13.引擎工具链基础
13.1 工具链
游戏引擎宣传时通常会展示炫酷的光照效果和逼真的物理仿真,但很少详细介绍工具链的进化。在引擎开发中,工具链才是核心部分。工具链的工程量通常比运行时(Runtime)大得多,是商业级游戏引擎中最重要的模块之一。

工具链的定义
工具链(Tool Chain)是游戏引擎用户与底层运行时(渲染系统、物理引擎、网络通信等)之间的桥梁。工具链是一个完整的生态系统,负责协调不同背景和思维方式的用户协同工作。
工具链的架构位置
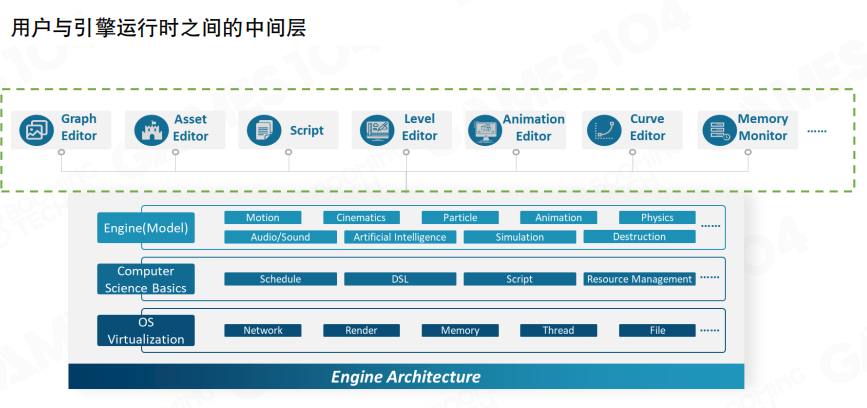
游戏引擎的复杂度接近小型操作系统,现代游戏引擎通常达到千万级代码规模。引擎架构分为四层:
- 底层:操作系统虚拟化层(网络、渲染、内存、线程、文件等)
- 中间层:计算机科学基础(调度、领域特定语言、脚本、资源管理等)
- 核心层:引擎运行时(运动、过场动画、粒子、动画、物理、音频、人工智能、模拟、破坏等)
- 顶层:用户工具层(图形编辑器、资产编辑器、脚本编辑器、关卡编辑器、动画编辑器、曲线编辑器、内存监控器等)
工具链位于用户工具层,是用户与引擎运行时之间的中间层,提供各种编辑器用于创建和管理游戏内容。
工具链连接DCC工具
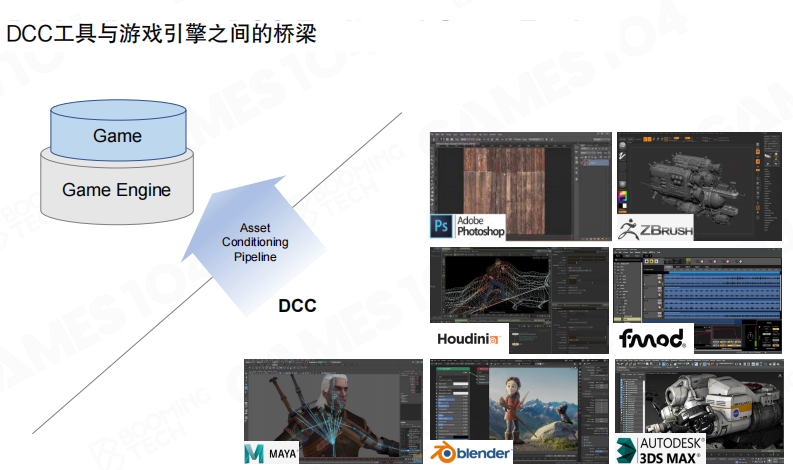
工具链连接游戏引擎与第三方DCC工具(Digital Content Creation,数字内容创作工具)。现代游戏开发需要使用大量第三方工具:
- 3D建模工具:Maya、3ds Max、Blender
- 数字雕刻工具:ZBrush
- 2D图像处理:Adobe Photoshop
- 程序化生成:Houdini
- 音频中间件:FMOD
这些DCC工具生成的资产数据是异构的,需要通过工具链的资产调节管道(Asset Conditioning Pipeline,ACP)处理,才能进入游戏引擎流水线。工具链负责格式转换、优化、验证等工作。
调和不同思维方式的用户
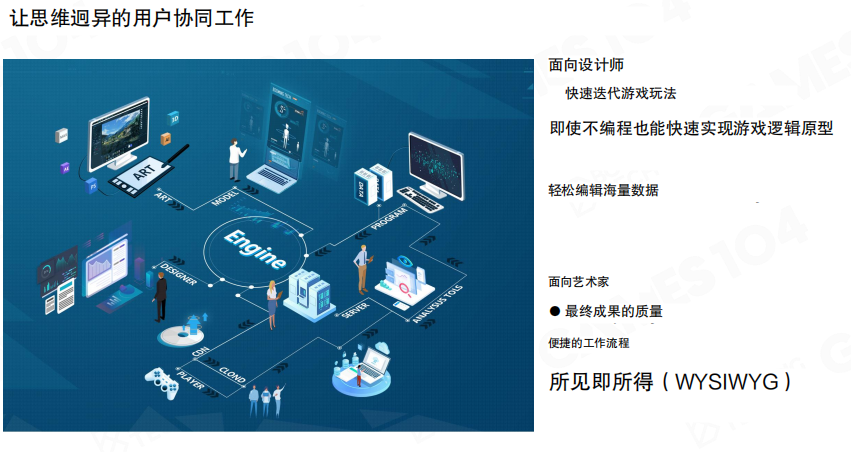
工具链的核心价值在于调和不同思维方式的人协同工作的平台。游戏团队通常包含三类不同背景的用户:
程序员(Programmer)
程序员思维严谨、逻辑性强,关注点包括:
- 场景中静态物体和动态物体的数量
- 数据在系统中的运行状态
- 代码逻辑的正确性和性能
程序员关注数据层面的信息,使用的工具偏向技术调试和性能分析。
艺术家(Artist)
艺术家对世界的理解是感性的、非定量的,但敏锐。关注点包括:
- 色彩的冷暖调整
- 场景的氛围和质感
- 角色动作的流畅性
- 视觉效果的表达和用户体验
艺术家更关注视觉表达而非底层的光照模型或物理原理,需要能够直观表达创意的工具,例如颜色分级(Color Grading)等视觉调整工具。
设计师(Designer)
设计师关注游戏的玩法和体验,关注点包括:
- 打击感的数值设计
- 攻击判定区域(暴击区、轻击区)
- 硬直和连击系统
- 游戏逻辑的快速迭代
设计师需要游戏逻辑的可视化表示,例如蓝图编辑器(Blueprint Editor)或图形编辑器(Graph Editor),使其能够在无需编程的情况下快速实现游戏逻辑原型。
工具链的设计理念
工具链设计需考虑不同使用者的思维习惯和需求:
- 面向程序员:提供调试工具、性能分析工具、代码编辑器
- 面向艺术家:提供可视化工具、所见即所得(WYSIWYG)的编辑体验
- 面向设计师:提供快速迭代工具、无需编程即可实现游戏逻辑的编辑器
这三类用户打开各自的工具时,看到的内容完全不同。工具链让这些说不同语言的人能够协同工作,成为调和不同背景人员的基础平台。
工具链的复杂度
在成熟的商业引擎中,工具链的复杂度或体量通常超过运行时。运行时代码开发难度高,但工具链代码的总开发量和开发成本会高于引擎本身,这是商业级引擎的普遍实践。
工具链包含大量编辑器模块:
- 场景编辑器(Level Editor):构建游戏世界
- 图形编辑器(Graph Editor)/ 蓝图编辑器(Blueprint Editor):编辑游戏逻辑
- 材质编辑器(Material Editor):创建和调整材质
- 着色器编辑器(Shader Editor):编写和调试着色器
- 脚本编辑器(Script Editor):编写游戏脚本
- 动画编辑器(Animation Editor):制作动画
- 粒子编辑器(Particle Editor):创建粒子特效
这些工具模块的复杂度总和往往超过引擎运行时的复杂度。
总结
工具链是游戏引擎中最重要的模块之一,主要功能包括:
- 连接用户与运行时:作为用户工具层与引擎运行时之间的桥梁
- 连接DCC工具与引擎:通过资产调节管道处理第三方工具生成的异构数据
- 调和不同背景的用户:使程序员、艺术家、设计师能够协同工作
- 复杂度超过运行时:在商业级引擎中,工具链的开发成本通常高于运行时
理解工具链的核心价值,有助于更好地设计和实现游戏引擎的工具系统。
13.2 复杂的工具
构建工具链时,最困难的部分是图形用户界面(GUI,Graphical User Interface)。工具链需要处理大量数字输入和参数调整,涉及复杂的用户界面系统。
GUI正变得越来越复杂。从早期的MS-DOS文本界面,到Windows NT 3.1的图形界面,再到现代游戏引擎工具链的复杂界面,GUI的复杂度不断提升。现代工具链需要支持快速迭代、设计与实现分离、可复用性等特性。
即时模式(Immediate Mode)
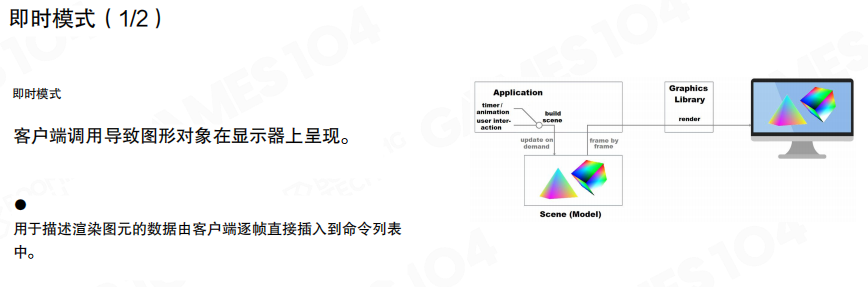
即时模式(Immediate Mode)是最简单的GUI实现方式。在即时模式中,客户端调用导致图形对象在显示器上呈现,用于描述渲染图元的数据由客户端逐帧直接插入到命令列表中。
即时模式的特点:
- 轻量级:实现简单
- 过程式编程:直接调用绘制函数
- Widgets不维护任何数据或状态:每次绘制都是独立的
优点:
- 直观易懂:代码逻辑清晰
- 简单:易于快速原型开发
- 快速原型:适合快速验证想法
缺点:
- 可扩展性差:难以处理复杂界面
- 性能表现不佳:每帧都需要重新绘制
- 维护性差:代码容易变得混乱
即时模式适用于简单工具或快速原型。例如Unity的IMGUI、Omniverse GUI、Piccolo图形用户界面等系统使用即时模式。
保留模式(Retained Mode)

保留模式(Retained Mode)是现代游戏引擎工具链更常用的GUI实现方式。在保留模式中,图形库(而非客户端)保留待渲染的场景,客户端对图形库的调用并不会直接触发实际渲染,而是通过图形库管理的资源进行大量间接操作。
保留模式的特点:
- 面向对象:Widgets包含自己的状态和数据
- 按需绘制控件:支持复杂效果(动画等)
优点:
- 高可扩展性:易于扩展和维护
- 高性能:统一处理绘制命令,性能更好
- 高可维护性:代码结构清晰
缺点:
- 开发者使用门槛高:需要理解消息队列/回调函数
- GUI与应用程序间的同步:需要处理同步问题
保留模式适用于复杂工具系统。例如虚幻引擎的UMG、WPF GUI、QT GUI等系统使用保留模式。
GUI设计模式
构建保留模式GUI系统时,需要遵循设计模式来组织数据和视图。如果不遵循设计模式,当工具功能增加到上百个、工具数量达到十几个时,系统很容易出现问题。
MVC模式
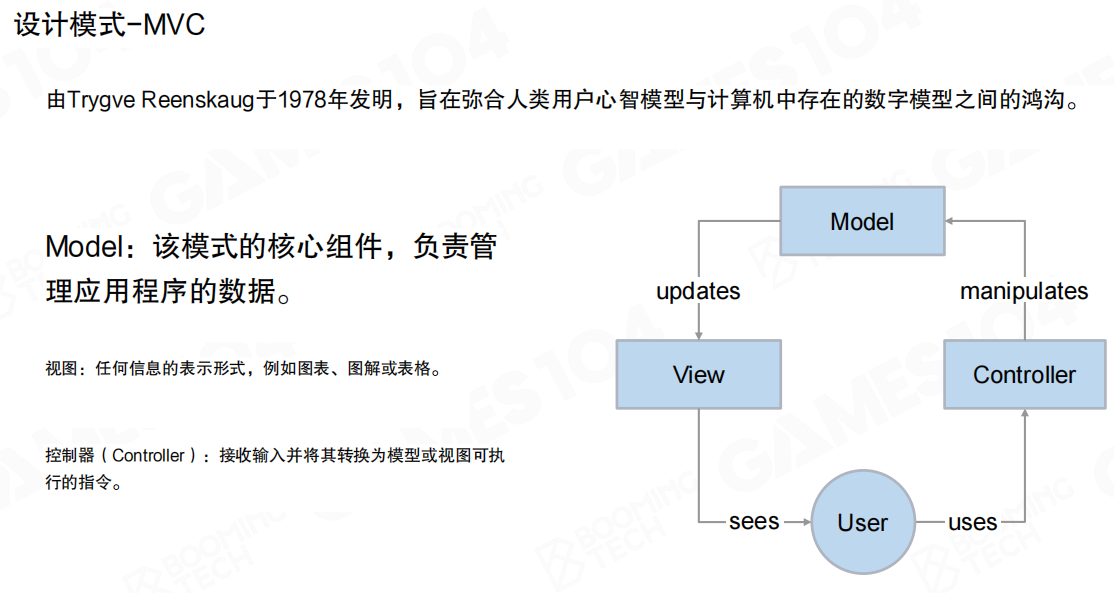
MVC(Model-View-Controller)是经典的人机交互设计模式,由Trygve Reenskaug于1978年发明,旨在弥合人类用户心智模型与计算机中存在的数字模型之间的鸿沟。
MVC的组件定义:
- Model:该模式的核心组件,负责管理应用程序的数据
- 视图(View):任何信息的表示形式,例如图表、图解或表格
- 控制器(Controller):接收输入并将其转换为模型或视图可执行的指令
MVC的核心思想是将用户(User)、视图(View)和模型(Model)进行分离。当用户想要修改视图时只能通过控制器(Controller)进行操作,并由控制器转发给模型,从而避免用户直接操作数据产生各种冲突。
MVC将数据流清晰化:数据从Model单向流向View,View不能反向写入Model。如果需要修改Model中的数据,只能通过Controller进行各种处理和过滤后再修改Model。这种单向数据流使系统更容易管理和调试。
MVP模式
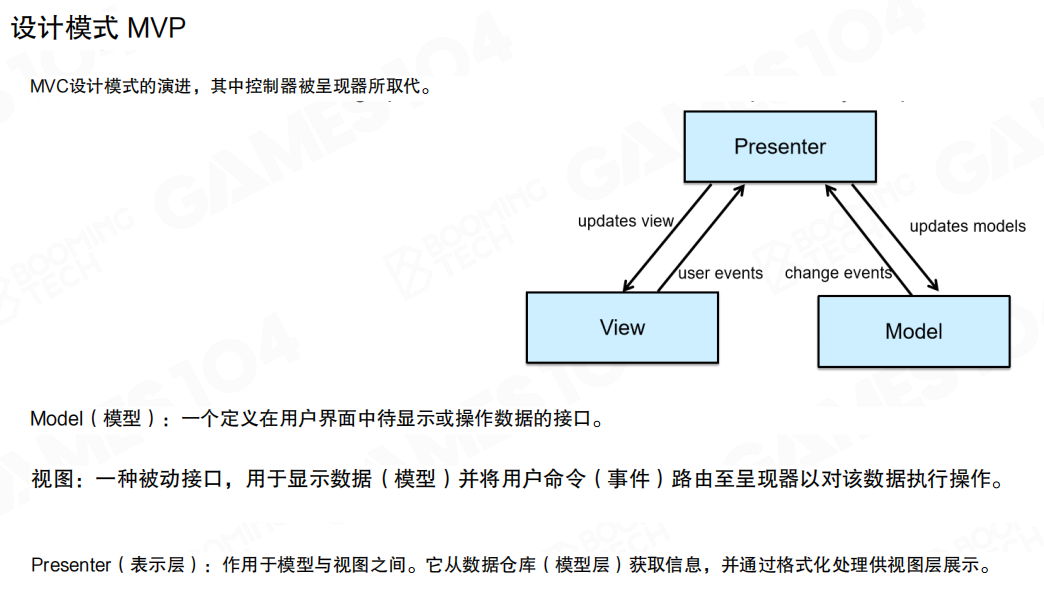
MVP(Model-View-Presenter)可以看做是对MVC的演变。MVP模式对视图和模型进行了更彻底的分离,视图只负责对数据进行展示,模型只负责对数据进行处理,它们之间的通信则通过展示者(Presenter)来实现。
MVP的组件定义:
- Model(模型):一个定义在用户界面中待显示或操作数据的接口
- 视图(View):一种被动接口,用于显示数据(模型)并将用户命令(事件)路由至呈现器以对该数据执行操作
- Presenter(表示层):作用于模型与视图之间,从数据仓库(模型层)获取信息,并通过格式化处理供视图层展示
当用户想要修改数据时,用户的请求会通过视图提交给展示者,然后再由它转发给模型进行处理。MVP的优势在于视图和模型完全解耦,便于单元测试。但代价是Presenter需要理解Model和View两种不同的语言,容易变得臃肿。
MVVM模式
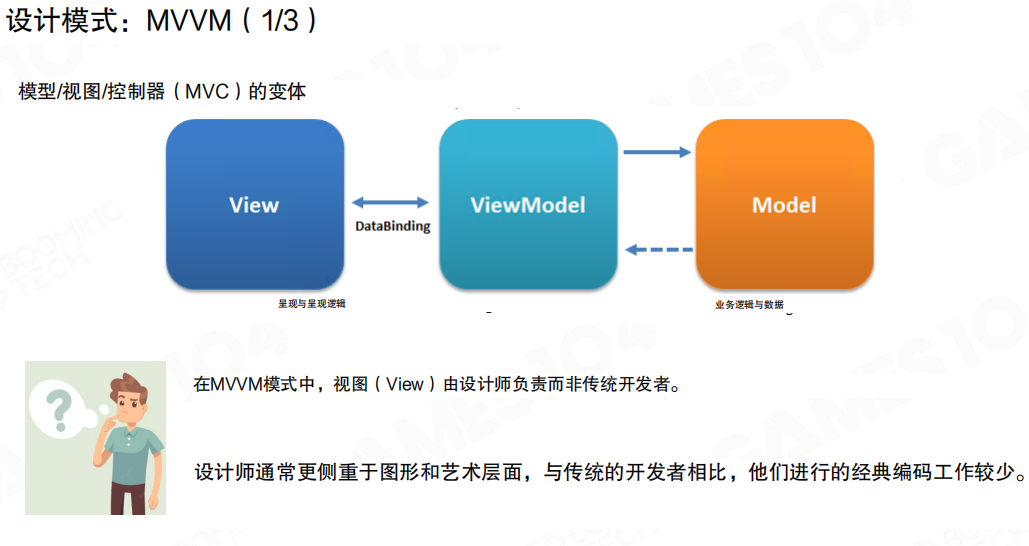
MVVM(Model-View-ViewModel)是目前游戏引擎中大量使用的UI设计模式。在MVVM中,视图和模型的中间层称为ViewModel。在MVVM模式中,视图只包含简单的UI状态数据,这些数据通过ViewModel解析成合适的数据结构再提交给模型进行处理。

MVVM的关键特性是数据绑定(DataBinding)。视图和ViewModel之间通过声明式的绑定机制连接,而不是通过代码硬编码。这种机制允许交互设计师使用XML或XAML等标记语言直接定义UI,实现所见即所得(WYSIWYG)的编辑体验。

MVVM的优点:
- 自研:可以独立开发
- 易于维护和测试:视图和模型完全分离
- 易于复用的组件:组件可以复用
MVVM的缺点:
- 对于简单的用户界面,MVVM模式可能显得过于繁重
- 数据绑定是声明式的,调试起来更加困难
MVVM适用于需要设计师参与UI设计的场景。例如WPF提供了完整的MVVM框架支持,设计师可以使用XAML脚本或编辑器自动生成各种UI,程序员只需编写简单的C#代码即可完成绑定。
序列化与反序列化
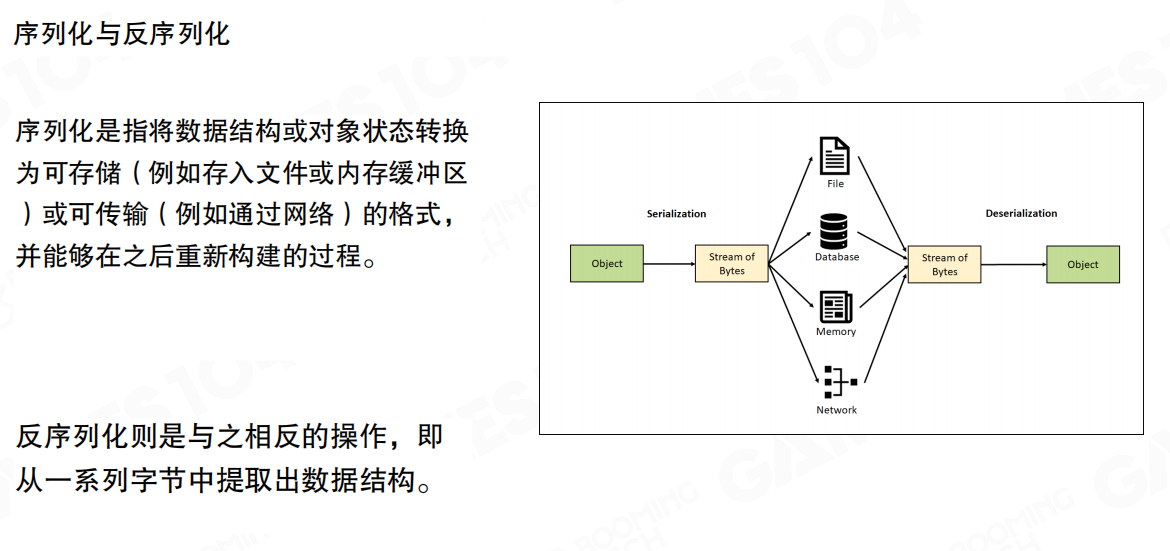
构建工具链时,需要处理数据的加载和保存。这需要使用序列化(Serialization)和反序列化(Deserialization)技术。
序列化是指将数据结构或对象状态转换为可存储(例如存入文件或内存缓冲区)或可传输(例如通过网络)的格式,并能够在之后重新构建的过程。
反序列化则是与之相反的操作,即从一系列字节中提取出数据结构。
序列化和反序列化不仅指文件存储,还包括:
- 数据库存储:将对象状态序列化为数据库中的块数据
- 网络传输:客户端向服务器发送消息时,需要将游戏对象的所有描述序列化为二进制数据流
这两个概念是现代游戏引擎的基础概念,在工具链、游戏引擎和网络通信中都发挥着重要作用。
文本文件格式

最简单的序列化方法是把数据保存为文本文件。文本文件虽然简单,但实际上目前很多系统仍然使用文本文件进行信息传输。目前常用的文本文件格式包括TXT、JSON、YAML、XML等。
文本文件的优点:
- 可用常见文本编辑器读取:便于理解和调试
- 易于追踪和分析:任何工具都能打开
- 便于调试:数据错误时容易定位问题
文本文件在游戏引擎中的应用:
- Unity编辑器(可选):YAML子集
- Piccolo:JSON
- CryEngine:XML/JSON(可选)
在开发引擎时,建议首先支持文本文件格式,这相当于给引擎加入了一个调试模式。任何数据出错时,可以先将数据转成文本格式进行调试,确认无误后再转成二进制格式。
二进制文件格式

当需要序列化的数据不断增长时,需要使用更高效的存储格式。通常情况下会使用二进制格式来对数据进行存储。
二进制文件的特点:
- 将数据保存为字节流:需要额外的读写工具
- 示例:UAsset、FBX二进制文件
二进制文件在游戏引擎中的应用:
- Unity运行时,Unity编辑器(可选)
- CryEngine(可选)
- Unreal:UAsset
Text vs 二进制
和文本文件相比,二进制文件往往只占用非常小的存储空间,而且对数据进行读取也要高效得多。例如FBX格式提供了两种格式:二进制格式和文本格式。文本格式的文件大小通常是二进制格式的十倍以上。

读取二进制时几乎不需要进行语法处理,但读取文本时需要做语法解析,包括处理逗号、句号、尖角号、注释等,生成语法树,构建关键字字典等。文本的加载速度通常比二进制慢十倍不止。
因此在现代游戏引擎中一般都会使用二进制文件来进行数据的保存和加载。对于上线的游戏,资产格式必须使用二进制格式,同时还需要考虑加密以防止被破解。
资产引用(Asset Reference)

在很多情况下游戏的资产是重复的,此时为每一个实例单独进行保存就会浪费系统的资源。因此,在现代游戏引擎中会使用资产引用(Asset Reference)的方式来管理各种重复的资产。

资产引用是一种通过建立引用关系,将冗余数据分离至资产文件并完成关联的方式。例如在场景中,多个对象可以引用同一个资产定义,每个实例只需要存储自己的位置、旋转、缩放等变换信息,而不需要重复存储网格数据。

资产的引用和去重是游戏引擎工具链最重要的底层逻辑之一。游戏引擎中可能有上万个、上十万个甚至上百万个资产文件,它们像一张网一样彼此关联在一起。
对象实例差异

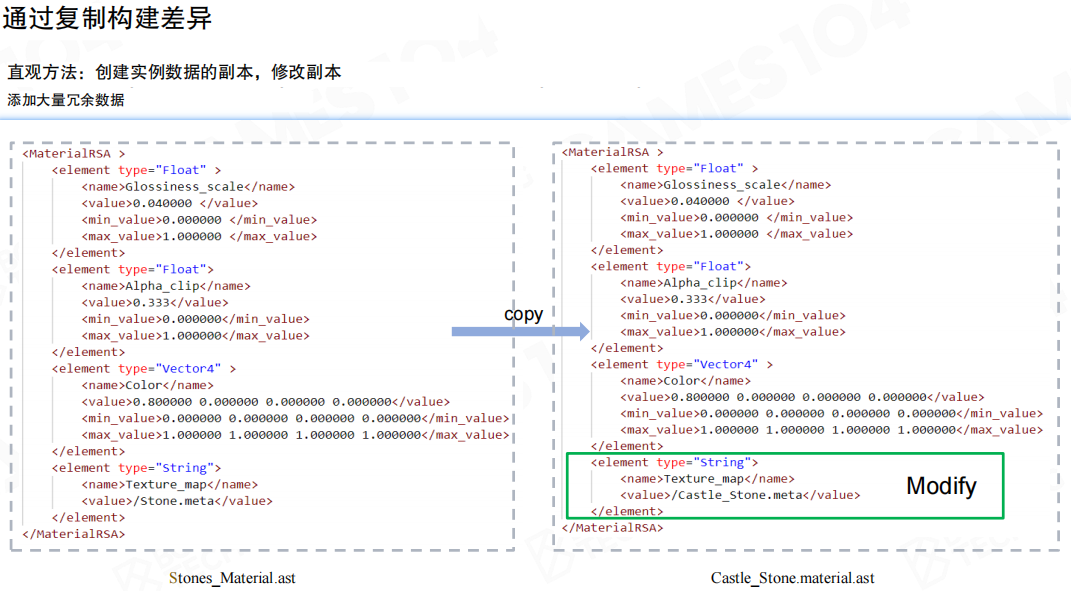
在游戏开发过程中,工具链往往还需要提供对游戏对象进行修改,从而实现不同的艺术效果。例如场景中出现了十次相同的房子,但艺术家希望将其中五个的贴图换成其他贴图。
最简单粗暴的做法是直接复制物体,然后修改副本。但这种方法存在明显问题:
- 数据冗余:一个物体的描述可能包含成千上万的数据,只改动一个属性就需要复制全部数据
- 关联断裂:如果对物体的网格进行总体调整,希望其他实例也相应变化,但复制后它们之间的关联就彻底断掉了
数据继承(Data Inheritance)

为了解决这个问题,现代游戏引擎引入了数据继承(Data Inheritance)的概念。数据继承是指继承被继承对象的数据,并允许覆盖对其数据结构中定义的数据进行赋值。
通过数据继承构建差异的方法:
- 继承原始数据:新数据继承父级数据的所有属性
- 覆盖特定属性:只修改需要改变的属性值
例如,一个材质可以继承自另一个材质,只覆盖纹理贴图路径,而其他属性(如光泽度、颜色等)保持不变。这样既避免了数据冗余,又保持了数据之间的关联。
数据继承是工具链中非常重要的底层技术。当用户在多个工具中来回操作时,会产生大量数据,这些数据可以通过继承关系组织起来,既保证数据的灵活多样性,又不会造成混乱。
13.3 资产加载
上一小节主要讨论如何保存数据,而游戏引擎工具链的难点在于如何加载不同的资产,即反序列化过程。反序列化需要对文件进行解析(Parsing),文件中的不同字段往往有着不同的关键字和域,需要扫描整个文件来获得文件结构。
解析资源文件
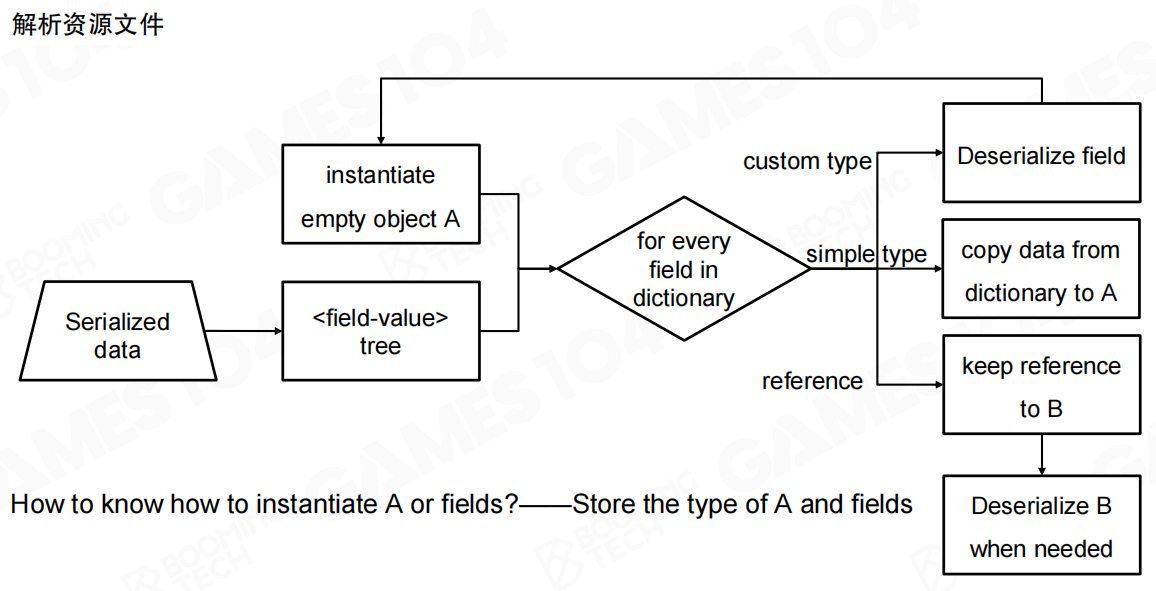
资产加载并不是简单地按顺序读取文件,而是一个解析过程。场景文件包含多个数据块,每个数据块有多个字段,字段有不同的值和类型。需要对整个文件进行扫描,检查每个字段是否存在。
解析过程包括:
- 实例化空对象:创建目标对象的空实例
- 解析为字段-值对树:将序列化数据解析为树状结构
- 遍历字段字典:对字典中的每个字段进行处理
- 处理不同类型字段:
- 自定义类型:递归反序列化字段
- 简单类型:从字典复制数据到对象
- 引用类型:保留对目标对象的引用,需要时再反序列化
关键问题是如何知道如何实例化对象或字段,答案是存储对象和字段的类型信息。这样在反序列化时才能正确创建对象并填充数据。
构建键-类型-值对树
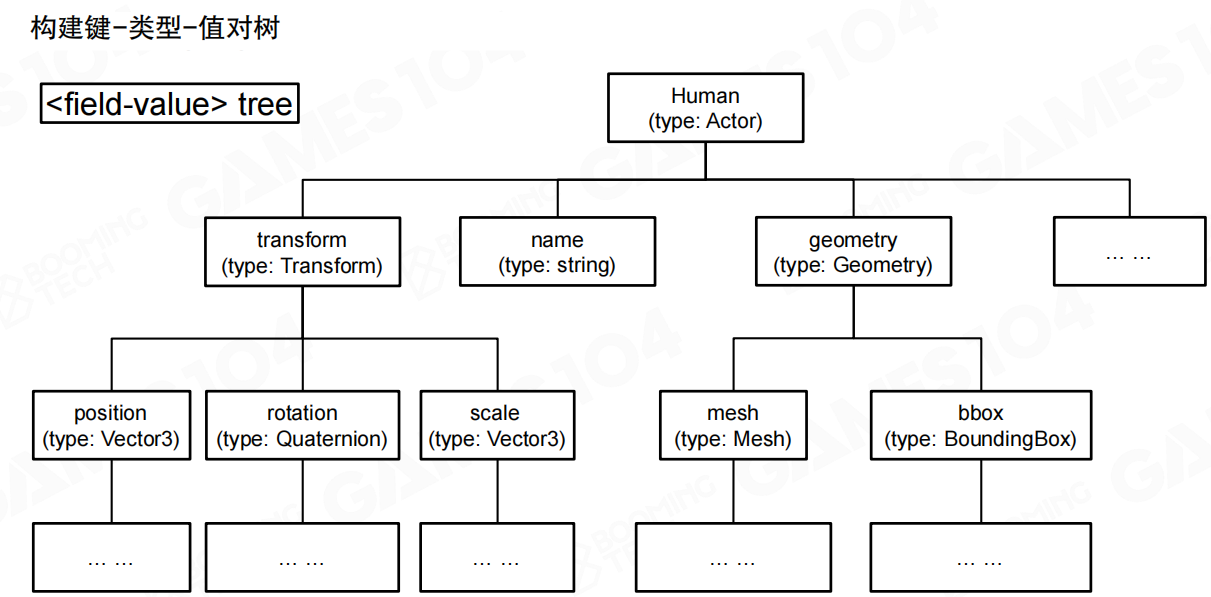
解析完成后,可以得到一棵由键-类型-值对组成的树来表达不同类型的数据。例如一个Human对象(类型为Actor)包含transform(类型为Transform)、name(类型为string)、geometry(类型为Geometry)等字段。transform又包含position(类型为Vector3)、rotation(类型为Quaternion)、scale(类型为Vector3)等子字段。
这种树状结构与XML、JSON等格式类似。无论多复杂的资产文件,都是树状结构。游戏引擎的资产管理也采用这种结构,类似于编译器的抽象语法树(AST)。树状结构可以表达复杂的系统,节点之间可以相互引用。
对于文本格式,需要先进行复杂的解析过程。例如使用JSON作为数据载体时,首先调用第三方库将JSON文件转换为树状结构(字典),然后通过二次处理获取所需资产。
对于二进制格式,通常在二进制文件的头部存储树状描述,包括有多少个字段、字段名称、类型、数据偏移位置等信息。这样后续数据可以快速处理。
二进制与文本格式对比
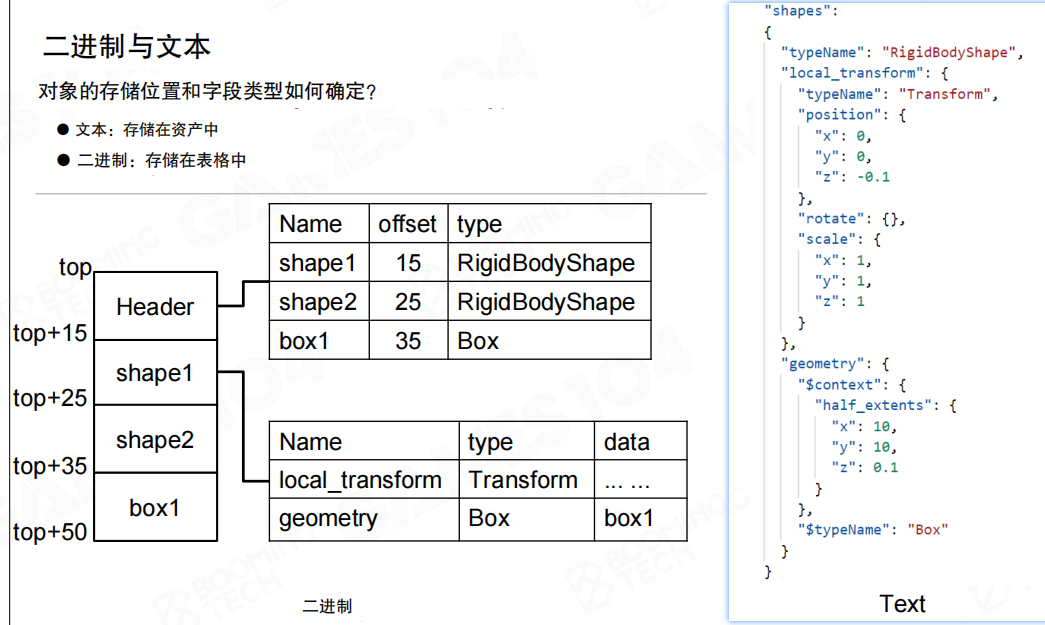
对象的存储位置和字段类型如何确定?文本格式将类型信息存储在资产中,二进制格式将类型信息存储在表格中。
在二进制格式中,内存布局包含Header和各个对象(如shape1、shape2、box1),Header中包含查找表,记录每个对象的名称、偏移量和类型。对象结构表描述对象的字段结构,包括字段名称、类型和数据。
在文本格式中,类型信息直接写在JSON结构中,例如"typeName": "RigidBodyShape"明确指定对象类型,"$typeName": "Box"指定几何类型。文本格式是自描述的,类型信息包含在数据中。
字节序(Endianness)

对二进制文件进行反序列化和解析时需要额外注意字节序(Endianness)问题。在不同硬件和操作系统上,同样的二进制文件可能被解析为不同的数据,这对于跨平台应用需要额外注意。
大端序(Big Endian):从最高有效字节开始,以最低有效字节结束。例如0x1234567在内存中存储为:0x100地址存储01,0x101地址存储23,0x102地址存储45,0x103地址存储67。
小端序(Little Endian):从最低有效字节开始,到最高有效字节结束。例如0x1234567在内存中存储为:0x100地址存储67,0x101地址存储45,0x102地址存储23,0x103地址存储01。
不同处理器的字节序存在差异:
PowerPC(PPC):大端序- Sun Sparc:大端序
- IBM S/390:大端序
Intel x86(32位):小端序Intel x86_64(64位):小端序- ARM:双端序(Big/Little Endian)
在工具链中,一般约定统一使用小端序(例如PC作为编辑器平台)。在反序列化时,如果发现目标平台是大端序(例如PlayStation),需要进行字节交换(Byte Swapping),将小端序数据转换为大端序数据。这个过程可以离线完成,在打包时处理。
版本兼容性问题
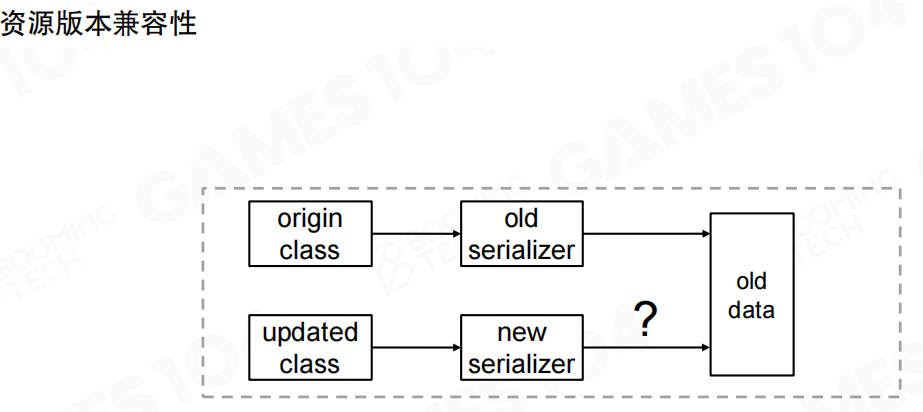
在工具链的反序列化过程中还需要考虑资产的兼容性问题。游戏开发周期往往较长,在这一过程中可能会出现引擎以及各种工具的升级。希望新版本可以对旧版本中设计好的资源进行兼容,从而避免重复劳动。
版本兼容性问题包括:
- 向后兼容(Backward Compatibility):新版本工具能够打开旧版本创建的数据
- 向前兼容(Forward Compatibility):旧版本工具能够打开新版本创建的数据(至少不崩溃)
在分布式部署环境中,版本兼容性需求更加复杂。不同团队开发的工具版本更新频率不同,需要保证不同版本之间的数据能够正常交互。
添加或删除字段

在版本更迭中最常见的情况是数据的域发生了修改,新版本的数据定义可能会添加或删去老版本定义的域。
例如原始类定义包含guid、name、transform三个字段。更新后的类可能删除transform字段,或者添加bbox字段。但旧数据仍然包含transform字段,新数据可能不包含transform字段,也可能包含bbox字段。
这种情况会导致兼容性问题:新序列化器能否正确处理旧数据?旧序列化器能否正确处理新数据?
通过版本硬编码解决兼容性

为了处理这种问题,可以手动为数据添加版本号,在加载数据时根据版本号来控制加载过程。例如Unreal引擎为资产添加版本号。
加载资产时:检查字段是否存在,然后加载数据。如果当前版本大于等于数据版本,则加载新字段;否则跳过新字段,使用默认值。
保存资产时:将所有数据写入资产文件,并更新版本号到当前版本。
这种方法简单直接,但随着系统发展3-4年以上,需要兼容的版本号会越来越多,维护成本较高。
通过字段UID解决兼容性
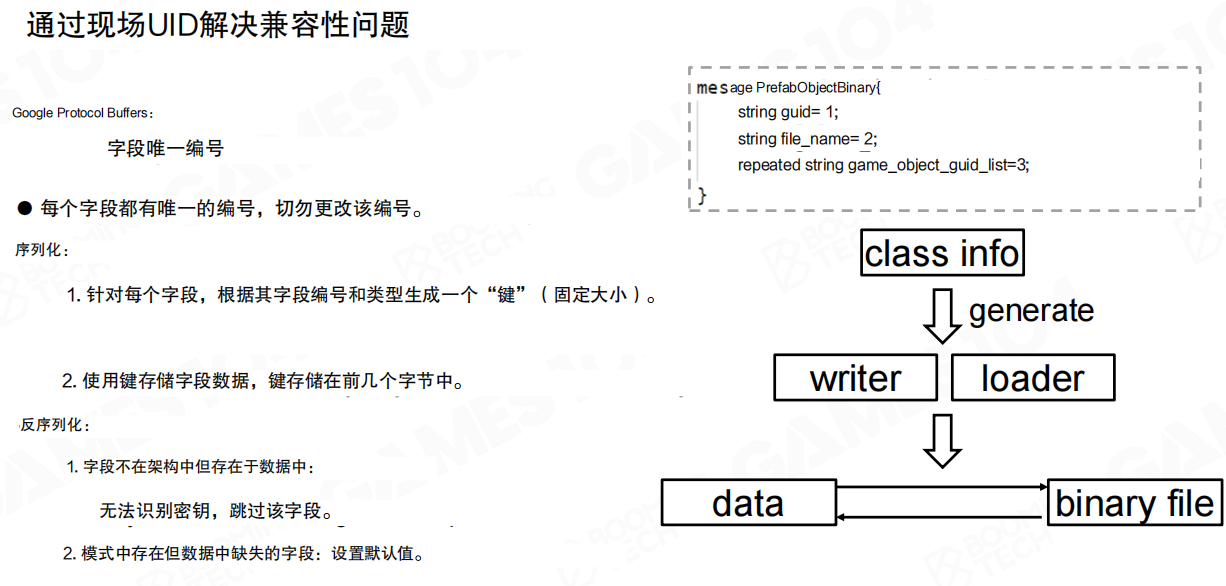
更好的处理方法是使用字段UID(Field Unique ID)来进行管理。Google提出的Protocol Buffers为每个字段赋予一个唯一编号,切勿更改该编号。
序列化时:针对每个字段,根据其字段编号和类型生成一个键(固定大小),使用键存储字段数据,键存储在前几个字节中。
反序列化时:
- 字段不在架构中但存在于数据中:无法识别密钥,跳过该字段(向前兼容)
- 模式中存在但数据中缺失的字段:设置默认值(向后兼容)
例如定义消息时:
message PrefabObjectBinary{
string guid = 1;
string file_name = 2;
repeated string game_object_guid_list = 3;
}
每个字段都有唯一的编号(1、2、3),这些编号在后续版本中保持不变。当添加新字段时,使用新的编号(如4、5),旧数据中不包含这些字段时使用默认值。当删除字段时,旧数据中的该字段会被跳过。
这种方法避免了版本号管理的复杂性,通过字段UID实现了灵活的版本兼容性。对于商业级游戏引擎,数据格式可能达到几十甚至上百种,每种格式由不同团队开发和维护,字段UID方法能够保证整个工具链体系的鲁棒性。
13.4 如何制作高鲁棒性的工具
游戏引擎工具链对鲁棒性有非常高的要求。一旦工具链出现问题,会对整个游戏开发流程产生巨大影响。如果工具链崩溃,可能导致数百人一上午无法工作,等待bug修复。这种压力促使工具链开发者必须将鲁棒性作为核心关注点。
鲁棒性最基本的要求是允许程序从崩溃中进行恢复,从而还原初始的开发状态。为了实现这样的功能,需要将用户所有的行为抽象为原子化的命令(Command),通过命令的序列来表示整个开发过程。
撤销/重做
对于游戏引擎来讲,撤销/重做其实非常复杂。很多数据编辑是相关的(Correlated)。
例如改了一个房子的颜色,房子没问题。绕着房子旁边种了一些树,也没有问题。突然决定把地面往上拉3-4米形成小土坡,这时房子和树都会相应地发生变化。在房子旁边自动生成一些装饰,生成房子周边的一圈沙地空白地。
当要撤销时,会发现有些操作会影响到其他操作。首先把房子删了,旁边那圈装饰可能就有问题。把地形调整改了之后,刚才种的那些树,可能它的角度很多人都会发生变化。
所以在游戏引擎里面,这种撤销和重做彼此之间是有很深的关联性,而且很多操作是相关的。
崩溃恢复
即使做得再好的工具,都会崩溃。崩溃之后,艺术家编辑了一个小时的东西,也不会想着去存盘,突然就崩溃掉了。这时需要崩溃恢复功能。
命令模式可以很好地解决这个问题。系统会定时将这些command存到磁盘上,这样万一系统挂了的时候,可以从磁盘上去找。当系统恢复时,可以从磁盘恢复命令序列,重新执行所有命令来重建系统状态。
命令模式(Command Pattern)
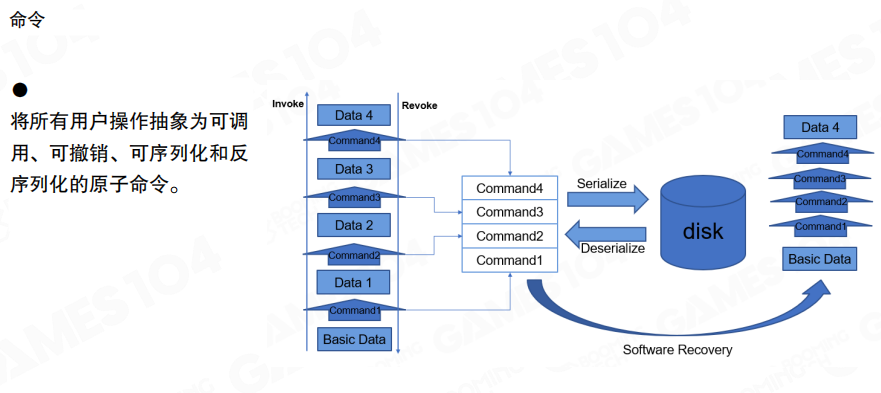
命令模式将所有用户操作抽象为可调用、可撤销、可序列化和反序列化的原子命令。命令系统包括:
- 调用过程(Invoke):从基础数据开始,依次执行Command1、Command2、Command3、Command4,逐步生成Data1、Data2、Data3、Data4
- 撤销过程(Revoke):可以依次撤销Command4、Command3、Command2、Command1,恢复到之前的状态
- 持久化(Persistence):命令可以序列化到磁盘,也可以从磁盘反序列化
- 软件恢复(Software Recovery):系统崩溃后,可以从磁盘恢复命令序列,重新执行所有命令来重建系统状态
这种模式在软件工程中已经被研究得非常透彻。例如Word、PowerPoint等软件都使用这种模式实现撤销/重做和崩溃恢复功能。
命令的定义

ICommand<TData>提供了命令的基本抽象。任何需要支持撤销/重做/崩溃恢复等功能的系统,都必须实现继承自ICommand<TData>的系统相关命令。
命令接口定义:
- UID:唯一标识符,用于保证命令的顺序
- Data:命令的数据,通常是运行时实例的副本或修改的属性值
Invoke():执行命令Revoke():撤销命令Serialize():序列化命令到字节数组Deserialize():从字节数组反序列化命令
命令的定义比想象的要简单。每个command需要有一个UID、一串Data,以及Invoke和Revoke两个核心函数。还有Serialize和Deserialize函数用于持久化。
命令UID

命令在从磁盘恢复时需要严格遵循顺序。命令UID具有两个重要特性:
- 随时间单调递增:UID随着时间单调递增,保证命令的执行顺序
- 唯一标识:每个命令都有唯一的标识符
为什么需要UID?因为当进行回退(Revoke)或恢复(Recovery)时,希望执行严格遵循原始的顺序。在真正编辑操作时,很多操作如果执行的顺序不一样,结果会完全不同。UID就是保证这个顺序的单调递增的核心点。
命令序列化与反序列化

命令序列化与反序列化提供将命令实例序列化为数据以及将数据反序列化为命令实例的功能。TData类型需提供序列化与反序列化接口。
命令系统本身不负责数据的序列化,而是由数据自身提供标准的序列化和反序列化方法。例如一个GameObject要提供序列化方法,能够把当前在内存中的全部状态序列化下来。Command系统调用GameObject的序列化方法,把数据存下来。
这样设计的好处是,当实现这套Command系统时,可以变相地促使整个引擎系统都写得非常干净,让所有操作都能够原子化。
三大核心命令

整个command系统可以划分为三种不同类型的指令,包括添加数据、删除数据以及更新数据。实际上几乎所有的command都可以视为这三种基本指令的组合。
添加(Add)
- 数据(Data):通常数据是运行时实例的一个副本
- 调用(Invoke):使用数据创建运行时实例
- 撤销(Revoke):删除运行时实例
删除(Delete)
- 数据(Data):通常数据是运行时实例的一个副本
- 调用(Invoke):删除运行时实例
- 撤销(Revoke):使用数据创建运行时实例
更新(Update)
- 数据(Data):通常指运行时实例被修改属性的旧值与新值及其属性名称
- 调用(Invoke):将运行时实例属性设置为新值
- 撤销(Revoke):将运行时实例属性恢复为原值
无论多么复杂的API系统,用这三类command基本上就能表达。文本编辑器的所有撤销/重做操作基本上就是用这三类操作就能解决:增加一个text、删除一个text、更新一个text。
13.5 如何制作工具链
现代游戏引擎的工具链往往包含成百上千个不同的工具程序,这些程序会面向不同背景的开发人员并实现相应的功能。对于工具链来说,一个基本要求是要保证不同工具之间的沟通以及整个系统的可扩展性。不希望每个工具程序都使用单独的一套数据定义方式,这会导致整个工具链系统过于庞大而且难以进行维护。
因此需要寻找不同工具中的一些共性,并把这些共同的数据封装为基本的单元。利用对这些基本单元的组合来描述更加复杂的数据结构。
面向不同用户的多样化工具
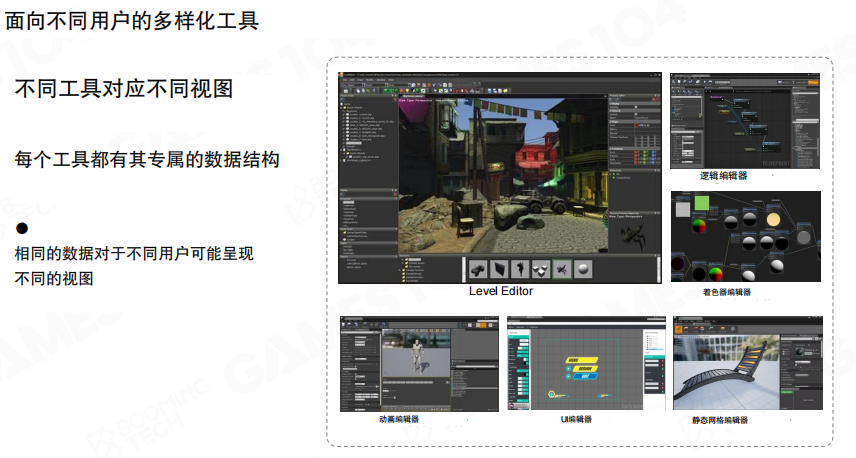
不同工具对应不同视图,每个工具都有其专属的数据结构。相同的数据对于不同用户可能呈现不同的视图。
工具链面对完全不一样的用户,每个用户的需求不一样。例如:
- Level Editor(关卡编辑器):用于构建游戏世界
- 逻辑编辑器(Logic Editor):用于编辑游戏逻辑
- 着色器编辑器(Shader Editor):用于创建材质和着色器
- 动画编辑器(Animation Editor):用于制作角色动画
- UI编辑器(UI Editor):用于设计用户界面
- 静态网格编辑器(Static Mesh Editor):用于编辑3D模型
这些工具为不同背景的开发者提供了不同的视图和数据结构,但都操作同一套底层数据。
所有工具分开开发的问题

如果每个工具都单独开发,这是最简单的方式,但存在明显问题:
- 无扩展性:工具之间无法沟通,数据无法共享
- 可维护性差:每个工具使用单独的数据定义方式,系统过于庞大且难以维护
工具链不是单一的工具,而是多个工具组成的系统。它们彼此之间需要有血缘关系,要彼此通讯,彼此联系,互相能听得懂。如果每个工具单独去写,工具链就没有可扩展性,也没有可维护性,因为这些数据全部都是异构的。
寻找通用构建模块
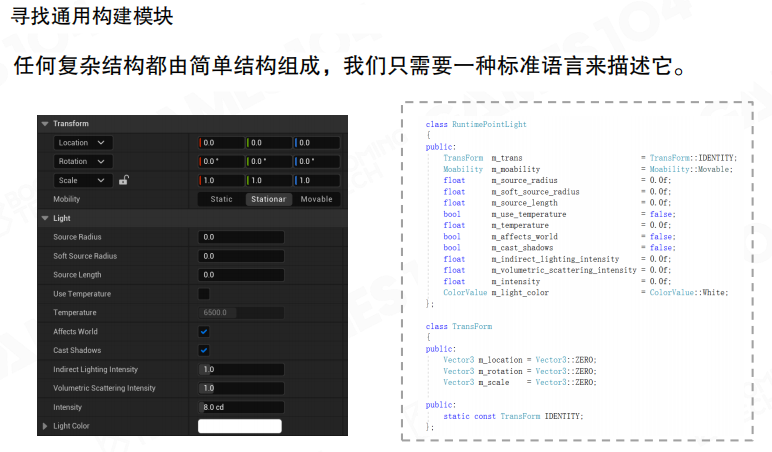
任何复杂结构都由简单结构组成,只需要一种标准语言来描述它。
当打开一个数据时,会发现再复杂的数据,都是由很多简单的building block构成的。例如描述一个点光源时,有Vector3的坐标位置、Vector3的方向、颜色等,这些都是非常基础的building block。
任何复杂的数据可以描述成一些简单数据的集合。就像物理学中,虽然世界非常复杂,但可以找到基础的原子,通过108种原子的组合去表达世界的任何一种物质。
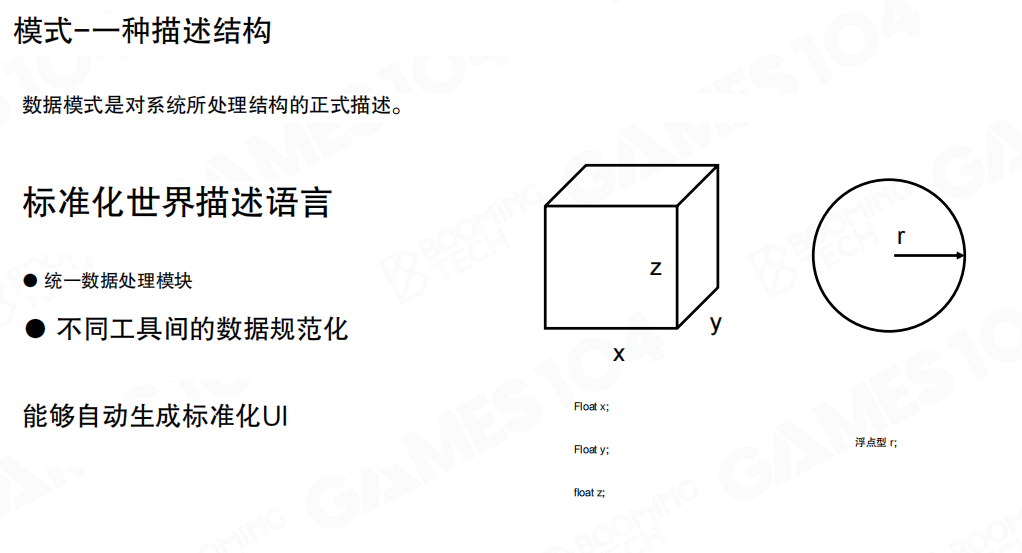
例如一个长方体,它的描述就是三个量:float x、y、z代表长宽高。如果要表示一个圆,就一个量float r就表示出来了。这个float加上一个结构,就是一个schema。
Schema
Schema-基本元素
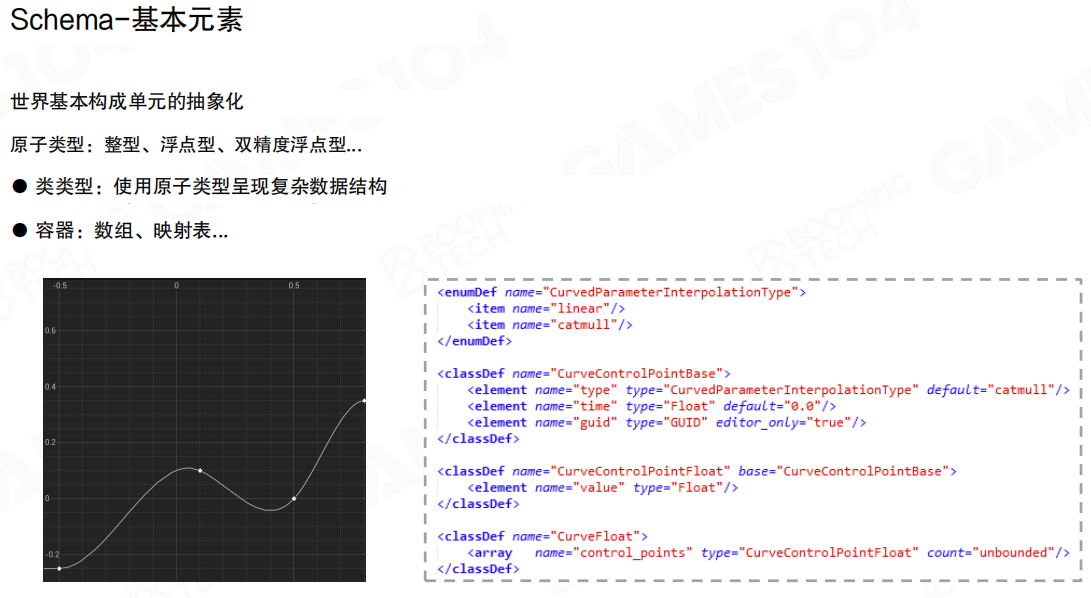
Schema(模式)是数据模式的简称,是对系统所处理结构的正式描述。Schema是世界基本构成单元的抽象化。
Schema的基本元素包括:
- 原子类型:整型、浮点型、双精度浮点型等
- 类类型:使用原子类型呈现复杂数据结构
- 容器:数组、映射表等
例如一条曲线(Curve)可以用一组控制点的集合来表达。每个控制点包含类型(CurvedParameterInterpolationType,如linear或catmull)、时间(Float)、值(Float)等属性。曲线本身就是一个控制点数组。
Schema-继承
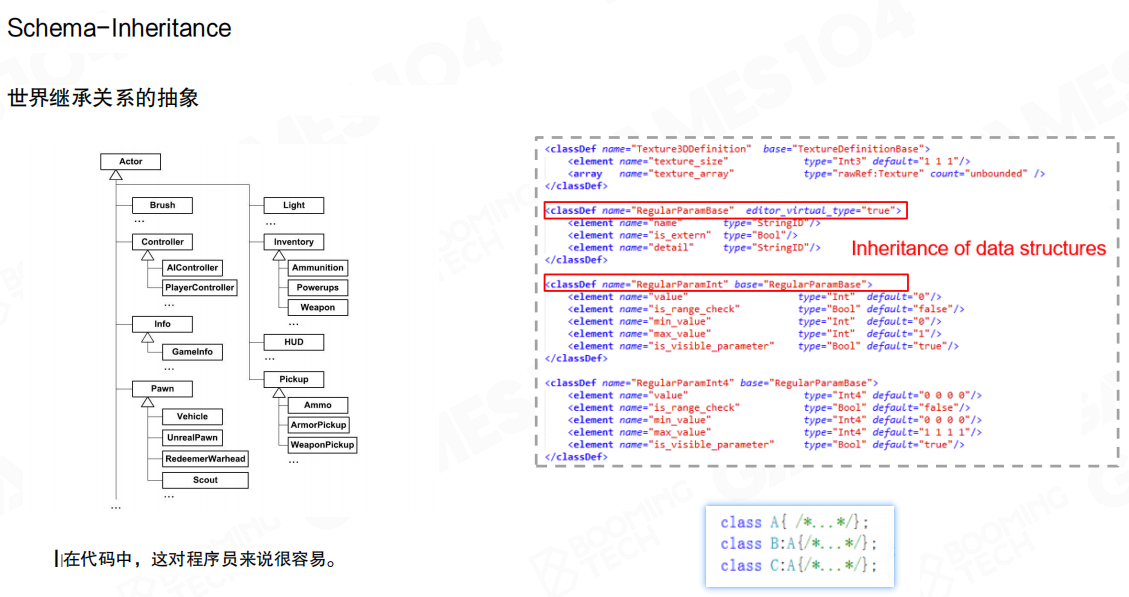
Schema需要支持继承关系,这非常像高级语言的类的派生继承。因为schema本身就描述了一种类。
例如定义一个”人”的schema,有身高、长相、体重等数据。然后可以派生”军人”schema,从人的schema派生出来,再加两个field:战斗力是多少、血量是多少。再派生”商人”schema,可以加有钱有多少、经商能力是多少。
在代码中,这对程序员来说很容易。例如Texture3DDefinition可以继承自TextureDefinitionBase,RegularParamInt和RegularParamInt4都可以继承自RegularParamBase。
Schema-数据引用

Schema中要允许互相引用数据。在定义车的描述时,有些field会指向另外一个资产和数据。
例如一个角色会引用到一堆文件:网格、动画、行为树等文件。在网格文件中,又会引用到纹理、贴图等文件。这样在数据定义层面会形成一个关系树。
在代码中,需要通过文件路径读取数据,并将其实例化为对应的文件类。例如texture_array可以定义为rawRef:Texture类型的数组,表示对Texture对象的数据引用。
Schema-定义方式
Schema的定义非常像高级语言,所以产生了两个流派:

独立模式定义文件
使用类似脚本的语言或XML、JSON等语言直接定义schema。例如Protocol Buffers使用.proto文件定义消息结构。
在代码中定义
使用高级语言(如C++)直接定义类,通过宏(如UCLASS、UPROPERTY)来描述这是一个可反射的数据。例如Unreal Engine使用C++类定义,通过宏标记需要反射的属性和方法。
不同定义方式的优缺点

独立模式定义文件
优点:
- 易于理解:文本格式清晰直观
- 低耦合:数据定义和工程实践彻底分离
- 避免引擎版本与架构版本不匹配的问题
缺点:
- 需要代码生成器:根据schema解析生成各种代码
- 版本不兼容问题:schema版本可能过新或过老,与引擎二进制版本不一致
- 在结构中定义函数困难:需要实现完整的语法
在代码中定义
优点:
- 轻松实现函数反射:可以直接定义方法
- 天然支持继承关系:C++的类继承机制
缺点:
- 难以理解:代码复杂度高
- 高度耦合:数据定义和引擎代码高度匹配
两种方法各有利弊,很难说哪个更好。独立文件方式需要代码生成器,容易出现版本不匹配问题。代码定义方式虽然复杂,但数据定义和引擎是高度匹配的,编译后整个系统就统一了,不太会出现版本不兼容。
引擎数据的三种视图
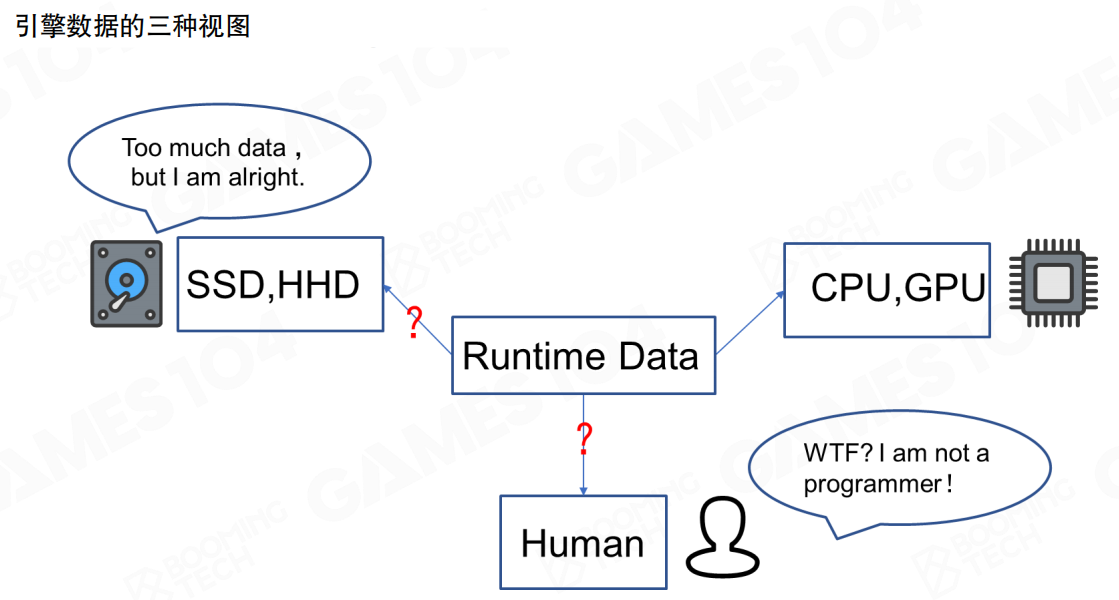
基于schema系统可以发现,同样的数据在游戏引擎的不同系统和工具中可能会有不同的表现形式。
- 存储视图(Storage View):数据存储在SSD、HHD中,存储空间很大,但需要考虑读写速度和空间需求
- 运行时视图(Runtime View):数据在CPU、GPU中处理,以运行和计算效率为第一要务
- 工具视图(Tool View):数据面向开发者,需要根据不同使用者的背景和需求来设计不同的数据表现形式
运行时视图

运行时视图的重点:
- 以更快的速度阅读:快速读取数据
- 以更快的速度进行计算:高效处理数据
在内存中,数据结构定义都是为了各种数学变换,例如加减乘除、拷贝添加删除速度快为依据。例如RuntimeSpotLight类包含light_trans(Matrix4x4)、inner_cone_radian、outer_cone_radian、intensity、light_color等属性,这些属性都是为高效计算而设计的。
存储视图
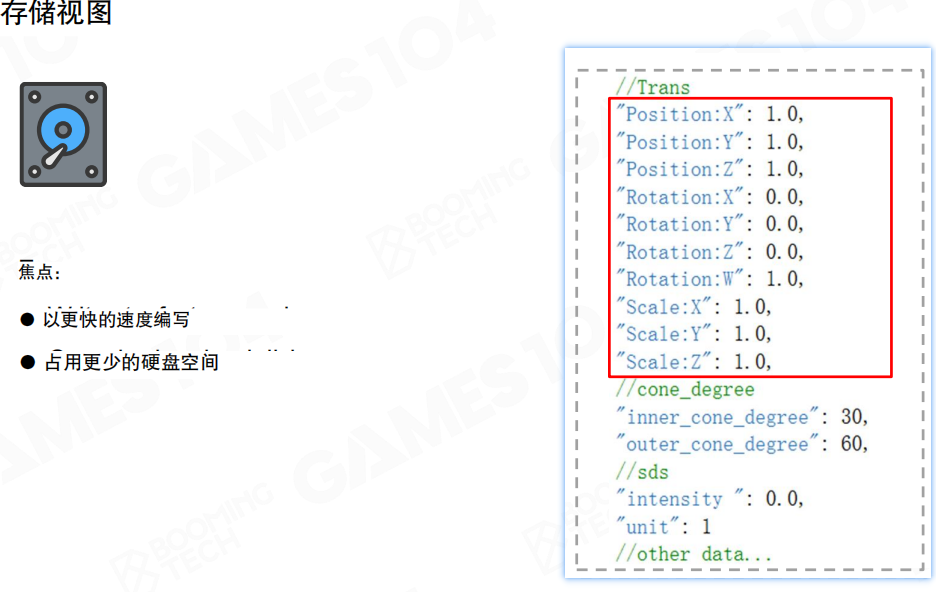
存储视图的焦点:
- 以更快的速度编写:快速写入数据
- 占用更少的硬盘空间:节约存储空间
在存储中,一般会尽量以节约存储空间为目标。例如一个矩阵,虽然它是4×4的矩阵,但实际上能用到的一般是4×3或3×3,这时会做很多数据的压缩处理。
存储格式可能是JSON格式,包含Position、Rotation、Scale等字段,以及inner_cone_degree、outer_cone_degree、intensity、unit等属性。
工具视图

工具视图的焦点:
- 更易于理解的形式:数据以人类可理解的方式呈现
- 多种编辑模式的需求:为不同用户提供不同的编辑模式
工具数据通常并不直接存在,一般在生成用户界面时会进行特殊处理。例如一个color,schema定义的是三个整数,但在工具里面会把它变成一个颜色选择器,用户可以看到非常符合人类理解的调色板。
工具视图-易懂性
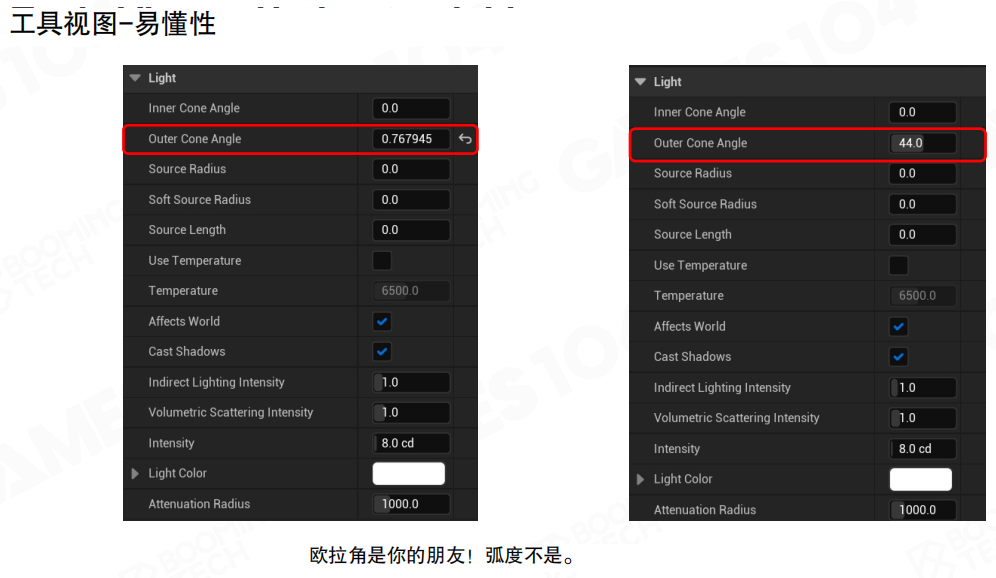
工具视图的核心是要对不同的人展开不同的view。
例如在设置一个引擎数据时,很多时候会设置角度。在引擎中一般用弧度,因为所有数学库的sin、cos、tan计算全部是基于弧度的。但跟艺术家讲输入一个3/4π,艺术家就懵了。这时工具中输出的全是欧拉角,比如270度、180度、360度、45度,这样人类就非常好理解。
工具视图应该使用度数(如44.0度)而不是弧度(如0.767945弧度),这样更符合人类的直觉。
工具视图-多种编辑模式
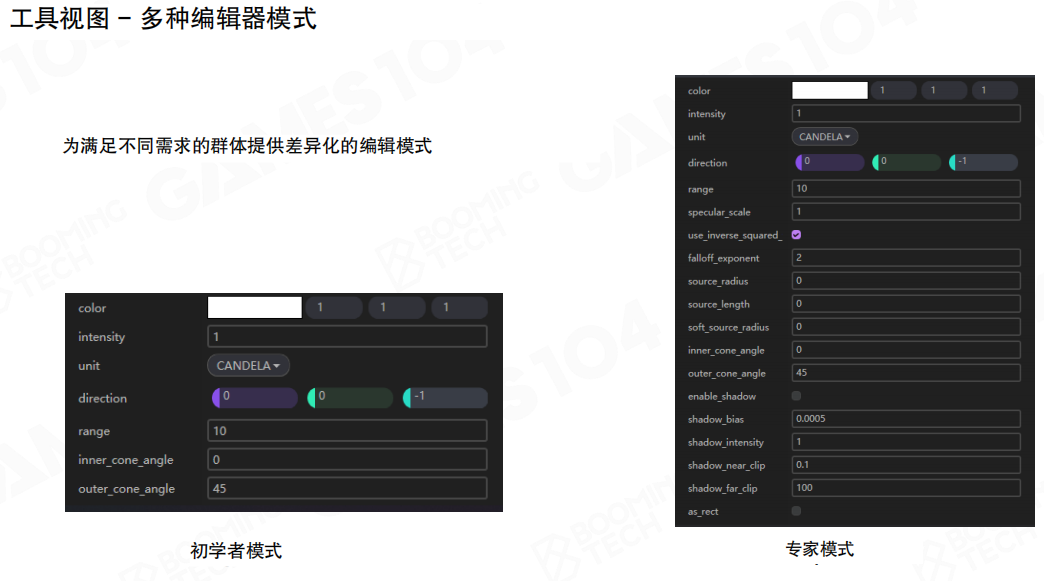
为满足不同需求的群体提供差异化的编辑模式这样可以为不同水平的用户提供不同的界面复杂度。
13.6 所见即所得
“你看到的就是你得到的。”
所见即所得(What You See Is What You Get,WYSIWYG)是现代游戏引擎工具链的核心设计原则:工具中的预览结果,应当尽可能与运行时的真实效果保持一致。对于生产流程来说,这意味着材质、光照、动画、物理等系统的表现不能在“编辑器视图”和“游戏中”出现明显偏差,否则会直接增加反复验证与返工的成本。
为什么 WYSIWYG 对生产效率至关重要
对工具链最敏感的两类人群,是艺术家与设计师:
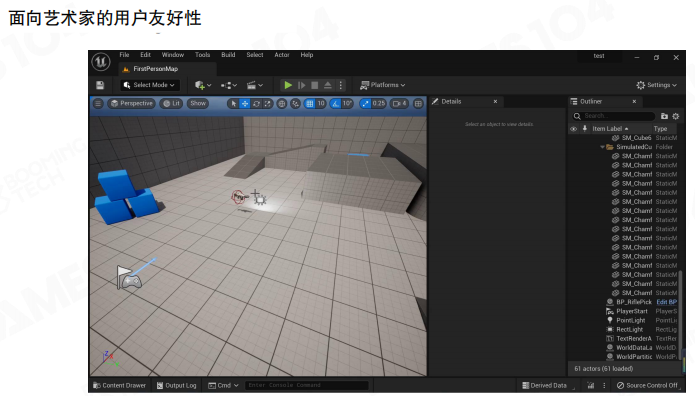
- 面向艺术家的用户友好性:艺术家需要一个可信的预览环境。如果在编辑器里调出的光照、材质质感、动作表现,进入游戏后出现差异,那么制作与调参会被迫在两套环境间来回对齐,效率会显著下降。
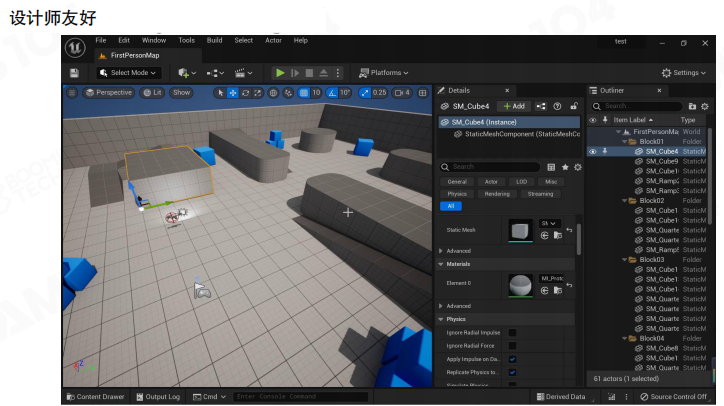
- 设计师友好:设计师把工具链当作快速原型(prototype)的基础设施。关卡布局、遮挡关系、可见性验证、交互与手感评估,都依赖编辑器提供稳定且可复现的预览与试玩能力。
工具链架构:从“独立工具”到“在游戏工具中”
早期引擎常见的做法,是将工具链实现为相对独立的系统:工具层与引擎运行时相对分离,通常只共享少量数据格式与底层算法。这样做的动机在于编辑器交互细节繁多(选择、拖拽、吸附、对齐、快捷键切换等),工程复杂度高,独立实现有利于隔离风险、降低对运行时的侵入。
独立工具(Standalone Tools)的优缺点:
- 优点:
- 适合做 DCC 工具插件(如导入、烘焙、资源处理等)
- 易于启动和迭代工具本身(工程更独立)
- 缺点:
- 难以实现所见即所得:工具侧的预览路径与运行时管线往往存在差异,最终效果需要额外验证与对齐

现代商用引擎更常用的架构,是将工具层放在引擎体系的最上层:工具直接调用引擎底层模块,尽可能复用运行时系统。这样做的目的,是让渲染、动画、物理、资源等关键系统在编辑器与游戏中走同一条路径,从架构上更容易满足 WYSIWYG。
在游戏工具中(In-Game Tools)的优缺点:
- 优点:
- 直接访问引擎数据,减少重复实现与数据搬运
- 便于在编辑器中预览游戏,预览更可信
- 更容易实现实时编辑(所改即所见)
- 缺点:
- 引擎架构更复杂:需要一套完整的引擎 UI 系统、编辑态数据与状态管理
- 强依赖引擎稳定性:引擎崩溃时,工具链也会一起崩溃


编辑器中的播放:PIE
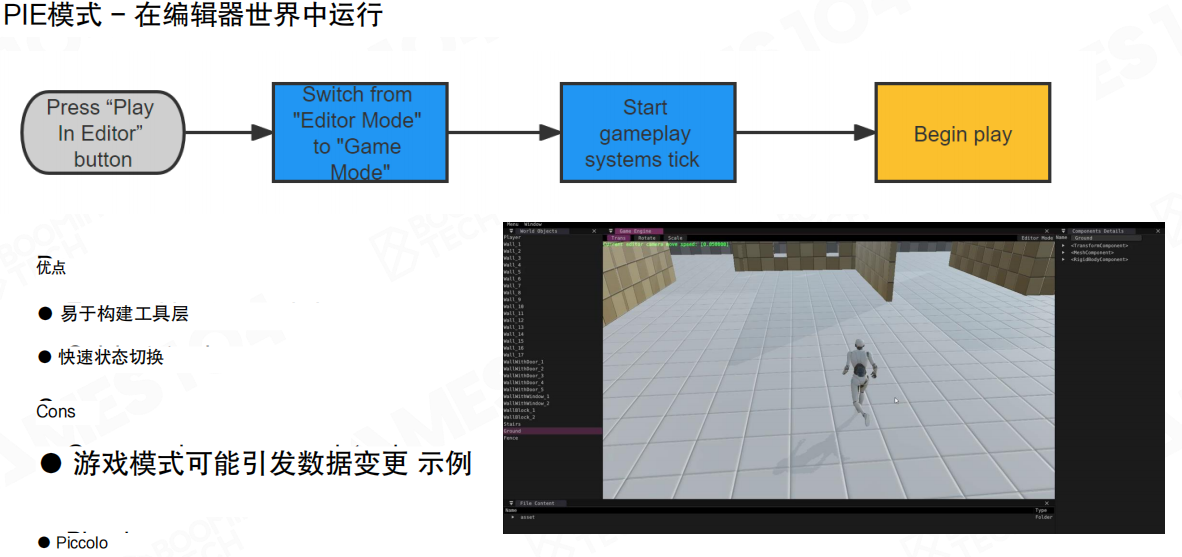
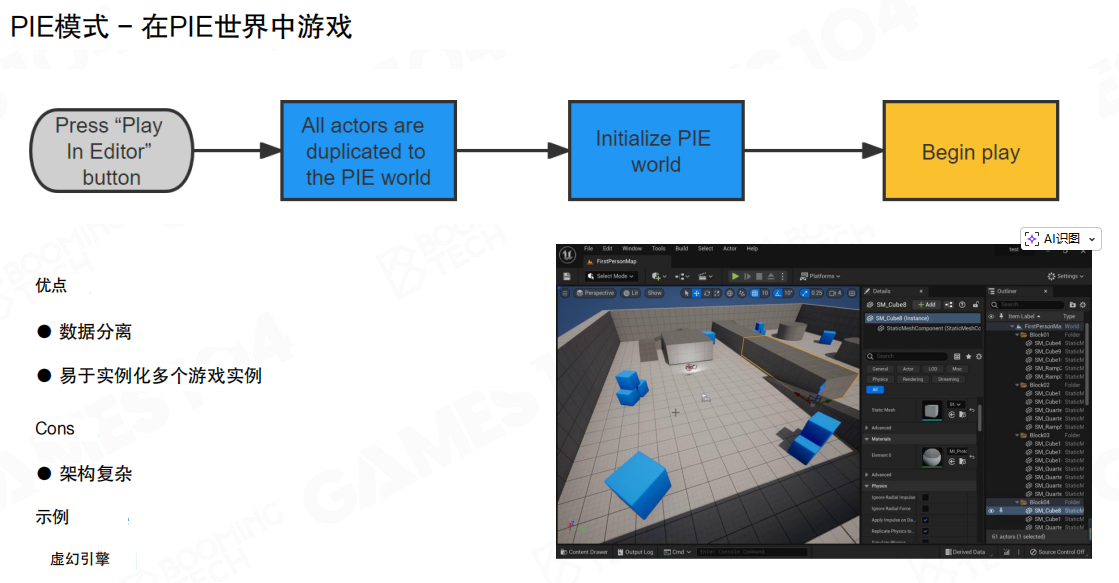
当工具层建立在运行时系统之上时,一个关键能力是 编辑器中的播放(Play In Editor,PIE)。
PIE 的目标是:无需退出编辑器,即可一键进入可游玩的游戏状态,从而节省加载时间、保持创作连续性,并快速验证修改。

在编辑器中进行游玩,常见有两种实现方式:在编辑器世界中运行 与 在 PIE 世界中运行。
在编辑器世界中运行
这种方式会在同一份世界里从“编辑状态”切换到“游戏状态”,启动 gameplay tick 并进入 BeginPlay。
优点:
- 易于构建工具层
- 状态切换快,编辑与游玩几乎无缝
缺点:
- 数据污染风险:游玩过程中产生的运行时状态可能混入编辑数据;长期来看可能出现编辑器与独立运行环境表现不一致的问题
在 PIE 世界中运行(沙盒/分身)
另一种方式是在点击 PIE 时复制当前编辑世界,生成一个独立的 PIE World:将相关 Actor 拷贝到沙盒世界并完成初始化,然后在沙盒里 BeginPlay。
优点:
- 数据分离:编辑数据与游玩数据相互独立,避免污染
- 更接近真实游戏环境:更容易暴露“打包后才会出”的问题
- 便于实例化多个游戏实例(多开/多窗口验证)
缺点:
- 架构更复杂:需要维护两份世界与跨世界资源/引用关系
- 额外内存开销:需要为沙盒世界分配额外资源
13.7 可扩展性
不同类型的游戏会对编辑器提出截然不同的定制需求:有的需要完整的水体交互调参界面,有的需要专用的关卡标注与分析工具,有的则需要把内部工作流固化为一套强约束的制作管线。作为引擎开发者,我们几乎不可能预先覆盖所有场景,因此工具链必须把“可扩展性”作为基本能力来设计。
插件是工具链可扩展性的载体
插件(Plugin)指能够为现有程序添加特定功能的软件组件。在工具链中,插件的价值主要体现在:
- 按需扩展:用户可根据项目需求补齐引擎未内置的工具能力。
- 可分享与可复用:插件能在团队或社区传播,形成生态,降低重复开发成本。
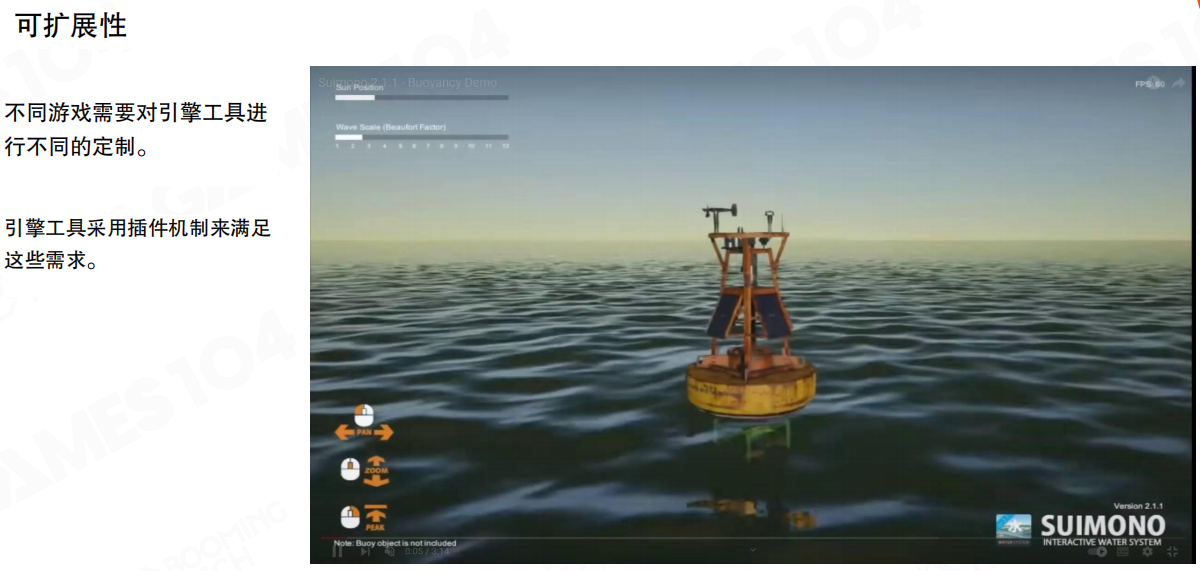
商业级引擎通常会提供良好的插件支持,方便用户开发并分享插件能力。下图展示了 Unreal 生态中常见的第三方插件形态:它为“水体交互”提供了可视化界面与参数调节能力,是典型的“引擎平台 + 第三方功能”组合。
插件框架的接口与 API
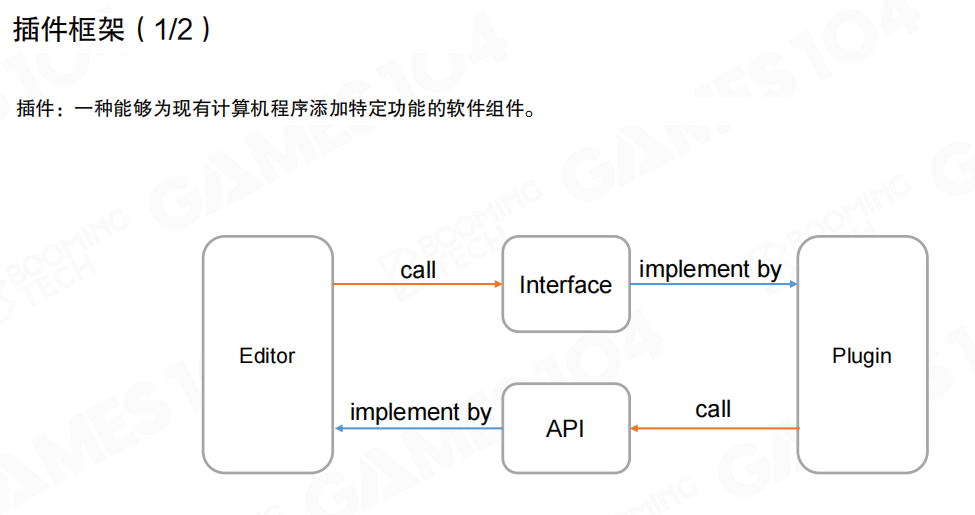
要让第三方插件安全、稳定地接入编辑器,常见做法是提供一套插件框架:编辑器与插件通过接口(Interface)与 API(Application Programming Interface)完成双向协作。
通常存在两条调用链:
- 编辑器通过 接口(Interface)调用插件能力(插件实现接口)。
- 插件通过引擎暴露的 API 调用编辑器/引擎能力(引擎提供 API)。
插件框架基础组件
一个最小可用的插件系统通常包含三类要素:
- 插件管理器(PluginManager):负责插件的发现、加载、初始化与卸载。
- 接口集合(Interface Set):提供给插件实现的一组抽象类型,约束插件的生命周期与对外交互边界。
- API 集合(API Set):引擎对外暴露的一组函数/服务,插件通过这些入口实现 UI 注册、资源访问、场景编辑等逻辑。

这里有一个关键的工程要求:编辑器自身的功能也尽量通过同一套 API 组合出来。这样第三方插件与引擎内置工具在能力层面尽可能一致,既能减少“对内特权”,也能反向推动 API 设计更完整、更稳定。
向编辑器 UI 添加工具入口
插件最常见的诉求之一,是把入口挂到编辑器 UI(工具栏按钮、菜单项、右键上下文菜单等)。实现方式通常是:
- 插件在初始化阶段通过 API 注册 UI 元素(按钮/菜单)及回调。
- 插件管理器在加载插件时驱动注册流程,编辑器统一管理这些扩展点。
- 用户触发 UI 后进入插件逻辑,再通过 API 操作场景与资源。
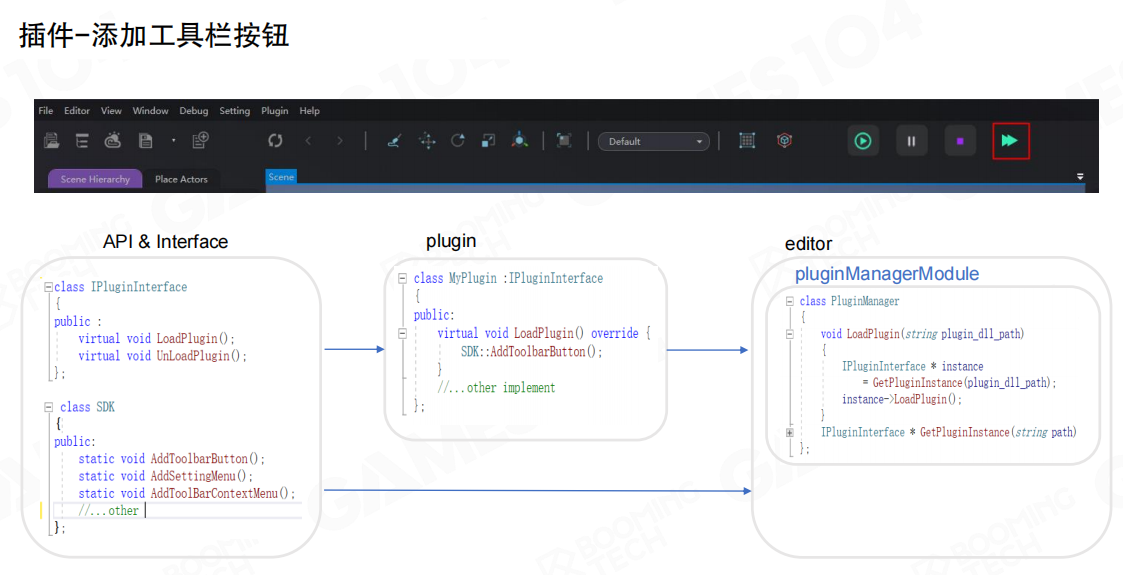
成熟商业引擎在插件接入上非常工程化。以 Unreal 为例,插件通常以模块(Module)的形式存在,实现统一的模块接口,并在启动阶段完成命令注册与菜单扩展。开发者在约定入口调用注册函数,即可把功能挂到编辑器主菜单或工具栏。
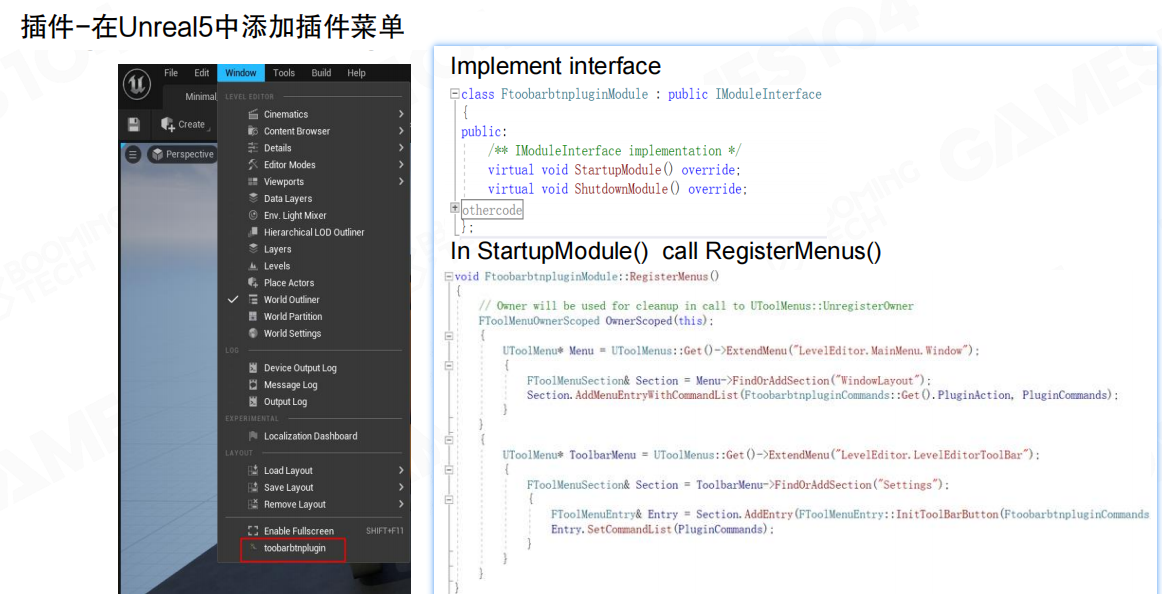
这种模式的重点不在于“能加一个菜单”,而在于它把编辑器能力拆成了可组合的 API,使第三方可以以较低成本接入,并且在引擎升级时保持相对稳定的扩展路径。
插件系统对工具链的要求
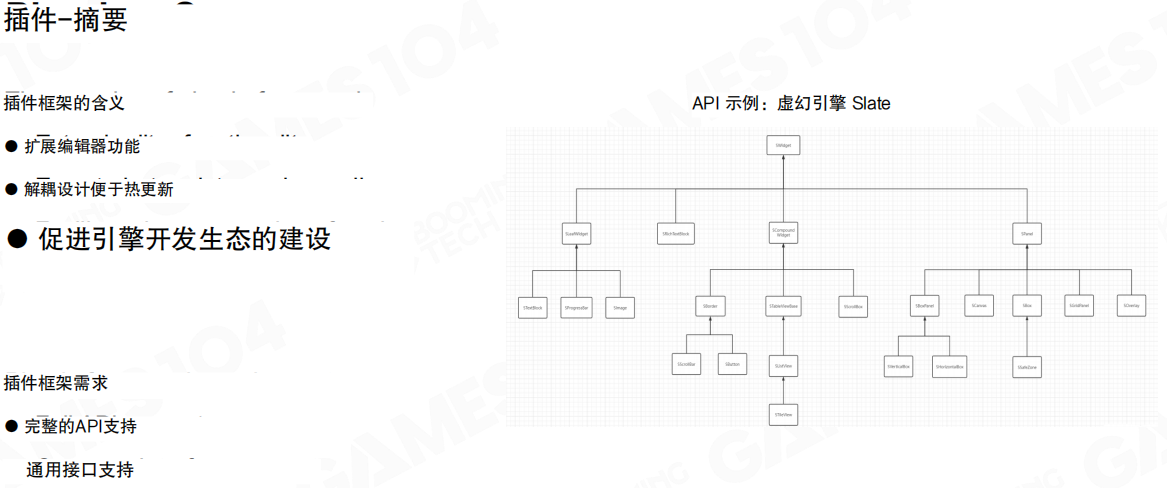
插件系统决定了工具链的上限。它既是扩展编辑器能力的方式,也是引擎生态形成的基础。要把插件做到“好用”,通常需要:
- 完整且稳定的 API 支持:覆盖 UI 扩展、资源与场景访问、序列化、事件系统等关键能力。
- 通用的接口支持:以接口约束插件生命周期与交互边界,便于管理与热更新。
- 平台化思维:将引擎视为平台,允许大量第三方开发者在其上协作、复用与迭代能力。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

