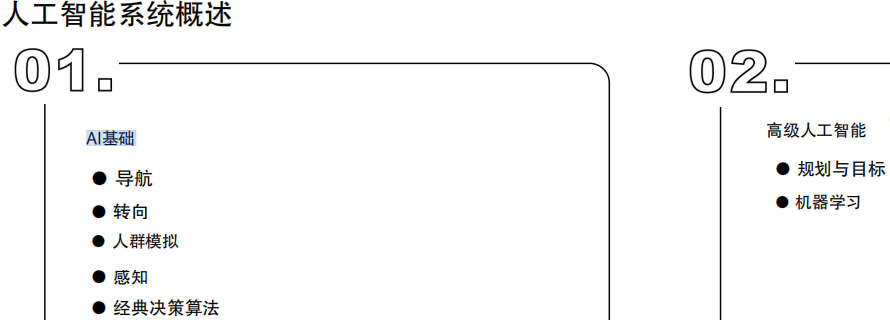
17.游戏引擎Gameplay玩法系统高级AI
17.1 AI课程大纲
17.2 层次任务网络
为什么需要HTN 从“反应机”到“任务与目标”
上一节的 行为树(Behavior Tree, BT)更像“反应机器”:世界抛出条件,树按分支给出反应。它非常稳定、非常可控,但当行为被拉长到“要完成一件事”时,语义往往需要依赖注释补充——树上堆满 Selector / Sequence 的组合,结构本身很难直接呈现“当前子树的目标”。这一节引入的 层次任务网络(Hierarchical Task Network, HTN)从“任务与目标”出发,把意图写进结构里:先声明要完成的任务,再把任务分解为子任务,并在每个步骤中选择最合适的方法。

HTN 在工业界并不陌生,很多商业游戏会把它作为高级 AI 的骨架。它的直觉是“像人一样先立一个目标,再做计划”,而不是只对刺激做条件反射。
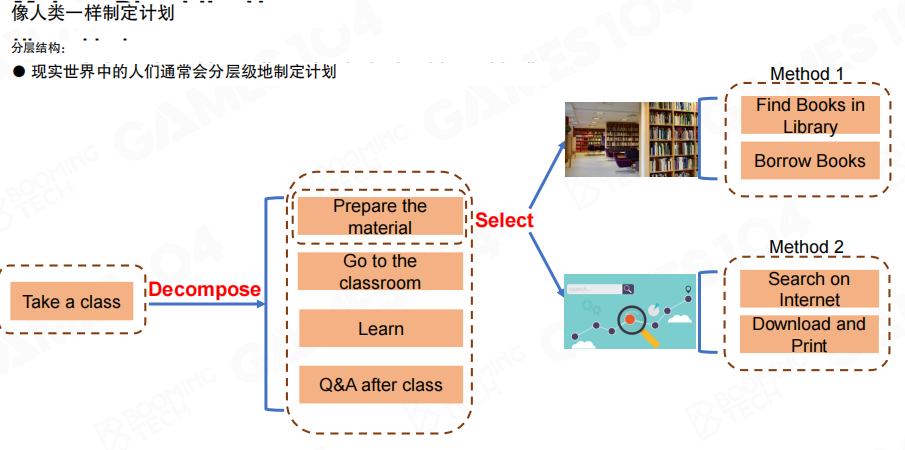
用“上课”举例:根任务是“上课”,可以被分解为“准备资料→去教室→学习→课后问答”。而“准备资料”并非只有一种做法:可以去图书馆(找书/借书),也可以上网(搜索/下载/打印)。这一类“先分解,再在分解点上选择方法”的表达方式,正是 HTN 想要显式建模的对象。
HTN框架 世界状态、传感器与规划执行链路
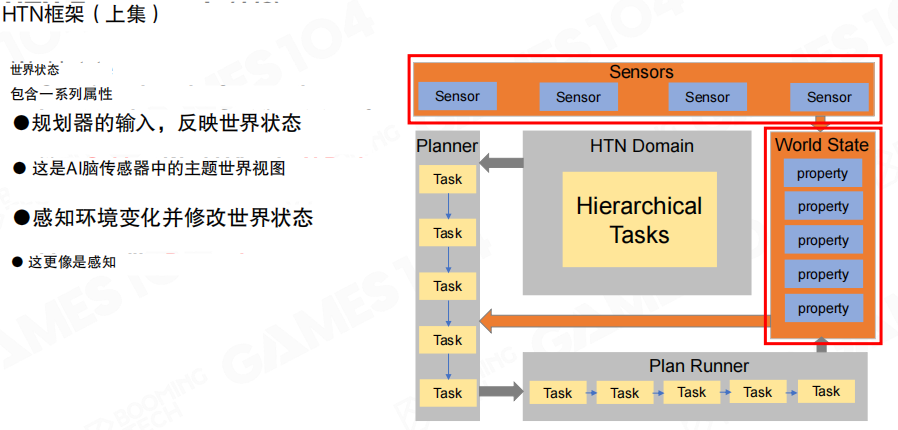
HTN 的第一层关键概念是 世界状态(World State)与 传感器(Sensors)。这里的“世界状态”并不是对外部世界的客观全量访问,而是 AI 内部对关键属性的主观刻画:只保留决策与规划需要的那些属性(例如资源、是否中毒、是否看见敌人等)。传感器负责从环境中取数,并据此更新这份内部世界模型。
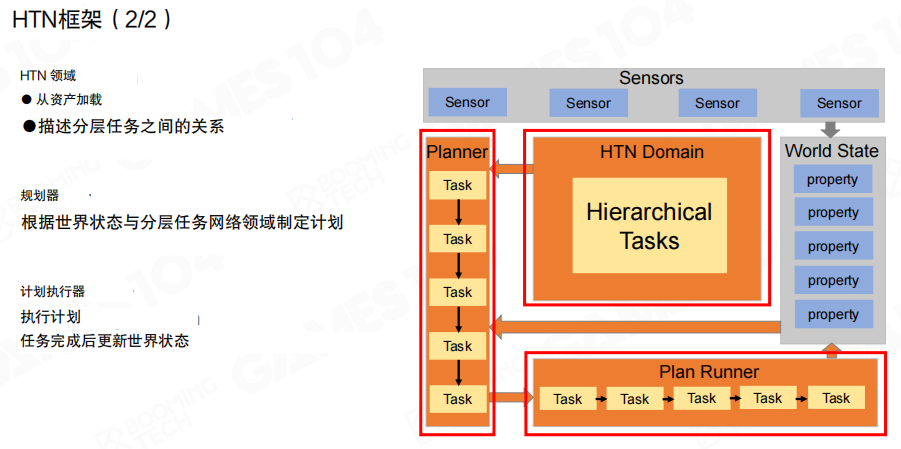
在这份世界状态之上,HTN 还需要三块骨架:
- 领域(HTN Domain):描述层次任务、方法与它们之间的关系,可理解为“任务知识库”,通常是从资产加载出来的数据。
- 规划器(Planner):根据当前世界状态,在领域中选择合适的任务与方法,生成一个可执行的计划。
- 计划执行器(Plan Runner):按顺序执行计划中的任务,并在任务完成后更新世界状态。
任务建模 基础任务与复合任务

HTN 的第二层关键概念是 任务类型。HTN 通常把任务分成两类:基础任务(Primitive Task)与 复合任务(Compound Task)。
基础任务 前置条件 / 动作 / 效果
基础任务更接近“一个动作”,它必须能回答三件事:
- 前置条件(Precondition):在当前世界状态下,这个动作是否允许执行。
- 动作(Action):实际执行的逻辑(脚本、动画、移动、交互等)。
- 效果(Effect):动作成功后如何修改世界状态属性。
把前置条件与效果写清楚,等价于明确“读取什么状态”与“写回什么状态”。规划阶段需要靠这些读写关系把任务串成链路;执行阶段也需要靠它把世界状态持续刷新。

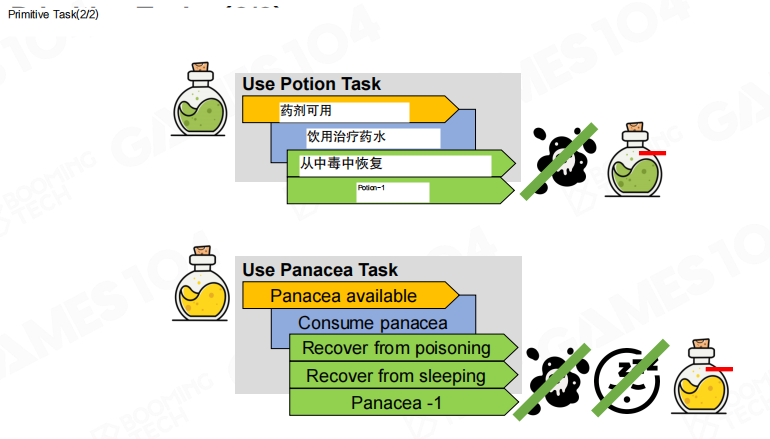
图里给出“使用药水/万能药”的基础任务示例:前置条件分别是“药剂可用/万能药可用”,动作是“饮用”,效果既包含状态恢复,也包含库存减少。这种“动作改变世界”的显式建模,是 HTN 能做规划的基础。
复合任务 方法选择与任务链
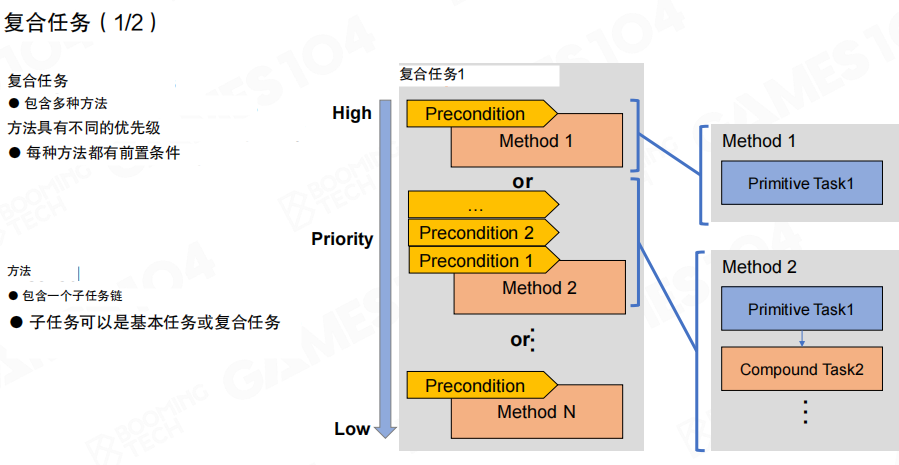
复合任务更接近“一个目标”,它不直接落到动作,而是提供多个 方法(Method):
- 方法之间有 优先级(Priority),从高到低尝试。
- 每个方法都有自己的 前置条件(Precondition),用于判断此方法是否可用。
- 每个方法不是“单一步”,而是一条任务链:链上既可以是基础任务,也可以继续嵌套复合任务。
直观类比上一节:方法选择像 选择器(Selector),方法内部的任务链像 顺序节点(Sequence)。但 HTN 把“要完成的任务是什么”放到了最外层,语义更直接。
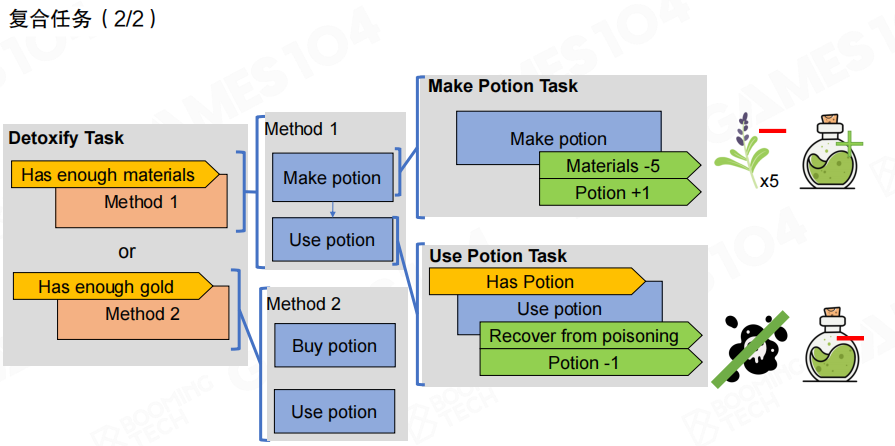
图里用“解毒”展示复合任务的展开:优先方法是“材料足够→制作药水→使用药水”,若材料不够,再尝试“金币足够→购买药水→使用药水”。计划不再是一堆条件分支的堆叠,而是“目标→方案→步骤”的结构化表达。
构建领域 从根任务出发组织层次结构
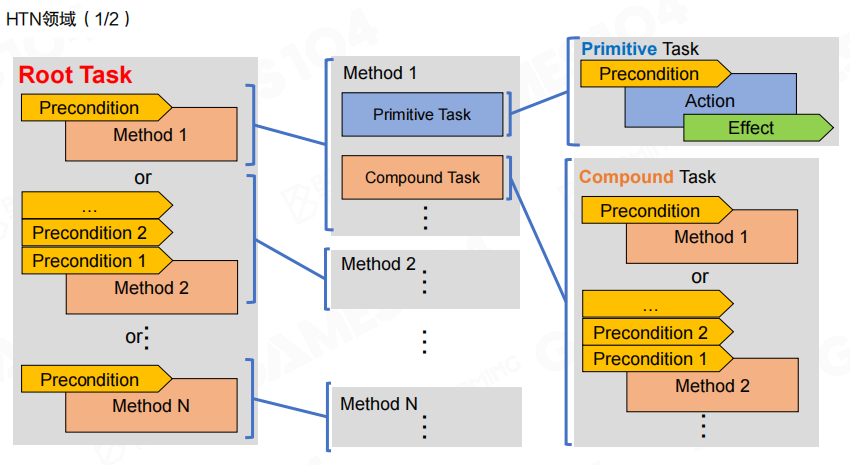
当基础任务与复合任务准备就绪后,可以构建 领域(HTN Domain):从 根任务(Root Task)出发,向下连接多个方法,再连接任务链,直到落到基础任务。根任务往往代表一个高层意图集合(例如战斗、逃跑、生存等),它决定了 AI“优先想做什么”。
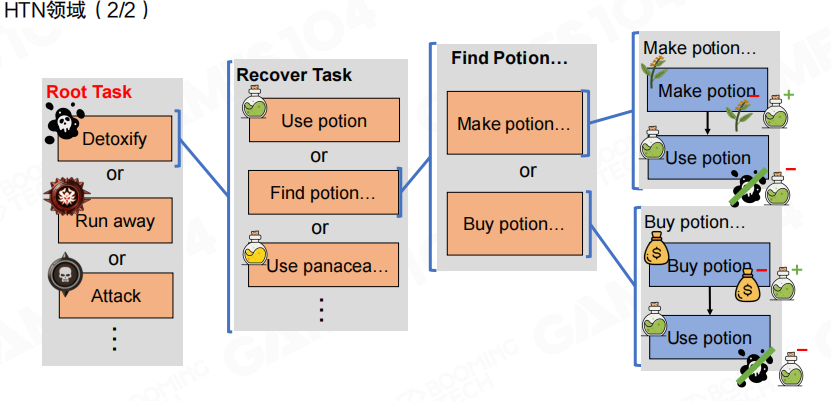
图里给出一个更完整的领域示例:根任务可以在“解毒/逃跑/攻击”等目标间选择;“恢复”又可以继续分解为“用药/找药/用万能药”;“找药”还能分解为“制作/购买”。这类结构的优点是:任务语义与分层关系在图上是直接可读的。
规划与执行 先生成计划,再按序运行
有了领域之后,HTN 的核心工作变成两件事:规划(Planning)与 执行(Running)。
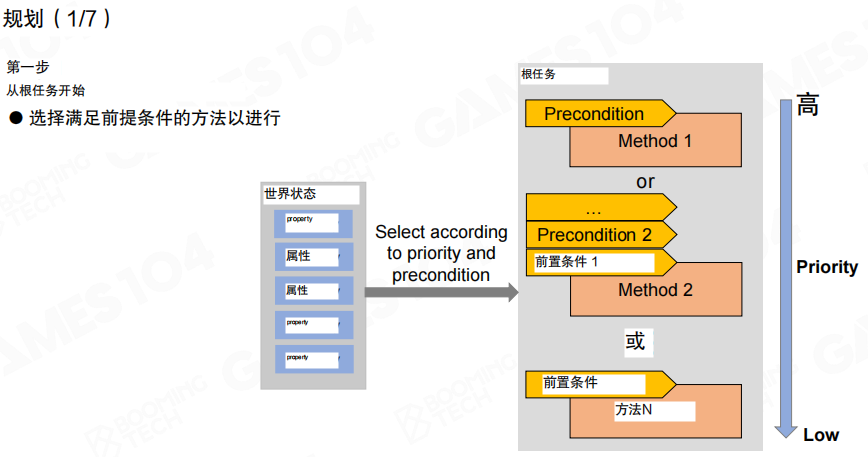
规划的第一步是“选方法”:从根任务出发,依据当前世界状态,按优先级检查方法前置条件,选择第一个满足的方案。
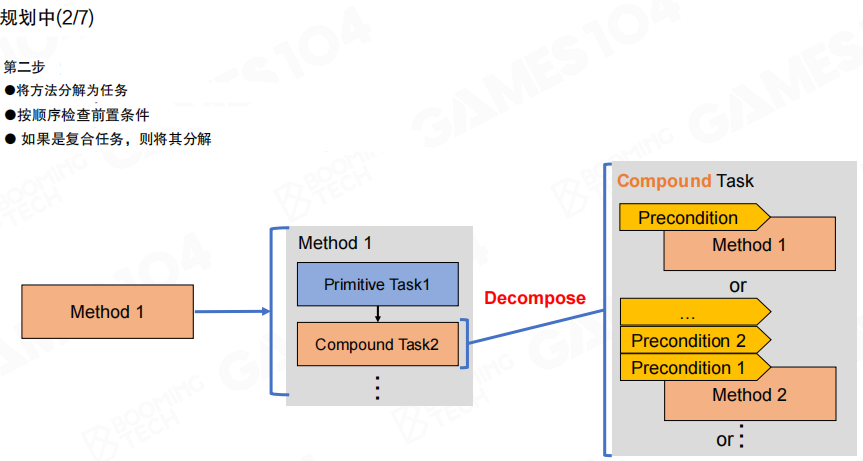
规划的第二步是“做分解”:把选中的方法展开为任务链,链上遇到复合任务就继续分解,直到尽可能落到基础任务。
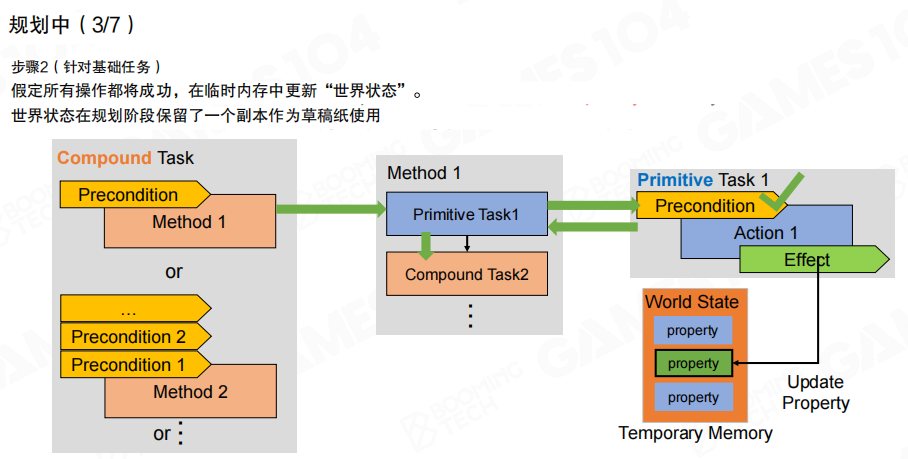
当分解遇到基础任务时,规划阶段会做一个关键技巧:在临时内存里维护世界状态的 副本(Temporary Memory)。规划器假设动作成功,并用任务效果更新这份副本,从而让后续任务的前置条件能够被满足(例如“先买到药水”,才能“再使用药水”)。
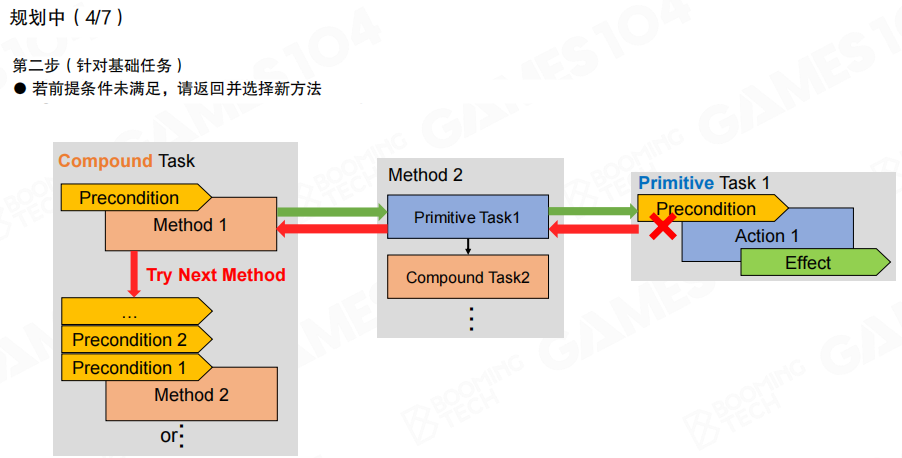
如果某个基础任务的前置条件不满足,就回退到上一级复合任务,尝试下一个方法(Try Next Method)。规划本质上是在“可用方法空间”里做回溯搜索。
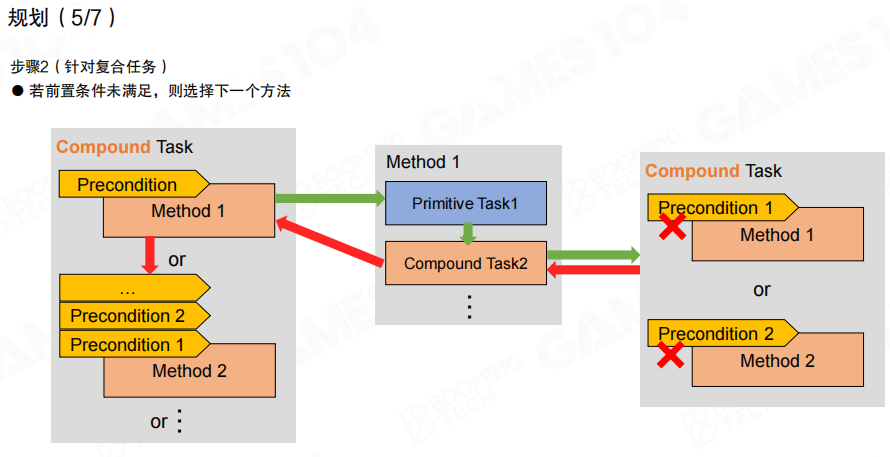
同样地,当分解到某个子任务失败时,失败会向上回传,促使上层复合任务切换方法;如果所有方法都不可用,失败会继续向上回传,直到根任务。
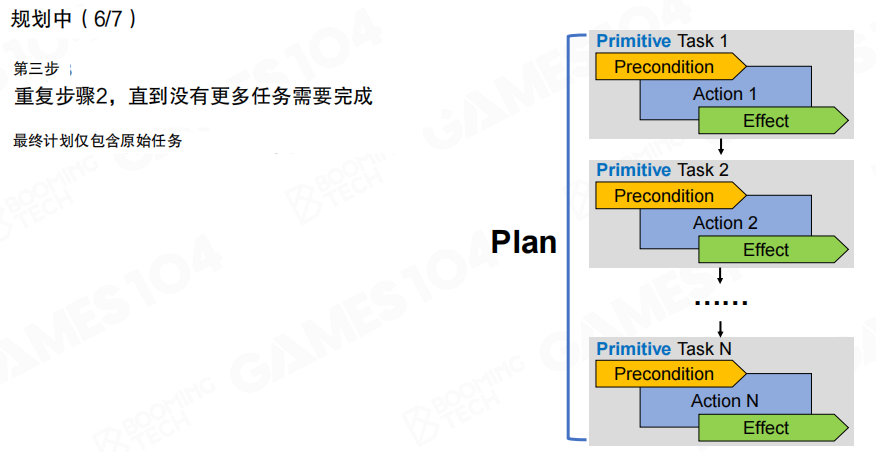
当分解与回溯结束,规划器最终输出的是一个 计划(Plan):由一串基础任务组成的线性序列。复合任务与方法在规划完成后不再出现在结果中,留下的是可直接执行的原子动作列表。
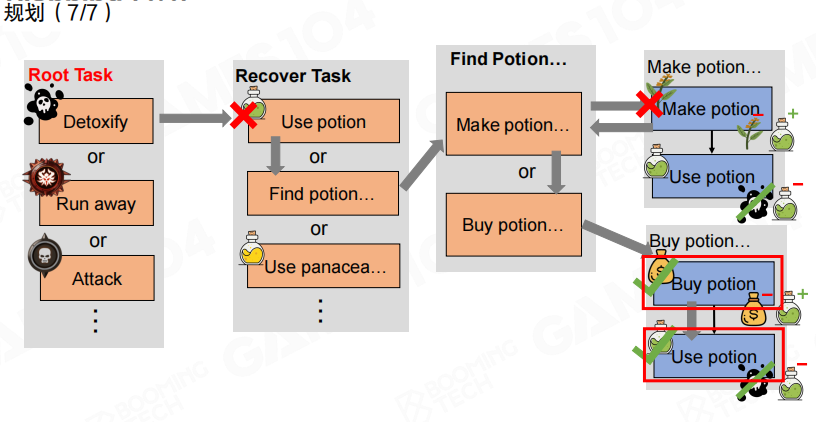
图里给出一个典型路径:在“找药”的分解中,“制作药水”因为条件不满足而失败,于是切换到“购买药水”,最后得到“购买→使用”的基础任务序列(红框标出最终落地的动作)。

执行阶段由计划执行器按序推进:
- 执行每个基础任务前,先检查前置条件;不满足则直接失败。
- 满足则执行动作;动作成功后写回世界状态(应用效果),并继续下一个任务。
- 直到全部成功,或任意一个任务失败为止。
重规划 计划失效时如何恢复稳定性
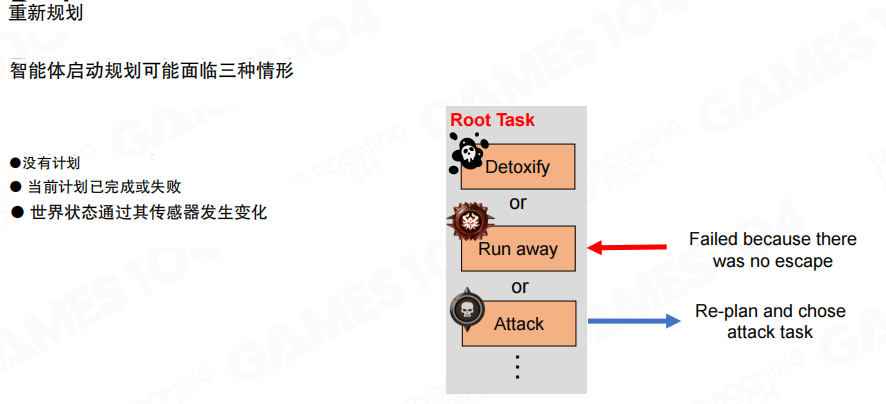
由于游戏世界是动态的,计划并不总能一路走到底,因此需要 重规划(Re-plan)。常见触发场景包括:
- 当前没有计划。
- 当前计划执行完毕或执行失败。
- 传感器更新导致世界状态关键属性发生变化。
图里示例是“逃跑失败(没有逃生路径)→重新规划并选择攻击”。这类“环境变化后尽快换目标”是 HTN 稳定运行的关键。
小结

小结:
- 优点:HTN 与行为树相似,但抽象层级更高;输出的是带长期效应的计划;在相同情形下通常比行为树更快(不需要每帧从根反复遍历整棵树)。
- 缺点:玩家行为难以预测,任务链容易失败;世界状态、前置条件与任务效果的设计需要高度一致性,否则会出现“计划生成困难”或“频繁重规划导致行为抖动”等工程问题。
17.3 目标导向行为规划
什么是GOAP
目标导向行动规划(Goal-Oriented Action Planning,GOAP)是一类以“目标”为中心的规划(Planning)方法。与偏反应式的结构相比,GOAP 的自动化程度更高,核心不是把行为路径写死,而是把“能做什么”和“想达成什么”形式化交给规划器求解,因此更适合应对环境变化带来的分支。
课程中给出的工程侧例子包括《中土世界 暗影魔多》《古墓丽影》《刺客信条 奥德赛》等,重点在于 GOAP 能让 AI 行为更具环境适应性,并减少对设计师手工枚举分支的依赖。
这类方法常见的工程直觉是反向规划(Backward Planning)。与“从当前状态一步步正向推导”不同,规划从目标状态出发倒推需要满足的前置条件,再倒推需要的动作与资源链路,直到落回当前世界状态可执行的动作序列。

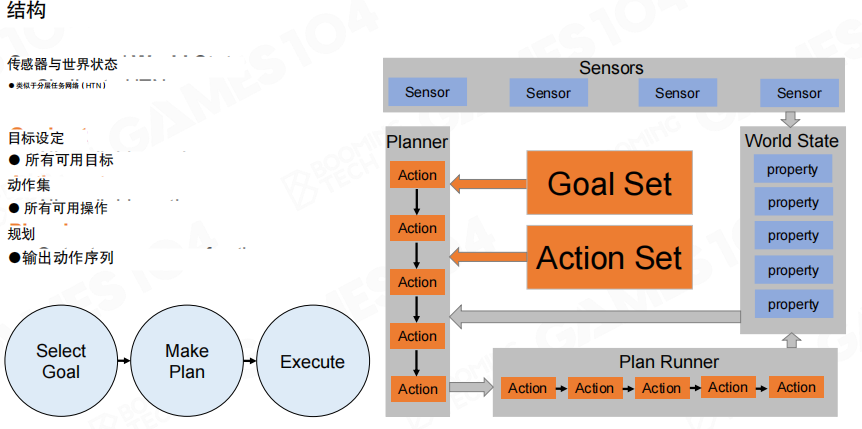
结构与数据
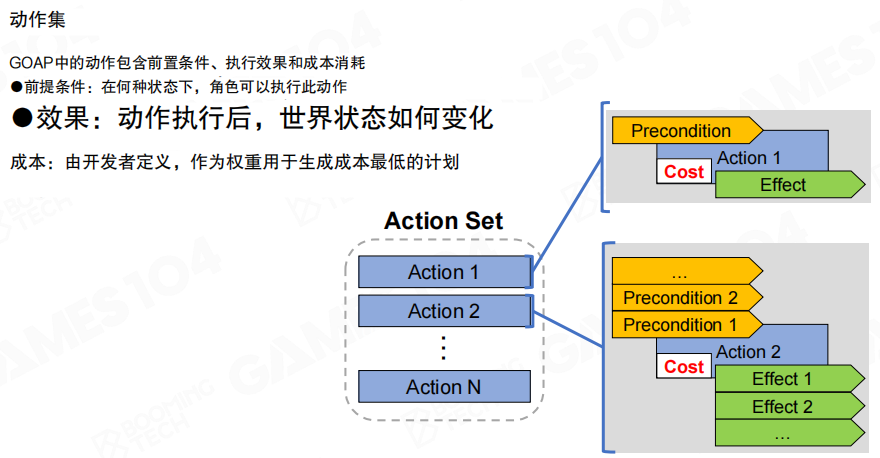
GOAP 的整体框架与 HTN 在形态上相近,同样围绕“感知→世界状态→规划→执行”展开,但 GOAP 把领域知识从“任务分解树”切换为两组显式集合。
- 目标集(Goal Set):AI 可能追求的目标集合。
- 动作集(Action Set):AI 可用的动作集合。
- 世界状态(World State):由传感器更新的一组属性(property),作为规划输入与执行校验的依据。
- 规划器(Planner):根据目标与动作定义生成一个动作序列。
- 计划执行器(Plan Runner):按序执行规划结果,并在必要时触发重规划。
图中 “Select Goal → Make Plan → Execute” 对应了 GOAP 的基本运行节拍,即每轮先选目标,再生成计划,最后执行计划。
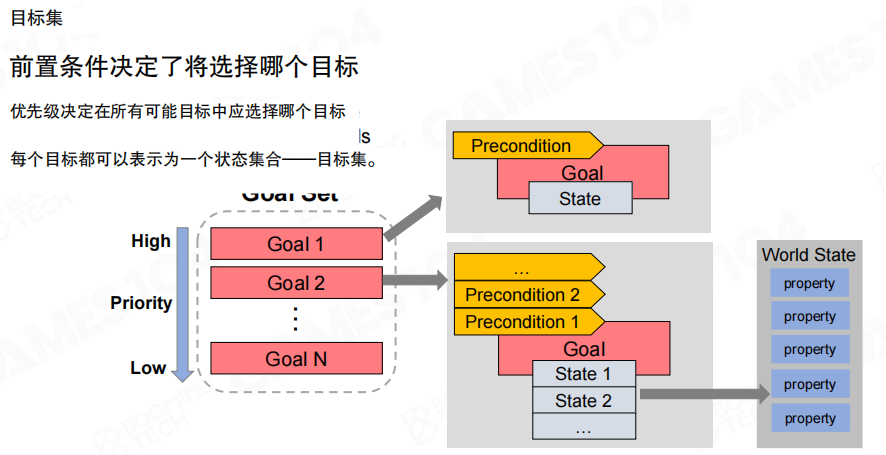
目标集合
在 GOAP 中,目标不是写在结构注释里的语义,而是需要被严格定义的数据对象。每个目标通常包含两部分信息。
- 前置条件(Precondition):用于判定该目标在当前世界状态下是否可以被选择。
- 目标状态(Goal State):用一组期望达成的状态集合来表达目标本身。
图里强调了两个维度的选择逻辑。
- 优先级:在所有候选目标中形成从高到低的序列。
- 前置条件:决定当前这一刻是否应当选择某个目标。
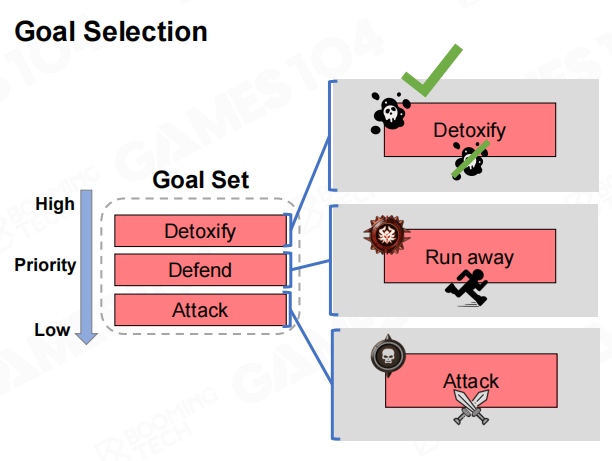
上图给出一个更贴近游戏语境的目标选择示例。目标集内同时存在“解毒”“逃跑”“攻击”等目标,但是否选择“解毒”取决于其前置条件是否满足(例如当前处于中毒状态)。这种“目标显式化”的做法,使得目标选择可以从行为结构中解耦出来,成为一段可复用的判定逻辑。
动作集合
动作集可以类比为“可执行操作库”,与 HTN 的基础任务在元素上相似,但 GOAP 还需要为规划求解补足一个关键量。
- 前置条件(Precondition):动作可执行所需满足的条件。
- 效果(Effect):动作执行后对世界状态产生的改变。
- 成本(Cost):由设计或工程规则定义的代价,用于在多条可行计划中选择“更优”的一条。
图中展示了动作与世界状态的联系方式,规划器通过“前置条件/效果”把动作串成序列,再利用“成本”对候选序列进行比较。
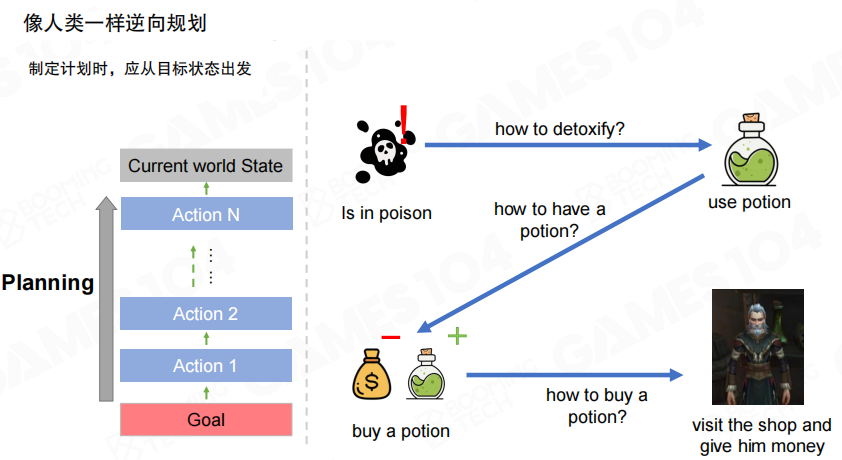
反向规划的直觉
上图用“中毒→解毒”的链路解释反向规划的直觉。目标是“解毒”,最后一步往往是“使用解药”;为了“使用解药”,需要先“获得解药”;为了“获得解药”,可能需要“购买解药”,再倒推到“前往商店并支付”。这种从目标倒推依赖链的方式,适合把“资源获取”“替代方案”统一到同一套求解框架里。
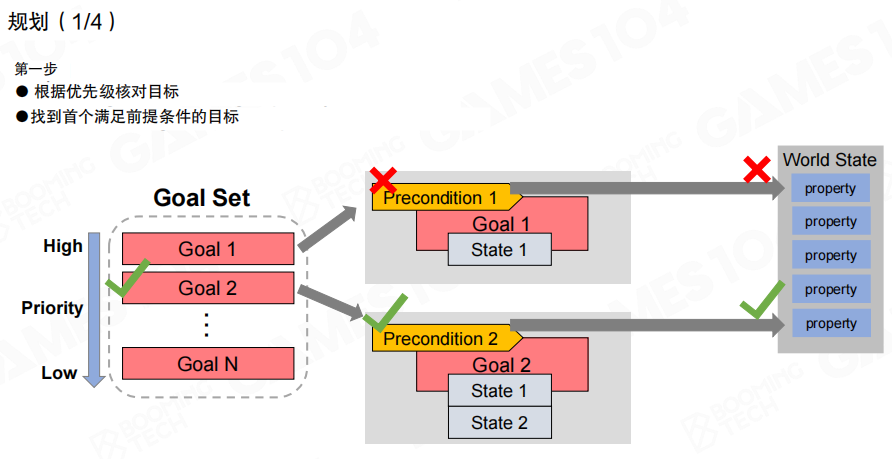
规划流程
选定目标
第一步是从目标集中按优先级扫描,并用目标的前置条件与当前世界状态做匹配,选出当前轮次的目标。图中用对勾与叉号表示不同目标的前置条件是否被世界状态满足。
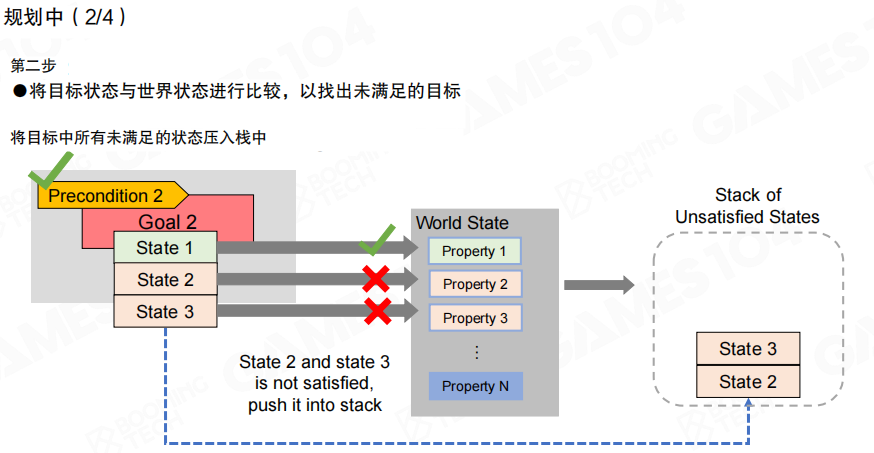
构建未满足状态栈
第二步是把目标状态与世界状态进行比较,将目标中尚未满足的状态压入未满足状态栈(Stack of Unsatisfied States)。图里示例是“目标包含多个状态”,其中部分状态与世界状态不一致,因此需要进入栈中等待被满足。
选择能满足状态的动作
第三步从未满足状态栈顶取出一个状态,在动作集中寻找“效果”能够满足该状态的动作,并评估该动作的可行性。图中展示了一个动作通过效果 “Set State 3” 来满足目标状态,同时动作自身仍然带有若干前置条件与成本。
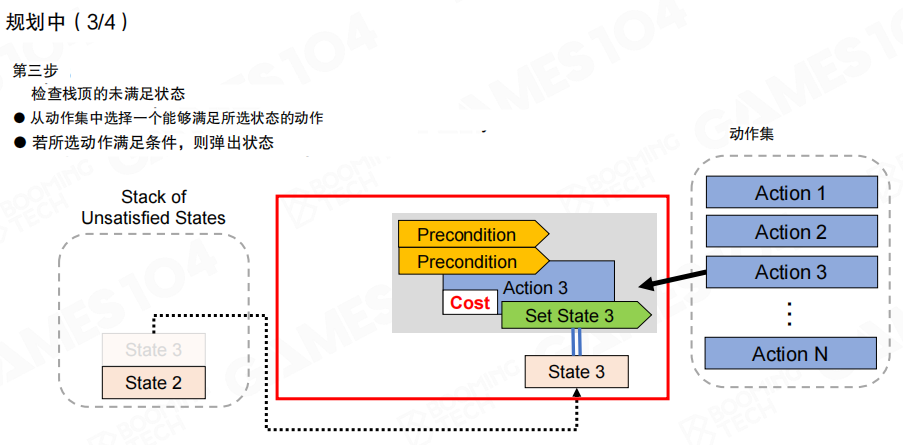
推入计划栈并递归处理前置条件
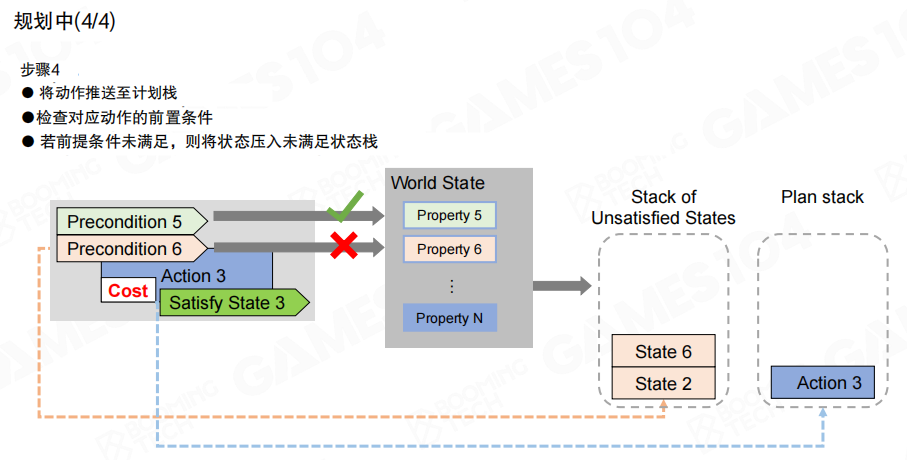
第四步把选中的动作推入计划栈(Plan Stack),并检查该动作的前置条件是否在当前规划上下文中已满足;若仍未满足,则把这些前置条件反向压回未满足状态栈,继续执行“选择动作→推入计划”的循环。目标是让未满足状态栈逐步清空,从而得到一条可执行的动作序列。
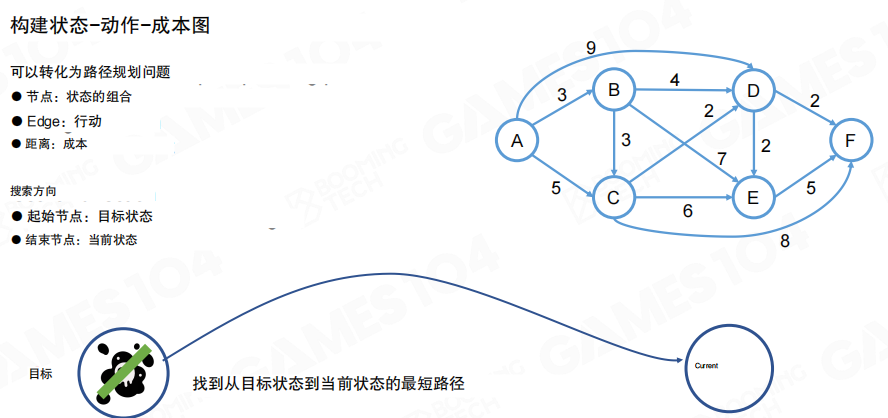
从规划到图搜索
当目标与动作都由“状态集合”连接起来时,规划问题可以转化为图上的路径问题。
- 节点(Node):世界状态的组合。
- 边(Edge):可执行动作。
- 权重(Weight):动作成本。
图中强调了一个与寻路相似的设定。由于规划采用反向推导,搜索方向往往是从“目标状态”出发,寻找回到“当前状态”的最短路径。
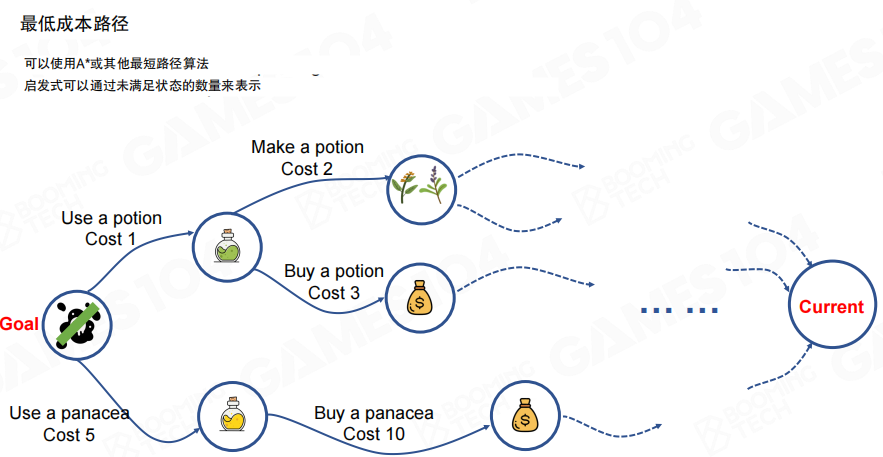
在图模型下,求解“最低成本计划”就等价于求最短路径,常用算法包括 A星(A*)等。图里给出多条“获得并使用解药”的候选链路,每条链路由若干动作组成并累积成本,规划器输出的计划就是其中成本更低且可达的一条。
小结

小结:
- 优势:与 HTN 相比,GOAP 往往更动态;把目标与动作解耦为两组显式集合,环境变化时同一目标可生成不同执行路径;在一定程度上缓解“前置条件与效果不匹配导致计划难以成立”的问题。
- 挑战:规划求解需要额外计算开销,运行速度通常慢于 行为树(Behavior Tree)/有限状态机(Finite State Machine)/层次任务网络(Hierarchical Task Network);同时依赖一个足够可表达的世界状态,以及一致的动作前置条件与效果定义,否则规划质量与稳定性会受到明显影响。
17.4 蒙特卡洛树搜索
为什么需要MCTS
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一类把“规划与决策”交给搜索过程的方法。典型代表是 AlphaGo(AlphaGo),以及一些回合制策略游戏的宏观决策系统。与手工枚举规则相比,MCTS 的行为往往更具多样性,适合在巨大搜索空间里做近似求解。

把 MCTS 类比成“下棋式思考”更容易把握其工程动机。决策并非只看眼前一步,而是在内部快速推演大量分支,再从中选出更优的一步作为输出。
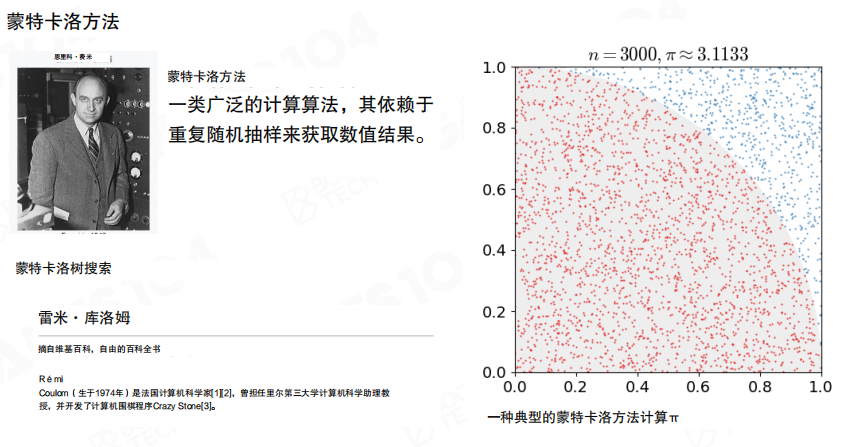
MCTS 的 “Monte Carlo” 来自蒙特卡洛方法(Monte Carlo Method),其核心是通过重复的随机采样来估计复杂量。直观理解是“用足够多次采样换取稳定的统计结论”。
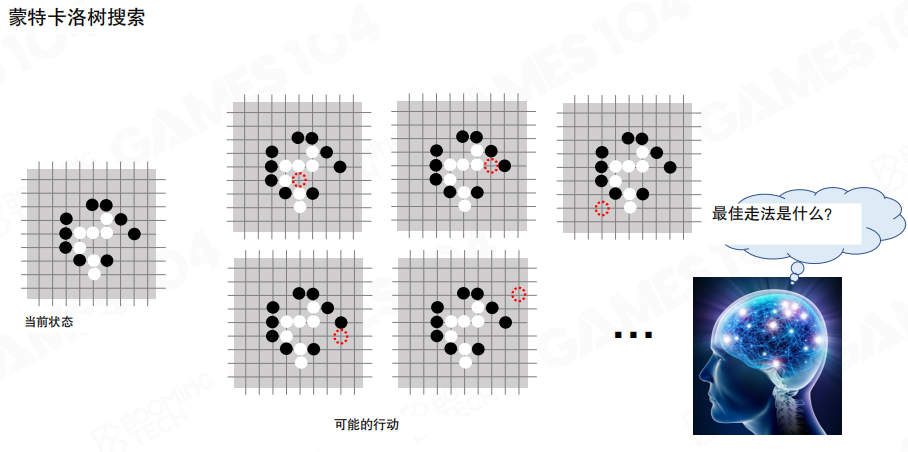
建模 状态、动作与状态空间
以围棋为例,当前局面对应一个状态(State),合法落子对应一组动作(Action)。决策的本质是从当前状态出发,在可行动作中选出“更值得执行”的那个。
为了让搜索可计算,需要把问题表达成“节点与边”的形式。最常见的建模方式是节点表示状态、边表示动作。
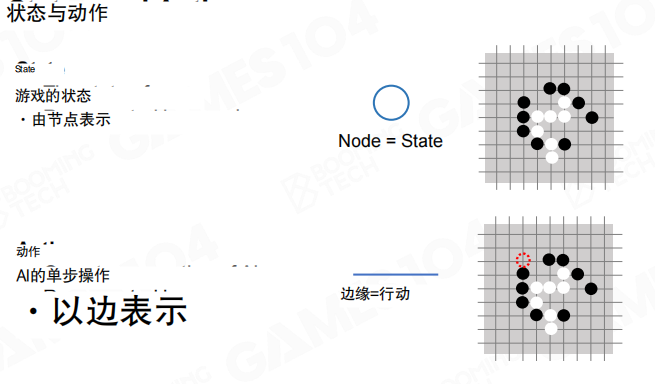
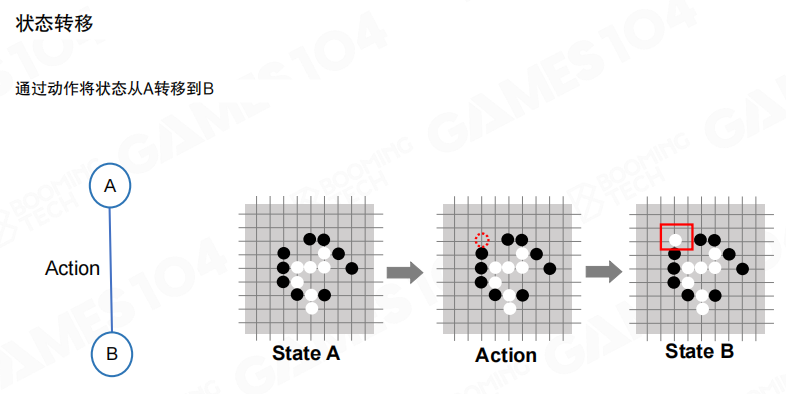
在节点和边的定义下,一次动作会把系统从状态 A 转移到状态 B。对博弈问题而言,动作选择会交替发生,状态序列就形成了一条路径。
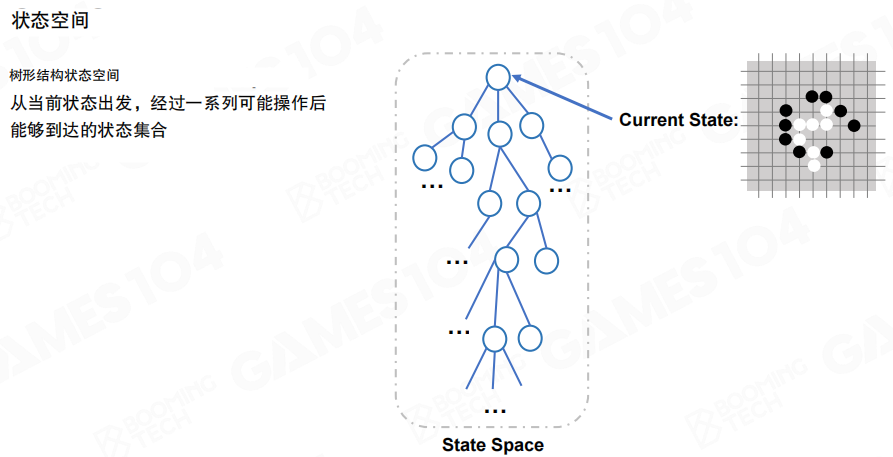
从当前状态出发,把所有可能动作逐层展开,会得到一棵树形结构的状态空间。理论上这棵树可以无限展开,但现实中只能探索其中的一小部分。
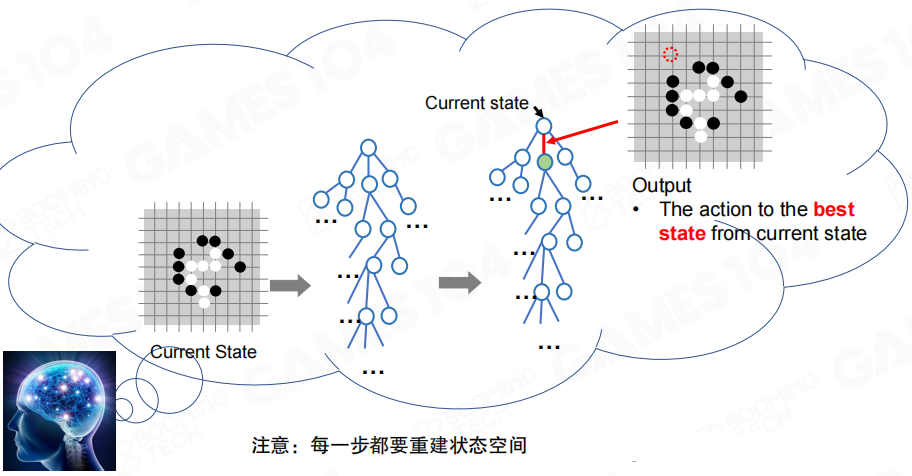
因此 MCTS 的输出并不是“完整计划”,而是面向当前状态的一次动作选择。每走一步后,根节点变成新的当前状态,搜索过程随之继续。
核心思想 仿真与统计
仿真
MCTS 的关键环节是仿真(Simulation),也常被称为 rollout。仿真并不等价于穷举,而是在选定某个节点后,按照一个默认策略(Default Policy)快速把对局推到终局,得到胜负结果。

价值估计 Q 与 N
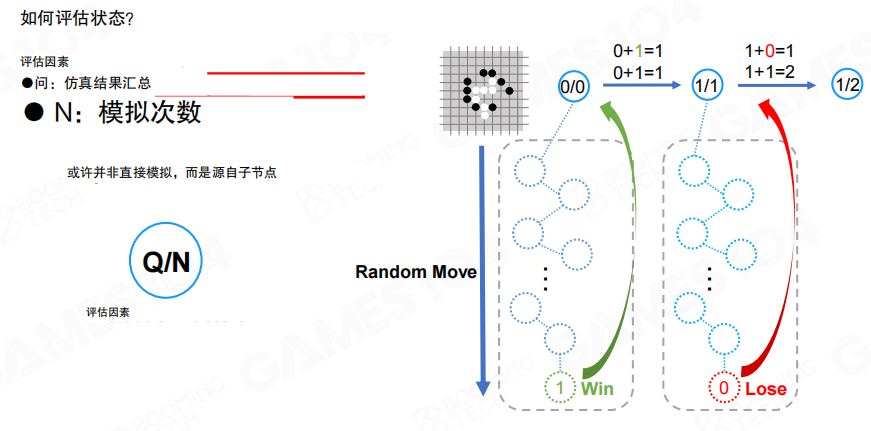
仿真结果会被汇总成两个统计量。
- Q:累计回报或胜局数量。
- N:模拟次数。
因此节点的一个直观评价可以写成 (Q/N),表示从该节点出发在当前默认策略下的经验胜率。
反向传播
一次仿真结束后,结果不会只更新叶子节点,而是沿着访问路径向上更新祖先节点的 Q 和 N,这一步称为反向传播(Backpropagation)。工程意义是让“子节点的试验结果”逐步反馈到更高层的决策点。
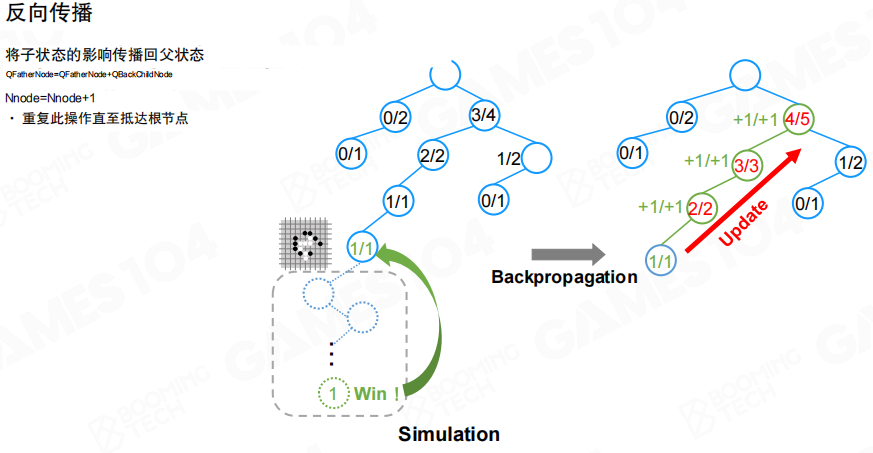
迭代流程 选择、扩展、仿真、回传
经典 MCTS 由四步循环构成,循环在计算预算内持续进行。
- 选择(Selection)
- 扩展(Expansion)
- 仿真(Simulation)
- 回传(Backpropagation)
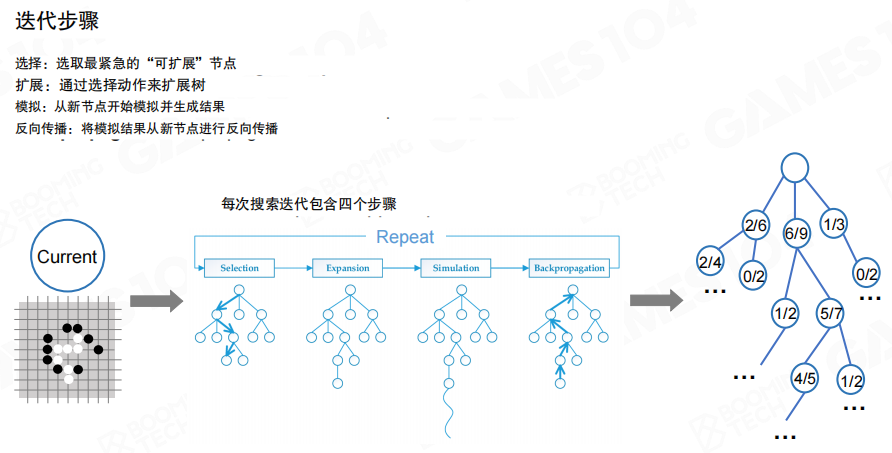
在巨大状态空间中,无法遍历所有分支,因此搜索通常只关注“更有潜力”的区域,并在预算耗尽时停止。

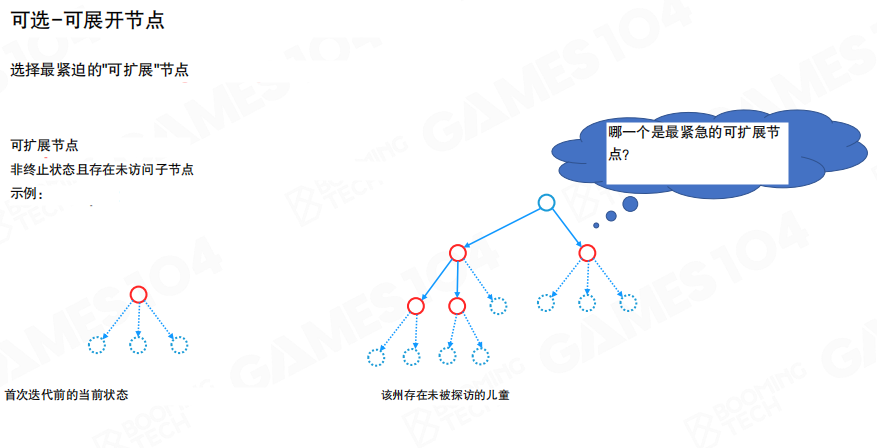
可展开节点
可展开节点的直觉是“仍存在尚未尝试的动作”。当一个节点的部分子动作尚未加入树中,该节点就仍可被扩展。
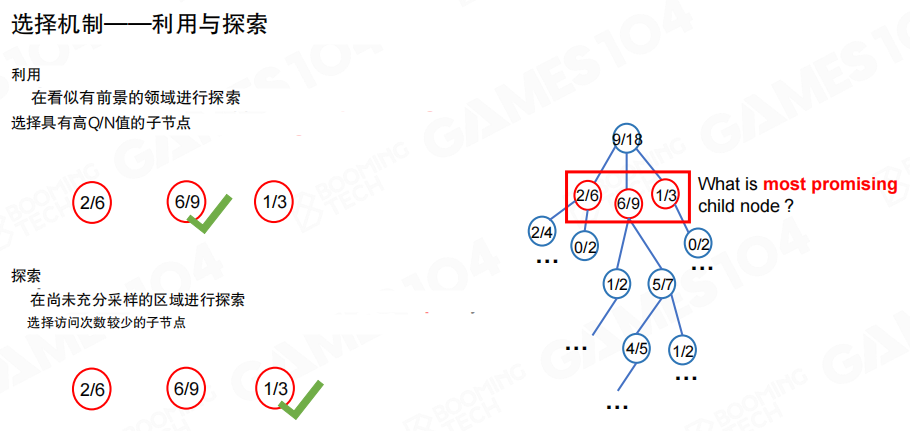
利用与探索
选择阶段需要在两种倾向之间权衡。
- 利用:优先走向当前胜率更高的子节点。
- 探索:优先尝试访问次数更少、信息更稀缺的子节点。
UCB准则
常见做法是使用 UCB(Upper Confidence Bound,上置信界)把“利用”和“探索”合并为一个分数。图中给出的形式可以写作
\[
UCB_j = \frac{Q_j}{N_j} + C \sqrt{\frac{2\ln(N)}{N_j}}
\]
其中第一项偏向利用,第二项偏向探索;常数 (C) 控制探索强度。
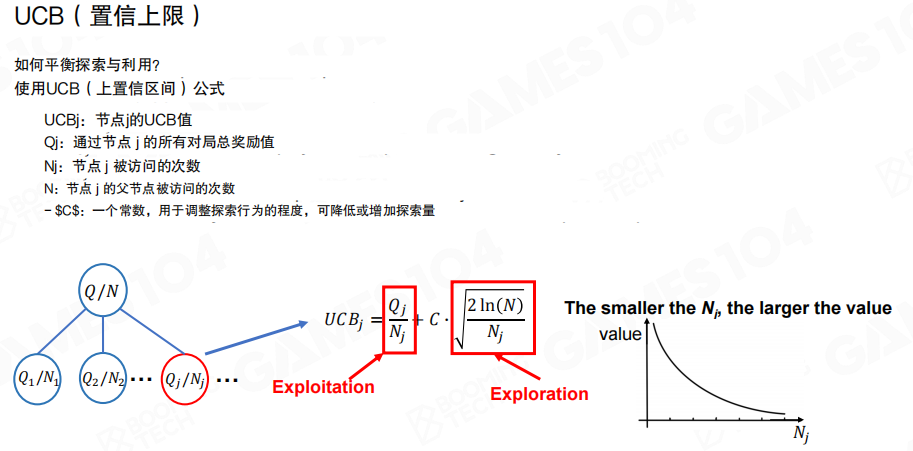
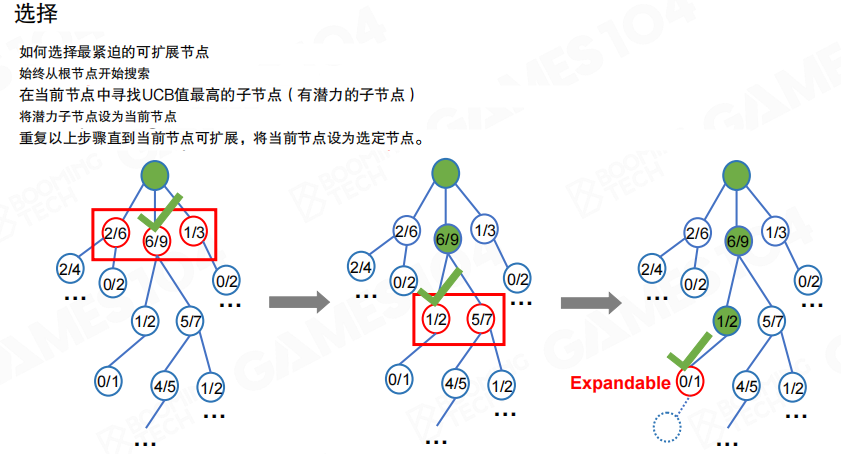
选择阶段从根节点开始,反复挑选 UCB 值最大的子节点向下走,直到遇到一个可展开节点,再进入扩展阶段。
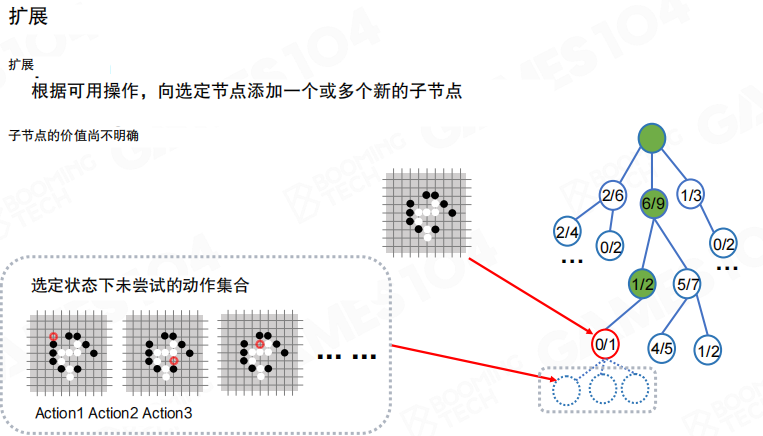
扩展
扩展阶段把某个未尝试动作加入树中,生成新的子节点。新节点的价值未知,需要后续仿真来估计。
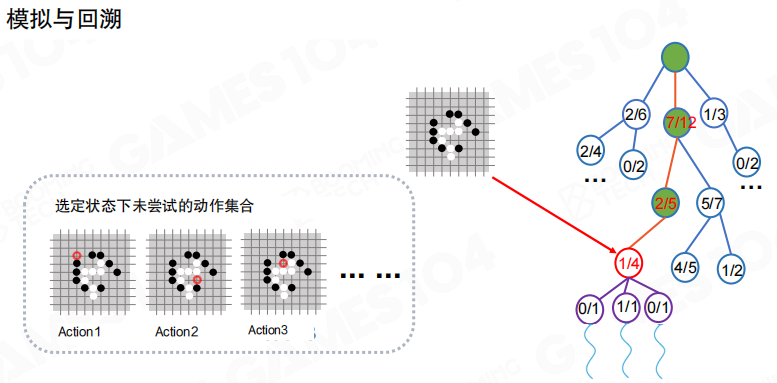
仿真与回溯
扩展出的新节点会触发一次或多次仿真,得到胜负结果,再通过回传更新整条路径上的统计量,使树逐步“长出偏好”。
终止条件与输出
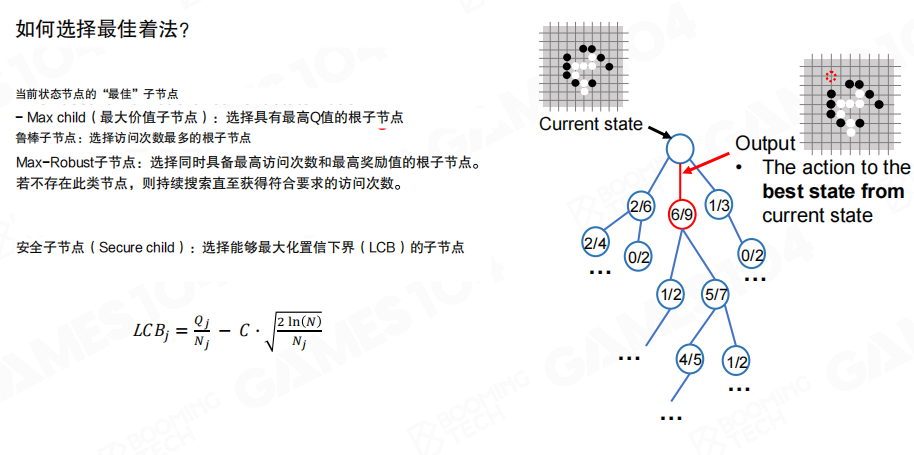
MCTS 需要一个明确的计算预算作为终止条件,例如仿真次数上限、时间上限或节点数量上限。停止后,只需要在根节点的子节点中选择一个动作作为最终输出。
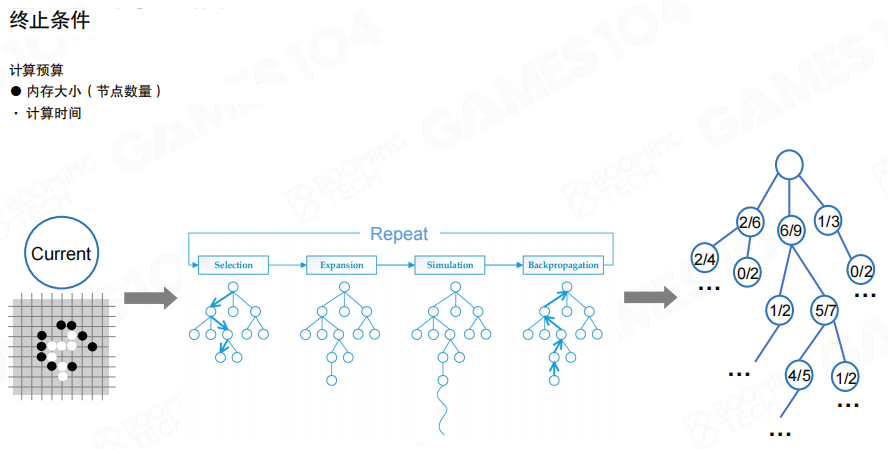
“最终输出选哪个子节点”也存在多种策略,例如选择胜率最高的子节点、选择访问次数最多的子节点,或采用更保守的下置信界思想做折中。
小结
优缺点可以概括为两组工程结论。
- 优点:MCTS 智能体行为更具多样性;智能体更偏向自主决策;能够应对搜索空间巨大的问题。
- 缺点:对多数实时游戏而言,状态与动作的设计成本较高;复杂环境下建模困难;计算开销显著,往往需要与 行为树(Behavior Tree)/GOAP(Goal-Oriented Action Planning)/HTN(Hierarchical Task Network)等结构组合使用。

17.5 机器学习基础
这一节的目标不是系统讲完机器学习的完整理论,而是把”机器学习在游戏里通常怎么落地”拆成若干基础概念:先区分学习范式,再聚焦与游戏决策最相关的强化学习,并用马尔可夫决策过程给出可计算的形式化表达。

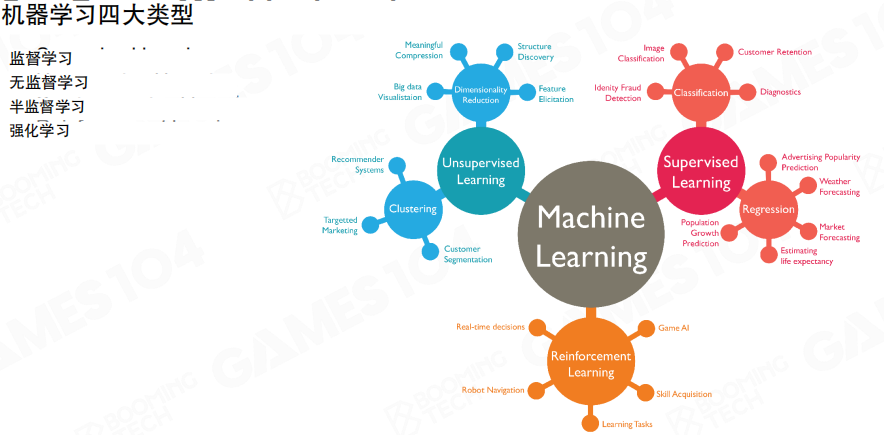
机器学习常见类型
课程把机器学习分为四类:监督学习、无监督学习、半监督学习、强化学习。它们的差异不在模型形式,而在”学习信号从哪里来”。
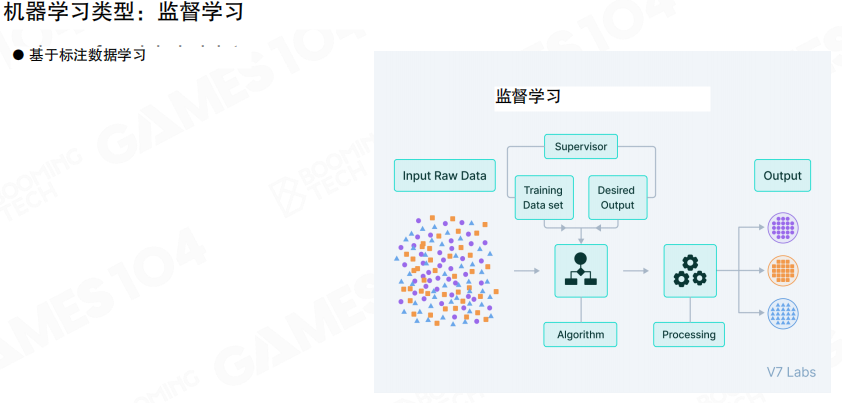
监督学习
监督学习以带标签数据为起点,核心任务通常是分类或回归。图中的流程强调了”输入数据→训练集与期望输出→算法学习→输出结果”的典型管线,即通过标签提供明确的学习目标。
无监督学习
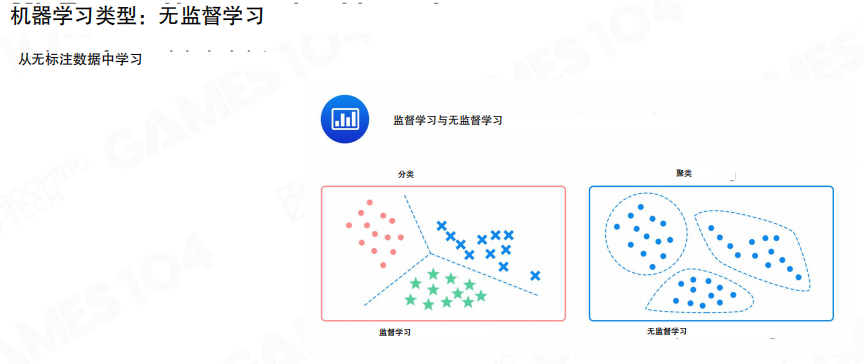
无监督学习面对的是未标注数据,目标是从数据本身抽取结构。图中用”分类边界”与”聚类簇”对比了两类常见任务:前者依赖标签给出边界,后者则是在没有标签的前提下发现数据的分布形态。
半监督学习
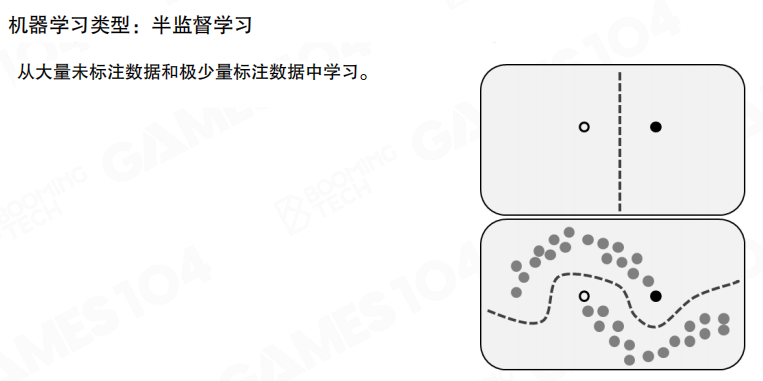
半监督学习处于两者之间,利用大量未标注数据与少量标注数据共同训练。图中上半部分表示”只有少量标注点”,下半部分表示”借助未标注样本的分布形态,把决策边界推向更符合整体结构的位置”,从而减少对标注规模的依赖。
强化学习
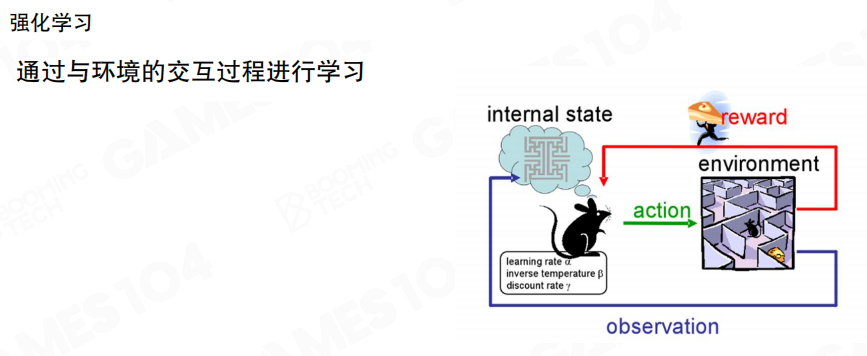
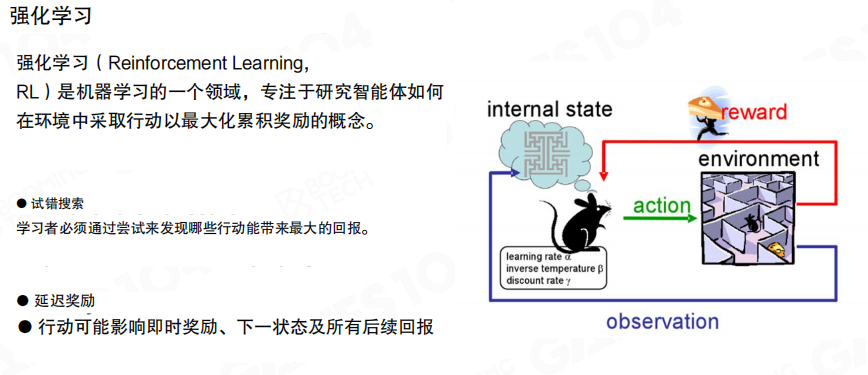
强化学习(Reinforcement Learning,RL)把学习建模为“智能体与环境交互”的过程。图中的回路强调了三类信号。
- 观测(Observation):环境反馈给智能体的可见信息
- 动作(Action):智能体对环境施加的控制
- 奖励(Reward):环境对动作结果的评价
强化学习的工程难点之一是试错(Trial and Error)与延迟奖励。图中提示了一个关键事实:一次动作可能影响即时奖励,也可能影响后续多个时间步的回报,因此学习目标往往是最大化累计奖励而非单步得分。
马尔可夫决策过程
强化学习常用的理论框架是马尔可夫决策过程(Markov Decision Process,MDP)。在 MDP 中,智能体与环境构成闭环,环境根据智能体的动作更新状态并给出奖励。
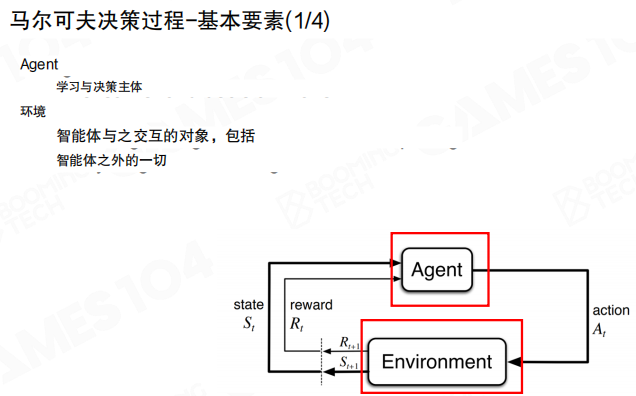
状态
状态(State)表示智能体对当前环境的刻画。图中用平台游戏截图类比状态的”当前帧快照”,并强调状态的数据结构通常由工程侧设计与抽取。
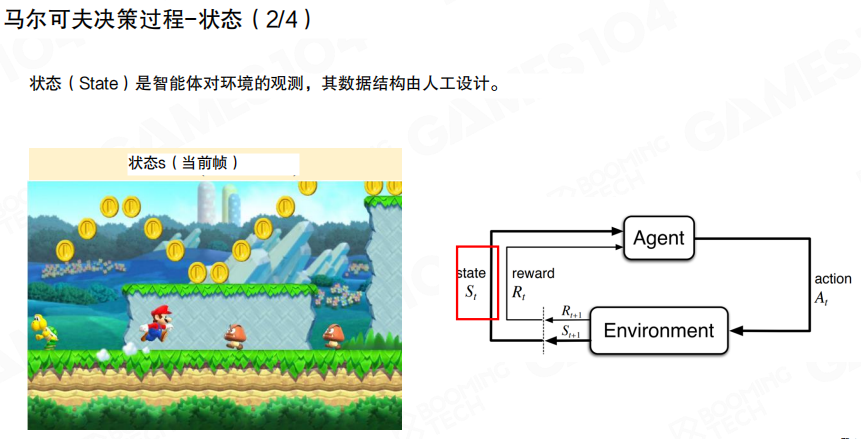
行动
行动(Action)是智能体在游戏中可执行的最小行为单元。图中用”左/右/跳”示例动作空间,并在 MDP 框图中标出动作从智能体流向环境。
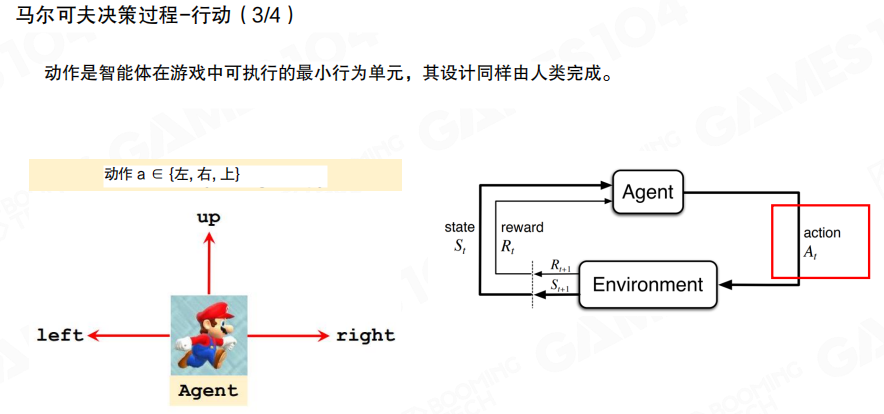
奖励
奖励(Reward)是环境对行为结果的反馈信号。图中给出不同事件对应不同奖励值的示例,并强调奖励在每个时间步都可能产生,用于驱动策略的优化方向。
MDP 的数学表达
MDP 可以用三类量来形式化描述。
- 转移概率:执行动作后从状态 (s) 转移到状态 (s’) 的概率 (p(s’|s,a))
- 策略:在状态 (s) 下选择动作 (a) 的概率分布 (\pi(a|s))
- 累计回报:对未来奖励的加权求和 (G_t),其中折扣因子 (\gamma) 用于平衡短期与长期回报

策略

图中把策略写成 (\pi(a|s)) 的形式,含义是在给定状态 (s) 的条件下,智能体选择动作 (a) 的概率。以“左/右/跳”的离散动作空间为例,策略输出的不是单个动作,而是一组动作概率分布,随后再据此采样或取最大概率动作完成决策。
17.6 构建高级游戏AI
为什么游戏 AI 需要机器学习
前面章节的寻路、转向、行为树、HTN、GOAP 等方法,本质上都需要把大量人类知识固化进结构与参数里,例如 GOAP 的成本、HTN 的分解方法、行为树的节点组织。这样做的上限往往受限于“可设计的分支空间”,很难覆盖开放世界的复杂性与多样性。
机器学习的价值在于把一部分”分支枚举”交给数据与训练过程,让智能体在可控的约束下形成更丰富的策略空间,从而更接近玩家对复杂世界与多样行为的期待。

游戏中的机器学习框架
把深度神经网络部署为智能体的核心决策模块时,最基础的闭环仍然是“观测→决策→环境反馈”。
- 观测(Observation):来自游戏环境的可学习输入,既可以是结构化向量特征,也可以是图像与多层地图特征。
- 行动(Action):神经网络策略输出,驱动智能体在环境中执行操作。
- 环境(Game Environment):提供状态更新与反馈信号。
图中的核心信息是,神经网络策略与传统的决策模块一样,需要清晰的输入与输出接口,否则无法训练也无法上线运行。

深度强化学习示例 游戏建模
课程用深度强化学习(Deep Reinforcement Learning,DRL)的视角给出一条常见流程:定义状态、动作、奖励,设计神经网络结构,并制定训练策略。这四步对应的是把”可玩游戏”转写成”可学习系统”的工程拆解。

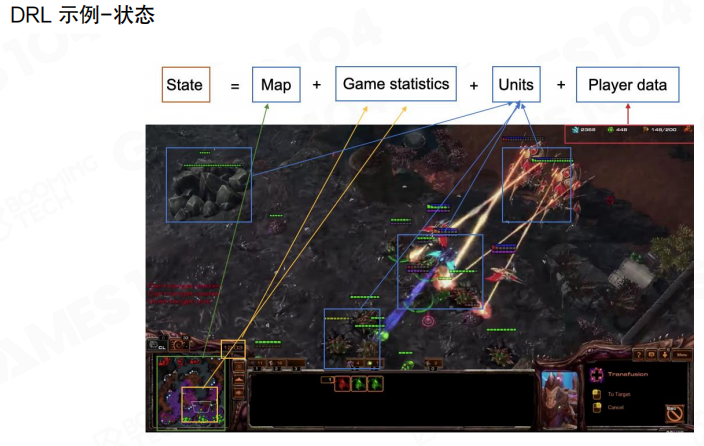
状态
状态的关键不是“采集得越多越好”,而是把与决策相关的信息组织为可学习的输入。图里给出一种常见拆分方式。
- 地图(Map):空间信息与多层地图特征
- 游戏统计(Game statistics):经济、人口、科技等标量统计
- 单位信息(Units):场上实体的属性与位置
- 玩家信息(Player data):选择单位、相机与历史操作等交互数据
这种拆分把不同形态的数据分离出来,为后续网络结构选型铺路。
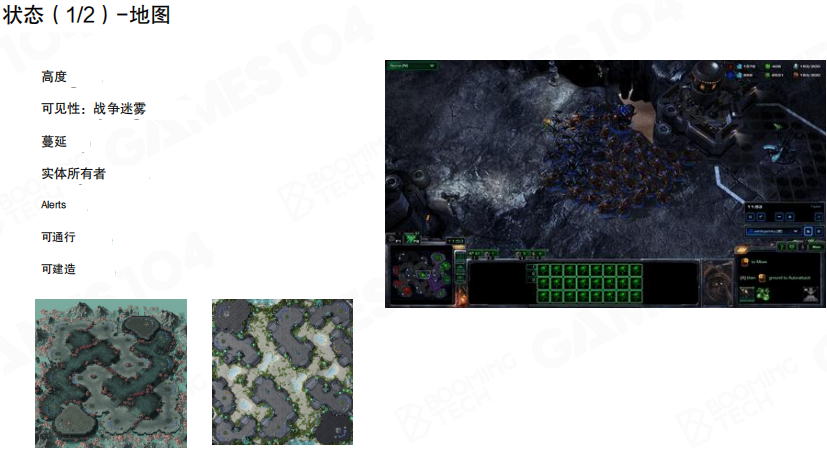
地图特征往往不是一张图,而是一组语义层叠加的特征图,例如高度、可见性、战争迷雾、可通行与可建造区域、警报与事件图层等。对强化学习而言,地图层的工程意义在于把”空间推理”交给网络处理,而不是在策略里手写规则。
单位特征则更接近”实体表”,包含单位类型、所属关系、生命值与状态、位置、属性、生产与资源状态等。与地图不同,单位数量随战局变化而变化,因此需要能处理变长输入的表示方式。

动作
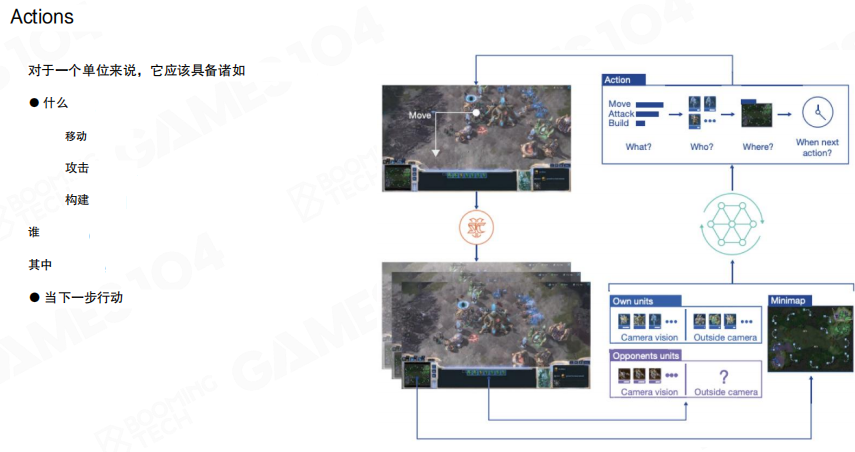
动作空间的定义直接决定了“智能体能做什么”。图中把动作拆成多段问题。
- 做什么:移动、攻击、建造等动作类型
- 由谁做:选中的单位或单位集合
- 对谁做:目标单位或目标点
- 在何时做:延迟与队列化的动作调度
把动作拆成结构化子字段,是在不牺牲表达能力的前提下控制动作空间规模的常见做法。
奖励
奖励函数是训练信号的来源,也是策略风格的隐式控制器。图中给出两种工程思路。
- 稀疏奖励:只在胜负等关键事件上给奖励(胜利 +1,失败 -1),工程实现简单,但学习信号稀缺。
- 密集奖励:把塔、防御、经济、击杀、承伤、地图控制等拆成高频奖励,学习更稳定,但奖励设计与权重平衡的成本更高。

图中还提示了一个常见技巧:用伪奖励(Pseudo Reward)与评估网络协同工作,例如把”当前操作与高水平人类数据的统计距离”纳入训练目标,使策略在早期更快贴近可用行为分布,再逐步让强化学习接管探索。
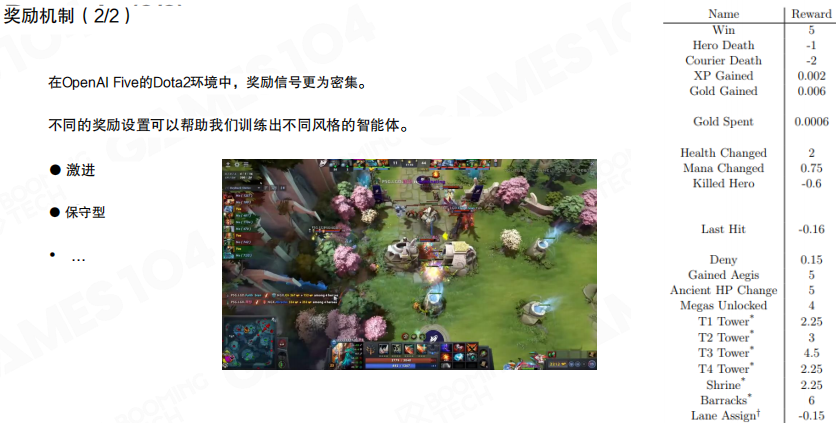
以 OpenAI Five 为例,奖励信号更密集,且可以通过不同奖励项与权重组合引导不同风格策略,例如更激进或更保守。密集奖励的优势是训练过程更可控,但也引入了”奖励工程”的复杂度。
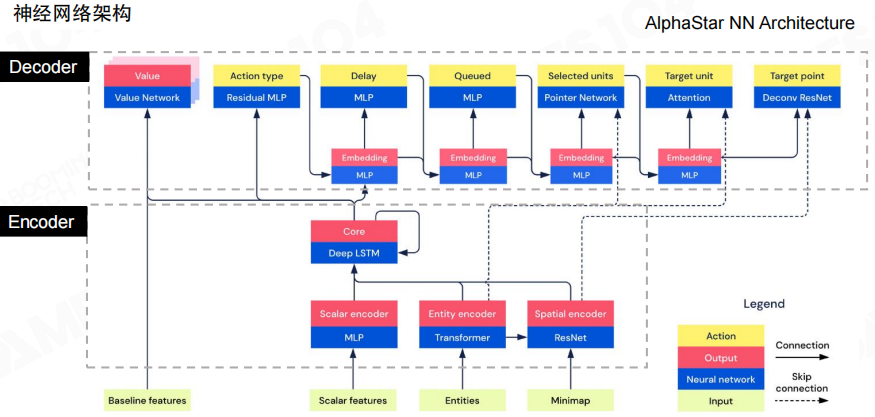
网络结构 让不同类型输入各就各位
AlphaStar 的网络结构展示了一个核心工程思想:不同形态的数据不适合用同一种网络硬塞,而应当分别编码后再融合,再由解码器把融合后的表征翻译为可执行动作。
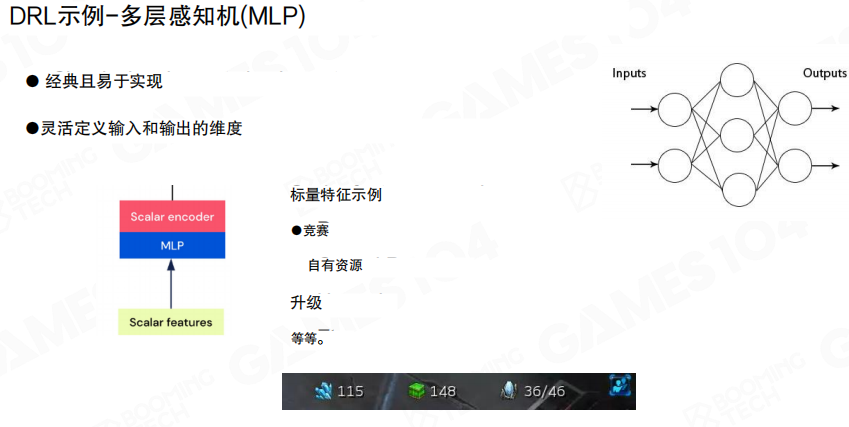
多层感知机 MLP
多层感知机(Multi-Layer Perceptron,MLP)适合处理定长的标量向量特征,例如资源量、人口、升级与统计信息。其优势是实现简单,输入输出维度明确。
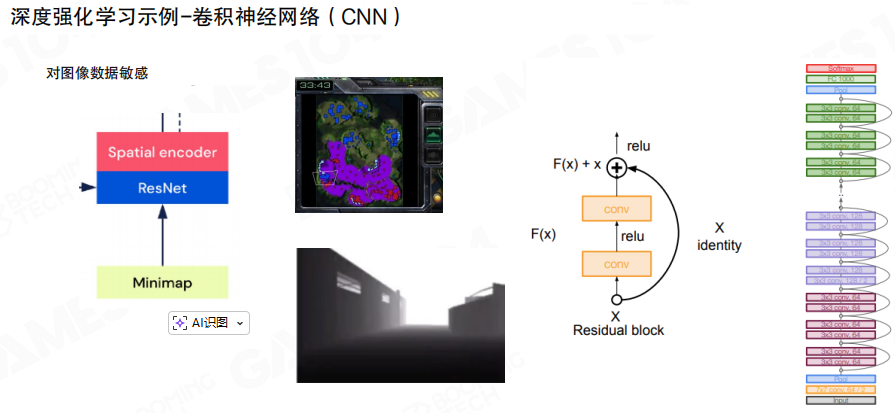
卷积网络
卷积神经网络(Convolutional Neural Network,CNN)适合处理空间结构明显的输入,例如小地图、可见性图层与多层地图语义。图中以 残差网络(ResNet)说明了常见的空间编码器结构。
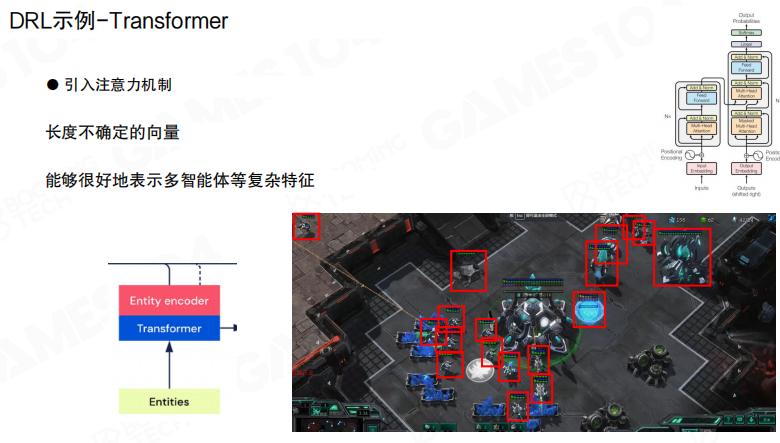
Transformer
当输入是变长的实体集合时,Transformer 提供了更自然的表达方式。图中强调了注意力机制与变长向量建模能力,用于编码单位列表等”实体级特征”。
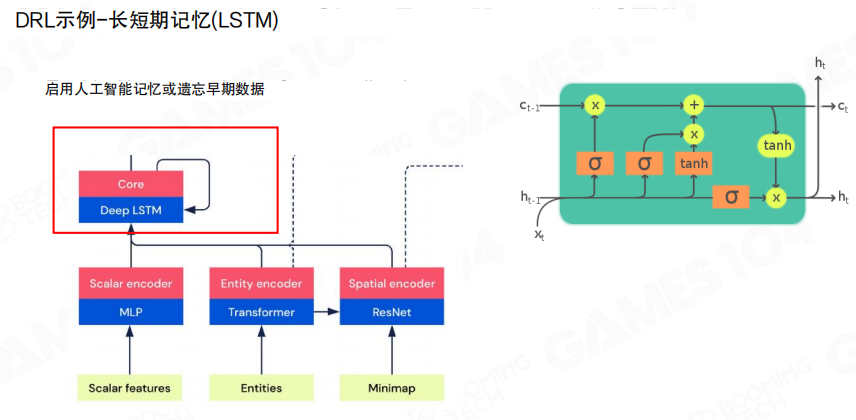
长短期记忆
在策略决策中,短期记忆与历史上下文常常是必要信息,例如战争迷雾导致的部分可观测。图中用长短期记忆(Long Short-Term Memory,LSTM)表示对历史信息的聚合与保留,用于形成更稳定的决策表征。
神经网络架构选择
固定长度向量特征适合用 MLP,变长实体特征可以用 Transformer 或带记忆的结构,空间图像特征适合用 ResNet 等卷积结构。神经网络结构选型并非追求”更复杂”,而是匹配数据形态与计算预算。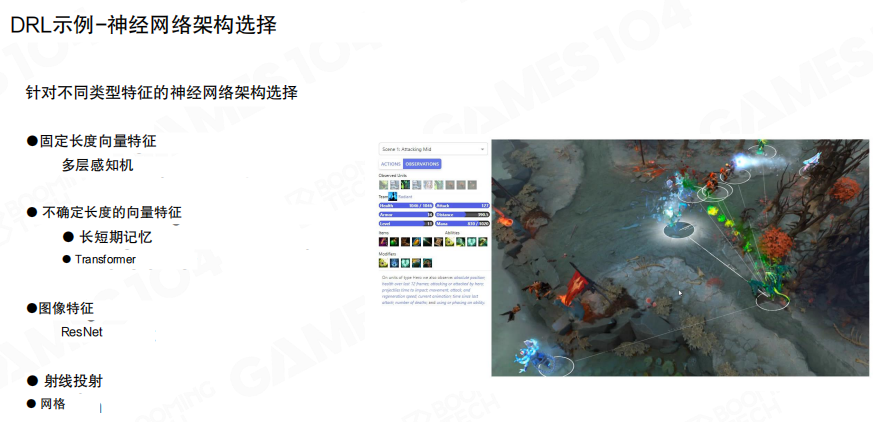
训练策略 从模仿到自我进化
AlphaStar 的训练并非直接从零开始。把第一阶段称为监督学习:先从高水平人类对局数据中学习基础策略,并用 KL 散度(Kullback–Leibler Divergence)等统计距离约束策略分布与人类决策分布的偏离,使策略在早期快速收敛到可用行为区域。

在此基础上再使用强化学习对策略进行优化,并把对监督策略分布的约束继续纳入考虑,从而减少强化学习阶段出现”策略漂移导致行为不自然”的风险。图中提到的 TD((\lambda))、V-trace、UPGO 等属于具体强化学习算法族的工程选择。

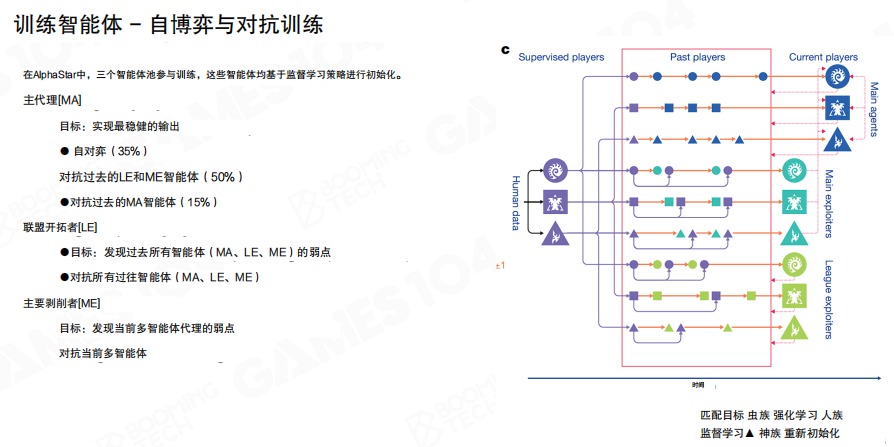
为了避免陷入局部最优,训练过程还引入了”联赛式”的对抗训练框架:主智能体与不同类型的对手集合交替训练,通过历史版本、针对性对手与联盟对手共同构造更丰富的对抗分布,以持续暴露策略弱点并促使策略迭代。
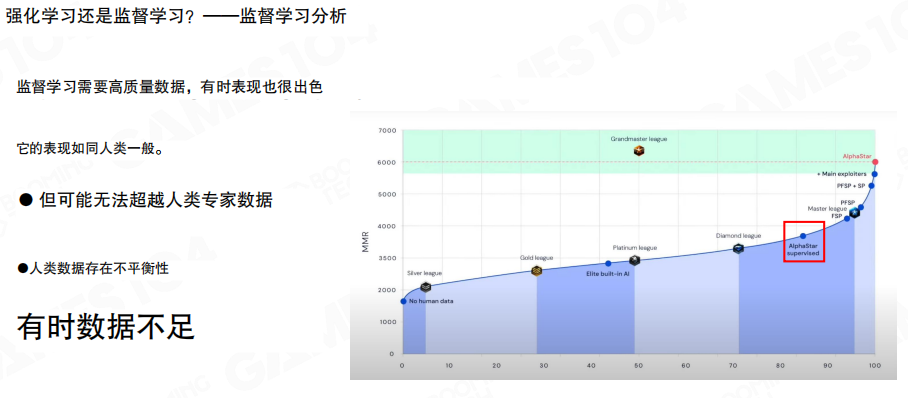
监督学习与强化学习的取舍
图中从工程角度总结了两类训练方式的典型特点。监督学习依赖高质量数据,行为往往更接近人类,但上限通常受数据分布限制,且存在数据不平衡等问题。强化学习更可能带来性能突破,但训练过程更困难,且数据采集与环境构建成本更高。

对强化学习而言,”奖励稀疏”是核心难点之一。图中用密集奖励与稀疏奖励对比说明了问题适配性:密集奖励的任务更容易学习,而稀疏奖励任务往往需要更复杂的探索机制与更高的训练成本。


混合式落地与成本
深度神经网络很强,但训练与迭代成本也很高。工程实践中更常见的做法是“混合式”架构:在合适的子问题上使用深度网络,在其它环节使用行为树、状态机、HTN、GOAP 等传统模块,以在效果、可控性与成本之间做平衡。

图中给出了一个从微观到宏观的权衡视角,强调把深度网络部署到“最值得学习的决策层级”,同时保留传统模块在可解释性与工程稳定性上的优势。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

