19.网络游戏的进阶架构
19.1 位移同步
位移同步本质上是在做 复制(Replication):把“操作者视角里发生的运动”,以可接受的延迟与带宽成本,在其他玩家客户端上复现出来。
难点不在“把位置发过去”,而在“发过去以后看起来像真的”。因为网络链路不仅有延迟(Latency),还有抖动与丢包:对方已经跑到前面了,你这边可能还在显示他几百毫秒之前的位置。
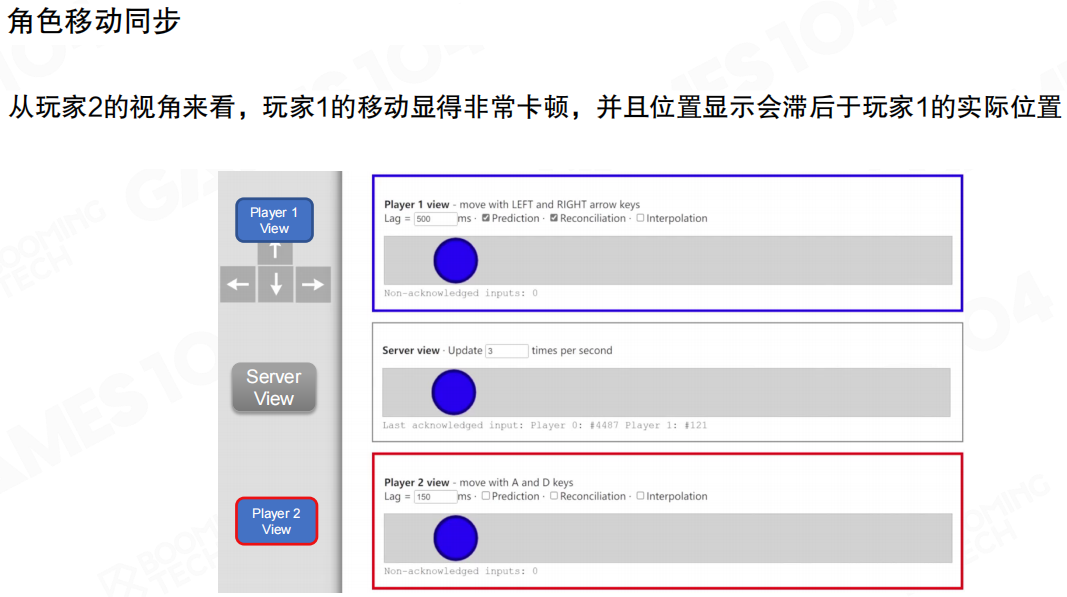
从旁观者视角(Player2)看,最朴素的“收到一个包就更新一次位置”会导致两个问题:
- 卡顿:位置更新是离散的,网络一抖就更明显。
- 滞后:操作者(Player1)→服务器→旁观者的两跳延迟叠加,旁观者看到的永远是“过去”的你。
这也是为什么位移同步要单独拎出来:它直接决定了“别人在你屏幕里是否像活的一样”。
插值与外推
工程上最常见的手段是两类插值:
- 内插(Interpolation):用“已知的两个状态”去补中间状态,强调稳定与平滑。
- 外推(Extrapolation):根据历史状态预测未来,强调减少滞后,但风险更高。
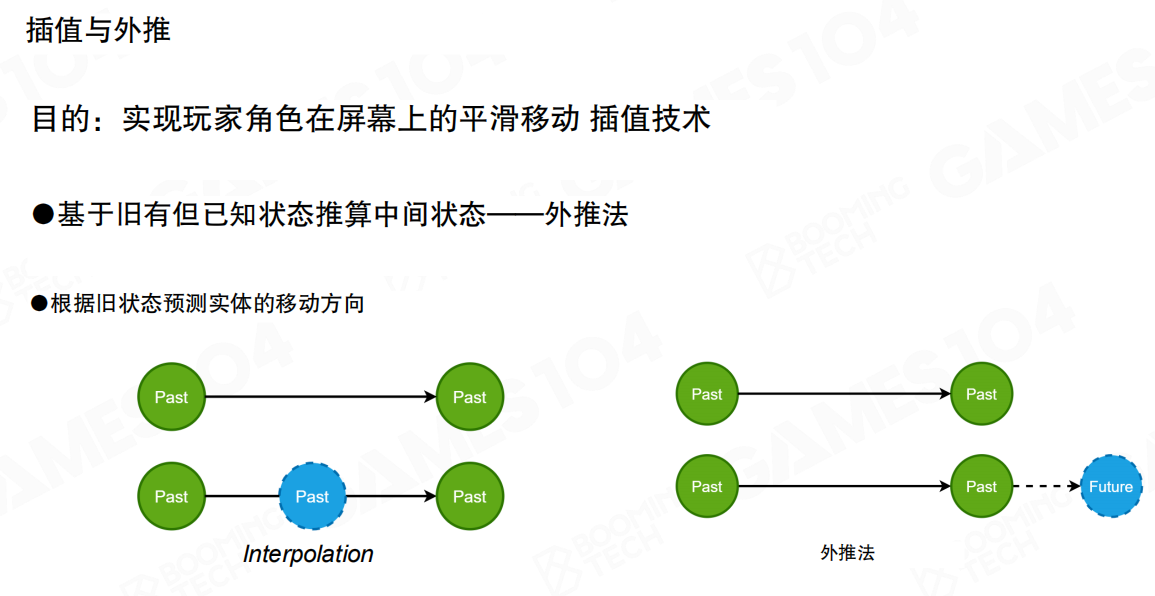
内插
内插的直觉很简单:服务器不断给你一串离散的状态点(位置/朝向/速度)。你不必立刻把最新点渲染出来,而是在相邻两点之间做插值,让运动在屏幕上连续。
内插要想“稳”,关键是要有足够的控制点。一个常见技巧是 延迟渲染:把收到的包先放进缓冲区(buffer),人为引入一个插值偏移(offset),让显示时刻故意落后于真实时间一点点,这样你在渲染 (S_1\rightarrow S_2) 的时候,(S_3) 往往已经到手了。
代价也很明确:你用平滑换来的是“更晚一点看到对方的真实位置”。
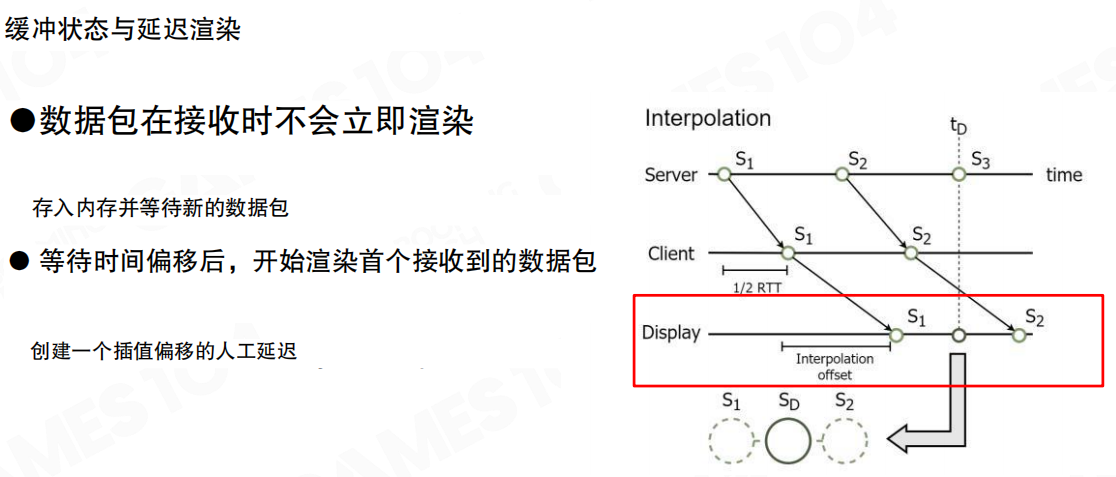
当缓冲区与偏移设置合理时,旁观者看到的复制角色会明显更顺滑,抖动也更容易被“抹平”。
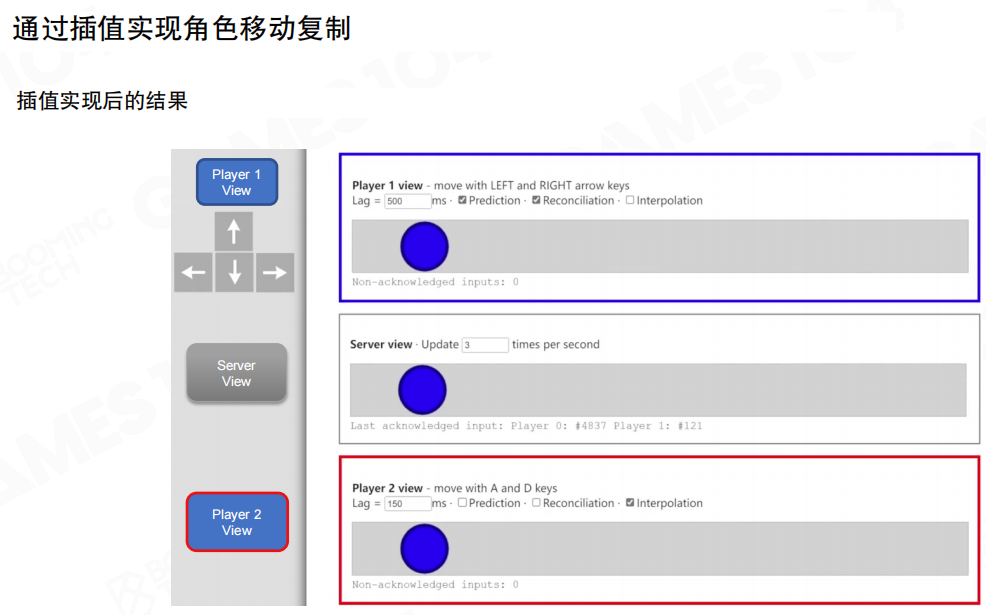
不过内插也有边界:它让“各端看到的世界”差异更大。在高速载具或高对抗场景里,这种差异会变成判定争议(到底撞没撞、到底有没有擦到)。

外推
外推的思路更激进:既然我拿到的一定是“过去的状态”,那我就根据历史估计“此刻你应该在哪”。只要对延迟有基本估计,外推就能在视觉上追近真实位置。
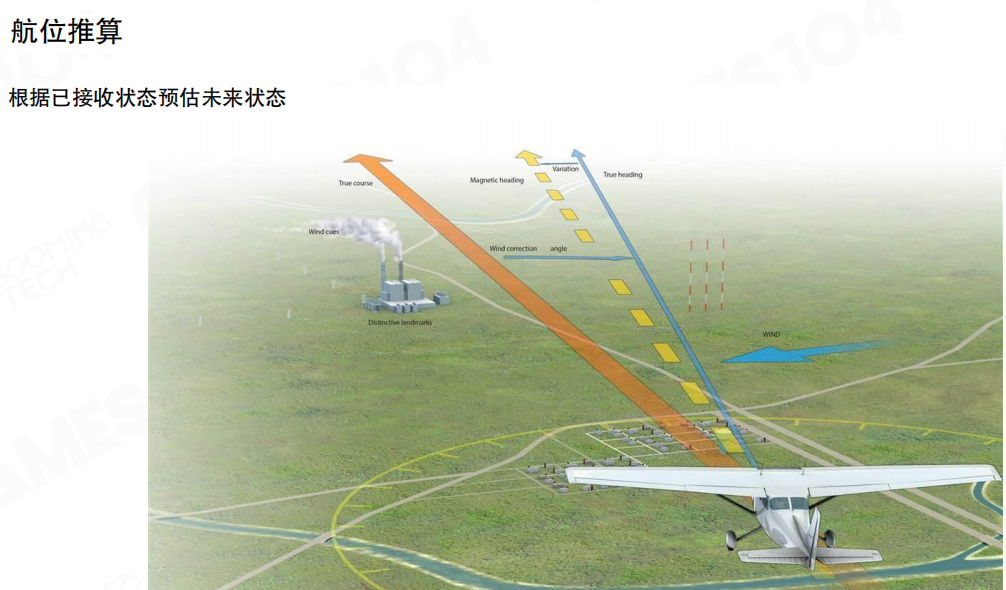
外推在很多领域都有经典原型:航位推算(Dead Reckoning)。例如飞机/船只在缺少持续定位时,根据已知位置、速度、航向以及环境扰动(风、洋流)去估计当前位置。
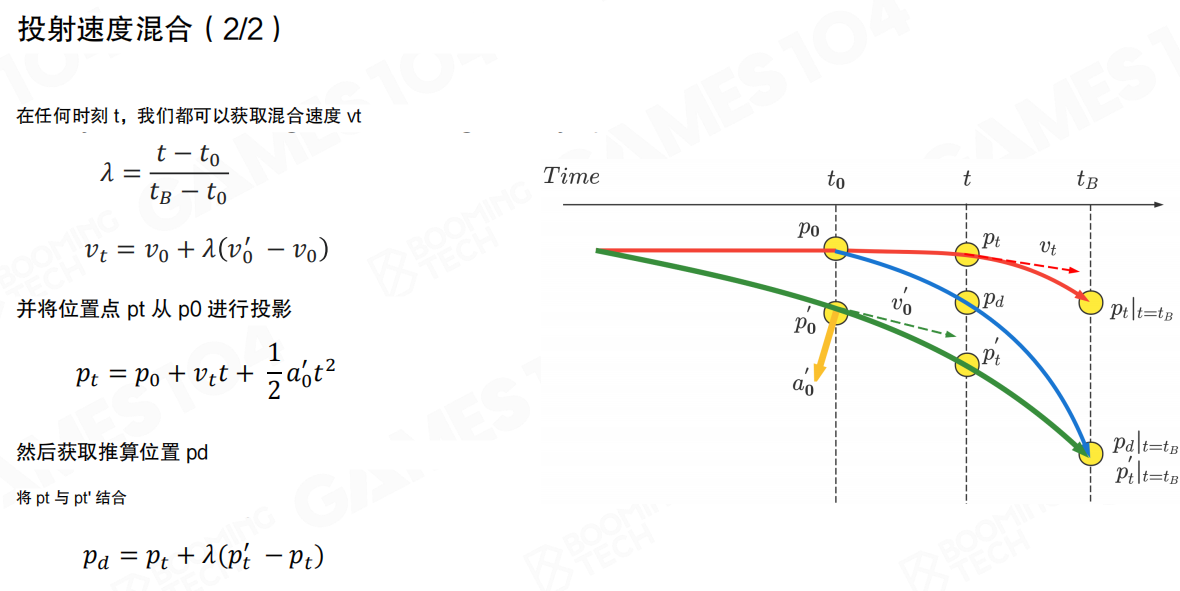
投射速度融合
把外推落到游戏里,一个常见方法是 投射速度融合(Projective Velocity Blending,PVB)。它的目标不是“立刻纠正到服务器状态”,而是在一个固定的融合时长内,把复制体平滑拉回服务器给出的轨道。
假设在 (t_0) 时刻,复制体的状态为位置 (p_0)、速度 (v_0)、加速度 (a_0)。同时我们收到服务器同步的权威状态:位置 (p’_0)、速度 (v’_0)、加速度 (a’_0)。如果在一段时间 (t) 内外界没有额外干扰,则服务器预测的目标位置可以写成:
\[
p’_t = p’_0 + v’_0 t + \frac{1}{2} a’_0 t^2
\]
我们的目标是在融合截止时刻 (t_B) 附近,平滑地到达 (p’_{t_B})。
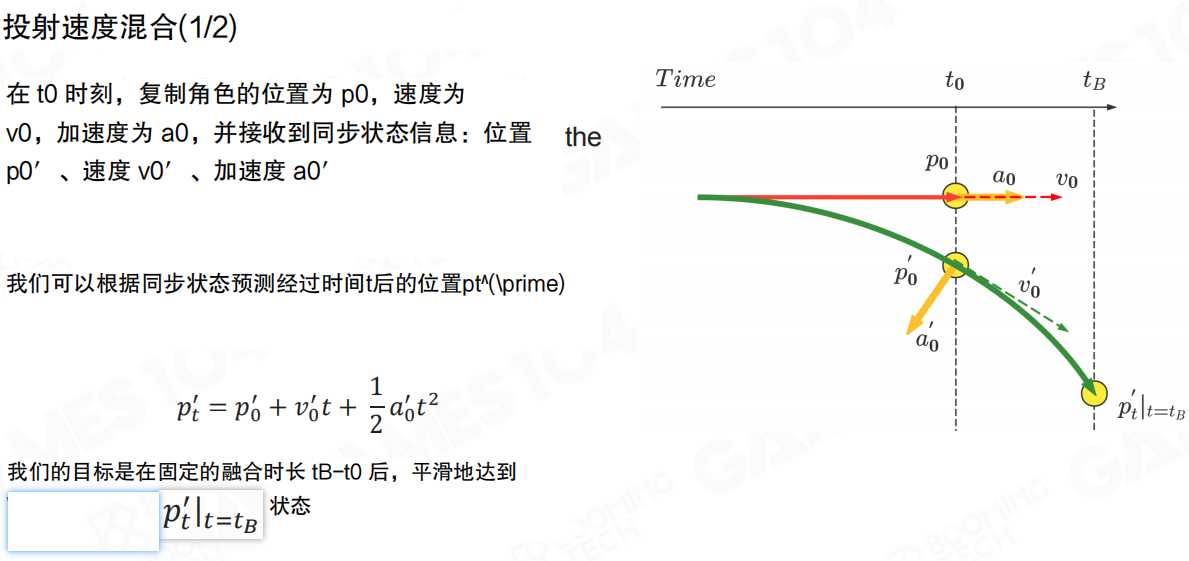
PVB 的一个“简单但好用”的做法是先对速度做线性融合,再用融合后的速度去投影位置。令
\[
\lambda = \frac{t - t_0}{t_B - t_0},\quad
v_t = v_0 + \lambda\left(v’_0 - v_0\right)
\]
然后从 (p_0) 出发用 (v_t) 做一次投影(这里沿用图中的写法):
\[
p_t = p_0 + v_t t + \frac{1}{2} a’_0 t^2
\]
最后再把投影点 (p_t) 与目标点 (p’_t) 做一次线性融合,得到显示用的位置 (p_d):
\[
p_d = p_t + \lambda\left(p’_t - p_t\right)
\]
需要注意:这种做法强调“看起来平滑、能追上”,并不严格遵循动力学;它更像是一个带约束的插值器。
碰撞问题
外推最容易翻车的地方在碰撞。因为外推依赖“上一份快照/上一段速度”,但碰撞往往意味着运动模型突然改变:速度方向瞬间反转、速度大小骤降、或者被物理约束卡住。
这会导致复制体在客户端继续“惯性前进”,甚至出现穿插;而物理系统检测到穿插后可能施加很大的分离力,于是你看到的就不是“轻轻擦碰”,而是“被弹飞”。

一种典型过程可以按阶段理解:
- 阶段一:碰撞开始,复制体仍沿外推轨迹前进。

- 阶段二:复制体继续运行,但外推基于“最后一帧快照”,对碰撞后的真实减速/反弹没有感知。

- 阶段三:最终收到一个“停止/转向”的权威快照,但复制体可能因为先前的外推积累了较大速度,于是出现明显不自然的分离或回弹。

物理融合
一种常见的工程解法不是“坚持外推到底”,而是 切换权重:在碰撞窗口内,把控制权更多交给本地物理(Local Physics);碰撞结束后,再逐渐回到外推/同步结果,避免穿插与分离力爆炸。

使用场景
把两种方法放回“玩家体验”里看,差异会更清晰:
- 内插更常用于角色:角色移动往往具有高不确定性与高加速度特性(急停、急转、瞬时位移),用外推容易预测错;内插虽然更滞后,但更稳。

- 外推更常用于载具:车、船等运动更接近真实物理模型,速度/加速度变化相对连续,外推预测更可靠;典型场景包括竞速游戏、载具系统等。

真实项目里通常不会只选一个:例如载具用外推、角色用内插;当数据不足时再启用外推兜底,或者对不同对象使用不同的缓冲与纠偏策略。

19.2 命中判定
命中判定(Hit Registration)是射击类网络游戏的核心体验之一:你按下开火的那一刻,系统需要给出一个所有人都接受的结论——这枪到底算不算命中。
难点在于:你看到的世界并不是服务器此刻的世界。网络延迟与插值让敌人的位置滞后,等你“看见、反应、开枪”,链路里已经经过了多次等待与缓冲。
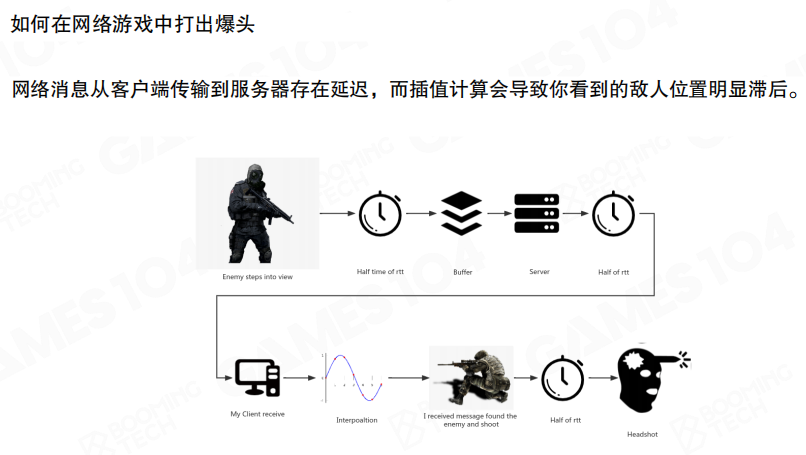
敌人位置
当我们讨论“爆头”,首先要回答一个更基础的问题:你此刻瞄准的那颗头,在服务器上到底在哪?
从客户端视角看,敌人位置往往是经过内插之后的“显示位置”;而服务器维护的是更接近实时的权威位置。两者之间天然存在偏移。

这会直接带来“该往哪打”的困惑:你对着屏幕里的人开枪,服务器却可能认为对方已经移动到了别处(甚至已经进了掩体)。
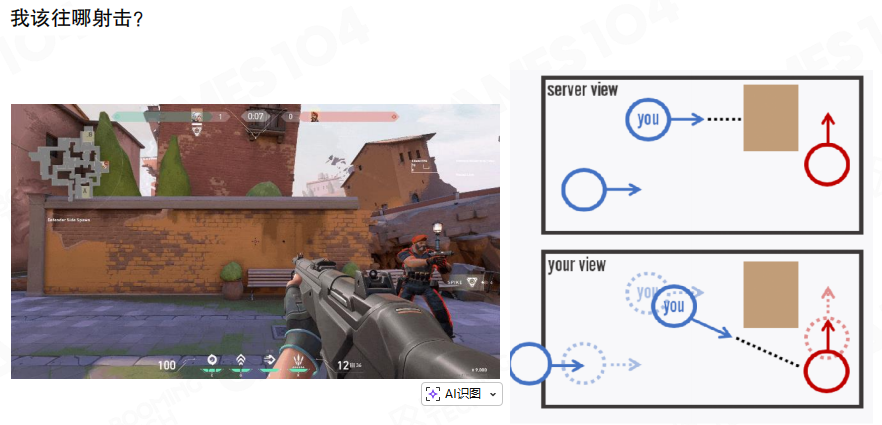
共识
严格来说,在延迟存在的前提下,“开枪瞬间敌人绝对位置”并没有一个所有人都能同时观测到的绝对真相。命中判定的目标更贴近分布式系统:让所有玩家对“是否命中”达成共识(Consensus)。
主流实现大致分两类:客户端侧判定与服务器侧判定。

客户端侧判定
客户端侧命中检测(Client-Side Hit Detection)的思想很直观:以射击者本地看到的结果为准。玩家开枪后,客户端基于本地的敌人位置与弹道模型直接做命中检测,然后把“命中事件”上报给服务器。
它最大的优点是体验好:反馈更即时、瞄准更“跟手”,也能显著减轻服务器压力。

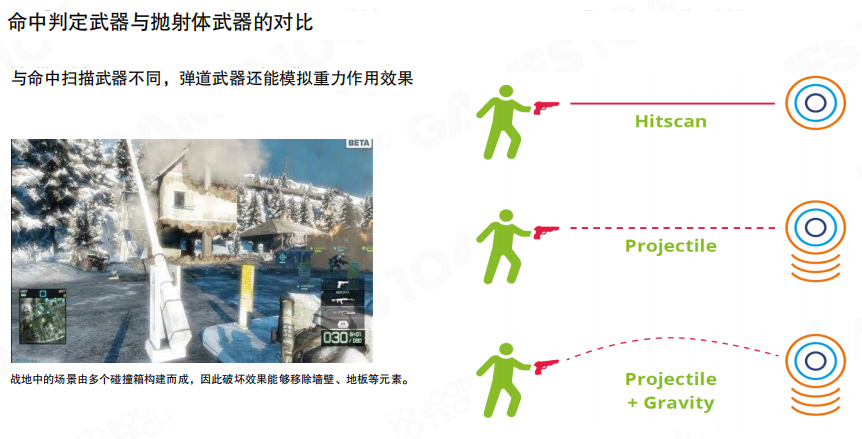
不同武器会对应不同的弹道模型:
- 命中扫描(Hitscan):射线瞬时命中,典型用于步枪/手枪。
- 抛射体(Projectile):子弹有飞行时间,典型用于火箭弹、榴弹。
- 抛射体 + 重力:带下坠的弹道,更贴近真实射击。
弹道越复杂,越倾向把计算放在客户端先做(至少先做),否则服务器成本会迅速变高。
但“客户端说命中就命中”显然不安全。常见折中是:客户端先判定命中,服务器再做轻量验证(verification),例如检查射击起点是否合理、命中点是否可信、射线是否穿墙等。

问题在于:验证越严格越像重新做一遍判定,服务器就越重;验证越粗糙,就越依赖客户端的诚实与反作弊体系。
一些游戏会引入“必须猜测”的成分:例如把服务器侧可接受的命中范围放大,只要打进一个较大的区域就视为命中,从而在体验与安全之间做权衡。
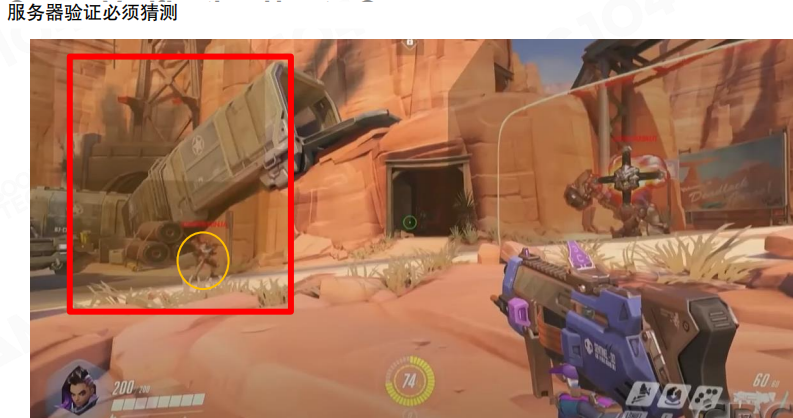
从安全视角看,客户端侧方案的风险主要集中在两类:
- 伪造命中事件:客户端/网络包被篡改,伪造“命中某人”的上报。
- 延迟操控:通过人为制造网络不稳定,获得不合理的时间窗口(例如延迟开关)。

服务器侧判定
服务器侧命中判定(Server-Side Hit Registration)的优势是权威与安全:服务器掌握完整世界状态,也更容易做统一裁决。
但它的第一道坎是:射击者并不知道服务器上“此刻”的目标位置。若直接用服务器的当前状态做检测,就会出现射击者明明瞄准到了却被判定未命中——特别是目标在移动、或在掩体边缘时。

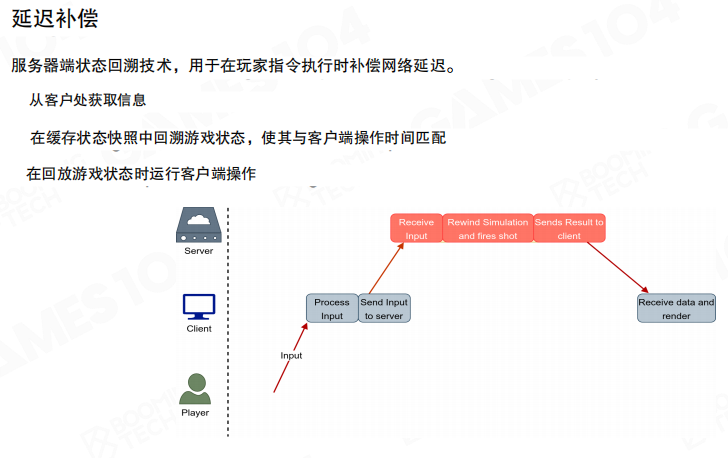
延迟补偿
解决这个矛盾的核心思路是 延迟补偿(Lag Compensation):服务器收到“开枪”消息后,不用“当前世界”去算命中,而是回到射击者开枪那一刻应当看到的历史世界。
这要求服务器保存一段时间的历史状态快照(或者至少保存关键对象的历史位置),以便在收到射击事件时执行回溯计算。
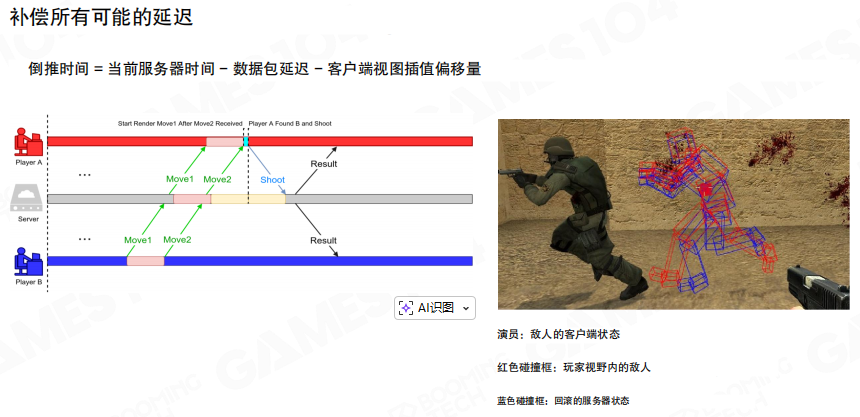
回溯的时间点可以理解为:
\[
t_{rewind} = t_{server} - \text{网络延迟} - \text{客户端插值偏移}
\]
其中“客户端插值偏移”对应位移同步里为了平滑而引入的延迟渲染 offset。服务器把目标与场景回放到 (t_{rewind}),再在那个历史状态上执行射线/弹道检测,最后把结果广播给所有客户端。
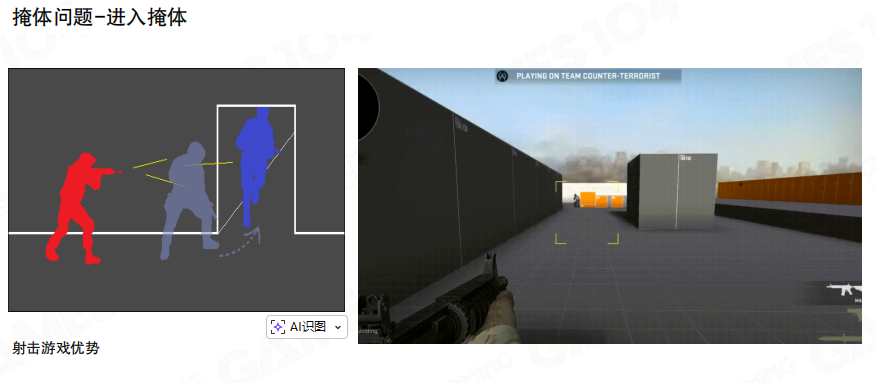
掩体优势
即使做了延迟补偿,掩体(cover)依旧是争议高发区。典型有两种不对称场景:
- 进掩体:你觉得自己已经躲进去了,但对方视角里你还没进去,于是你被击中。
- 出掩体:你从掩体后探头时,你先看见对方,而对方晚一点才看见你,形成短暂的先手窗口。
这类不对称通常被称为窥视者优势(Peeker’s Advantage),也常被叫作“进攻者优势/探头优势”。
反过来,当你从掩体撤回去时,旁观者可能仍在显示你上一刻的位置,于是出现“看起来已经躲回去但还是被打中”的现象。

前摇与视觉补偿
除了算法,设计层也常用两类办法给同步争取时间:
- 动作前摇(Startup Frames):把攻击/关键动作拆成前摇—生效—后摇,前摇能覆盖一部分网络延迟,让判定更稳定。
- 本地视觉补偿:客户端可先做本地命中检测,立即播放血液/命中特效以增强反馈;但所有永久性效果(例如扣血、击杀结算)必须以服务器确认为准。


19.3 基础MMO架构
大型多人在线游戏(Massively Multiplayer Online Game,MMOG)的关键在于”规模“:大量玩家同时在线,协作、竞争与社交行为被持续地放大。它不是某个固定玩法类型(例如 MMORPG),更像一类”承载多人在线世界”的系统形态。

最早期的网络游戏形态非常朴素,但已经具备了”多人共享同一环境”的雏形:简单的联网对战,以及以文字为载体的多人角色扮演(MUD 一类)。形态变了,核心诉求并没有变:让玩家在同一个虚拟世界里感知到彼此。
到了现代,大型多人在线游戏的形态更丰富:RPG 之外,FPS、RTS 等也能具备”海量在线”的规模属性。玩法的多样化,直接带来系统层的复杂化。
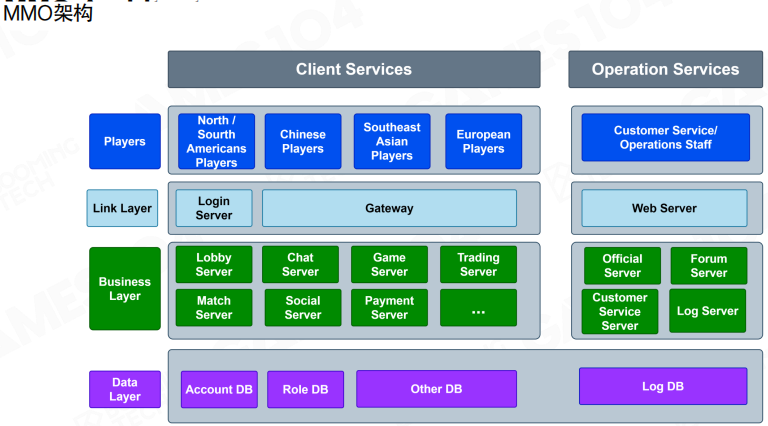
子系统
如果把 MMO 看成一个持续运行的小型社会,那么它往往需要一组相对独立、边界清晰的子系统来支撑:
- 用户与账号:注册、登录、风控、封禁等。
- 匹配与组队:把合适的玩家组织到一起(不仅考虑段位,也会考虑延迟、队伍等)。
- 交易与经济:市场、拍卖、邮件、货币与道具流转,常常带有现实世界的经济属性。
- 社交:聊天频道、好友、公会、公告等。
- 数据与运营:日志、统计、回溯、客服处理等。

分层架构
一个常见的 MMO 服务器端分层可以简化为三层:
- 连接层(Link Layer):管理用户连接、登录与网关。
- 业务层(Business Layer):大厅、战斗、社交、交易、匹配等具体业务服务。
- 数据层(Data Layer):账号、角色、日志等数据的持久化存储。
这样的拆分并不追求”唯一正确”,但它能让关键边界更清晰:谁负责接入与防护、谁负责业务、谁负责数据。
连接层
连接层最直观的两个组件是 Login Server 与 Gateway。
- Login Server:负责登录验证(实践中常见基于 HTTPS 的加密通道),完成身份校验后发放会话凭证(token)。
- Gateway:玩家只与网关通信,网关再转发到内部的业务服务。它的价值在于隔离内外网:协议校验、限流、防护与一些通用编解码逻辑,优先放在网关收敛处理。
网关往往是可水平扩展的:玩家越多,网关实例越多;它更像统一的”接入入口”,而不是承载业务逻辑的地方。

大厅
玩家通过连接层进入游戏后,通常会先到 大厅(Lobby):这是一个用来“聚集与等待”的地方。
它可以是一个真实的主城场景,也可以是纯 UI/菜单式的”虚拟大厅”。大厅的核心作用是把玩家管理在一个可控的缓冲区里:等待匹配、组队、切换模式,以及与其他玩家产生社交互动。

角色服
大型多人在线游戏的玩家数据通常非常大:账号信息、角色属性、背包、邮件、任务进度等都会不断增长。为了避免“业务服务各存一份导致数据四散”,常见做法是把核心玩家数据集中到 角色服务器(Character Server)管理。
业务服务通过角色服读写玩家的权威数据:例如装备变更、道具增减、邮件附件领取等。这样做的好处是边界清晰,代价是角色服会成为重负载服务,需要更谨慎的扩展与容错设计。
交易
交易系统(Trading System)往往带有较强的“金融属性”。它需要处理:
- 一致性:物品与货币的增减不能出错。
- 原子性:一次交易要么完整成功,要么完整失败。
- 可回滚:断线、崩溃等异常情况下,能够恢复到一致状态。
这类系统通常会做得更”保守”:宁愿牺牲一点吞吐,也要保证账目清楚。

社交
社交系统(Social System)包含聊天频道、好友、公会等。它看起来像”功能模块”,但并发一上来就会变成稳定性挑战:发消息、拉黑、分频道、小队语音/文本、公告推送……都需要独立的服务与限流策略支撑。
匹配
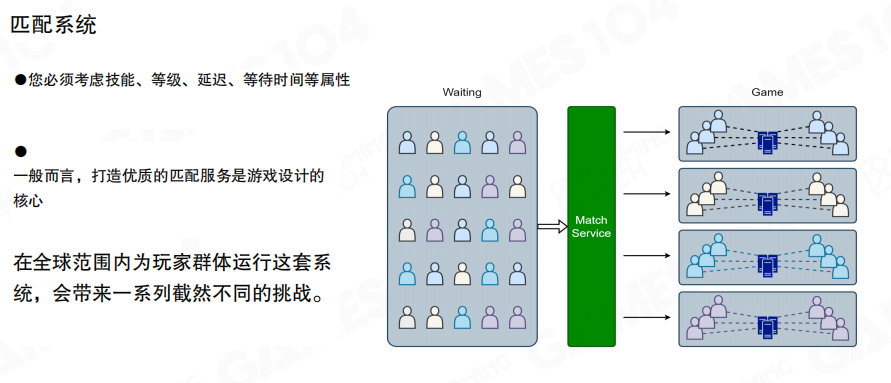
匹配系统(Matchmaking)决定玩家体验的下限。它至少要考虑两件事:
- 实力接近:用段位/评分体系保证对局相对公平。
- 网络接近:尽量把延迟相近的玩家放在一起,降低体验差异。
当队伍、跨区、开黑等因素加入后,匹配策略会快速复杂化,因此它通常会作为一个独立的核心服务长期演进。
数据存储
在线世界是”持续存在”的:玩家可以下线,但服务器不能停;数据随时产生,且必须可追溯、可检索。常见的三类存储各有所长:

- 关系型数据库:结构稳定、事务能力强,适合账号、订单、核心资产等”强一致”数据。

- 非关系型数据库:结构灵活、写入与扩展更友好,适合日志、部分状态数据、画像与分析类数据。

- 内存数据库:用更高的读写性能换取持久性成本,适合缓存、排行榜、会话与部分中间态数据管理(例如 Redis 一类)。

分布式
当玩家规模增长时,单体服务很快会碰到资源与性能的拐点:吞吐下降、响应变慢、错误率上升。把系统拆成分布式是常见的路径:服务可以横向扩展,按需增减实例。
分布式系统的本质是”把组件放到不同机器上协同工作”,这会引入新的工程问题:组件间通信、状态一致、故障隔离与恢复等。
分布式常见挑战包括:
- 数据访问互斥:并发读写带来竞争条件。
- 幂等性:消息重试与乱序时,重复请求不能破坏状态。
- 部分失败:某个服务挂掉是常态,需要隔离与降级。
- 不可靠网络:延迟、抖动、丢包会持续存在。
此外,一致性与共识问题往往贯穿全局:一个小故障如果没有被及时隔离,可能在链路中放大并扩散。

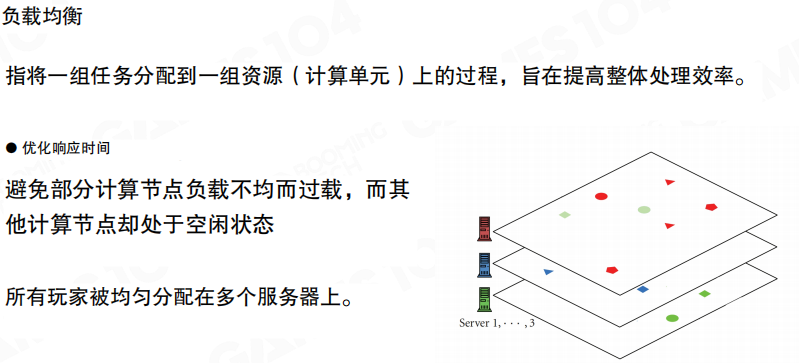
负载均衡
负载均衡(Load Balancing)的目标是把请求/玩家均匀分配到多个服务器上,避免某个节点过载而其它节点空闲。
一致性哈希
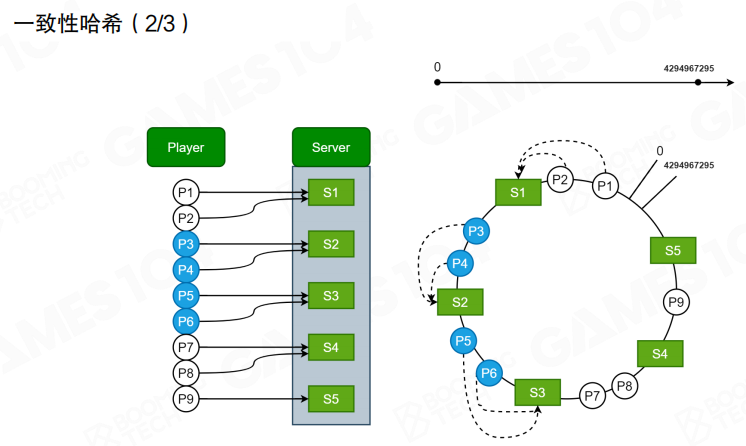
假设角色服有多个实例,如果每次都”挨个问一遍玩家属于谁”,RPC 开销会非常大。更常见做法是用 一致性哈希(Consistent Hashing)做静态映射:给 玩家 与 服务器 都计算哈希值,映射到一个环上,按规则(例如顺时针找到最近的服务器)决定归属。

直观上,它解决了”增删节点时的大规模迁移”问题:只会影响到环上一段连续区间的玩家。
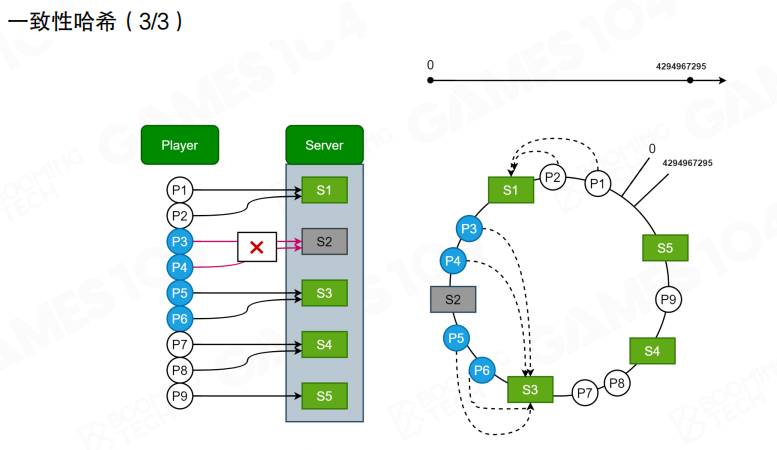
当某个服务器下线时,与它相邻的一段玩家会顺延到下一个服务器;当新增服务器时,也只会切走一段区间的玩家。
虚拟节点
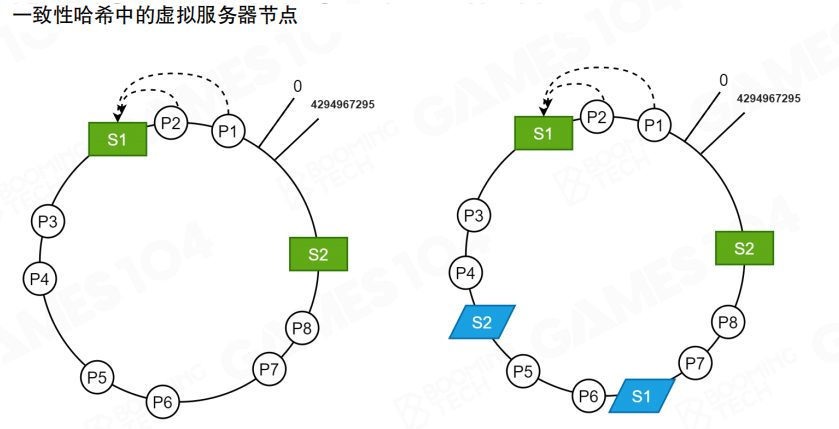
一致性哈希的效果很依赖哈希分布:如果服务器节点太少或分布不均,负载仍可能倾斜。常见补救是引入 虚拟节点(Virtual Nodes):让每台真实服务器在环上对应多个虚拟位置,从而把区间切得更细,整体更均匀。
服务治理
当系统里有大量服务实例时,另一个问题会变得突出:服务怎么被发现、怎么被管理。典型做法是引入服务注册中心(例如 ZooKeeper、etcd),把”服务地址与状态”集中管理。
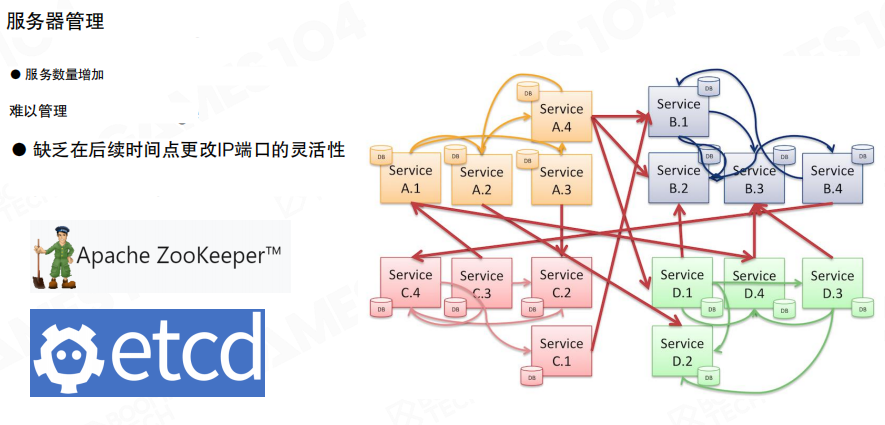
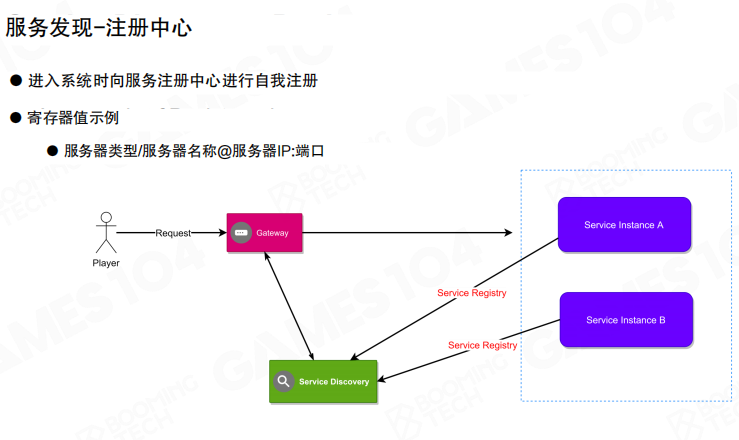
服务启动时向注册中心注册(类型、名称、地址等);网关或其它服务通过注册中心找到可用实例。
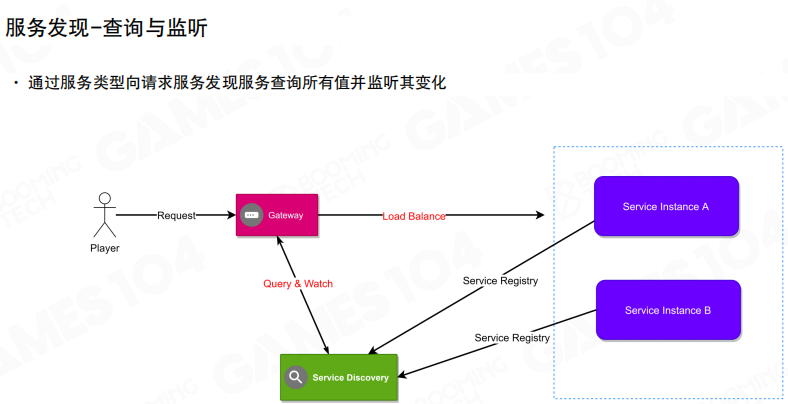
注册中心还会提供 查询与监听(Query & Watch):当实例扩缩容或地址变化时,依赖方能够及时更新路由,并在入口处完成负载均衡。
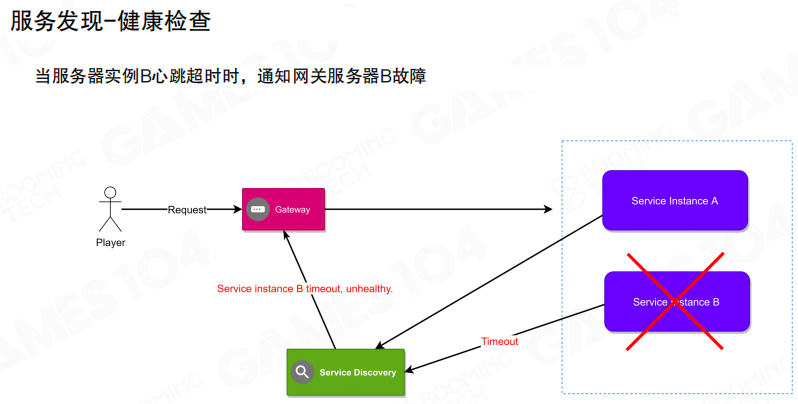
最后是 健康检查:当某个实例异常(超时/不可达)时,注册中心触发通知,入口侧把流量切走,避免故障扩散。
19.4 宽带优化
带宽优化(Bandwidth Optimization)看起来不像“玩法”那么直观,但它会直接决定两件事:成本与体验。
- 成本:带宽通常按用量计费(例如移动端、云服务器),玩家规模越大,费用增长越快。
- 体验:数据量过大容易触发拥塞,带来排队与重传,表现为延迟上升、抖动变大;在极端情况下,网关/运营商侧还可能主动限速或断开连接。

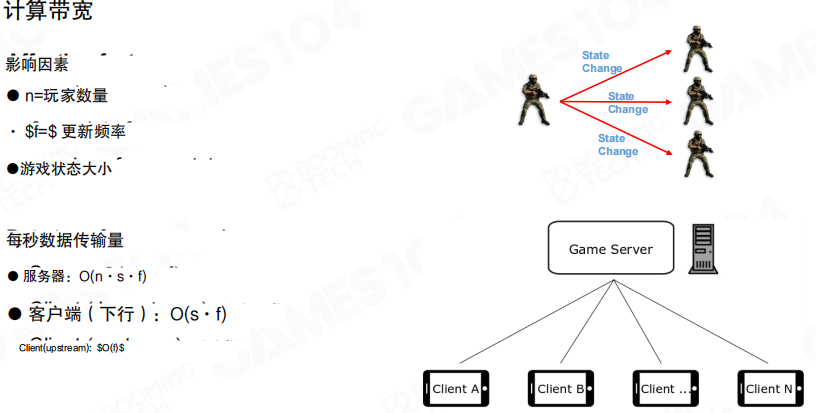
带宽估算
把问题抽象成三个变量更容易算清楚:
- (n):玩家数量(或更准确地说:一次同步中“相关对象”的数量)。
- (f):更新频率(每秒同步多少次)。
- (s):单次同步的数据大小(一个对象的状态包大小)。
每秒传输量可以粗略写成:
- 服务器侧(下行):(O(n \cdot s \cdot f))(如果把所有对象广播给所有人,会进一步接近 (O(n^2)) 的增长)。
- 客户端侧(下行):(O(s \cdot f))(关注对象越多,实际也会随 (n) 放大)。
这里的直觉很重要:在 MMO 场景里,规模一上来,数据是乘法增长,所以必须从 (n)、(f)、(s) 三个方向同时下手。
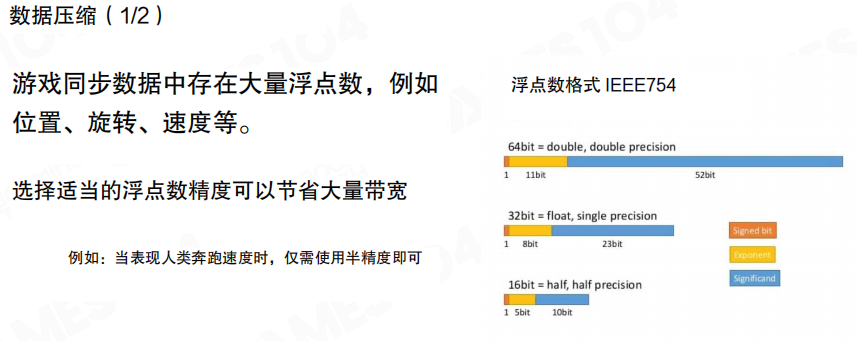
数据压缩
同步数据里常见大量浮点数(位置、旋转、速度等)。压缩不一定要上复杂算法,最常见、性价比也很高的一类做法是 量化(Quantization):用更低精度的数值表达“够用”的状态。
例如玩家位置如果不需要达到 double 精度,float 甚至 half precision 就可能足够;或者把浮点数转成定点数,用固定的单位(厘米/毫米)表达坐标。
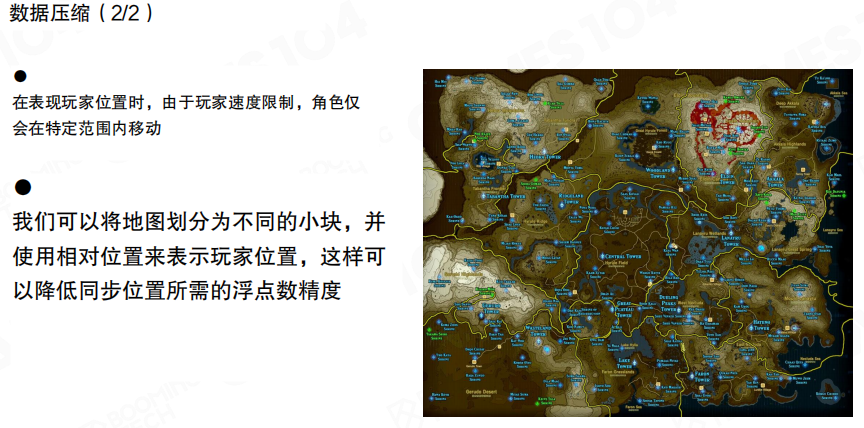
量化通常会搭配空间分区一起做:把地图划分为较小的块,在块内用”相对坐标”表达位置。这样既减少了数值范围,也能降低对精度的要求。
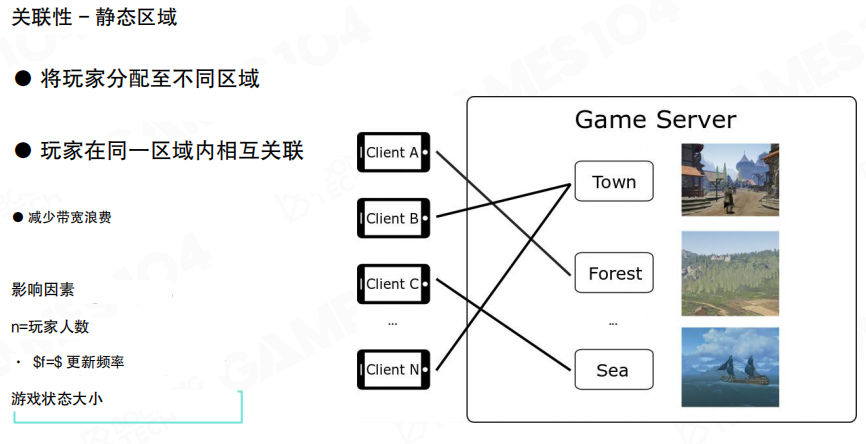
对象关联性
另一条更“根本”的带宽优化思路是:不要同步无关对象。
最朴素的实现是把所有状态更新都发给所有客户端,但它的复杂度接近 (O(n)) 甚至 (O(n^2)),在玩家数量上来后不可持续。大多数网游最终都会引入”关联性”过滤。

静态区域
一种简单有效的方式是把世界拆成若干静态区域(Zone/Region):玩家在同一区域内相互关联,跨区域默认不互相同步,减少大量无意义的广播。
关注区域(AOI)
开放世界里不一定适合用硬边界的区域,这时更常用 关注区域(Area of Interest,AOI):以玩家为中心,只同步其一定范围内可见/可交互的对象。

AOI 最直接的实现是“半径查询”:计算玩家与其他对象的距离,距离小于阈值则认为相关。实现简单,但当玩家很多时会退化为 (O(n^2)) 的计算量。
例如单个区域约 1000 名玩家、每秒 20 次更新,距离计算量约为:
[
1000 \times 1000 \times 20 = 20{,}000{,}000
]
这还不包含后续的序列化与网络发送开销。

空间网格
更常见的工程实现是”空间网格”:把世界按 ((x, y)) 切成规则网格,对象映射到格子里;查询 AOI 时只需要检查玩家周围少量格子的对象集合。
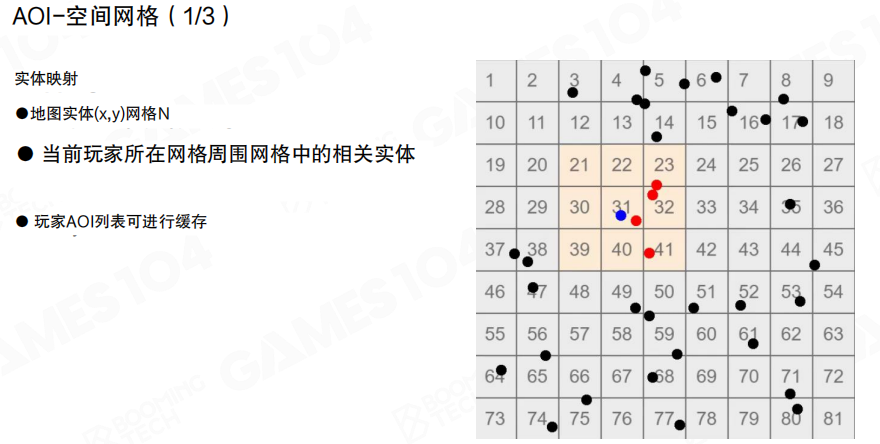
网格法通常用事件驱动维护”观察列表”(observed list):当对象进入/离开某些格子时,触发进入(Enter)/离开(Leave)事件,增量更新 AOI 列表,而不是每帧全量重算。
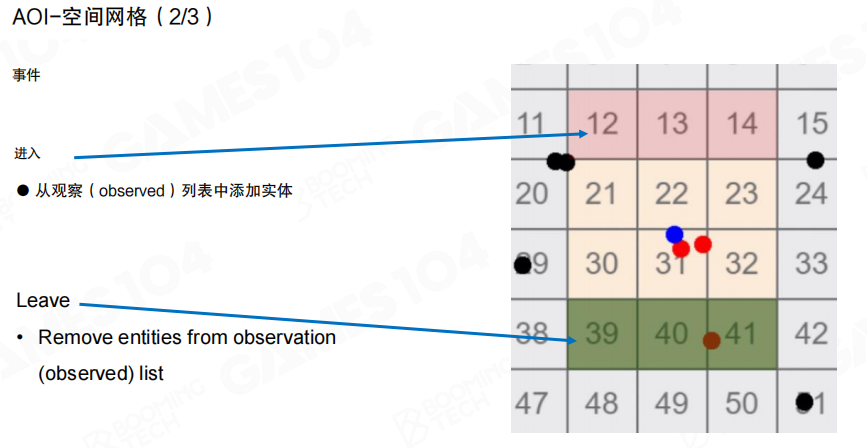
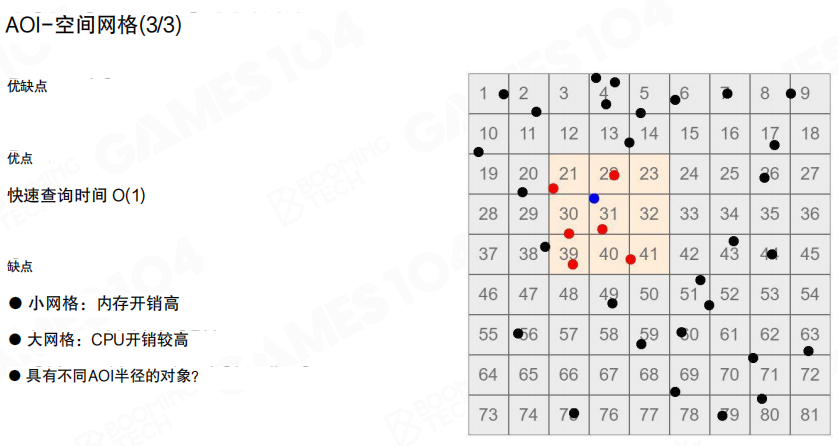
网格法的优点是查询接近 (O(1)) 且实现稳定;代价在于格子尺度的选择:
- 格子太小:格子数量多,维护开销与内存开销变大。
- 格子太大:每个格子内对象太多,查询又会变慢。
同时,如果不同对象需要不同 AOI 半径,也需要额外的适配策略。
十字链表
除了网格,还可以用更“数据结构化”的方式:十字链表(Sweep and Prune 相关思想)。
核心做法是分别在 X 轴与 Y 轴上维护对象的有序列表(双向链表或其它有序结构),并记录每个对象在列表中的位置。
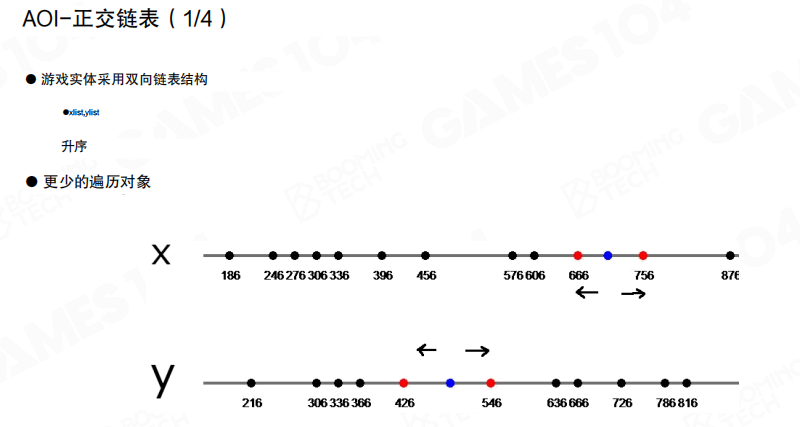
要找 AOI 半径内的对象时:
- 在 X 列表里向左/向右扫描到“超出范围”为止。
- 在 Y 列表里做同样扫描。
- 最终用”同时满足 X 范围且满足 Y 范围”的交集作为候选对象集合。
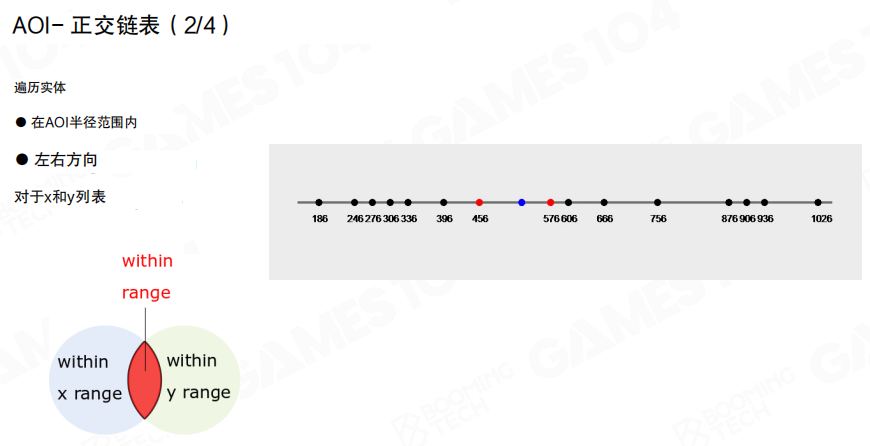
更进一步的实现会把”进入范围/离开范围”做成类似触发器的事件:对象移动时只会引发局部的顺序调整与事件派发,适合用来维护 AOI 观察列表。
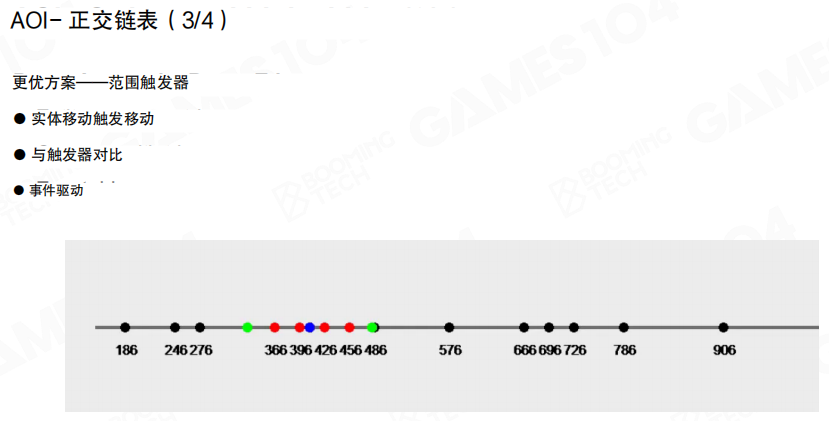
十字链表的优势在于内存友好、可支持不同 AOI 半径;但在对象高速、大幅移动时,维护有序结构的成本会上升。

潜在可见集(PVS)
对于一些空间结构强、可见性可预计算的游戏,还能用 潜在可见集(Potentially Visible Set,PVS)做“更粗一层”的剔除:先确定玩家所在区域可能看到的对象集合,再在集合里做 AOI/精细过滤。
赛车一类场景就很典型:赛道拓扑明确,玩家高速度移动但可见范围相对可控,PVS 可以有效减少同步对象规模。

更新频率
最后一类常用策略是调整 更新频率:距离玩家越近的对象,更新越频繁;越远的对象,更新越稀疏。这样可以在不显著影响感知的前提下,降低带宽占用。
结合前面三个变量 (n, f, s) 来看,本质就是把 (f) 做成与距离相关的函数:近处用更高频率保证交互与命中判定,远处用更低频率依赖插值/外推保持观感平滑。

19.5 反作弊
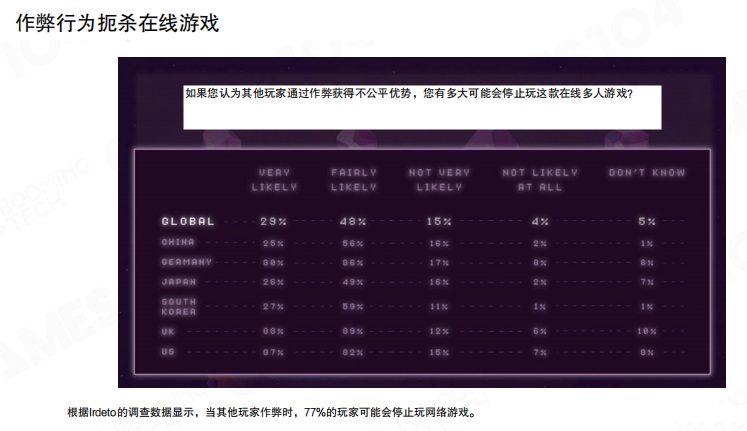
在线游戏里,作弊并不是”少数人的小动作”,而是会直接破坏匹配公平性与社区氛围,最终反噬留存与收入。图里给了一个很直观的结论:当玩家确认环境里存在作弊时,相当一部分玩家会倾向于退出。
威胁面
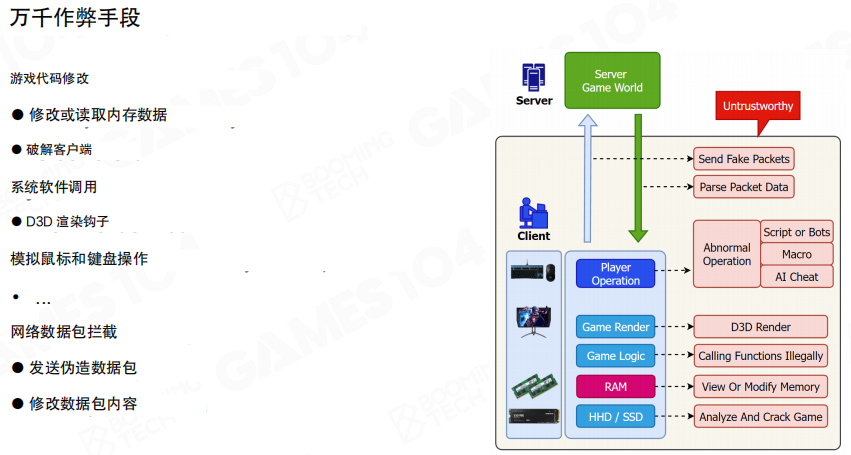
反作弊的第一原则是:客户端不可信。任何发生在玩家机器上的事情,都有被篡改的风险。
从攻击面看,作弊的手段非常多样,可以粗略分成几类(图中给了典型例子):
- 客户端篡改:修改本地代码、资源或配置,绕过本地校验。
- 进程与内存层:对运行中的进程做注入/篡改/读取,影响表现与逻辑。
- 网络层:伪造或篡改网络消息,让服务器接收到“看似合理但实际不合法”的输入。
- 自动化与 AI:脚本、宏、机器人,以及基于视觉识别的外挂。
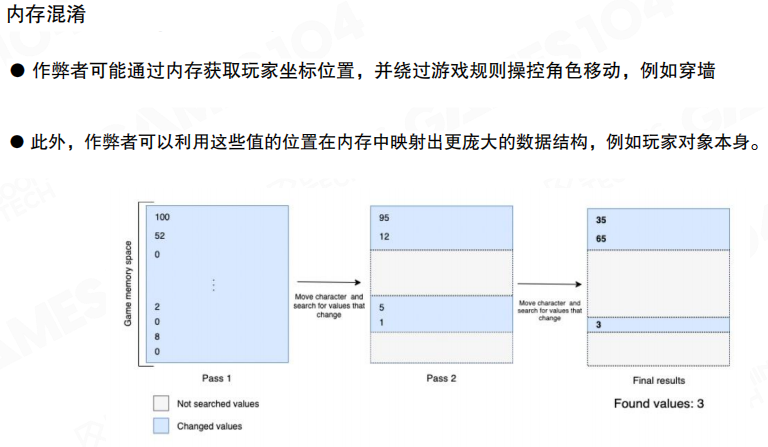
内存混淆
很多作弊的核心在于“把不该被玩家直接控制的状态变成可控”。工程上常见的应对策略是把关键状态做成 更难被直接定位与篡改 的形式,例如对关键数据做混淆/加密,并尽量减少客户端保存“能直接决定胜负”的权威状态。
这里的取舍是明确的:客户端侧的保护只能提高成本,无法提供绝对安全。最终仍要依靠服务器侧规则与一致性校验兜底。
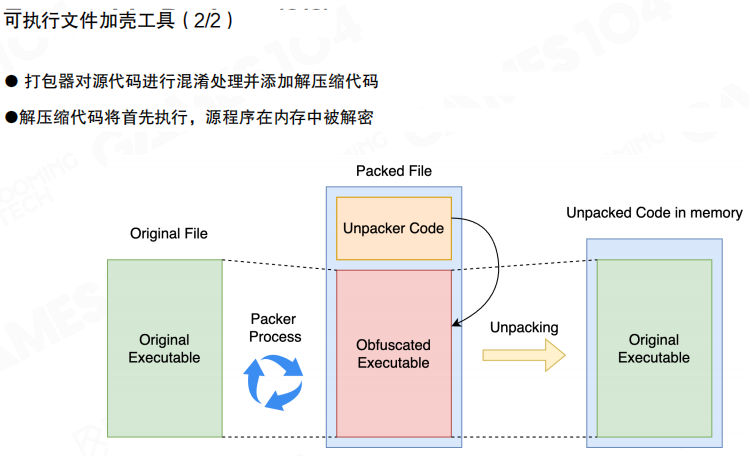
客户端加固
对抗”逆向分析与二次打包”,常见做法是做客户端加固(例如代码混淆、加壳等),提升静态分析难度;但这类方案通常是一场长期对抗:保护越强,对性能、兼容性与崩溃定位的影响也越明显。

哈希校验本地文件
资源文件被篡改会直接改变”可见性与可识别性”,因此很多网游都会做本地文件校验:通过哈希/签名等方式,验证客户端关键文件是否被修改。一旦发现异常,通常会拒绝进入对局或触发进一步复检。

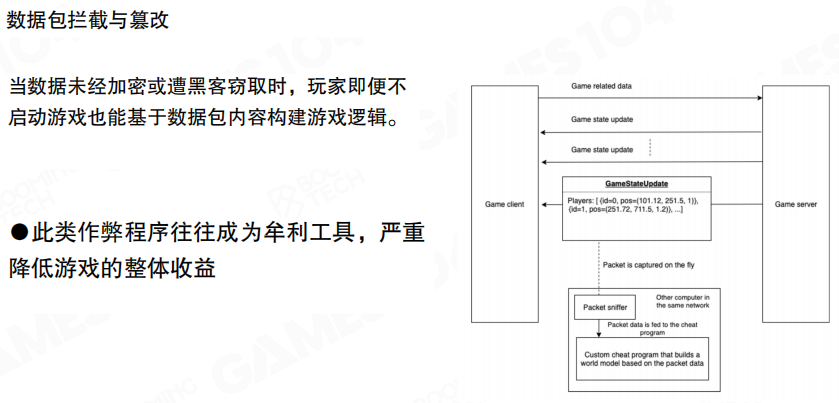
通信安全
网络层的问题本质是:如果通信内容可被旁路观察或篡改,那么攻击者就可能构造“欺骗服务器”的输入。工程上需要做到两点:
- 机密性:传输内容不应以明文暴露。
- 完整性:消息应能被验证“未被篡改”。
这也是为什么网游的关键链路通常需要加密与校验,而不是依赖客户端”自觉”。
加密
从实现角度看,加密常见分两类:
- 对称加密:加解密使用同一把密钥,速度快,适合大流量传输。
- 非对称加密:使用公钥/私钥体系,适合安全地协商密钥或传输少量关键数据。
实际系统里通常会组合使用:用非对称加密完成密钥协商,再用对称加密承载持续通信。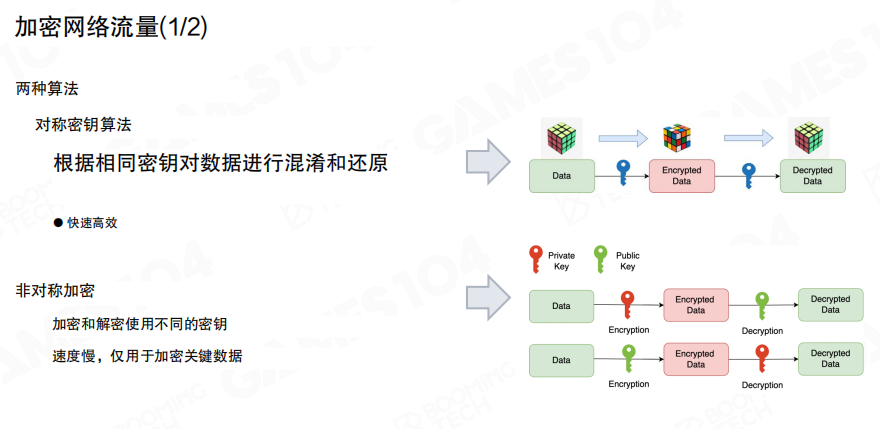
图里展示的就是这种”混合方案”:通过公钥体系把会话用的对称密钥安全分发出去,后续通信用对称密钥加密,性能与安全性更容易平衡。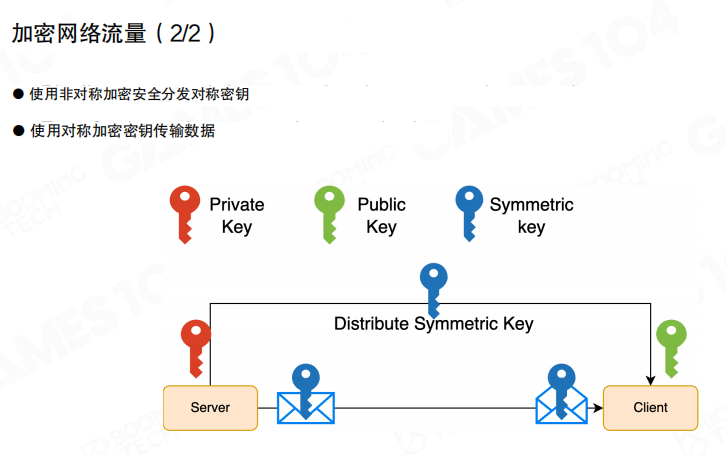
系统调用与注入
在 PC 平台,攻击者还可能通过系统层接口影响渲染与输入,制造”只对作弊者可见”的信息优势。反作弊系统通常会重点关注进程内的异常行为、可疑注入与不符合预期的调用链,尽早在客户端侧阻断风险。
反作弊组件
行业里已经有成熟的反作弊产品(例如 VAC、Easy Anti‑Cheat)。它们通常提供:
- 启动与运行期检测:识别可疑环境与异常交互。
- 完整性与变更防护:尽量防止非法修改与配置变更带来的风险。
- 处置链路:从检测到处罚的闭环支持。

AI 作弊
AI 作弊的难点在于:它可以只依赖屏幕图像与输入设备,绕过很多传统”进程内检测”。这意味着反作弊需要更多地结合服务器侧数据与行为模式分析,而不只是靠客户端扫描。
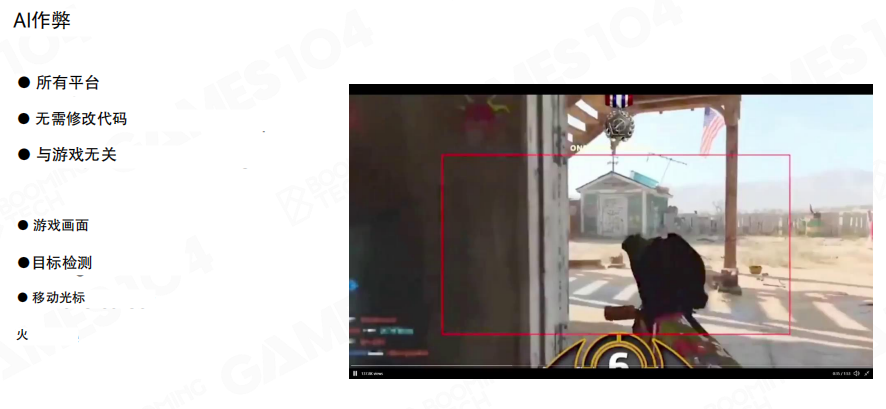
更现实的问题是门槛下降:目标检测、姿态识别等工具链越来越成熟,使得”做出可用的自动化辅助”变得更容易。这会把对抗长期推向”用 AI 对抗 AI”的方向。

人工审核
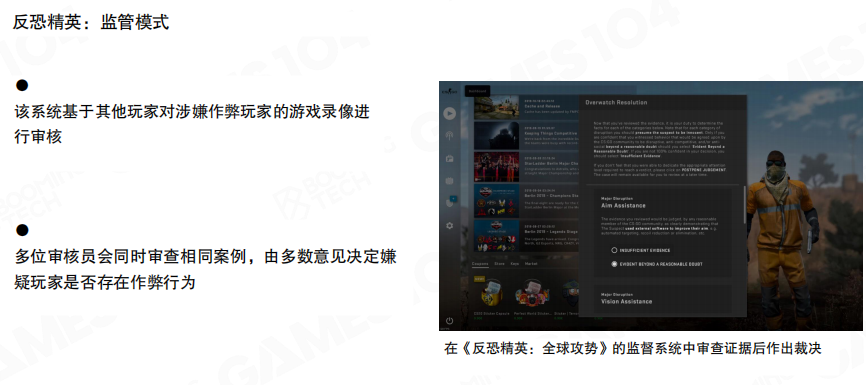
当自动化检测无法给出足够置信度时,引入人工审核是常见补充。例如图中展示的”监管模式”:基于录像证据,由多位审核者共同裁决,降低误判带来的伤害。
统计与规则
反作弊更像一个系统工程:客户端检测、服务器规则、玩家举报与人工审核需要形成闭环。统计系统会持续收集对局数据(例如胜率、爆头率、命中分布、行为序列等),结合规则与模型打分,将可疑账号送入复核流程。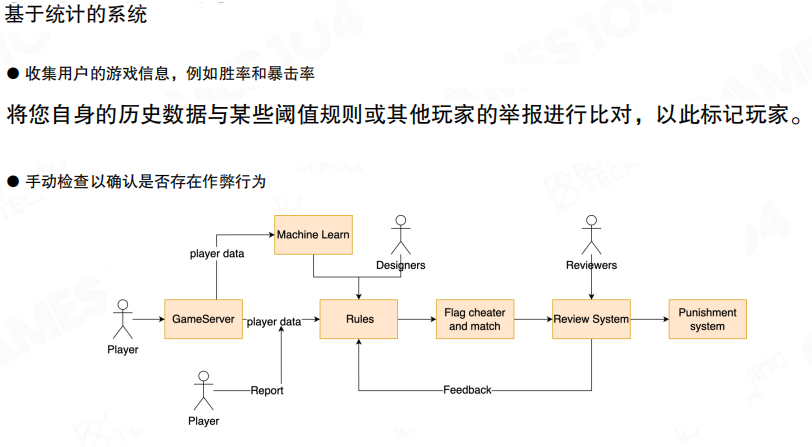
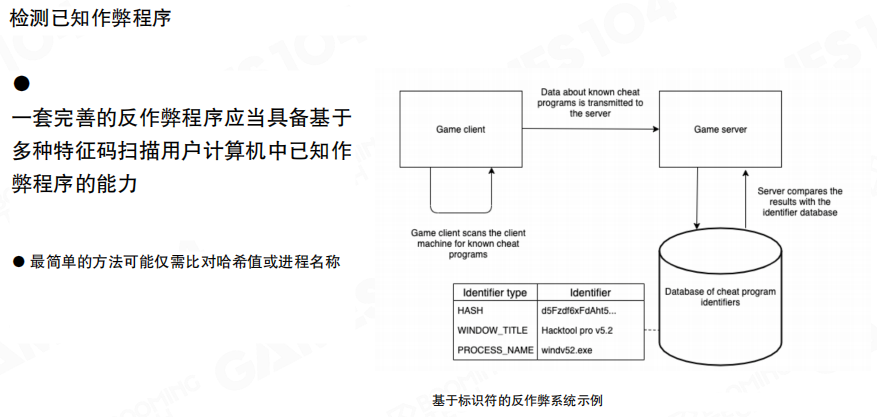
已知外挂检测
对”已知”的外挂与工具链,识别会相对直接:维护特征库,通过客户端上报与服务器比对进行匹配。它的优点是成本低、命中快;缺点也很明显:对未知与快速迭代的作弊手段,仍然需要其它层的能力补齐。
19.6 构建可拓展的游戏世界
要把“世界做大”,其实是在回答一个更具体的问题:怎么让同一个虚拟世界承载足够多的玩家,同时还能保持交互连续、负载可控。
从工程实现上看,常见有三类思路:
- 分区(Zone):把大世界切成很多块,每块由一个服务器负责;玩家在世界里移动时,会在服务器之间迁移。
- 实例化(Instance):把同一区域复制成多个副本,各自承载一部分玩家,减少拥塞与竞争(典型场景是“下副本”)。
- 复制(Replication):把同一片世界做成多层/多份镜像,玩家被分配到不同层,必要时通过“影子实体”同步可见信息(常见于高密度 PvP 或主城分流)。
这三类方法并不互斥:大型开放世界通常会组合使用。

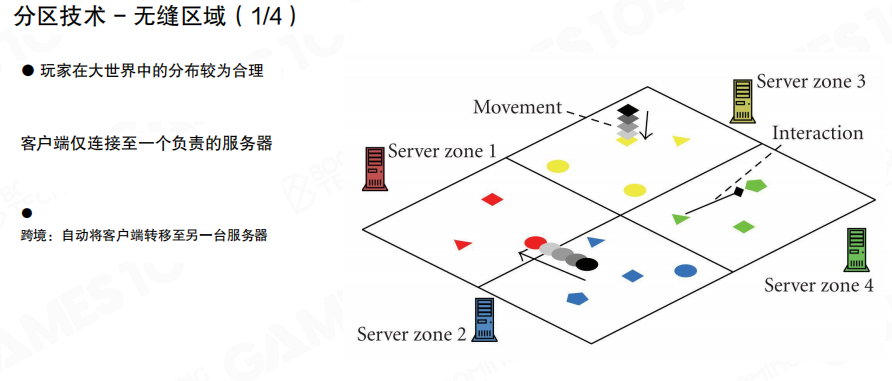
无缝分区
分区最直接的问题是体验:玩家跨区时,如果边界处理不好,会出现“突然刷出/突然消失”的割裂感。
无缝分区的目标就是两件事:
- 分布合理:玩家在大世界里的分布尽量均匀,避免某个区域被挤爆。
- 迁移平滑:客户端在跨区过程中不需要”重新登录/换线”,而是被自动迁移到负责新区的服务器。
边界带
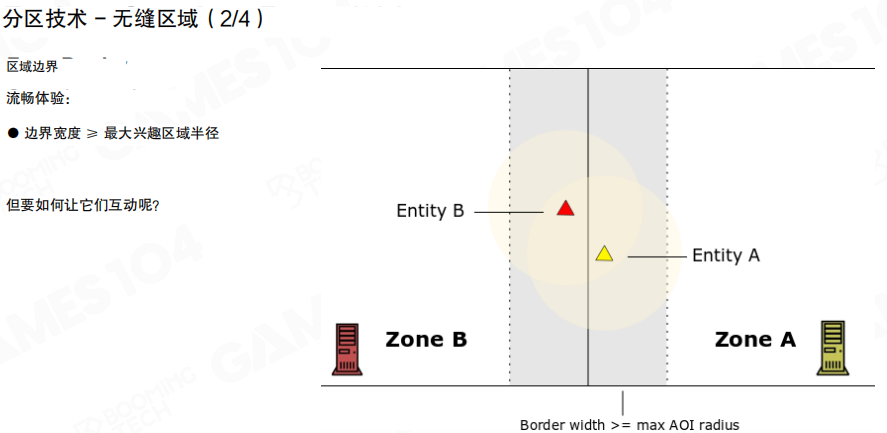
跨区最难的其实是交互:Entity A 在 Zone A,Entity B 在 Zone B,但它们的 AOI(关注区域)可能会跨过边界。
一个常见做法是引入 边界带(Border/Overlap):在两个 Zone 之间保留一段重叠区域,用来提前“预热”对方区域的可见对象。
图里给了一个关键约束:
- 边界带宽度 (\ge) 最大 AOI 半径
这样才能保证:只要实体处在边界附近,它关心的对象一定能在”重叠区”里被看见与更新。
幽灵实体
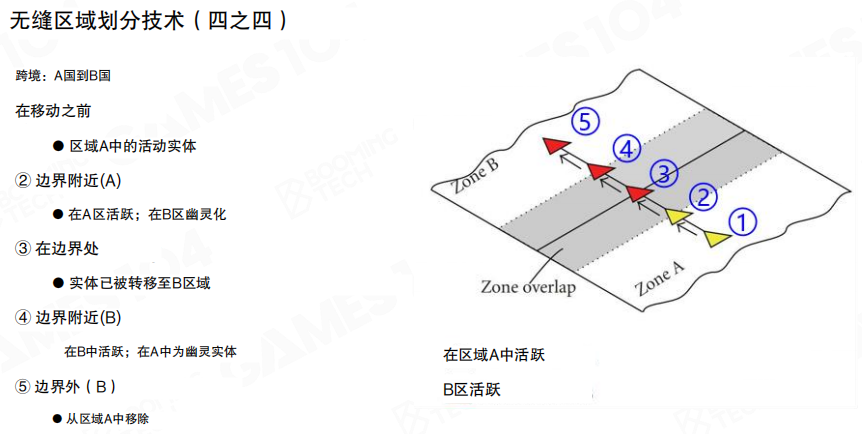
在边界带里,通常会引入 幽灵实体(Ghost / Shadow Entity)来维持连续可见性:
- 活跃实体(Active):由当前所在 Zone 的服务器作为权威端负责模拟与结算。
- 幽灵实体(Ghost):在相邻 Zone 中的代理副本,用于可见与基础交互展示;它接收来自活跃实体的状态更新。
这样,Zone A 的玩家可以在接近边界时”提前看到” Zone B 的对象,反过来也一样;但真正的逻辑仍由各自的权威 Zone 处理。

跨区迁移
跨区迁移可以理解为“权威归属”的切换:当实体从 Zone A 穿越到 Zone B 的某个阈值后,它在 B 侧从 Ghost 变成 Active;A 侧则把原来的 Active 降级成 Ghost 直到彻底离开边界带。
图里的 1→5 展示了一个常见的连续过程:从 A 内部接近边界、进入重叠区、跨越分界线、到 B 内部稳定下来。
工程上通常还会加一个迁移缓冲/迟滞(Hysteresis):避免玩家在边界线附近来回抖动导致实体频繁搬迁、服务器间状态反复切换。
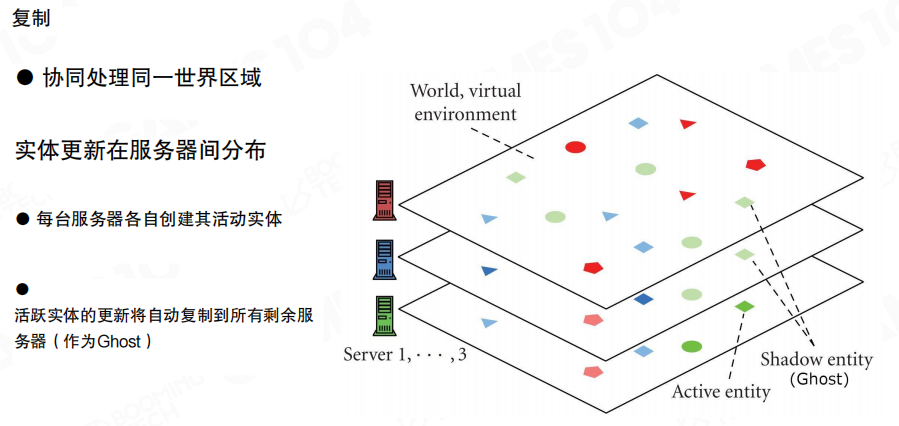
复制
当单纯的分区还不够(例如某些区域玩家密度过高),会引入“复制”的思路:多台服务器协同处理同一片世界区域。
图里展示的是一种直观模型:每台服务器都有自己的活跃实体集合,同时把其它服务器的活跃实体以 Ghost 的形式复制过来。这样每台服务器都能对外提供”完整世界的视图”,但只有本机负责的实体才是权威。
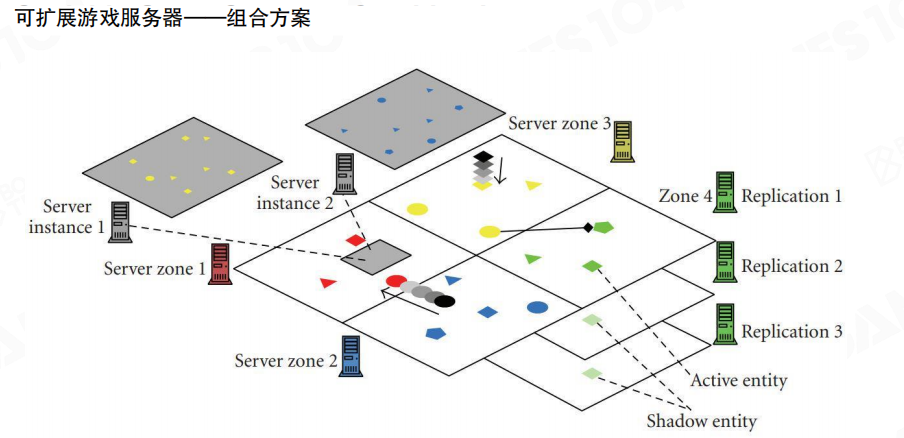
组合方案
更实用的做法通常是组合:
- 空间上用分区:把大世界拆成多个 Zone,处理“广度”问题。
- 密度上用复制/实例化:在热点区域用 Replication 或 Instance 分担压力,处理“人太密”的问题。
- 边界用 Ghost 兜底:用重叠区与幽灵实体保证跨区连续体验。
核心目标始终是同一个:把负载切开,但让玩家感觉世界没有被切开。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

