20.面向数据编程与任务系统
20.1 并行编程基础
游戏引擎对性能的要求极高。在1/30秒内要完成大量物理模拟、游戏逻辑运算,还要渲染数百万甚至上千万像素的光照计算。更不用说玩家还要求60帧、120帧甚至更高。这意味着我们必须把硬件和操作系统的性能压榨到极限。

代码执行并非表面看起来那么简单。游戏引擎运行在操作系统之上,而操作系统又运行在特定硬件之上。要编写高性能程序,必须同时考虑硬件与操作系统因素。
摩尔定律的极限与多核技术
集成电路中的晶体管数量大约每两年翻一番,这是经典的摩尔定律。但近年来,芯片密度已经不再每两年翻一番,工艺已经接近量子力学的物理极限。从22纳米往下,理论极限可能在0.5纳米左右,再往下几乎不可能了。
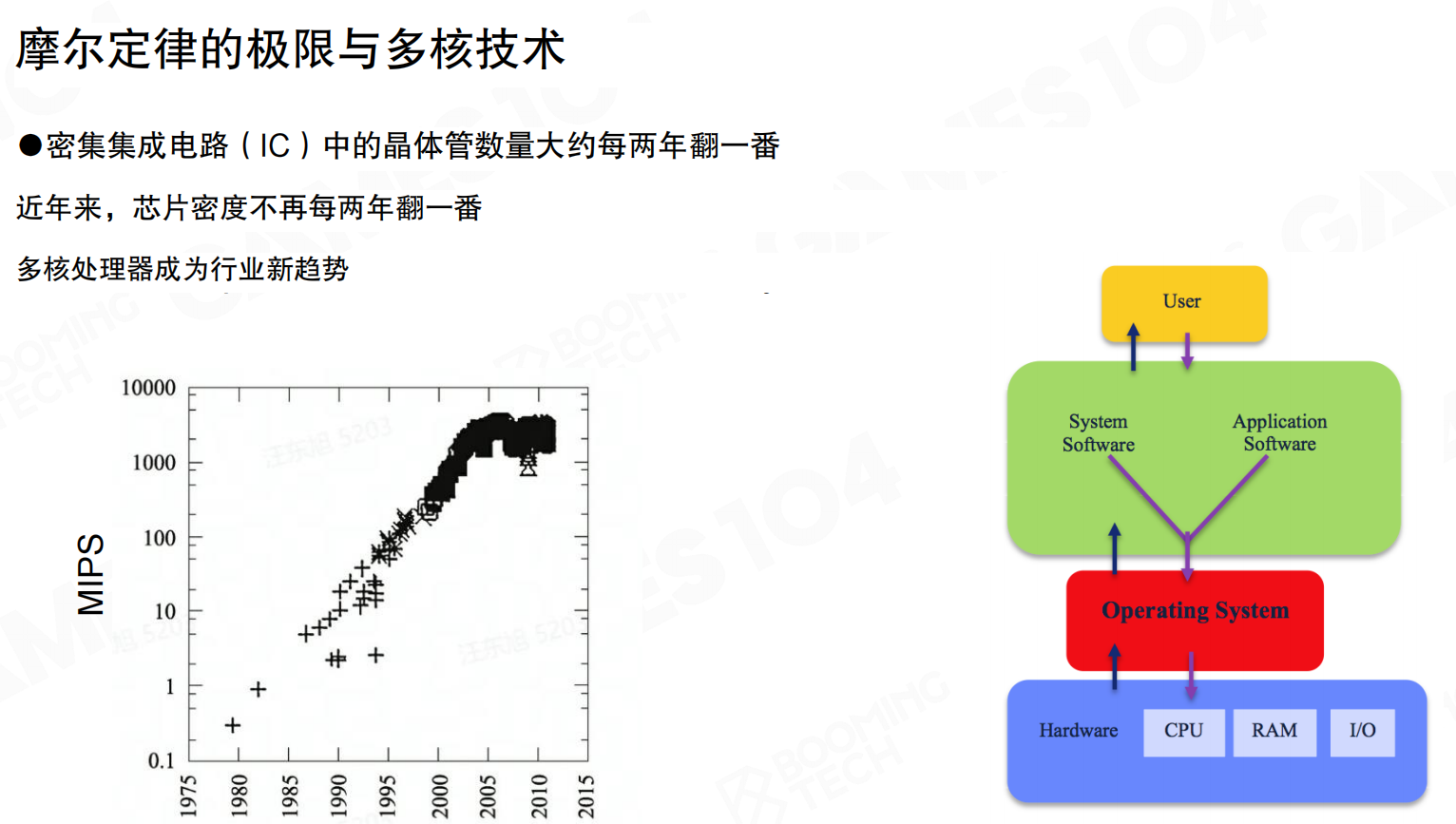
既然单核主频无法继续提升(现在基本卡在3-4GHz,再往上散热和功耗都是问题),解决方案就是使用更多核心。多核处理器因此成为行业新趋势。今天买电脑,四核、八核、十六核已经是常态。
有了这么多核心,我们自然要想办法把它们的算力全部利用起来。
进程与线程
并行编程的基础概念是进程(Process)和线程(Thread)。
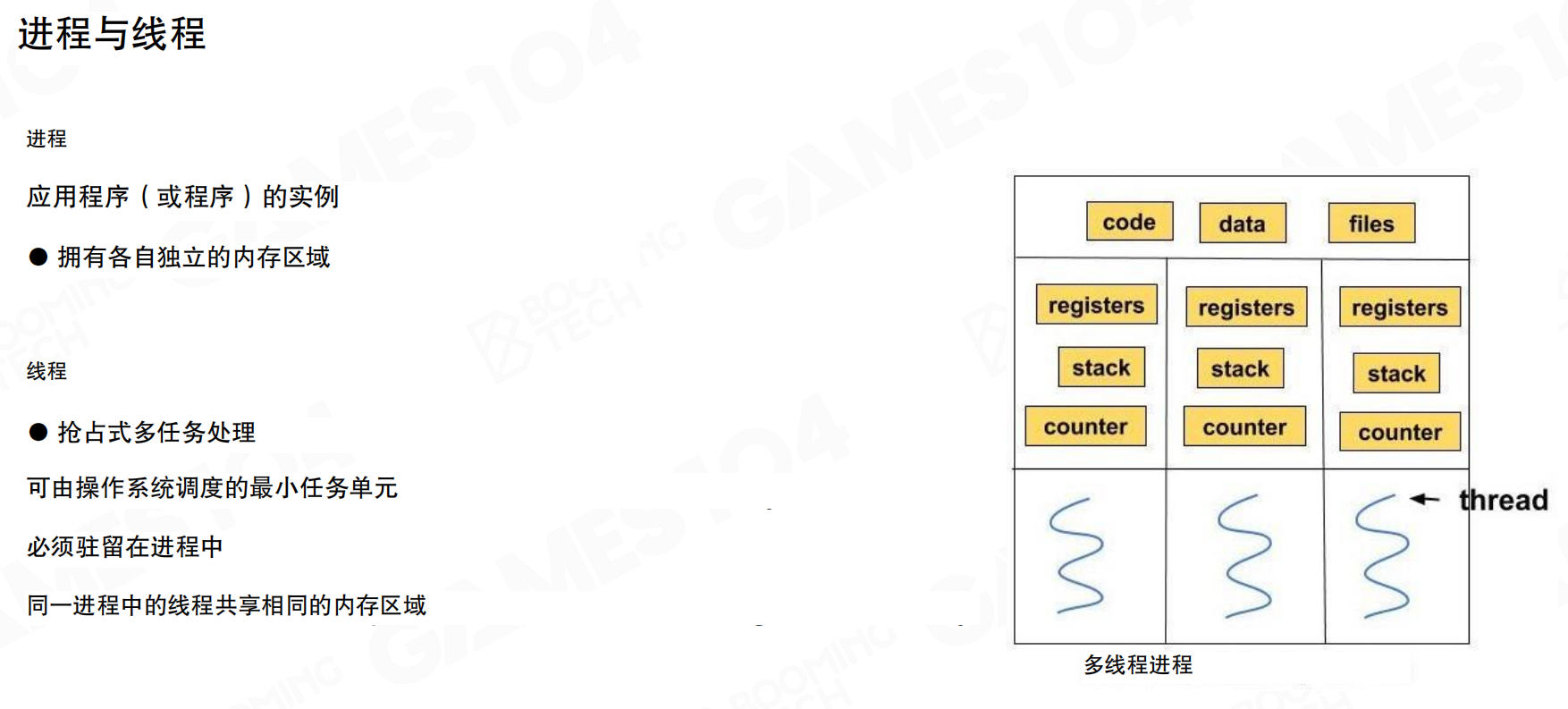
进程是应用程序的实例,拥有各自独立的内存区域。线程是可由操作系统调度的最小任务单元,必须驻留在进程中。同一进程中的线程共享相同的内存区域(代码、数据、文件),但每个线程有自己独立的寄存器、栈和程序计数器。
简单理解:进程之间内存完全独立,需要通过特殊机制才能交换信息;线程之间共享内存,数据交换更直接,但也更容易产生冲突。
多任务处理的类型
多任务处理分为两种类型:
抢占式多任务处理(Preemptive Multitasking):当前执行的任务可在调度器决定的任意时刻被中断。调度器决定接下来执行哪个任务。这种方式广泛应用于大多数操作系统(如Windows),因为不能让一个进程占用所有系统资源。
非抢占式多任务处理(Non-Preemptive Multitasking):任务必须被显式编程以移交控制权。任务必须相互协作,调度方案才能生效。这种方式在操作系统中很少用,但在一些实时操作系统(RTOS)中也有应用。

线程上下文切换
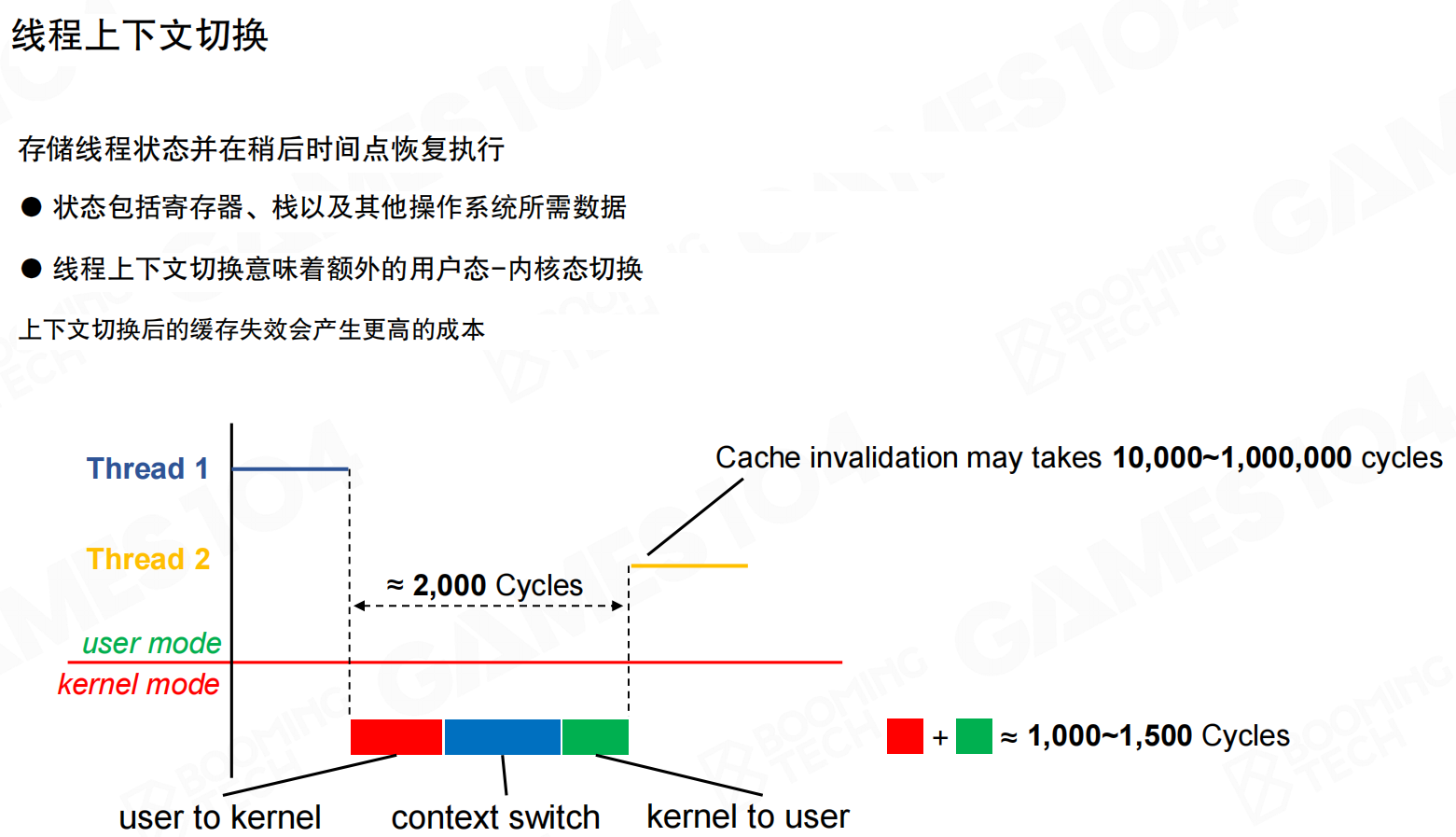
线程切换时会产生额外开销。线程上下文切换需要存储线程状态(寄存器、栈等),并在稍后恢复执行。这个过程涉及用户态到内核态的切换,至少需要约2000个CPU周期。
更严重的是缓存失效问题:切换后的线程数据不在各级缓存中,需要从内存重新加载,这个过程可能需要1万到100万个周期。因此,线程上下文切换实际上非常昂贵,这也是为什么后续要讲的Job System采用Fiber架构的原因。
并行计算中的并行问题
并行问题可以分为两类:
令人尴尬的并行问题(Embarrassingly Parallel,也称完美并行):并行任务之间极少或无需依赖与通信。每个任务独立完成,最后汇总结果即可。典型的例子是蒙特卡洛模拟,每个采样点的计算完全独立。
非易并行问题:并行任务之间需要进行通信和协调。现实中的游戏引擎往往属于这一类,各个系统之间存在数据依赖和依赖关系,导致并行化变得复杂。

并行编程中的数据竞争
数据竞争(Data Race)是并行编程中最常见的问题:单个进程中的多个线程同时访问同一内存位置,且至少有一次访问是用于写入操作。
例如,job_count++看似是一个操作,实际上包含三个步骤:读取任务计数、计算job_count+1、写入新的任务计数。如果两个线程同时执行这个操作,可能都读取到相同的初始值,各自加1后写回,导致其中一个增量丢失。线程预期任务数+2,但实际只+1。

处理数据竞争最简单的方式是使用锁(Lock)。同一时间只有一个线程能够获取锁,为共享资源访问设置临界区(Critical Section)。
进入临界区前调用mutex.lock(),退出时调用mutex.unlock()。临界区内的代码保证同一时间只有一个线程在执行,其他需要访问同一内存的线程会被强制等待。

尽管使用锁可以保证程序正确执行,但锁会带来一些问题:
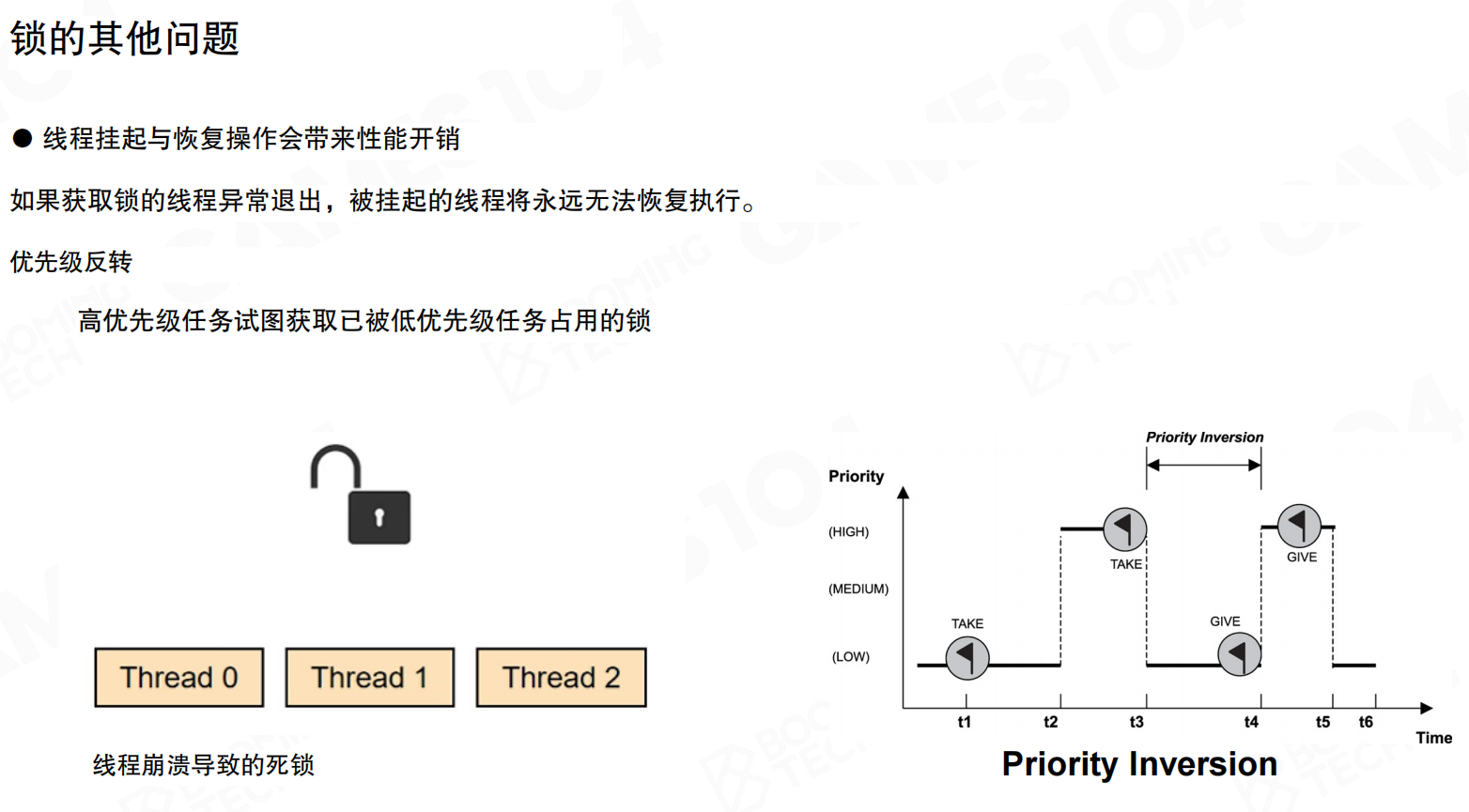
线程挂起与恢复的性能开销:如果获取锁的线程异常退出,被挂起的线程将永远无法恢复执行,导致死锁。
优先级反转(Priority Inversion):高优先级任务试图获取已被低优先级任务占用的锁时,高优先级任务实际上被低优先级任务阻塞,导致优先级反转。
因此,在编写并行程序时,应尽可能减少锁的使用。
处理数据竞争的另一种方法是使用原子操作(Atomic Operation)。原子操作是硬件层面实现的基本操作,无法同时被多个CPU一起执行。
原子操作包括:
- 原子加载与存储:Load(将数据从共享内存加载到寄存器)和Store(将数据移入共享内存)
原子性读-修改-写(RMW)操作:Test and Set、Compare and Swap(CAS)、Fetch and Add等
利用原子操作可以实现无锁的程序并行,从而避免死锁并提升运行效率。C++11提供了完整的原子操作库支持。

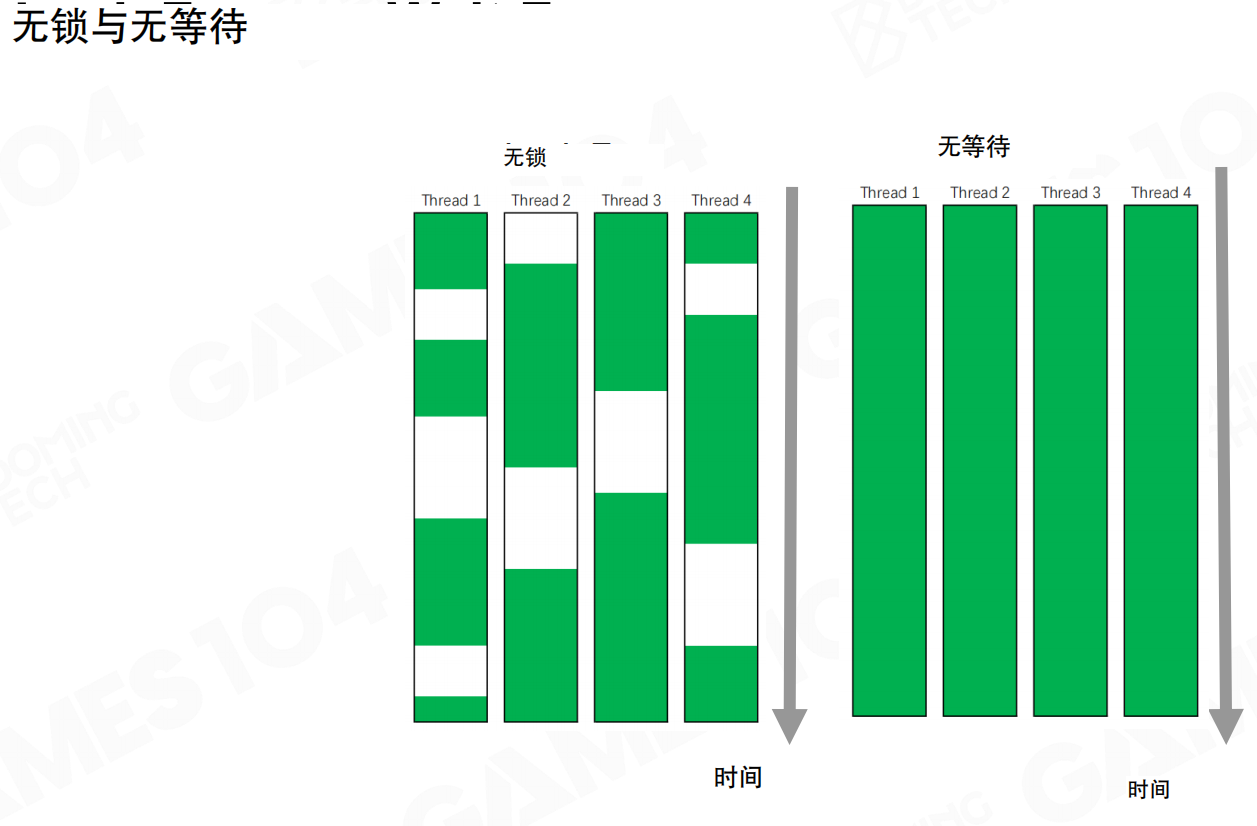
无锁(Lock-free):虽然避免了死锁,但线程之间可能因为原子变量之间的等待或依赖而产生很多空洞,CPU利用率可能不是100%。
无等待(Wait-free):理论上可以保证所有线程持续执行,CPU利用率接近100%。但Wait-free编程非常复杂,需要严格的数学证明。对于游戏引擎开发,掌握Lock-free这一层通常已经足够。
编译器重排优化
现代编译器会对代码进行自动优化,通过调整代码的执行顺序来提升单线程程序的运行效率。但这种调整在多线程情况下可能导致问题。
例如,函数a = b + 1; b = 0;在开启优化后,编译器可能重排为:先读取b的值到临时变量,然后立即将b设为0,最后用临时变量计算a。只要单线程结果一致,编译器就认为这是有效的优化。但在多线程环境下,这种重排可能导致其他线程看到不一致的状态。

编译器和CPU通常会调整指令的执行顺序以优化性能。这就是并行编程的难点所在。
例如,线程1执行a = b + 1; b = 0;,线程2循环等待b != 0,然后断言a == 2。在单线程情况下,这个断言应该成立。但由于编译器和CPU的重排序,线程2可能在看到b == 0时,a还没有被正确设置,导致断言失败。
这就是为什么在Debug版本中代码运行正常,但在Release版本中可能莫名其妙崩溃的原因。

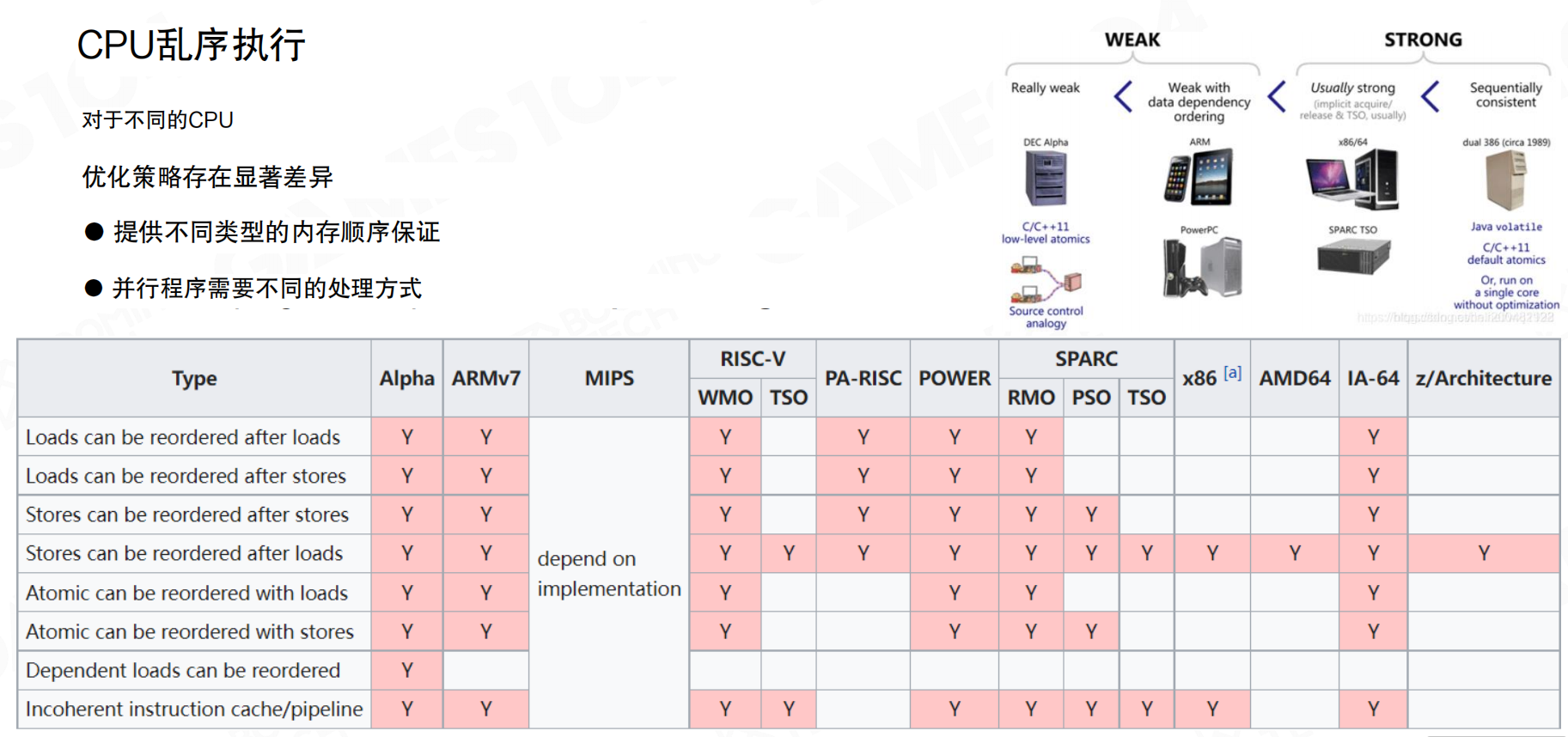
不同的CPU提供不同类型的内存顺序保证。从弱到强,内存模型可以分为:Really weak(如DEC Alpha)、Weak with data dependency ordering(如ARM、PowerPC)、Usually strong(如x86/64、SPARC TSO)、Sequentially consistent(如早期的386)。
不同架构的CPU对以下重排序的支持不同:
- Loads可以重排序到Loads之后
- Loads可以重排序到Stores之后
- Stores可以重排序到Stores之后
- Stores可以重排序到Loads之后
- 原子操作与Loads/Stores的重排序
- 依赖Loads的重排序
特别像ARM架构,它非常追求功耗和性能,所以尽量简化设计,允许更多的重排序。这就是为什么有时候在PC模拟器上代码运行正常,但在真机上就出问题的原因。
现代CPU采用乱序执行:CPU不会等待指令一条条执行,而是把一大段函数切成很多块,指令和数据同时在里面运行,这样速度才快。编译器也是按照这个原理优化的。
因此,在进行并行编程时,必须建立这样的基本常识:一段函数在CPU中执行是乱序的,不能假设变量的值符合你写下来的顺序。C++11提供了显式要求编译器确保执行顺序一致的机制,但代价是执行性能会变差。
20.2 游戏引擎并行架构
固定多线程
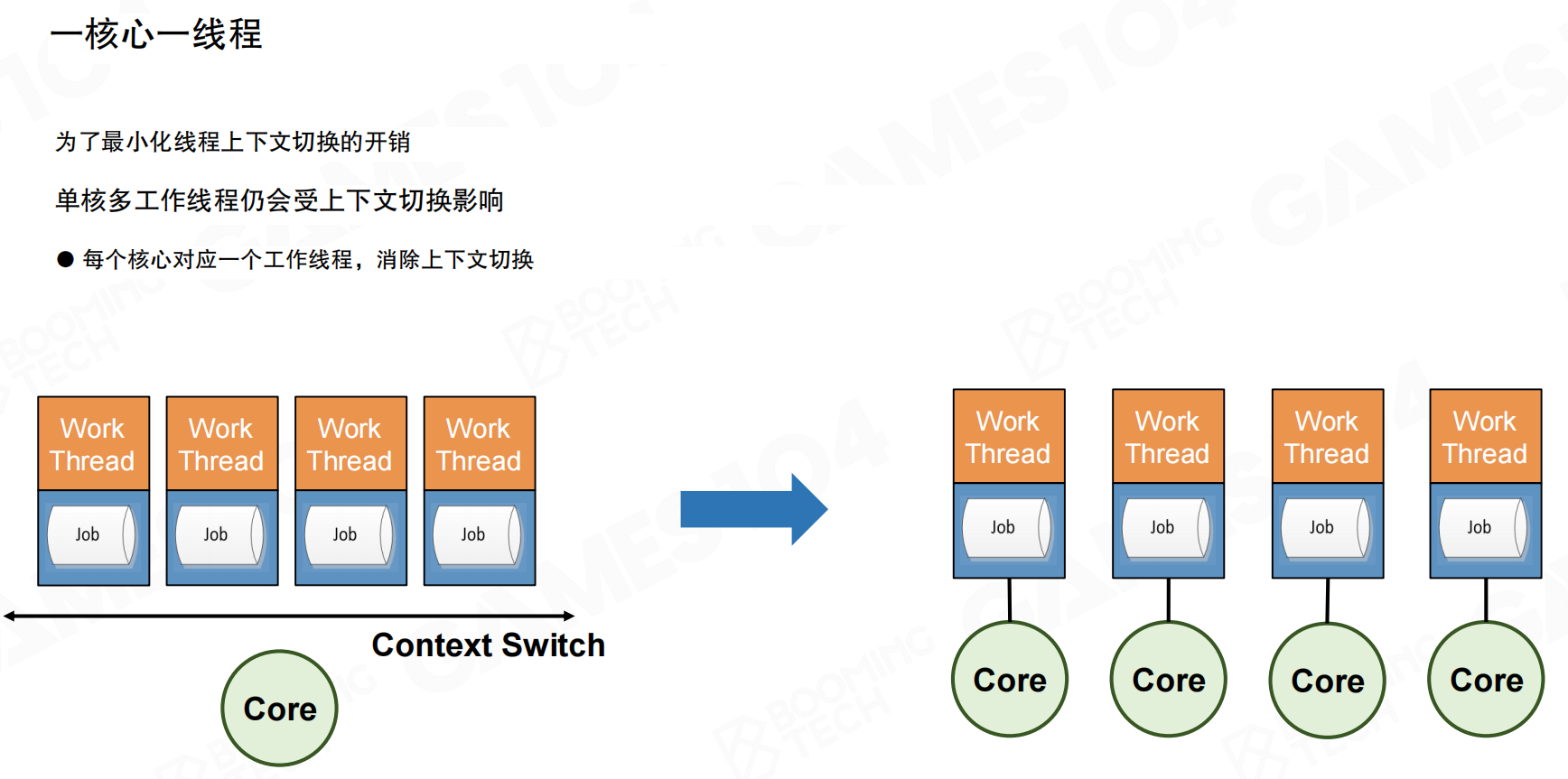
固定多线程(Fixed Multithreading)是最经典的并行架构方案。引擎的每个系统分配一个固定线程:渲染、模拟、逻辑、网络等各自拥有专属线程。每一帧开始时通过线程间通信交换数据,然后各自执行任务。

该架构在2-4核环境下表现良好,职责划分清晰,实现简单。主要问题在于难以保证不同线程上的负载一致。不同线程间负载差异往往很大:部分线程快速完成,但必须等待其他线程结束。这是典型的木桶效应——所有线程等待最慢的线程完成,整帧才能结束。
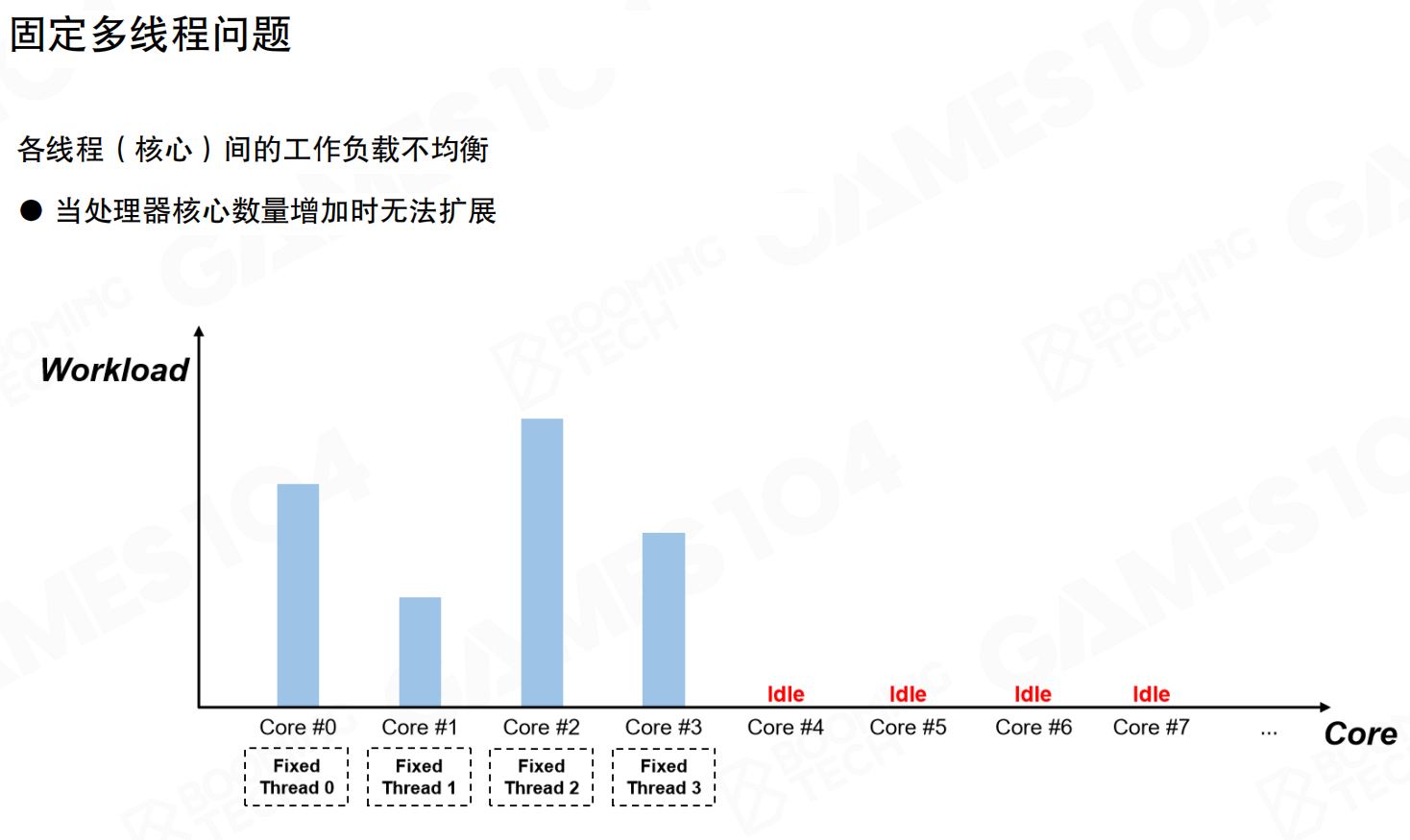
固定多线程的另一个问题是无法随处理器核心数量扩展。双核环境下,四个线程需要在两个核心上竞争,频繁的上下文切换带来性能损失。在多核环境下(如8核、16核),多余的核心只能闲置,造成计算资源浪费。这也是高配电脑上游戏卡顿但CPU占用率不高的原因之一。
将重负载任务拆分给轻负载线程存在两个限制:一是数据访问的局部性(Locality),需要保持线程访问的数据集中,避免跨线程访问导致数据竞争;二是不同场景下各线程负载差异巨大(某些场景渲染慢,某些场景逻辑忙),难以动态调整。
Fork-Join模式
Fork-Join模式通过工作线程池实现并行计算。对于计算量大且一致性高的任务(如动画计算),固定线程通过Fork操作将任务分配到工作线程(Work Thread)并行执行,完成后再通过Join操作汇总结果。工作线程数量由CPU核心数决定,使用线程池避免频繁的线程创建与销毁。
举个例子:渲染线程需要计算100个角色的动画。它可以将这100个角色分成4组,每组25个,分别交给4个工作线程并行计算。4个工作线程同时处理各自的25个角色,完成后渲染线程通过Join操作收集所有结果,继续后续的渲染流程。
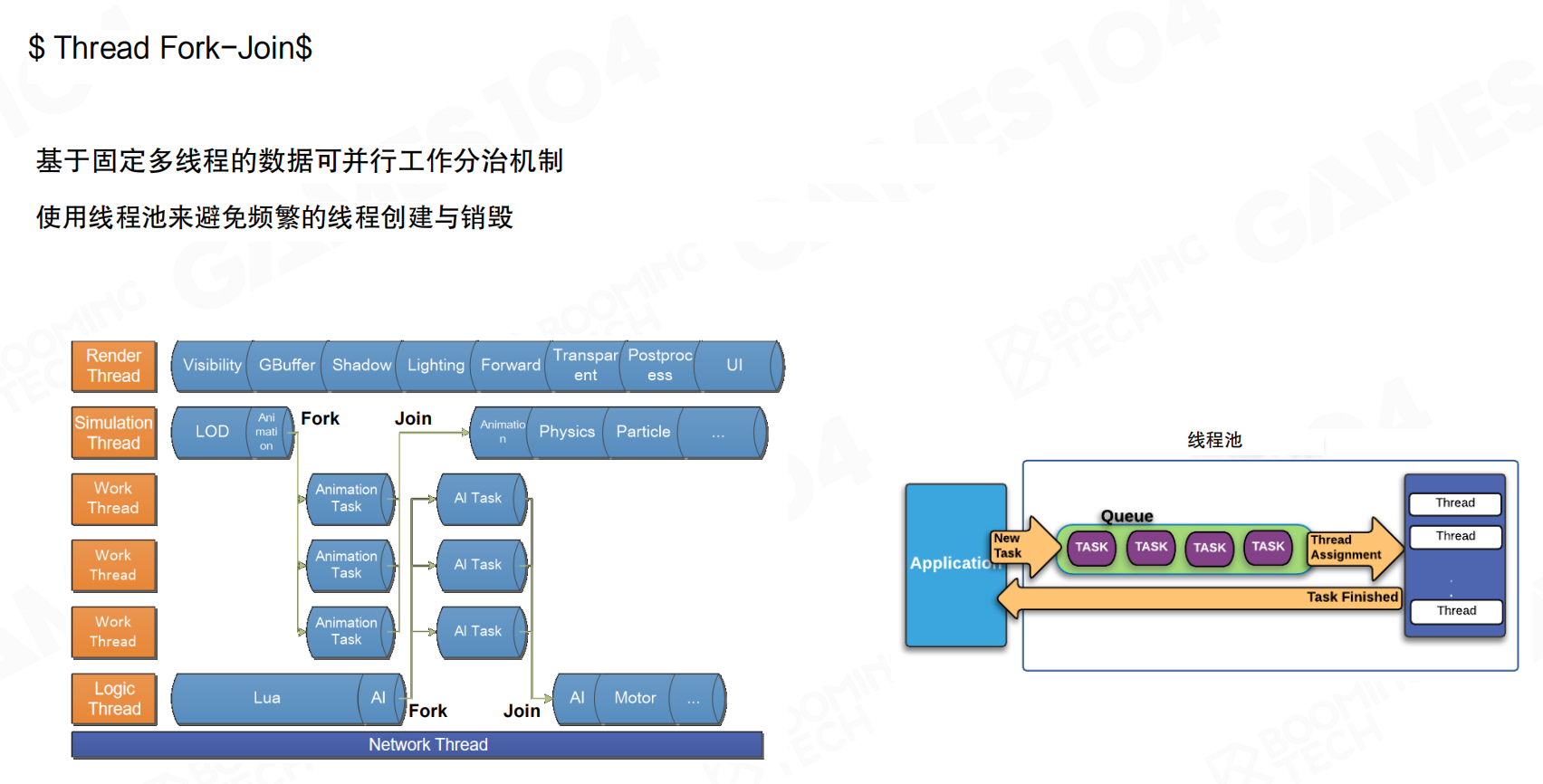
相比固定多线程,Fork-Join适应性更好,能更充分地利用多核算力。但仍存在问题:需要手动拆分工作、管理工作线程计数,对开发者不友好;过多线程带来上下文切换开销;各线程间工作负载仍不均衡。
例如,如果100个角色中,前25个角色动画计算简单(只需10ms),后25个角色动画计算复杂(需要100ms),那么前3个工作线程很快完成,但必须等待最后一个工作线程完成,造成资源浪费。

即使采用Fork-Join模式,新任务到来时工作负载分配仍难以平衡。许多任务无法事先预测负载,导致部分核心忙碌、部分核心空闲。
比如,物理系统突然需要计算大量碰撞检测,但此时工作线程可能正在处理其他任务。新任务到来时,调度器无法准确判断每个任务的执行时间,可能出现部分核心空闲、部分核心过载的情况。
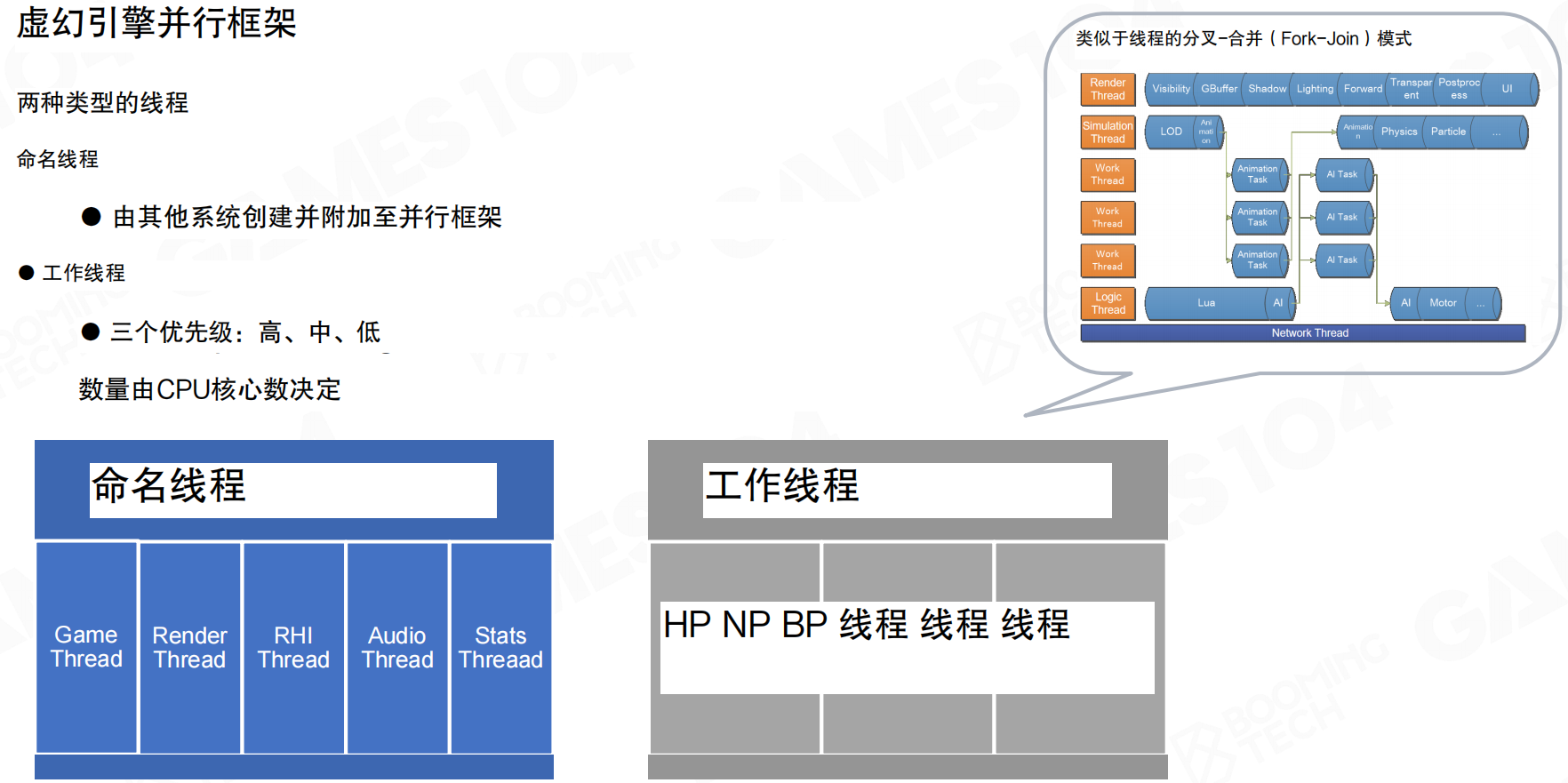
虚幻引擎采用Fork-Join架构,设计了两种线程类型:命名线程(Named Thread)和工作线程(Worker Thread)。命名线程由其他系统创建并附加至并行框架,对应引擎不同系统(Game Thread、Render Thread、RHI Thread、Audio Thread、Stats Thread等)。工作线程有三个优先级(高、中、低),数量由CPU核心数决定,用于执行具体计算任务。
例如,Game Thread负责游戏逻辑,Render Thread负责渲染,它们都是命名线程,职责固定。当Render Thread需要并行计算时,它会将任务Fork到工作线程池中。工作线程池根据CPU核心数创建(如8核CPU创建8个工作线程),按优先级处理任务。
任务图
任务图(Task Graph)使用有向无环图(DAG)表示任务依赖关系。节点代表任务,边缘代表依赖。系统根据任务间的依赖关系决定执行顺序和可并行执行的任务。
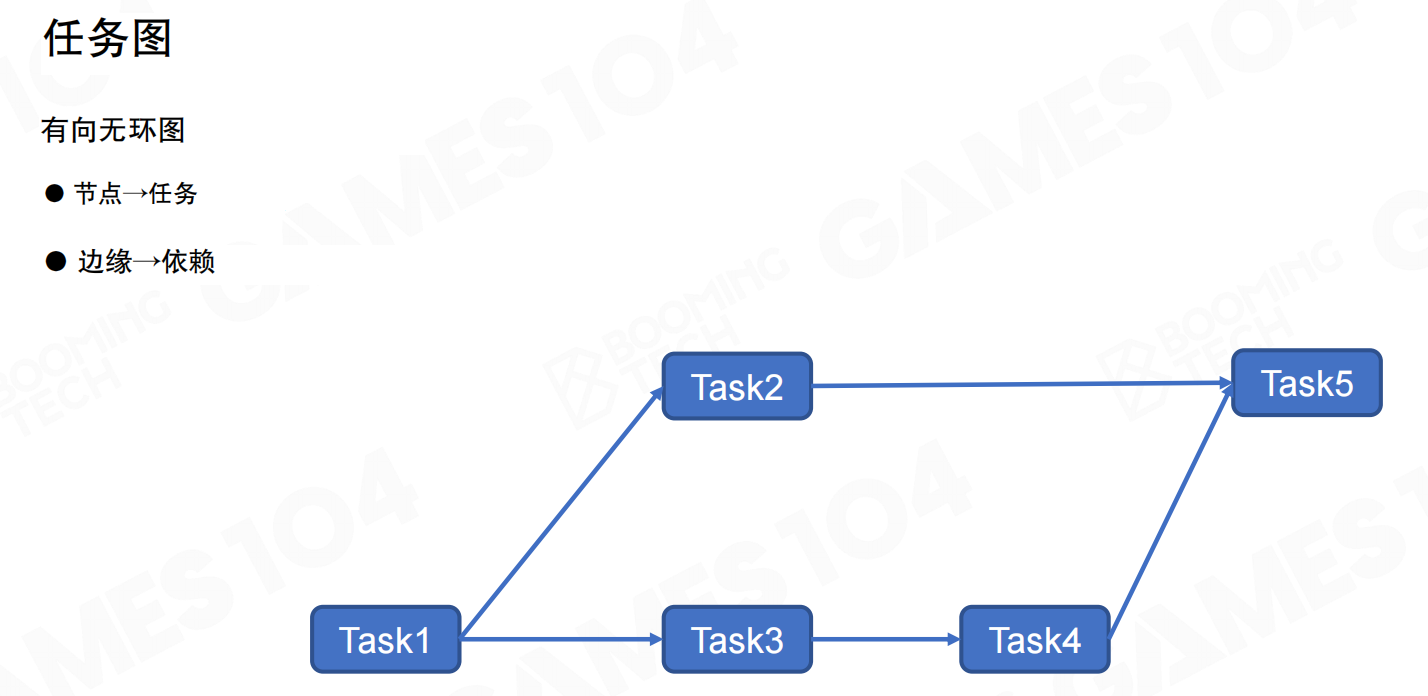
任务图的构建通过代码链接实现:定义Task1(无依赖),Task2依赖Task1,Task3依赖Task1,Task4依赖Task3,Task5依赖Task2和Task4。系统解析依赖图后自动执行。

任务图的问题在于:对于游戏引擎场景,任务构建往往不透明;任务执行过程中可能动态创建新任务,依赖关系不断变化。任务图的静态方式在动态增加节点时复杂度高,早期版本也未实现”执行到一半等待其他任务完成后再继续”的机制,需要后续系统解决。
20.3 任务系统
协程基础
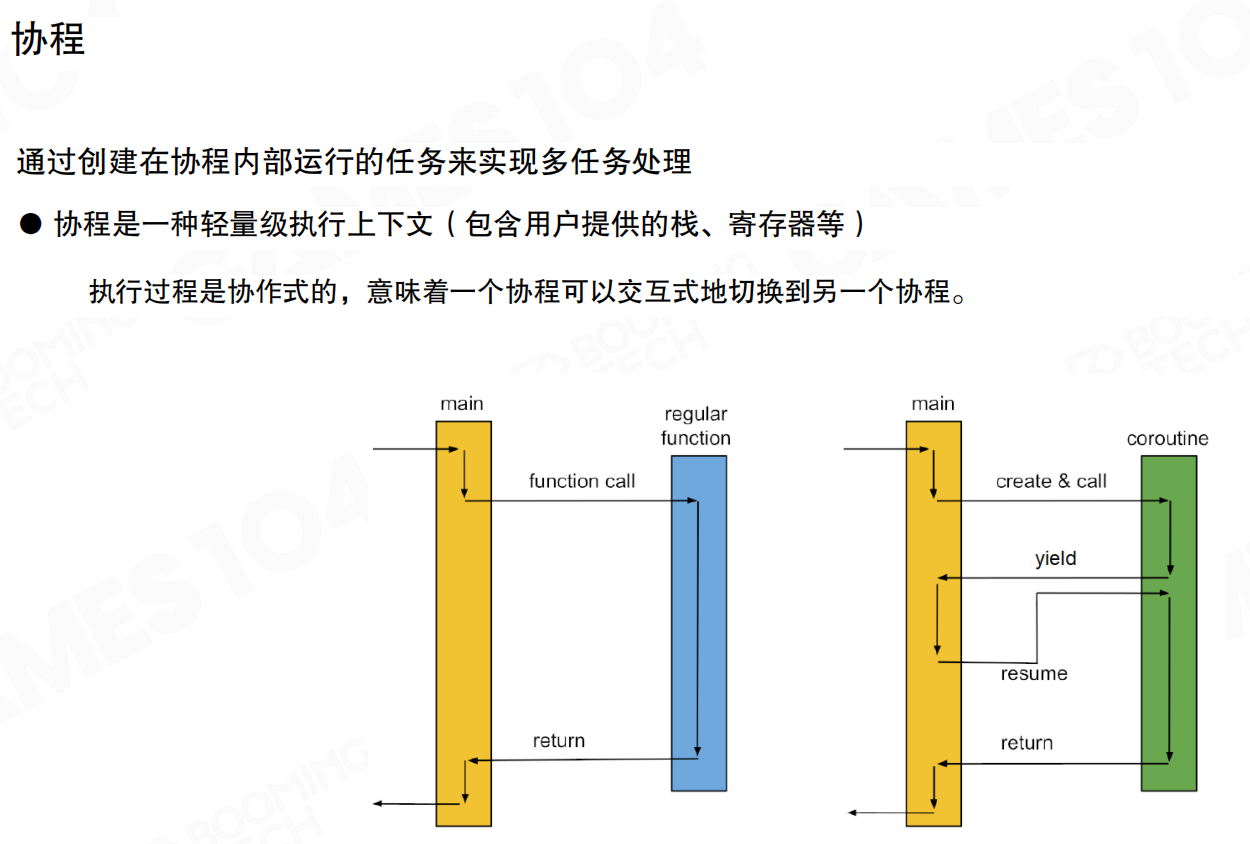
现代游戏引擎的任务系统(Job System)基于协程(Coroutine)实现。协程是轻量级执行上下文,包含用户提供的栈、寄存器等。函数执行过程中可通过yield操作让出执行权,稍后通过resume恢复执行,从上次暂停处继续。执行过程是协作式的,协程可交互式切换。
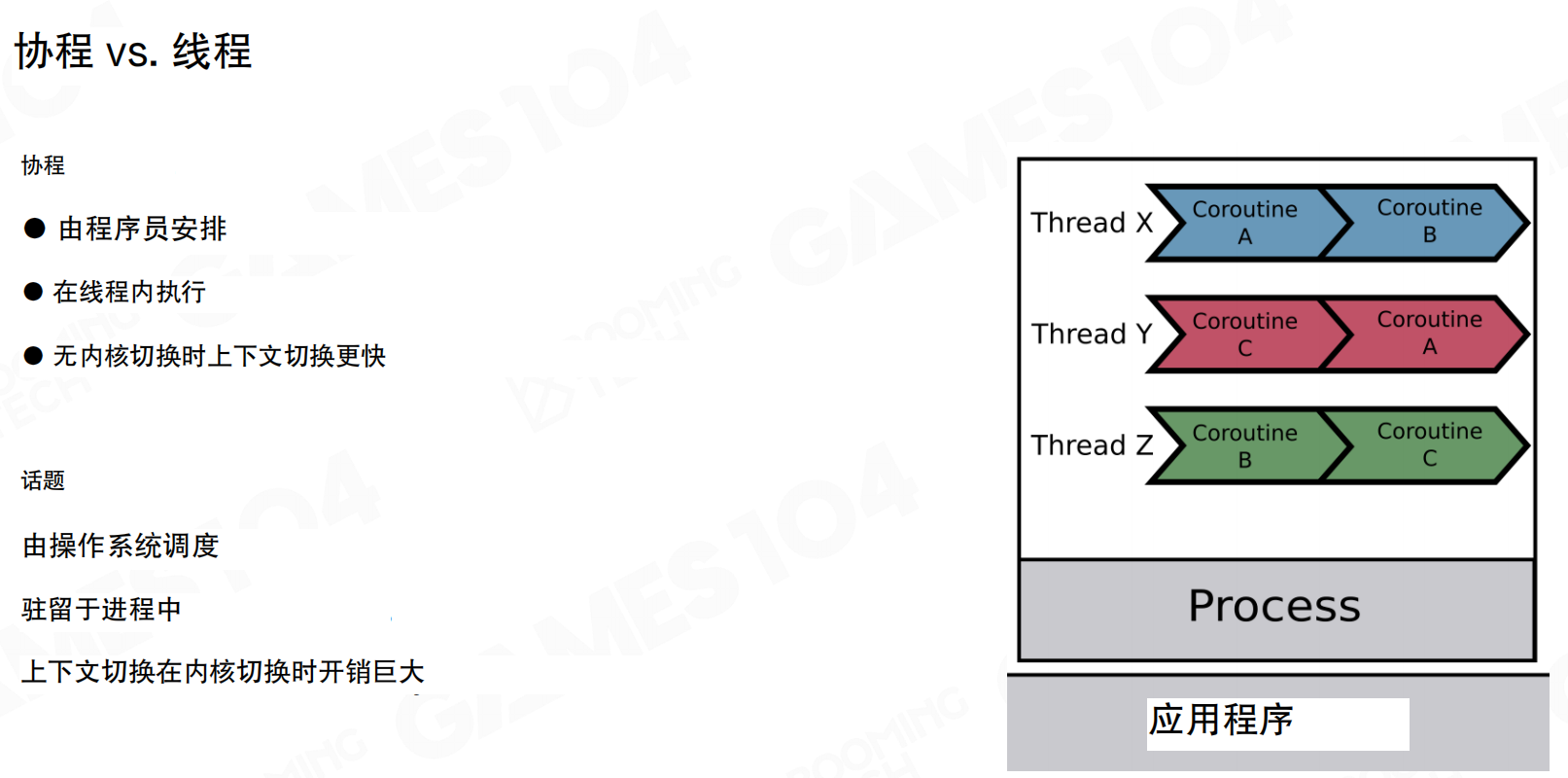
协程与线程的本质区别在于调度方式。线程由操作系统调度,驻留在进程中,上下文切换需要进入内核,开销巨大。协程由程序员安排,在线程内执行,无需内核切换,上下文切换更快。从CPU角度看,协程切换时线程未中断,只是程序逻辑控制切换,未触发内核切换。
有栈协程与无栈协程
协程有两种实现方式:有栈协程(Stackful Coroutines)和无栈协程(Stackless Coroutines)。
有栈协程拥有独立的运行时栈,该栈在yield后仍保留。支持在嵌套堆栈帧内进行yield操作,可像普通函数一样使用局部变量。协程恢复时,所有局部变量和计算状态完整恢复。

无栈协程在yield时没有独立的运行时栈需要保留,只有顶层例程可执行yield操作(子例程因无调用栈而无法确定返回位置)。恢复执行所需的数据应与堆栈分开存储。局部变量在yield后可能丢失,使用更困难。
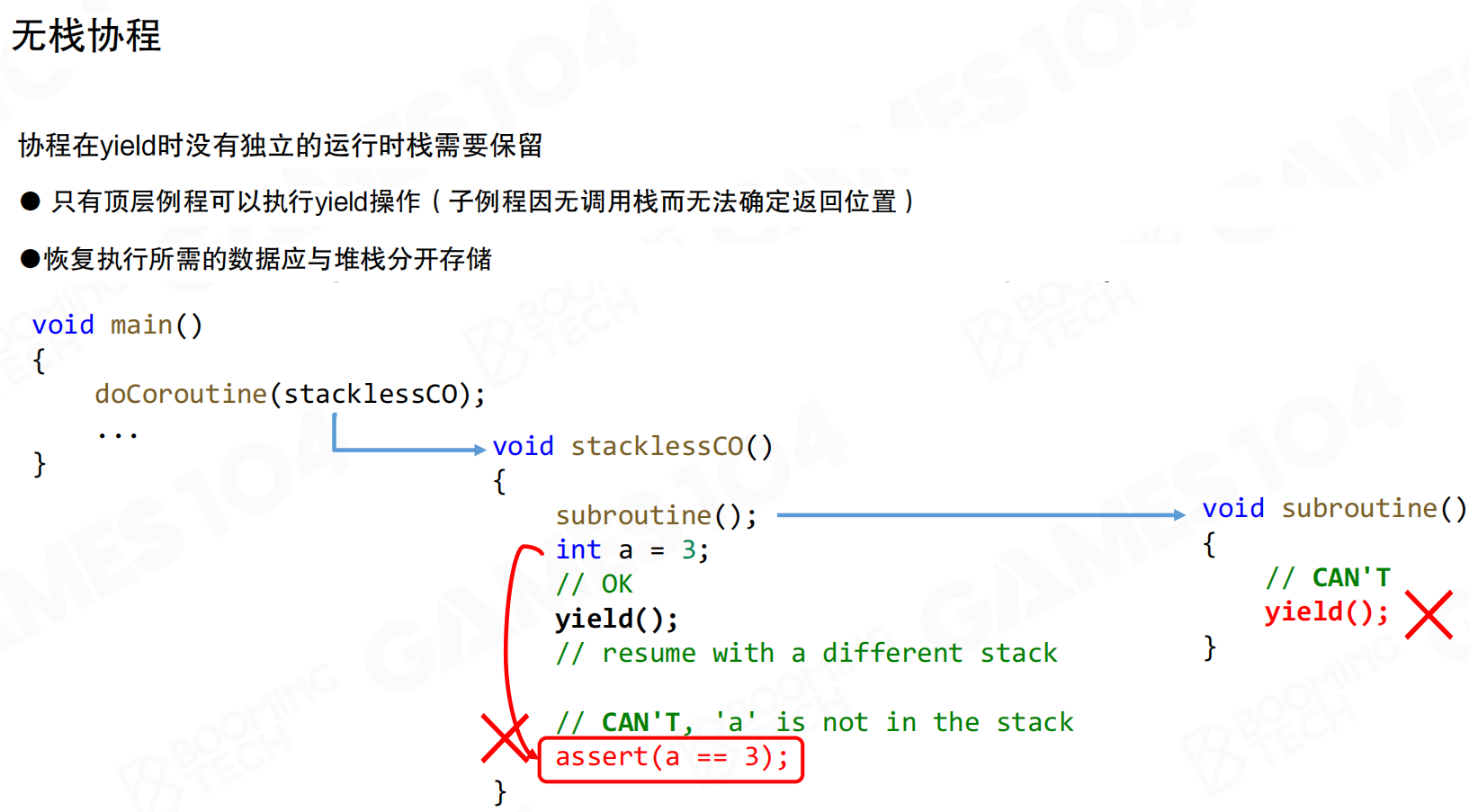
有栈协程功能更强大,支持在嵌套堆栈帧内进行yield操作,但需要更多内存为每个协程预留栈空间,上下文切换时间更长。无栈协程无法在子程序内部执行yield操作,使用更困难,但协程栈无需额外内存,上下文切换更快。

实践中推荐使用有栈协程。尽管切换开销稍大,但可避免状态改变导致的问题。对于需要大量开发者使用的游戏引擎系统,有栈协程提供更好的开发体验,降低使用门槛。
基于纤程的作业系统
基于协程思想可实现基于纤程的作业系统(Fiber-based Job System)。作业(Job)通过纤程(Fiber)执行。Fiber类似于协程,区别在于Fiber由调度器调度。线程是执行单元,纤程是上下文。每个处理器核心对应一个线程,以最小化上下文切换开销。作业在纤程上下文中执行。
可以这样理解:线程是工人,纤程是工作台。一个工人(线程)可以在多个工作台(纤程)之间切换,但不需要离开工厂(CPU核心)。当某个工作台的任务需要等待时,工人可以切换到另一个工作台继续工作,而不是停下来等待。

多核环境下,尽可能保证一个线程对应一个核(包括逻辑核),进一步减少线程切换开销。这是Fiber系统的核心思想:系统内线程切换几乎为零。只要不触发硬件中断,效率就很高。
例如,8核CPU就像8个工厂,每个工厂(CPU核心)配备一个固定工人(线程)。这个工人不会离开自己的工厂,但可以在工厂内的多个工作台(纤程)之间自由切换。当工作台A的任务需要等待材料(IO操作)时,工人立即切换到工作台B继续工作,工厂始终在运转。由于工人只在同一工厂内的工作台间切换,不需要跨工厂调动,避免了昂贵的调度成本。传统多线程系统就像工人需要在不同工厂间跑来跑去,而Fiber系统让工人固定在一个工厂内,只需在工作台间移动,效率自然更高。
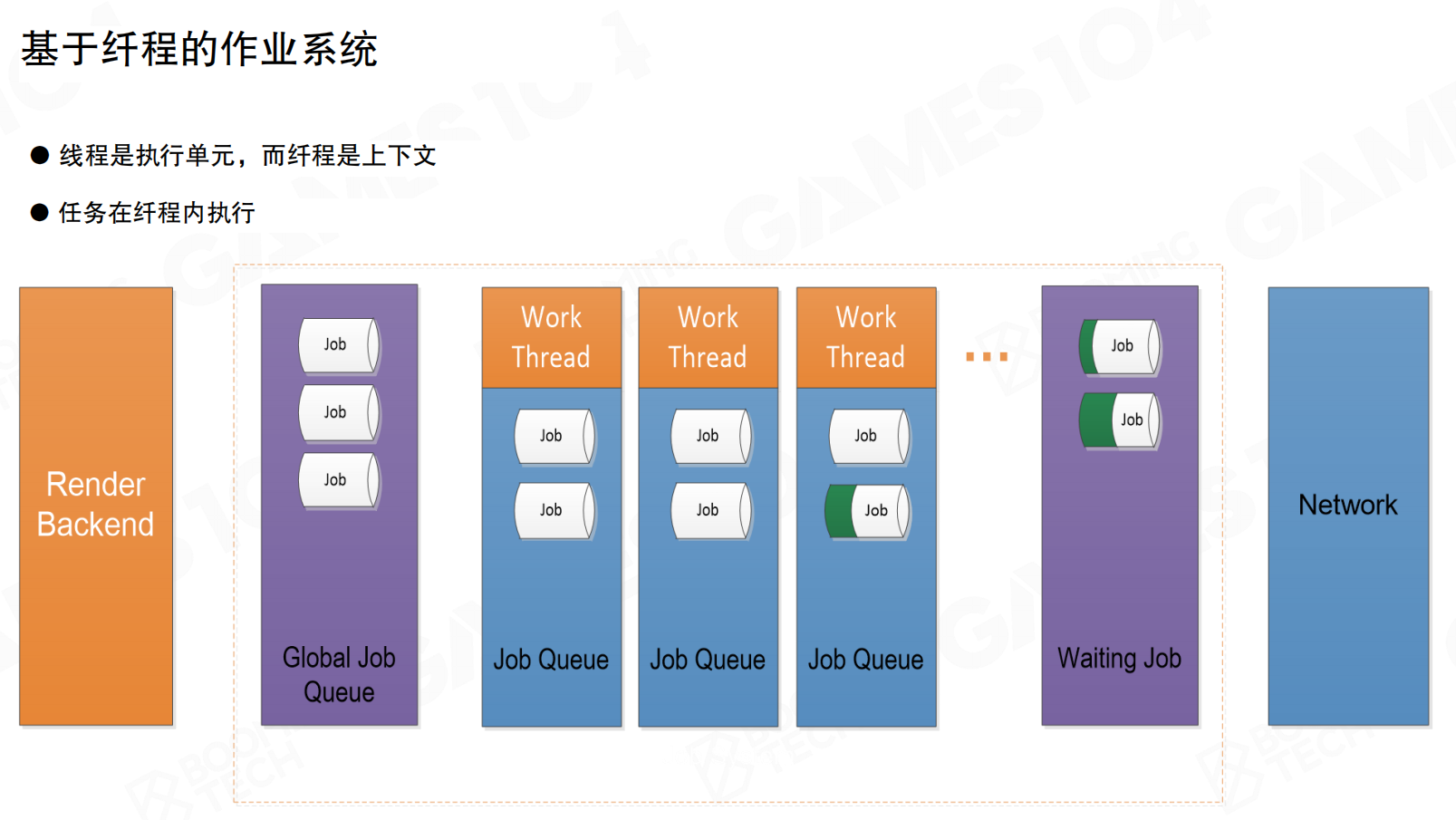
作业调度机制
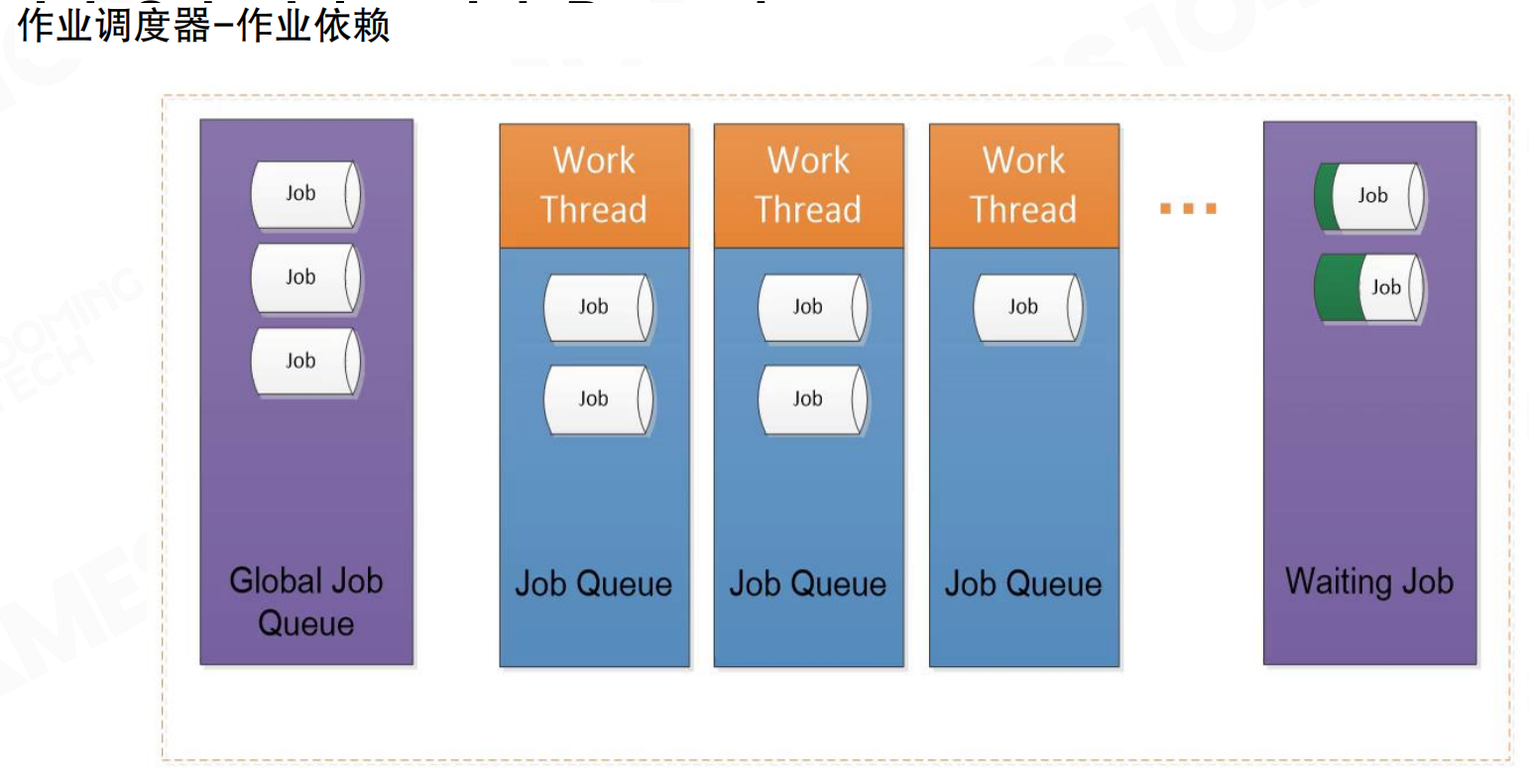
系统根据程序需要生成大量Job,调度器根据线程负载分配到合适的线程及线程上的Fiber中。系统包含全局作业队列(Global Job Queue)、各工作线程的作业队列(Job Queue)和等待作业队列(Waiting Job)。作业从全局队列分配到各工作线程,执行完成后可能进入等待队列。
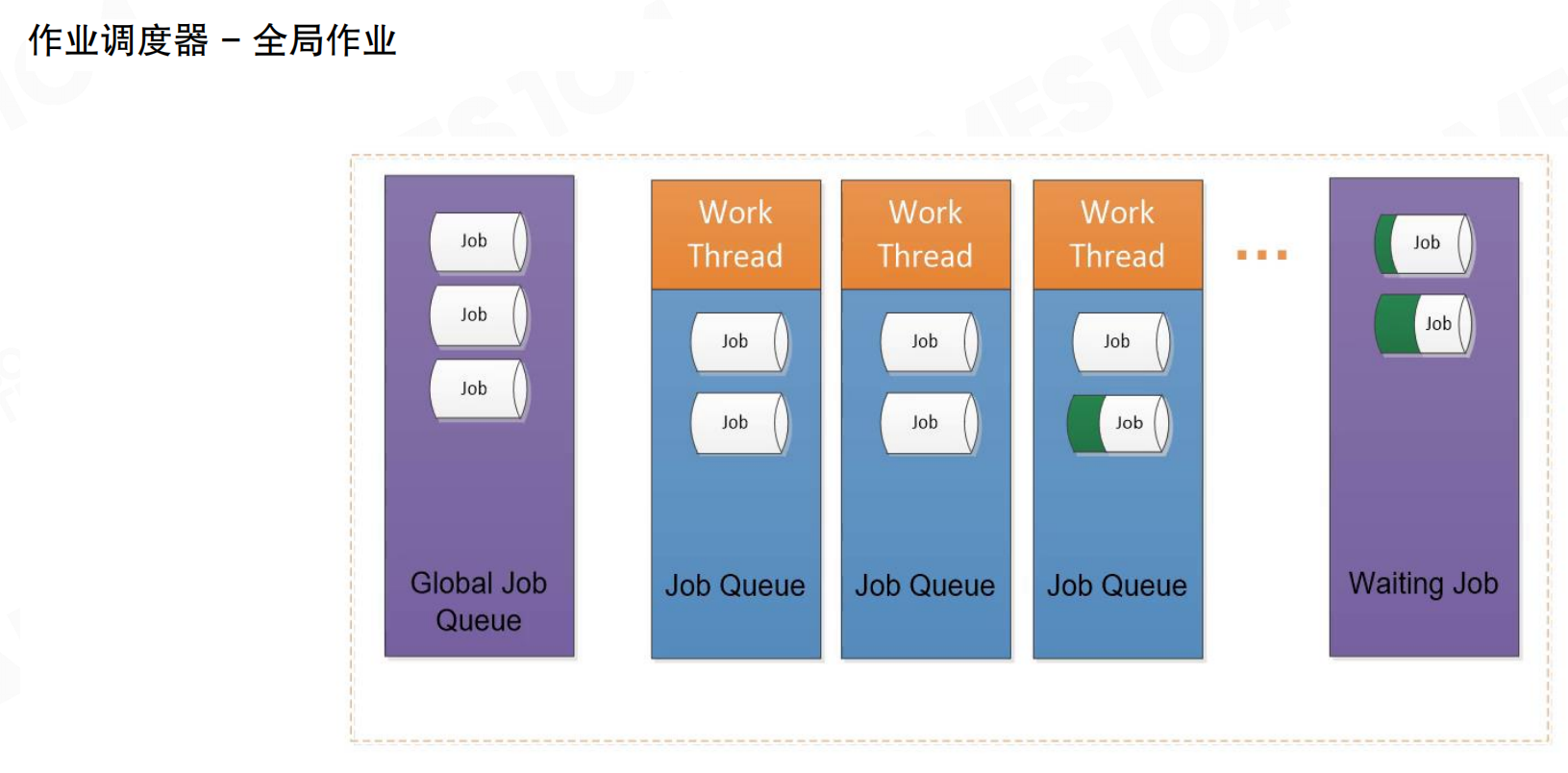
Job执行顺序分为FIFO(先进先出)和LIFO(后进先出)两种模式。游戏引擎实践中通常选择LIFO模式。游戏引擎中,许多Job的产生是前一个Job执行到一半时fork出多个新Job,这些新Job执行过程中又可能fork出更多Job。它们之间存在依赖关系,fork出的任务未完成时,自身无法完成。因此采用后进先出的堆栈方式。

当Job出现依赖时,将当前Job移动到等待区,执行线程中的下一个Job。这种方式可减少CPU等待,提高效率。调度器管理依赖关系,确保依赖任务完成后,等待的Job能正确恢复执行。
线程闲置时,调度器将其他线程中的Job移动到闲置线程进行计算。这是作业窃取(Job Stealing)机制。无论调度器设计多好,实际仍无法准确估计每个任务的执行时间,因为任务运算复杂度、IO等待、依赖关系都可能导致执行时间不可预测。必然出现部分工作线程已完成、部分仍有大量任务的情况。调度器将未完成线程中的任务”窃取”到空闲线程中执行。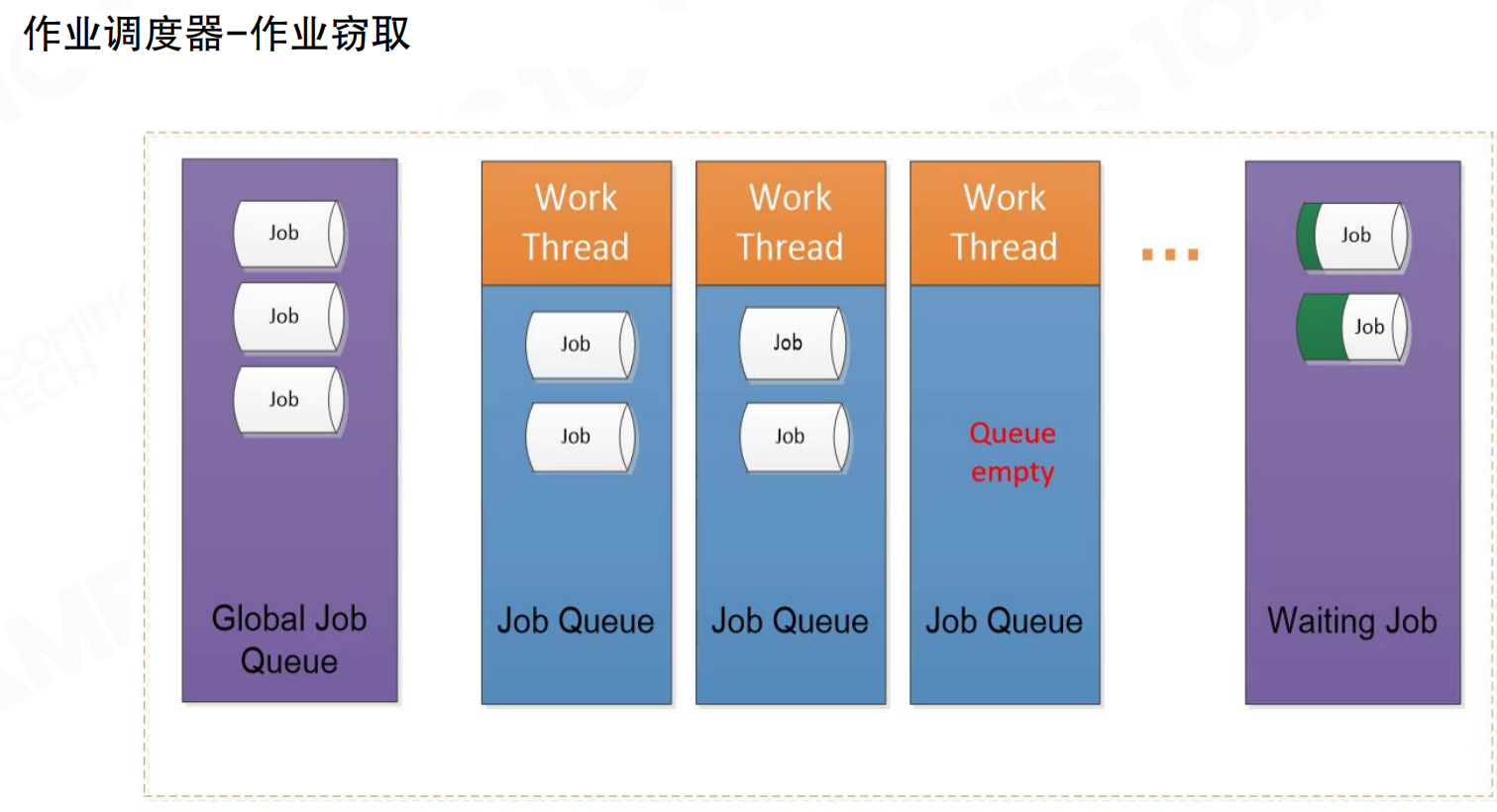
任务系统的优缺点
相比前述多线程方法,任务系统能更好地利用多核并避免线程切换,提升计算性能。它易于实现任务调度,易于处理任务依赖关系,作业栈隔离,避免频繁上下文切换。

任务系统也存在挑战:首先,C++本身不支持纤程,需要自行实现协程机制(可使用Boost等库,但不同操作系统实现方式存在差异)。其次,存在限制,如thread_local无效。更重要的是,实现真正鲁棒的Job System需要对多线程硬件底层开发有深入理解,需防范所有并行编程可能出现的异常情况,否则可能构建出看似完善但实际在复杂业务逻辑下容易崩溃的系统。
20.4 编程范式
编程范式(Programming Paradigms)对程序性能有重要影响。游戏引擎中会使用多种编程范式实现不同功能。编程语言并不总是与特定范式绑定,实践中某些范式被广泛采用。
面向过程编程
早期游戏通常使用面向过程编程(Process-Oriented Programming, POP)。POP采用逐步推进的方式,通过一系列指令将任务分解为变量和例程(或子例程)的集合。

POP的问题在于:用这种方式编写游戏引擎几乎不可能。数据维护不善,与现实世界物体的关联性难以建立。对于现代游戏引擎的复杂系统,POP已无法满足需求。
面向对象编程
随着游戏系统复杂度提升,面向对象编程(Object-Oriented Programming, OOP)在现代游戏引擎中起重要作用。OOP基于”对象”概念,对象可包含数据和代码。人类以面向对象方式从现实世界抽象是很自然的。
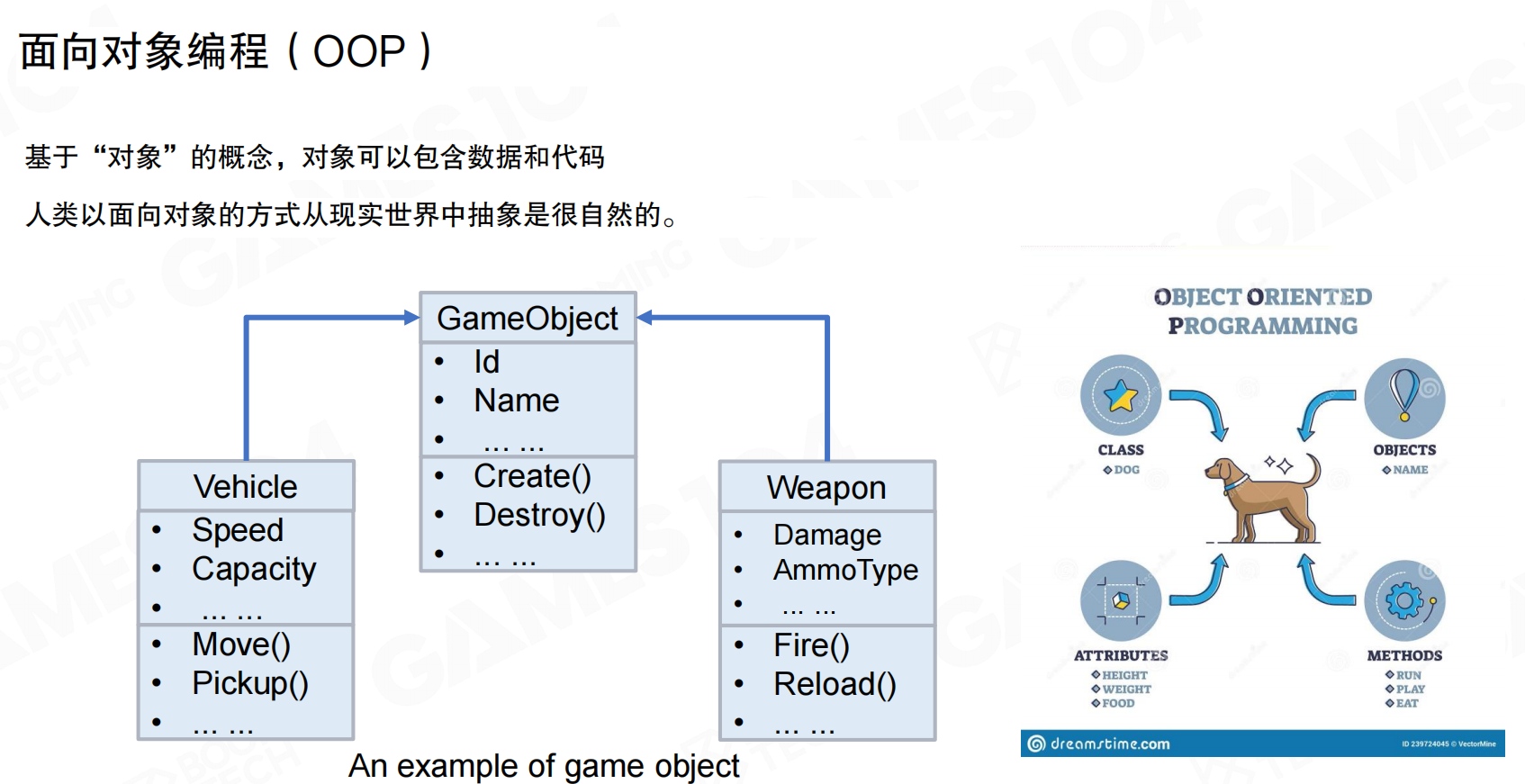
OOP通过类(Class)定义对象模板,对象(Object)是类的实例,具有属性(Attributes)和方法(Methods)。游戏引擎中常见的继承关系如GameObject作为基类,Vehicle和Weapon作为派生类,各自拥有特定属性和方法。
面向对象编程的问题
尽管OOP符合人类认知,但在实践中存在诸多问题。
代码放置的二义性
OOP存在二义性问题:角色的攻击行为既可以写在角色身上(Attacker.doDamageTo()),也可以写在被攻击者身上(Victim.receiveDamage())。类似地,Player.attachTo()还是Enemy.isAttached()?不同程序员有不同的写法,导致代码一致性差。

继承树中的方法分散
OOP中存在大量继承关系,难以确定方法具体在哪个类中实现。当玩家攻击蜘蛛敌人时,需要检查许多不同的类和方法来寻找答案。在深不见底的继承树中查找函数实现是件头疼的事。
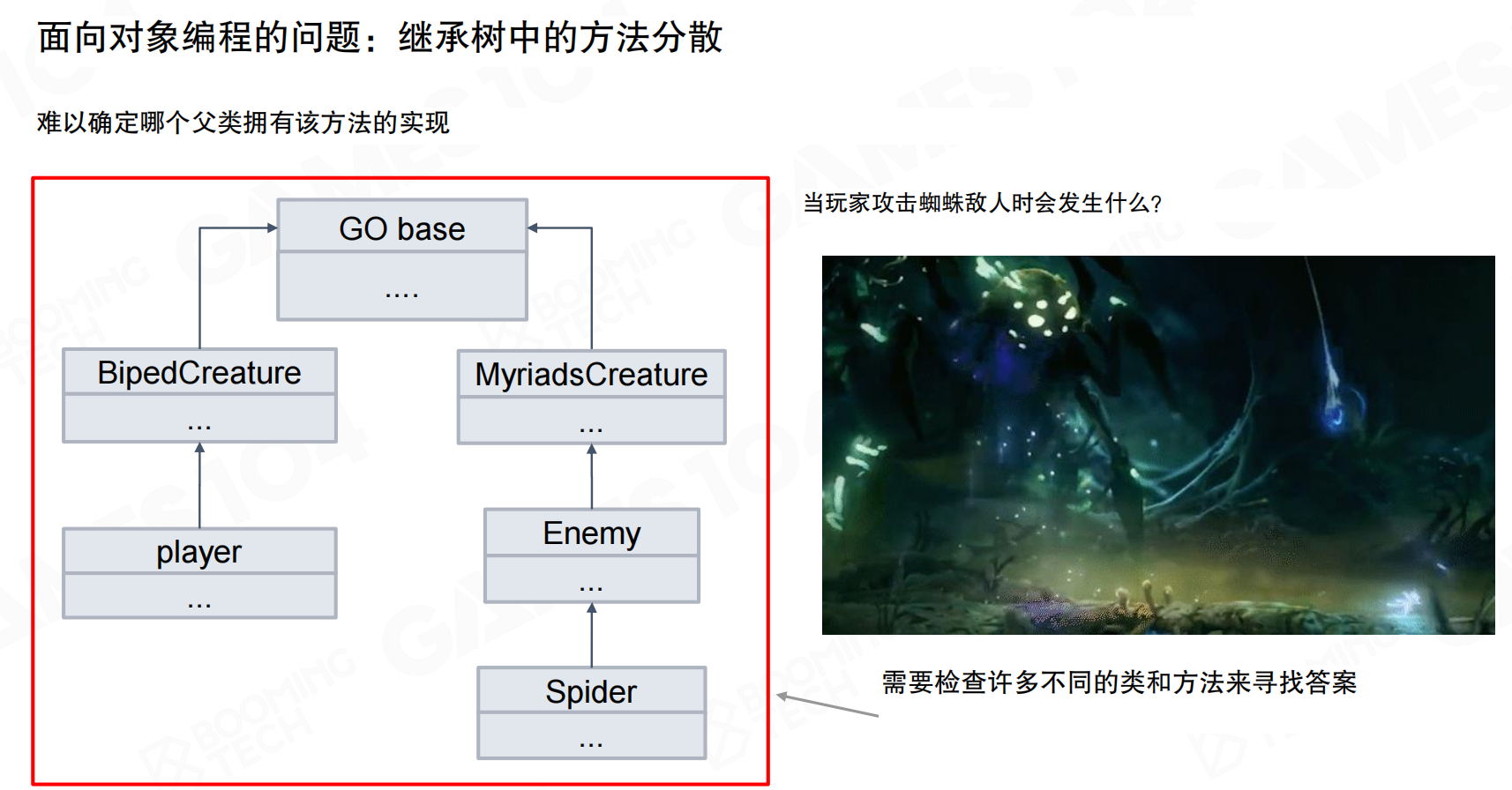
混乱的基类
基类往往需要提供非常多的功能,对于很多派生子类来说这样的基类过于臃肿。找到一些通用的方法就放到基类里,结果得到了一个混乱的基类。这并非最佳面向对象设计,虽然完全可以做出更好的方案,但现实中代码往往演变成这样,即便无人刻意为之。

性能问题
OOP最大的问题在于性能可能很低。尽管OOP符合人的认知,但对象的数据往往分布在不同的内存区域上,导致程序运行时浪费大量时间读取数据。内存分散,每个对象的创建和销毁都是分散进行的,在内存中呈现”东一块西一块”的分布。
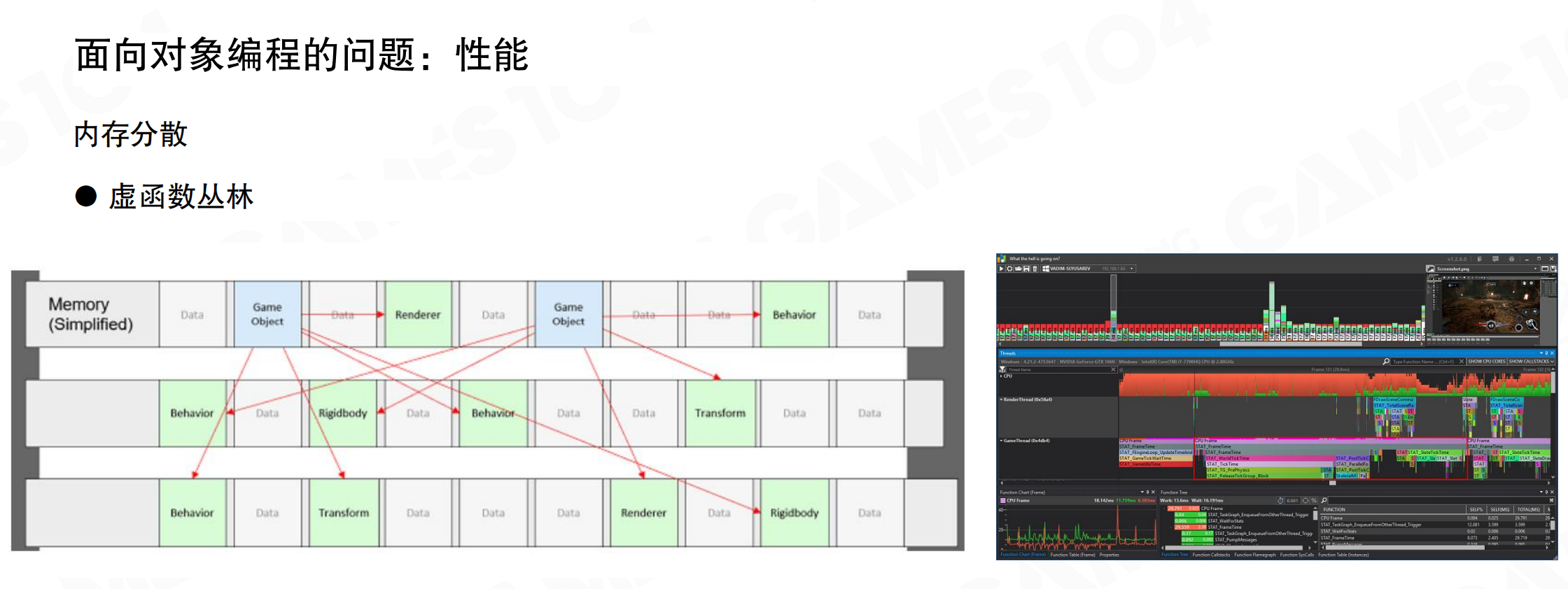
OOP中还有虚函数(Virtual Function)的问题。虚函数全是指针,代码在内存中跳来跳去。执行到某处突然跳到另一个地方执行另一个函数,导致缓存命中率低。用性能分析工具查看OOP系统的profiling时,会发现性能非常不稳定。
可测试性问题
OOP的可测试性非常差。面向对象设计通常需要大量初始化设置才能进行测试。要测试一个soldier.attack()方法,需要设置多个soldier对象,这又需要初始化游戏对象模型、加载基础属性、设置动画树、设置电机状态等。这与单元测试的思想相违背——单元测试理想情况下应该只测试特定模块的数据,而不需要创建整个对象体系。
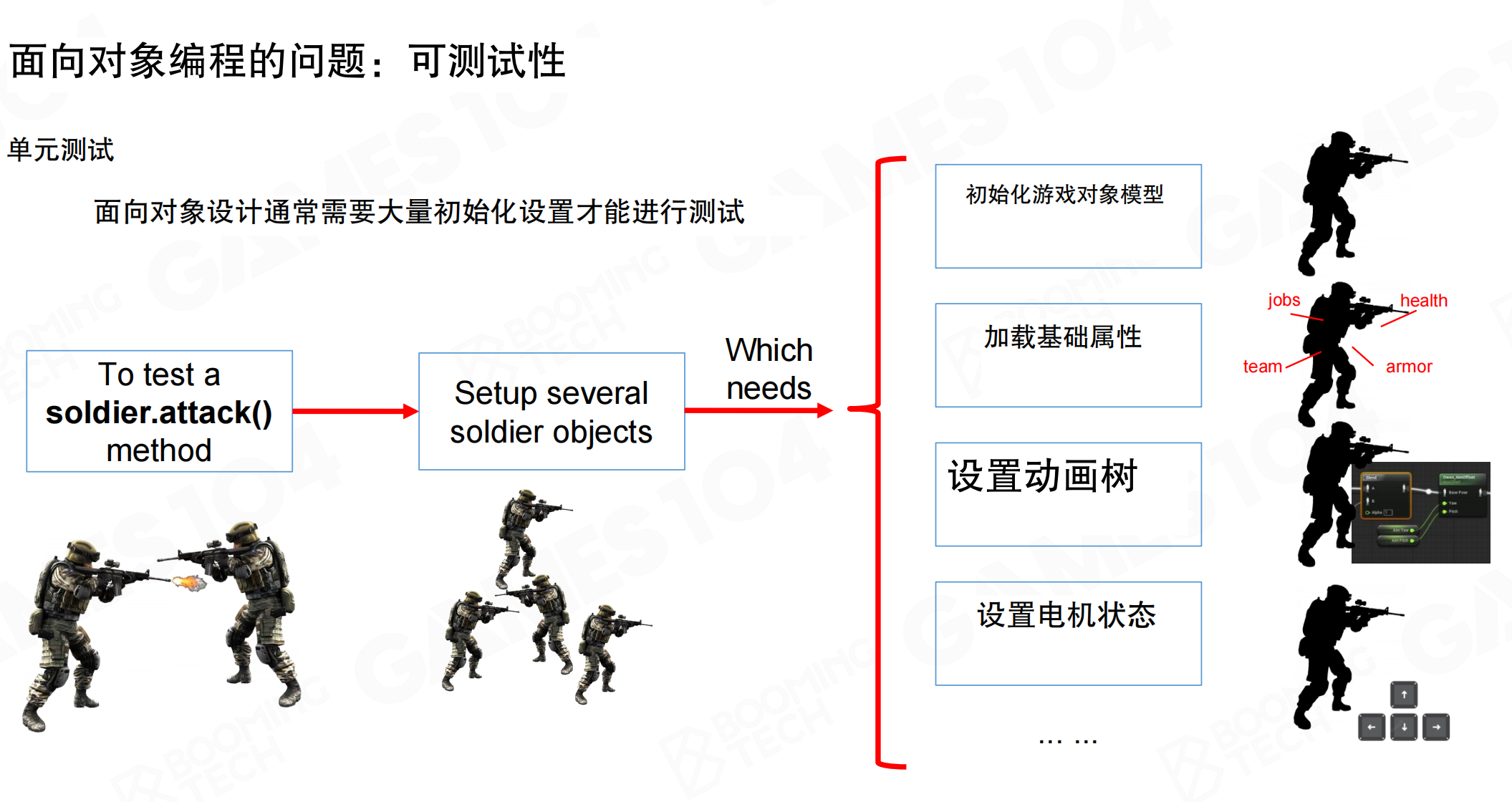
在几百万行代码的游戏引擎中,可测试性要求非常高。OOP系统很难将一个元素提取出来单独进行测试,这是传统OOP的一大问题。
20.5 面向数据编程
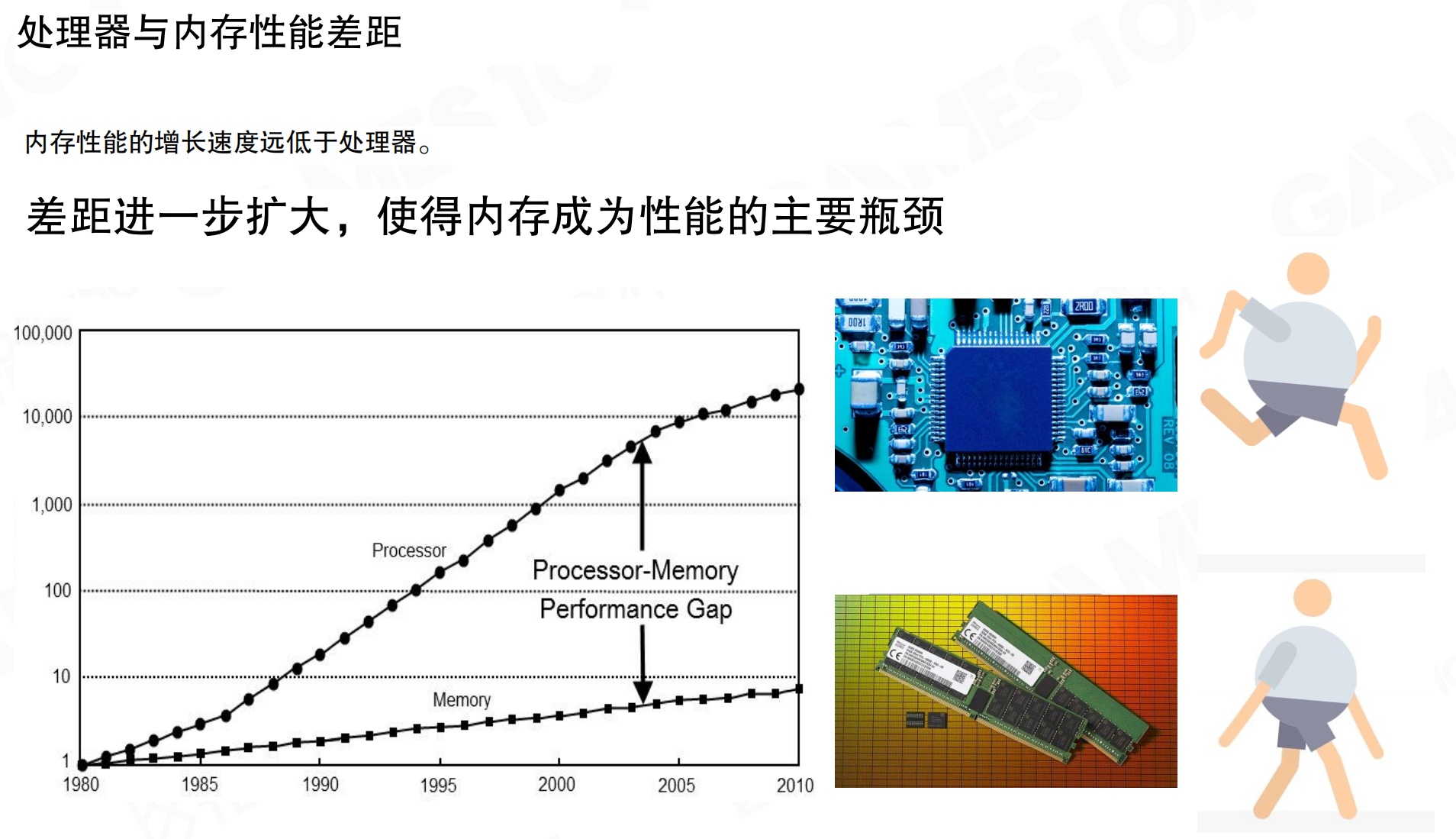
面向数据编程(Data-Oriented Programming,DOP)的核心观点是:现代硬件中,限制性能的往往是内存访问而非计算能力。处理器性能增长远快于内存,两者之间的性能差距(Processor–Memory Performance Gap)持续扩大,导致”等待数据”成为主要瓶颈。
多级缓存
为缩小性能差距,现代CPU采用多级缓存(Cache)将热数据保留在更靠近核心的位置。典型的多级缓存结构包括:
- L1缓存:容量小、速度最快,通常区分指令缓存(Instruction Cache)与数据缓存(Data Cache),延迟约1ns。
- L2缓存:容量更大、速度稍慢,延迟约3ns。
- L3缓存:容量最大,通常多核共享,延迟约10ns。
- 主内存:延迟约100ns。
数据从L1逐级向下查找(L1→L2→L3→内存)时,延迟按数量级放大。缓存命中率直接决定性能上限。

局部性
缓存机制有效的前提是程序访问数据具有局部性(Locality):
- 时间局部性:短时间内重复访问同一块内存,同一批数据被反复使用。
- 空间局部性:访问某个地址后,倾向于继续访问附近的地址,数据在内存中相邻。
如果数据在内存中连续存储,CPU一次取回一段连续数据后,后续访问更容易落在同一段内,提高缓存命中率。
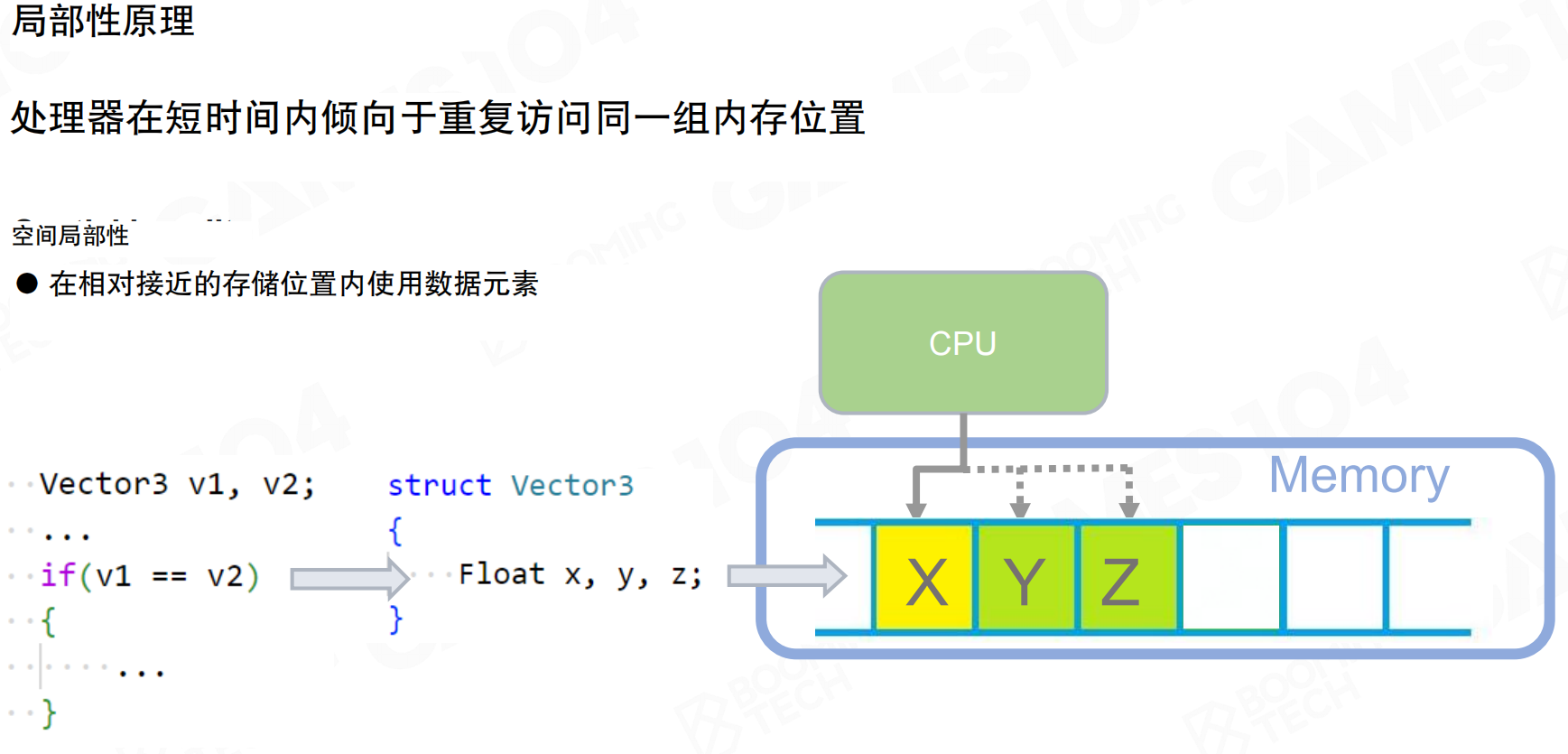
单指令多数据
单指令多数据流(SIMD)充分利用局部性:一次指令对多个元素执行同一种运算。
普通标量流程需要多次加载、计算、存储。SIMD将多个8-bit或32-bit数据打包进寄存器,一次完成一组运算,减少指令条数与访存次数。
在引擎实现中,这意味着数据布局应更利于批量处理,而非围绕对象将字段分散存储。
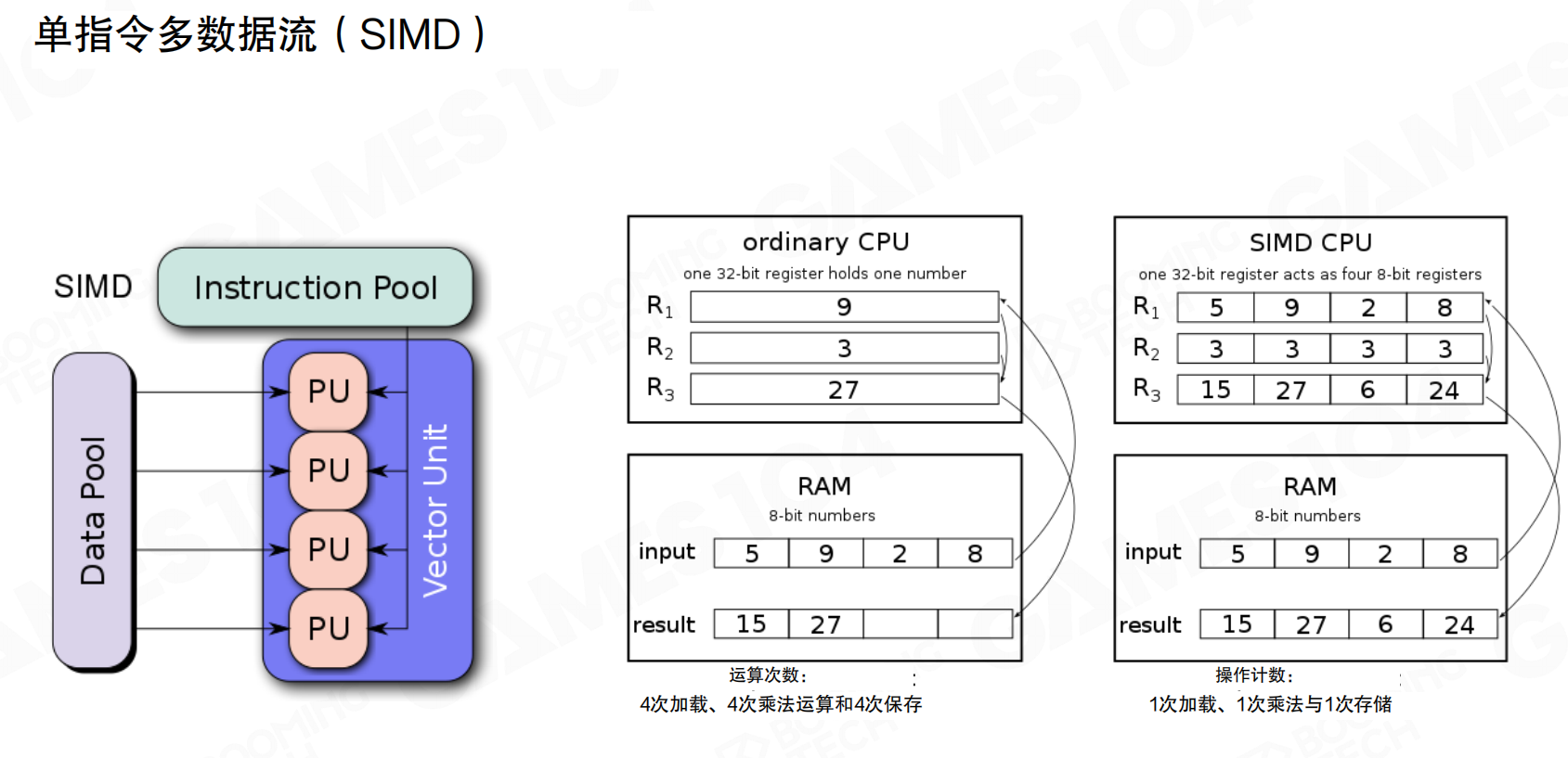
缓存置换
缓存容量有限,需要置换策略。最近最少使用(LRU,Least Recently Used)是常见策略:
- 记录每条缓存行的上次使用时间(或等价序号)。
- 缓存满时,优先置换最久未使用的条目。
例如访问序列A、B、C、D、E、D、F:访问E时发生miss,替换最久未用的A;访问F时再次miss,替换最久未用的B。核心目的是将有限缓存尽量留给近期还会再用的数据。
工程实践中,也常采用近似策略(如随机置换)降低维护成本。只要整体能保持局部性,收益依然明显。
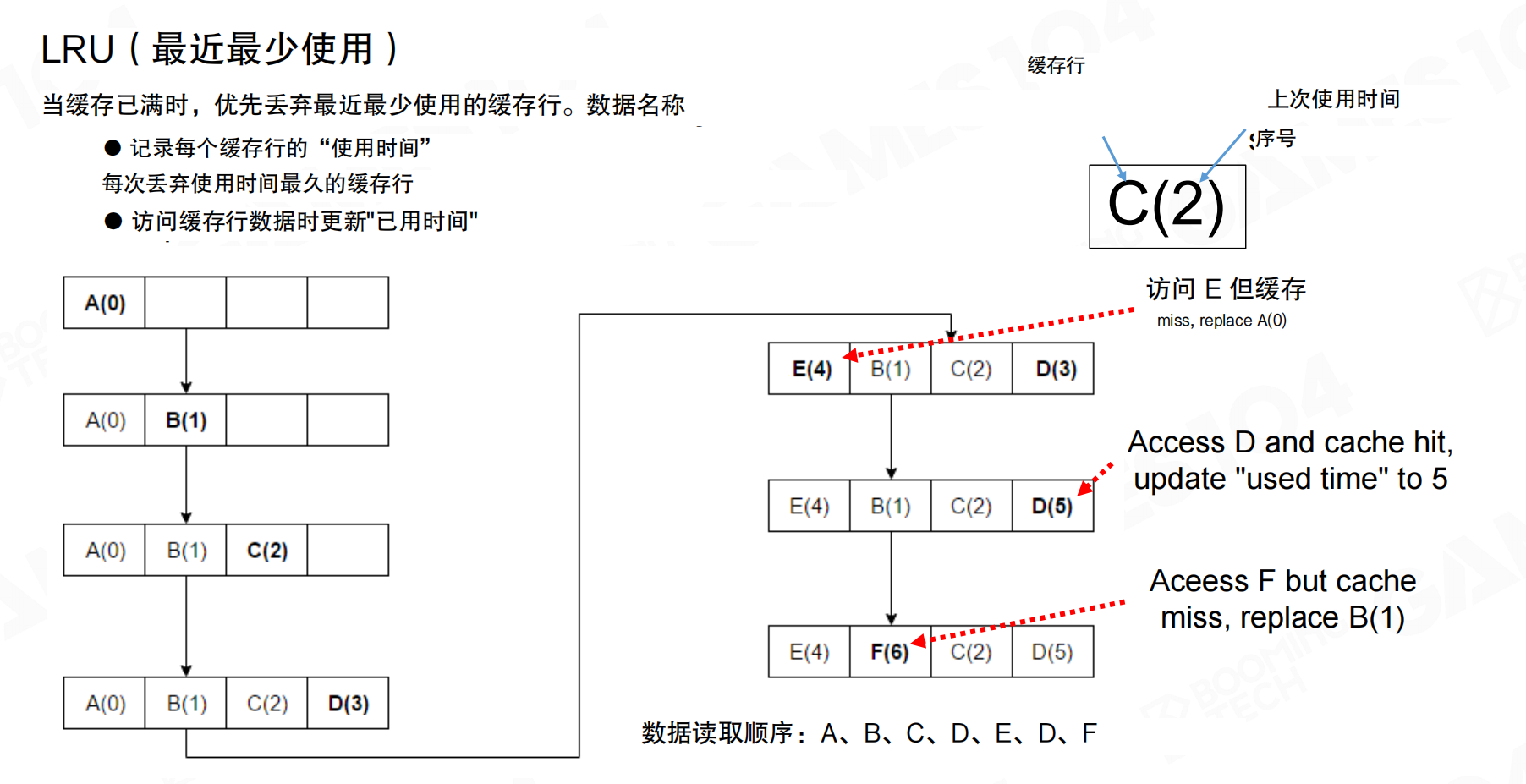
缓存行
从编程视角看,CPU与内存之间搬运数据的单位不是单个变量,而是缓存行(Cache Line)。
关键点:
- 数据在内存与缓存之间以固定大小的块传输,通常为64字节。
- 读取一个地址时,实际会加载其所在的整条缓存行。
如果访问模式能充分利用同一条缓存行内的数据(空间局部性),性能会显著提升。反之,如果每次只用到缓存行的一小部分,会造成大量浪费。
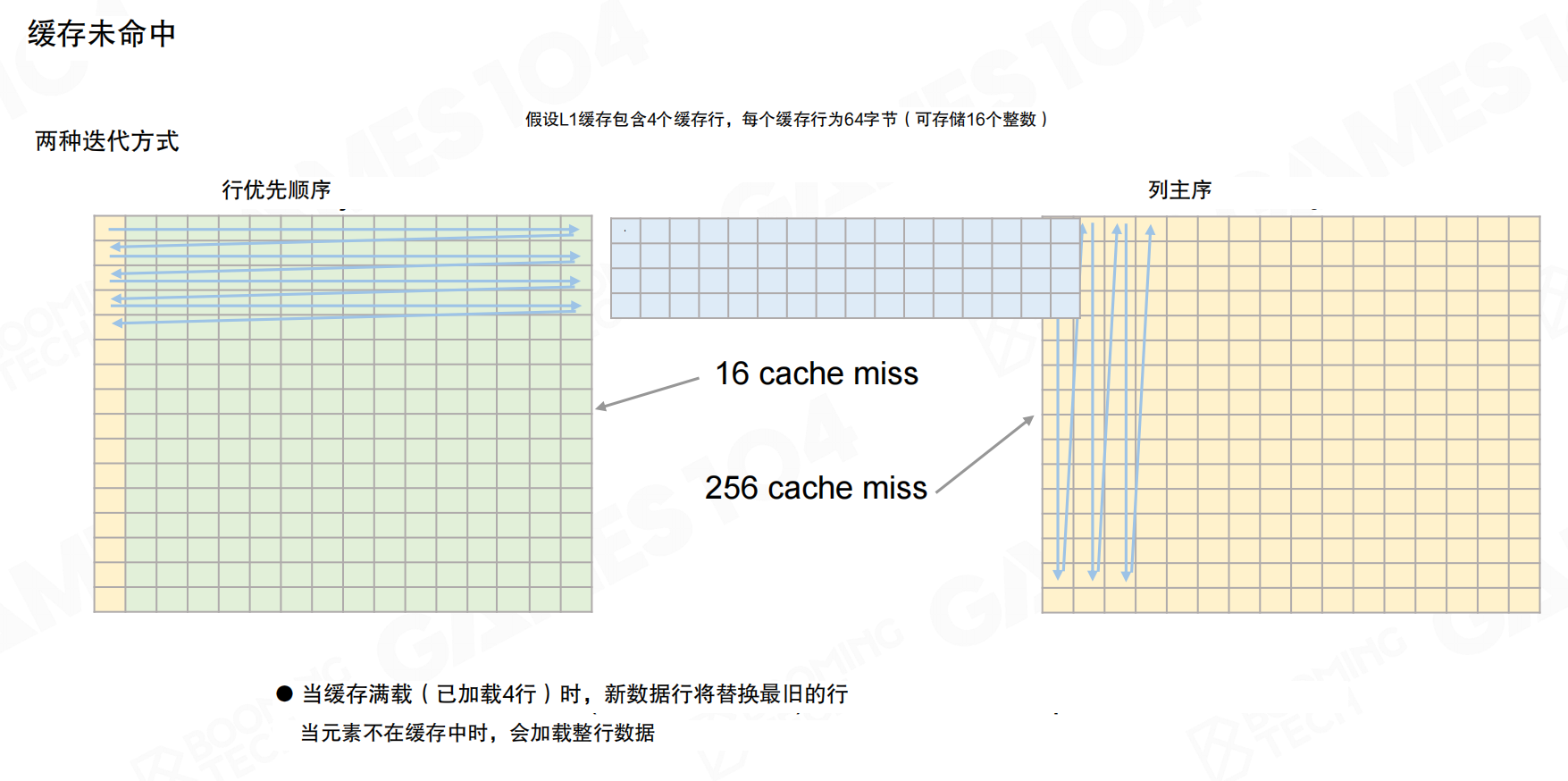
访问顺序
访问顺序直接影响性能。以矩阵遍历为例:
- 行优先:访问顺着内存连续布局,缓存行能被充分复用,miss次数少。
- 列主序:访问跨越大步长,几乎每次都要加载新缓存行,miss次数大幅上升。
同样的算法和数据量,仅改变循环顺序,性能可能相差一到两个数量级。
世界是数据
DOP将游戏世界视为数据的集合。一帧游戏画面包含:静态物体模型、粒子特效、地形网格、敌人距离、联盟信息、地图数据、弹药量、武器类型等。这些最终都表现为结构化数据。引擎需要以尽可能低的缓存未命中率,将这些数据加工成可用的结果。

指令也是数据

除了数据访问,指令也会发生缓存未命中。代码在内存中的分布影响指令缓存命中率。大量间接调用或分支发散会让指令缓存更难命中。性能分析显示,指令缓存未命中(ICache Misses)可能占到相当比例的时钟开销。
性能敏感代码不仅要数据友好,也要指令友好:减少间接调用、避免分支发散、保持代码路径紧凑。
让代码与数据一起变紧凑
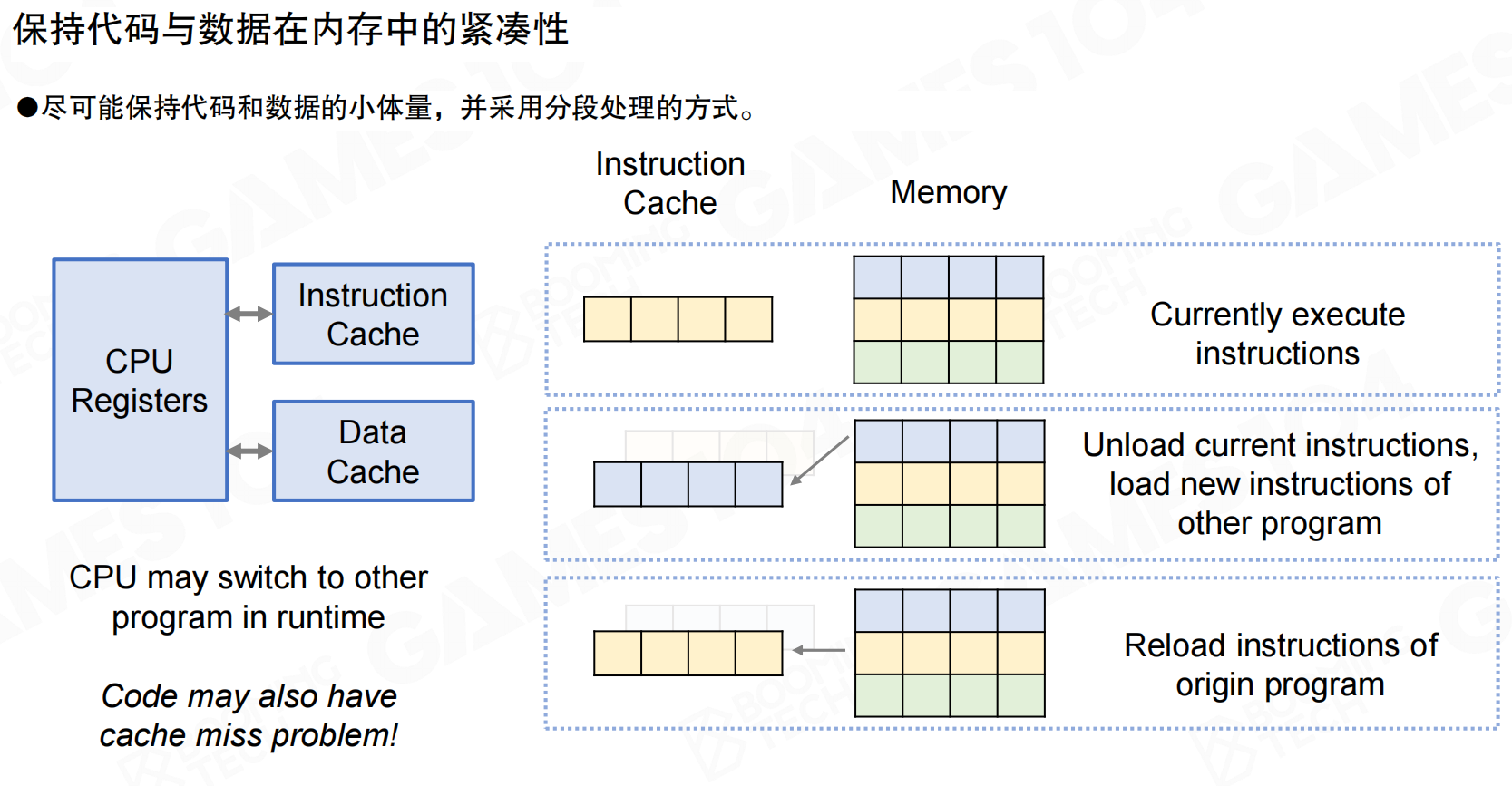
DOP的工程实践要点是保持代码与数据在缓存中的紧凑性。指令缓存与数据缓存各自有工作集(working set),运行时切换到其他代码路径会带来重新装载指令的成本。
对应到引擎实现,常见策略包括:
- 分段处理:将一帧拆成若干阶段,每个阶段处理一小批相邻数据,阶段内尽量复用同一套指令与数据。
- 批处理优先:同类对象或组件集中处理,减少在不同代码路径之间切换。
- 缩小工作集:让当前阶段真正需要的数据更少、更连续,更容易驻留在缓存中。
20.6 性能敏感编程
基于DOP思想设计高性能程序,需要关注几个关键点:减少顺序依赖性、避免伪共享、优化分支预测。
降低顺序依赖性

减少顺序依赖性(Reduce Sequential Dependencies)是并行化的前提。如果代码段之间存在变量依赖(同一变量被重新赋值),就无法并行执行。
例如,两段代码分别执行a=2; b=a*5和a=4; b=a/2,由于变量a和b被重复使用,存在写后读依赖,无法并行执行。
编译器使用静态单赋值(SSA,Static Single Assignment)处理这类情况:将第二段代码中的变量重命名为a2和b2,消除变量名依赖,使两段代码可以并行执行。SSA的核心原则是:变量一旦完成初始赋值就绝不再修改。
缓存行中的伪共享
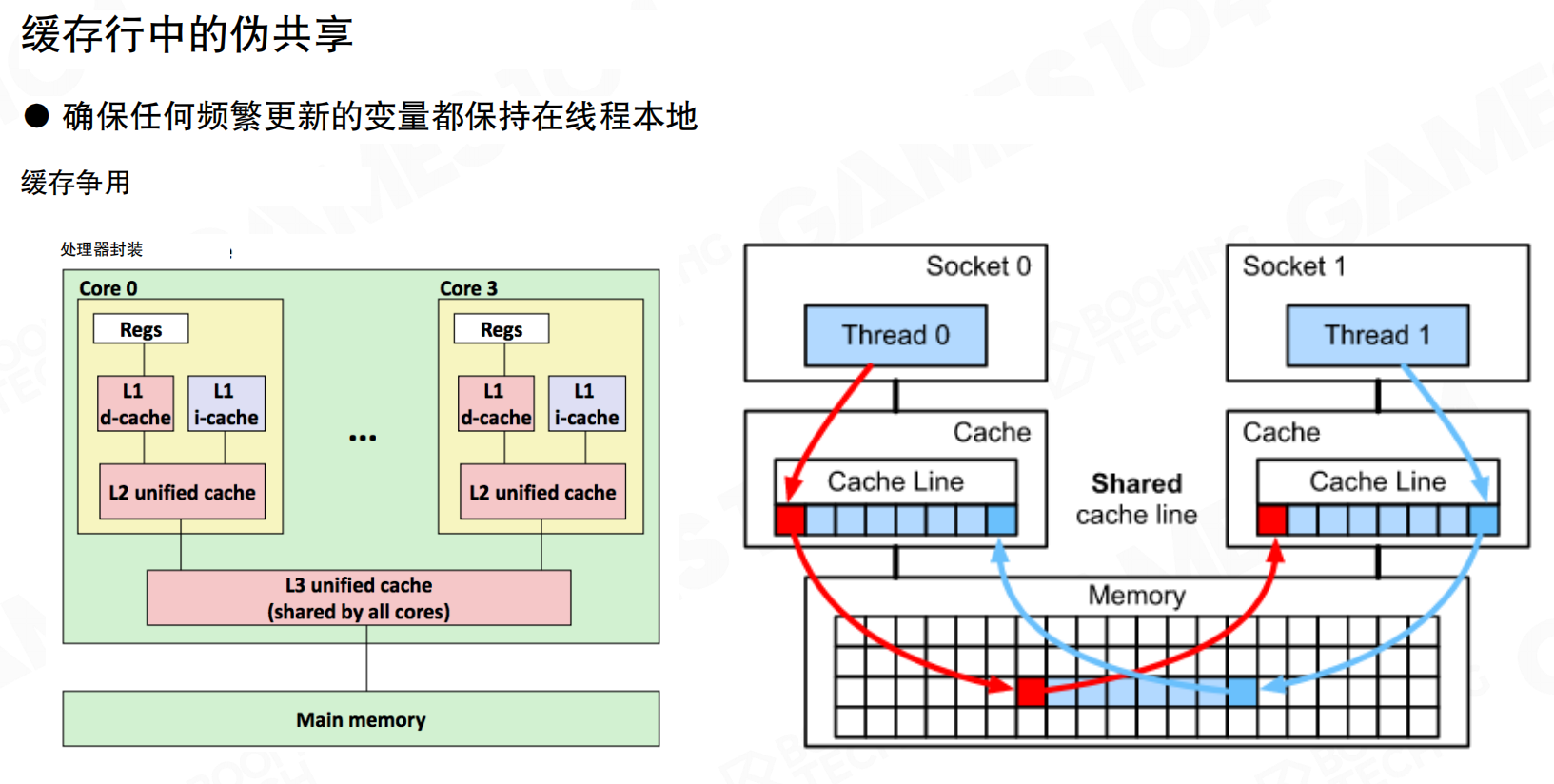
多线程程序中,即使两个线程访问不同的变量,如果这些变量位于同一缓存行(64字节),也会产生伪共享(False Sharing)。
两个线程分别访问同一缓存行的不同部分时,一个线程的写入会导致整个缓存行在所有线程的缓存中失效,需要重新从内存加载。即使两个线程写入的地址不同,只要在同一缓存行范围内,就会导致大量内存交换开销。
可以这样理解:缓存行就像一个共享的笔记本,64字节是一页纸的大小。线程A在笔记本的第1行写数据,线程B在第10行写数据,虽然写的是不同位置,但都在同一页纸上。当线程A修改第1行时,整个页面(缓存行)被标记为”已修改”,线程B的缓存中这一页就失效了,必须重新从主内存读取整页内容。即使线程B只关心第10行,也不得不重新加载整页,造成不必要的性能损失。
实际场景中,如果两个线程各自维护一个计数器(如thread1_counter和thread2_counter),它们恰好定义在相邻内存位置,可能落在同一缓存行内。虽然两个线程访问的是完全独立的变量,但频繁更新会导致缓存行在CPU核心间反复失效和同步,性能可能下降数十倍。解决方案是让每个线程的频繁更新变量保持足够的间隔(至少64字节),或者使用线程本地存储,确保它们不在同一缓存行。
确保频繁更新的变量保持在线程本地,避免不同线程访问同一缓存行。这是编写高性能多线程系统时必须注意的问题。
分支预测
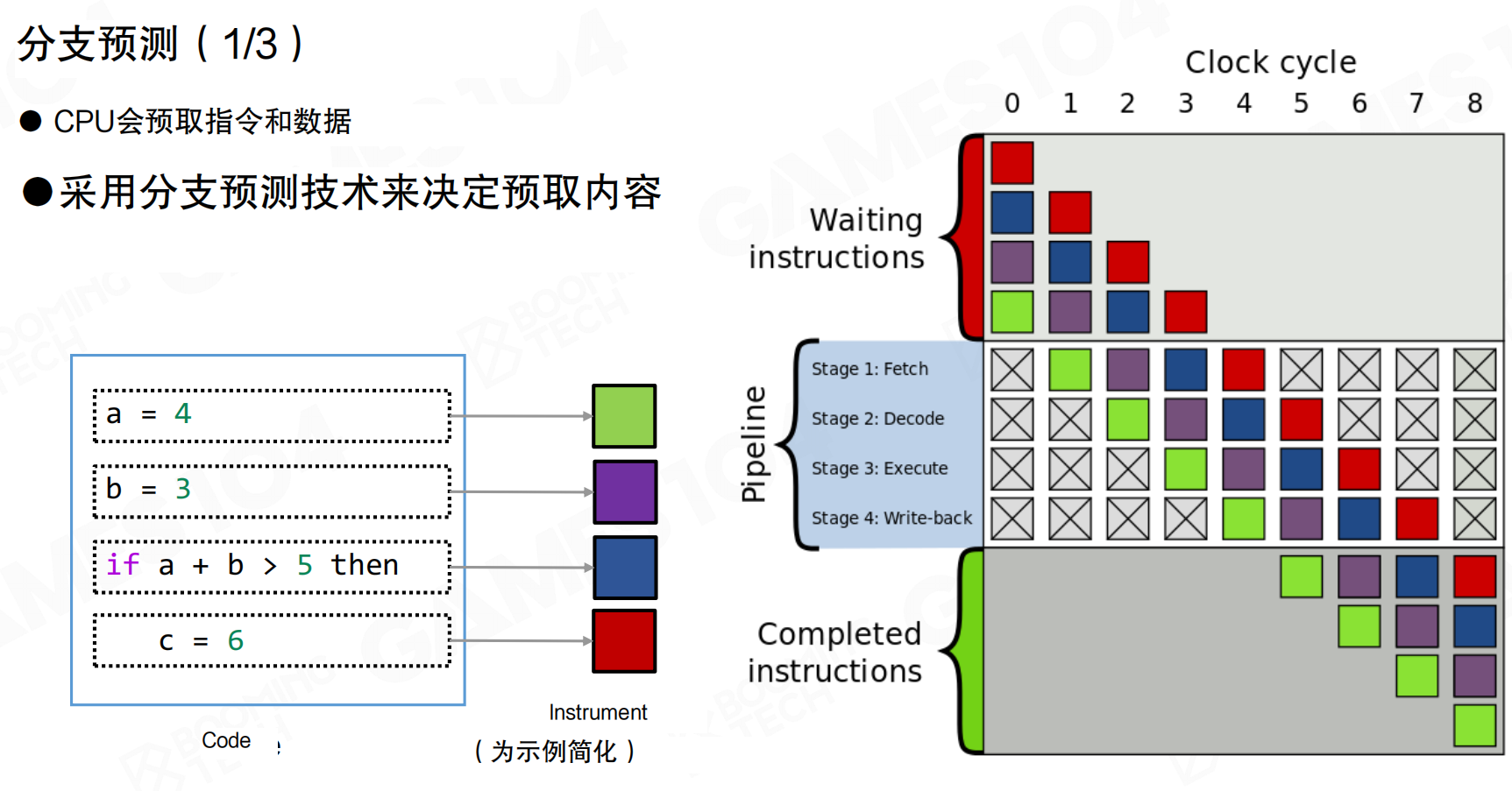
CPU会预取指令和数据,采用分支预测技术决定预取内容。现代CPU使用指令流水线(Pipeline)并行执行指令,包含Fetch、Decode、Execute、Write-back等阶段。
当遇到分支语句(如if-else)时,CPU会预测最可能执行的分支,提前将该分支的指令加载到L1缓存中。如果预测正确,流水线可以连续执行;如果预测错误,需要清空流水线,从内存重新加载正确分支的指令,造成性能损失。

分支预测错误会导致严重的性能下降。例如,循环中根据数组元素值选择执行doFunc1()或doFunc2()。CPU基于历史模式预测下一个分支,但如果数据模式不规则,预测会频繁出错。
当预测错误时,CPU预取的指令和数据无效,需要从内存重新加载正确分支的代码。如果这段代码不在L2或L3缓存中(冷代码),需要从主内存加载,等待时间可能达到数百个时钟周期。

如果数据是有序数组,分支预测错误会大幅减少。例如,将数组排序后,小于等于10的元素在前,大于10的元素在后。CPU只需要在分界点处预测错误一次,之后的分支预测都会正确。
对于有序数组,仅会出现1次预测失误,性能显著提升。即使排序本身有开销,如果后续处理逻辑复杂,整体性能仍会提升。
存在性处理
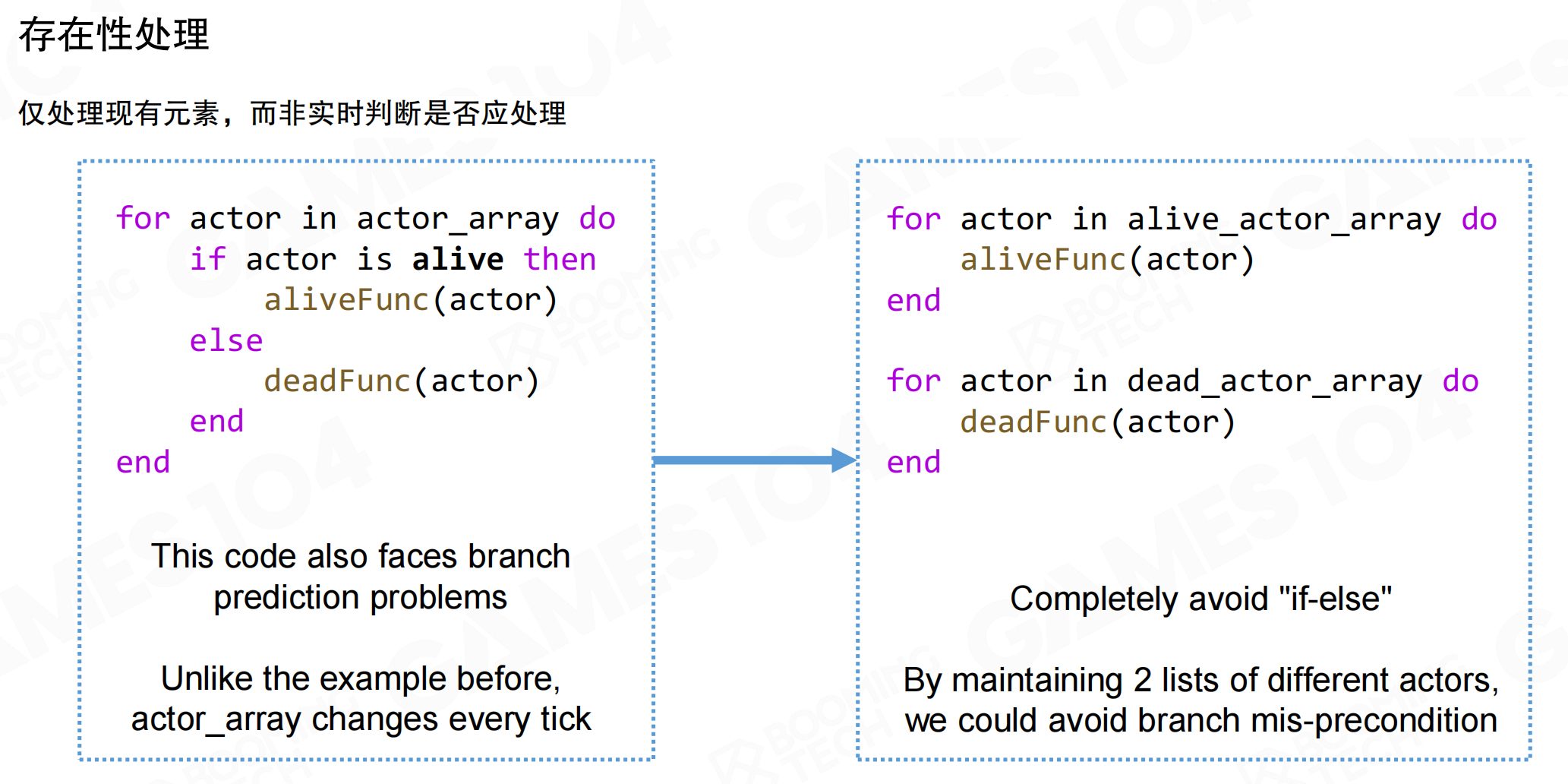
更通用的方法是按照业务逻辑对数据进行分组,每组只使用相同的函数处理,完全避免分支判断。
例如,处理actor数组时,如果需要在循环中判断if actor is alive then,会导致分支预测问题。优化方案是维护两个独立的数组:alive_actor_array和dead_actor_array。创建actor时根据状态加入对应数组,处理时分别遍历两个数组,完全避免if-else判断。
这种方法不仅避免了分支预测错误,还提高了数据局部性。在编写高性能代码,特别是高频执行的代码时,减少分支运算对性能影响很大。即使数据在缓存中,代码的swap也会导致数据失效,造成额外开销。
20.7 性能敏感数据组织
数据组织方式对程序性能有巨大影响。高性能代码开发中,需要理解数据在内存中的实际布局,而不仅仅是抽象层面的对象和容器。
减少内存依赖
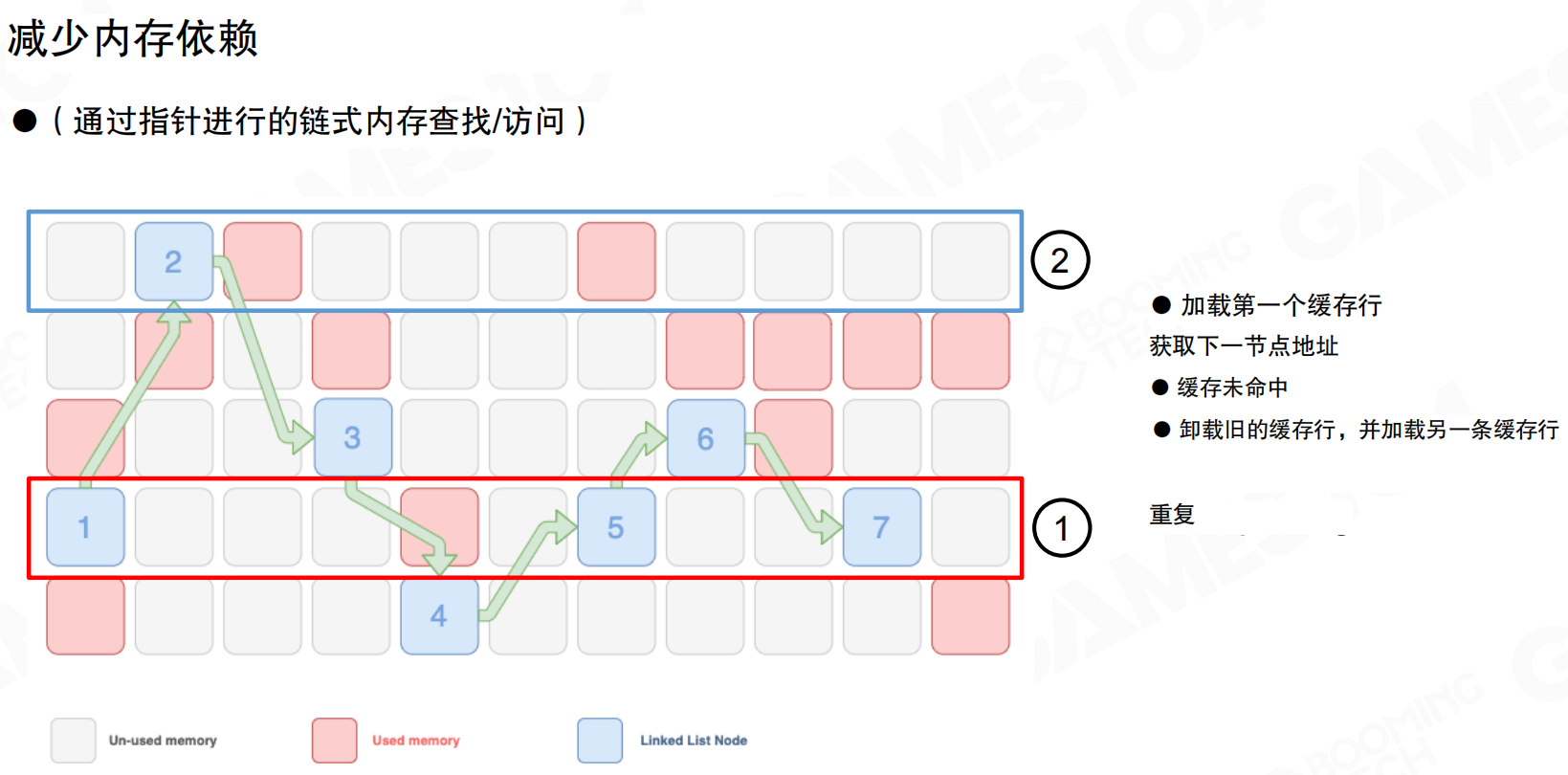
通过指针进行的链式内存查找/访问会导致频繁的缓存未命中。链表节点在内存中分散存储,遍历链表时:
- 加载第一个缓存行,获取节点数据
- 获取下一节点地址
- 缓存未命中(下一节点很可能不在当前缓存行)
- 卸载旧的缓存行,加载新的缓存行
- 重复上述过程
每个节点跳转都可能触发缓存未命中,需要从内存重新加载。这种非连续的内存访问模式是性能杀手。面向对象编程中,数据通过引用和指针满天飞,在追求高性能时必须避免这种模式。
数组结构体 vs 结构体数组
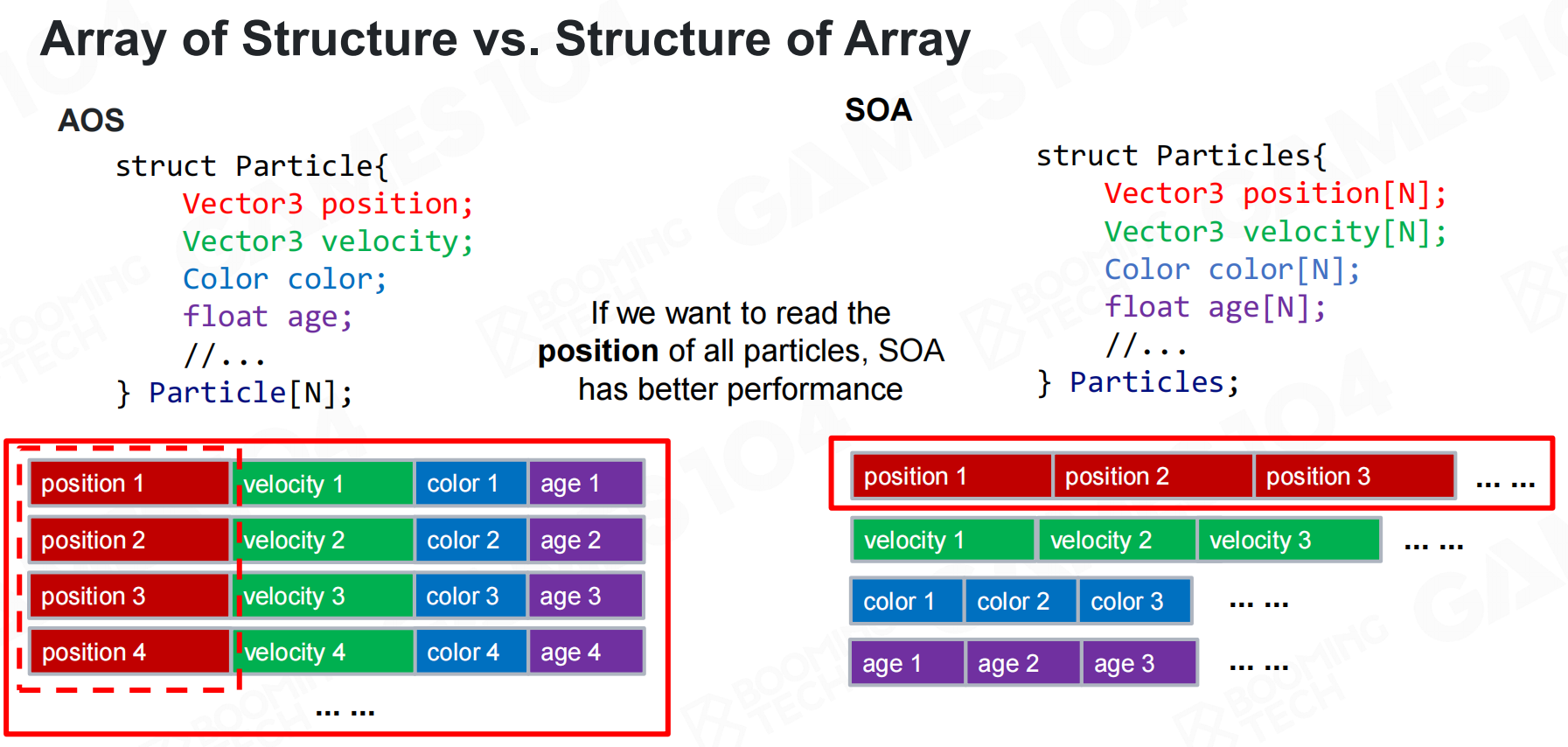
数据组织有两种经典方式:AOS(Array of Structures,结构体数组)和SOA(Structure of Arrays,数组结构体)。
AOS按照OOP思想,将数据封装到不同对象中,使用数组作为容器。例如定义Particle结构体,包含position、velocity、color、age等属性,然后创建Particle particles[N]数组。内存布局是:第一个粒子的所有属性连续存储,然后是第二个粒子的所有属性,以此类推。
SOA将所有数据放到一个结构中,每个属性是独立数组。例如定义Particles结构体,包含Vector3 position[N]、Vector3 velocity[N]、Color color[N]、float age[N]等。内存布局是:所有粒子的position连续存储,所有粒子的velocity连续存储,以此类推。
如果程序需要读取所有粒子的position,AOS会产生大量cache miss,因为每次读取position都要跳过velocity、color、age等数据。SOA中所有position数据连续存储,访问时缓存命中率高,性能更好。
GPU的compute shader本质上就是以数据为驱动的编程,每个shader是函数,数据紧密排列。追求高性能时,应按照SOA方式组织数据。
20.8 ECS架构
前面介绍过基于OOP的组件编程,通过继承实现具体的GameObject。这种编程范式效率较低:代码分散在各个类中,虚函数调用频繁,数据分散存储,导致大量缓存未命中。
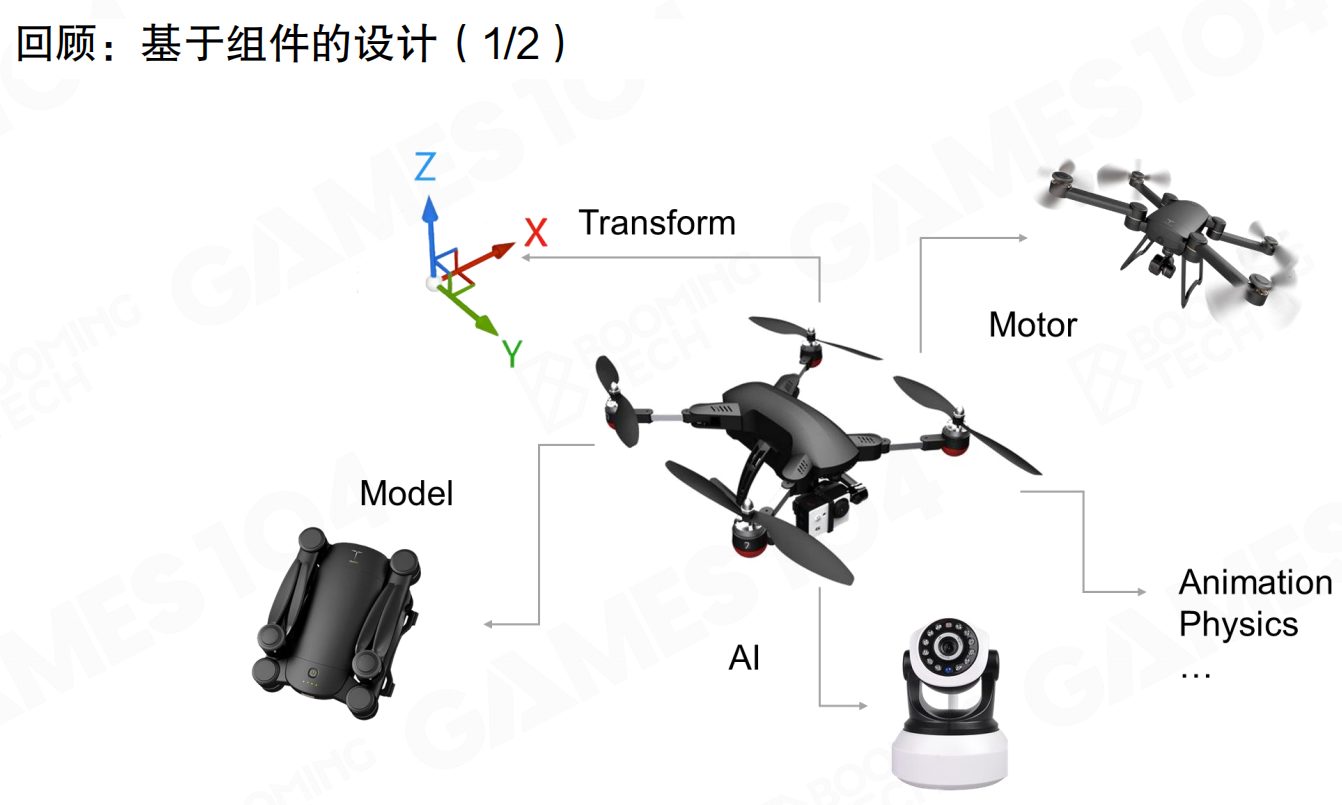
基于组件的设计中,GameObject通过组合不同的Component实现功能。例如无人机包含Transform、Model、Motor、AI等组件,每个组件负责特定功能。
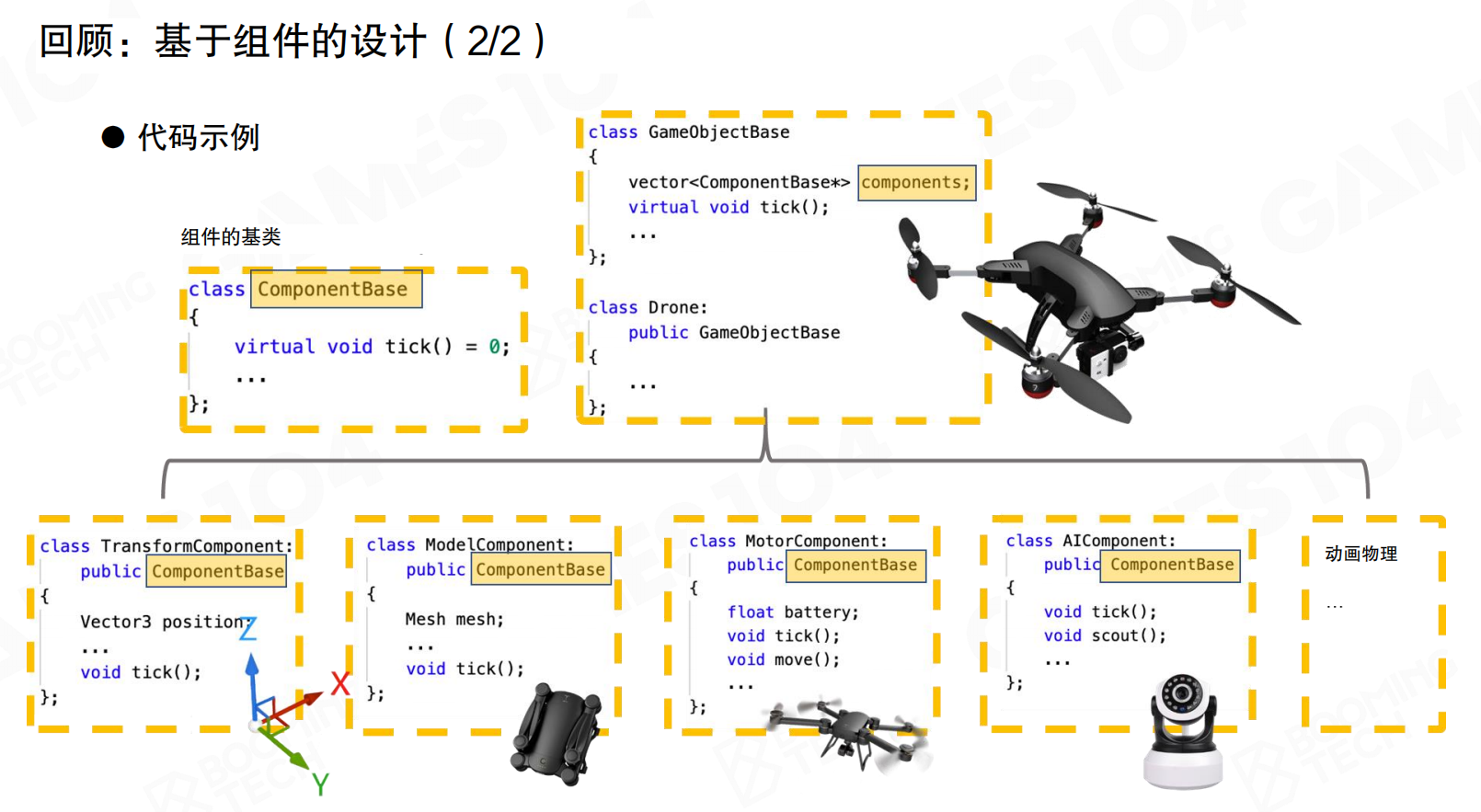
代码实现上,定义ComponentBase基类,GameObject包含vector<ComponentBase*> components。每个具体组件(如TransformComponent、ModelComponent、MotorComponent、AIComponent)继承自ComponentBase,实现各自的tick()方法。
实体组件系统
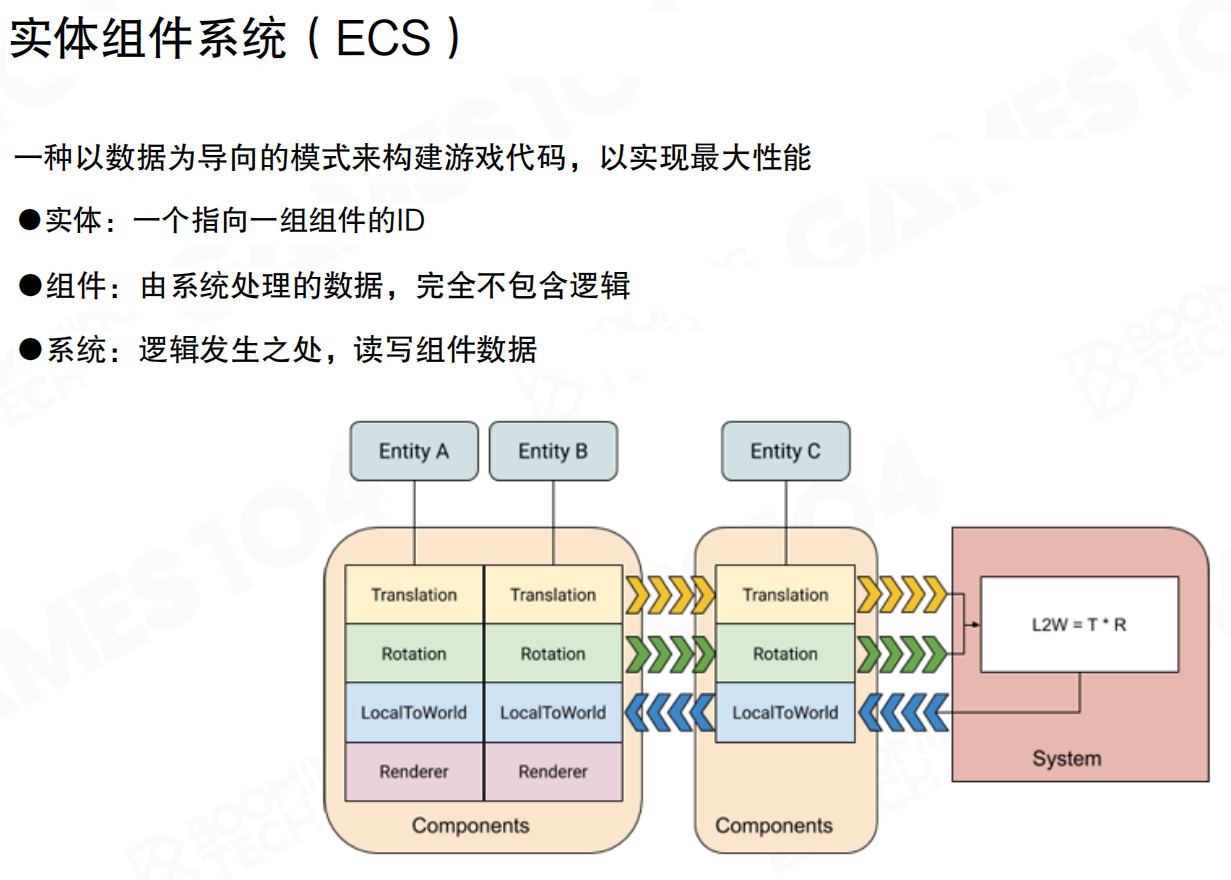
实体组件系统(Entity Component System,ECS)是一种以数据为导向的模式,用于构建游戏代码以实现最大性能。
ECS的三个核心概念:
实体(Entity):一个指向一组组件的ID,仅作为标识符,不包含任何数据或逻辑。组件(Component):由系统处理的数据,完全不包含逻辑。组件是纯数据,可以读写,但本身不知道自己的意义。系统(System):逻辑发生之处,读写组件数据。系统对组件进行处理,通常同时处理多类组件的数据。
ECS将数据从GameObject中分离出来,每一类数据集中存储。Entity通过离散关系关联到不同组件的索引。System对数据的处理不是一次只处理一个组件,而是批量处理同一类型的所有组件,充分利用数据局部性和缓存效率。
Unity数据导向技术栈

Unity的数据导向技术栈(Data-Oriented Technology Stack,DOTS)基于ECS架构实现,结合C#任务系统进行并行化,并设计了Burst编译器优化代码。
DOTS包含三个核心支柱:
实体组件系统(ECS):提供面向数据编程框架,重新以数据为导向组织计算框架。- C#作业系统:提供生成多线程代码的简易方法,让用户更轻松地编写正确的多线程代码。
- Burst编译器:生成快速且高度优化的原生代码,将IL/.NET字节码转换为高度优化的原生代码。
Unity ECS原型
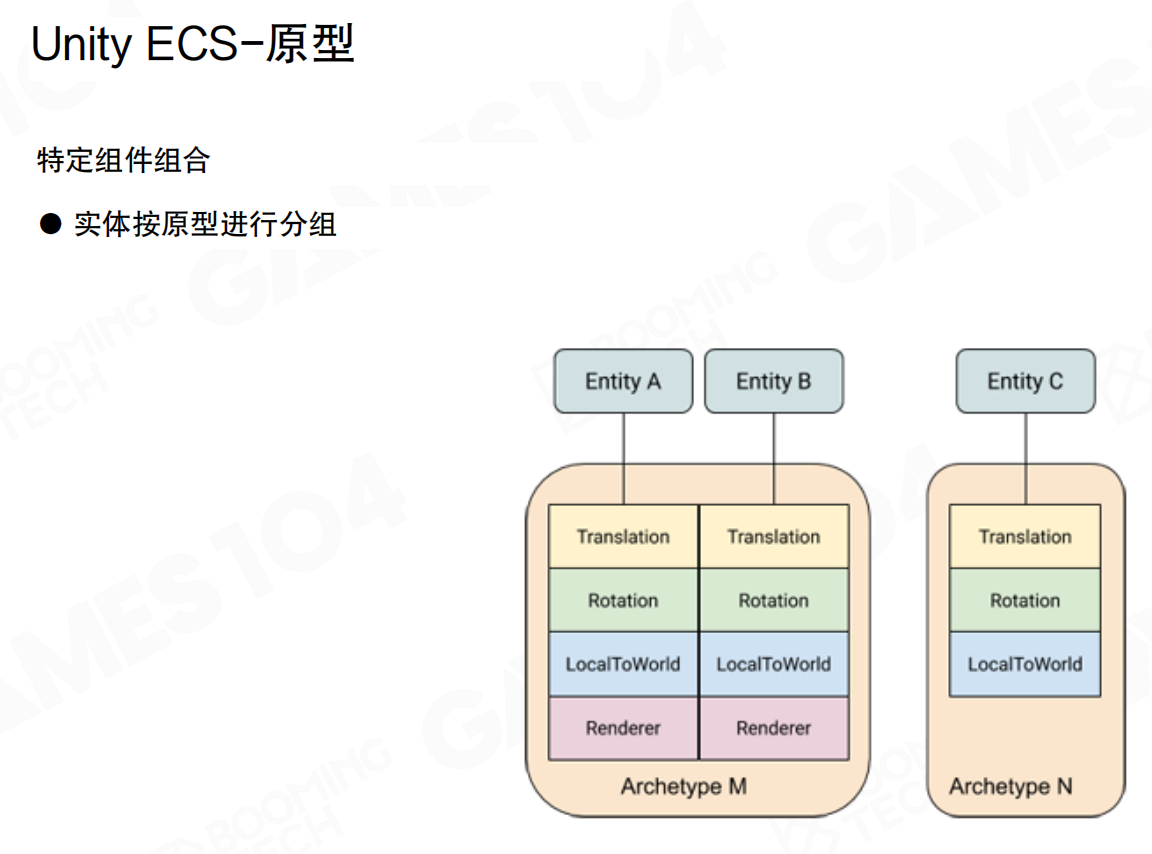
Unity ECS设计了原型(Archetype)对不同类型的Entity进行抽象。特定组件组合对应一个Archetype,实体按原型进行分组。
例如,NPC、Monster、Vehicle等不同类型的Entity对应不同的Archetype。每个Archetype定义了该类型Entity所需的组件组合。这样具有相似功能的Entity可以组织到一起方便管理,System处理时不需要逐个检查Entity是否有所需组件,只需查询Archetype即可。
为什么不需要逐个检查?因为Archetype本身就是组件组合的”签名”。同一个Archetype内的所有Entity保证具有完全相同的组件组合,这是Archetype系统的基本约束。当System需要处理具有[Transform, Velocity]组件的Entity时,它只需查询包含这两个组件的Archetype。一旦找到匹配的Archetype,该Archetype内的所有Entity都必然具有这两个组件,无需逐个验证。这就像按标签分类:如果一箱货物都贴了”易碎品”标签,你不需要逐个检查,就知道整箱都是易碎品。传统OOP方式需要遍历所有Entity并检查每个Entity的组件,而ECS通过Archetype预先分类,System直接处理匹配的Archetype,避免了大量条件判断和分支预测失败。
当Entity动态添加或移除组件时,其组件组合发生变化,必须从一个Archetype移动到另一个Archetype。例如,一个原本只有[Transform]组件的Entity添加了Velocity组件后,会从Archetype[Transform]移动到Archetype[Transform, Velocity]。这个过程涉及:查找或创建目标Archetype(如果不存在)、将Entity的所有组件数据从旧Chunk复制到新Chunk、从旧Archetype中移除Entity、更新Entity的引用。由于需要数据迁移,这是一个相对昂贵的操作,因此引擎通常建议批量操作组件变更,或使用延迟操作机制,在合适的时机统一处理Archetype迁移,避免频繁的移动操作影响性能。
Unity ECS数据布局
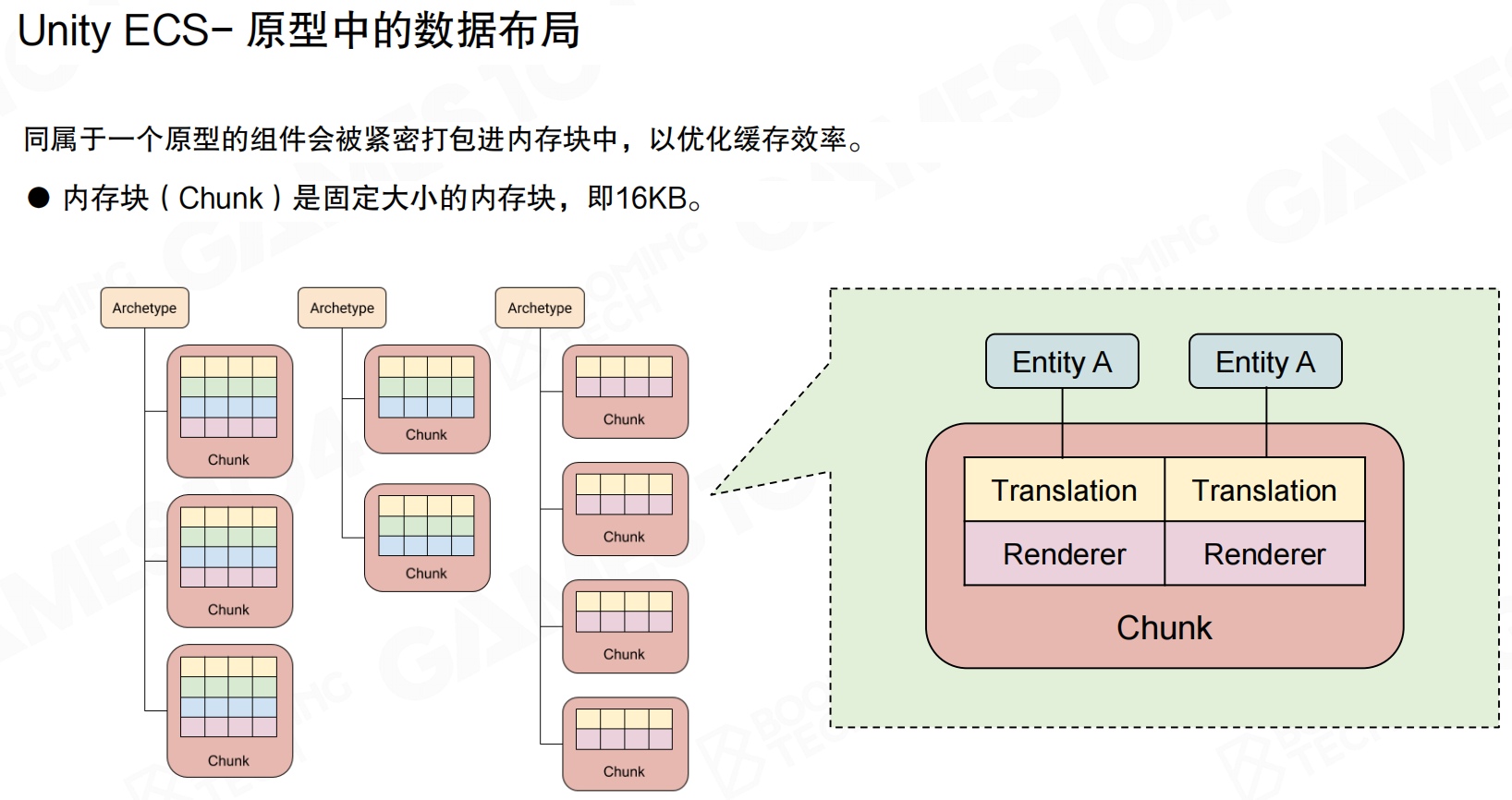
同属于一个原型的组件会被紧密打包进内存块(Chunk)中,以优化缓存效率。Chunk是固定大小的内存块,通常为16KB(现代引擎中可能更大,如128KB)。
Chunk内部采用SOA布局:同一类型的所有组件连续存储。例如,Chunk中所有Transform组件在一起,所有Velocity组件在一起,而不是每个Entity的所有组件在一起。这样System处理时,一次可以处理整个Chunk中同一类型的所有组件,充分利用缓存局部性。
以英雄联盟为例,假设游戏中有100个小兵(Minion),它们都属于同一个Archetype(具有位置、血量、攻击力等相同组件)。传统AOS布局就像把每个小兵的所有数据放在一起:小兵1的位置、血量、攻击力紧挨着,然后是小兵2的位置、血量、攻击力,以此类推。当需要更新所有小兵的位置时,CPU必须跳跃式访问内存:读取小兵1的位置,跳过血量和攻击力,读取小兵2的位置,再跳过血量和攻击力…这种访问模式缓存命中率低。
SOA布局则将所有小兵的位置数据连续存储在一起,所有血量数据连续存储在一起,所有攻击力数据连续存储在一起。当物理系统需要更新所有小兵的位置时,可以连续读取所有位置数据,CPU缓存一次性加载大量位置数据,处理完位置后再切换到血量数据,访问模式高度连续,缓存命中率大幅提升。这就像图书馆按主题分类:把所有”数学书”放在一个区域,把所有”历史书”放在另一个区域,而不是每本书都按”数学-历史-数学-历史”的方式排列,找书时效率自然更高。
一个Chunk只包含同一Archetype的Entity,确保System处理时数据访问模式一致。处理完一个Chunk后,切换到下一个Chunk,整个Chunk的数据和代码一起进入缓存,效率最高。
Unity ECS系统

Unity ECS中的System通过Entities.ForEach查询具有特定组件的Entity,然后对它们执行逻辑。例如MoveSystem查询具有Translation和Velocity组件的Entity,更新位置。
System可以指定对组件的访问模式:ref表示读写,in表示只读。通过ScheduleParallel()可以将处理任务并行化,充分利用多核性能。
Unity C#作业系统

Unity C#作业系统让用户更轻松地编写正确的多线程代码。作业是执行特定任务的小型工作单元,作业可以依赖于其他作业完成后才能运行。
定义作业需要实现IJob接口,包含Execute()方法。通过Schedule()方法调度作业,返回JobHandle。后续作业可以通过Schedule(JobHandle)指定依赖关系,确保依赖的作业完成后再执行。
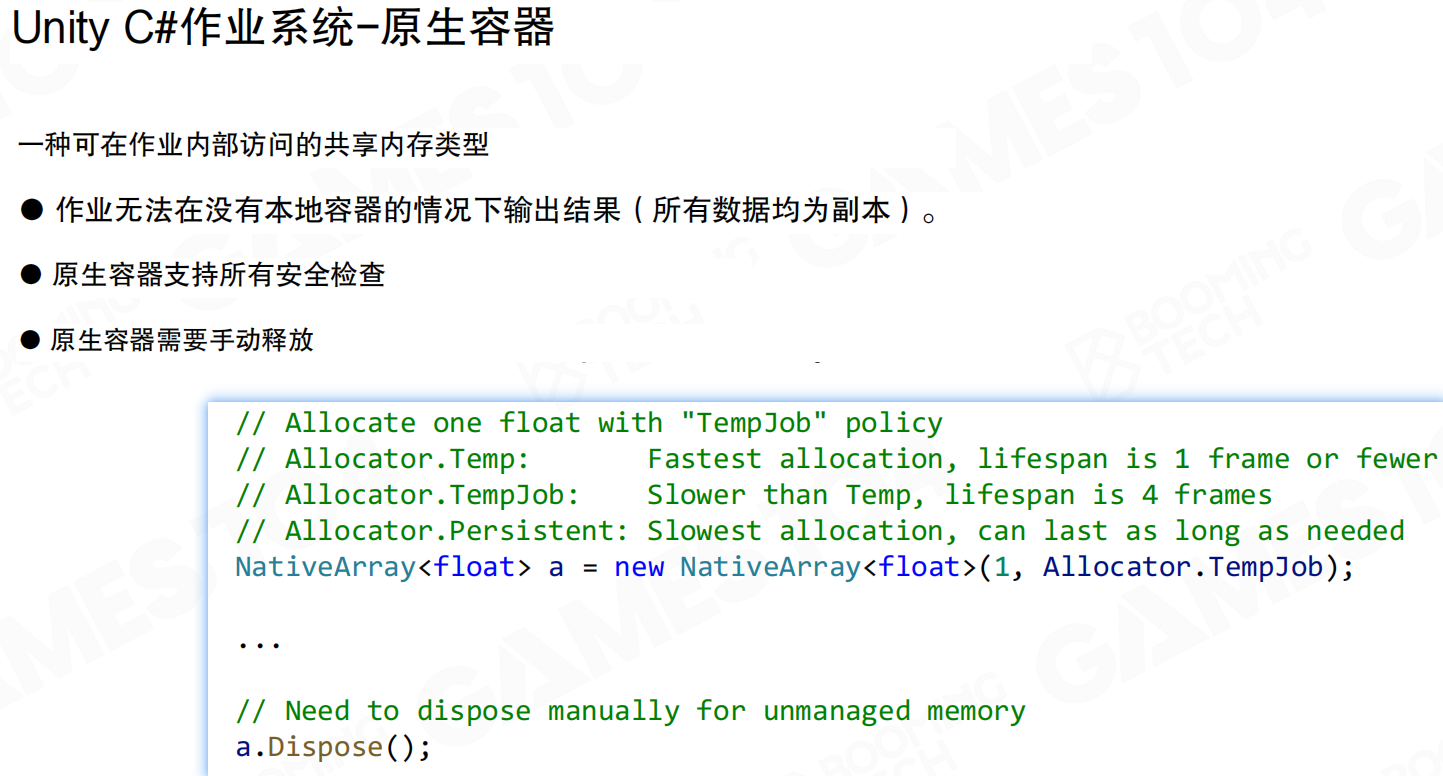
作业内部访问共享内存需要使用原生容器(Native Containers)。原生容器是一种可在作业内部访问的共享内存类型。作业无法在没有原生容器的情况下输出结果(所有数据均为副本)。
原生容器支持所有安全检查,但需要手动释放。Allocator.Temp分配最快,生命周期为1帧或更短;Allocator.TempJob稍慢,生命周期为4帧;Allocator.Persistent最慢,可以持续任意长时间。
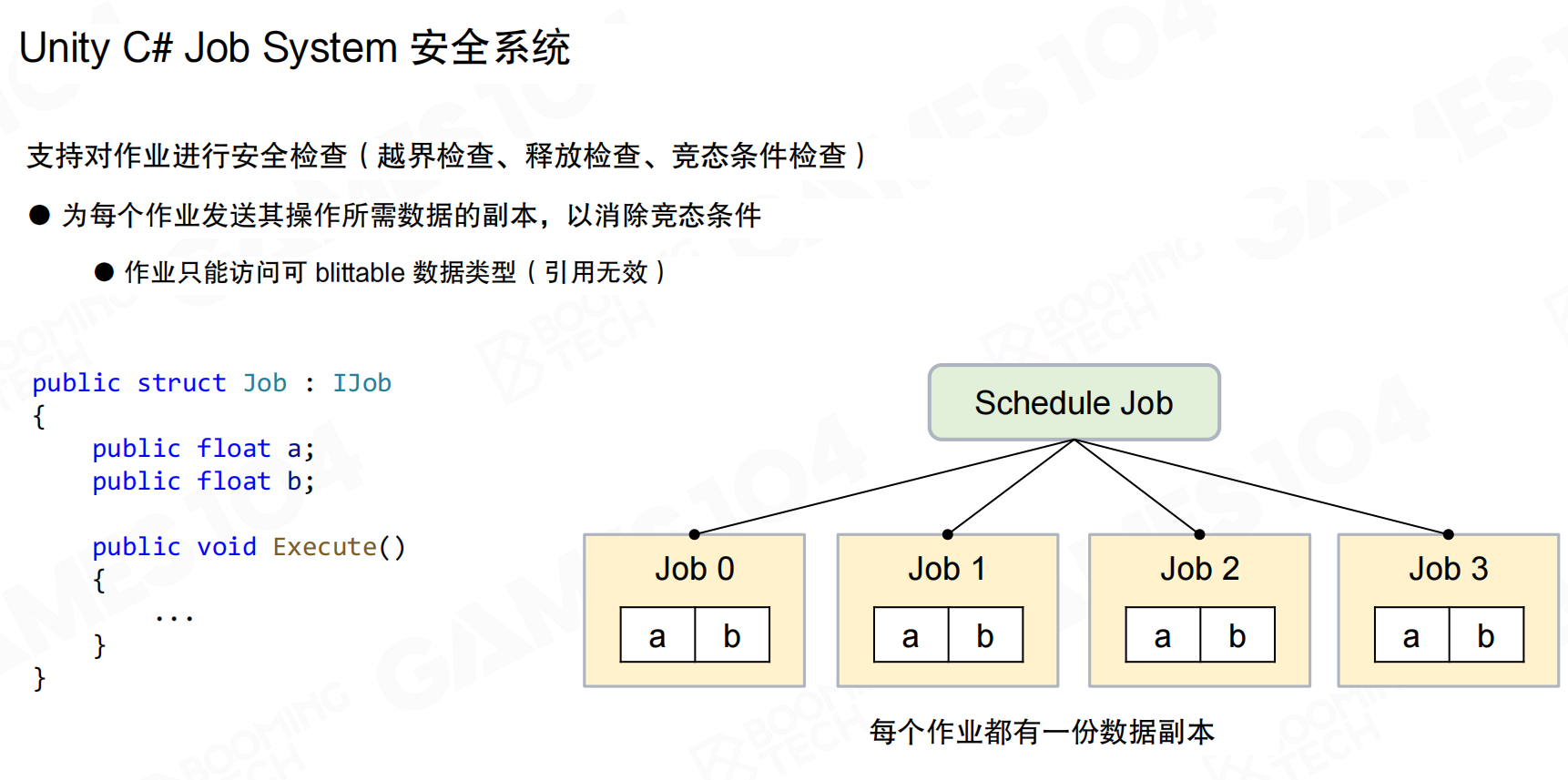
Unity C#作业系统支持对作业进行安全检查:越界检查、释放检查、竞态条件检查。为每个作业发送其操作所需数据的副本,以消除竞态条件。作业只能访问可blittable数据类型(引用无效)。
每个作业都有一份数据副本,确保线程安全。虽然这会增加内存开销,但避免了复杂的锁机制,提高了开发效率和代码安全性。
Burst编译器
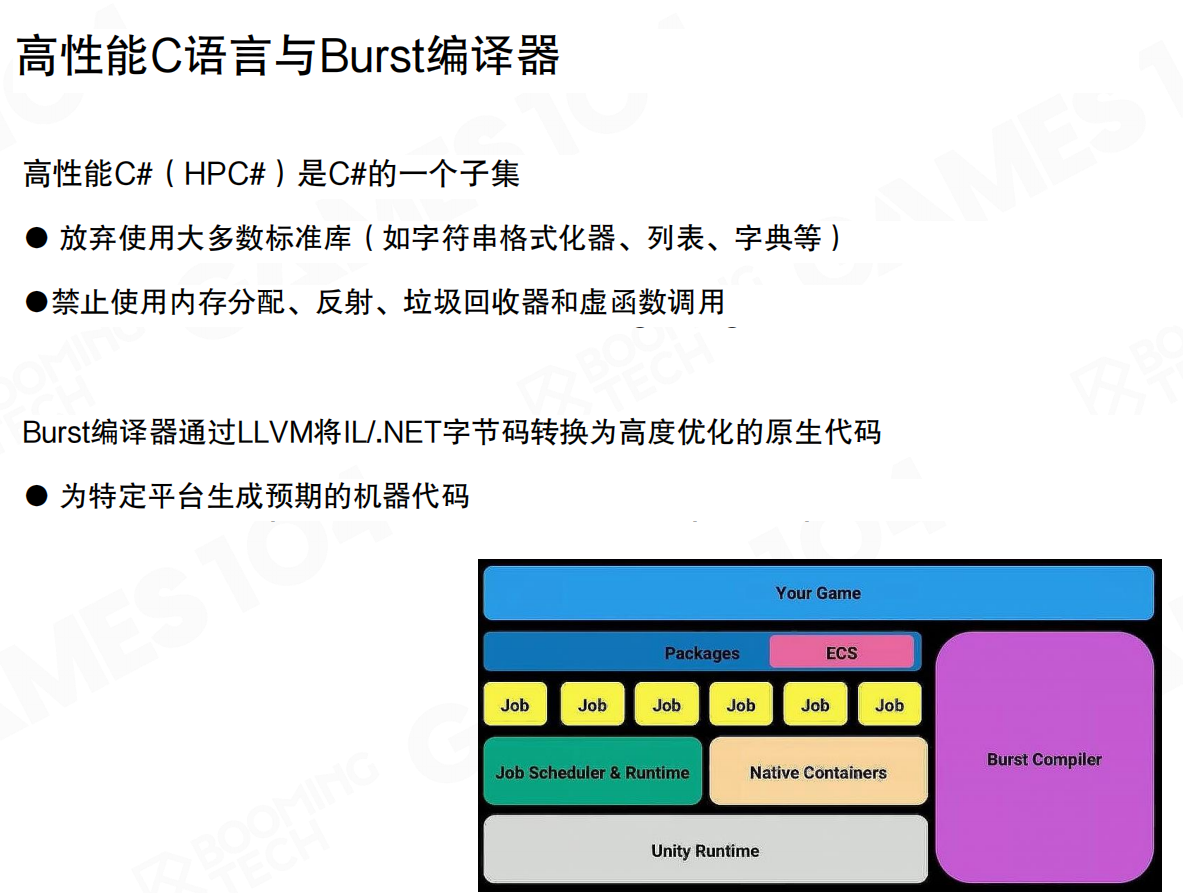
**高性能C#**(HPC#)是C#的一个子集,放弃使用大多数标准库(如字符串格式化器、列表、字典等),禁止使用内存分配、反射、垃圾回收器和虚函数调用。
Burst编译器通过LLVM将IL/.NET字节码转换为高度优化的原生代码,为特定平台生成预期的机器代码。这是Unity实现DOTS的关键:C#本质上运行在虚拟机上,不是native code。要实现高性能的数据访问和协程机制,需要native级别的代码。
Burst编译器将C#代码编译成接近汇编级别的原生代码,数据访问可以直接映射到内存,实现一一对应的连续映射。同时,编译器层面完成必要的安全检查,确保资源正确释放。
虚幻Mass系统
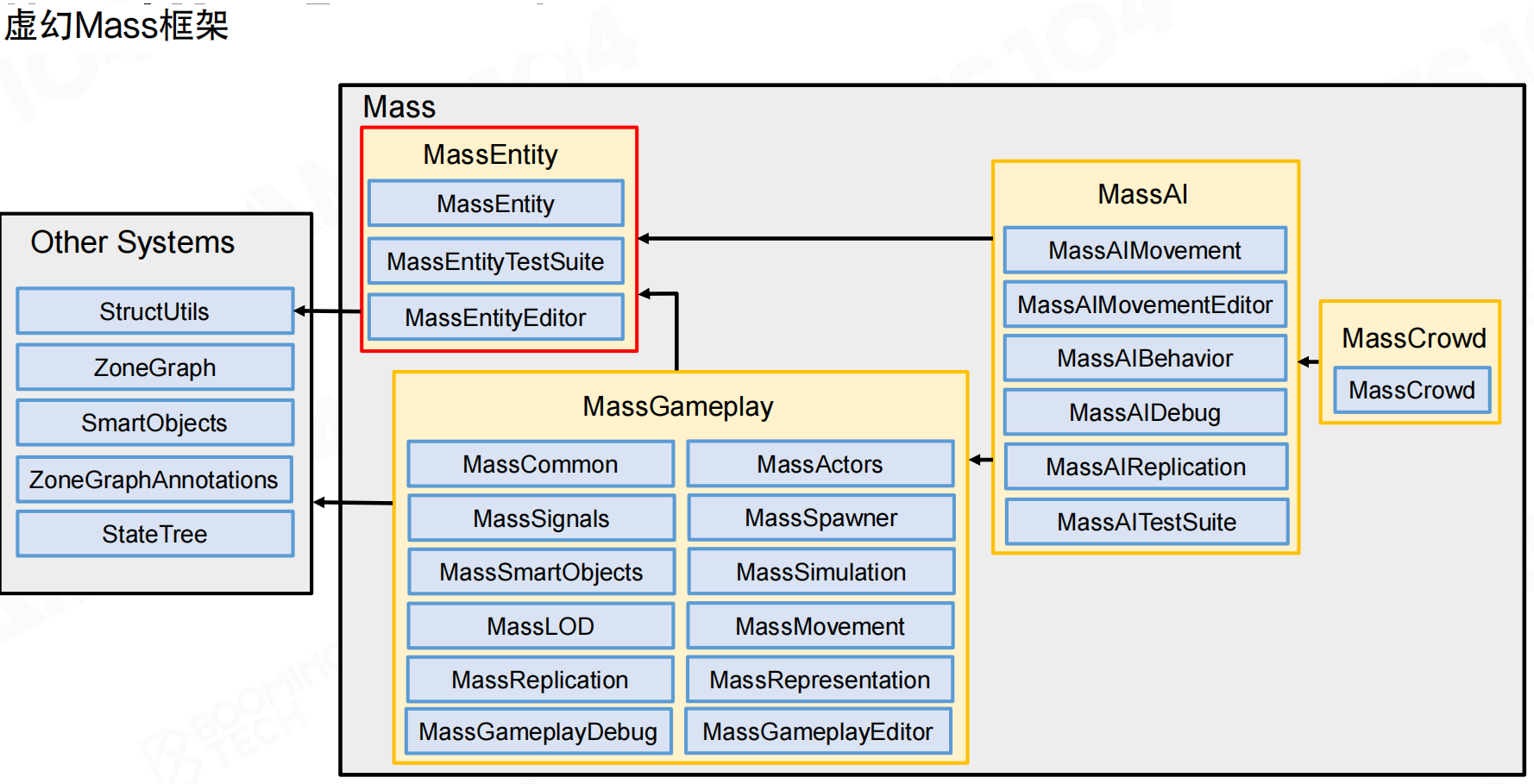
虚幻引擎使用Mass系统实现ECS架构。Mass系统包含MassEntity、MassGameplay、MassAI、MassCrowd等模块,与StructUtils、ZoneGraph、SmartObjects、State Tree等外部系统集成。
Mass系统与Unity DOTS非常类似,都使用Entity作为Component的索引ID。Mass系统主要用于大规模实体模拟,如《黑客帝国:矩阵觉醒》Demo中曼哈顿场景的成千上万汽车和行人。
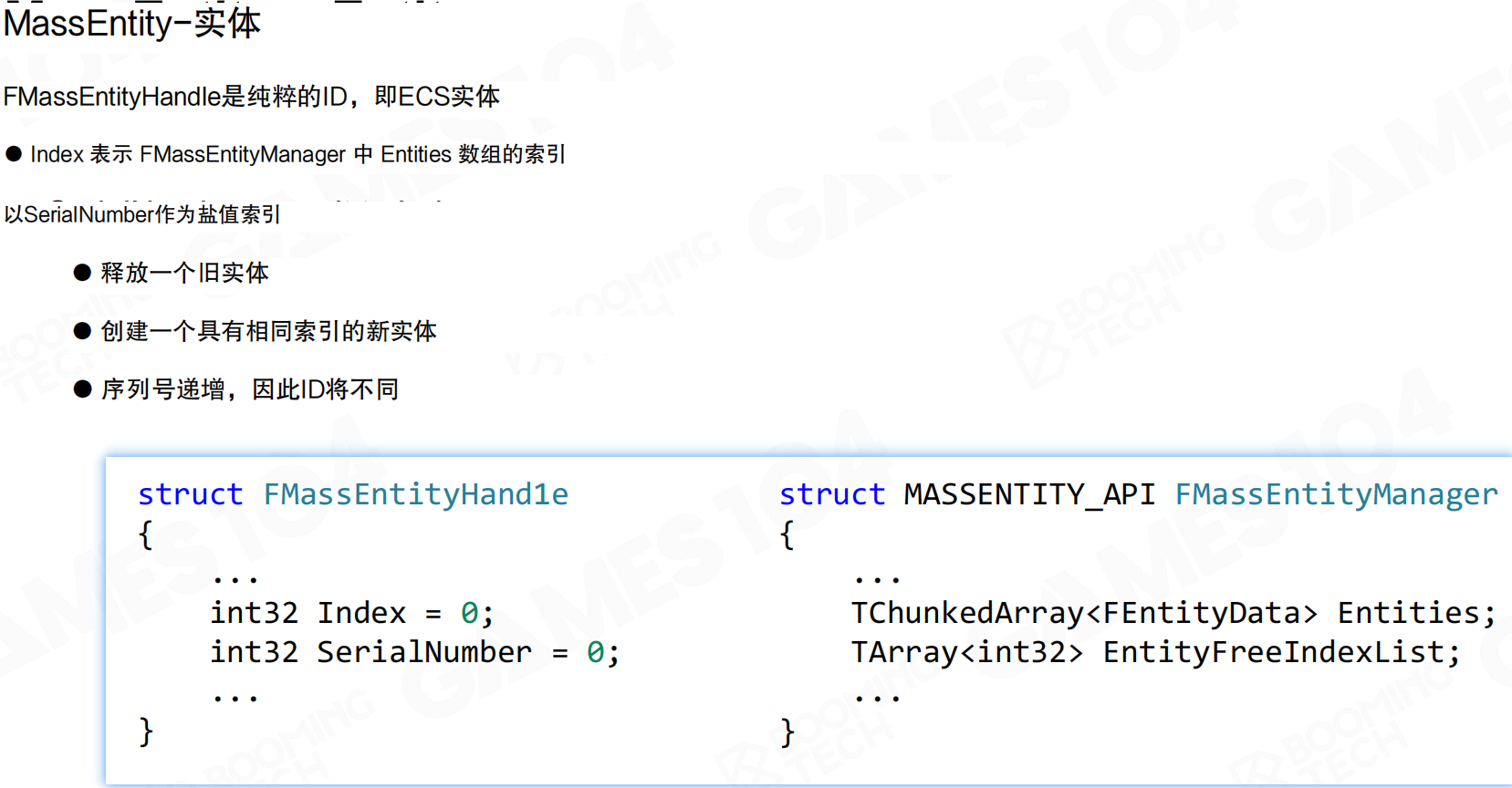
Mass系统中的Entity是FMassEntityHandle,它是纯粹的ID。Index表示FMassEntityManager中Entities数组的索引,SerialNumber作为盐值索引。
释放一个旧实体后,创建具有相同索引的新实体时,序列号递增,因此ID将不同。这确保了即使索引被重用,ID也是唯一的,防止悬空引用。
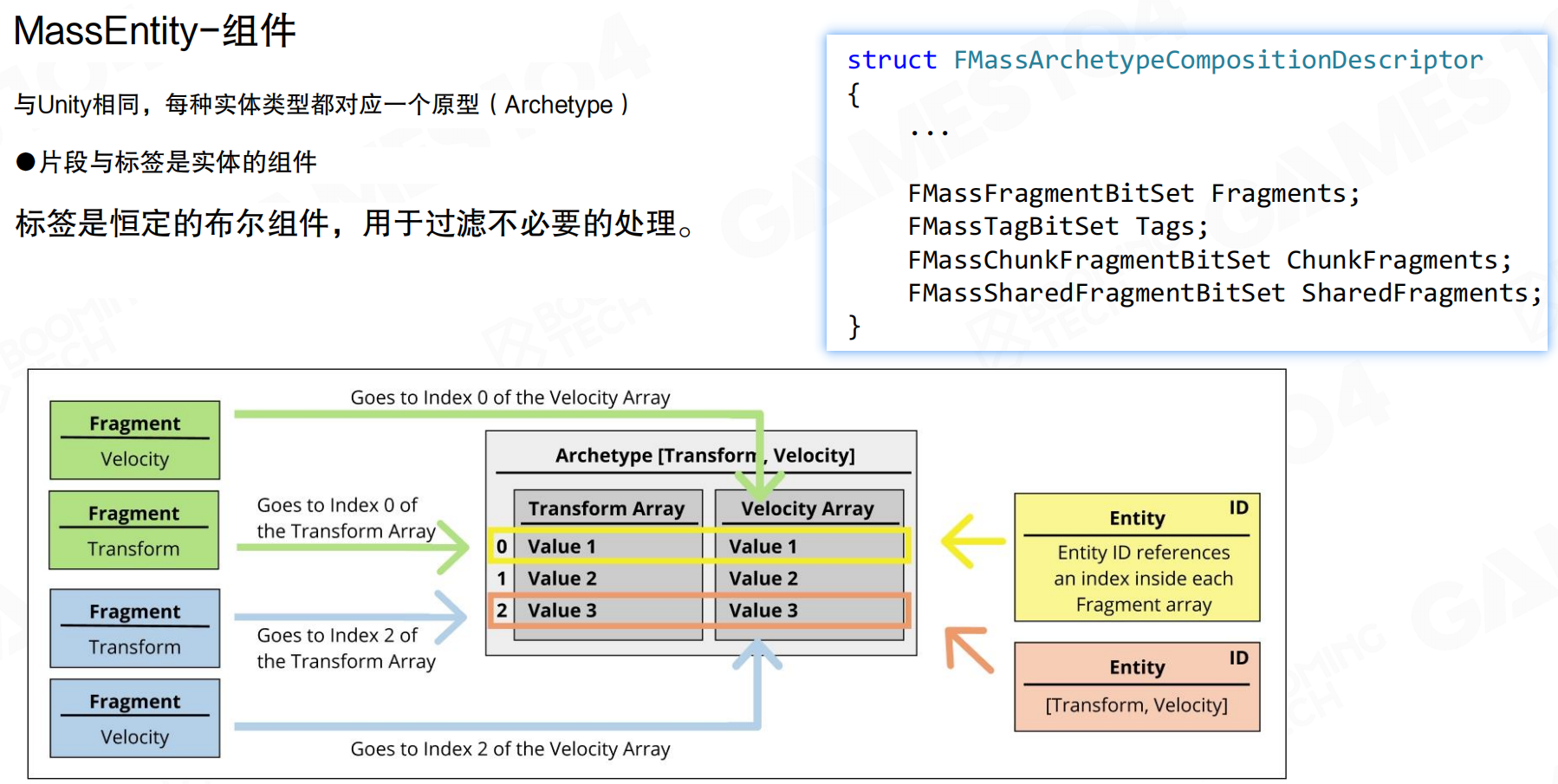
Mass系统中的Component称为Fragment,强调它只具有数据的属性。与Unity相同,每种实体类型都对应一个原型(Archetype)。片段与标签是实体的组件,标签是恒定的布尔组件,用于过滤不必要的处理。
Fragment存储在Archetype中,采用SOA布局:同一类型的所有Fragment存储在连续数组中。Entity ID作为索引,引用每个Fragment数组中的对应位置。例如,Archetype [Transform, Velocity]中,所有Transform值在一个数组,所有Velocity值在另一个数组,Entity通过索引访问对应的Transform和Velocity。
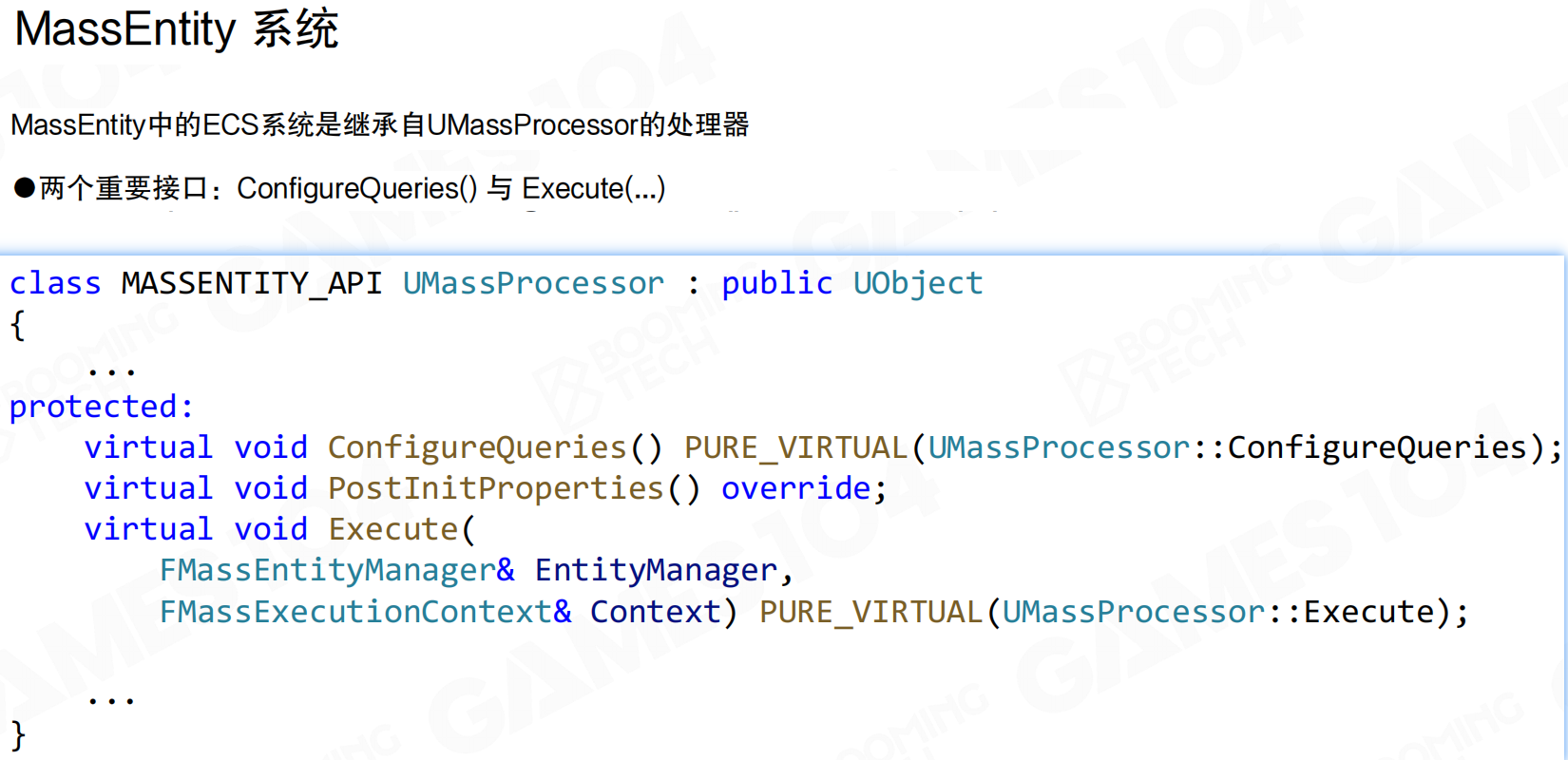
Mass系统中的System称为Processor,表示它只承担业务逻辑的功能。Processor继承自UMassProcessor,需要实现两个重要接口:ConfigureQueries()和Execute(...)。
ConfigureQueries()在Processor初始化时运行,用于配置查询条件。Execute()是Processor的执行逻辑,对查询到的Entity进行处理。

ConfigureQueries()使用FMassEntityQuery过滤满足系统要求的Entity Archetype。FMassEntityQuery会缓存这些过滤后的Archetype,加速后续执行。
Processor通过EntityQuery查询具有特定Fragment组合的Archetype,EntityQuery返回对应Archetype的Fragment数组。例如,查询具有Transform和Velocity的Entity,EntityQuery会过滤出对应的Archetype,返回Transform和Velocity数组。
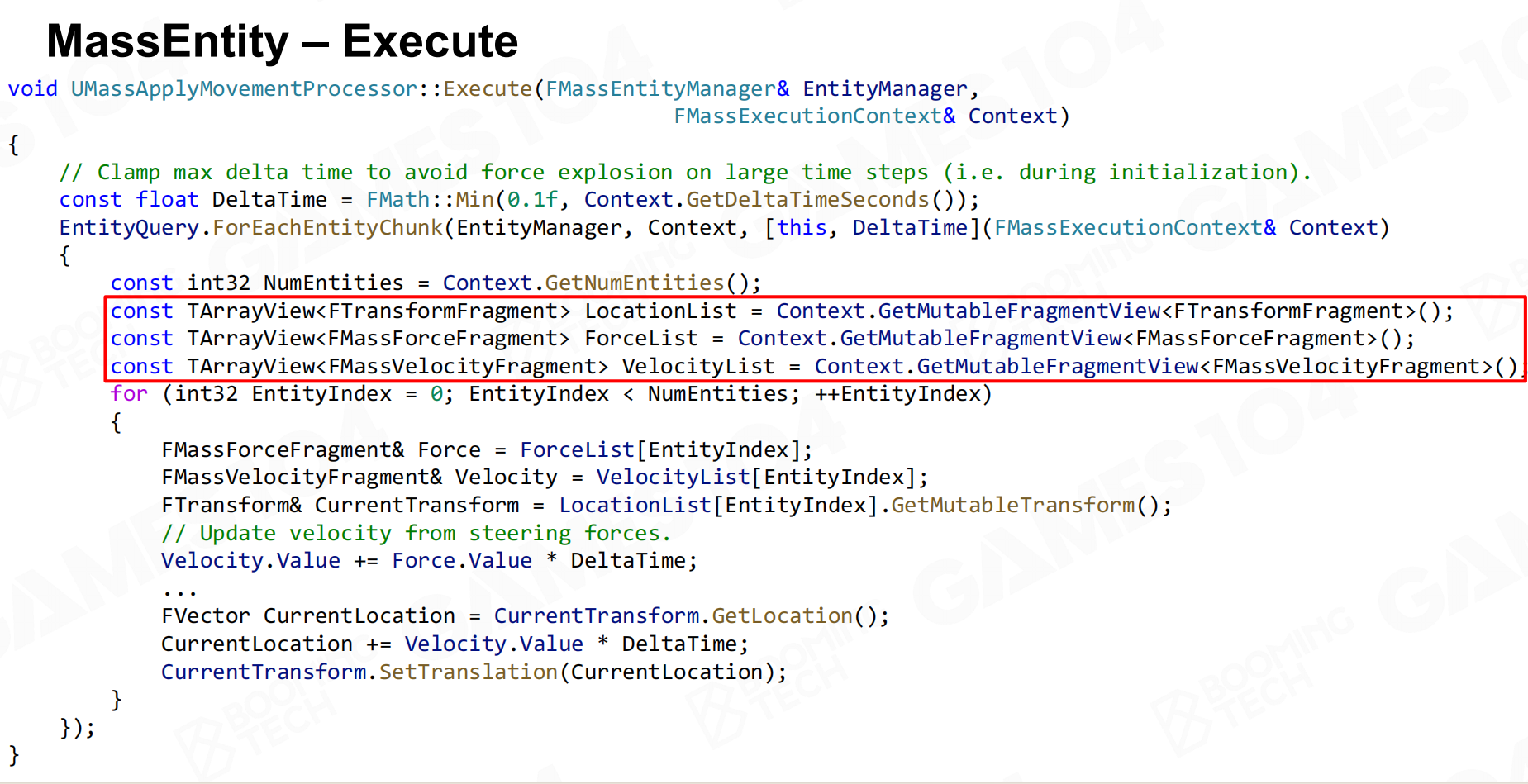
Execute()方法中,Processor通过EntityQuery.ForEachEntityChunk()按Chunk处理Entity。对每个Chunk,获取Fragment的数组视图(如TArrayView<FTransformFragment>、TArrayView<FMassVelocityFragment>),然后遍历Chunk中的每个Entity,更新其数据。
例如,UMassApplyMovementProcessor根据力和速度更新位置:Velocity.Value += Force.Value * DeltaTime,然后CurrentLocation += Velocity.Value * DeltaTime。由于Fragment数据在Chunk中连续存储,这种批量处理效率很高。
ECS的适用场景
ECS系统虽然强大,但并非万能。游戏是非常复杂的东西,很多业务逻辑依赖关系复杂,很难把整个引擎都变成ECS。
ECS一般用在非常确定的情况下:大规模实体模拟、物理计算、粒子系统等需要批量处理大量数据的场景。强如虚幻5,其ECS也只放在Mass这个特定案例中,主体引擎仍然是面向对象的Component-based架构。
Fiber-based的Job System和ECS有关系,但没有那么直接的关系。Fiber-based Job System更多是高级任务之间的调度,而ECS更像是在大量运算时面向数据组织计算。这两个系统有交集,但不是完全高度一致。Unity DOTS和虚幻Mass系统实际上还是基于dependency graph构建任务,fork出去,join回来再做下一件事,效果也很好。
做游戏引擎架构要实事求是,什么地方适合用什么技术就用什么技术,关键是把技术用对。OOP和DOP在实战型游戏引擎中同等重要,甚至OOP的重要性可能还更大一些。
20.9 结论
并行编程、任务系统、数据组织、ECS架构,这些看似零散的内容,核心都是高性能编程。

并非所有CPU操作都生而平等,性能差异是数量级的。
从寄存器操作(<1周期)到线程上下文切换(10,000-1,000,000周期),性能差异可达100万倍。寄存器运算、L1缓存读取只需几个周期;分支预测错误、L3缓存读取需要几十到几百周期;主内存读取需要100-150周期;线程上下文切换(包括缓存失效)需要1万到100万个周期。
所有优化方案都围绕这张图展开:减少内存访问、避免分支预测错误、减少线程切换、优化数据布局、使用ECS批量处理。理解不同操作的开销差异,就能理解为什么需要这些优化技术。
游戏引擎对性能要求极高,实现超高性能编程需要深入理解硬件:CPU、内存、缓存的协作机制。这张图是理解高性能编程的关键。系统架构师需要深入理解图中每个操作的开销,这是基本功。
同样的逻辑、同样的代码,实现方式不同,性能可能相差100倍。理解硬件层面的性能差异,是游戏引擎最内核的东西。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

