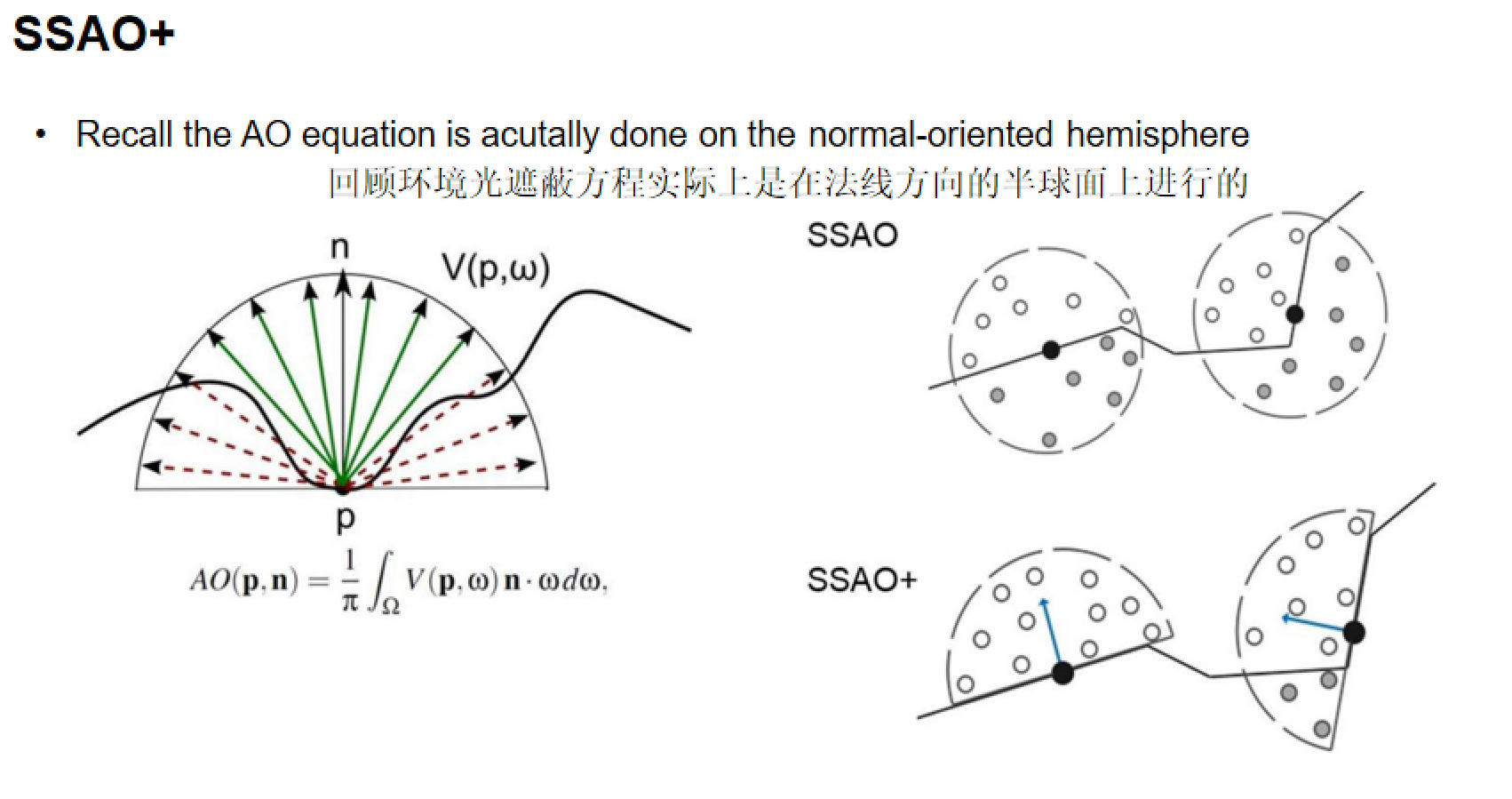
SSAO核心思想:对屏幕像素进行局部空间采样,计算点可显示的概率,作为最终颜色的比例系数。
实现方法:
- 从相机出发渲染出一张深度图
- 对于深度图上的每个像素,在屏幕空间找到该点对应的模型位置
- 在其周围采样N个点,利用采样点和深度图估计该点处的遮挡关系
SSAO+优化:SSAO采样时使用球体区域采样,但实际看到平面时,可视区域只有半球。SSAO+沿法线方向在视图空间生成半球面,多次区域采样,判断是否被遮蔽,计算颜色衰减比例。
公式:A(p) = 1 - Occlusion / N,其中Occlusion为被遮挡的采样点数,N为总采样点数。


优点:相比预计算AO,能够动态处理AO效果
缺点:
- 实时计算量较大
- 需要有真实的遮蔽结构
- 只考虑屏幕空间上的几何,在某些情况下会导致错误的结果(如距离摄像机很远时,采样区域过大,可能不是局部遮挡关系)
基于地平线的环境光遮蔽(HBAO)
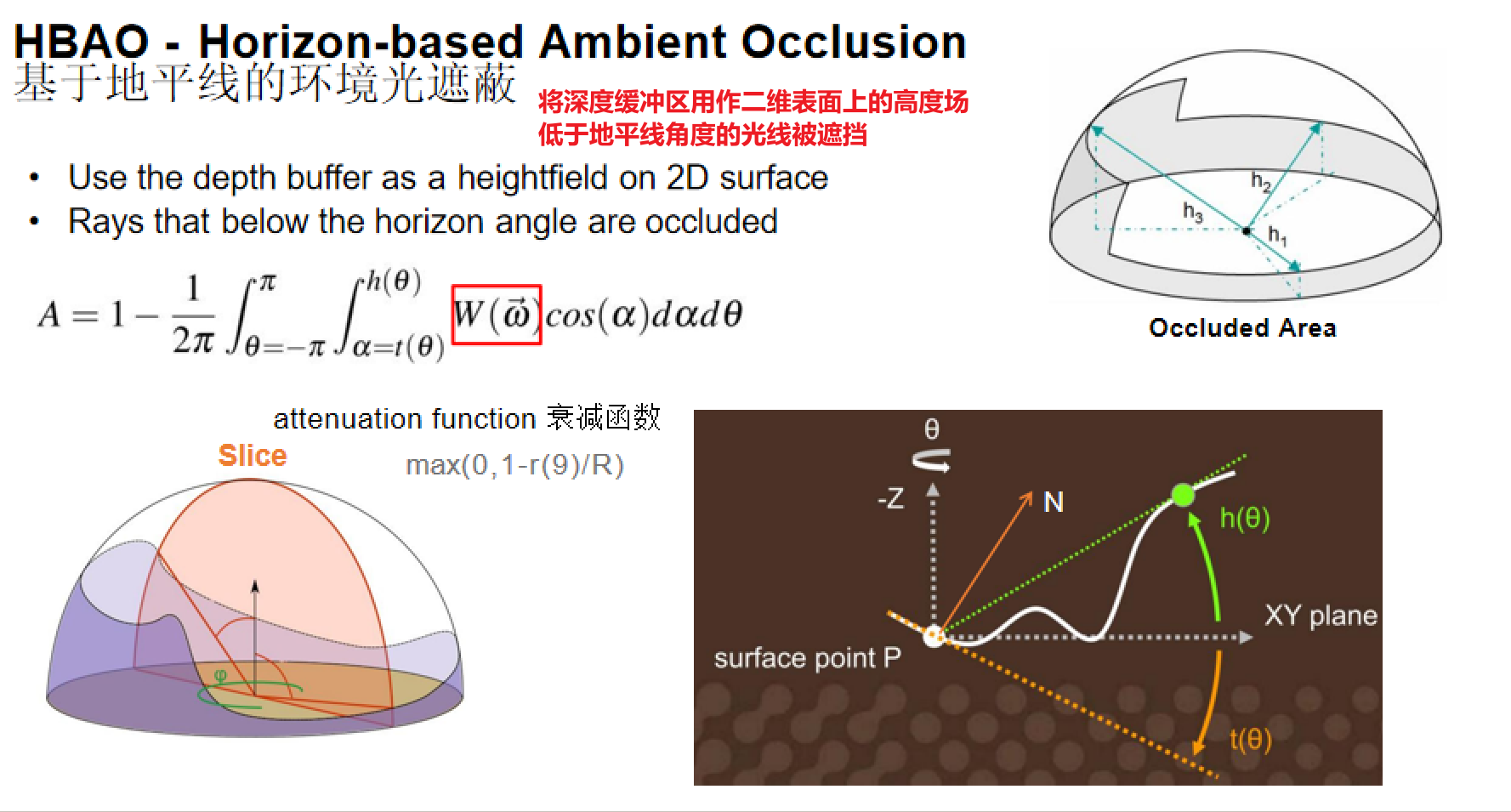
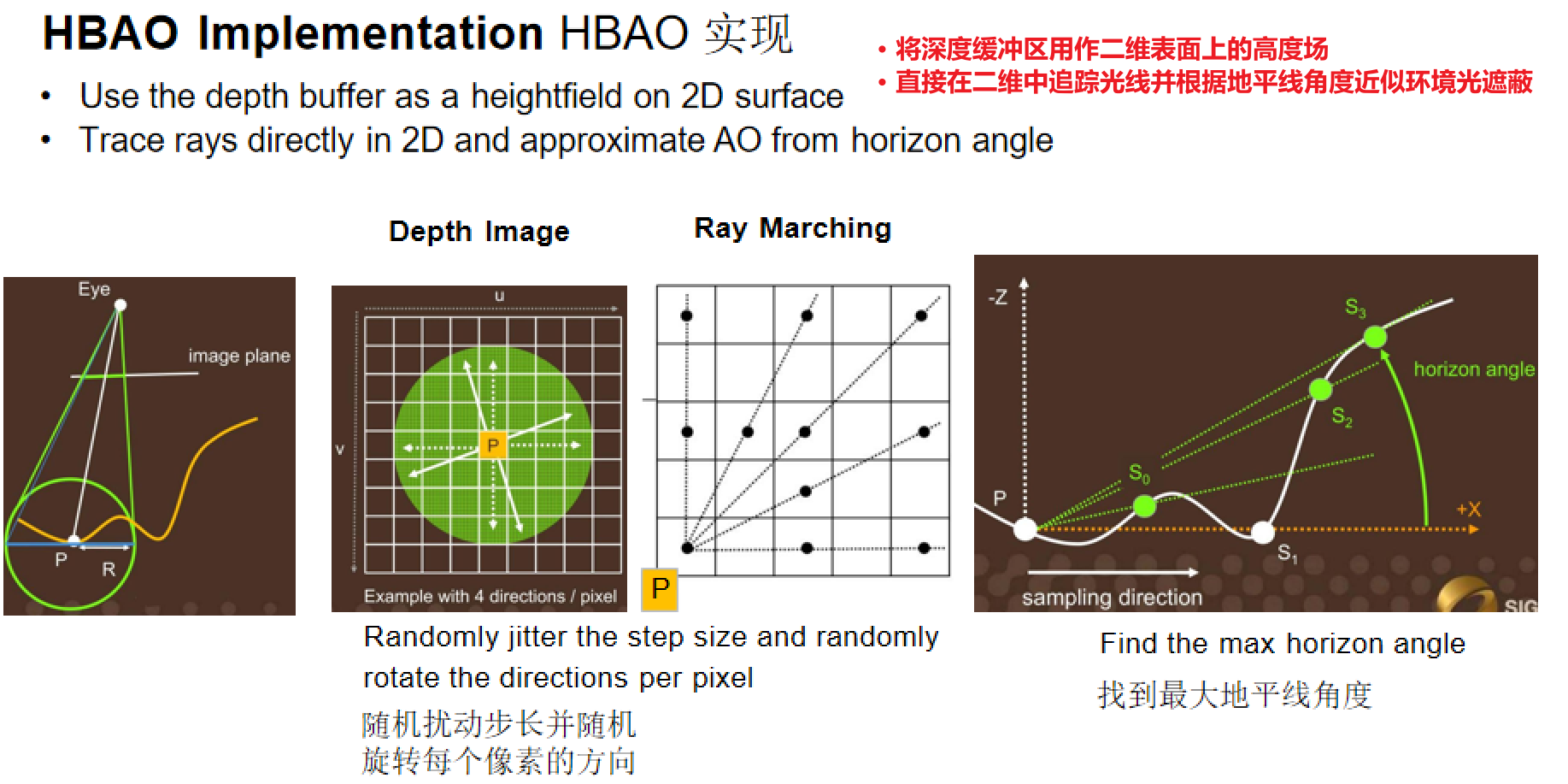
核心思想:将深度缓冲区用作二维表面上的高度场,直接在二维中追踪光线并根据地平线角度近似环境光遮蔽。低于地平线角度的光线被遮挡。
HBAO方程:A = 1 - (1 / (2π)) * ∫ from θ=-π to π ∫ from α=t(θ) to h(θ) W(ω)cos(α)dαdθ
衰减函数:max(0, 1-r(θ)/R)
实现步骤:
- 在视图空间中围绕每个像素p生成N个球体内的随机样本
- 通过将样本深度与深度缓冲区比较来测试样本遮挡情况
- 对样本点的可见性进行平均以近似环境光遮蔽
- 随机扰动步长并随机旋转每个像素的方向(Jittering)
- 通过ray marching找到最大地平线角度
HBAO假设各个方向上的光贡献相同(这也是算法的缺陷),对SSAO+在计算衰减比例上做了简化:区域采样点计算比例 => 积分切面最大仰角。
基于真实感的环境光遮蔽(GTAO)

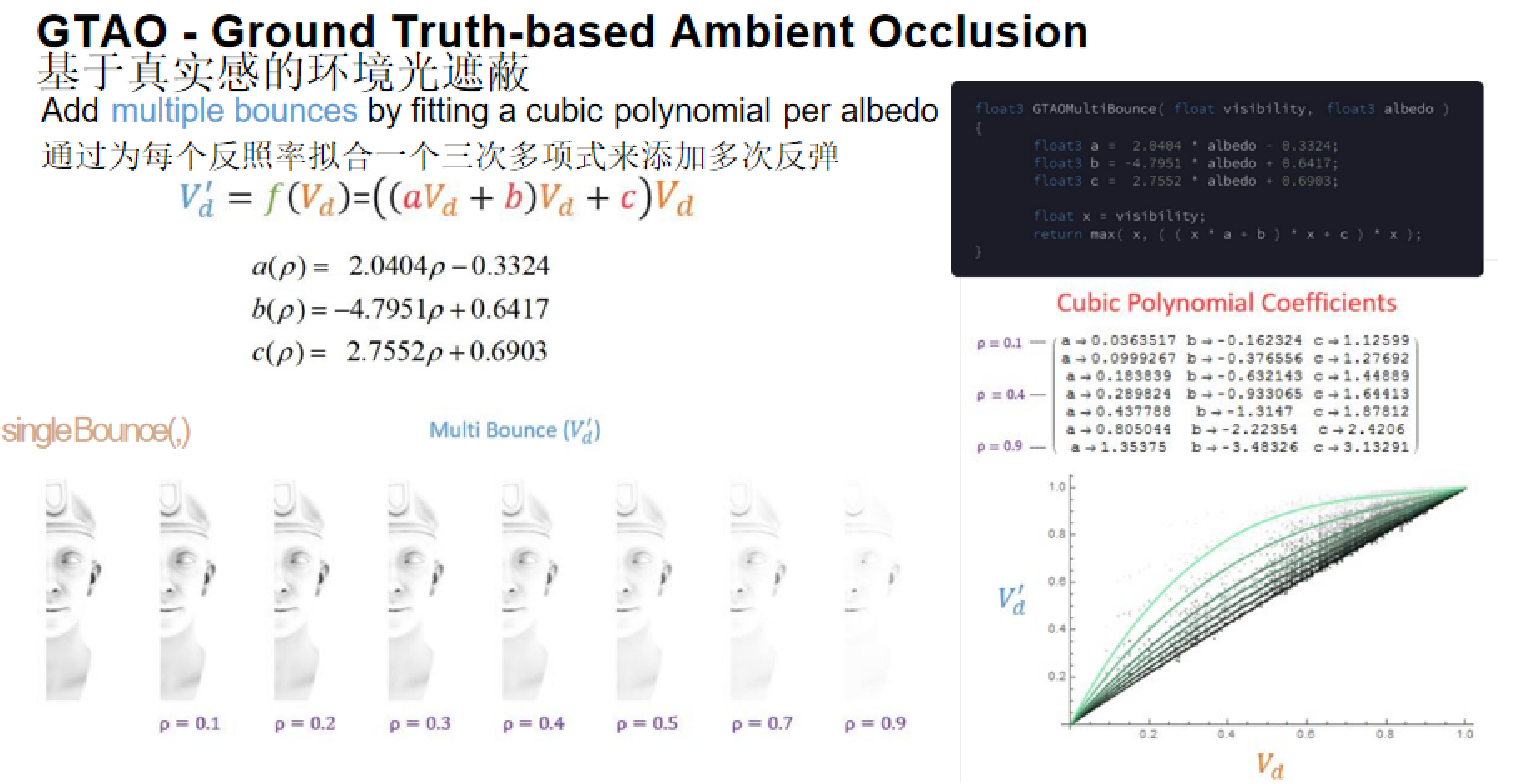
核心改进:GTAO引入了缺失的余弦因子,移除了衰减函数,并添加了多次反弹的快速近似。
GTAO方程:A(x) = (1/π) ∫₀^π ∫_(θ₁(φ))^(θ₂(φ)) [cos(θ - γ)]⁺ |sin(θ)| dθ dφ
其中[cos(θ - γ)]⁺为余弦项,考虑了渲染方程中的余弦因子。
多次反弹近似:通过为每个反照率拟合一个三次多项式来添加多次反弹:
V'd = f(Vd) = ((aVd + b)Vd + c)Vd
其中系数a、b、c是反照率ρ的线性函数:
a(ρ) = 2.0404ρ - 0.3324b(ρ) = -4.7951ρ + 0.6417c(ρ) = 2.7552ρ + 0.6903
GTAO补充了缺失的余弦项,并对光线进行多次弹射的效果进行了拟合,使得最终结果接近真实值。
光线追踪环境光遮蔽(Ray-Tracing Ambient Occlusion)
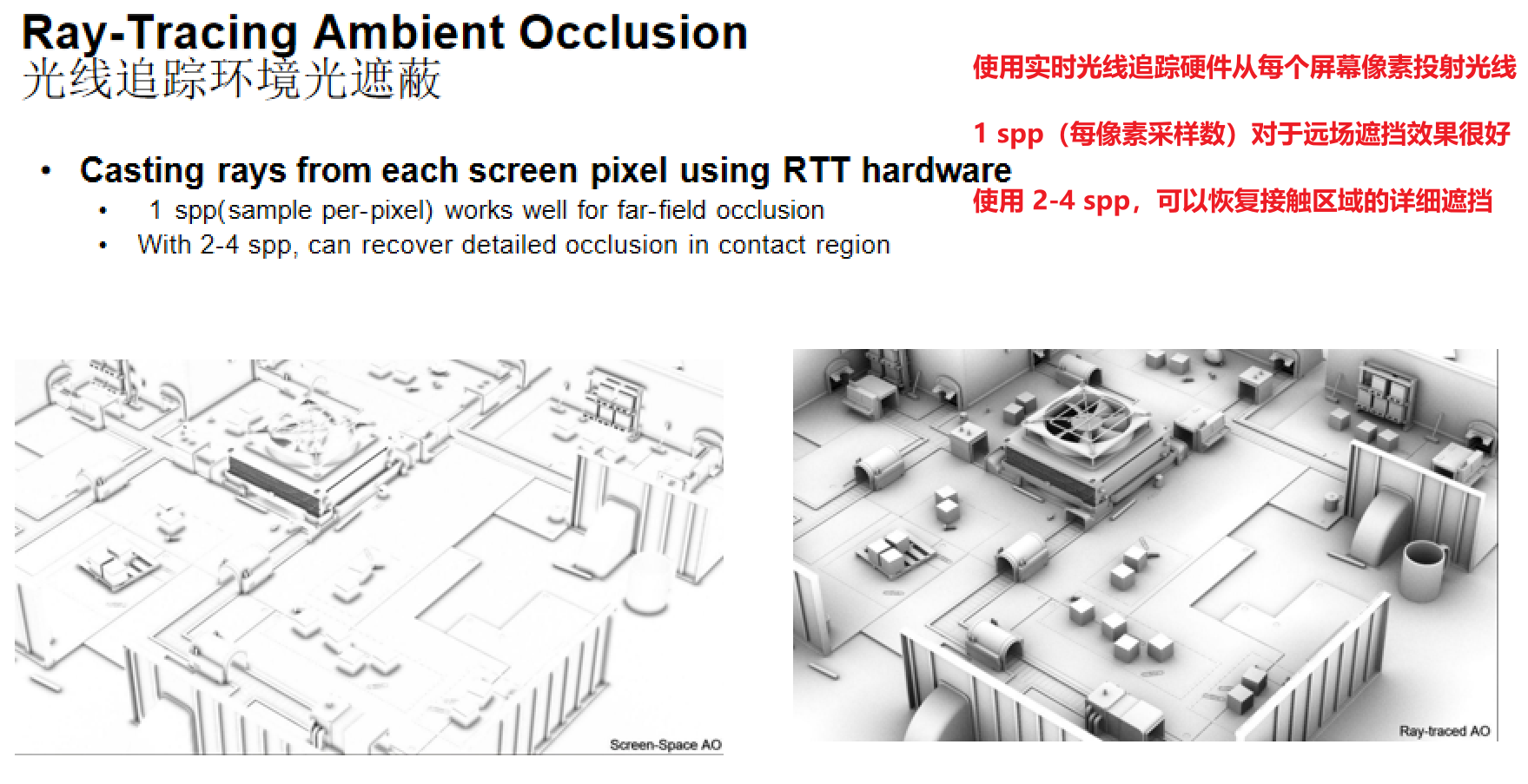
核心思想:使用实时光线追踪硬件从每个屏幕像素投射光线,基于RTX硬件,每个像素发出一些射线来进行遮蔽检测来计算AO情况。
采样策略:
- 1 spp(每像素采样数):对于远场遮挡效果很好
- 2-4 spp:可以恢复接触区域的详细遮挡
优点:相比屏幕空间方法,能够获得更准确和详细的遮挡信息,特别是在接触区域和复杂几何结构处。
利用现代GPU的强大计算能力,可以通过实时光线追踪的方式来计算AO,获得更高质量的渲染效果。
7.2 雾效
雾效是游戏设计者非常喜欢的视觉效果,能够增强场景的深度感和氛围。雾的本质是气溶胶,与高度有一定关系。雾越浓,透明度越低。
深度雾(Depth Fog)

核心思想:假设空间中充满了均匀的雾,只需要根据深度缓冲就可以计算看到物体的透明度。
三种雾透明度计算方式:
线性雾:
factor = (end - z) / (end - start)- 雾效随距离线性增加,过渡均匀
指数雾:
factor = exp(-density × z)- 雾效随距离指数增长,远处雾效更明显
指数平方雾:
factor = exp(-(density × z)²)- 雾效随距离指数平方增长,最常用,远处雾效最强
深度雾是最简单的雾效实现方式,使用深度信息来考虑雾的视觉效果,计算简单高效。
高度雾(Height Fog)

核心思想:处理与高度相关的雾效,例如从山脚向上看可以看到雾效,但在山顶看不到雾效。现实中雾往往和所处高度有关,海拔越低的地方雾效越明显。
雾密度分布:D(h) = Dmax × e^(-σ × max(h - Hs, 0))
其中:
- Dmax:最大雾密度
- σ:密度衰减因子
- Hs:雾起始高度
- h:当前高度
在某一高度值以下,雾的浓度是常数;超过这个高度后,雾浓度逐渐稀薄,呈指数递减。
沿视线方向的高度雾积分:
FogDensityIntegration = Dmax × d × e^(-σ × max(vz - Hs, 0)) × (1 - e^(-σ × dz)) / (σ × dz)
其中:
- d:视线距离
- vz:观察者高度
- dz:视线垂直分量
透射后的雾颜色:
- 雾内散射:
FogInscatter = 1 - exp^(-FogDensityIntegration) - 最终颜色:
FinalColor = FogColor × FogInscatter
为了降低运行时硬件负担,可以把事先计算好的解析值直接带入使用。
基于体素的体积雾(Voxel-based Volumetric Fog)
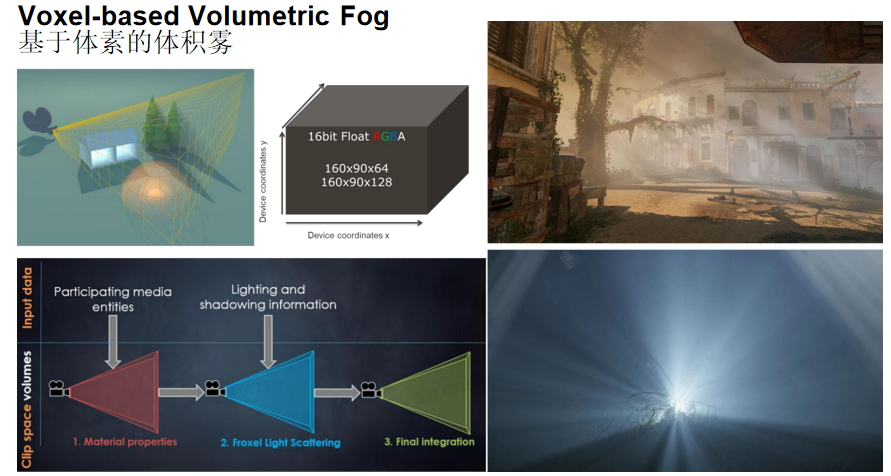
核心思想:深度雾和高度雾都在屏幕空间进行处理,难以处理某些效果,如幽暗环境中一束光透过雾产生的丁达尔效应。体积雾可以产生丁达尔效应,实现更逼真的雾效。
实现方法:
- 体素化空间:根据视锥与摄像机的远近,对空间进行划分(近处密集,远处稀疏),更符合自然效果
- 数据存储:使用3D纹理(16位浮点RGBA)存储体素数据,如160×90×64或160×90×128分辨率
- 光线步进:对切分后的视锥进行ray marching计算,考虑光线在参与介质中的各种行为(散射、吸收等)
处理流程:
- 材质属性:处理参与介质实体的属性
- Froxel光散射:计算光照和阴影信息在体素中的散射
- 最终积分:结合所有计算结果,生成最终的体积雾效果
体积雾的生成与体积云类似,但使用的是3D纹理。在现代3A游戏中,体积雾能够实现逼真的雾效,包括光线的体积散射和丁达尔效应。
7.3 抗锯齿
走样(Aliasing)是渲染中常见的问题。当相机的采样频率小于场景变化的频率时,会导致图像上出现锯齿和走样。反走样(Anti-aliasing)的目标是去除图像上的走样,基本思路是在每个像素点上进行多次采样并取平均,过滤掉高频信号。
锯齿的原因

锯齿是一系列由高频信号与有限的渲染分辨率采样不足引起的渲染瑕疵。主要出现在三个区域:
- 边缘采样:几何边缘的锯齿(Jaggies),表现为阶梯状边缘
- 纹理采样:纹理细节的走样,如摩尔纹(Moiré)和闪烁
- 高光采样:高光反射区域的锯齿,表现为像素化的高光
抗锯齿基本策略
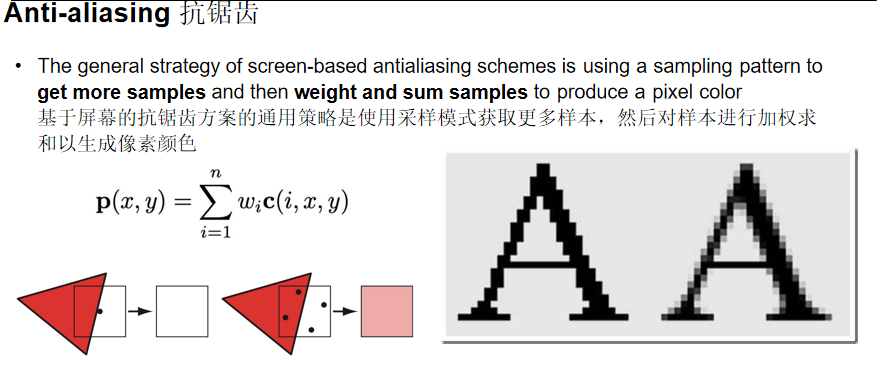
基于屏幕的抗锯齿方案的通用策略:使用采样模式获取更多样本,然后对样本进行加权求和以生成像素颜色。
像素颜色计算公式:p(x, y) = ∑(i=1 to n) wᵢc(i, x, y)
其中wᵢ为权重,c(i, x, y)为第i个采样点的颜色。
超级采样与多重采样抗锯齿(SSAA/MSAA)
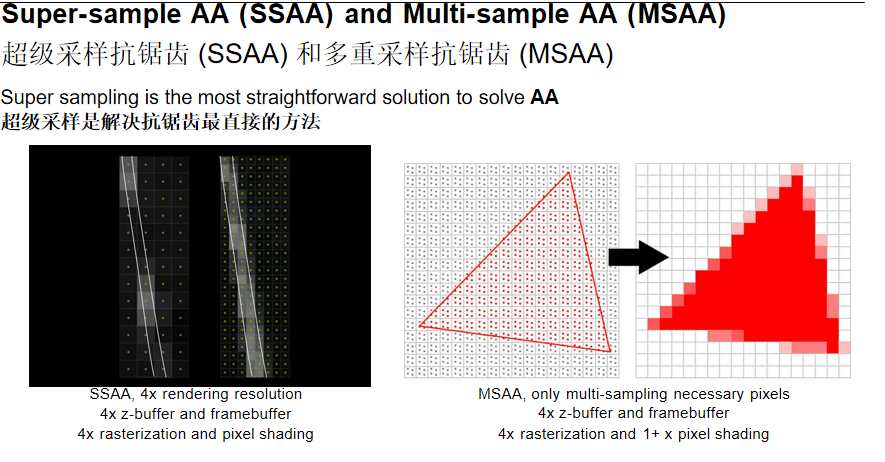
超级采样抗锯齿(SSAA):直接使用更高的分辨率进行渲染,然后在输出图像前通过降采样获得正常分辨率的图像。
- 4x SSAA:4倍渲染分辨率,4倍Z缓冲区和帧缓冲区,4倍光栅化和像素着色
- 缺点:计算复杂度非常高,在现代游戏引擎中基本已经弃用
多重采样抗锯齿(MSAA):只对必要的像素进行多重采样,利用采样点进行着色,然后通过取平均的方式处理走样。
- 4x MSAA:4倍Z缓冲区和帧缓冲区,4倍光栅化,1倍像素着色(只对边缘像素进行多次着色)
- 优点:相比SSAA,大幅降低了像素着色开销
快速近似抗锯齿(FXAA)

核心思想:基于1x渲染图像进行抗锯齿,在图像的边缘区域使用插值的方式实现反走样。
实现步骤:
- 通过亮度查找边缘像素:使用边缘检测算子检测图像亮度发生剧烈变化的区域
亮度计算:L = 0.299 × R + 0.587 × G + 0.114 × B
对比度计算:
// 计算当前像素和邻域像素的对比度
float MaxLuma = max(N, E, W, S, M); // 最大亮度
float MinLuma = min(N, E, W, S, M); // 最小亮度
float Contrast = MaxLuma - MinLuma; // 对比度
// 如果对比度超过阈值,则检测到边缘
if(Contrast >= _MinThreshold) // _MinThreshold = 0.05
{
// 进行边缘处理
}
- 计算偏移方向:通过卷积运算判断边缘是在水平方向还是垂直方向发生较大变化
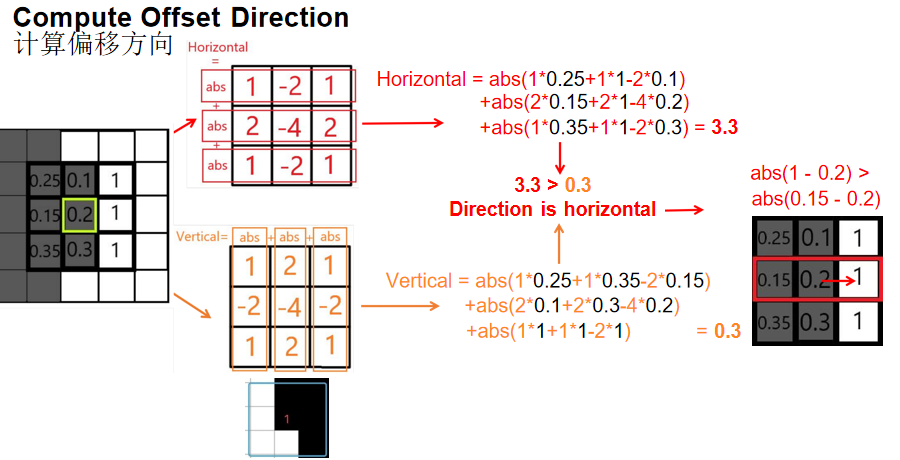
水平梯度:使用水平滤波器计算水平方向的梯度幅度
垂直梯度:使用垂直滤波器计算垂直方向的梯度幅度
方向判断:比较水平和垂直梯度,选择梯度较大的方向作为偏移方向
- 边缘搜索算法:沿垂直方向搜索并计算平均亮度,找到边缘端点

算法步骤:
- 查找像素所在的锯齿边缘
- 记录当前像素和偏移像素的对比度亮度和平均亮度:
L_contrast = abs(L_current - L_offset),L_avg = (L_current + L_offset) / 2 - 沿2个垂直方向搜索并计算平均亮度:
L_edge1n = (L_An + L_Bn) / 2,L_edge2n = (L_Cn + L_Dn) / 2 - 直到
abs(L_edge1n - L_current) > 0.25 × L_contrast或abs(L_edge2n - L_current) > 0.25 × L_contrast时停止
- 计算混合系数:根据当前点到边缘端点的距离确定插值系数
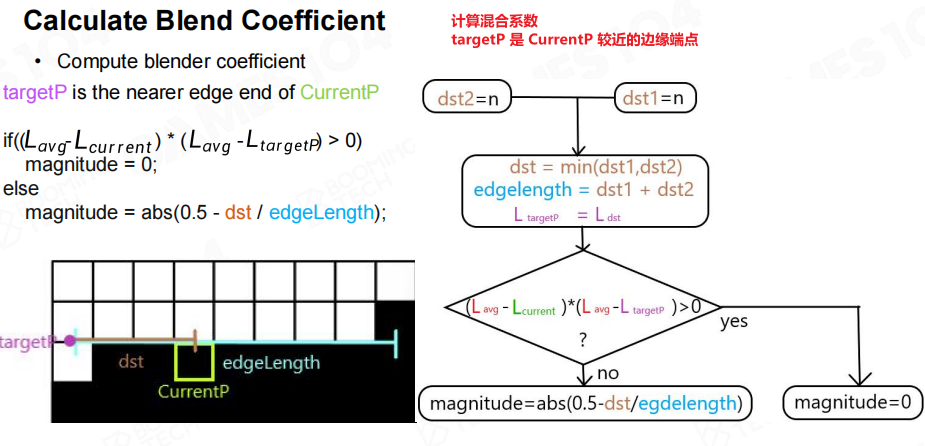
混合系数计算:
// targetP是CurrentP较近的边缘端点
dst = min(dst1, dst2); // 到较近端点的距离
edgeLength = dst1 + dst2; // 边缘总长度
// 如果当前像素和端点在同一侧,不进行混合
if((Lavg - Lcurrent) * (Lavg - Ltargetp) > 0)
magnitude = 0;
else
magnitude = abs(0.5 - dst / edgeLength); // 计算混合系数
- 混合邻近像素:对边缘像素进行颜色插值
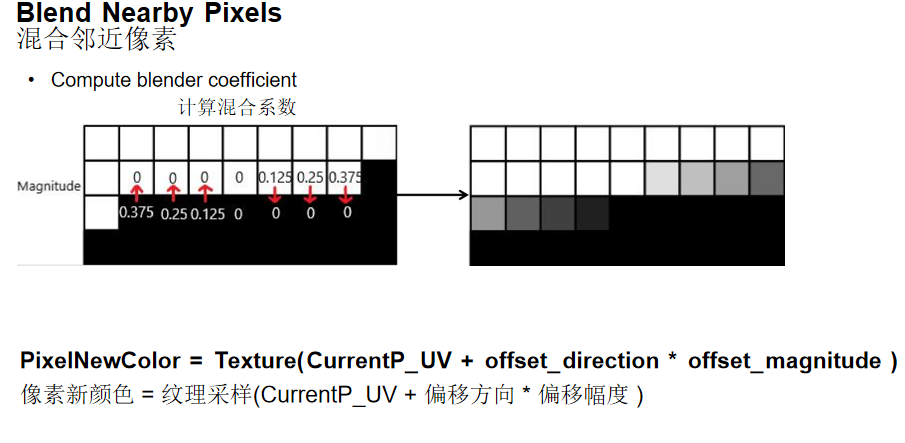
像素颜色计算:PixelNewColor = Texture(CurrentP_UV + offset_direction × offset_magnitude)
通过偏移方向和偏移幅度对边缘像素重新采样,与邻居像素混合,实现平滑的边缘效果。

FXAA是非常实用的抗锯齿方法,速度很快,现代显卡基本都集成了该方法,商业游戏较多使用该方法。
时序抗锯齿(TAA)
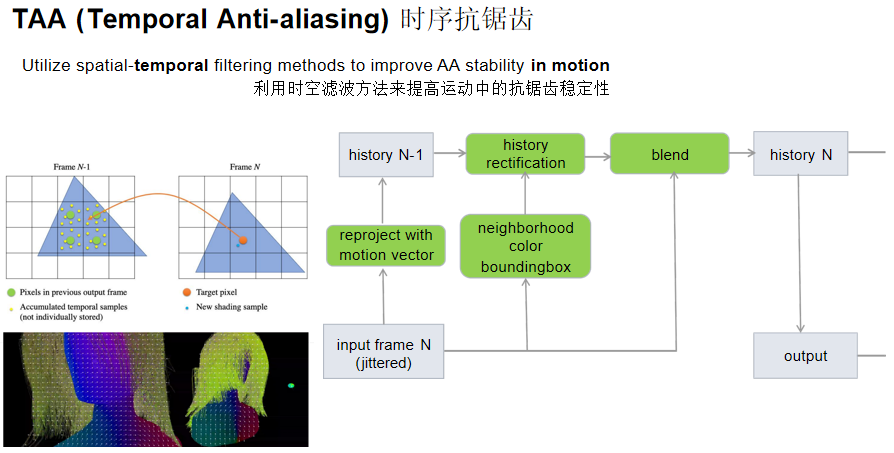

核心思想:利用时空滤波方法提高运动中的抗锯齿稳定性。考虑每个像素在上一帧所处的位置,将上一帧对应位置的颜色和当前帧的颜色进行加权平均来进行滤波。
TAA算法流程:
- 输入:当前帧N(带抖动)和历史帧N-1
- 重投影:使用运动向量将历史帧N-1重投影到当前帧
- 邻域颜色边界框:分析当前像素邻域的颜色范围
- 历史修正:根据邻域颜色边界框修正重投影的历史,防止重影等伪影
- 混合:将修正后的历史与当前抖动输入帧混合
- 输出:生成当前帧N的历史和最终抗锯齿图像
运动向量:记录每个像素从前一帧到当前帧的运动方向和距离,用于将前一帧的采样重投影到当前帧。

TAA也是现代引擎常用的方法,能够有效提高运动中的抗锯齿稳定性,获得更平滑的渲染效果。
7.4 后处理
后处理(Post-process)是指在Camera渲染完成之后,对渲染的纹理进行进一步处理。后处理用于保证画面正确以及实现特殊效果,之前提到的SSAO、Depth Fog也属于后处理流程。后处理可以理解为游戏渲染的”美颜相机”,对画面表现力有质的提升。

后处理主要分为两类目的:
- 物理真实:正确曝光、光晕效果等
- 风格化表达:颜色分级(Color Grading)等
泛光(Bloom)

核心思想:现实中看到强光源时,周围会有一圈光晕,Bloom用于模拟这种效果。在游戏中,Bloom能够增强场景的艺术感和氛围。

物理基础:泛光的物理基础在于,现实世界中透镜永远无法完美对焦。即使完美的透镜也会将传入的图像与艾里斑(Airy disk)进行卷积,产生光晕效果。另一种解释是,人眼晶状体中的参与介质(类似气溶胶)会产生米氏散射,光线在眼睛内部发生散射,在视网膜上形成光晕效果。
实现步骤:
- 提取高亮区域:通过阈值检测亮部区域

亮度计算:Y = Rlin × 0.2126 + Glin × 0.7152 + Blin × 0.0722
阈值检测:
// 计算当前像素的亮度
float luminance = dot(scene_color.rgb, vec3(0.2126f, 0.7152f, 0.0722f));
// 如果亮度超过阈值,则提取为高亮区域
if(luminance > threshold) // threshold通常为1.0,或使用平均场景亮度
{
highlight_color = scene_color; // 保留原始颜色
}
else
{
highlight_color = float4(0.0f, 0.0f, 0.0f, 1.0f); // 黑色
}
- 高斯模糊处理:对提取的高亮区域进行模糊
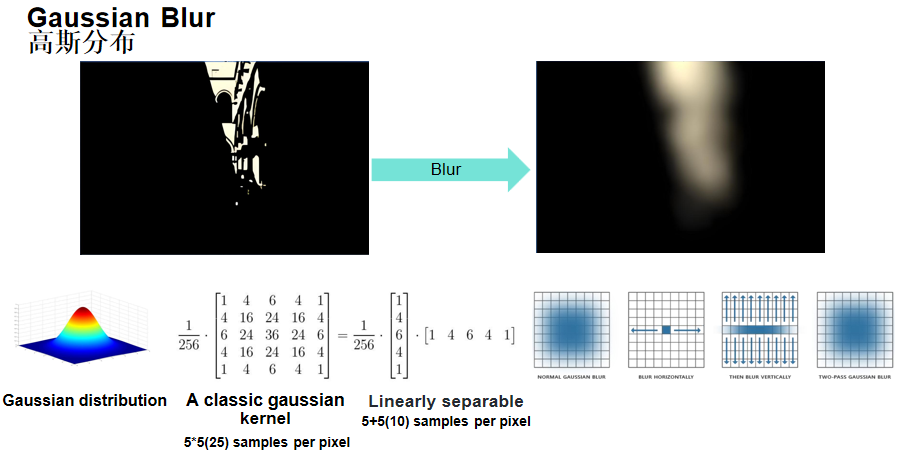
高斯模糊原理:高斯分布具有线性可分离特性,可以将2D卷积分解为两个1D卷积,大幅降低计算量。
5×5高斯核:
1/256 × [1 4 6 4 1]^T × [1 4 6 4 1]
两遍高斯模糊:
- 第一遍:水平方向模糊(5个采样点)
- 第二遍:垂直方向模糊(5个采样点)
- 总采样数:5 + 5 = 10个采样点(相比2D卷积的25个采样点,效率提升2.5倍)
- 金字塔高斯模糊:对于大范围光晕,使用图像金字塔加速
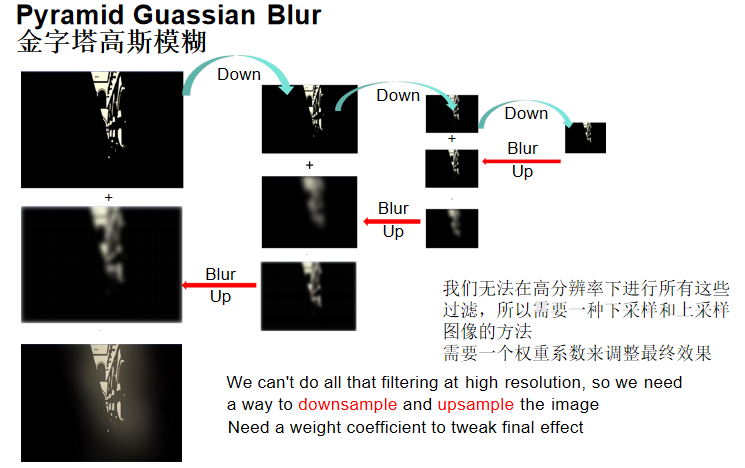
核心思想:无法在高分辨率下进行大范围模糊,需要下采样和上采样图像的方法。
处理流程:
- 下采样:将图像逐级下采样,形成图像金字塔
- 低分辨率模糊:在最低分辨率层级进行高斯模糊
- 上采样叠加:将模糊结果逐级上采样,与上一级图像叠加,并再次模糊
- 权重系数:每层叠加时使用权重系数调整最终效果
这种方法在低分辨率上进行模糊,然后逐级放大叠加,计算量远小于在高分辨率图像上进行大范围模糊。
- 合成最终效果:将模糊后的高亮区域叠加到原始图像

合成公式:FinalColor = OriginalColor + BloomColor × intensity
通过调整叠加强度(intensity),可以控制光晕的强弱。

Bloom效果能够显著增强场景的艺术感和氛围,是现代游戏必备的后处理效果。
色调映射(Tone Mapping)

核心问题:自然界中亮度范围很大(太阳光可能是烛光的几亿倍),但显示设备的亮度范围有限。若不对颜色做处理,当显示的颜色亮度超出显示上限时会被截断,产生过曝现象。
解决方案:使用Tone Mapping将HDR图像的亮度映射到显示器能够处理的亮度范围内。

Tone Mapping定义:
- 无法在标准动态范围(SDR)设备上直接显示高动态范围(HDR)图像
- Tone Mapping函数的目的是将宽范围的高动态范围颜色映射到显示器可以输出的标准动态范围
Tone Mapping曲线:颜色的映射方案就是Tone Mapping的核心,通过一条曲线将HDR亮度值映射到SDR范围。
Filmic s-curve
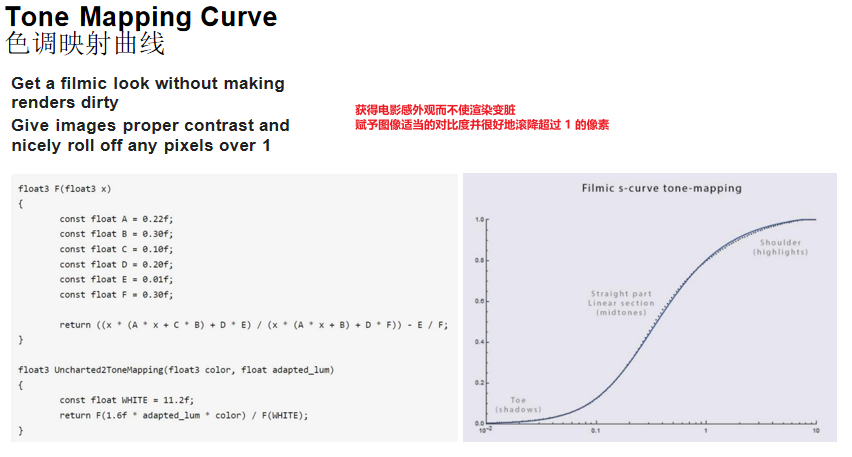
核心思想:Filmic s-curve是行业早期提出的颜色映射曲线,通过大量实践进行参数化拟合,让游戏画面获得电影般的质感。
曲线特性:
- Toe(阴影):压缩暗部细节
- Straight part(中间调):线性映射,保持对比度
- Shoulder(高光):压缩亮部细节,滚降超过1的像素
实现函数:
// Filmic曲线核心函数
float3 F(float3 x)
{
const float A = 0.22f;
const float B = 0.30f;
const float C = 0.10f;
const float D = 0.20f;
const float E = 0.01f;
const float F = 0.30f;
return ((x * (A * x + C * B) + D * E) / (x * (A * x + B) + D * F)) - E / F;
}
// Uncharted 2 Tone Mapping
float3 Uncharted2ToneMapping(float3 color, float adapted_lum)
{
const float WHITE = 11.2f;
return F(1.6f * adapted_lum * color) / F(WHITE);
}
Filmic曲线通过多项式公式拟合,可以直接在Shader中计算,无需查表,效率高且效果好。
ACES(Academy Color Encoding System)

核心思想:ACES来自美国电影艺术与科学学院,是目前最被认可的颜色曲线,能够有效在各种终端有稳定的显示效果。
ACES的优势:
- 视觉一致性:在HDR和SDR之间保持视觉一致性
- 设备适配:能够无差别地适应各种显示终端(HDR显示器、SDR显示器、电影院等)
- 专业调校:所有数值和曲线都经过大量专业视觉艺术家调校
- 艺术意图分离:将艺术意图与支持不同设备的机制分离开
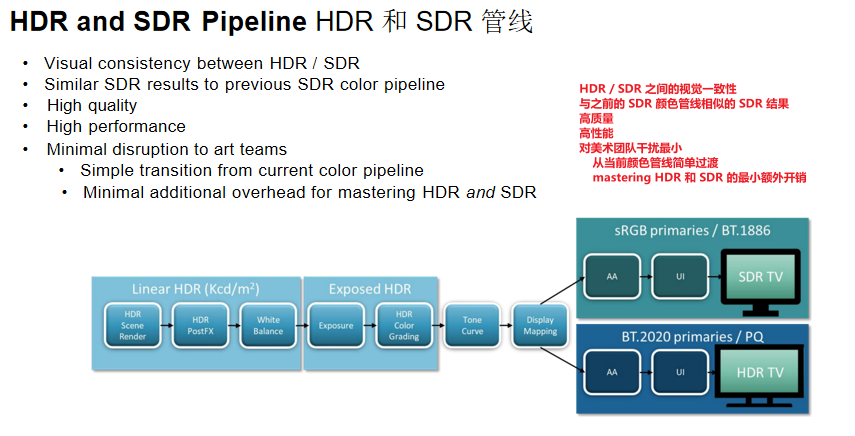
HDR和SDR管线:
- 统一管线:HDR场景渲染 → HDR后处理 → 白平衡 → 曝光 → HDR颜色分级 → Tone曲线 → 显示映射
- 分支输出:从显示映射分支为SDR输出(sRGB/BT.1886)和HDR输出(BT.2020/PQ)
- 优势:视觉一致性、高质量、高性能、对美术团队干扰最小
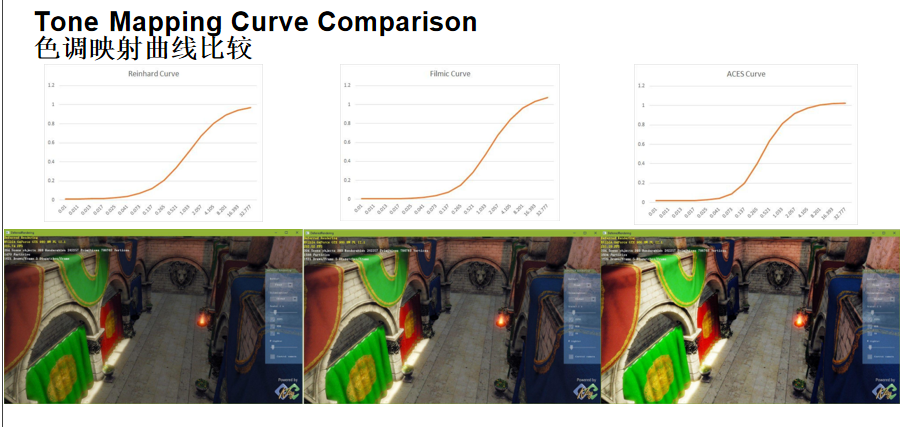
不同曲线对比:
- Reinhard曲线:平衡、略微扁平的效果
- Filmic曲线:高对比度、色彩丰富、高光明显
- ACES曲线:亮部足够亮、色彩饱满、暗部清晰、明暗有致
目前3A游戏中越来越多地使用ACES曲线进行色调映射。
颜色分级(Color Grading)

核心思想:Color Grading用于调整画面的色调,以达到烘托气氛或特殊的画风效果。本质是建立一个颜色到颜色的映射,从而获得不同的画面表现效果。
处理方式:对原有像素颜色通过查表(Lookup Table, LUT)变为需要的颜色。

LUT定义:
- LUT用于根据LUT中包含的数据将源像素的输入颜色值重新映射到新的输出值
- LUT可以被视为一种可以应用于图像或镜头的颜色预设
LUT示例:同一场景应用不同的LUT会产生完全不同的视觉效果,如冷色调、暖色调、高饱和度、低饱和度等。
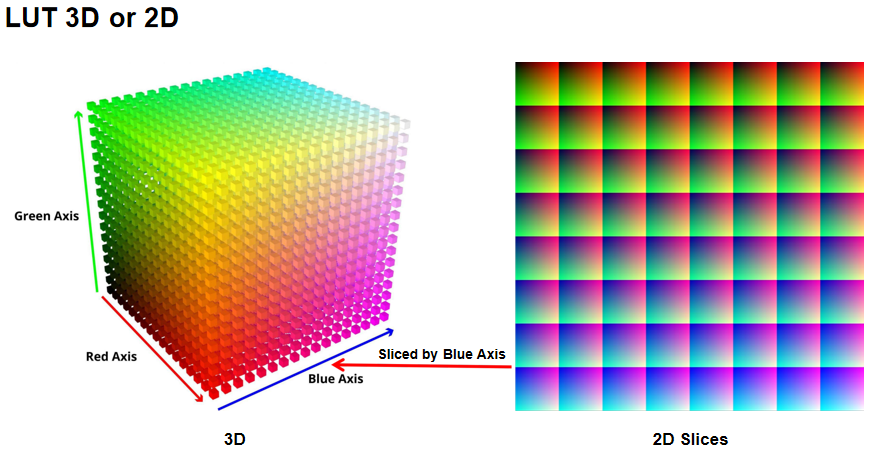
3D颜色空间到2D纹理:
- 3D LUT:RGB颜色空间可以表示为3D立方体,每个维度对应一个颜色通道
- 2D切片:可以将3D立方体沿某个轴(如蓝色轴)切片,形成2D纹理
- 存储方式:使用3D纹理或纹理数组存储映射关系,通过查表方式对画面进行调色
LUT分辨率:通常使用16×16×16或32×32×32的LUT即可,因为颜色是连续的,中间值可以通过插值获得,无需存储完整的256×256×256映射。
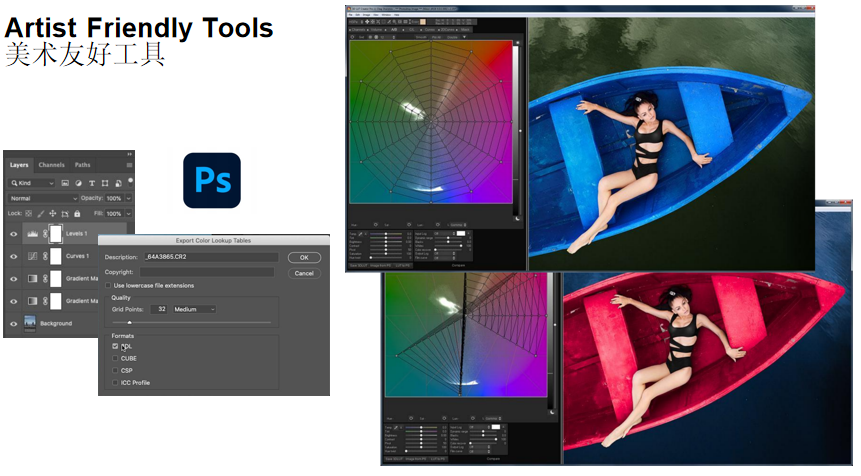
艺术家友好工具:
- Photoshop:艺术家可以在Photoshop中调色,然后导出为LUT(3DL、CUBE等格式)
- 专业调色软件:专门的Color Grading工具,艺术家通过颜色轮和滑块调整,直接生成LUT
- 工作流程:艺术家调色 → 导出LUT → 引擎加载LUT → 实时应用效果

应用效果:Color Grading可以烘托玩家不同的情绪,从而提升玩家的游戏体验。例如,在Boss战中,画面颜色会发生变化,营造紧张氛围。
Color Grading是游戏渲染中最具成本效益的功能:实现简单,但对游戏效果有质的飞跃。原始图可能看起来很一般,但一旦应用Color Grading,画面就会变得非常有情绪和表现力。
7.5 渲染管线
渲染管线(Rendering Pipeline)是管理所有渲染操作执行顺序和资源分配的机制。到目前为止,我们已经学习了渲染方程、地形、大气、AO、雾效、抗锯齿、后处理等众多渲染算法,但还有一个核心问题:如何将这些算法有序地组织起来,使得整个渲染系统能够正常工作?
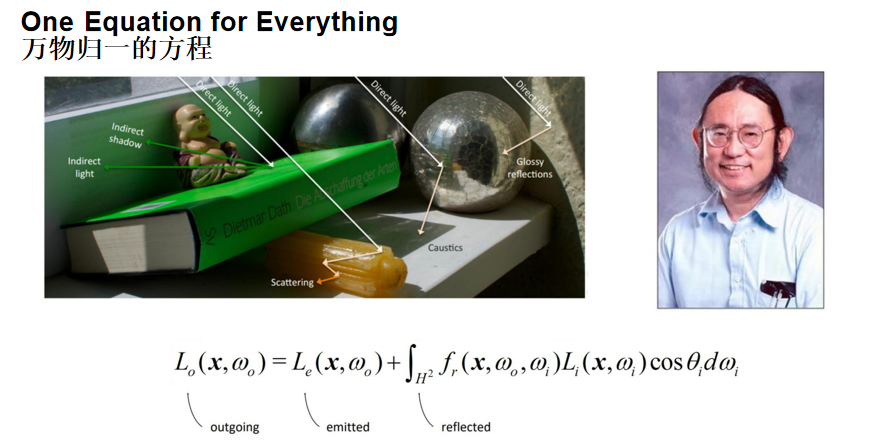
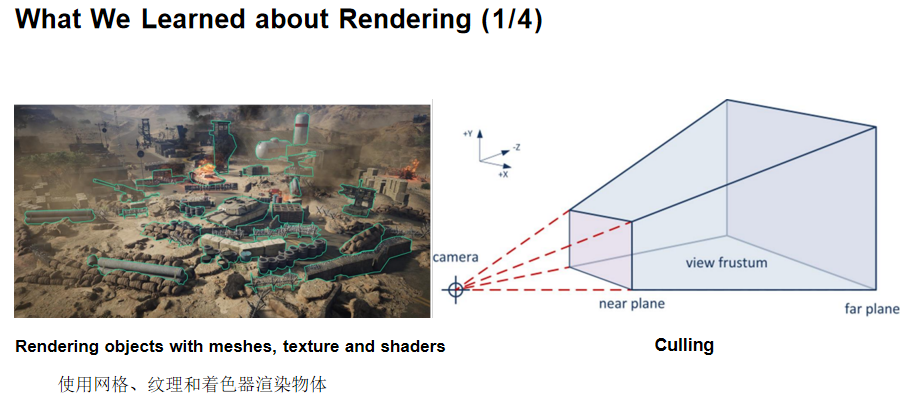



游戏引擎的渲染与图形学中的渲染最本质的区别在于:我们无法抽象出一个简单干净的算法。实际上,在一个游戏画面中,有几十种到上百种算法同时在运作,而渲染管线就是将这些算法有序组织起来的机制。
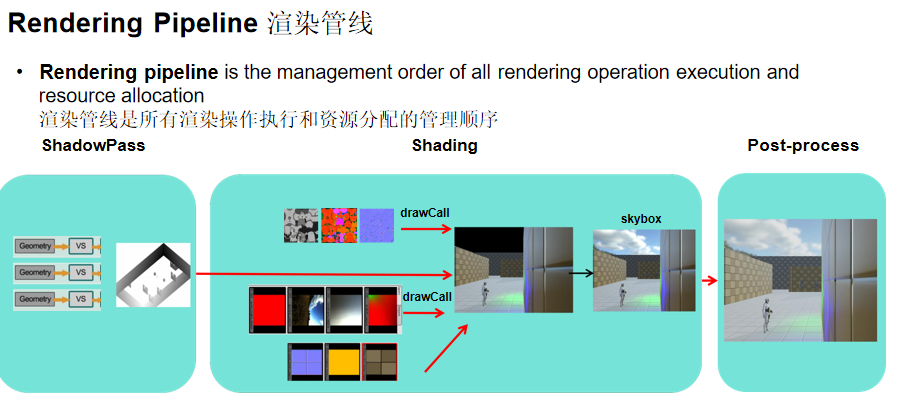
最简单的渲染管线流程:先计算Shadow Map,然后依次渲染物体进行光照和着色,最后进行后处理(如Bloom、曝光、Color Grading)。这就是前向渲染(Forward Rendering),很多商业级游戏都采用这种方式。
前向渲染(Forward Rendering)
核心思想:按照网格和光源进行遍历,依次把计算得到的颜色累加到指定的像素上。渲染消耗与可视对象和光源相关(对象 × 光源)。

物体渲染顺序:
- 不透明物体:由近及远渲染(避免OverDraw)
- 半透明物体:由远及近渲染(处理颜色混合)
透明物体排序问题:透明物体必须在不透明物体之后绘制,且需要按照深度由远及近排序。当两个透明物体前后重叠时,必须先绘制后面的物体,再绘制前面的物体,才能正确混合颜色。
透明物体排序的局限性:某些情况下(如三个透明物体相互穿插),无法完美解决排序问题,只能使用物体的中心点进行排序。这是现代游戏引擎中一个非常困难的问题,特别是在处理大量透明粒子(如烟雾、爆炸效果)时。
前向渲染在早期游戏中广泛使用,如《Just Cause 1》(2006)、《Heavy Rain》(2010)等3A游戏都采用这种方式。但随着现代游戏场景中光源数量急剧增加,前向渲染的效率问题逐渐暴露。
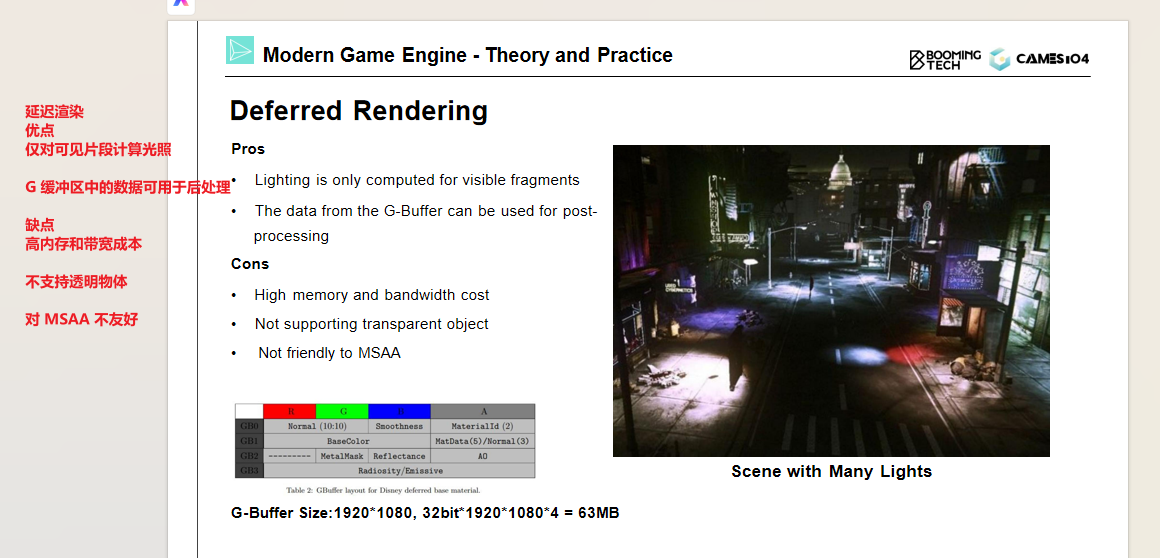
延迟渲染(Deferred Rendering)
核心问题:前向渲染中,每有一个光源就要对渲染物体处理一遍。当场景中存在大量光源时,开销太大。

解决方案:延迟渲染采用两个Pass的处理方案:
- Pass 1:渲染G-Buffer:存储屏幕像素需要的几何信息(Albedo、Specular、Normal、Depth等)
- Pass 2:延迟着色(Deferred Shading):针对像素进行逐光源处理
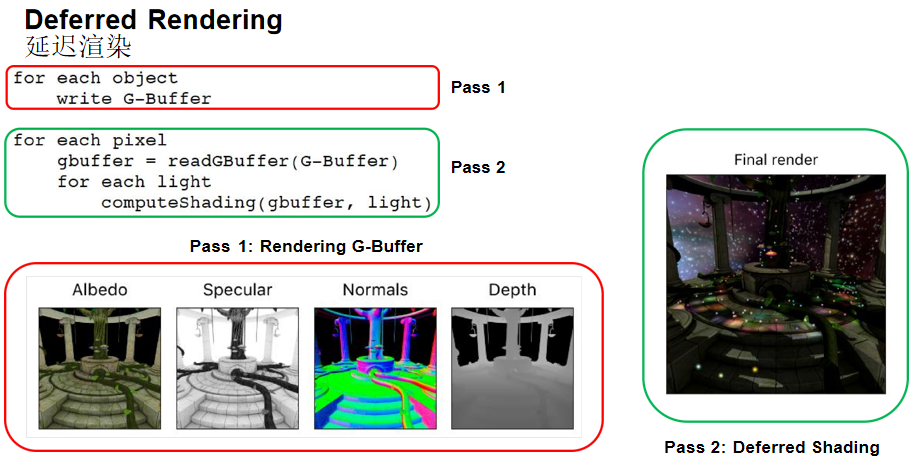
延迟渲染的优势:
- 高效处理多光源:每个像素只计算一次几何信息,然后对所有光源进行着色,避免了OverDraw
- 对光的处理十分方便:可以在屏幕空间直接添加点光源(如夜晚街道场景中的多个小点光源)
- 易于Debug:G-Buffer中的几何信息可以方便地用于后处理计算
延迟渲染的缺点:
- 高内存和带宽成本:G-Buffer需要存储大量几何信息,对显存和带宽压力很高
- 难以支持MSAA:由于G-Buffer的特性,MSAA的实现变得复杂
- 不支持半透明物体渲染:半透明物体仍需要使用前向渲染
延迟渲染在过去十几年中是游戏引擎行业最常用的绘制方式,能够高效处理多光源场景。
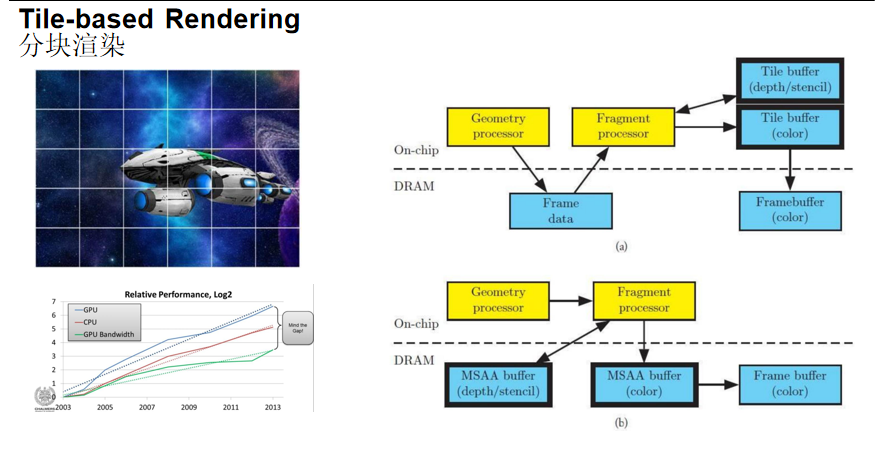
分块渲染(Tile-based Rendering)
核心问题:延迟渲染的G-Buffer对显存和带宽压力很高,在移动端(对带宽、内存和散热极其敏感)尤其明显。
解决方案:将画面拆分成许多小块(Tile),渲染绘制时针对Tile进行处理。移动端GPU架构通常采用这种方式:在芯片内部有高速但尺寸很小的SRAM,将画面切成小块后,只需在小块内进行渲染,然后写入帧缓冲区,而不需要存储整个G-Buffer。
分块光源剔除(Light Culling by Tiles):分块渲染带来了额外的好处——光源可以被分配到各个Tile中。对于屏幕上的每个Tile,可以通过简单的视锥体测试,确定该Tile被哪些光源影响,生成光源列表(Light List)。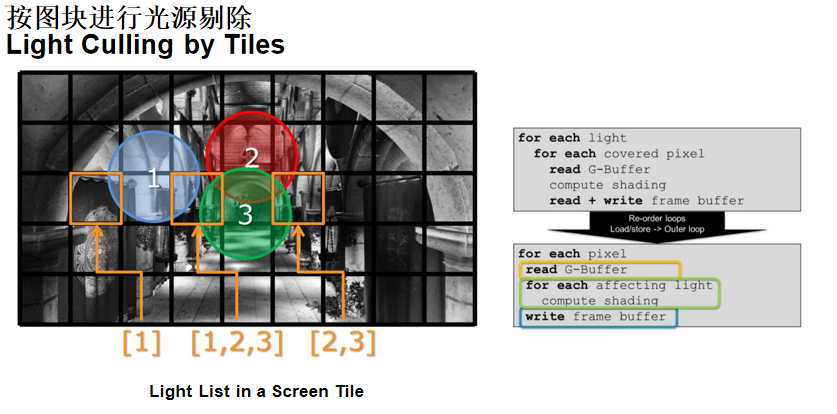
深度范围优化(Depth Range Optimization):利用Pre-Z Pass生成的深度信息,可以获取每个Tile的最小/最大深度。对于点光源(在空间中是一个球体),可以测试光源的深度范围与Tile的深度范围是否相交,从而进一步减少光照计算。90%以上的屏幕区域可能不需要被某些光源照亮。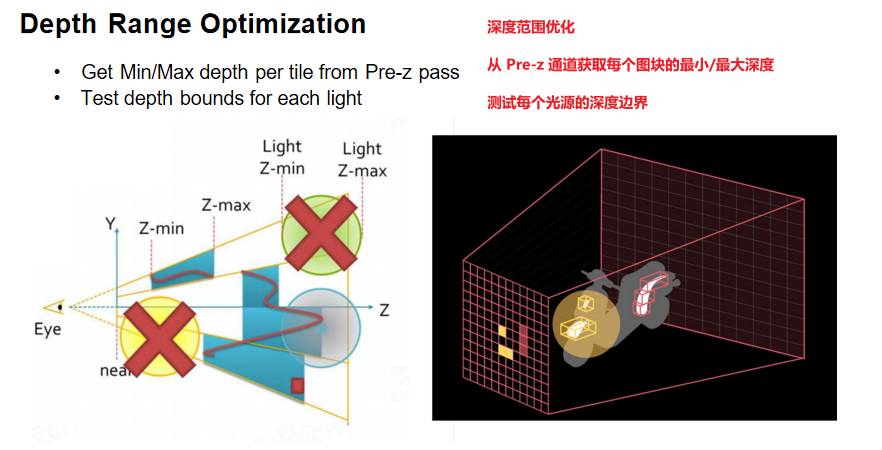
TBDR(Tile-based Deferred Rendering):对Deferred模式使用Tile-based Rendering,这是很多游戏的主流绘制方案,因为它对光的处理非常高效。5年前左右,很多大作都采用了这样的架构。
Forward+(Tile-based Forward Rendering)
核心思想:对Forward模式使用Tile-based Rendering,即按照Tile进行前向渲染。

实现步骤:
- 深度预通道(Depth Prepass):防止过度绘制,提供Tile深度边界
- 分块光源剔除(Tiled Light Culling):输出每个Tile的光源列表
- 逐物体着色(Shading per Object):像素着色器迭代光源剔除中计算的光源列表
Forward+对移动端特别友好,即使在一些PC游戏上也有使用。
基于集群的渲染(Cluster-based Rendering)
核心思想:对空间进行划分时,同时按照深度进行切分,将视图空间划分为多个四棱锥(Cluster),每个Cluster单独计算光源的可见性。
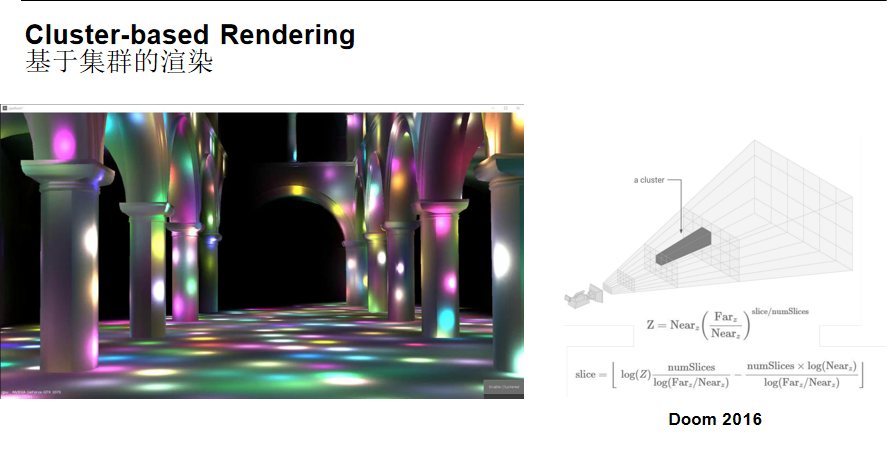
深度切分公式:
Z = Near_z × (Far_z / Near_z)^(slice / numSlices)slice = [log(Z) × (numSlices / log(Far_z / Near_z)) - (numSlices × log(Near_z) / log(Far_z / Near_z))]
Cluster-based Rendering可以处理场景中有上千个光源的极端情况,可以看做是分片渲染在深度上的推广。如果使用传统的Forward Rendering,几千个光源的场景几乎无法渲染。
可见性缓冲区(Visibility Buffer)
核心思想:将几何信息和材质信息分离开来。在前一个Pass中生成一个类似于G-Buffer的全屏Buffer,但每个texel只存储Primitive ID、Barycentrics(重心坐标)和Depth,然后根据这些信息反向查找几何体的材质属性。
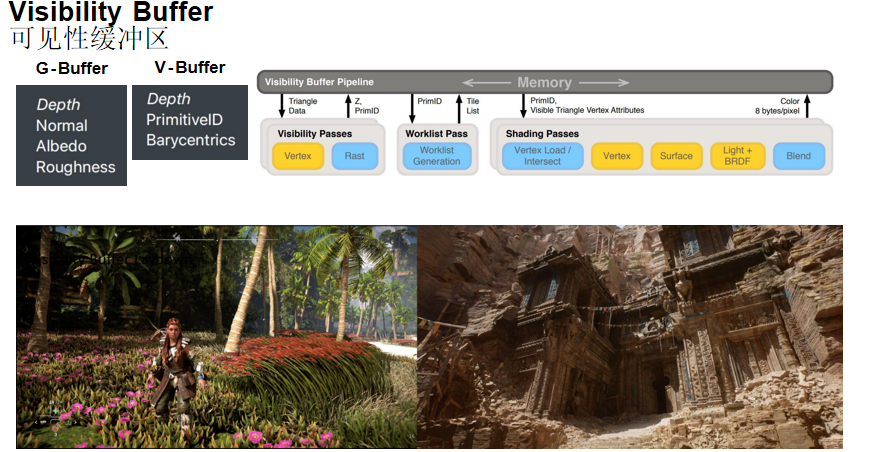
Visibility Buffer Pipeline:
- Visibility Passes:输入三角形数据,经过顶点着色器和光栅化,输出深度和Primitive ID
- Worklist Pass:根据Primitive ID生成Tile列表
- Shading Passes:根据Primitive ID和可见三角形的顶点属性,进行顶点加载、表面着色、光照和BRDF计算,最后混合输出颜色
为什么Visibility Buffer重要:
- 几何密度越来越高:随着虚幻5的Nanite技术、地平线最新作的植被系统等,几何密度非常高,很多时候几何会超过像素
- 避免OverDraw:传统的G-Buffer方法会浪费大量几何的OverDraw,需要大量纹理采样和运算
- 更高效的查找:Visibility Buffer查找VB和IB的效率远高于G-Buffer的纹理采样
- 支持更复杂的材质:可以支持更多更复杂的材质类型,而G-Buffer一般假设材质是一致的
Visibility Buffer的优势:
- 提供更好的几何数据:可以获取完整的几何信息
- 内存、带宽压力小:相比G-Buffer,存储的数据量更小,可以使用MSAA
- 剔除无用材质信息:只存储可见的几何信息,剔除所有无用的材质信息
Visibility Buffer的缺点:
- 计算消耗变大:需要索引不同的纹理,计算复杂度增加
Visibility Buffer是现代渲染管线的重要前沿发展方向。可以预测,在未来3到5年,会有越来越多的管线引入这个机制。目前它一般作为增强型Pipeline使用,但随着技术成熟,可能会成为主流Pipeline。
渲染管线的挑战
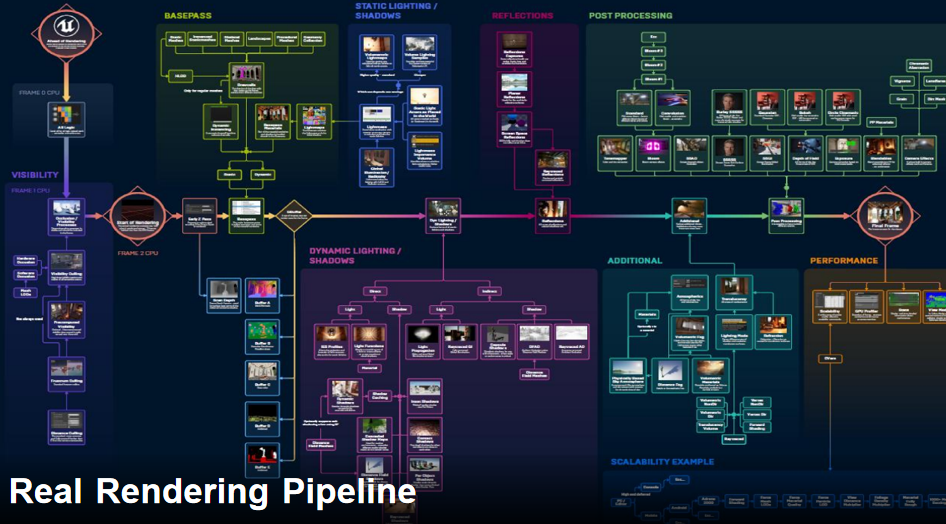

构建一个完整的游戏引擎渲染管线面临以下挑战:
模块化与灵活性:不同项目的渲染需求差异很大(如有人希望使用TAA,有人希望使用FXAA以强调效率)。引擎的各种模块和算法需要像积木一样能够自由组合。
存储资源管理:每个算法除了计算之外,还要占用大量存储资源(各种Buffer)。在整个渲染过程中,这些资源并不需要从头到尾都存在,可能一个计算完成后,结果被另一个计算消耗掉,Buffer就应该被释放。如果不进行精密管理,会导致大量内存、显存空间被浪费。
现代图形API的复杂性:随着DX12和Vulkan等新一代图形API的兴起,硬件管理的复杂度大幅增加。这些API将硬件的裸算力开放给开发者,包括内存管理、资源状态管理、同步机制(内存屏障、锁)等。一旦处理不当,可能导致游戏崩溃或死锁。
尽管每个算法单独拆下来都是可以理解和实现的,但真正构建一个完整的游戏引擎时,如何让这么多算法协同工作,实际上是非常麻烦的。这就是为什么现代游戏引擎的渲染管线如此复杂,需要大量的工程实践和经验积累。
7.6 Frame Graph
在商业游戏引擎的渲染系统中,除了需要包含各种先进的渲染算法外,还需要考虑如何对各种算法有序地进行管理。以虚幻引擎为例,整个渲染管线中包含了大量的可选算法,在实际渲染时需要进行相应的调度使它们按顺序执行。
同时,像Vulkan和DirectX 12等现代图形API往往开放了大量的GPU底层接口进行编程。这使得程序员可以高效地实现对硬件计算资源的管理,但如果开发时不够谨慎,则容易造成整个系统的崩溃。
Frame Graph(帧图)就是为了解决这些问题而提出的技术,它把整个渲染过程所需的算法和各种资源表示为一张有向无环图(DAG),通过对图的管理来实现不同资源的调度。
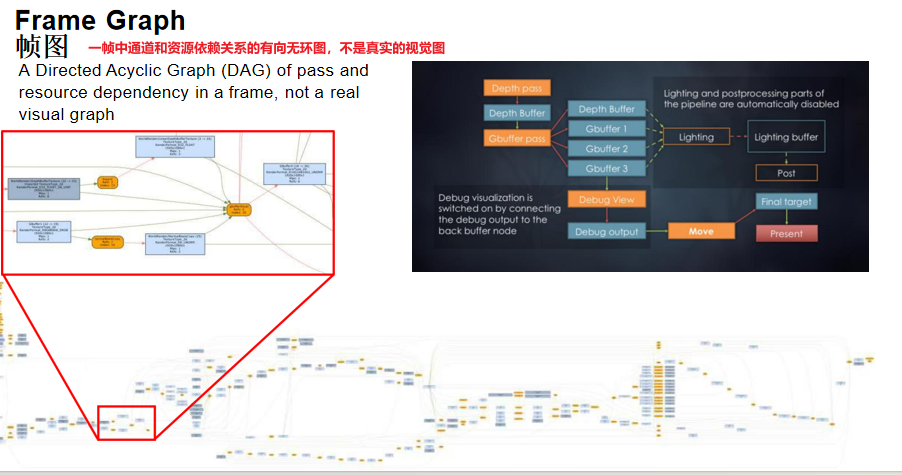
Frame Graph定义:一帧中通道和资源依赖关系的有向无环图,不是真实的视觉图。它用图形化的语言把渲染本身的前后关系和依赖关系表达出来。
Frame Graph的核心思想
核心问题:当渲染系统变得足够复杂时,手动管理各种算法和资源变得非常困难,容易出错。特别是在大团队协作时,如何让每个开发者写的算法彼此之间不冲突,是一个巨大的挑战。
解决方案:将渲染管线中的所有内容变成模块(Module),使用脚本或可拖拽的图,把计算和资源的依赖关系用有向无环图表达出来,然后由系统自动检查依赖关系,自动优化资源重用。
Frame Graph的优势
自动资源管理:系统会自动检测资源的使用情况。如果发现一个Buffer在后面的计算中不再使用,系统会自动将其释放,然后在另一个计算中重用。这个过程叫做Aliasing(别名),能够避免手动管理资源时的错误。
依赖关系检查:系统会自动检查各个Pass之间的依赖关系,确保渲染顺序正确,避免资源冲突。
降低错误率:在GPU上写渲染代码时,一旦出错,可能导致整个系统崩溃(以前甚至可能把操作系统挂掉),Debug起来非常头疼。Frame Graph能够大大降低这种错误的发生率。
Frame Graph的实际应用
Unity的SRP(Scriptable Render Pipeline):Unity的URP(Universal Render Pipeline)和HDRP(High Definition Render Pipeline)都是基于SRP定义的。URP是一个更加简单通用的渲染管线,HDRP是一个加了很多高端效果的高质量渲染管线。这两个管线都使用SRP来定义,这是一个非常好的设计。
实际案例:以《Battlefield 4》为例,它的Frame Graph图非常复杂,即使展开一个很小的部分,也有大量的节点。如果没有Frame Graph这样的工具来管理,这样的Pipeline特别容易出错。
Frame Graph的挑战与未来
当前挑战:
- 接口封装:接口到底怎么封装,如何平衡灵活性和易用性
- 开放程度:到底开放给Graphics Programmer的方式是什么
- 易用性:Technical Artist能否直接使用
未来发展方向:Frame Graph目前还不算很成熟,行业里大家还在探索。但这个思想值得了解:当一个系统足够复杂,连渲染本身变得足够复杂的时候,我们定义了一个图形化的语言,把渲染本身的前后关系和依赖关系表达出来,这样才能够让超复杂的3A级游戏的开发能够被有序地管理起来。
Frame Graph是渲染管线管理的重要发展方向,它代表了从手动管理到自动化管理的转变,是大型游戏引擎开发的必然趋势。
7.7 Render to Monitor
当GPU完成渲染后,需要把渲染结果输出到显示屏幕上。这是游戏引擎渲染的最后一步。当显示器的刷新频率和GPU的输出频率不一致时,会产生画面割裂的情况,这就是屏幕撕裂(Screen Tearing)。
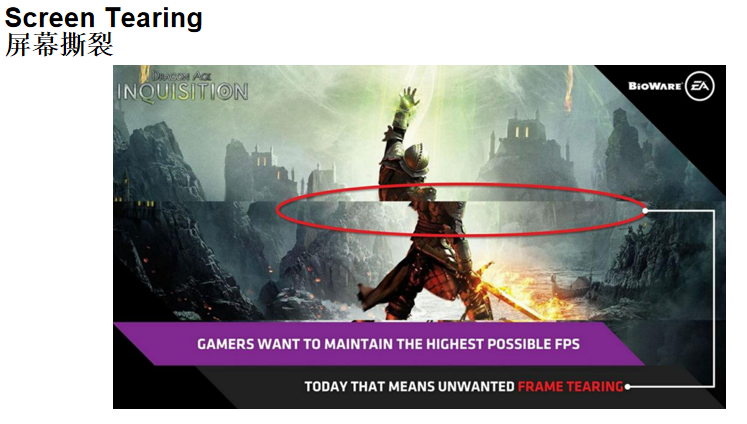
屏幕撕裂(Screen Tearing)
核心问题:在大多数游戏中,GPU帧率会有很大波动。当新的GPU帧在上一个屏幕帧的中间更新时,就会发生屏幕撕裂。画面会出现上下两部分错开的情况,特别是在4K显示器上更容易观察到。
产生原因:
- GPU渲染帧率不稳定:引擎每一帧的渲染时间不一定,复杂场景和简单场景的帧数不同
- 显示器刷新频率固定:显示器以固定的频率(如60Hz,即每16.67ms刷新一次)刷新画面
- 时机不匹配:如果GPU正好在显示器刷新过程中更新了Frame Buffer,显示器就会显示部分旧帧和部分新帧,造成画面撕裂

垂直同步(V-Sync)
核心思想:将缓冲区交换与垂直刷新同步,强制显示器等待GPU完成Frame Buffer的写入,然后等到下一次刷新时才将整个Frame刷新过去,而不是在写入一半时就刷新。
V-Sync的工作原理:必须把Frame Buffer全部写完之后,等到下一次刷新时,整个Frame才刷新过去,而不能在写入一半时刷新。

V-Sync的问题:
- 帧率降低:如果GPU无法在显示器刷新周期内完成渲染,必须等待下一个刷新周期,导致帧率降低
- 卡顿(Stutter):当GPU错过刷新周期时,显示器会重复显示上一帧,导致画面卡顿
- 鼠标延迟:由于需要等待刷新周期,鼠标输入会有延迟,影响游戏体验
V-Sync虽然可以防止撕裂,但会带来帧率降低、卡顿和输入延迟等问题,对于专业玩家来说影响较大。不过随着显示器刷新率越来越高,这个问题的影响在逐渐减小。
可变刷新率(Variable Refresh Rate, VRR)
核心思想:让显示器的刷新频率变成动态可调的,游戏按什么帧率渲染,显示器就按什么频率刷新,实现GPU和显示器的完美同步。
传统V-Sync vs. 可变刷新率:
- 传统V-Sync:显示器以固定频率刷新,GPU必须等待刷新周期,导致延迟和卡顿
- 可变刷新率:显示器刷新率动态跟随GPU渲染帧率,GPU完成一帧就立即显示,无需等待
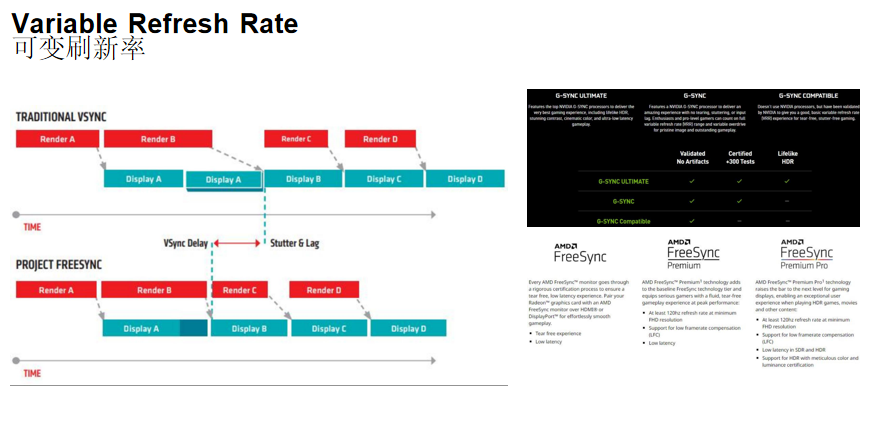
NVIDIA G-SYNC:
- G-SYNC ULTIMATE:最高级别,经过验证无伪影,通过300+项测试,支持HDR
- G-SYNC:使用NVIDIA G-SYNC处理器,无撕裂、无卡顿、无输入延迟,支持完整可变刷新率范围和可变过驱动
- G-SYNC Compatible:不使用NVIDIA处理器,但经过NVIDIA验证,提供基本的可变刷新率体验
AMD FreeSync:
- AMD FreeSync:基础级别,经过严格认证,确保无撕裂、低延迟体验
- AMD FreeSync Premium:至少120Hz刷新率(最低FHD分辨率),支持低帧率补偿(LFC),低延迟
- AMD FreeSync Premium Pro:至少120Hz刷新率(最低FHD分辨率),支持LFC,SDR和HDR低延迟,支持HDR并经过精密的颜色和亮度认证
可变刷新率技术完美解决了屏幕撕裂和V-Sync带来的卡顿问题,是现代游戏显示技术的重要发展方向。NVIDIA和AMD都在大力推广各自的VRR技术,为玩家提供更好的游戏体验。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

