21.动态全局光照和Lumen
21.1 全局光照 GI基础
在介绍游戏引擎中全局光照(Global Illumination, GI)的实现方法前,先回顾渲染方程(Rendering Equation)。一切渲染问题的本质在于求解渲染方程。

James Kajiya在1986年SIGGRAPH上提出的渲染方程,用简洁的数学语言描述了光与表面的交互。这个方程指导了图形学领域35年以上的工作。

渲染方程的核心在于计算从表面点x向观察方向ω_o的出射辐射率L_o。它等于该点的自发光辐射率L_e,加上从半球Ω上所有入射方向ω_i反射的光。积分项包含入射辐射率L_i、双向反射分布函数f_r(BRDF)和余弦项cos θ_i。求解这个方程的难点在于其递归形式:场景中的物体被光源照亮后,被照亮的物体又会成为新的光源再次照亮其他物体。
想象你站在房间里看一面白墙。你看到的亮度不仅来自天花板上的灯(直接光照),还来自墙壁反射到白墙上的光(间接光照)。更复杂的是,白墙反射的光又会照亮其他物体,那些物体反射的光又回到白墙,形成多次反弹。就像台球桌上的球,一个球撞到另一个球,被撞的球又去撞其他球,形成连锁反应。
直接光照与间接光照
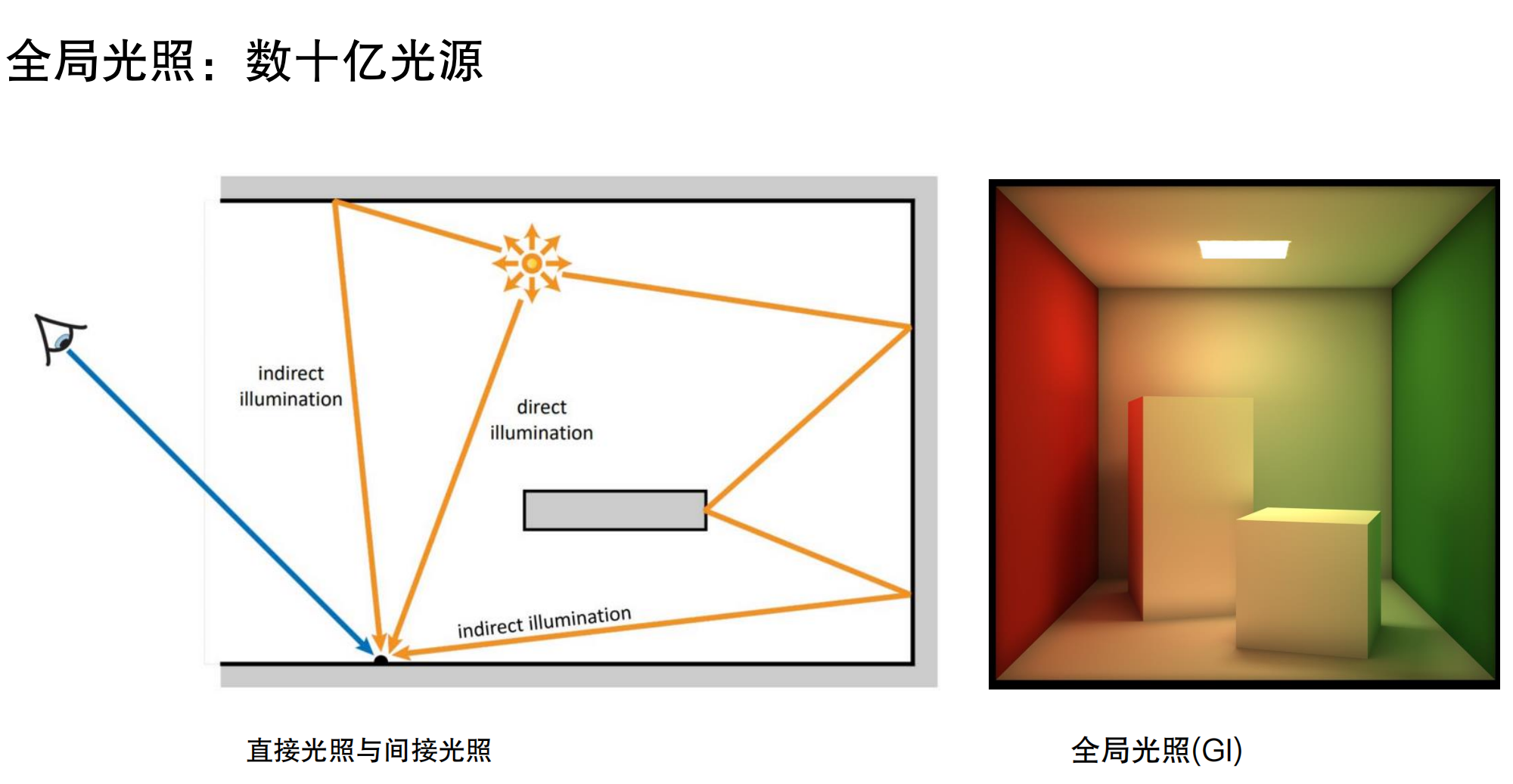
直接光照(Direct Illumination)指光线从光源直接到达表面。间接光照(Indirect Illumination)指光线经过一次或多次反弹后才到达表面。以Cornell Box为例,来自屋顶的灯光照亮左右两侧的红色和绿色墙壁,墙壁反射的光线又会照亮盒子,使盒子的两侧呈现红色或绿色,这种现象称为颜色渗透(Color Bleeding)。
想象你在一个只有手电筒的房间里。手电筒直接照到的地方是亮的,这是直接光照。但你会发现,即使手电筒没有直接照到的地方,比如墙角,也不是完全黑的,因为光线从墙壁、地面反弹过来了,这就是间接光照。更明显的是,如果房间里有一面红墙,手电筒照到红墙后,红墙反射的红光会照亮周围,让其他物体也带上红色调,这就是颜色渗透。
全局光照的重要性

在复杂游戏场景中,全局光照能显著提升画面表现力。只使用直接光照时,未直接照亮的区域几乎完全黑暗,细节丢失严重。启用全局光照后,光线在场景中多次反弹,阴影区域被间接光照亮,细节清晰可见,画面更真实自然。
比如一个只有一盏台灯的房间。如果只有直接光照,台灯照不到的地方(比如桌子下面、墙角)会完全漆黑,就像恐怖片里的场景。但现实中,即使台灯没有直接照到,这些地方也不会完全黑,因为光线会从墙壁、天花板、地面反弹,让整个房间都有一定的亮度。全局光照就是模拟这种真实的光线反弹效果。
现代游戏对画面真实感的要求不断提高。过去明显是计算机生成的画面,现在已接近动画片质量,甚至逼近手持相机拍摄的纪实电影效果。全局光照是实现这一目标的关键技术之一。没有全局光照,画面缺乏真实感。
蒙特卡洛积分
求解渲染方程的经典方法是蒙特卡洛积分(Monte Carlo Integration)。当积分难以解析求解时,可以通过随机采样来近似积分值。
比如你尝试估算一个不规则池塘的面积,但无法直接测量。蒙特卡洛方法就像这样:在池塘周围画一个矩形,然后随机往池塘里扔石子。如果扔了1000个石子,有750个落在池塘里,250个落在外面,那么池塘面积大约是矩形的75%。扔的石子越多,估算越准确。这就是蒙特卡洛的核心思想:通过随机采样来估算难以直接计算的值。
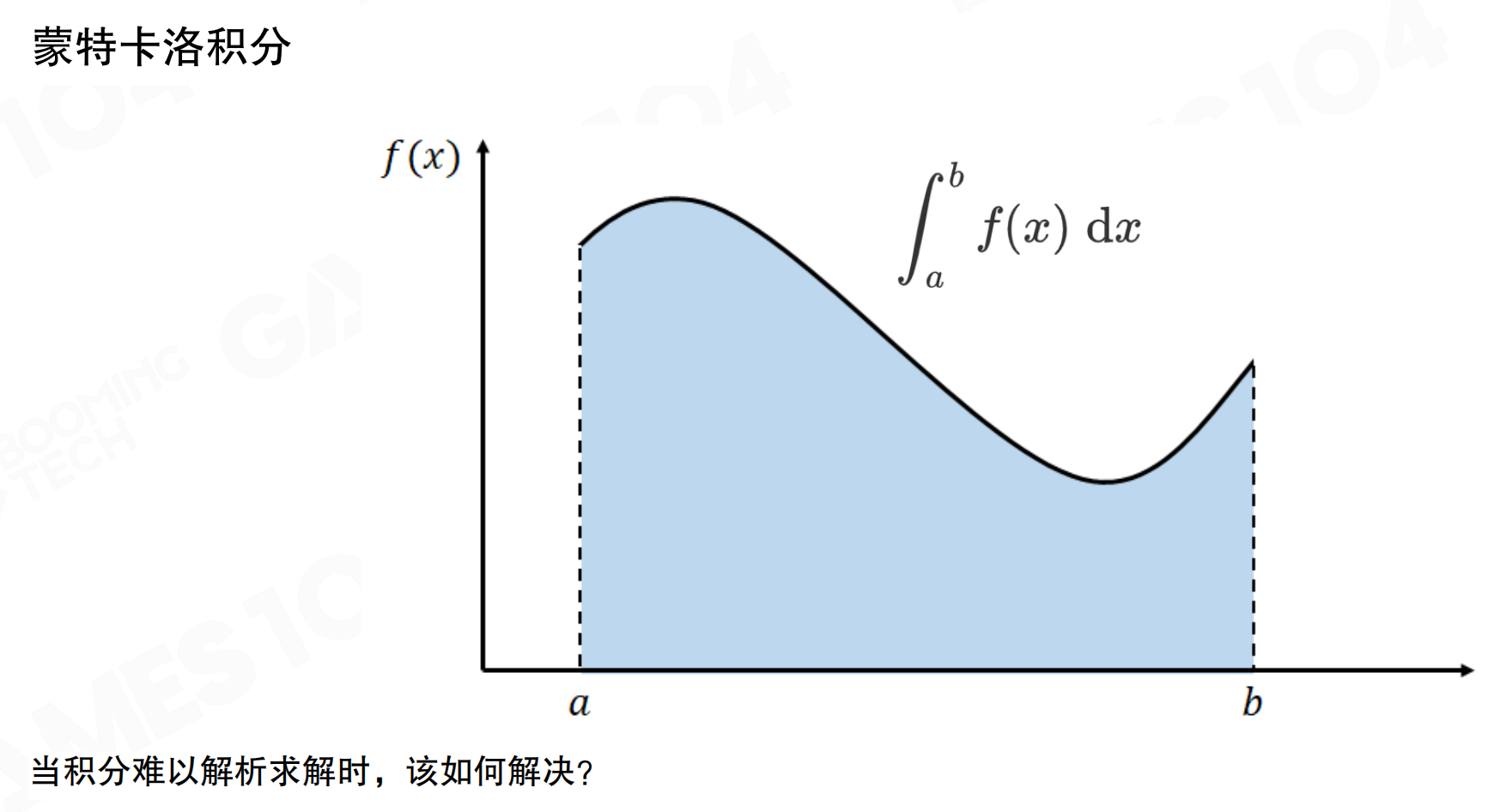
对于函数f(x)在区间[a, b]上的积分,蒙特卡洛方法通过随机采样函数值并求平均来近似积分。采样点越多,近似结果越接近真实值。
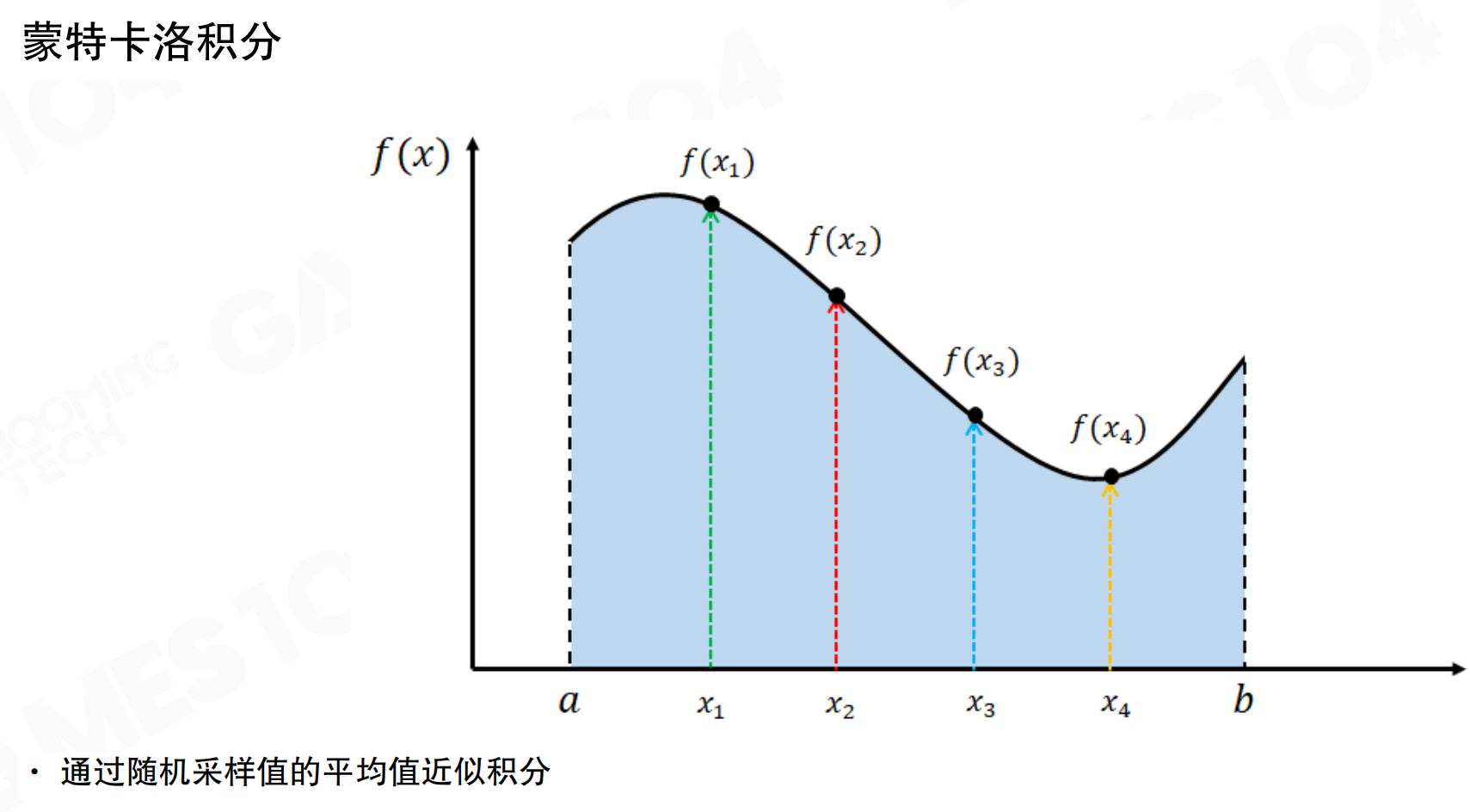
在区间内随机选择采样点x_1, x_2, ..., x_n,计算对应的函数值f(x_1), f(x_2), ..., f(x_n),通过平均值近似积分。采样数量越多,噪声越小,结果越平滑。
蒙特卡洛光线追踪
光线追踪(Ray Tracing)算法的本质就是通过蒙特卡洛积分来求解渲染方程。
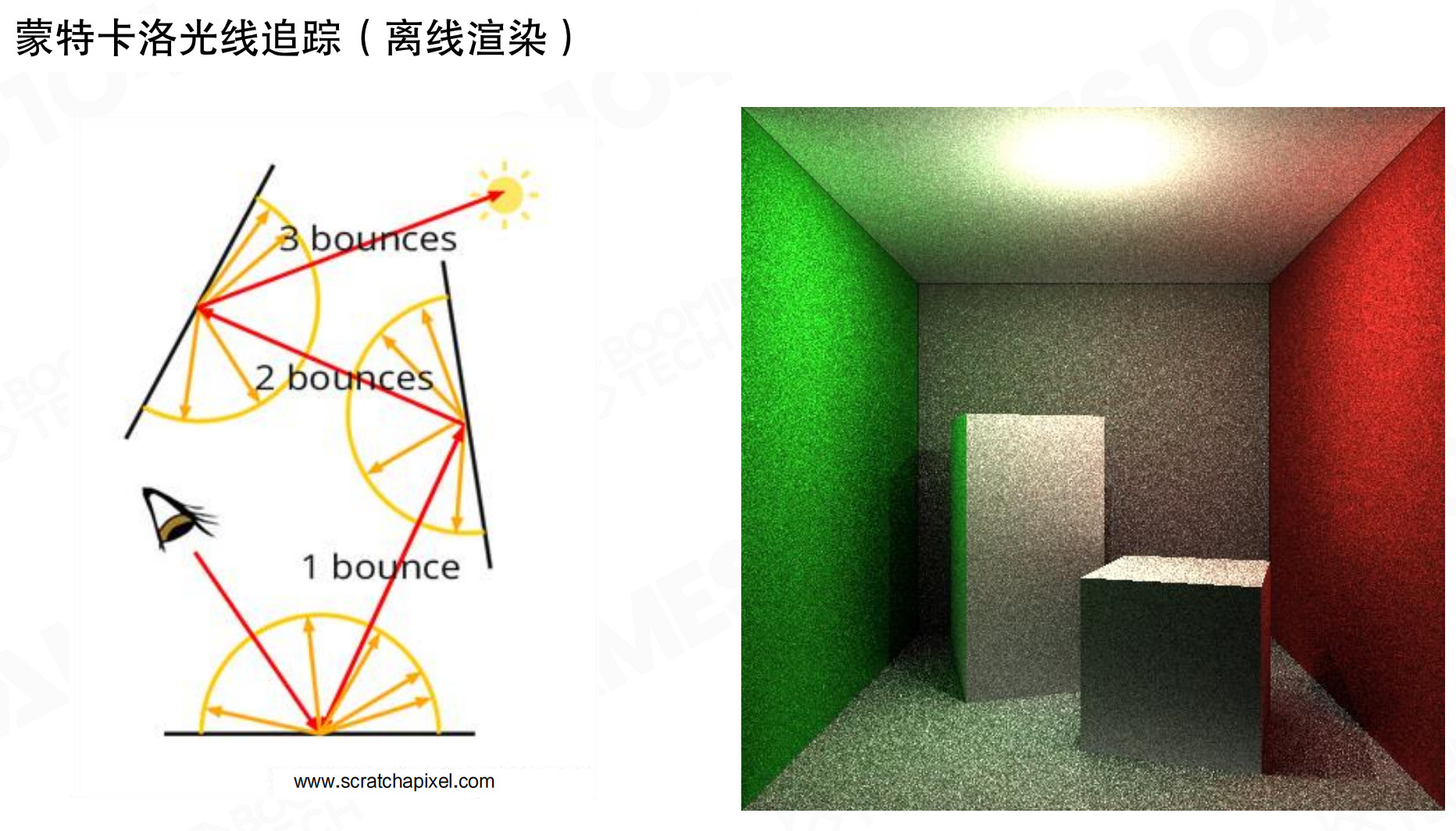
从眼睛位置对屏幕上每个像素发射光线,光线击中物体后,向四面八方投射光线寻找入射光。这些光线又会击中其他物体,在击中点再次向四面八方采样。这就是一次反弹(1 bounce)、两次反弹(2 bounces)、三次反弹(3 bounces)的过程。每次反弹都会产生指数级增长的计算量。单次反弹还可以接受,但多次反弹的计算成本极高。
就像玩弹球游戏。从发射器打出一个球,球撞到第一个障碍物后,会向四面八方弹开,形成多个球。每个球又撞到其他障碍物,再次弹开,形成更多球。1次反弹可能有10个球,2次反弹可能有100个球,3次反弹可能有1000个球。这就是指数级增长。在渲染中,每个”球”就是一根光线,需要计算它的路径和颜色。
更复杂的是,在大型场景中,真正亮的地方可能只是天顶的一扇窗,但整个房间被多次反弹的光照亮。进行光线追踪时,可能发射了50根光线,但只有极少数光线能采样到光源,大部分光线都浪费了。这导致渲染结果产生大量噪声。
比如一个只有一扇小窗户的地下室。窗户很小,但整个房间都被照亮了,因为光线在墙壁、地面之间不断反弹。但如果你随机往房间里扔50个乒乓球,只有几个能直接穿过窗户,大部分都撞到墙壁后弹到其他地方。这就是为什么需要发射很多光线才能准确采样到光源。
采样数量与噪声
采样是蒙特卡洛方法的核心。采样数量越多,噪声越小,但计算成本也越高。
类似用手机拍照,光线很暗。如果只拍1张照片,画面会有很多噪点,就像老式电视的雪花。如果拍10张照片然后平均,噪点会减少。如果拍100张、1000张照片平均,画面会越来越清晰平滑。但拍的照片越多,处理时间越长。这就是采样数量与噪声、计算成本的关系。

左上角显示每像素1个采样,从左到右、从上到下,每个方格的采样数逐倍递增。随着每像素采样数量的增加,噪声逐渐减少。当采样数达到2的16次方(约64000)时,图像已经相当平滑。但如果是多次反弹,即使单次反弹也需要几分钟才能渲染完成,多次反弹的计算时间更是难以估量。
均匀采样与概率分布函数
最简单的采样方法是均匀采样(Uniform Sampling)。
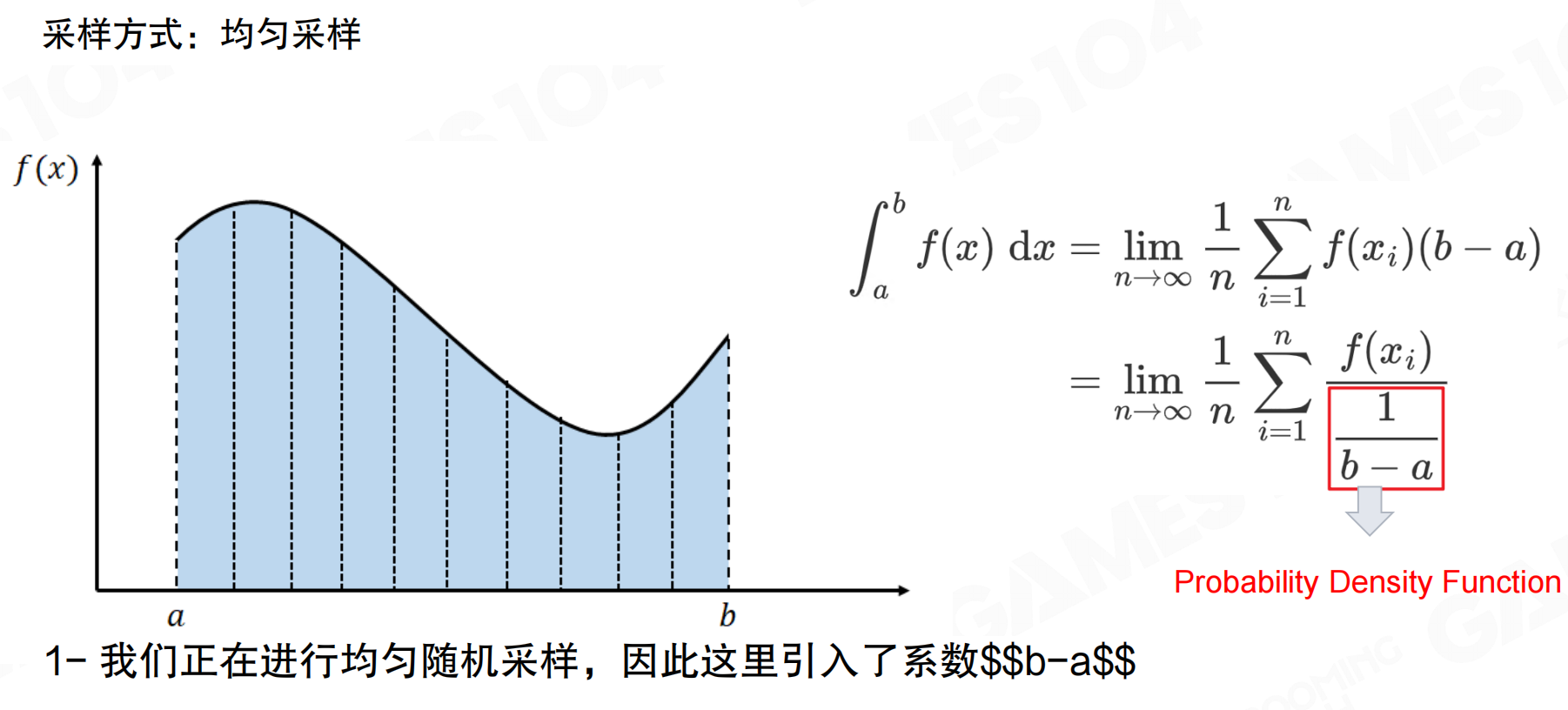
均匀采样在区间[a, b]上等概率选择采样点。对于函数f(x)的积分,可以通过采样值的平均值近似,其中1/(b-a)是均匀分布的概率密度函数(Probability Density Function, PDF)。
假设你要调查一个班级的平均身高。均匀采样就像随机抽取学生,每个学生被抽中的概率相同。如果你随机抽10个学生,测量他们的身高,然后求平均,就能估算整个班级的平均身高。这就是均匀采样。
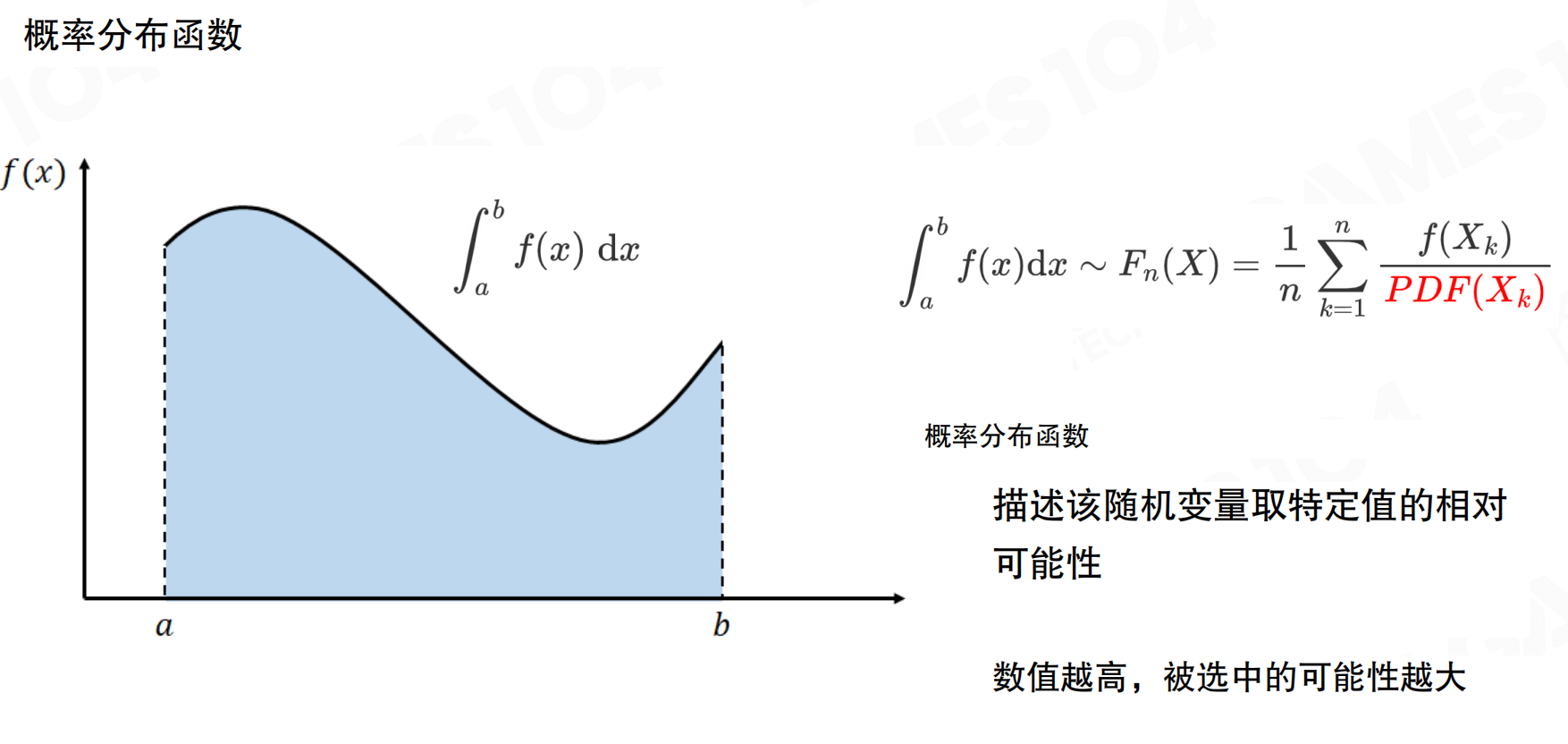
概率分布函数描述随机变量取特定值的相对可能性。数值越高,被选中的可能性越大。在蒙特卡洛积分中,积分可以近似为F_n(X) = (1/n) * Σ(f(X_k) / PDF(X_k)),其中PDF(X_k)是采样点的概率密度。
概率分布函数就像抽奖箱。如果箱子里有100个球,其中50个是红球,30个是蓝球,20个是绿球,那么红球被抽中的概率是50%,蓝球是30%,绿球是20%。PDF就是描述这种”被抽中可能性”的函数。
重要性采样
均匀采样的问题在于,除非采样密度很高,否则可能无法有效利用采样率。例如,在一个大型广场上进行光照积分时,如果只有一个窗子有光,均匀采样可能在窗子之间漏掉光源。
生活中的例子:想象你在一个巨大的黑暗仓库里找一盏小台灯。如果均匀采样,就像闭着眼睛随机走,可能走1000步都碰不到台灯。但如果你知道台灯大概在某个方向,就应该往那个方向多走几步,少走其他方向。这就是重要性采样:在重要的地方多采样,在不重要的地方少采样。
重要性采样(Importance Sampling)理论指出,当采样函数接近被积函数时,只需要相对少的样本就能很好地近似积分。现代高质量渲染的核心技术在于重要性采样的大规模应用。
想象你要估算一个城市的平均收入。如果均匀采样,可能抽到很多穷人,也抽到很多富人,需要很多样本才能准确。但如果你知道富人集中在某个区域,就应该在那个区域多采样,在其他区域少采样。这样用更少的样本就能得到更准确的结果。
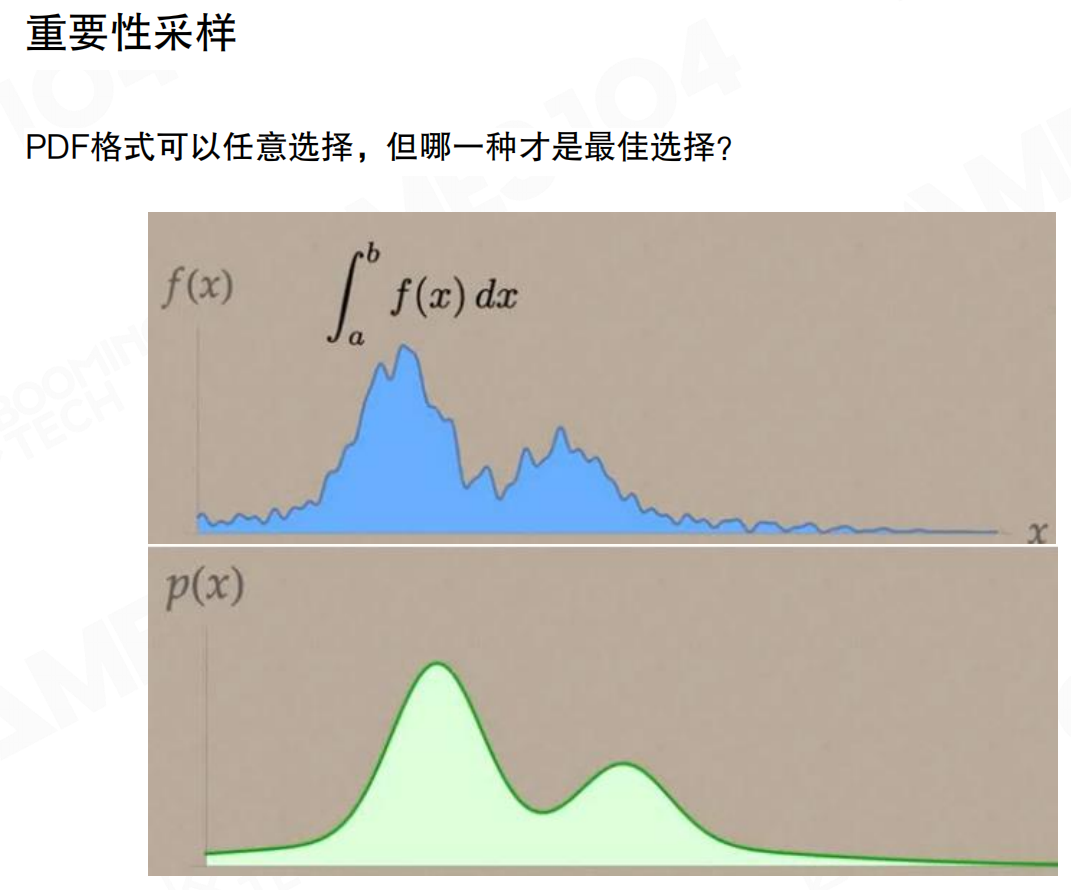
PDF可以任意选择,但哪一种才是最佳选择?对于渲染方程,被积函数包含余弦项cos θ_i,因此一个常见技巧是根据余弦项进行采样。类似地,也可以按照BRDF进行采样,这种采样方式对于光泽表面的物体往往有更高的积分效率。

在渲染方程中,被积函数是L_i(p, ω_i) f_r(p, ω_i, ω_o) (n · ω_i)。常见的PDF选择包括均匀分布p(ω_i) = 1 / 2π,以及余弦加权、GGX等其他PDF。
余弦权重重要性采样
对于大部分可以假设为漫反射的表面,对光的敏感度基本满足余弦分布。越靠近法线方向,敏感度越高;从侧面射来的光,即使光线很强,感应度也一般。这是朗伯余弦定律的体现。
想象一张白纸放在桌子上,太阳从正上方照下来。纸面正对太阳的部分最亮,从侧面照过来的光,即使很强,纸面也不会很亮。就像你用手电筒照一张纸,从正上方照最亮,从侧面照就暗很多。这就是为什么要在法线方向多采样,在侧面少采样。
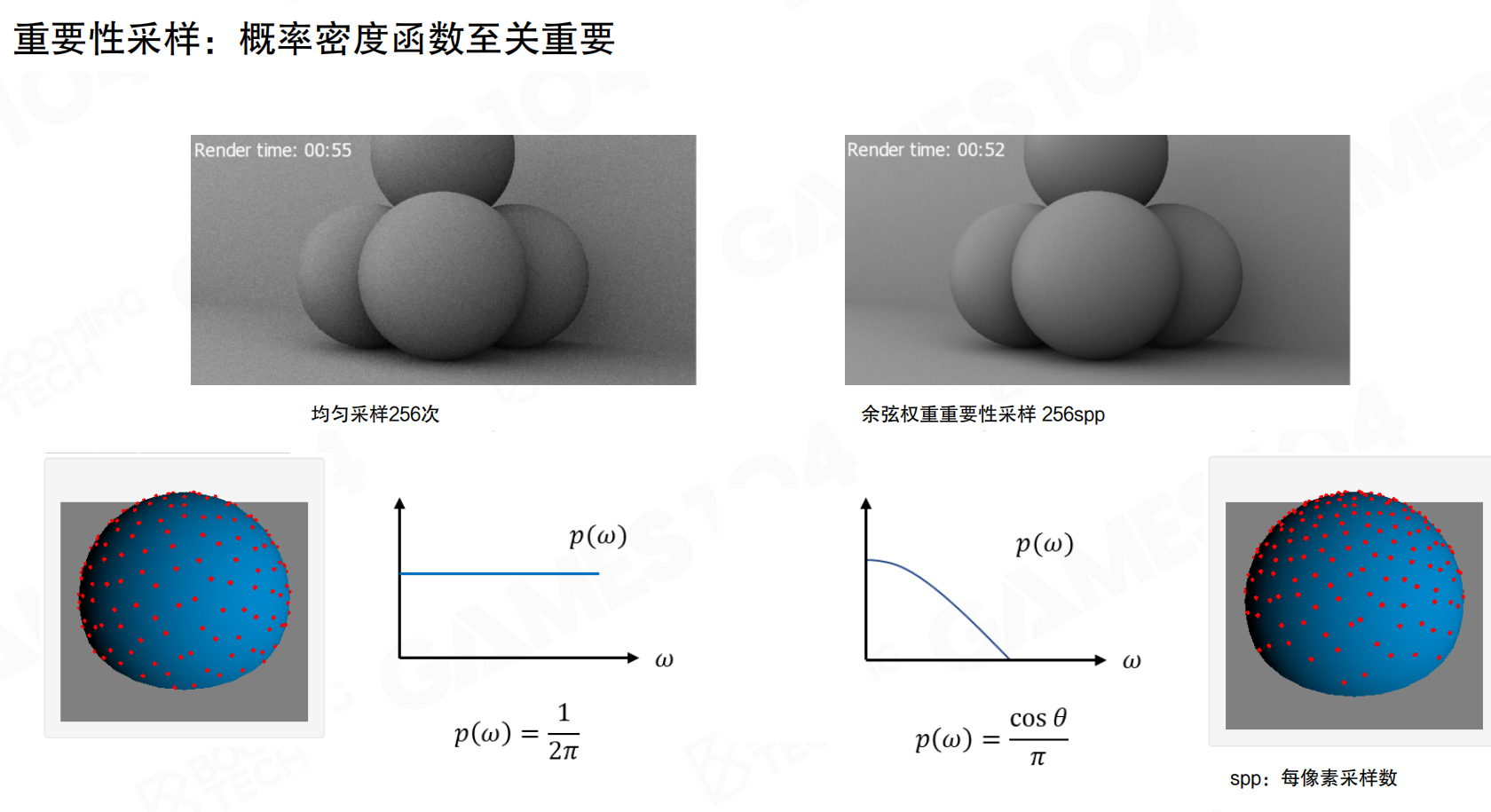
同样是256个每像素采样(spp),均匀采样会产生大量噪点,而余弦权重重要性采样在靠近天顶的地方分布更密集,靠近下方分布更稀疏,噪点明显减少。余弦权重采样使用p(ω) = cos θ / π作为PDF,在同样的采样数下能获得更好的渲染质量。
想象你要在球面上均匀撒种子。如果均匀采样,就像闭着眼睛随机撒,可能有些地方撒多了,有些地方撒少了。但如果你知道种子在靠近顶部的地方更容易生长,就应该在顶部多撒,在底部少撒。余弦权重采样就是这样:在重要的方向(靠近法线)多采样,在不重要的方向(远离法线)少采样。
余弦与GGX概率密度函数
对于非常光滑(glossy)的表面,如符合GGX材质的物体,可以使用基于GGX的PDF进行采样。

GGX分布比余弦分布更加尖锐。基于法线和GGX进行优化采样,能够更好地捕捉光滑表面的反射效果。GGX的PDF为p(ω) = α² cos θ / (π((α² – 1) cos² θ + 1)²),其中α是粗糙度参数。从对比图可以看出,使用GGX重要性采样后,金属材质的反射效果明显改善,噪点大幅减少。
小结
全局光照的核心在于求解渲染方程中的复杂积分。蒙特卡洛积分通过随机采样来近似积分,但采样效率至关重要。重要性采样通过设计合适的概率密度函数,用尽可能少的采样获得尽可能好的结果。对于每个屏幕像素,需要知道来自四面八方的光场影响,关键在于在正确的地方、重要的地方进行采样。这是理解后续各种GI算法的基础。
21.2 反射式阴影贴图 RSM
尽管通过光线追踪可以解决GI问题,但它的主要缺陷在于基本无法应用在游戏这样有实时性要求的场景中。为了实现实时GI,人们设计了各种近似算法,其中最早的工作可以追溯到2005年的反射式阴影贴图(Reflective Shadow Maps, RSM)。
RSM是实时GI领域的开山鼻祖,启发了后续很多工作。它核心解决的问题是:如何把光注入到场景中。从实现层面讲,RSM更接近于光子映射(Photon Mapping)。光子映射理论认为相机接收到的辐射率本质是由光源发射的光子经过场景不断吸收和反射最终被相机捕获的结果。因此可以从光源出发发射大量光子,计算光子在场景上的分布,然后通过相机收集。
RSM的核心思想基于一个观察:正常渲染从相机视角看,而阴影贴图(Shadow Map)从光源视角看。渲染Shadow Map时,如果从光源位置把整个场景渲染一遍,得到的就是所有被直接照亮的表面。这些被照亮的表面可以成为间接光源,向周围散射光线。
想象你用手电筒照一面白墙。从你的视角(相机视角)看,你看到的是墙的正面。但从手电筒的视角(光源视角)看,手电筒”看到”的是所有被它直接照亮的表面。这些被照亮的表面就像小灯泡,会向周围发光。RSM就是记录这些”小灯泡”的位置和亮度,然后用它们来照亮其他物体。
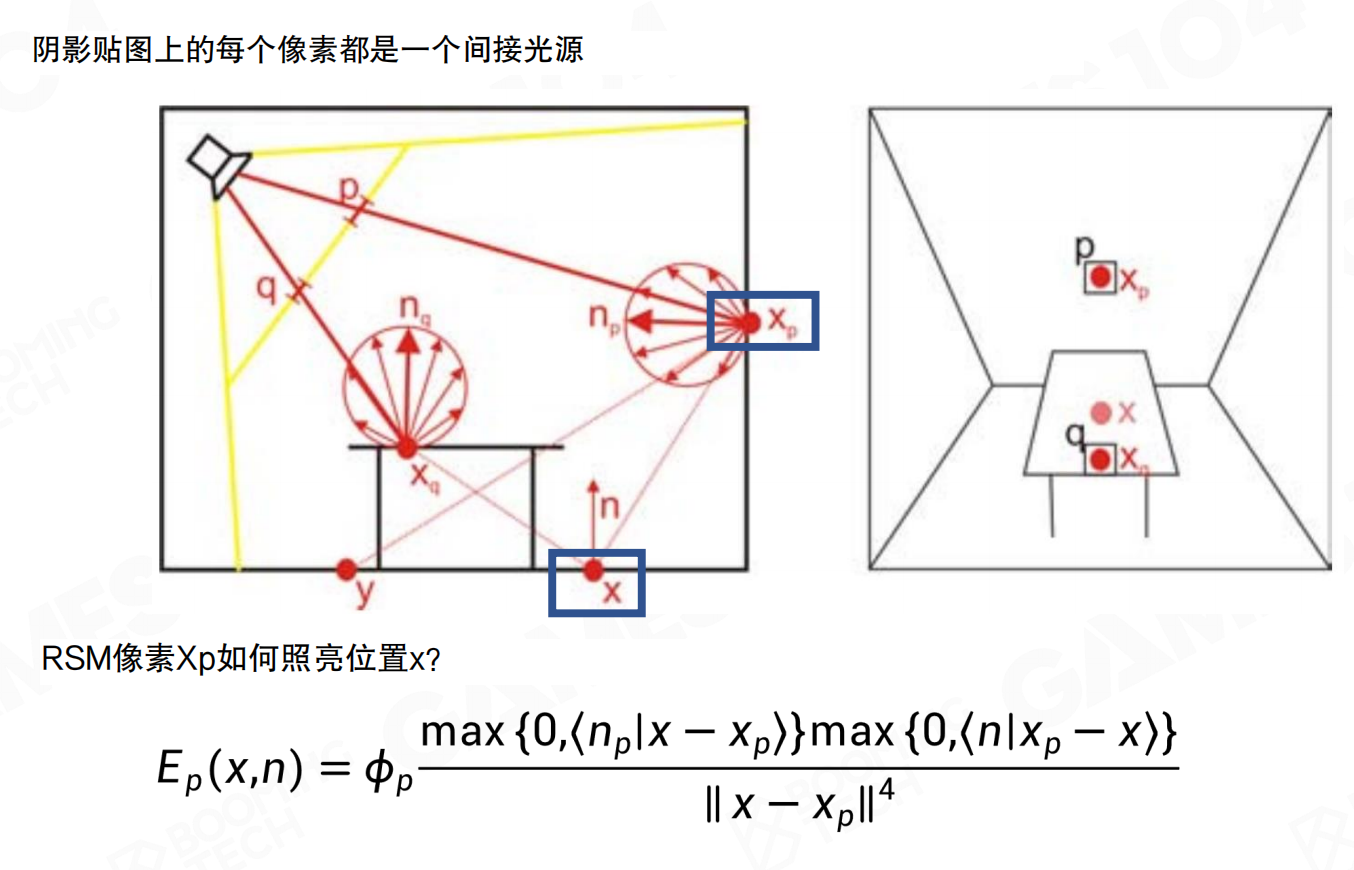
RSM像素x_p如何照亮位置x?当光源照射到点x_p时,根据朗伯模型,x_p会向各个方向散射光线。对于接收点x,间接辐照度E_p(x,n)的计算公式为:
E_p(x,n) = Φ_p * (max{0, <n_p | x - x_p> } * max{0, <n | x_p - x> }) / ||x - x_p||^4
其中Φ_p是间接光源x_p的通量,n_p是x_p处的法线,n是接收点x处的法线。两个点积项确保光线只在正确方向传播,距离的四次方衰减项(注意是四次方而非二次方,因为包含了向量归一化)控制光照强度随距离的衰减。
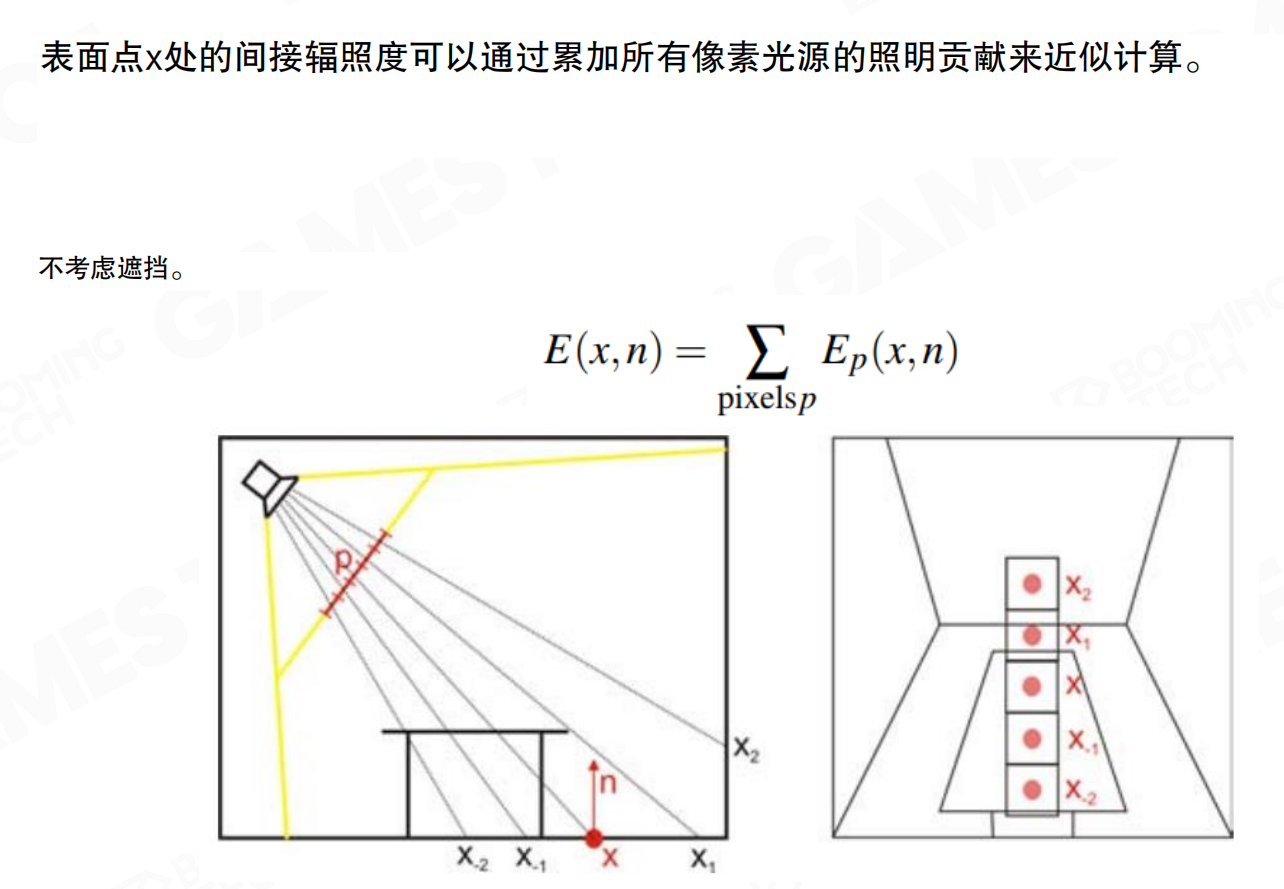
表面点x处的间接辐照度可以通过累加所有像素光源的照明贡献来近似计算,不考虑遮挡。公式为E(x,n) = Σ pixels_p Ep(x,n),即对所有RSM像素光源的贡献求和。这种方法将RSM上的每个像素都视为一个微小的面光源,通过采样这些光源来计算间接光照。
直接计算来自场景中所有被照亮表面的反射光线需要非常大的计算量。如果RSM是512x512分辨率,就有约26万个点。对每个屏幕像素都遍历所有点显然不现实。
想象你要计算房间里每个点被多少个小灯泡照亮。如果房间里有26万个灯泡,对每个点都检查所有灯泡,计算量巨大。就像你要统计一个城市里每个人被多少盏路灯照亮,如果对每个人都检查所有路灯,工作量无法完成。

RSM使用锥体追踪(Cone Tracing)技术进行简化。核心思路是随机采样RSM像素,而不是遍历所有像素。预先计算采样模式,在所有间接光照计算中重复使用。约400个样本已足够,使用泊松采样(Poisson Sampling)获得更均匀的样本分布。
回到城市路灯的例子。不需要检查所有路灯,只需要随机选择400个路灯,检查它们对当前点的影响。就像做民意调查,不需要问所有人,只需要随机问400个人,就能估算整体情况。泊松采样确保这400个样本分布均匀,不会都挤在一起。
采样模式的特点是:随着与中心距离的增加,采样密度逐渐降低,而采样权重(通过圆盘半径可视化)相应增大。对于非常漫反射的表面,可以采样较高mipmap层级的RSM,一次性采样更大的锥体;对于非常光滑的表面,采样较低mipmap层级,在尖角处多采样。这样可以在保证质量的同时大幅减少计算量。

由于间接光照相对低频,可以降低输出分辨率进一步提升效率。计算低分辨率图像的间接光照,对于全分辨率下的每个像素:获取其周围的四个低分辨率采样点,通过比较法线空间与世界空间位置进行验证,然后进行双线性插值。如果采样点与当前像素的空间位置相差特别大,或法向朝向不共面,则认为插值无效,需要重新计算这些像素(图中红色像素)。这些需要重新计算的像素通常不到屏幕的1%,对它们进行完整采样即可。
想象你要给一张高清照片(上百万像素)计算光照。如果每个像素都算一遍,太慢了。但间接光照变化很慢,就像远处的山,细节不多。所以可以先计算低分辨率版本(比如每16个像素算一个),然后对中间像素进行插值。就像看地图,远山用粗线条画,近处用细线条画。但如果发现某个地方插值不对(比如突然有个悬崖),就重新精确计算那个地方。
低分辨率间接光照+插值+错误检查的思路很实用。屏幕上有上百万个像素,用低密度光采样然后插值到每个像素,大部分情况下可行,少数情况下会产生artifact。通过错误检测标记这些像素并重新计算,在保证质量的同时提升效率。这个思路在后续的Lumen等算法中也有应用。
就像做数学题,大部分题目可以用简单方法快速估算,但遇到特殊情况(比如边界条件、奇点)就需要用精确方法重新计算。这样既保证了速度,又保证了准确性。

通过RSM实现的GI可以明显提升游戏画面中阴影部分的细节。在《战争机器4》《神秘海域4》《最后生还者》等游戏中,手电筒照射时,光线会从被照亮的表面反弹,照亮周围环境。关闭反弹光照时,只有直接照射区域可见,其他区域几乎完全黑暗;开启反弹光照后,间接光照让阴影区域可见,细节清晰,画面更真实自然。
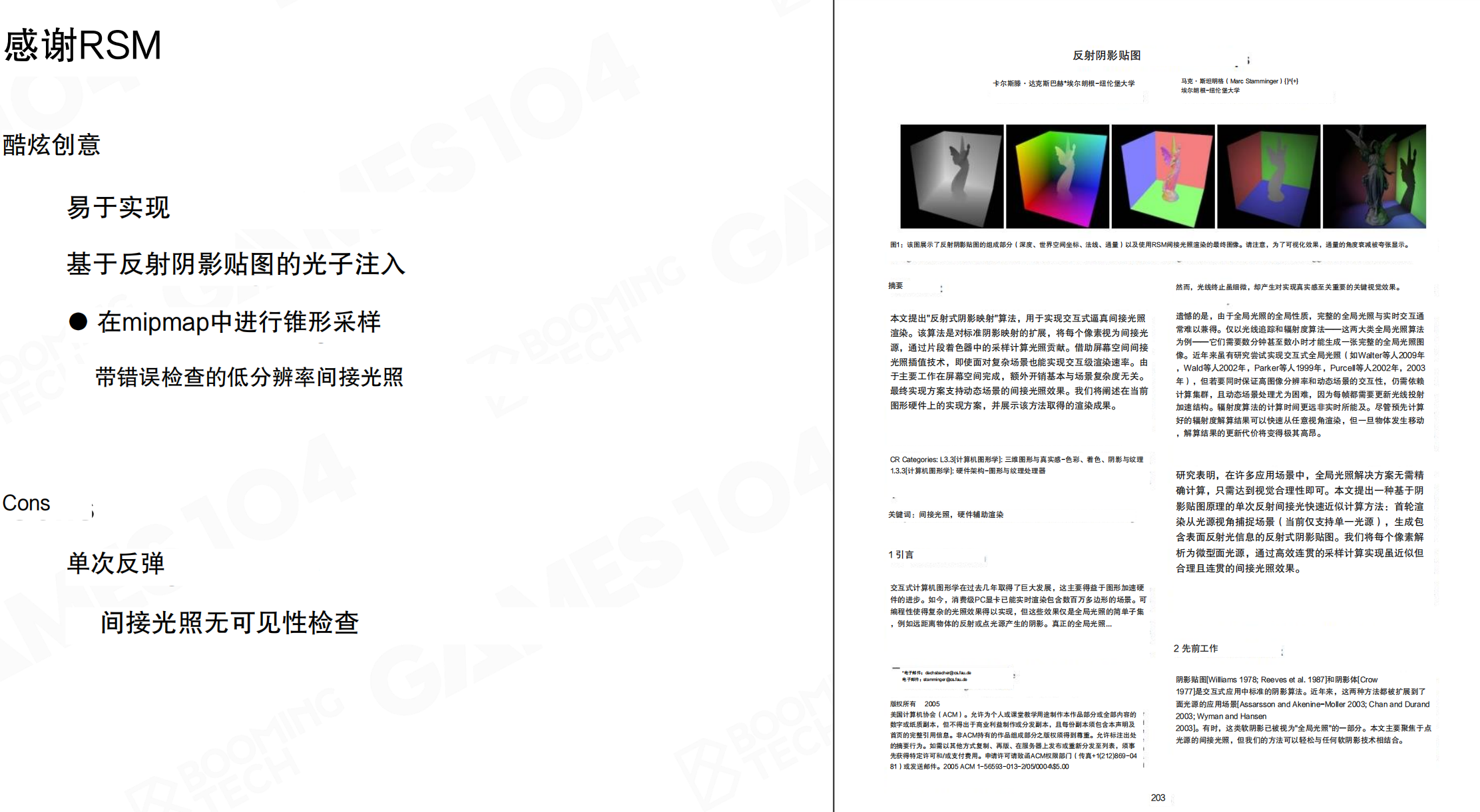
RSM作为实时GI的早期工作,具有以下优点:易于实现,计算效率高,基于反射阴影贴图的光子注入思想,在mipmap中进行锥形采样,带错误检查的低分辨率间接光照。其缺陷在于:只能处理单次反弹(Single Bounce),间接光照无可见性检查(No Visibility Check),会假设光线不被遮挡,可能产生artifact。
尽管RSM有很多局限,但它是一个非常有启发性的工作。它第一次真正实现了把光子注入到场景中,启发了后续大量实时GI算法的发展。理解RSM的核心思路,对于理解Lumen等现代实时GI系统非常重要。
21.3 光传播体积LPV 和 用于实时全局光照的稀疏体素八叉树SVOGI
光传播体积LPV
有了RSM把光子注入场景后,下一步是让光在场景中流动起来。光传播体积(Light Propagation Volumes, LPV)是考虑光线在场景中不断传播的一种GI算法,最早在2009年提出,首次亮相于CryEngine 3。

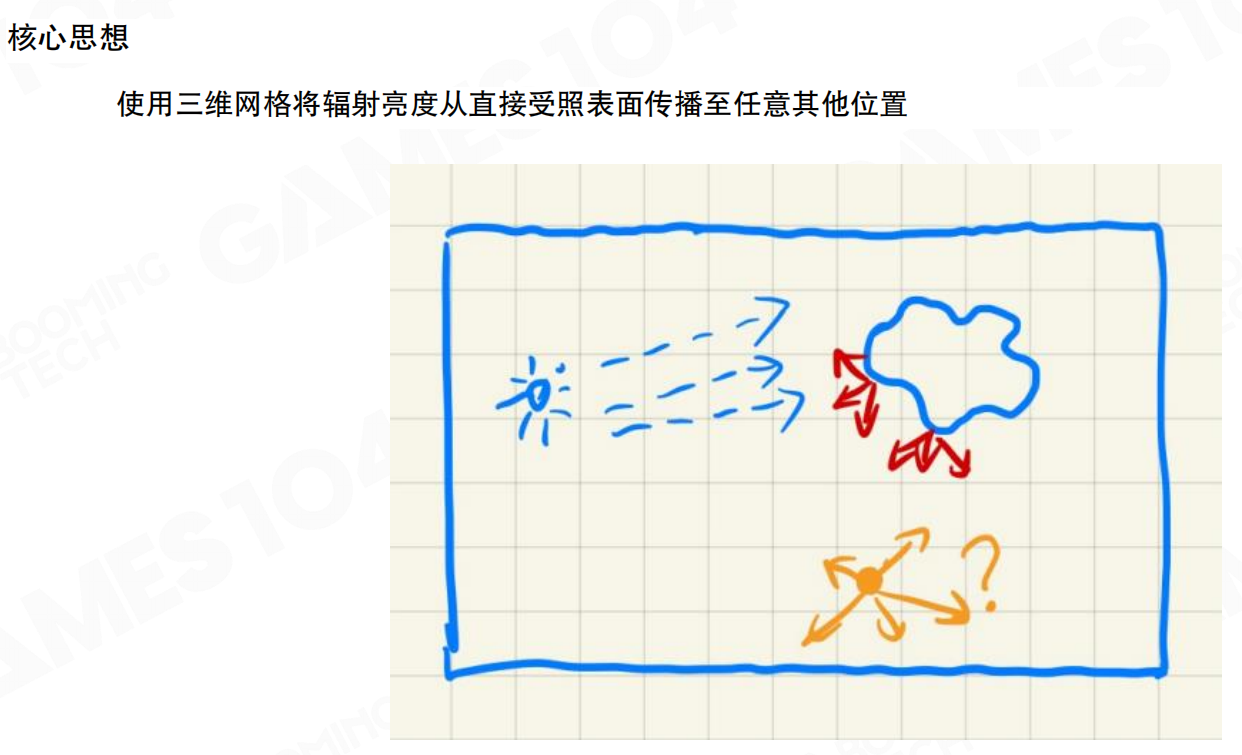
LPV的核心思想是:使用三维网格将辐射亮度从直接受照表面传播至任意其他位置。把世界分成无数个格子(体素),当光照射到每个格子时,如果格子内有物体,光会在其中形成反弹,形成辐射亮度的分布。渲染任何点时,可以从这些体素中取出辐射亮度信息。
想象一个装满小方块的透明盒子,每个方块代表一个体素。当手电筒照到某个方块时,这个方块会”记住”光的亮度和方向。然后光会从这个方块传播到相邻的方块,就像水从高处流向低处。经过几轮传播后,整个盒子里的每个方块都记录了周围的光照信息。当你需要知道某个位置有多亮时,直接查看对应方块的信息即可。
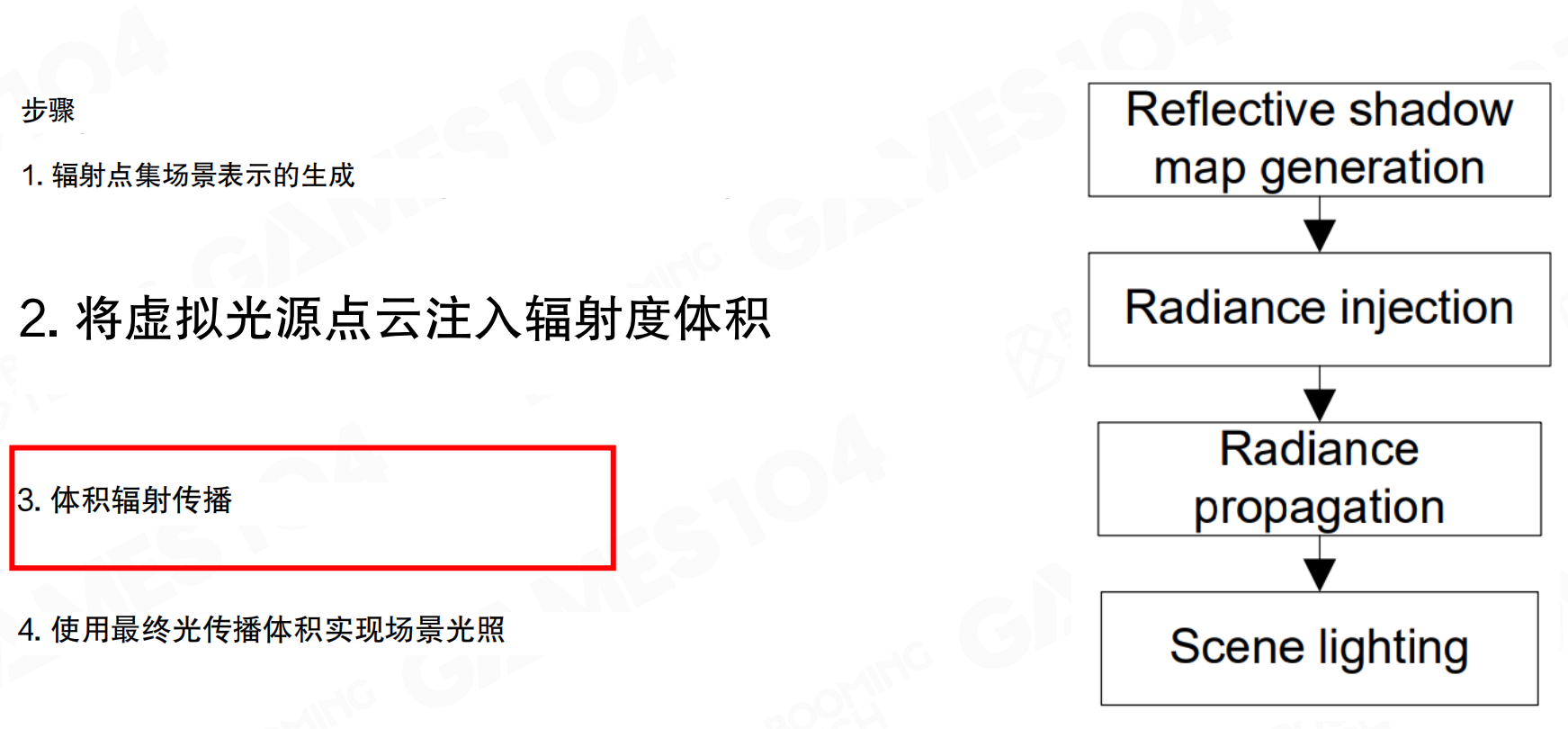
LPV的计算流程分为四个步骤:1. 辐射点集场景表示的生成(Reflective shadow map generation);2. 将虚拟光源点云注入辐射度体积(Radiance injection);3. 体积辐射传播(Radiance propagation),这是核心步骤;4. 使用最终光传播体积实现场景光照(Scene lighting)。
辐射信息”冻结”于体素中
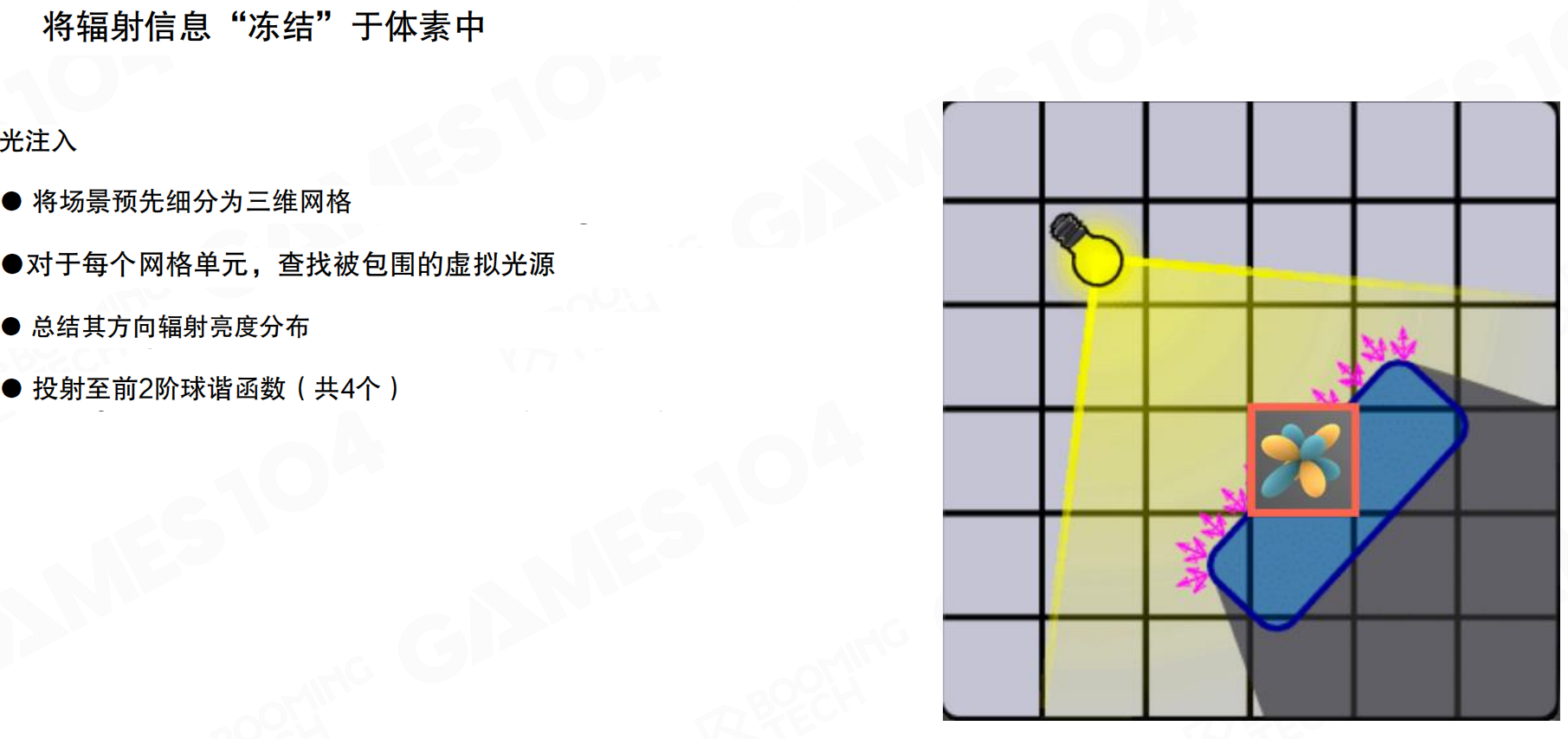
首先进行光注入(Light injection)。将场景预先细分为三维网格,对于每个网格单元,查找被包围的虚拟光源,总结其方向辐射亮度分布。由于辐射亮度是球面分布函数,直接存储和计算非常复杂。LPV使用球谐函数(Spherical Harmonics, SH)来表示方向分布,投射至前2阶球谐函数(共4个系数)。这样无论采集多少个表面点,它们的贡献都可以用SH加权累积在一起,用SH表达这个函数。
球谐函数的作用类似于用几个数字来概括一个复杂的方向分布。想象你要描述一个房间里的光照:从四面八方来的光强度都不同,直接记录每个方向需要大量数据。但用球谐函数,就像用”上亮下暗、左亮右暗”这样的简单描述,用几个系数就能大致表达整个球面的光照分布。虽然不够精确,但足够描述低频的光照变化,而且计算和存储成本低得多。
体积辐射传播
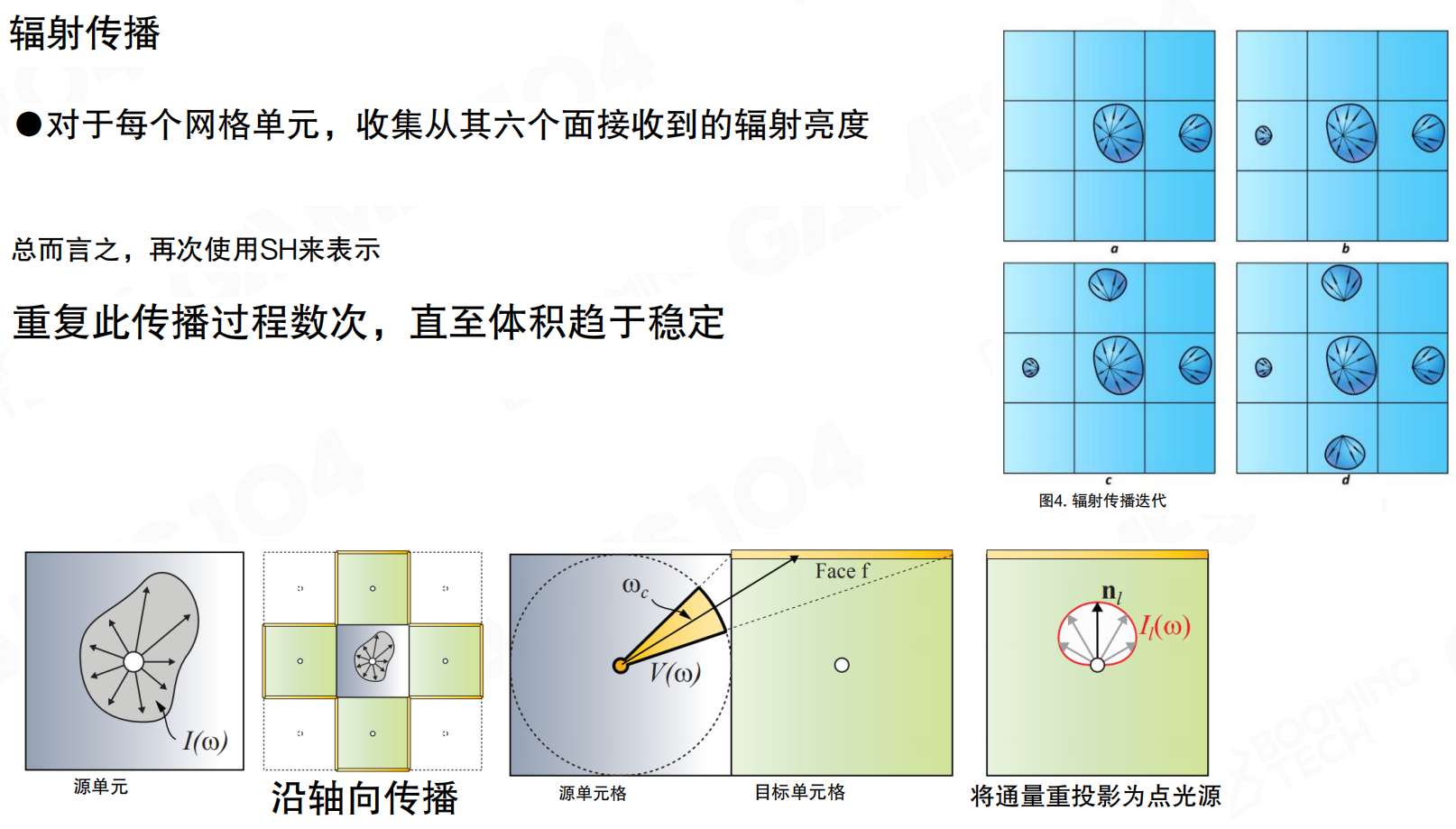
对于每个网格单元,收集从其六个面接收到的辐射亮度,再次使用SH来表示。然后进行传播:从表面上的体素向空间中的其他体素扩散。扩散通过编码实现,例如从左边出去的SH部分,通过数学方程传到另一面。重复此传播过程数次,直至体积趋于稳定。
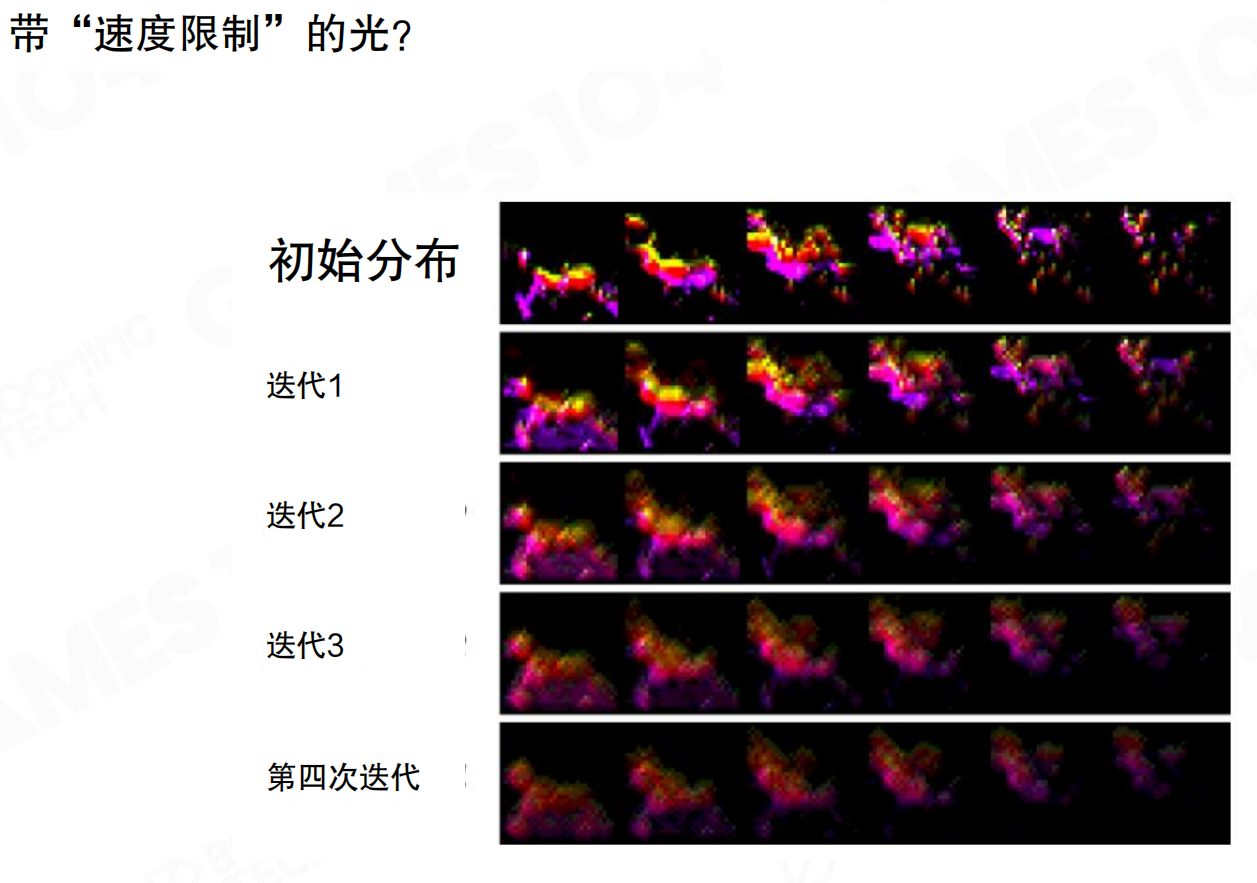
传播过程是迭代的。从初始分布开始,每次迭代后,辐射亮度在空间中逐渐扩散。经过多次迭代(如四次迭代),光在整个体积中趋于稳定分布。LPV将光线传播视为扩散过程,这种处理不完全遵循物理法则。光的扩散速度和范围与迭代次数有关,相当于光在各个体素中传递时有”速度限制”,与真实物理不一致。
这个过程类似于热传导。想象一个铁块,一端被加热。第一次迭代,只有紧挨着热源的部分变热;第二次迭代,热量传到更远的地方;第三次、第四次,热量逐渐扩散到整个铁块。虽然真实的光速是瞬间的,但LPV用这种迭代方式模拟光的传播,每次迭代光只能”走”到相邻的体素,就像热量需要时间传导一样。这样虽然不完全物理准确,但计算简单,效果也足够好。
用于实时全局照明的稀疏体素八叉树SVOGI
LPV使用均匀的三维网格,但场景中很多空间是空的,不需要存储。用于实时全局照明的稀疏体素八叉树(Sparse Voxel Octree for Global Illumination, SVOGI)的思路与LPV非常接近,都使用网格方式对场景空间进行划分,但SVOGI使用八叉树(Octree)来更高效地管理体素。
SVOGI使用保守光栅化(Conservative Rasterization)来获取场景的体素表达。保守光栅化保证即使是很薄很小的三角形,也至少有一个像素被覆盖。对三角形进行三个方向投影时,把这个像素三方向投影,就能得到体素的表达。这样可以把所有表面的体素都收集起来。
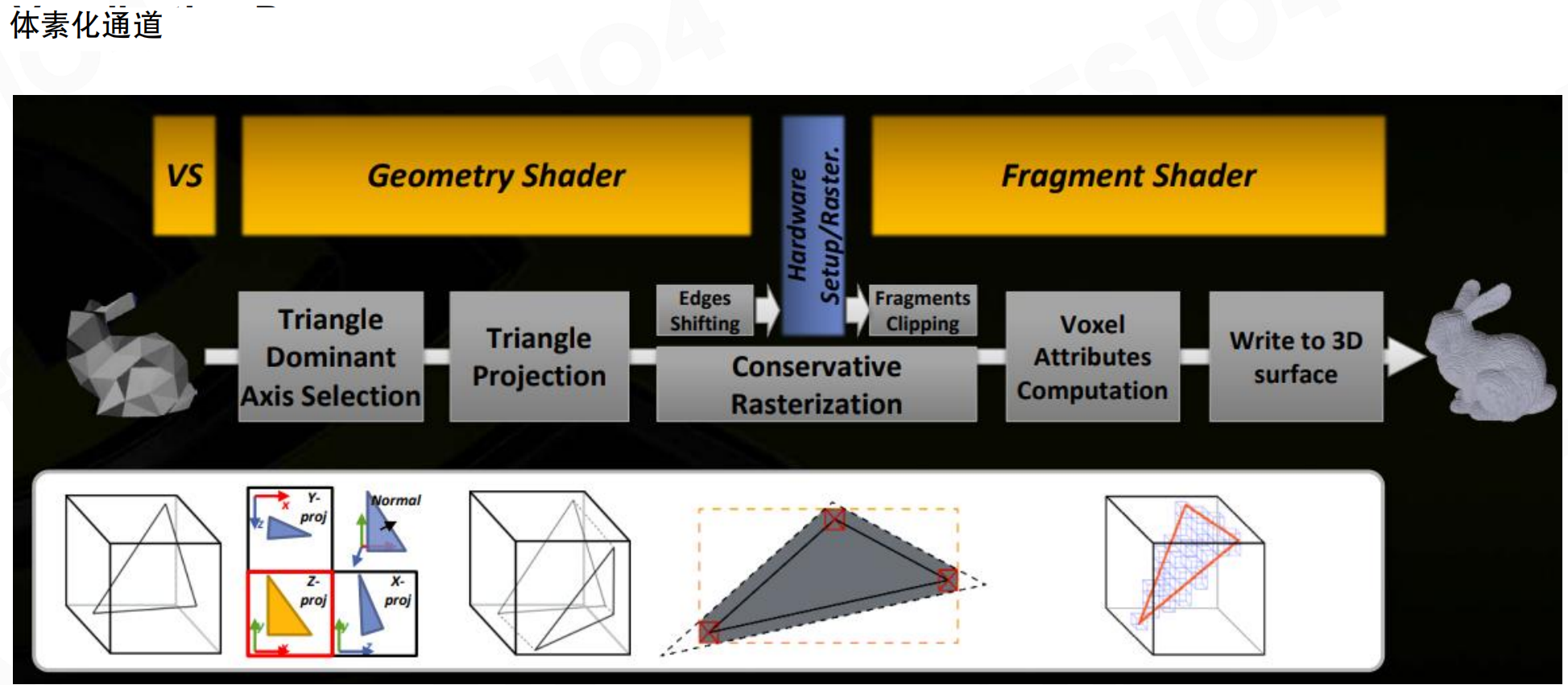
体素化通道包括:顶点着色器(VS)、几何着色器(Geometry Shader)、硬件设置/光栅化(Hardware Setup/Raster.)、片段着色器(Fragment Shader)。核心步骤是三角形主导轴选择、三角形投影、保守光栅化、体素属性计算,最后写入3D表面。保守光栅化通过边缘偏移(Edges Shifting)和片段裁剪(Fragments Clipping)来确保薄三角形也能被正确体素化。

收集表面体系后,得到场景中所有表面的体素表示。这些体素用八叉树组织:空间上每个维度的二分,在3D空间中就是2³=8次分割。没有物体的地方分得特别粗,直到分到有物体为止。这样形成对空间的稀疏表达,只存储有表面的体素。
八叉树就像俄罗斯套娃,但每次分成8个。想象一个大盒子代表整个场景。如果盒子里有物体,就把盒子分成8个小盒子。如果某个小盒子是空的,就不再细分;如果有物体,继续分成8个更小的盒子。这样,空的地方用一个大盒子表示,有物体的地方用很多小盒子精确表示。就像地图:空旷的海洋用大块表示,城市街道用小块详细表示。这样既节省存储,又能快速找到物体。
八叉树中的光注入与过滤
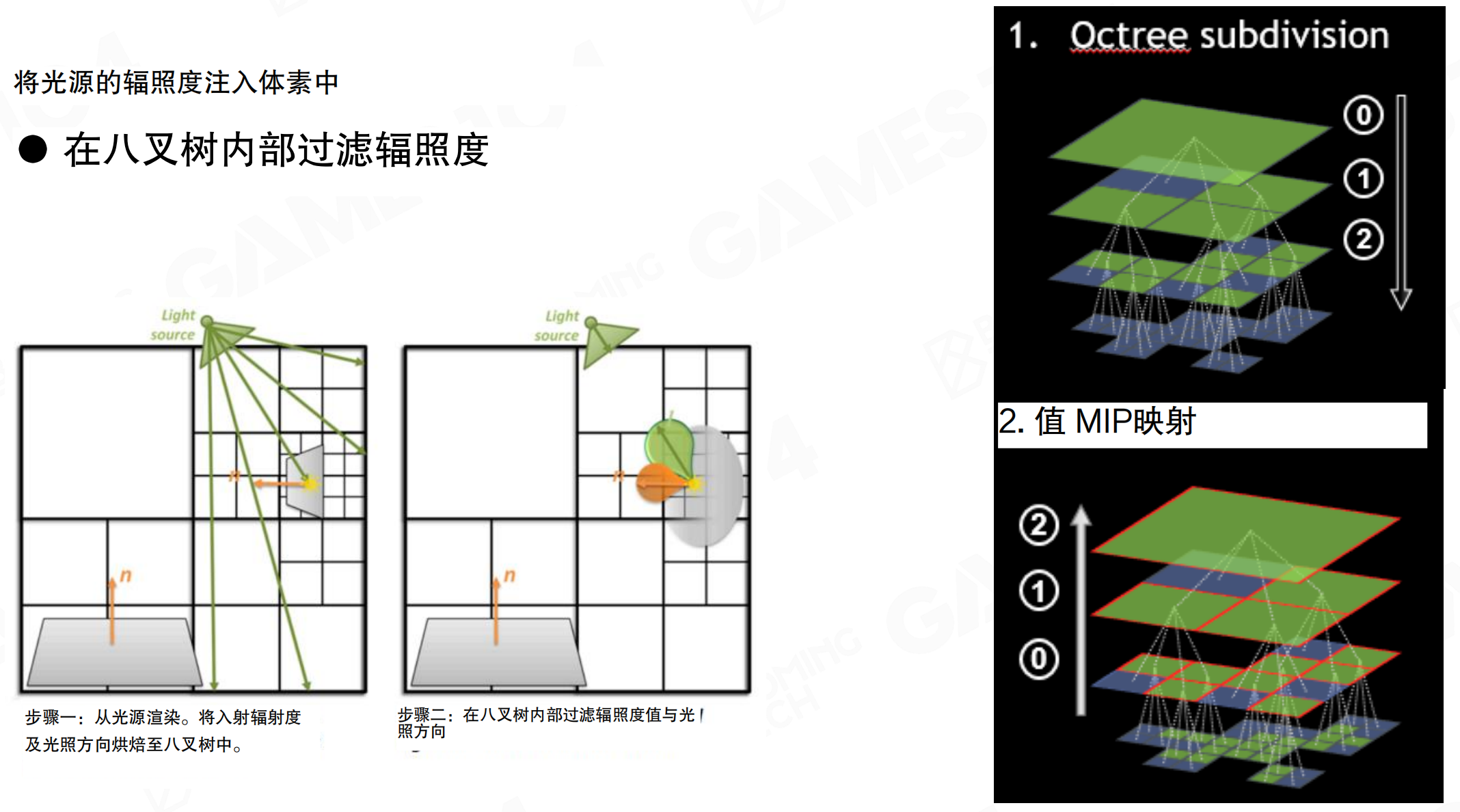
将光源的辐照度注入体素中,在八叉树内部过滤辐照度。步骤一:从光源渲染,将入射辐射度及光照方向烘焙至八叉树中。步骤二:在八叉树内部过滤辐照度值与光照方向。八叉树细分允许自适应分辨率:几何复杂或光照变化大的区域使用更细的体素,空区域使用更粗的体素。值MIP映射(Value MIP mapping)从细粒度体素向上聚合,生成多分辨率表示,便于在不同尺度查询光照信息。
基于体素树的锥体追踪着色
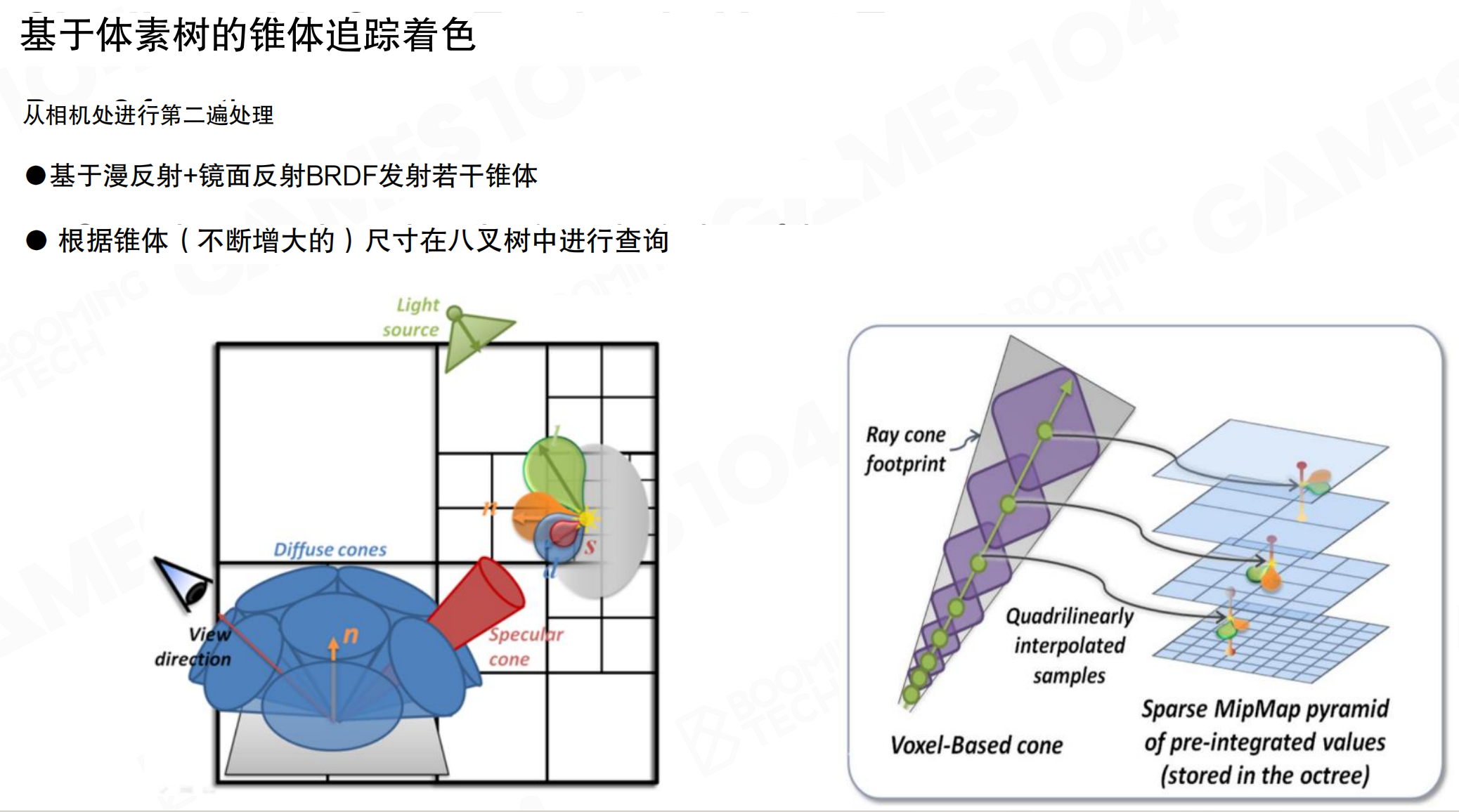
进行着色时,使用锥体追踪(Cone Tracing)方式对八叉树进行查询。从相机处进行第二遍处理,基于漫反射+镜面反射BRDF发射若干锥体。根据锥体(不断增大的)尺寸在八叉树中进行查询。锥体的特点是:随着距离增加,锥体展开,会扫到越来越大颗粒的体素。八叉树越靠近根节点,每个体素表达的空间区域越大,取到一个体素的值实际上可能是很大面积的辐射亮度平均。用锥体追踪可以高效查询光照,无需对每个方向都采样一根光线。锥体追踪在稀疏MIP映射金字塔中查询预积分值,使用四线性插值(Quadrilinear interpolation)平滑采样结果。
锥体追踪就像用手电筒照东西。手电筒的光束是一个锥形,近处照得细,远处照得宽。对于近处的细节,用细光束精确查看;对于远处的物体,用宽光束大致查看即可。在八叉树中,近处用细小的体素,远处用粗大的体素,正好匹配锥体的展开。就像用望远镜看风景:近处的树用高倍镜看细节,远处的山用低倍镜看整体。这样一次查询就能覆盖一个方向的光照,而不需要发射很多根细光线。
小结
LPV和SVOGI都使用体素化空间来存储和传播光照信息。LPV使用均匀网格和SH表示,通过迭代传播实现多反弹GI,但数学上不完全符合物理。SVOGI使用稀疏八叉树和保守光栅化,通过锥体追踪进行高效查询。这些方法为后续的实时GI算法奠定了基础,但实现复杂度较高,在硬件加速和数据结构管理上存在挑战。
21.4 基于体素化的全局光照 VXGI
SVOGI的稀疏八叉树数据结构在GPU上表达非常复杂,需要多层索引、存储邻居数据、保证一致性等,实现难度高。基于体素化的全局光照(Voxel Global Illumination, VXGI)可以看作是对SVOGI的简化,使用Clipmap这样的数据结构来描述场景。
对于GI来说,最重要的是眼睛看到的区域,特别是近处区域。远处区域虽然重要,但不需要高精度采样。Clipmap的思想是:离相机越近,体素越密集;离相机越远,体素越稀疏。这样形成视距相关的密度分布(view-dependent density distribution),比稀疏八叉树更GPU友好,实现更清晰简单。
就像人眼看东西:近处的东西看得清楚,需要高分辨率;远处的东西看得模糊,低分辨率就够了。Clipmap就像给场景套上几层不同精度的”网格”:最内层是精细网格,覆盖近处;中间层是中等网格,覆盖中距离;最外层是粗糙网格,覆盖远处。当你移动时,这些网格也跟着移动,始终保持相机在中心。就像用不同倍数的放大镜看地图:近处用高倍镜看细节,远处用低倍镜看整体。

Clipmap将体素数据存储在剪辑贴图中,使用多分辨率纹理。靠近中心的区域具有更高的空间分辨率,似乎天然契合锥体追踪的需求。相比稀疏体素八叉树(SVO),Clipmap的构建更为简便,无需节点、指针等,由硬件处理。Clipmap更易于读取。
与Mipmap不同,Mipmap随着LOD增加,总元素数和分辨率都降低。Clipmap在所有LOD层级都保持固定的元素数(如64个元素),但随着LOD增加,有效覆盖的空间范围变大。这就像用回形针把不同尺寸的纸叠在一起,最上层只有名片那么大,最下层可能是A4纸那么大,一拿就走。
Clipmap尺寸通常为64³到256³,具有3到5级细节层次。每个体素占16至32字节,需要12MB至2.5GB的显存。在2D视图中,可以看到三个级联(Cascade):Cascade 1(绿色)最内层,分辨率最细;Cascade 2(浅蓝色)中等分辨率;Cascade 3(深蓝色)最外层,分辨率最粗。
体素更新与环形寻址
当相机运动时,无需更新整个Clipmap,只需要更新相机采样的范围。这通过环形寻址(Circular Addressing)实现。

空间中的固定点始终映射到Clipmap中的同一地址。背景显示纹理地址使用公式:frac(worldPos.xy / clipmapSize.xy),即世界位置的xy坐标除以Clipmap尺寸的xy坐标,取小数部分。这样当相机移动时,原来做的数据不需要在内存中更新位置,只需要覆盖掉边界的数据,边界数据反向写回来即可。中间没有变化的数据保持原位置,避免了昂贵的memory copy操作。这个技巧在Virtual Texture等大世界空间表达中非常有用。
环形寻址就像用一张循环的地图。想象你有一张100×100的地图,当你往右走到边界时,不是把整张地图往左移,而是直接跳到左边继续走,就像地图是首尾相连的。这样,地图上的每个位置(比如坐标50,50)永远对应内存中的同一个地址。当你移动时,只需要更新新进入视野的边界区域,中间的数据保持不变。就像用滚动窗口看长文档:窗口移动时,只需要加载新进入的内容,已经显示的内容不需要移动。
用于不透明度的体素化
每个体素不是纯黑或纯白(能透光或不能透光),而是有不透明度(Opacity)。因为体素是一个大方格(如1米×1米),把一个mesh放进去,可能光透了55%,挡住了45%。需要计算每个体素在各个方向上的不透明度。
想象一个1米×1米×1米的透明方块,里面放了一根细铁丝。从正面看,铁丝可能只占方块面积的10%,所以不透明度是10%,90%的光能透过去。但从侧面看,铁丝可能占50%,不透明度是50%。从不同方向看,同一个体素的不透明度不同,就像透过百叶窗看东西,角度不同,遮挡程度也不同。
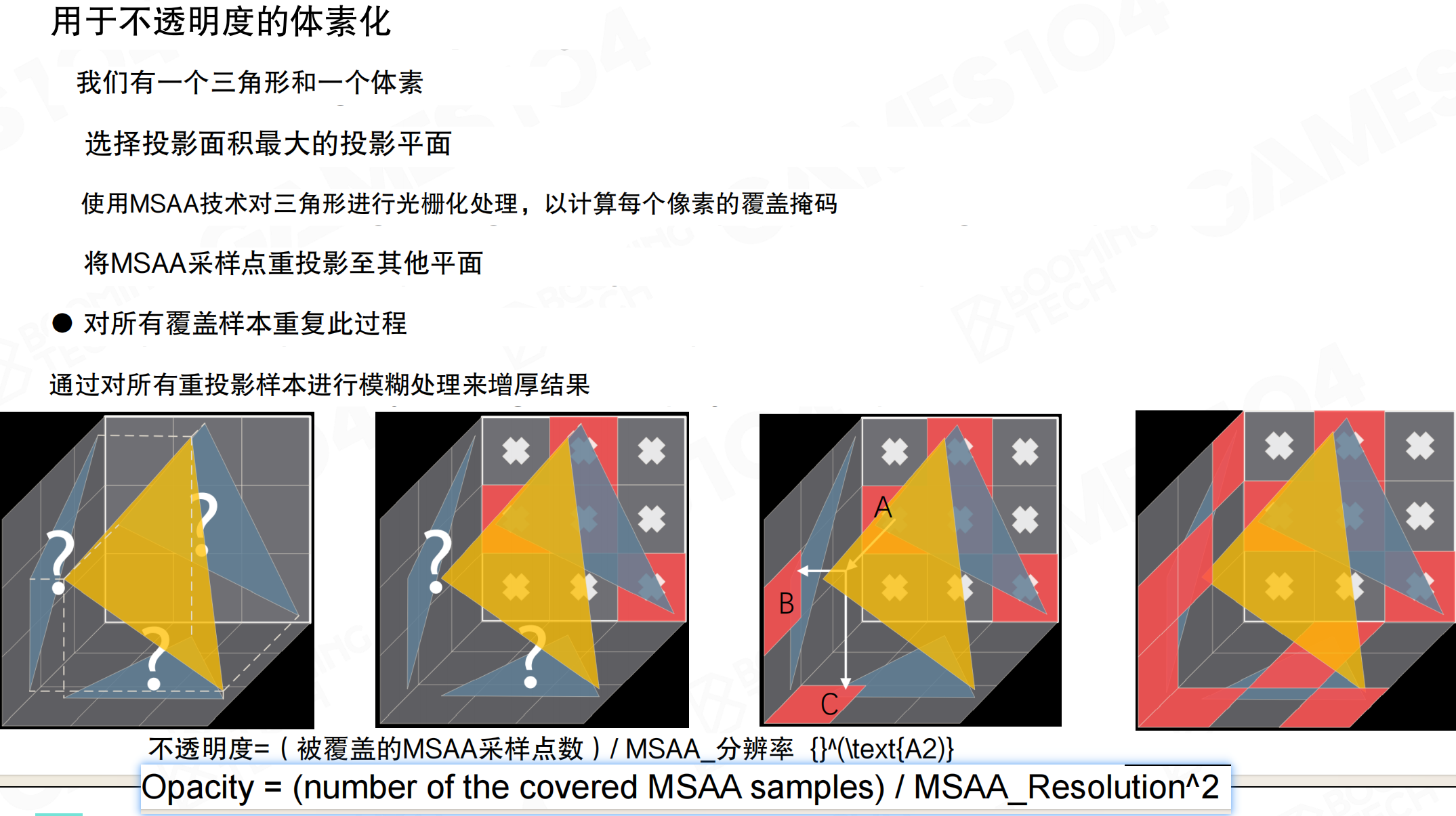
体素化不透明度的步骤:1. 有一个三角形和一个体素;2. 选择投影面积最大的投影平面;3. 使用MSAA技术对三角形进行光栅化处理,计算每个像素的覆盖掩码;4. 将MSAA采样点重投影至其他平面;5. 对所有覆盖样本重复此过程;6. 通过对所有重投影样本进行模糊处理来增厚结果。
不透明度计算公式:Opacity = (被覆盖的MSAA采样点数) / MSAA_分辨率²。注意不透明度的计算比较复杂,每个方向(三个方向)都要算一遍。从左右看可能透了30%,从上下看透了70%,从前后看可能透了50%,因为三维空间的形体在不同方向上的遮挡不同。

体素化:方向性覆盖。场景被体素化后,可以看到很多半透明的或灰色的取值,表示体素在不同方向上的不透明度。红色轮廓表示被覆盖的体素,灰色表示部分透明的体素。
光照注入
当来自光源的光线注入到场景中时,需要记录每个体素表面上接收到的直接光照。

计算包含受直接光照亮表面的体素的发射率,从反射阴影贴图(RSM)中获取信息。从光源位置渲染RSM,得到所有被直接照亮的表面。这些表面的体素会收集其辐射亮度(radiance),作为间接光源。图中可以看到只有部分体素被点亮,这些是接收到直接光照的体素,其他体素被阴影遮挡。
基于锥体追踪的着色
对于屏幕上的像素,通过锥体追踪(Cone Tracing)方式计算间接光照。
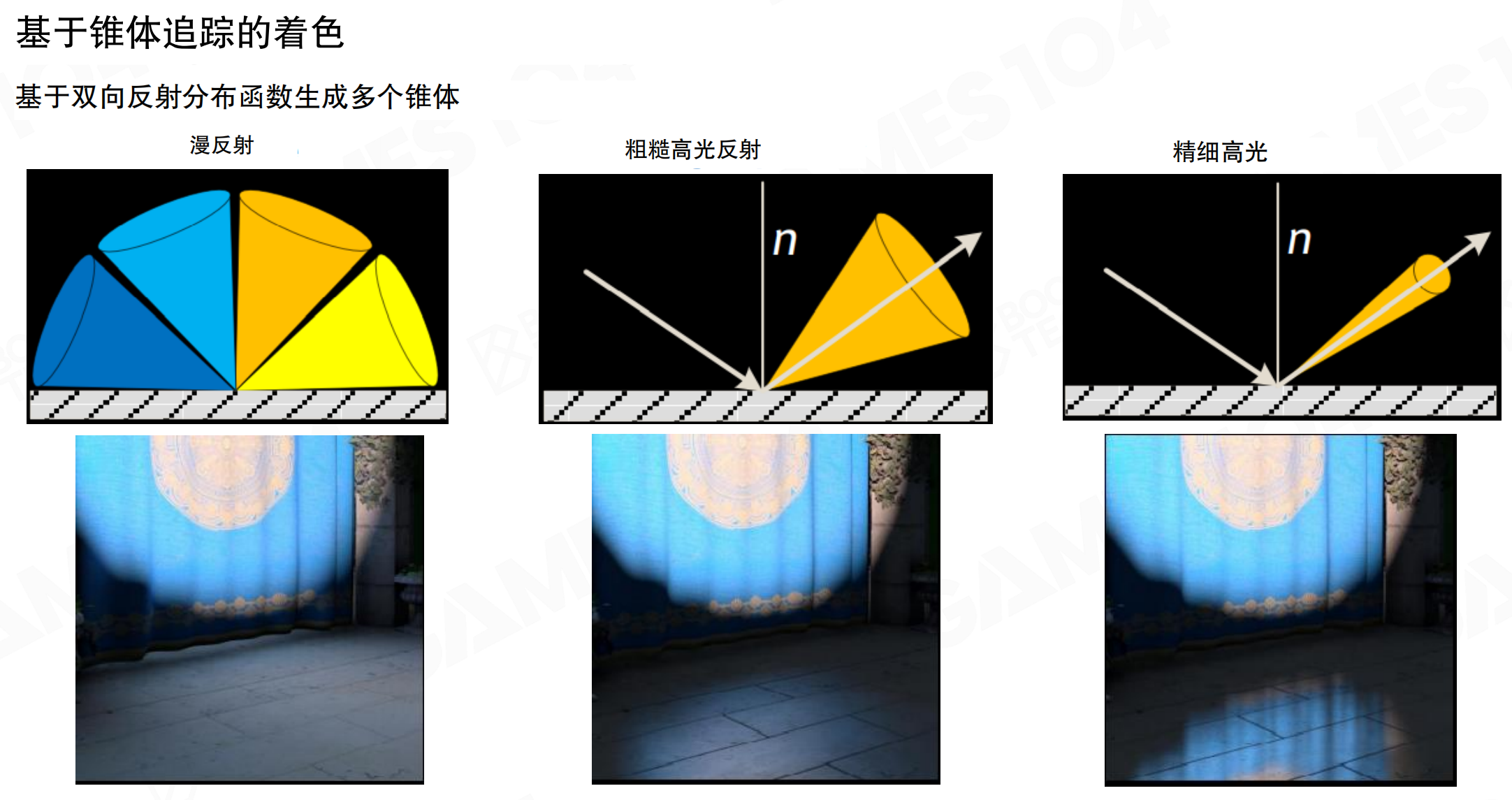
基于双向反射分布函数(BRDF)生成多个锥体。对于非常漫反射的表面,沿着法线为主轴,向四面八方扫一扫。对于粗糙高光反射的表面,沿着反射方向采样,锥体较宽。对于精细高光(非常光滑的表面),不仅沿着反射方向采样,还把锥体变得非常细,这样能穿透过去。从渲染结果可以看出:漫反射时,光照非常柔和均匀;粗糙高光时,有模糊的高光但反射不清晰;精细高光时,有清晰锐利的反射,地板上能看到清晰的窗帘图案反射。
沿路径累积体素辐射度与不透明度
锥体追踪不是简单的”打到体素就停止”,而是沿路径累积辐射度和不透明度。
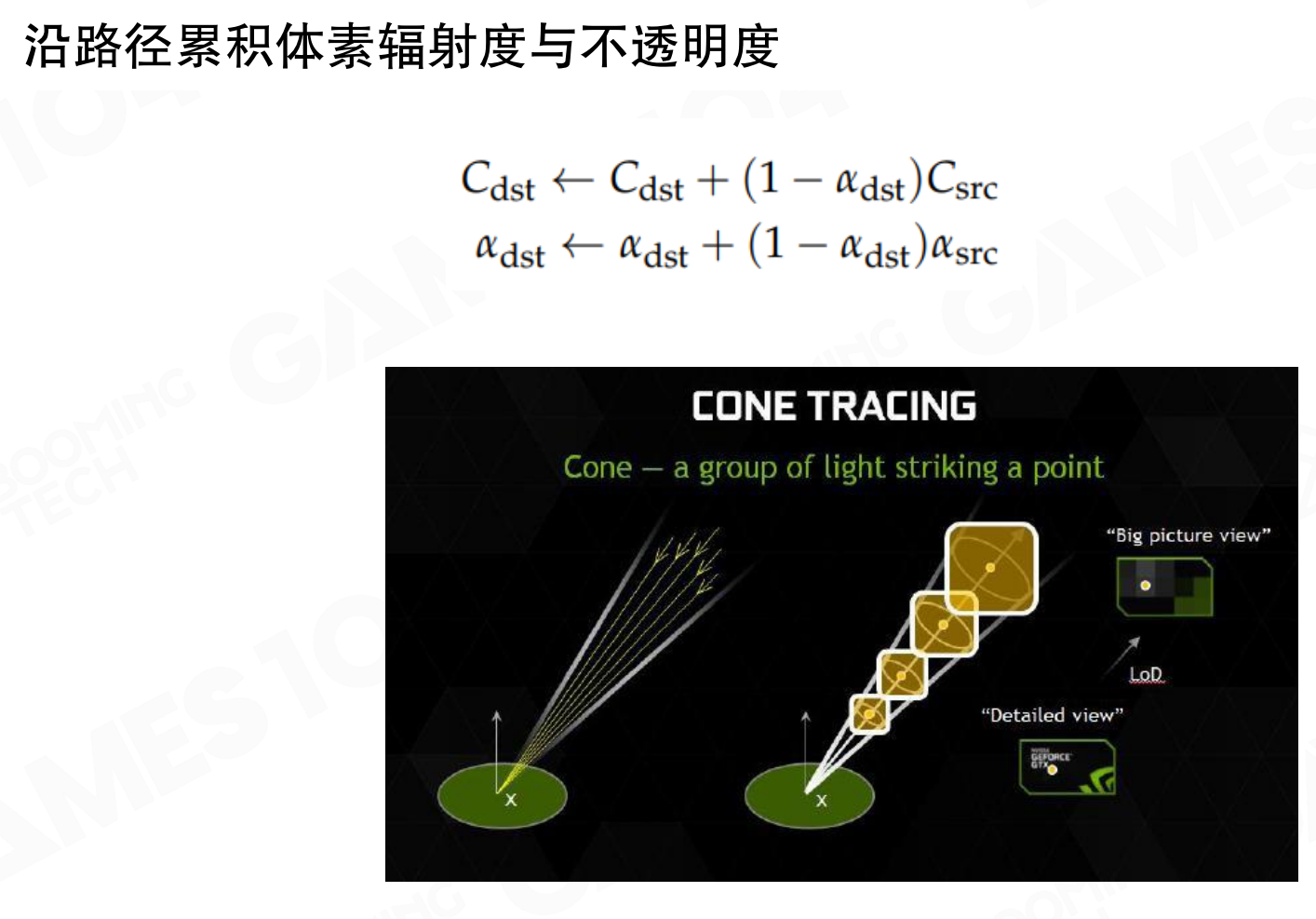
沿路径累积体素辐射度与不透明度的公式:
Cdst ← Cdst + (1 - αdst)Csrcαdst ← αdst + (1 - αdst)αsrc
这类似于透明物体绘制的alpha混合。锥体追踪时,沿着体素一路向上,每个体素反射出来的辐射亮度被累积,同时不透明度也被累积。当不透明度接近1时(几乎不透明),就不再往后走,因为后面的光已经无法透过来。这样可以让算法更快。
由于Clipmap是分层的,随着距离增加,锥体展开,会扫到越来越大颗粒的体素。在Clipmap的不同层可以模拟锥体展开的结果:越往上走,面积越大时,取Clipmap里面更高的mip层级的体素,一次性覆盖很大的区域。这些体素的alpha会不断变低,直到满足阈值。
VXGI存在的问题
VXGI的主要缺陷在于锥体追踪的结构仍然是对间接光照的一种近似,而且非常容易出现漏光(Light Leakage)问题。

错误遮挡(不透明度)的问题:简单地通过alpha混合将不透明度进行结合,会导致光线泄露。当遮挡墙远小于体素尺寸时,问题更严重。例如,三角形在体素里只挡了部分alpha,黄色方块也挡了部分alpha,如果按照乘法累积,alpha肯定不为零。但在实际光路上,如果想象那是个平面,光已经彻底被后面的体素阻挡了,但算法无法有效检测,导致光漏过去。
特别是对于很薄的物体,它已经小于最细的体素,或者距离比较远只能用稀疏的粗体素表达时,光都会被漏过去。这是所有实时GI算法,特别是早期算法都会遇到的问题,是实时全局光照的”一生之敌”。
漏光问题就像用粗网格筛沙子。想象一个1米×1米的网格,里面有一张只有1厘米厚的纸。从网格的角度看,纸只占了网格的1%,所以认为99%的光能透过去。但实际上,如果纸正好在光路上,应该完全挡住光。就像用渔网捕鱼,网眼太大,小鱼都漏过去了。体素太大,薄物体就”漏”过去了,导致光从不应该透光的地方透过来,产生漏光artifact。
小结
VXGI使用Clipmap数据结构,实现了视距相关的体素密度分布,比SVOGI的稀疏八叉树更GPU友好。通过环形寻址,相机运动时只需更新边界数据。使用不透明度表示体素的遮挡,从RSM注入光照,通过锥体追踪计算间接光照,沿路径累积辐射度和不透明度。VXGI是对SVOGI的取代性改进,但仍有漏光问题,这是实时GI算法的共同挑战。
21.5 屏幕空间全局光照 SSGI
前面介绍的方法都是基于体素的GI技术,使用RSM把光子注入场景,然后用体素收集这些光。另一条思路是屏幕空间全局光照(Screen Space Global Illumination, SSGI),最早由寒霜引擎(Frostbite)在2015年GDC上提出。
SSGI的核心思想简单:屏幕空间已渲染的像素可作为小光源使用。对于镜面表面,在屏幕空间反射即可使用这些数据。SSGI基于这一思路:发射多根光线,将渲染好的像素点作为全局光的小光源。
就像照镜子。你站在镜子前,镜子里已经渲染好了你的影像。SSGI把镜子里每个像素都当作一个小灯泡,用它们来照亮其他物体。不需要重新计算整个场景,只需要在已经渲染好的屏幕上”借光”。就像在房间里,已经点亮的灯可以照亮其他东西,不需要重新点灯。屏幕空间已经渲染好的像素就是这些”已经点亮的灯”。

总体思路:复用屏幕空间数据。在现代GPU渲染管线中,可以快速渲染出屏幕空间上的各种物理量(深度、法线、颜色等)。通过重用这些屏幕空间数据就可以实现GI,无需额外的体素化或复杂数据结构。
屏幕空间辐射度采样
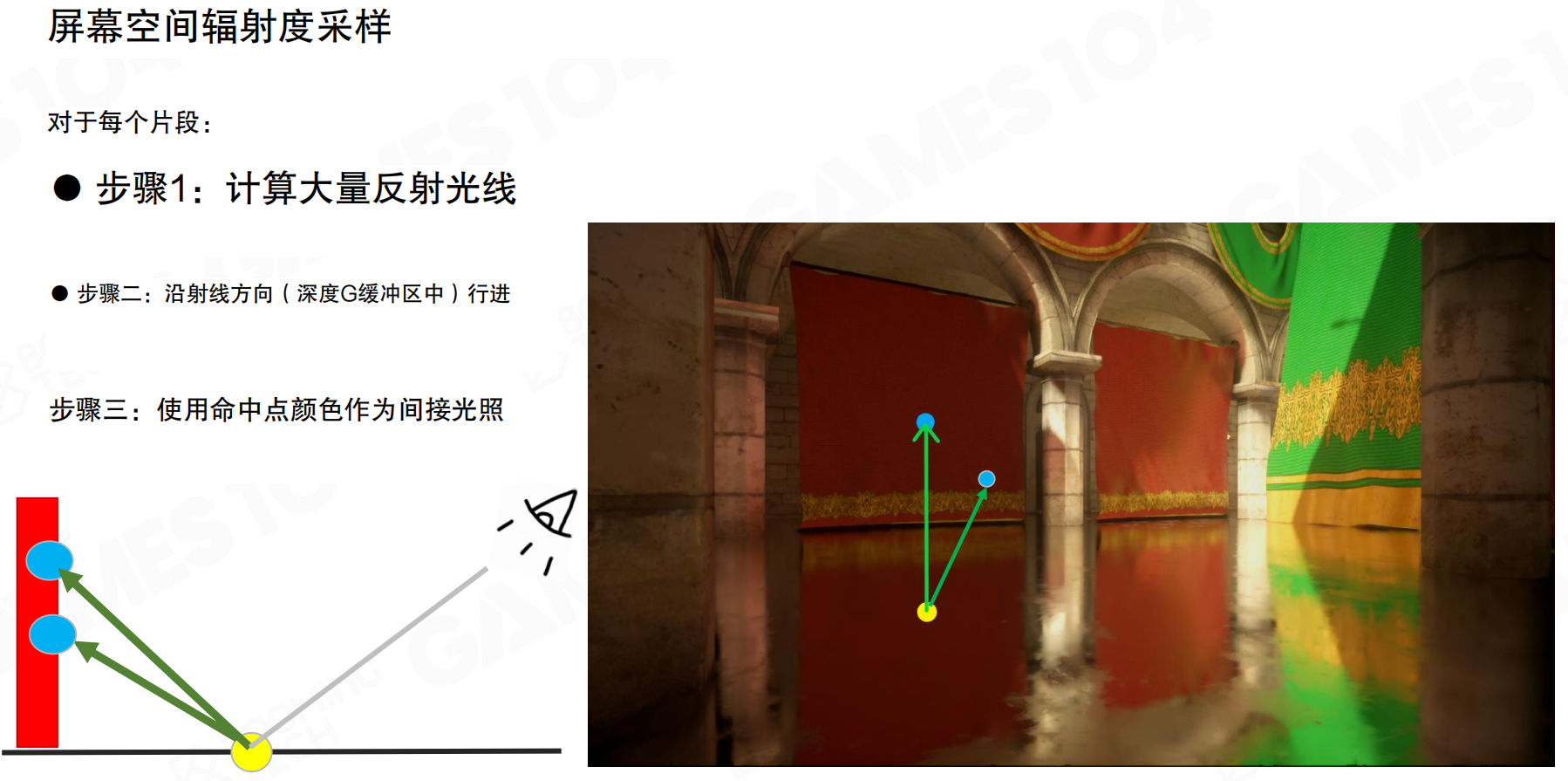
屏幕空间辐射度采样(Screen Space Radiosity Sampling)的步骤:对于每个片段,步骤1:计算大量反射光线。根据法线和相机方向,沿着法线、沿着相机反方向发散地发射一些光线。步骤2:沿射线方向在深度G缓冲区中行进。这些光线在屏幕空间里寻找空间上位置正确的点。步骤3:使用命中点颜色作为间接光照。如果那个点是亮的,就成为一个光源;如果那个点是红色,就获得红色辐射;如果是绿色,就获得绿色辐射。这样可以直接用屏幕空间的数据进行间接光照计算。
线性光线步进
在屏幕空间进行光线追踪的最简单方法是线性光线步进(Linear Ray Marching)。
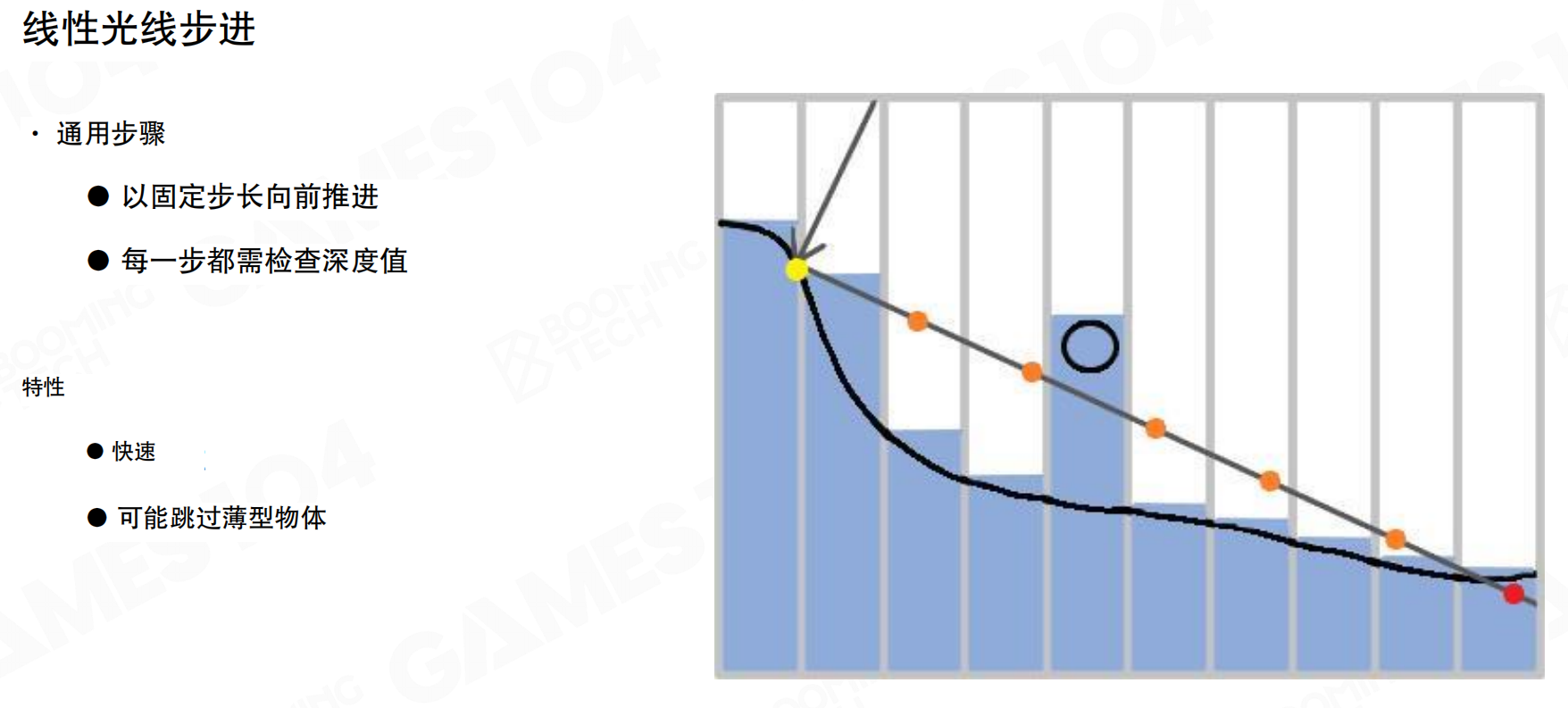
通用步骤:以固定步长向前推进,每一步都需检查深度值。从起点出发,沿着光线方向以固定间隔前进。每走一步,检查当前点的深度值。如果找到一点,其深度比当前深度更靠前,说明被挡住了,认为找到了交点。
线性光线步进的特点是快速,但可能跳过薄型物体。如果步长太大,可能从薄物体上方或下方直接跨过去,导致漏检。因此要求间距特别密,计算量较大。
层次化追踪
为了提升效率,SSGI使用层次化追踪(Hierarchical Tracing),基于最小深度Mipmap(Minimum Depth Mipmap)进行无堆栈光线步进。


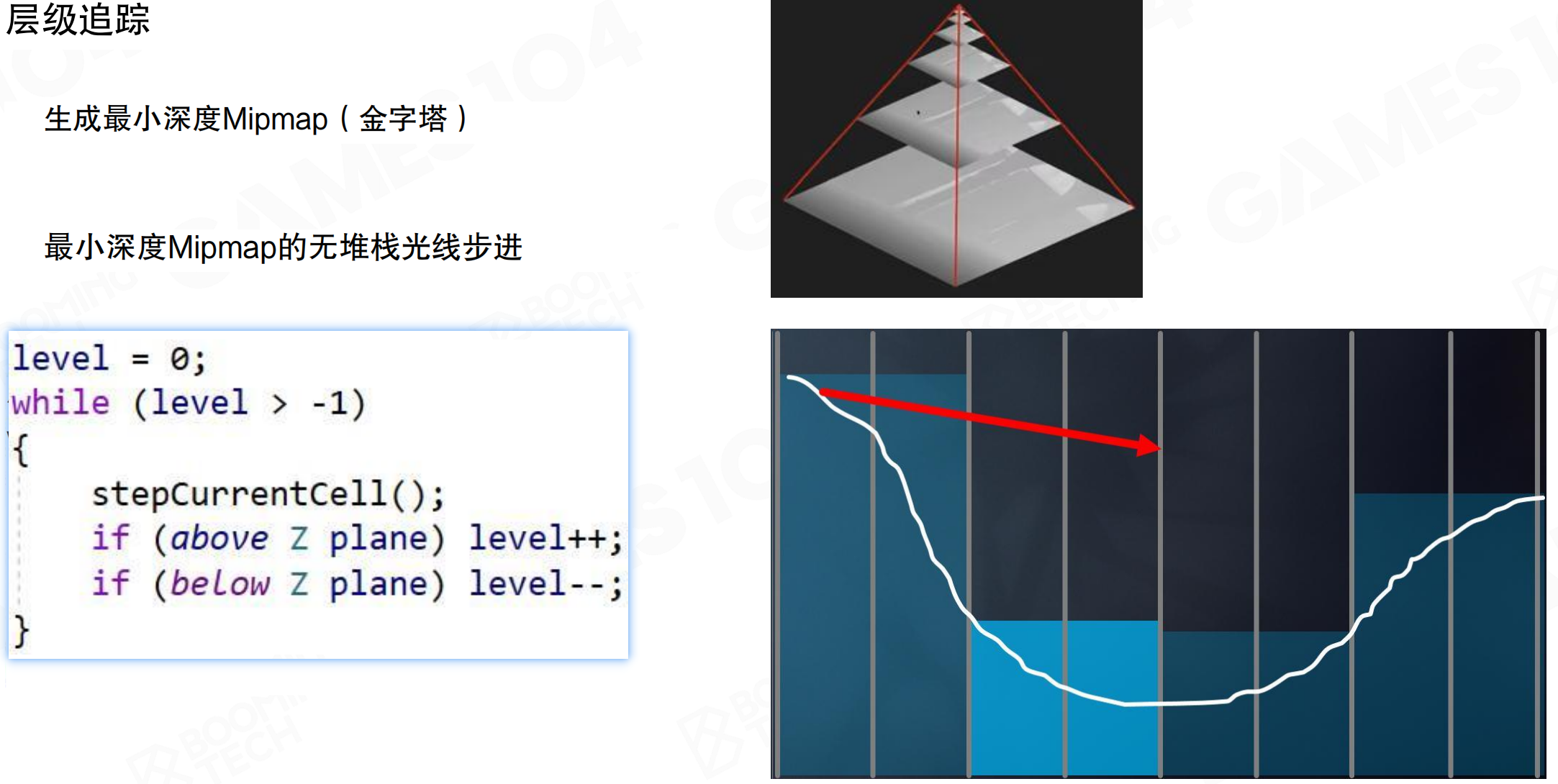
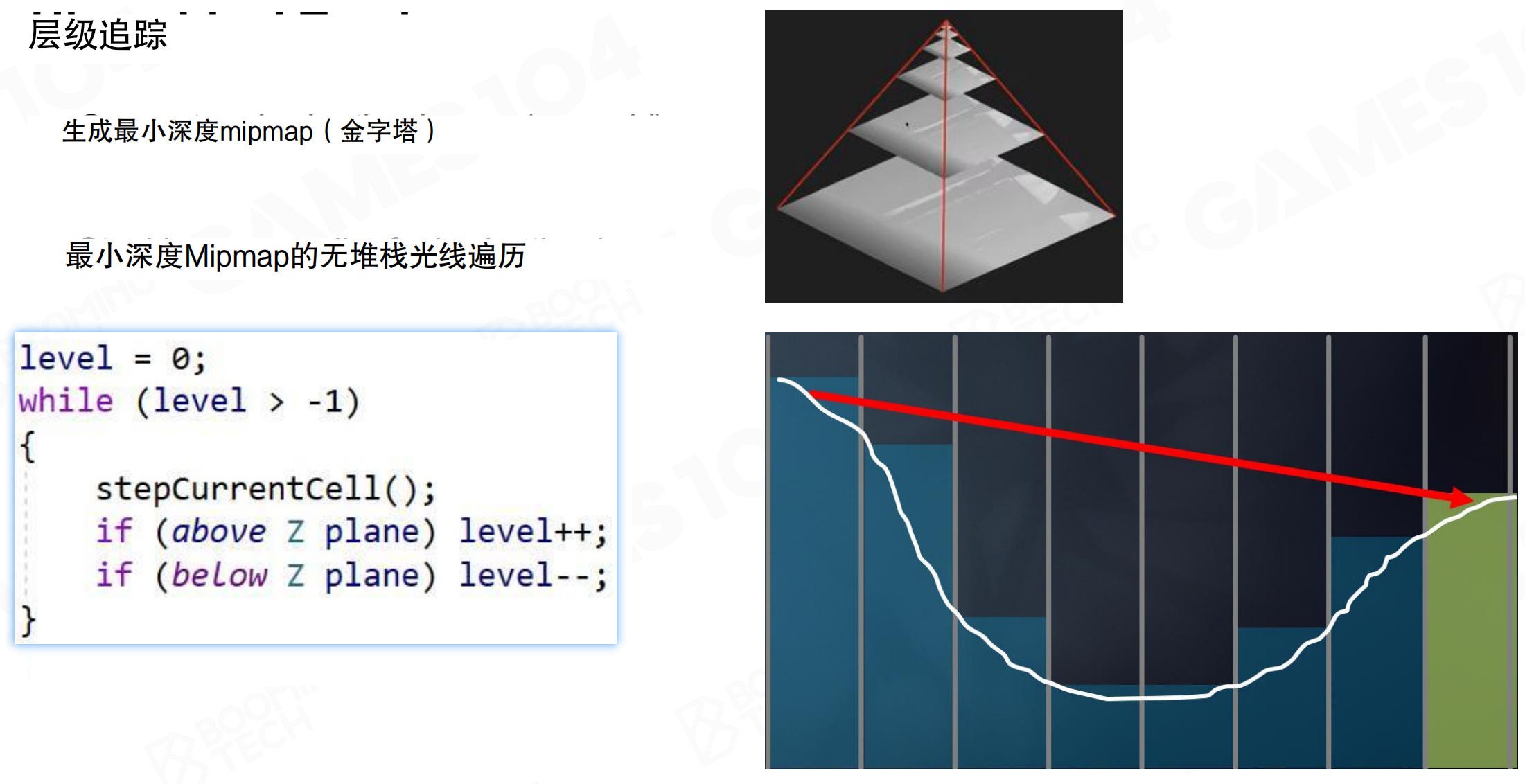
生成最小深度Mipmap(金字塔)。GPU提供了Hi-Z(Hierarchical Z-Buffer)算法,在DX12中API已支持。渲染时得到Z-Buffer,会自动做成一层层的Mipmap。每一层Mipmap中的点,对应下一层的四个点,在这四个点的depth中选取最小值(离相机最近的值,最突出的点)。可以认为:如果一个光线与某一层Mipmap不相交,那一定不与更细的几何相交;但如果相交了,有概率与更细的某个几何相交。这实际上把Z-Buffer做成了层次结构,每一层的Z都是下一层Z的bounding box。
Hi-Z就像用不同精度的地图找路。最底层是详细地图,每个像素都有精确的深度;往上一层是简化地图,四个像素合并成一个,取最近的那个深度;再往上是更简化的地图。当你用光线追踪时,先用粗糙地图快速判断:如果光线连粗糙地图都碰不到,那肯定碰不到详细地图。如果碰到了粗糙地图,再往下查详细地图。就像用望远镜找目标:先用低倍镜快速扫描,找到大致方向,再用高倍镜精确瞄准。这样大大减少了需要检查的深度值数量。
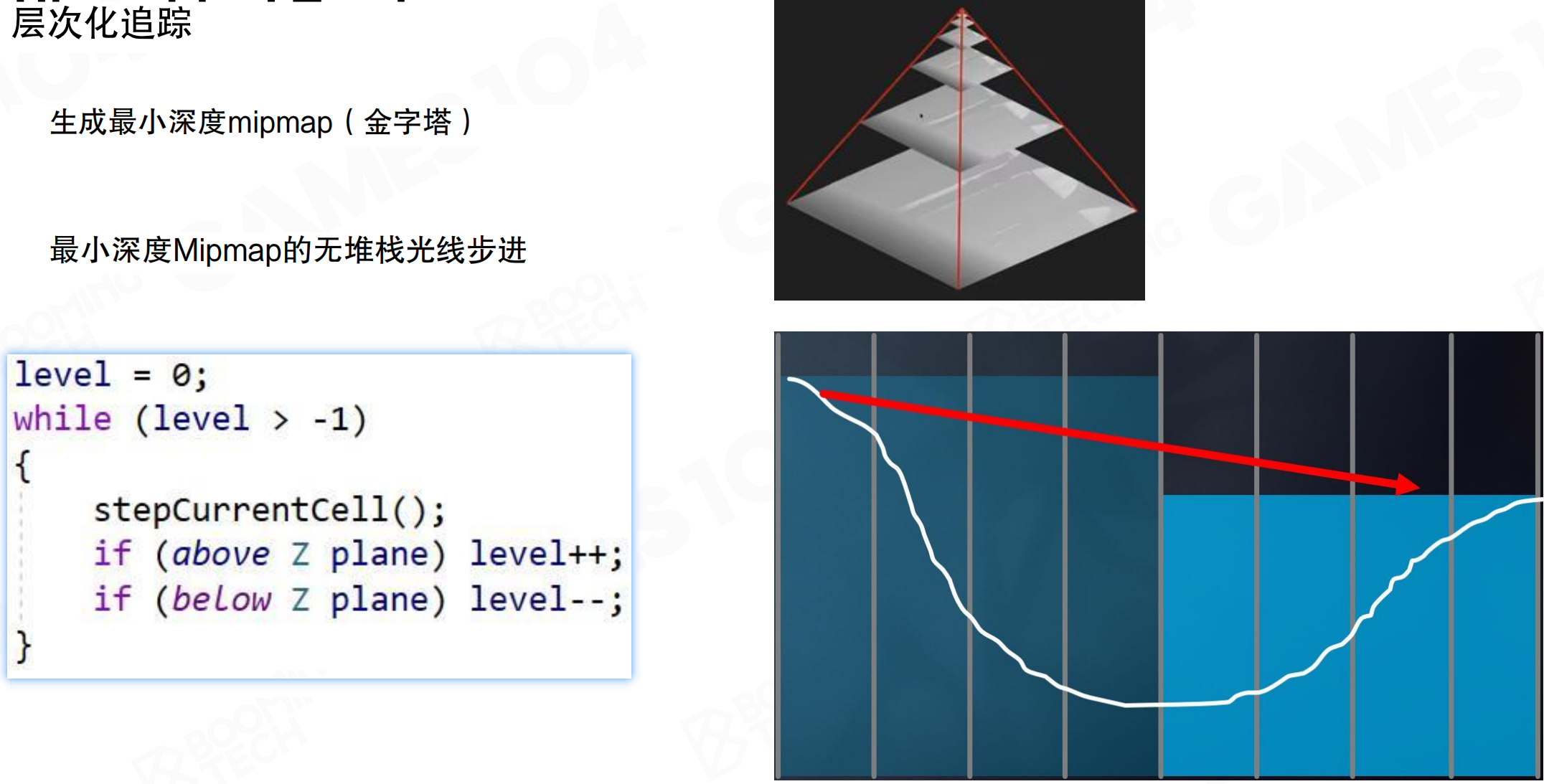
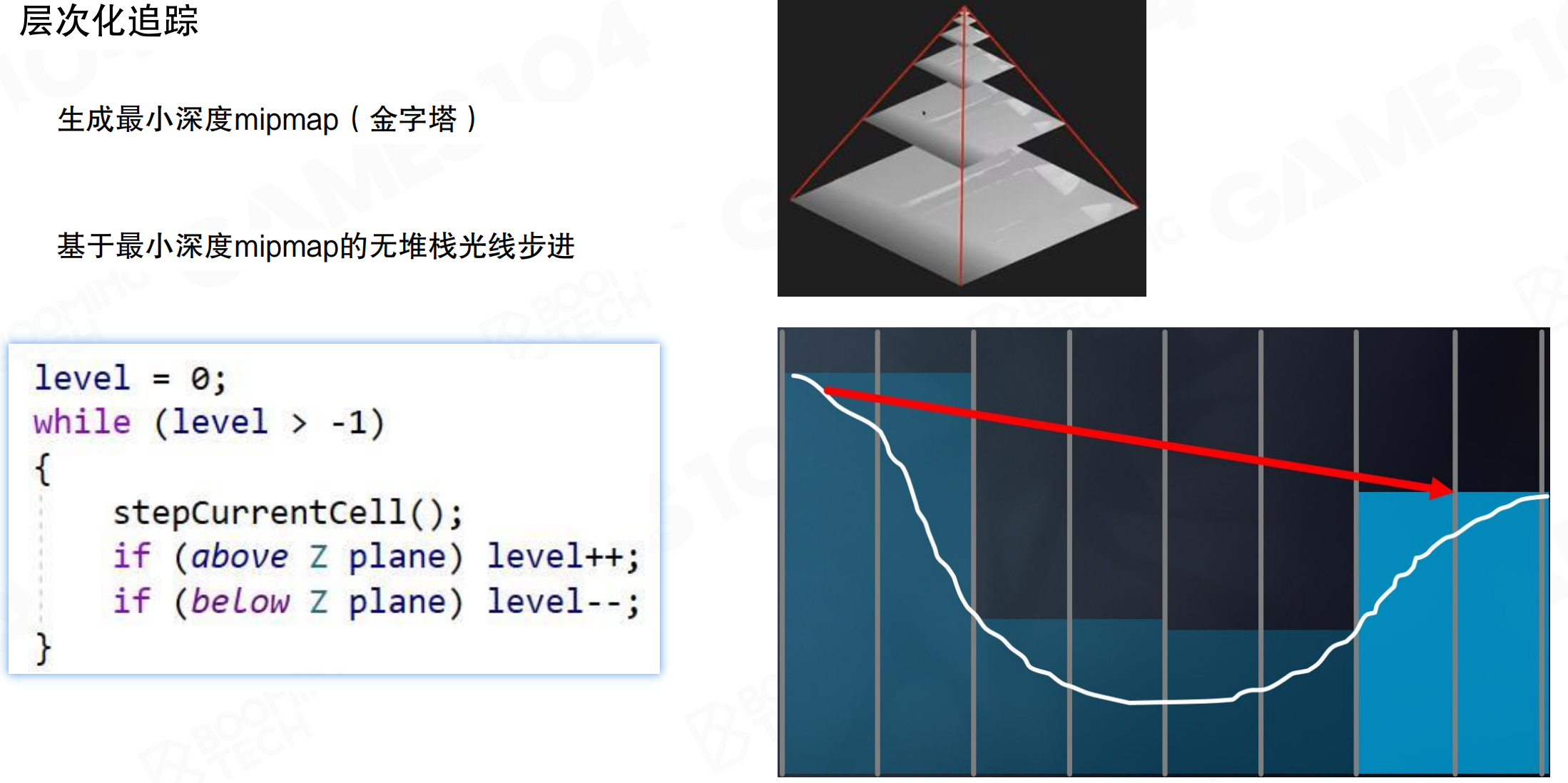
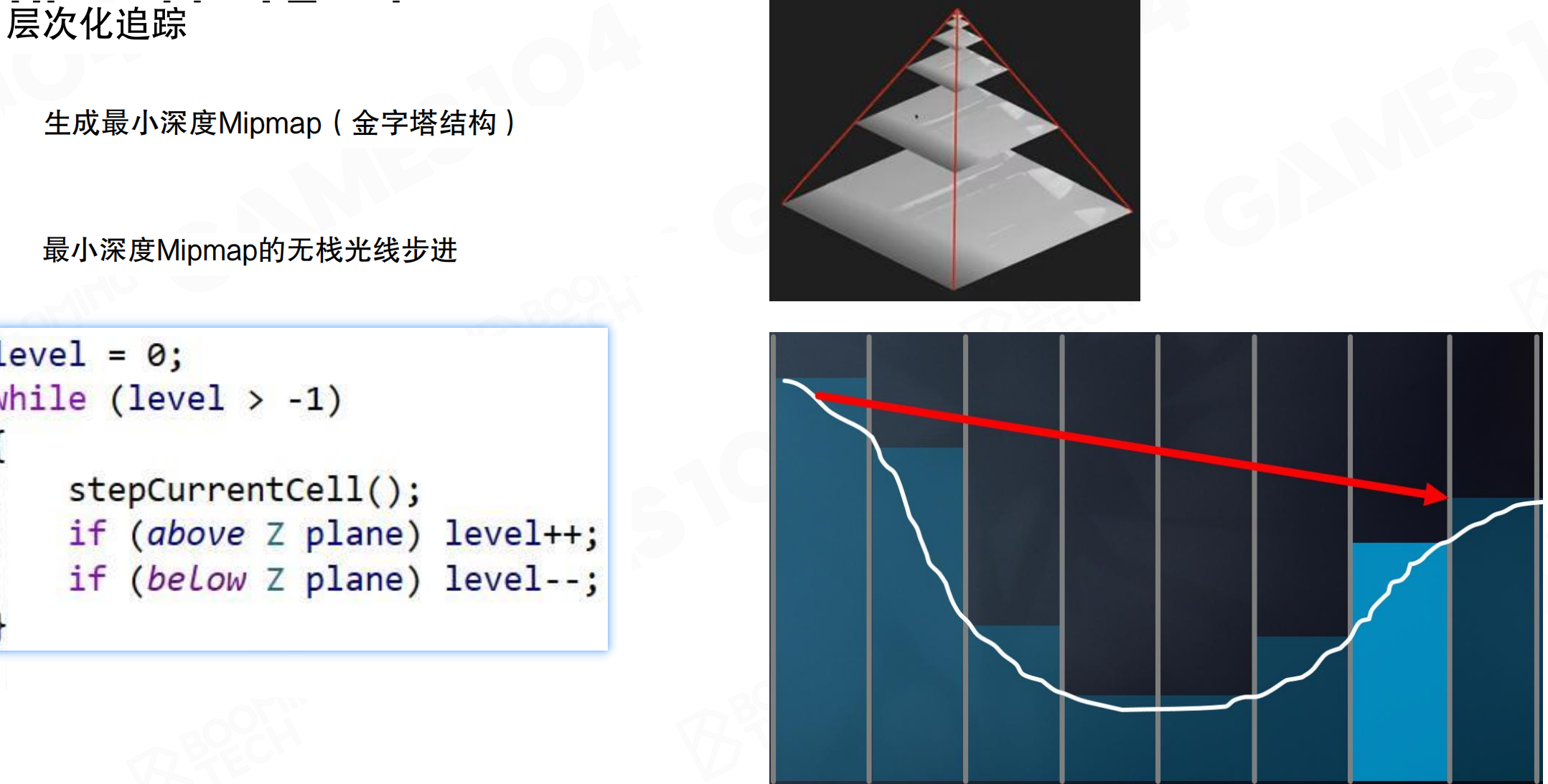
最小深度Mipmap的无堆栈光线步进算法:
level = 0;
while (level > -1)
{
stepCurrentCell();
if (above Z plane) level++;
if (below Z plane) level--;
}
先往外走一格,发现没有交点,就往Hi-Z那一层往上跑一层,做一次testing相当于走了两格。如果还没有交点,胆子更大,在Mipmap再往上走一层,做一次testing相当于走了四格。如果发现hit了something,知道可能交到了Mip 1或Mip 0的某个点,但不知道是哪个点。把光线往回退,退到Mip 1上,如果跟Mip 1的东西有交点,再往下走回到Mip 0,找到精确的交点。
这种方法采样更复杂,但对整个屏幕空间深度做了hierarchy后,每次ray casting的复杂度是O(log n)。对于1024或更高分辨率,通常十几步即可完成。使用uniform ray marching可能需要五六十步。可以在短时间内跨越很大距离。在屏幕空间做AO或其他需要ray marching testing时,Hi-Z比uniform采样更高效。
相邻像素之间的光线复用
为了进一步提升效率,SSGI对每个像素重复使用其相邻像素采样的间接光照。

相邻像素之间的光线复用(Ray reuse between adjacent pixels):存储命中点数据,假设邻近体素之间的可见性相同,将射向邻近命中点的光线视为有效。如果相邻的pixel对空间进行了几次采样,用Hi-Z方法求出了采样点。在离他很近的位置也要进行球面采样时,这个采样点能不能重用?如果不考虑visibility(不考虑光线到这儿被遮挡的关系),它采到了一个小灯泡,实际上也是你的小灯泡。相当于帮你也做了一次采样,所以这个light可以被reuse。
这个思想很关键。在实时GI中,不可能对每个采样点位置设置那么多光线,否则计算量过大。在相邻空间时,直接重用光线:向某个方向发射光线,得到5米外的一个点及其xyz位置。如果该点与当前点之间没有遮挡,该点散射出的radiance可以直接使用。虽然角度不同,强度会有差异(如漫反射),但空间上的颜色和位置可以直接使用。这个reuse思想在几乎所有实时GI中都有应用,在temporal上也可以重用。
就像邻居之间共享信息。你隔壁的邻居往某个方向看,发现5米外有个红墙。如果你也在看类似的方向,而且你们之间没有遮挡,那这个红墙的信息你也可以用,不需要重新看一遍。就像几个人一起找东西,一个人找到了,其他人如果位置相近,可以直接用这个信息,不用重复找。这样大大减少了需要发射的光线数量。
基于Mipmap滤波的圆锥追踪
对于粗糙表面,SSGI使用基于Mipmap滤波的圆锥追踪(Cone Tracing based on Mipmap Filtering)。

估算圆锥体在命中点的足迹,考虑粗糙度和命中距离。对颜色Mipmap进行采样,Mip层级由覆盖范围决定。使用预过滤颜色Mipmap(金字塔),通过模糊和降采样生成不同层级。随着距离增加,锥体展开,会扫到更大区域,使用更高层级的Mipmap。这样相当于对整个光照进行了一次filtering,能更好地处理不同粗糙度的表面。
SSGI技术总结

优点:适用于光泽和镜面反射的快速处理,优良画质,无遮挡问题(在屏幕空间内)。
缺点:屏幕外信息缺失,无法处理屏幕空间之外的物体,容易导致各种错误的渲染结果。例如,浮在空中的cube,地上有个偏镜面的东西,cube下面的底面应该是偏黑的,但因为那个像素点没有,所以反射的数据就拿不到。类似的artifact在SSGI里蛮多的。
SSGI的独特优势

尽管有缺点,SSGI有几个优势:
易于处理近距离接触阴影:使用Hi-Z Buffer进行ray marching,Hi-Z精度高。两个物体的交界面,几个pixel的误差都能计算出来,contact shadow处理效果好。基于体素的方法在这方面表现较差。
精确命中点计算:Hi-Z方法计算精度高,比用体素近似更准确。
与场景复杂度解耦:无论场景多复杂,使用什么技术,是否有动态物体,对SSGI都无关。对SSGI而言,就是一张带深度和亮度的图,所有计算都基于这张图。实际上对场景复杂度无感。
处理动态对象:能够处理动态物体,因为每帧都重新渲染屏幕空间数据。
这些属性很关键。这就是为什么在复杂的Lumen架构中,SSGI仍然有用。SSGI是处理specular reflection的有效方法,质量好,能补充细节。虽然有很多artifact,但这些artifact在Lumen中基本都解决了。
小结
SSGI复用屏幕空间数据,利用已渲染的像素作为间接光源。使用Hi-Z层次化追踪实现O(log n)复杂度的光线步进,通过相邻像素光线复用减少采样数量,使用基于Mipmap滤波的圆锥追踪处理粗糙表面。SSGI对场景复杂度无感,能处理动态对象,精确计算接触阴影,特别适合处理光泽和镜面反射。主要缺点是屏幕外信息缺失,导致各种artifact,但这些问题在Lumen中得到了解决。
21.6 Lumen:概述
Lumen是虚幻5引擎的实时GI方案。实时光线追踪也能做GI,但依赖硬件加速,而且采样成本高。Lumen不依赖硬件实现,能在更多平台上跑起来。
理解Lumen之前,需要先了解前面那些GI算法。Lumen是这些技术的集大成者,整合了RSM、LPV、SVOGI、VXGI、SSGI的核心思路。系统复杂度高,细节很多。
光线追踪的速度瓶颈

实时光线追踪的速度是瓶颈。每像素只能负担1/2根光线,但高质量GI需要数百次采样。户外场景需要约100 rays per pixel,室内场景因多次反弹需要500+ rays per pixel。差距很大。
硬件支持也是问题。N卡勉强可用,A卡支持较差。主机虽然支持,但效果一般。即使硬件支持,用于GI成本过高。因此需要Lumen这样的方案。
采样问题的困境

采样一直是GI的痛点。离线算法和实时算法都在跟采样问题较劲。到了实时场景,采样数被压到极低,问题更明显。
辐照度场(Irradiance fields)的问题:漏光、过度遮蔽、探针布局麻烦、更新慢、画面偏平。
屏幕空间降噪器的问题:复杂室内场景噪点过多,噪声分布不均匀。从图中可见,明亮窗户附近噪点密集,远处窗口噪点稀疏但依然明显。靠近窗口时结果可用,虽然noisy但能filter。离窗子较远时,filter也无法解决,直接变成大色斑。这是所有GI算法第一版都会遇到的问题:画面黑一块白一块。
Lumen的核心思路

低分辨率滤波场景空间探针照亮全像素。Lumen的核心思路可以总结为三点:
不用硬件ray tracing:不依赖硬件加速,通用性更好。
优化采样策略:尽可能减少采样带来的噪点。
探针贴近表面:在screen space放置probe,紧贴要被照亮的表面,获取球面光照。稀疏采样(比如16x16像素一个probe)照亮几何,但每个像素独立着色。高频细节通过法线朝向等表面属性产生,最终效果比较逼真。
示意图展示了这个思路:低分辨率探针(左上,网格状分布)× 场景几何(左下,彩色几何数据)= 最终结果(右侧,洞穴场景)。探针在低分辨率下滤波采样,然后照亮全分辨率像素,兼顾效率和质量。
这是Lumen的核心思路。思路简单,但实现细节很多。它整合了前面各种算法的优点,形成了一套能在各种硬件上运行的实时GI系统。
21.7 Lumen:任何硬件中的快速光线追踪和有符号距离场SDF
Lumen的第一部分解决如何在任意硬件上进行快速光线追踪。无论用什么GI方法,都要解决一个核心问题:射出一根光线,能不能交到物体,交到的是谁。可以用硬件ray tracing,但如果没有硬件支持,或者硬件ray tracing太慢,就需要其他方案。Lumen使用了有符号距离场(Signed Distance Field, SDF)。
什么是SDF

有符号距离场(SDF)定义:每一点到最近表面的距离。内部区域存储带符号的负距离值,距离等于0处即为表面。如果点在物体外面,距离全是正的;到表面时距离变成0;在物体里面时,距离是反向的到表面的距离,即负数。
SDF是空间上形体的对偶表达。过去用mesh表达形体,好处是符合直觉,但它是离散的,点线面之间没有直接关系,需要通过index buffer关联。三角形之间的连接也不存在,必须通过共用顶点才能知道连接关系。做mesh处理时要写大量adjacency information,把点线面的连接关系全部找出来。
SDF从数学上是和表面等价的变换,但它是连续的、uniform的、空间上的一个场。连续意味着可微,可微就能做很多事。SDF是uniform表达,可以表达无限精度的mesh,既能得到面积,又能快速求交,还能迅速求出连续的法线方向(通过求梯度)。这是SDF的优势。
想象一个球体。用mesh表示,需要很多三角形拼接。但用SDF表示,空间中的每个点都知道”我离球面还有多远”。在球外面,距离是正的(比如5米);在球面上,距离是0;在球里面,距离是负的(比如-2米,表示在球内2米深)。就像用等高线地图:每个点都知道自己离海平面多高。SDF的优势是连续且均匀:无论在哪里,都能快速知道到表面的距离,不需要查找三角形、计算交点等复杂操作。就像GPS:每个位置都知道自己到目的地的距离,不需要沿着道路一步步走。
每网格SDF
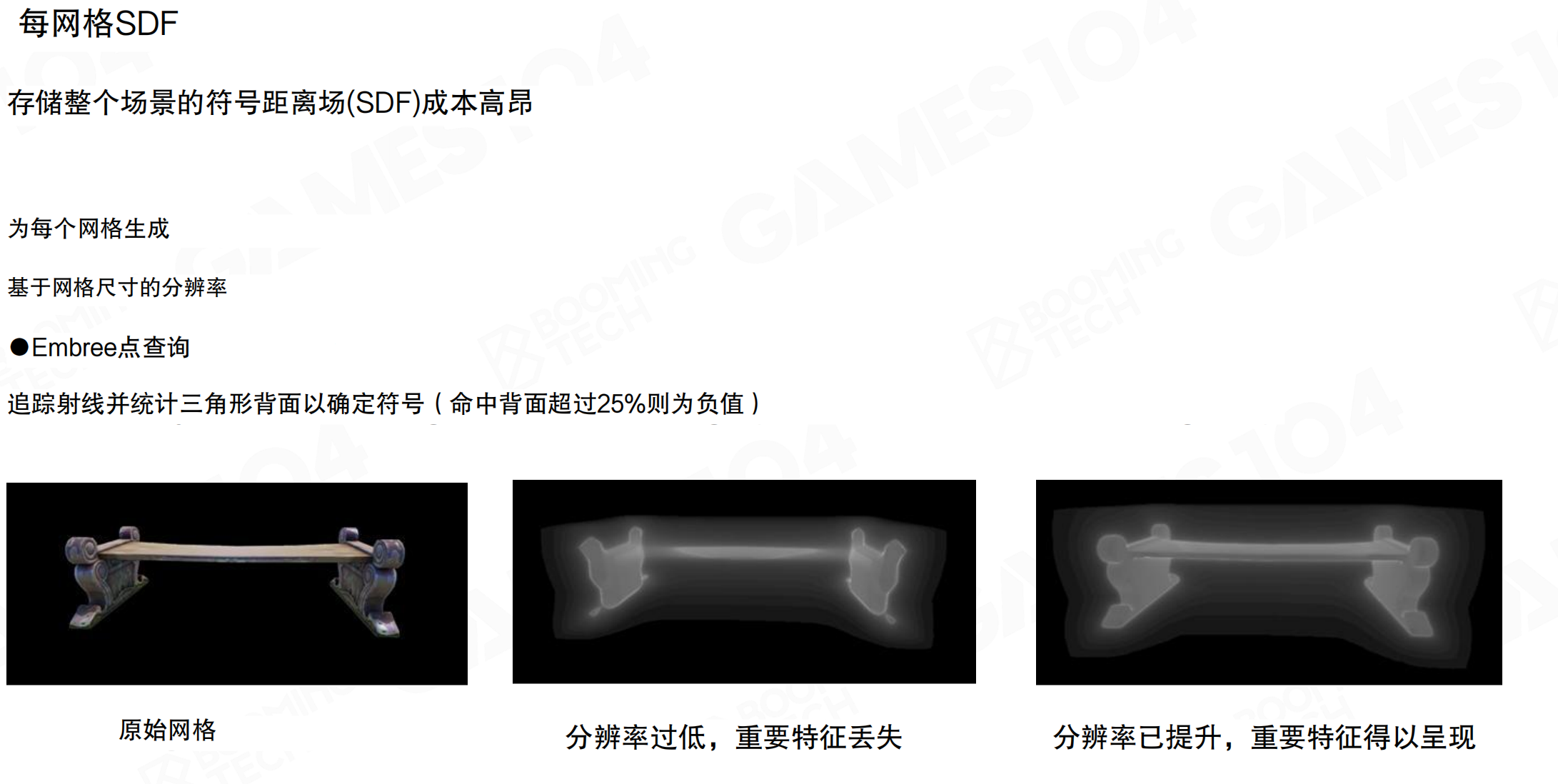
存储整个场景的SDF成本高昂。为每个网格生成SDF,基于网格尺寸的分辨率。使用Embree点查询,追踪射线并统计三角形背面以确定符号(命中背面超过25%则为负值)。
分辨率很重要。分辨率过低,重要特征丢失;分辨率提升后,重要特征得以呈现。从图中可以看到,低分辨率时椅子腿的细节丢失,高分辨率时细节清晰可见。
用于薄网格的SDF
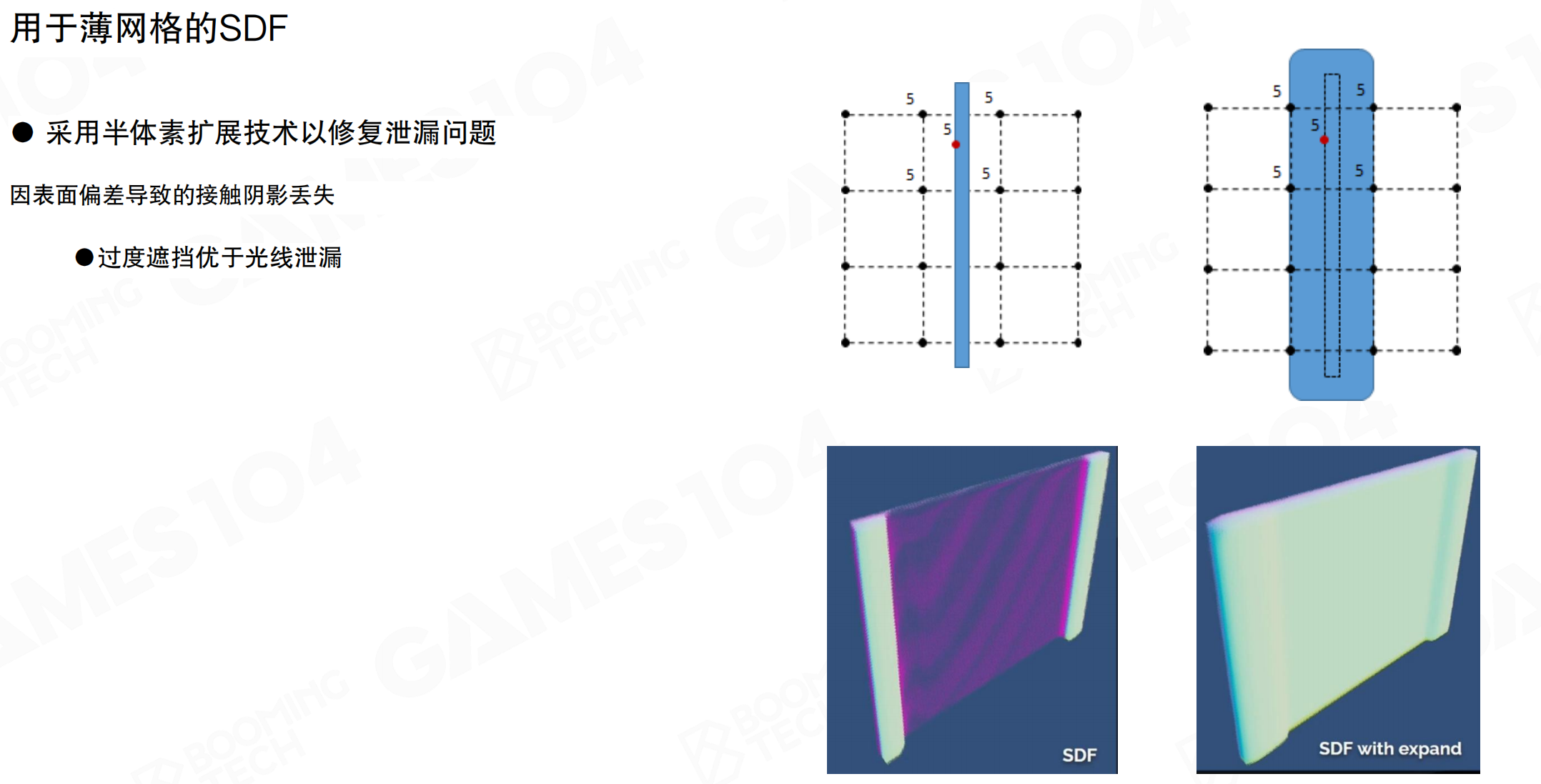
对于特别细的mesh,SDF表达有困难。如果已经跨过了最小的两个体素之间的距离,因为是对空间进行点采样,两边的面distance值都是正值,没有负值,就检测不到面的存在。
用于薄网格的SDF:采用半体素扩展技术修复泄漏问题。因表面偏差导致的接触阴影丢失,过度遮挡优于光线泄漏。从图中可以看到,扩展后薄物体变厚,虽然会过度遮挡,但避免了光线泄漏,这在工程上是可接受的。
基于SDF的射线追踪
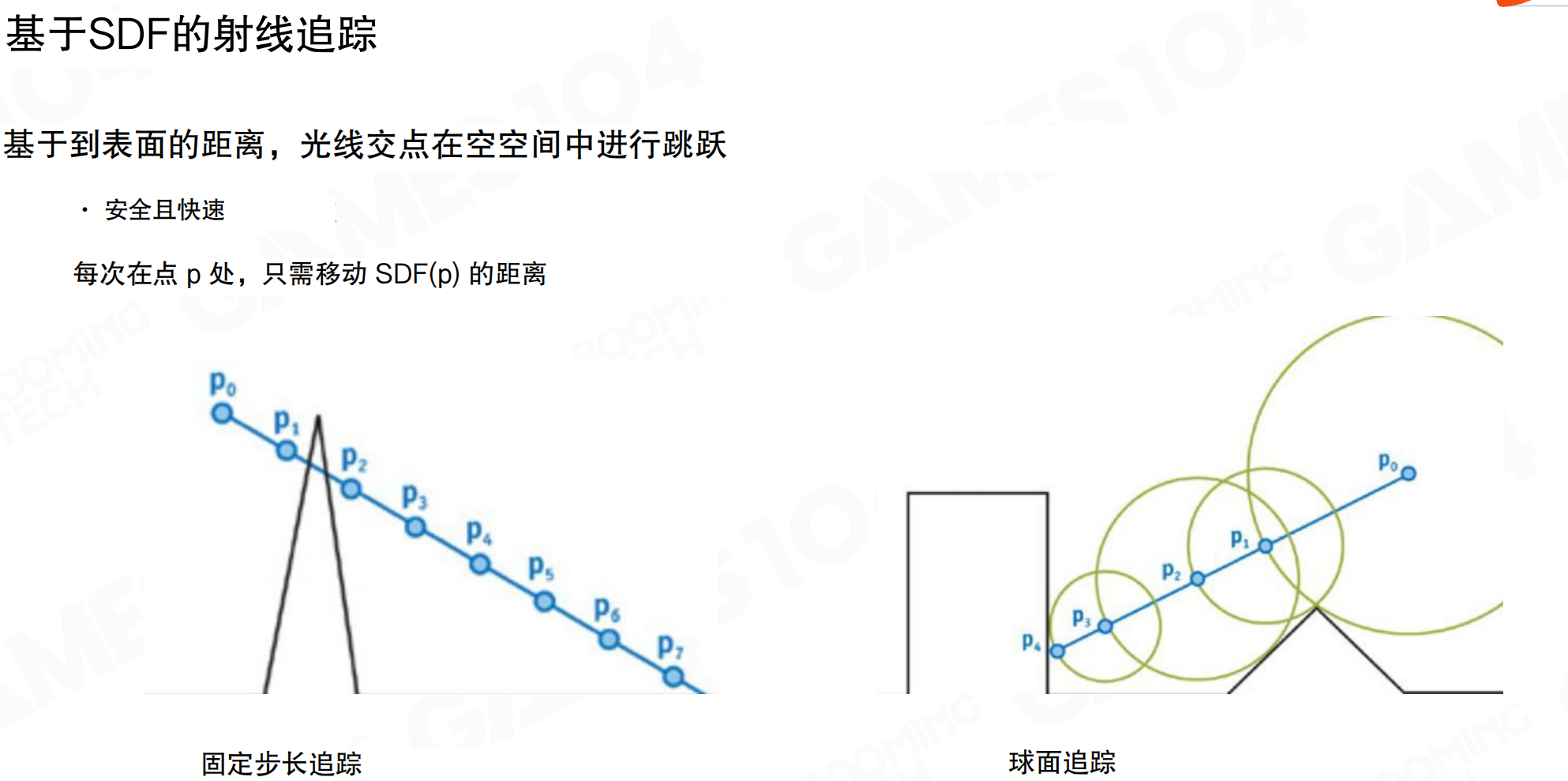
基于SDF的射线追踪:基于到表面的距离,光线交点在空间中跳跃。安全且快速。每次在点p处,只需移动SDF(p)的距离。
固定步长追踪:以固定步长向前推进,每一步都需检查深度值。可能跳过薄型物体。如果步长太大,可能从薄物体上方或下方直接跨过去。
球面追踪(Sphere Tracing):在点p处,SDF(p)是到最近表面的距离,可以画一个半径为SDF(p)的球。这个球保证不会与任何表面相交,所以可以安全地跳到球的边缘。随着接近表面,步长越来越小,最终收敛到交点。即使步子大了一点穿进去了,因为SDF有符号,负数告诉你表面在哪,还可以弹回来。所以SDF ray tracing既快又鲁棒。
球面追踪就像在黑暗中用手摸墙。你不知道墙在哪里,但你知道”我至少离墙还有5米”(SDF值)。所以你大胆往前走5米,肯定不会撞墙。到了新位置,发现”我至少离墙还有3米”,再走3米。越靠近墙,步长越小,最后精确找到墙的位置。即使不小心穿进去了,SDF的负值告诉你”你在墙内2米”,可以退回来。这比固定步长的方法快得多:固定步长可能每步只走1米,需要走很多步;球面追踪可以大步跳跃,只在接近表面时才小步走。
基于SDF的锥体追踪(软阴影)
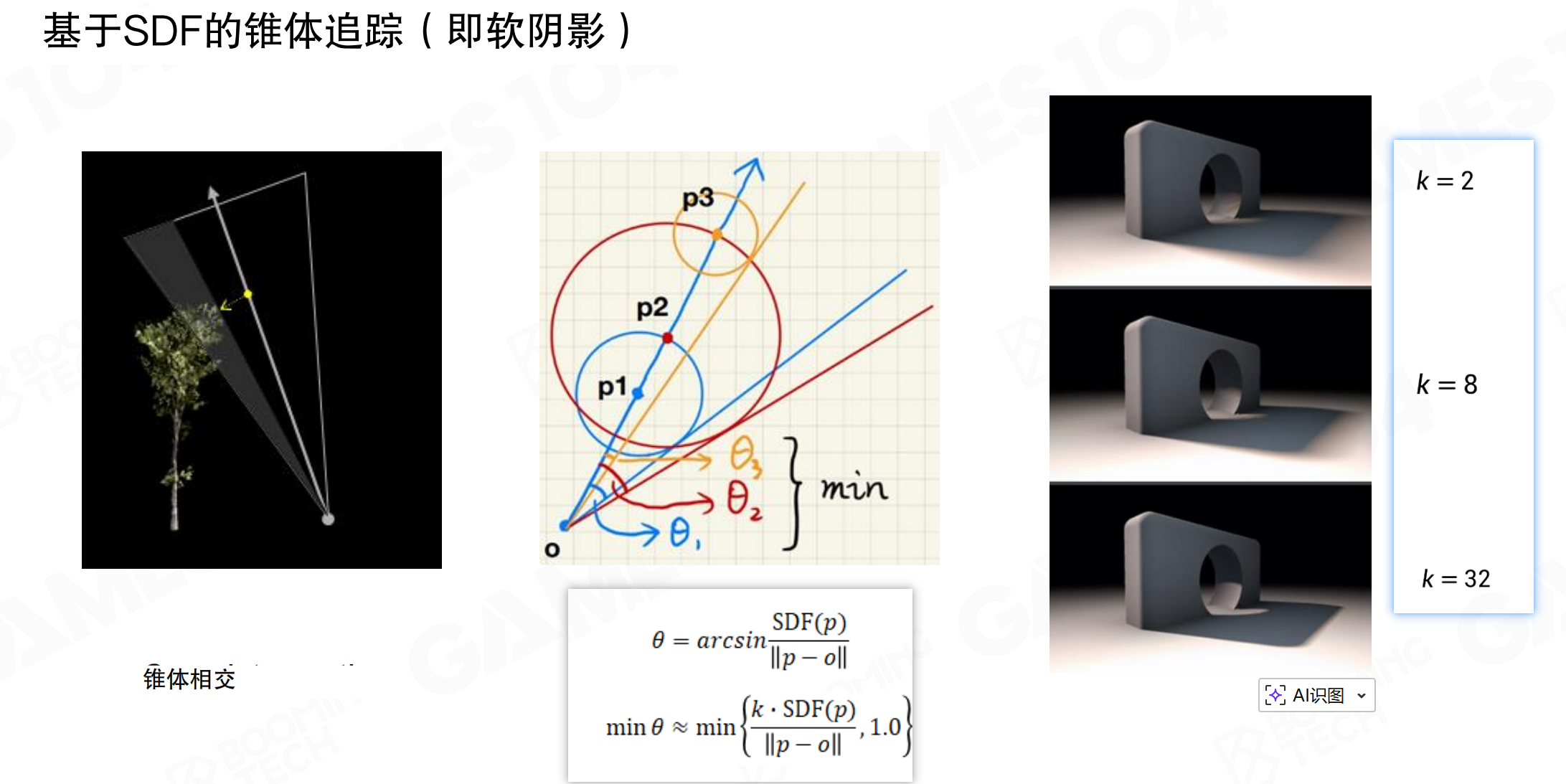
基于SDF的锥体追踪(即软阴影)。估算圆锥体在命中点的足迹,考虑粗糙度和命中距离。对颜色Mipmap进行采样,Mip层级由覆盖范围决定。
软阴影本质上是:如果天空中有一个面积光源,看它时大概多少面积会被挡住。根据从点出发到march最近点的距离,可以画一个球。在点的整个锥体disc和最近距离的disc之间,画一大一小两个圆,这两个圆之间的比值是一个很好的approximation,表示离遮挡物有多远。虽然不够精确,但已经很好用了。
公式:θ = arcsin(SDF(p) / ||p - o||),min θ ≈ min { (k * SDF(p)) / ||p - o|| , 1.0 }。参数k控制阴影软度:k=2时阴影较硬,k=8时较软,k=32时非常软。
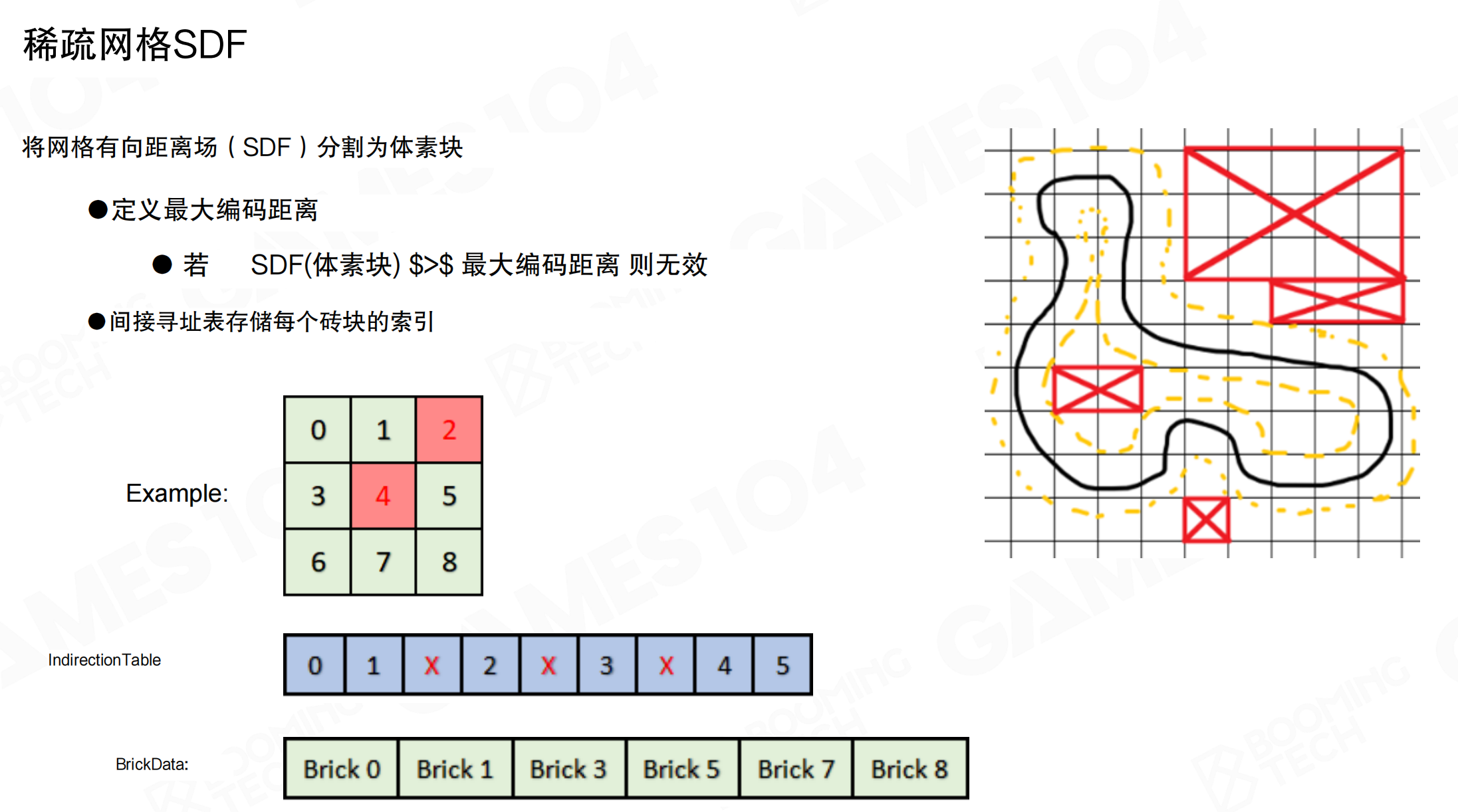
稀疏网格SDF

稀疏网格有向距离场:将网格SDF分割成块,定义最大编码距离。若所有SDF(体素块) > 最大编码距离则无效。间接寻址表存储每个块(brick)的索引。
从图中可以看到,只有靠近表面的区域(黄色虚线内)是有效的,远离表面的区域(红色X标记)是无效的,不需要存储。这样可以大幅减少存储空间。
稀疏网格SDF在不同mip层级的表现。mip0(126×154×112,5cm)分辨率最高,brick数量2310/6336,存储1.15MB/3.09MB。mip1(63×77×56,10cm)中等分辨率,brick数量532/792,存储0.26MB/0.39MB。mip2(35×42×28,20cm)最低分辨率,brick数量112/120,存储56.5KB/60.0KB。随着mip层级增加,分辨率降低,但有效brick比例提高,存储效率提升。
网格SDF层次细节

网格有向距离场层次细节:每帧GPU收集请求,CPU下载请求并流式调入/调出页面。生成3层MIP映射。最低分辨率层级常驻内存,其余两个层级采用流式加载。
从图中可以看到,Mip 0细节最丰富,石头块清晰可见;Mip 1细节稍减,但仍可分辨;Mip 2细节最少,基本是平滑表面。这样可以根据距离动态加载不同精度的SDF。
真实场景中的光线追踪成本

真实场景中的光线追踪成本:追踪相机光线并可视化步数。从图中可以看到,越靠近mesh边界的像素,step要走得非常远。这是因为要沿着方向测试很多物体,计算复杂度会越来越高。

每条光线上的多个物体:沿每条射线命中的物体数量。如果场景全是物体,每条光线要测试很多物体。从灰度图可以看到,亮度表示需要测试的物体数量,越亮表示需要测试的物体越多。
全局SDF

全局SDF在近表面区域存在精度不足的问题。在锥体起始位置附近采样对象SDF,其余部分使用全局SDF。从对比图可以看到,全局SDF(左)在表面附近有模糊的光晕,精度不足;混合方案(右)在近处使用对象SDF,远处使用全局SDF,表面更清晰。

基于全局SDF的射线追踪:大幅降低重叠对象的追踪成本。从对比图可以看到,使用全局SDF后(右),画面更平滑,计算成本大幅降低。不再需要逐个测试物体,可以快速找到交点。
围绕摄像机缓存全局SDF

围绕摄像机缓存全局SDF:以摄像机为中心的4个剪辑贴图层。Clipmap随移动滚动。远距离裁剪图更新频率较低,且采用稀疏存储(节省约16倍内存)。
SDF是uniform表达,天然支持clipmap。可以实现近处50米SDF密度高一点,远处100米、200米、400米SDF精度低一点。这样完美解决了各种求交需求。
物体SDF到全局SDF

对于单个mesh,做ray tracing速度很快,可以先找到bounding box,然后按SDF往里面打。但场景物体数量特别多,一条光线打过去,沿途所有object都得问一遍。
解决方案:既然物体都是分散的,在camera空间把这些SDF合成一个大的低精度的全局SDF。从per-object SDF合成global SDF有数学变换,还要处理物体移动、消失、增加的情况,需要update算法。
有了全局SDF后,ray tracing速度会非常快,因为它不再依赖于一个一个的物体。当然缺点是受制于存储空间,不能像per-object SDF那么精细,一般会比较粗。所以Lumen里两个都用:mesh SDF和global SDF。
就像找东西。如果房间里有很多小盒子,每个盒子都有详细的地图(per-object SDF),找东西时要一个个盒子打开看,很慢。但如果把所有盒子合并成一张粗略的大地图(global SDF),可以快速知道”大概在哪个区域”,然后再用详细地图精确查找。就像用世界地图找城市,再用城市地图找街道。全局SDF是”世界地图”,快速但粗糙;mesh SDF是”城市地图”,精确但需要逐个查询。两者结合,既快又准。
从图中可以看到,如果每个物体单独测试,要测试200多次物体(亮度100%表示200多次测试)。有了global SDF后,物体测试数量极大下降,可以快速找到近处的点,然后再根据周边的mesh去做,速度会快很多。
有了这样的架构,做ray tracing时既不依赖硬件ray tracing,速度又比直接测AABB、测ray和mesh的交点快很多。
21.8 Lumen:辐射注入与光照缓存
有了快速光线追踪后,需要把光照信息注入到场景中。Lumen使用Mesh Card保存物体在6个轴对齐方向上的光照结果。
Mesh Card

网格卡片(Mesh Card):六轴对齐方向上的正交相机。FLumenCard包含本地OBB、世界OBB和轴对齐方向索引。每个物体从6个方向(+X、-X、+Y、-Y、+Z、-Z)拍摄正交快照,记录被光照亮的样子。
为什么需要6个方向?GI是全光路问题。直接照明只需关注眼睛看到的面,但GI需要知道所有可能的光路。例如,笔的正面可能被侧面反射的光照亮,也可能被上方反射的光照亮。从6个方向采样,可以覆盖所有可能的光照方向。
就像给一个立方体拍照。如果只拍正面,只能看到前面的光照。但GI需要知道从上下左右前后六个方向来的光,因为光可能从任何方向反弹过来。就像用6个摄像头同时拍一个物体的6个面,记录每个面被光照亮的样子。这样无论光从哪个方向来,都能知道物体会被照成什么样。

场景中每个物体都会生成对应的Mesh Card。左图是渲染视图,右图是线框视图,可以看到每个物体都被分解为多个Card。
表面缓存(Surface Cache)

生成表面缓存:双通道。Pass 1:卡片捕获。每帧固定纹理像素预算(512×512),按距离摄像机远近排序及GPU反馈,捕获分辨率取决于卡片在屏幕上的投影。
对于每个Card,需要记录物体表面的albedo、法向、深度等信息。如果物体有自发光,还要记录emissive。

Pass 2:将卡片复制到表面缓存并进行压缩。从512×512的Card Capture Atlas复制到4096×4096的Surface Cache Atlas。
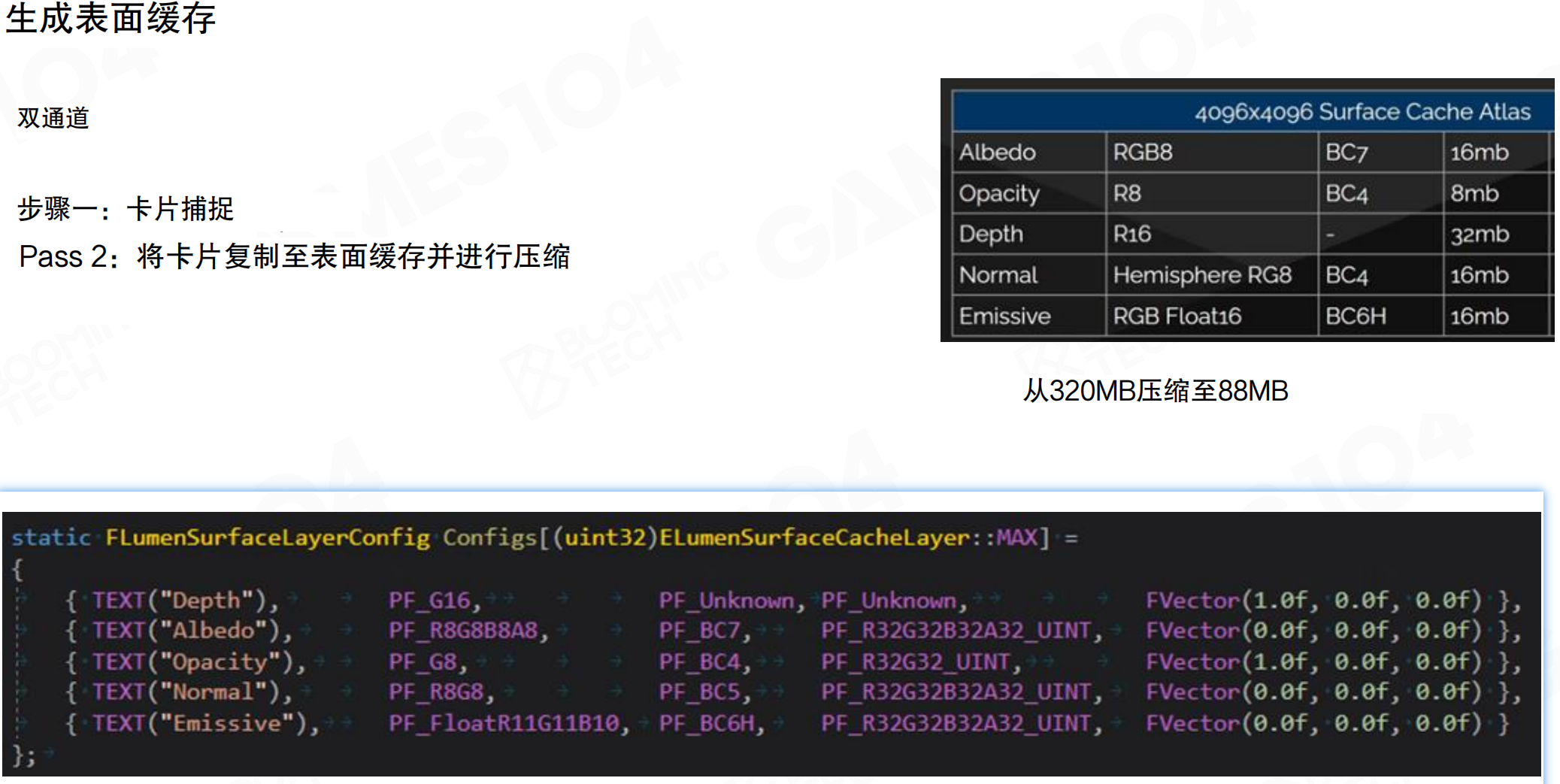
4096×4096 Surface Cache Atlas配置:
| Layer | 原始格式 | 压缩格式 | 内存大小 |
|---|---|---|---|
| Albedo | RGB8 | BC7 | 16MB |
| Opacity | R8 | BC4 | 8MB |
| Depth | R16 | - | 32MB |
| Normal | Hemisphere RG8 | BC4 | 16MB |
| Emissive | RGB Float16 | BC6H | 16MB |
从320MB压缩至88MB。Surface Cache不是单张纹理,而是一系列纹理的集合,包括albedo、normal、depth、opacity、emissive等。
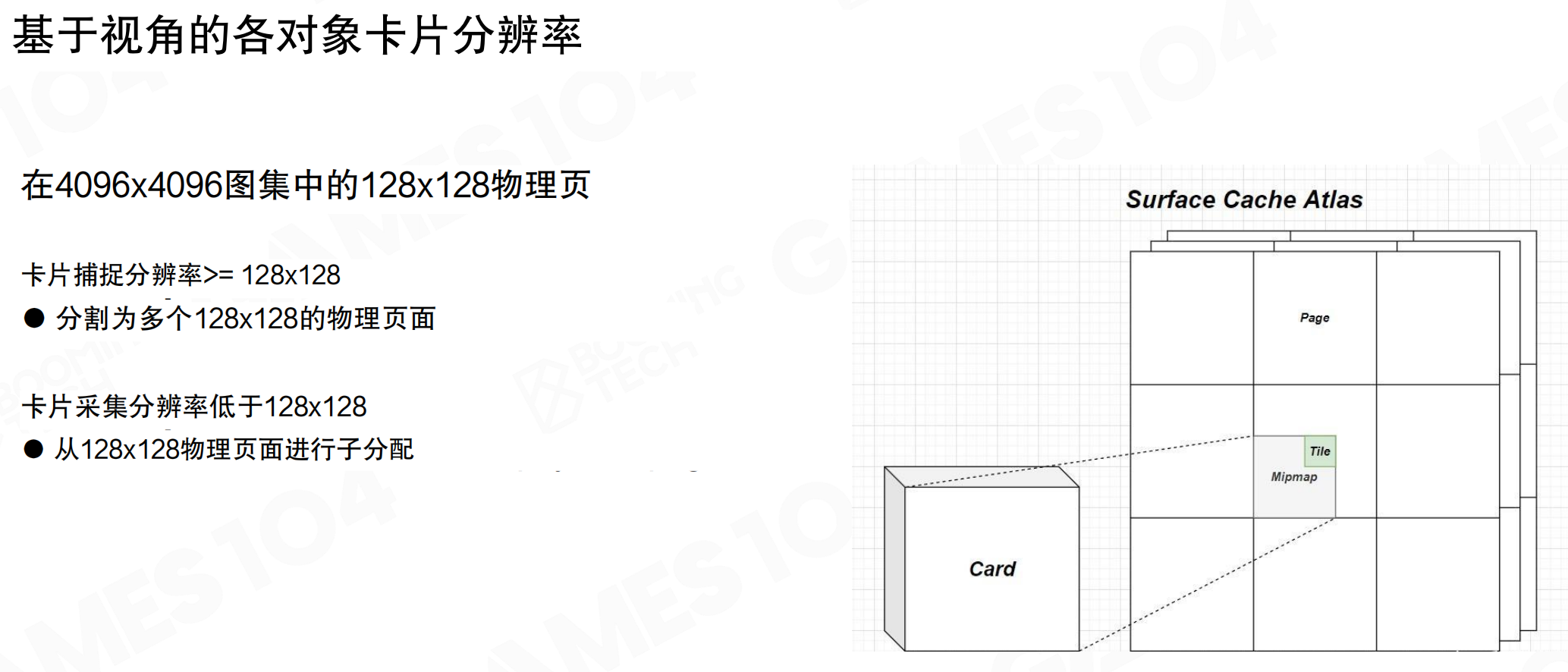
基于视角的各对象卡片分辨率:在4096×4096图集中的128×128物理页。卡片捕捉分辨率≥128×128时,分割为多个128×128的物理页面;卡片采集分辨率<128×128时,从128×128物理页面进行子分配。
根据物体距离相机的远近设置不同的Card分辨率。近处物体分辨率高,远处物体分辨率低。例如,侧面2米高的石头占据屏幕1/3,需要高分辨率;远处100米外5米高的雕像,分辨率可以低一些。这样充分利用存储空间。
光照缓存管线

核心问题:
- 如何在表面缓存上”冻结”光照
- 如何在命中点计算光照
- 该像素是否处于阴影之下
- 如何处理多次反射
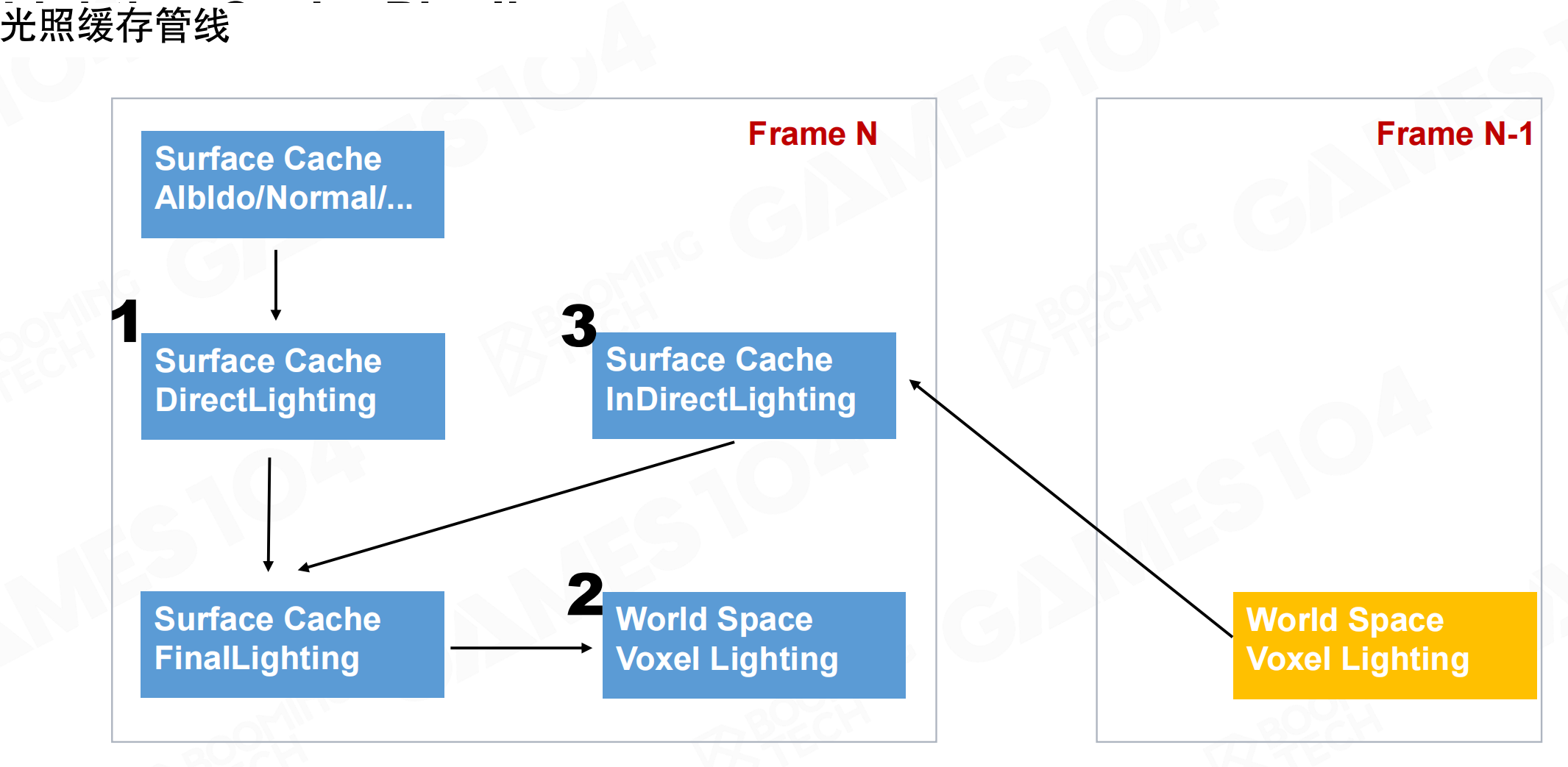
光照缓存管线分为三步:
- Surface Cache DirectLighting:计算直接光照
- World Space Voxel Lighting:将光照转换为世界空间体素表达
- Surface Cache InDirectLighting:使用上一帧的体素光照计算间接光照
Frame N的间接光照使用Frame N-1的World Space Voxel Lighting。Frame N的最终光照更新World Space Voxel Lighting,供Frame N+1使用。这是”左脚踩右脚”的迭代方法:每帧只计算一次bounce,但通过采样上一帧的结果,可以累积多次bounce的效果。第一帧只有一次bounce,第二帧有两次bounce,第三帧有三次bounce,随时间积累得到多次bounce的结果。
就像滚雪球。第一帧,光从光源直接照到物体(1次bounce)。第二帧,用上一帧的结果,光从光源→物体→其他物体(2次bounce)。第三帧,光从光源→物体→其他物体→再其他物体(3次bounce)。每帧只计算一次新的bounce,但通过复用上一帧的结果,逐渐累积更多bounce。就像接力赛:每个人只跑一段,但通过传递接力棒,最终跑完全程。这样避免了每帧都计算多次bounce的巨大开销。
直接光照
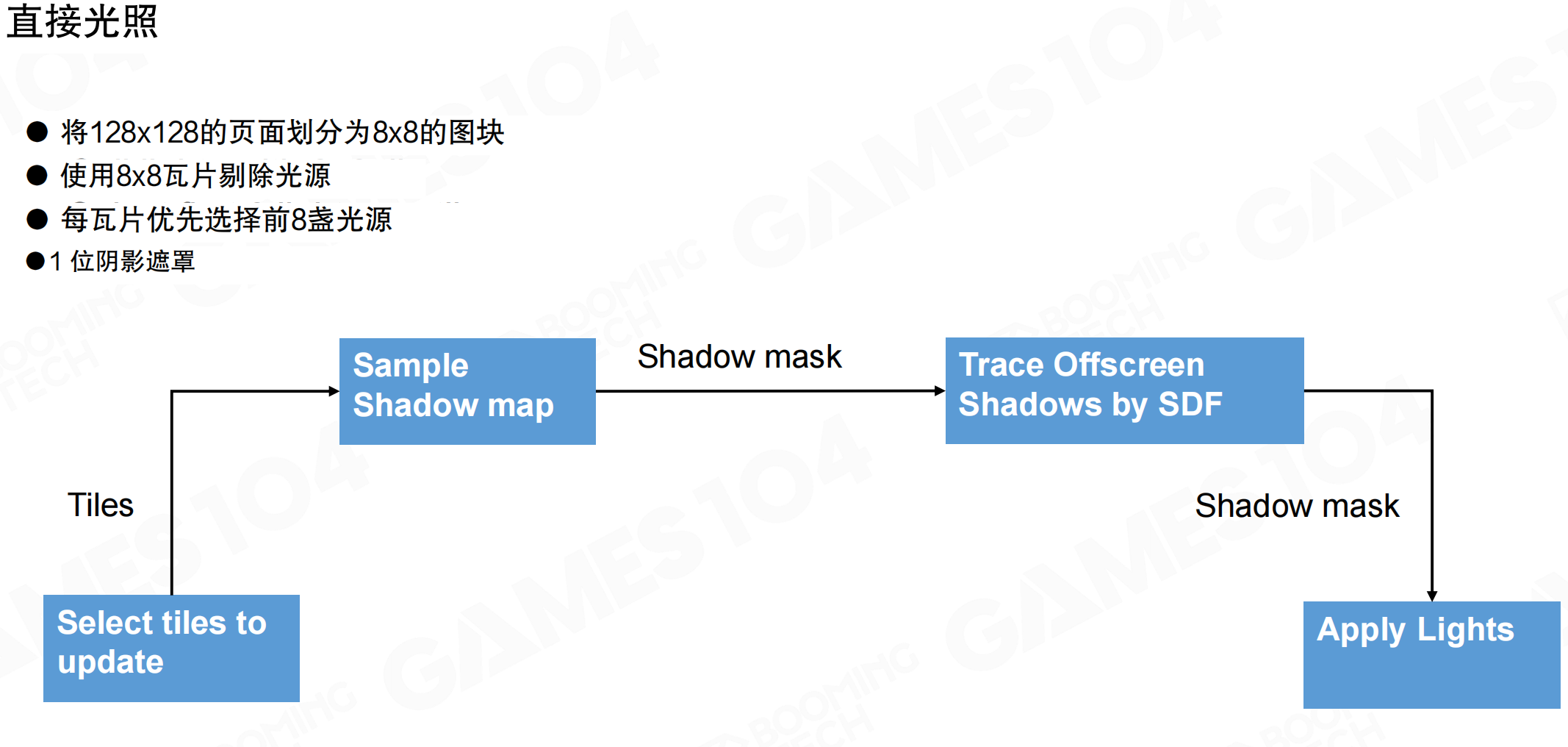
直接光照:将128×128的页面划分为8×8的图块,使用8×8瓦片剔除光源,每瓦片优先选择前8盏光源,1位阴影遮罩。
流程:选择要更新的tiles → 采样Shadow map → 生成Shadow mask → 使用SDF追踪屏幕外阴影 → 应用光源。
对于Surface Cache上的每个像素,计算其空间位置,与光源计算Lambert值。如果被阴影遮挡,使用Shadow map或SDF ray tracing判断可见性。使用mesh SDF进行ray tracing,从Surface Cache上的点向光源方向发射光线,用SDF查询是否可见。

多光源支持:一个图块可由多光源照明,最终结果将进行累加计算。对于Surface Cache中的每个texel,逐个光源计算一遍,累加在一起。假设是diffuse面反射,可以累加。这很重要:游戏场景通常有多个光源,不能限制设计师。任何用于游戏实战的GI算法必须支持多光源。
体素光照

全局SDF无法对表面缓存进行采样:无需逐网格信息,仅需命中位置与法线数据。使用体素光照进行采样。
对于近处物体,可以用per-mesh SDF精确采样表面radiance。对于远处物体,必须用global SDF,但global SDF只能找到采样点和法线,不知道hit到了哪个instance、哪个面。解决方案:以相机为中心,对整个场景做体素化表达,提供该点的亮度。

用于全场景辐射度缓存的体素Clipmap:4级64×64×64体素的剪辑图。每个体素6个方向的辐射亮度,依据法线采样并插值三个方向。Clipmap0覆盖50立方米空间,体素尺寸为0.78米(0.78×64≈50米),存储在3D纹理中。
Clipmap更新频率规则:
- Clipmap 0:Start_Frame=0,Update_interval=2
- Clipmap 1:Start_Frame=1,Update_interval=4
- Clipmap 2:Start_Frame=3,Update_interval=8
- Clipmap 3:Start_Frame=7,Update_interval=8
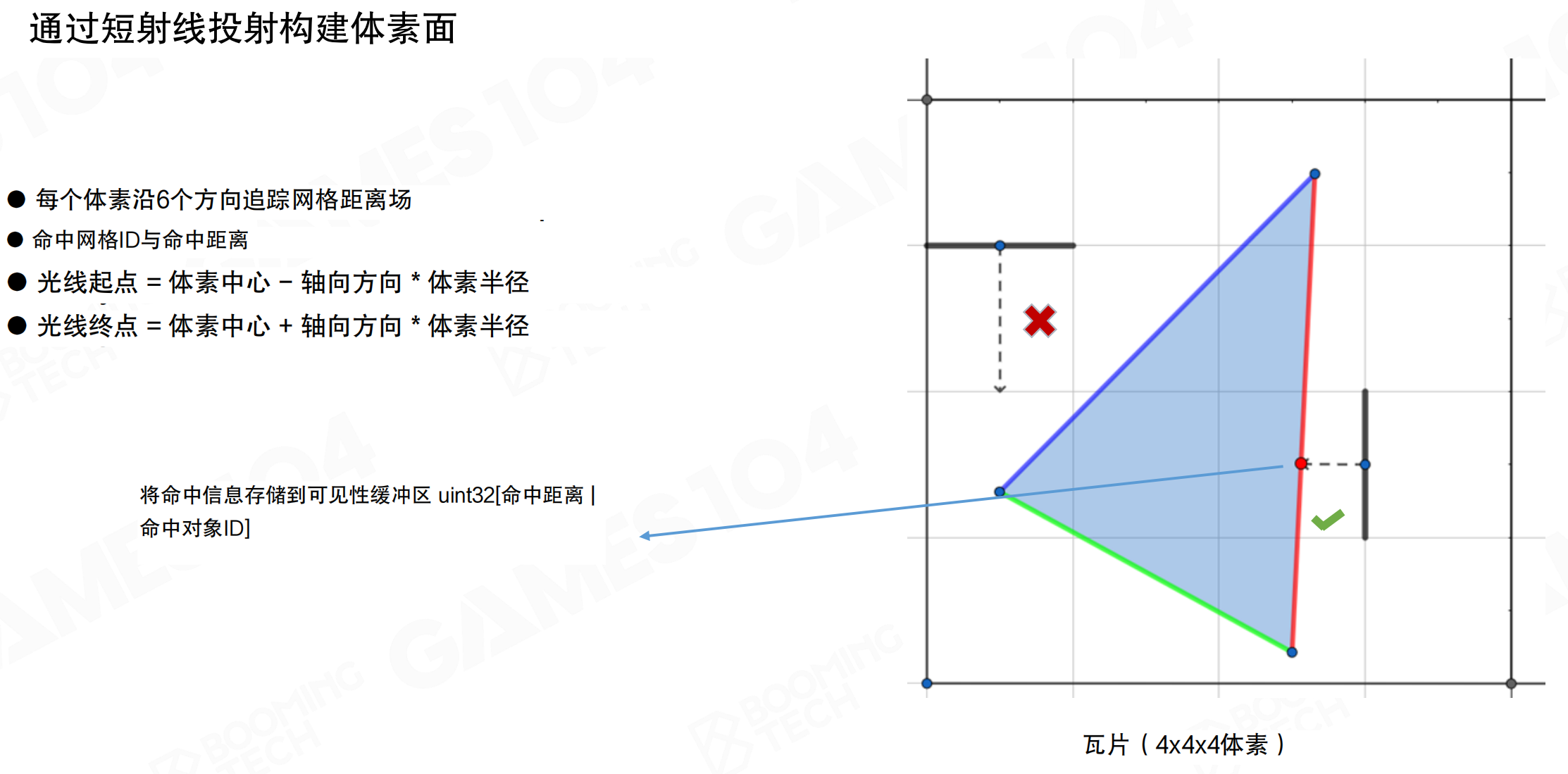
通过短射线投射构建体素面:每个体素沿6个方向追踪网格距离场,记录命中网格ID与命中距离。光线起点=体素中心-轴向方向×体素半径,光线终点=体素中心+轴向方向×体素半径。将命中信息存储到可见性缓冲区:uint32 [命中距离 | 命中对象ID]。
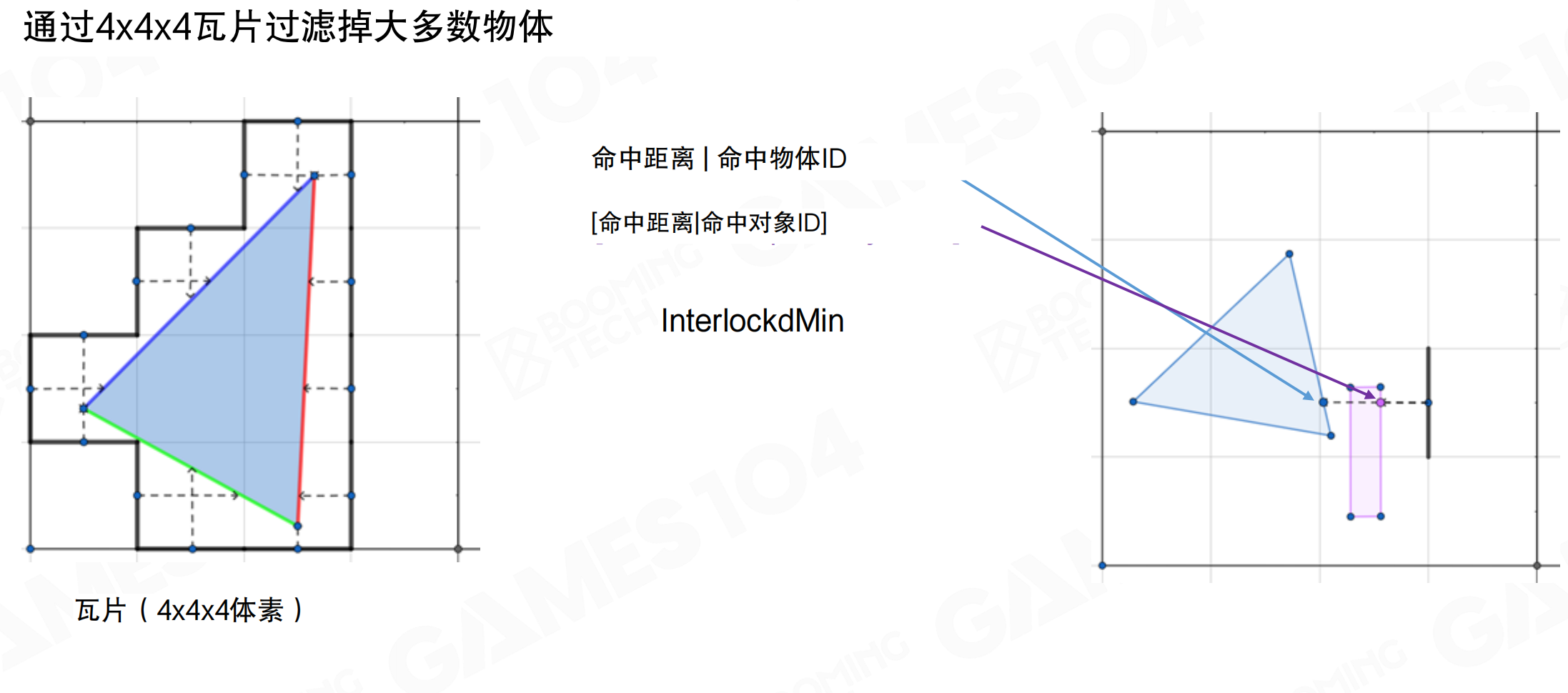
通过4×4×4瓦片过滤掉大多数物体:使用InterlockedMin找到最近的hit。将空间切成很多小格子,每个格子比voxel大一点。在3×3米的cube里,只有四五个物体,求交效率很高。这样voxelization速度非常快。
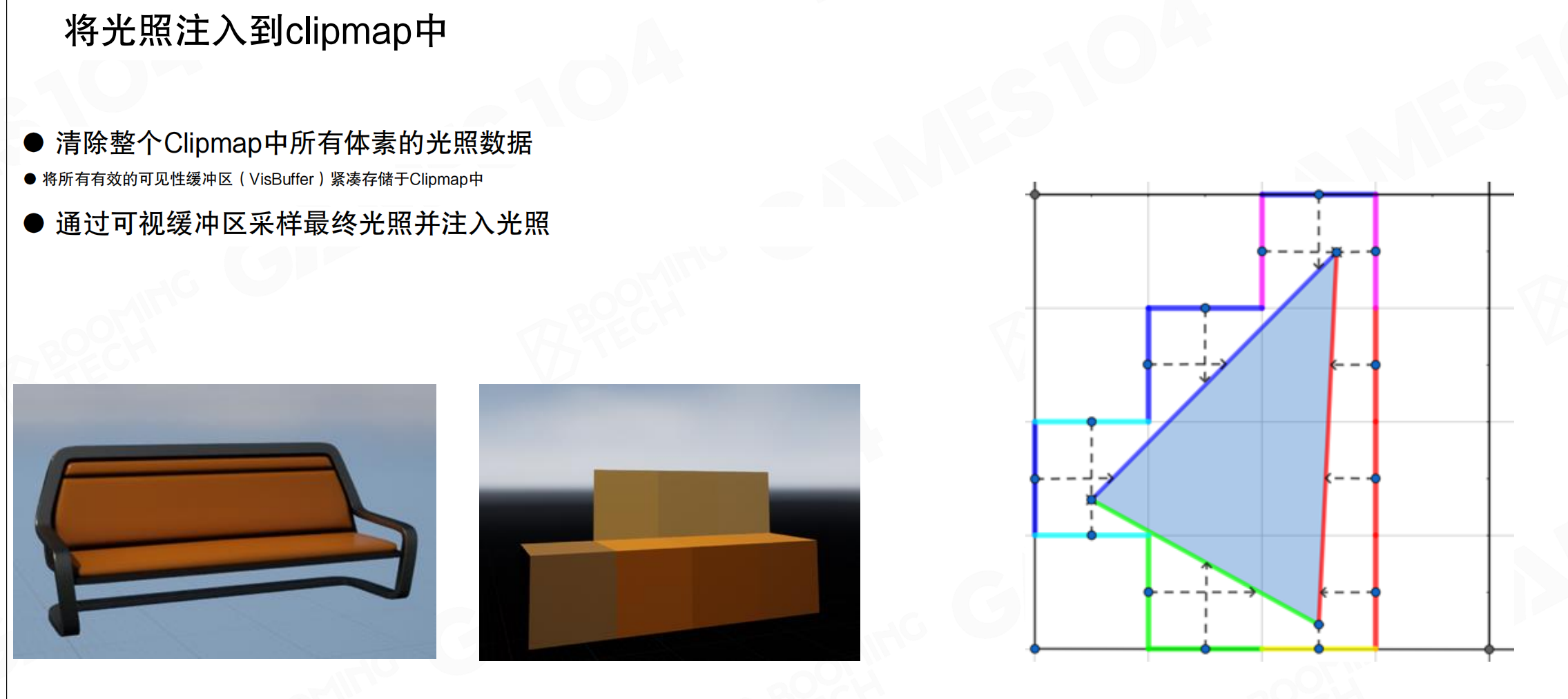
将光照注入到clipmap中:
- 清除整个Clipmap中所有体素的光照数据
- 将所有有效的可见性缓冲区(VisBuffer)紧凑存储于Clipmap中
- 通过可视缓冲区采样最终光照并注入光照
用Surface Cache的final lighting结果去照亮voxel lighting。下一帧更新Surface Cache indirect lighting时,使用voxelized世界的表达去做indirect lighting。这样天然具有multi-bounce的结果。
间接光照
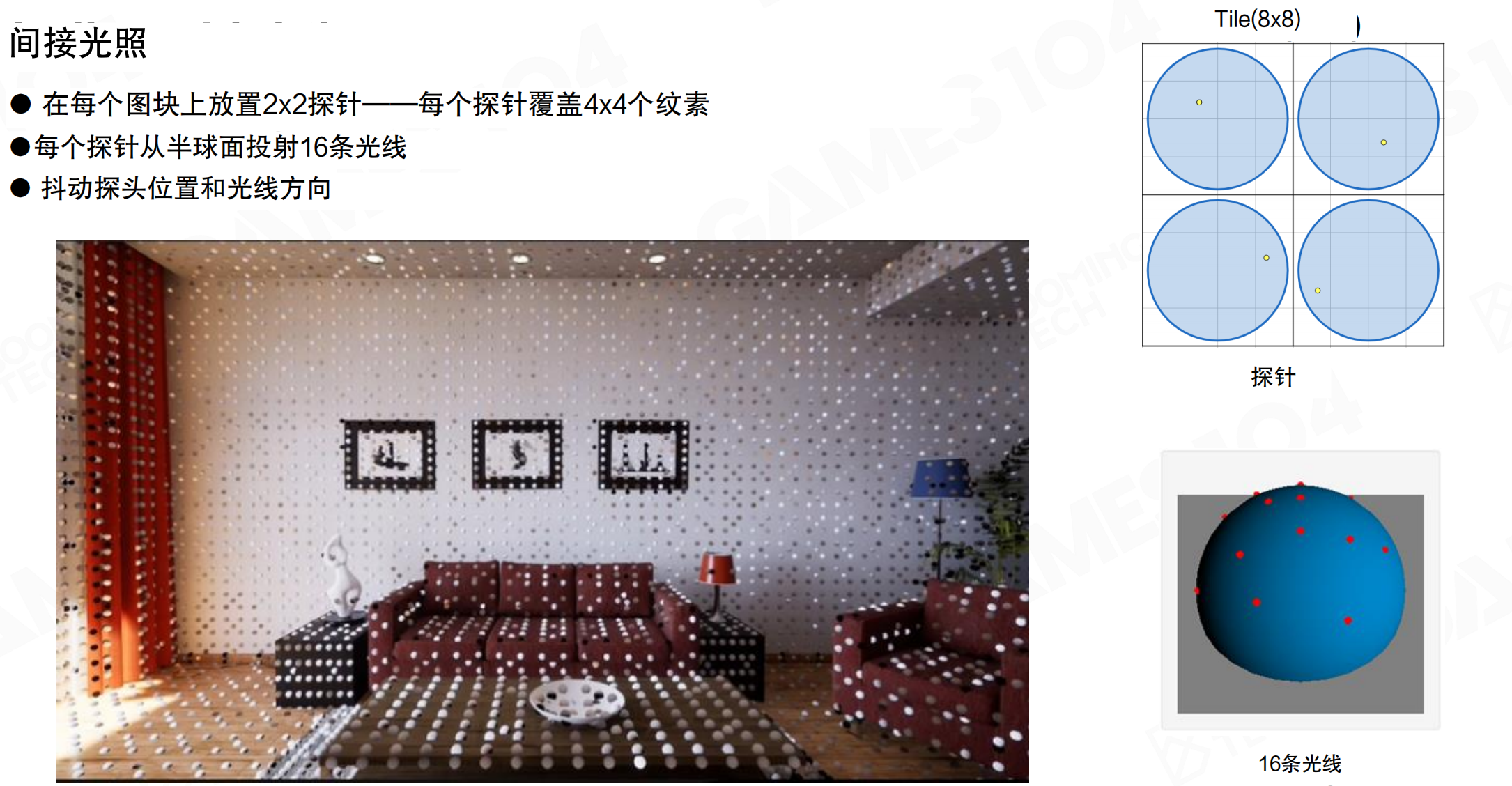
间接光照:在每个图块上放置2×2探针,每个探针覆盖4×4个纹素。每个探针从半球面投射16条光线,抖动探头位置和光线方向。
对于Surface Cache上每8×8的tile,选择4个采样点,每个采样点投射16根光线。这些光线与空间上的voxel表达求交,从voxel lighting上采样radiance。

探针间的空间滤波:转换为双波段球谐函数(存储为half4类型)。对探针数据进行空间滤波,平滑相邻探针之间的变化。然后转换为球谐函数,分别存储红、绿、蓝三个颜色分量。

基于四探头插值的逐像素间接光照:在像素上积分,对四个邻近探针进行双线性插值。间接光照、直接光照、Albedo合并得到最终光照。
Surface Cache不会用自己去做indirect lighting,永远从voxel lighting上采样。有了SH表达后,可以用SH进行插值,计算球面上的间接光照对shading的结果。
合并光照

合并光照公式:最终光照 = (直接光照 + 间接光照) × 漫反射_兰伯特(反照率) + 自发光
直接光照是HDR的,间接光照是LDR的。两者相加后乘以albedo,再加上emissive,得到最终光照。
光照更新策略

光照更新策略:
固定预算:
- 直接光照使用1024×1024纹素
- 间接光照采用512×512纹素
- 基于优先级=最后使用时间-最后更新时间来选择需要更新的页面
基于桶排序的优先级队列:128个存储桶。根据优先级更新存储桶直至达到预算。
Surface Cache的更新很费,所以Lumen做了预算限制。每一帧直接光照最多不超过1024×1024个texel更新,间接光照最多更新512×512个texel。每个mesh card都要排队,设置priority进行管理,选择更新。这涉及复杂的排队算法和bucket sort算法。
总结
Surface Cache是对世界光照信息的uniform表达,相当于把所有光子固化在上面。Mesh Card和World Space Voxel Lighting都符合SDF的设计思想:把irregular的东西变成uniform的regular表达,接下来做积分、卷积、采样都会更简单。
这个方法还解决了自发光问题。即使是一条光带,也能整体cache到lighting里。第一帧光带不起作用,但通过”左脚踩右脚”,把它注入到voxel light space,下一帧就能卷回来,再卷几次,就能看到墙被照亮了。这很巧妙。
Surface Cache相当于为lighting准备的impostor。不是所有物体都能用impostor表达lighting,也不是所有lighting都能用impostor表达,同时还要做multi-bouncing的global illumination。通过voxelization,把空间变成更粗但能表达几百米范围内场景lighting信息的表达。无论是近处的per-mesh表达,还是远处整个场景的大致亮度,都可以表达。
21.9 Lumen:构建多种不同类型的光照探针
有了Surface Cache和Voxel Lighting后,需要在物体表面通过采样计算着色。Lumen在屏幕空间放置探针(probe)来采样光照,每个probe记录光线前进的距离和收集到的radiance。
屏幕空间探针

屏幕探针结构:带边界处理的八面体图集。通常每个探针8×8,均匀分布的世界空间方向,相邻探针的方向具有匹配性。辐射度与击中距离在二维图集中。
最自然的思路是在空间上均匀分布,设置多个采样点,用这些点对球面空间的光照进行采样。但场景起伏多,靠近camera放密一些,离开camera放远一些。出现几何结构后,1米间隔放置一个probe无法保证表达光照变化。如果表达不了,渲染结果会显得很平。
Lumen的做法:在screen space打probe。每隔16×16个pixel采一个screen space的probe。为什么16×16?相机看的话,如果离你近的地方,16×16个pixel在空间上的距离不会太远。间接光照是低频的,在这么近的距离里,它的变化确实不会很大。高频的东西可以用表面自己的法线、材质细节表达出来。低频的光照间接光照可以直接上采样。
就像用网格点测量温度。不需要每个点都测,每隔一段距离测一个点就够了。如果两个测量点很近,温度变化不大,中间的点可以通过插值得到。间接光照就像温度:变化缓慢,不需要密集采样。而表面的细节(如纹理、法线)变化很快,需要每个像素都计算。就像画素描:先用粗线条勾勒大致的明暗(低频光照),再用细线条刻画细节(高频表面属性)。
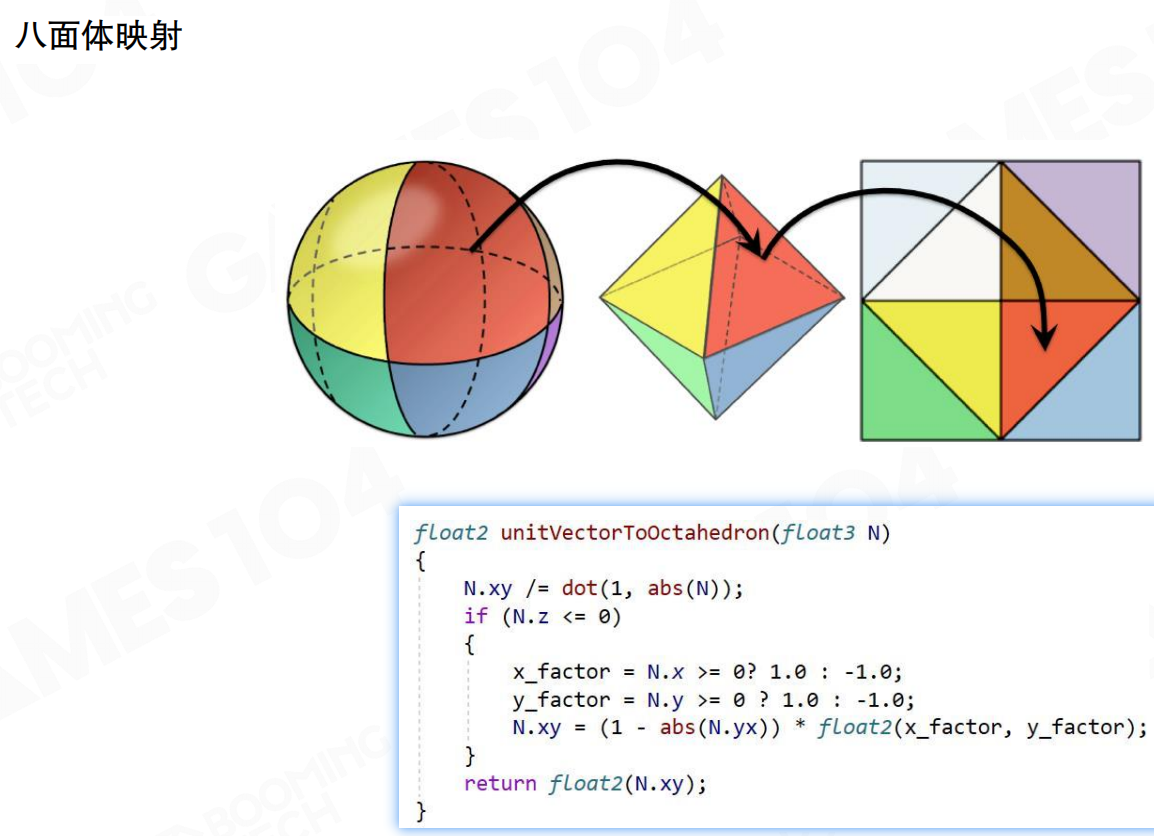
八面体映射:将3D单位向量映射到2D平面。球面→八面体→2D方形网格。unitVectorToOctahedron函数实现这个映射。八面体映射满足:任何方向映射到2D的UV计算简单,可进行双线性插值,相邻两个texel之间的采样点在纹理空间的差值近似于球面上的差值。这是有效的参数化方法。

屏幕探针布置:采用分层优化的自适应布局,在插值失败处进行迭代放置。从16×16到8×8,再到4×4,逐步细化。
如果两个pixel在真实物理世界的距离特别大,虽然视觉上投影上很相邻,在真实物理空间上距离非常远,16×16个texel采样就有问题。如果强行这么干,会把很多光照的细节模糊化掉。这就像天文学上的”视灵心”:两颗恒星看上去很近,但实际上距离非常远,深度值不一样。
需要检测:如果16×16的采样区域里,很多点之间的距离在真实距离非常远,认为采样精度不够,就refine,把密度增加一倍,变成8×8。8×8不够再refine,变成4×4。
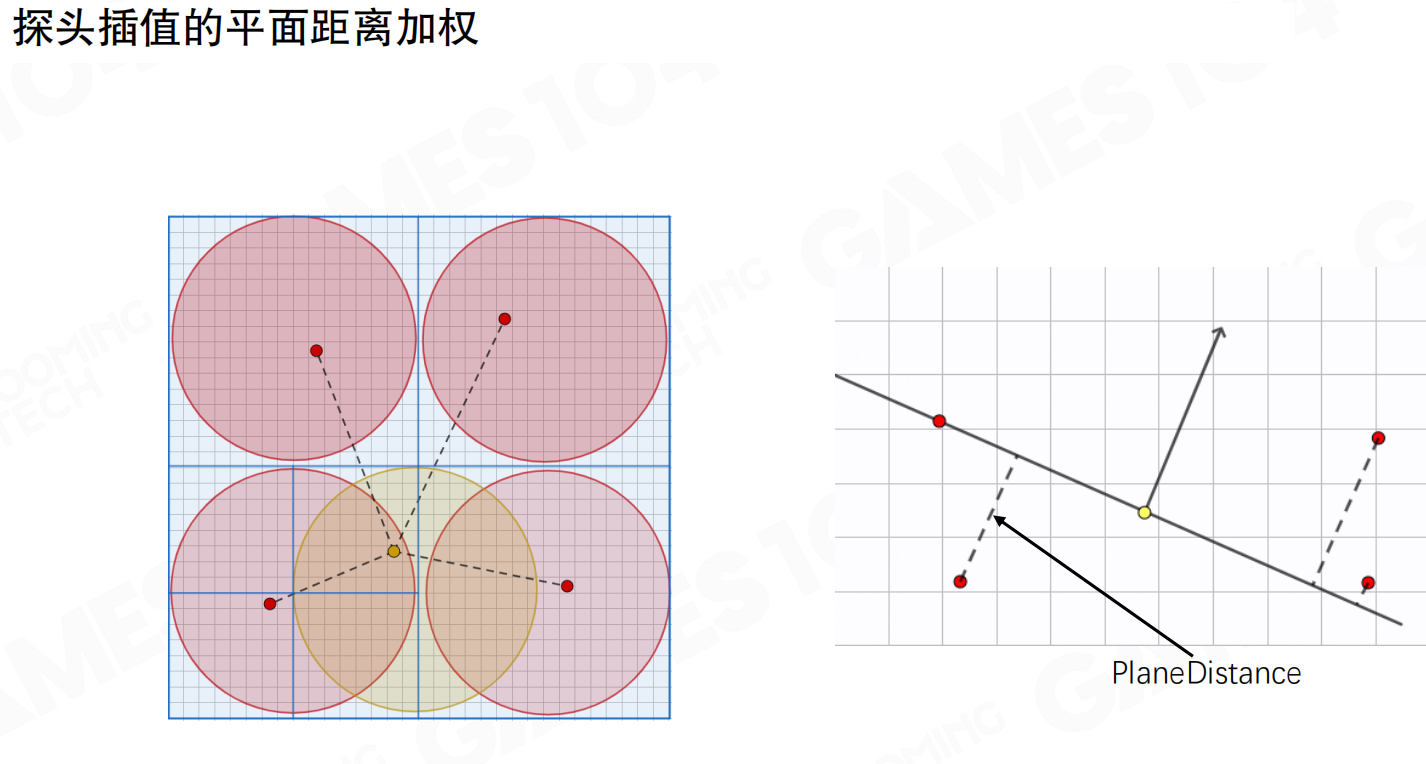
检测不可插值情况:基于法平面的投影距离进行插值。对于16×16的tile,假设任何一个pixel要渲染时,要从四个probe之间去插值。取16个或32个点采样时,这个点除了空间位置,还有法向,会得到一个平面。把四个probe的中心点投影到平面上,看投影距离的权重。如果error累计大于某个threshold,认为采样点不能用。如果足够多的采样点不能用,认为这四个采样点无效,需要refine。
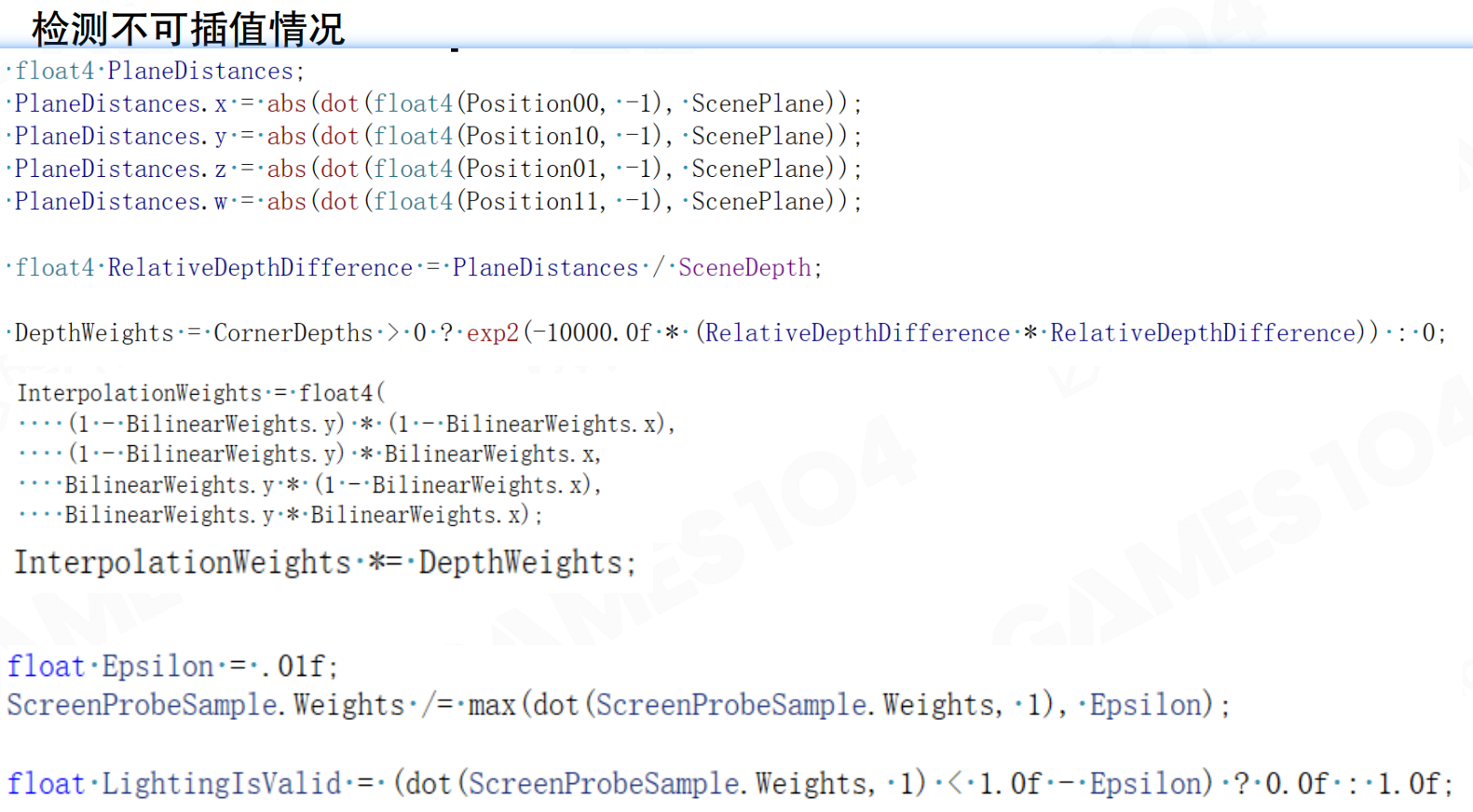
探头插值的平面距离加权:基于法平面的投影距离进行插值,包括空间距离插值。这个思想在R7、WAI、SSGI里都用过,被证明很有用。可以避免采样是无效的采样:相邻两个pixel之间在真实世界里相距可能会非常远,踩过来的这些probe在物理空间的位置可能非常远。对于这个点做shading时,如果用了这个probe实际上是无效的。当这种无效率大了足够多时,认为采样不够,就要refine。

屏幕探针图集:图集对实时性有上限限制,将自适应探针放置在图集底部。16×16、8×8、4×4不同分辨率。把screen space所有的probe做了一个atlas。做texture UV时一般是方形texture,但屏幕一般是长条形。假设屏幕上的pixel都是16×16的,每个probe是8×8,存进去时下面正好有一节空间没有用。把需要refined的这些probe packing在下面,存个index就好。每个screen probe存一个值,说这个probe有没有被refine,如果有被refine,位移应该在哪里。如果L0的probe需要refine,就找到往下一层,往下那个probe又存了说还可以再往下走。没有用多少额外的存储空间,因为text分配时是方形,放在下面的地方都用起来了。这样可以对视空间的lighting信息进行自适应采样。
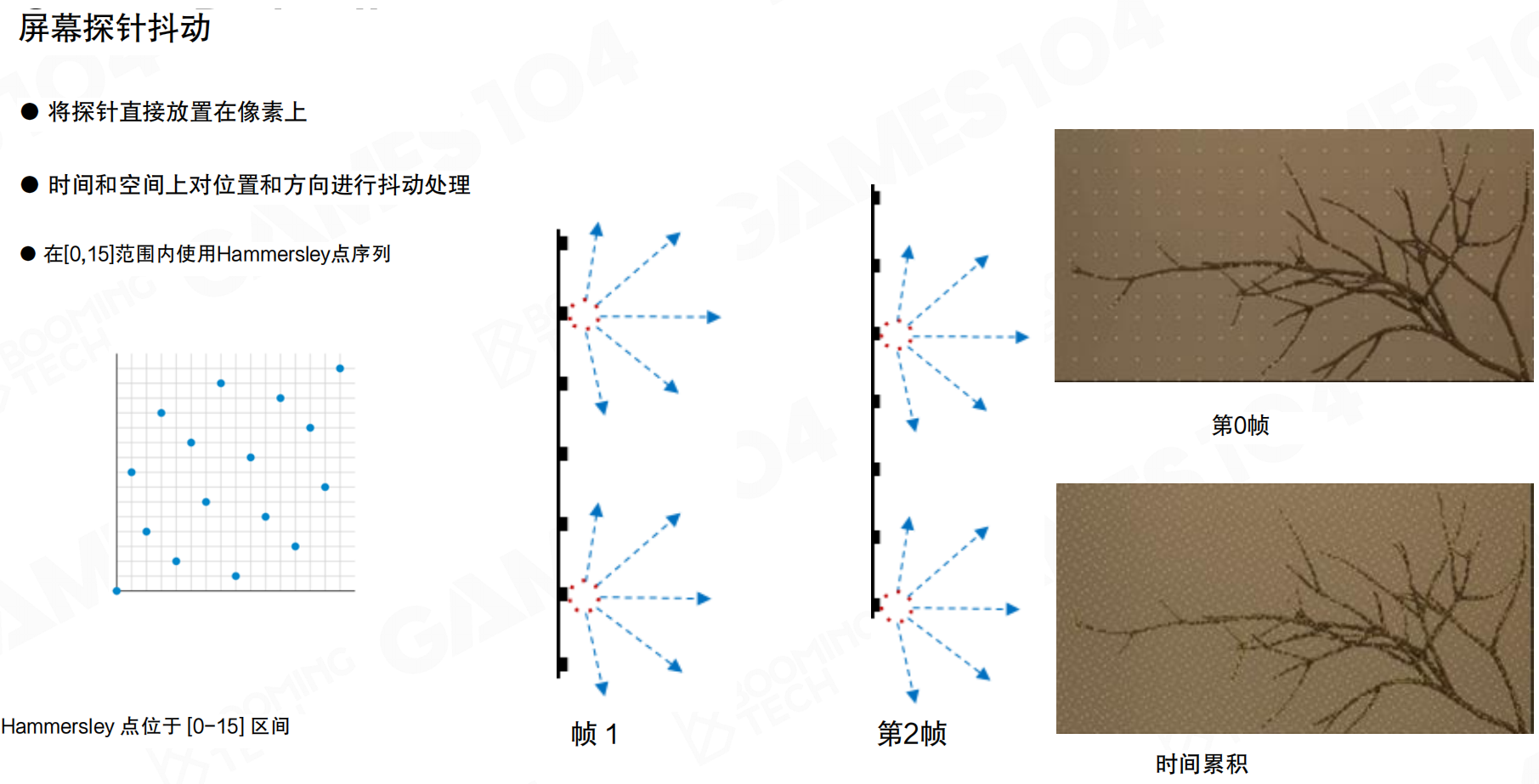
屏幕探针抖动:将探针直接放置在像素上,时间和空间上对位置和方向进行抖动处理,在[0,15]范围内使用Hammersley点序列。防止看上去太repeat或过度太high。当你有多少次多次抖动你的结果时,在时序上又变成了一次multi-bounce的采样。SSGI里也用了这样的技术,不停抖动采样。
重要性采样

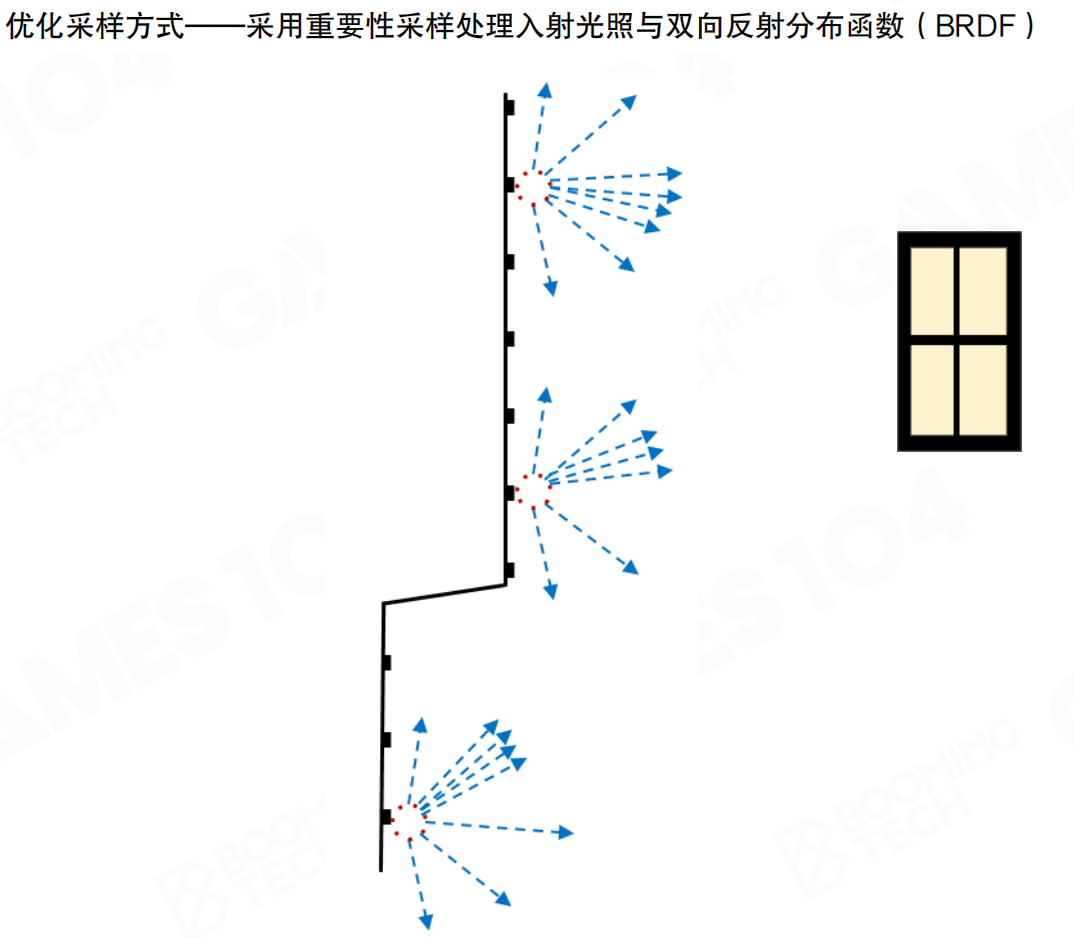
优化采样方式:采用重要性采样处理入射光照与双向反射分布函数(BRDF)。在比较重要的方向上进行采样,尽可能在光照比较强或接近物体法线的方向上分布光线。
回到Monte Carlo积分的公式,需要把光线更多地分布在光照比较强或接近物体法线的方向上。对于真正的rendering来讲,如果8×8往球面上采样,肯定有问题。窗户在哪里不知道。在一个房间里,indirect lighting窗户在哪是很重要的问题。如果采样不是使劲地朝着窗户那个方向去踩,任何GI算法算出来的结果都是像秃头般一样,七黑一块白一块,非常丑。
就像在黑暗的房间里找光源。如果随机往各个方向看,可能看了100个方向都看不到窗户,只有1个方向能看到。但如果知道窗户大概在哪个方向(比如从上一帧的数据),就应该多往那个方向看,少往其他方向看。就像在森林里找出口:如果知道出口大概在北方,就应该多往北看,而不是随机乱看。重要性采样就是”聪明地看”,在重要的方向多采样,在不重要的方向少采样。
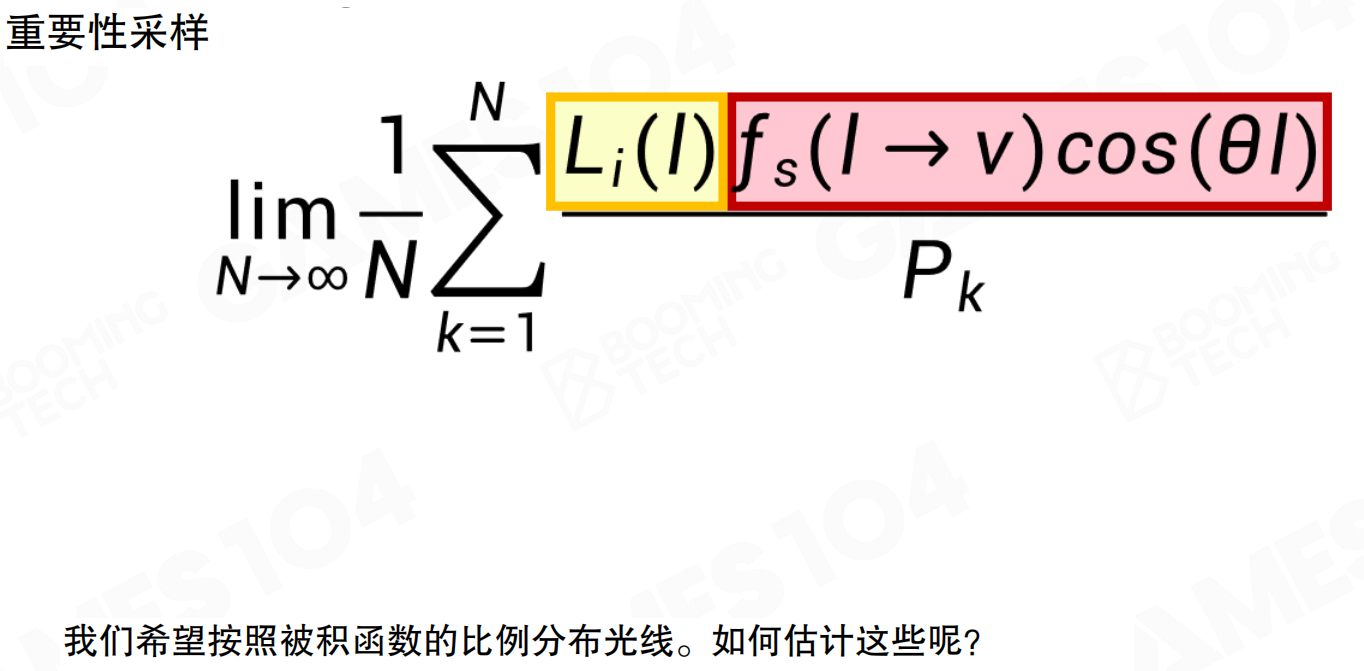
重要性采样公式:lim (1/N) * Σ [L_i(l) * f_s(l → v) * cos(θ_l)] / P_k。希望按照被积函数的比例分布光线。概率函数要尽可能符合被积函数的分布。被积函数是两个函数的积:一个是光,一个是表面的BRDF。找到问题的因子:需要知道光在哪强,还需要知道法向在哪。就算光在这儿,法相在这,光对我有什么意义?可能是背对你的,可能要更多的要踩一下背面的光。
基于上一帧探针的近似辐射重要性:Lumen会对上一帧以及四周相邻的probe进行平均来估计光照的分布。重投影至上一帧并对四个相邻屏幕探针进行平均处理辐射亮度。无需进行昂贵的搜索,因为光线已在八面体图集中建立索引。若相邻探头被遮挡,则回退至世界空间探头辐射度。
既然想知道光在哪,把上一帧的probe踩一遍。并不知道这一帧的光在哪,但做一个假设:光的变化没有那么快。从上一帧的probe里,从最近的上一帧的screen space probe里做一个采样,把它们的值积在一起,合在一起,大概知道哪个地方亮,哪个地方不亮。把四个指路性价值一样可以得到一个8×8的明暗相间的图,这个图中亮的地方就是光比较亮的地方,相当于在这个位置大概猜测天会亮在哪儿。last frame在GI里非常有用,上一帧的数据千万别丢,它有很多妙用。
就像用上一秒的照片预测下一秒。虽然场景可能略有变化,但大部分光照信息是连续的。上一帧发现窗户在左边很亮,这一帧窗户大概率还在左边,可以优先往左边采样。就像开车时用后视镜:虽然路在变化,但后视镜里的信息仍然有用,可以帮助判断当前情况。上一帧的probe数据就是GI的”后视镜”,提供了光照分布的先验信息。

累积法线分布邻近值:对于物体法向附近的方向,Lumen会估计probe附近的法向分布。对于放置在平坦墙面上的探针,其球面约有一半区域的BRDF值为零。从将使用此屏幕探针的像素中累积。
对于这个probe,即使知道pixel位置,即使jittering,normal也有明确方向,沿normal做cos lobe,下面的半个区域是黑的。但这里有个问题:framebuffer中的normal是单个像素的normal,normal变化频率很高。如果下面的mesh是nut制作的,细节很多。对于一个小区域,可能覆盖32×32,1000多个pixel,更大时会有更多pixel。1000多个pixel的大致法向朝向,不能由单个采样点的法向代表。在这个位置做light probe时,需要考虑周边所有几何的screen space连接的normal朝向。它是distribution,不是单一normal点。

邻近法线累积:在当前探针周围32×32像素范围内采集64个邻近像素。当像素深度权重大于0.1时予以接受。将这些像素的世界法向量累加到球谐函数中。
在做shading时,large lobe需要插值。在32×32的范围内,一个tile是16×16,为什么是32×32?因为对screen space进行bilinear interpolation时,一个probe的值最多影响32个pixel的距离。32×32范围内有1024个pixel。将1024个pixel的normal引发的distribution function全部累加,计算量过大。使用64个点采样。这个采样不是简单地在周围32×32区间随机选择64个点,还需要做depth check,确保depth在投影平面上相差不大。投影距离太远、法向距离太远的地方直接丢弃。每个normal的importance是cos lobe,每个cos lobe对应一个SH,将这些SH积分在一起,得到normal的distribution函数。有了这个函数,可以知道哪些区域从normal上看需要重点采样,得到BRDF。

结构化重要性采样:将少量样本分配给概率密度函数(PDF)的分层结构区域,实现良好的全局分层。采样点布局需要离线算法。完美映射至八面体mip四叉树。
对于每个screen space probe,最多采样64个。虽然是16×16,但实际上有上万个,甚至十几万个probe。每个probe设置那么多ray,现代硬件无法承受。能否在需要采样的地方加密采样?例如某个方向很重要,设置四根采样ray,但存储时合并成一个texel。在做retracing时,发现光源很小很密的地方,射线会密集一些,但最后做shading时,可以将这些射线结果合并,因为它们角度接近。做shading时不需要多次累加。保证总采样次数不变,但要有importance。

基于光照与双向反射分布函数的固定预算重要性采样:从均匀分布的探针射线方向开始。固定探针追踪射线数量=64。为每个八面体纹理像素计算BRDF概率密度函数*光照概率密度函数。按概率密度函数(PDF)从低到高对光线进行排序。对于每3条PDF值低于剔除阈值的射线,对匹配的最高PDF射线进行超采样处理。
所有采样的数量、设得ray的数量是不变的,所有的probe都是64根ray射出去。算出来了BRDF(法向所提供的PDF,也就是importance function)和lighting(lighting是从上一帧抠下来的importance function),把这两个卷积在一起,得到了哪些点是重要的,哪一点不重要的。有64×64个点,对这个点进行排序,就知道最不重要的那些方向和最重要的那些方向。设置一个阈值,从最不重要的方向1、2、3一次走,当找到三个,就是倒数前第三个,前三个,最不重要的方向,假设他们的PDF值都小于阈值时,就意味着最需要采样的那个方向,可以对它进行一次super sampling。因为本来只能采样一次,给你再加三次的话,不就四次了,四次就意味着可以进行一次refined sampling。通过PDF的值,把最不重要的方向全部过滤掉,让采样尽量集中在这个很重要的方向。这个方向可能来自于法向朝那个法向的分布,也可能来自于光源。

统一射线方向 vs 重要性采样后的光线方向:左边是统一射线方向,右边是重要性采样后的光线方向。可以看到,重要性采样后,更多的光线集中在窗户和明亮区域,更少的光线射向暗处。这样整个rendering的结果就会好很多。

对比结果:左边没有重要性采样,右边有重要性采样。可以看到,有importance sampling时,对光的采样就会好很多,GI的效果就会稳定非常多。场景都是室内,都有一张窗子,窗子就是GI的一生之敌。有一扇窗子,有importance sampling时,对光的采样就会好很多。

对比结果2:左边没有重要性采样,右边有重要性采样。可以看到明显的差异。

对比结果3:左边没有重要性采样,右边有重要性采样。可以看到,有importance sampling时,场景的GI效果明显更好。
降噪和空间探测器滤波
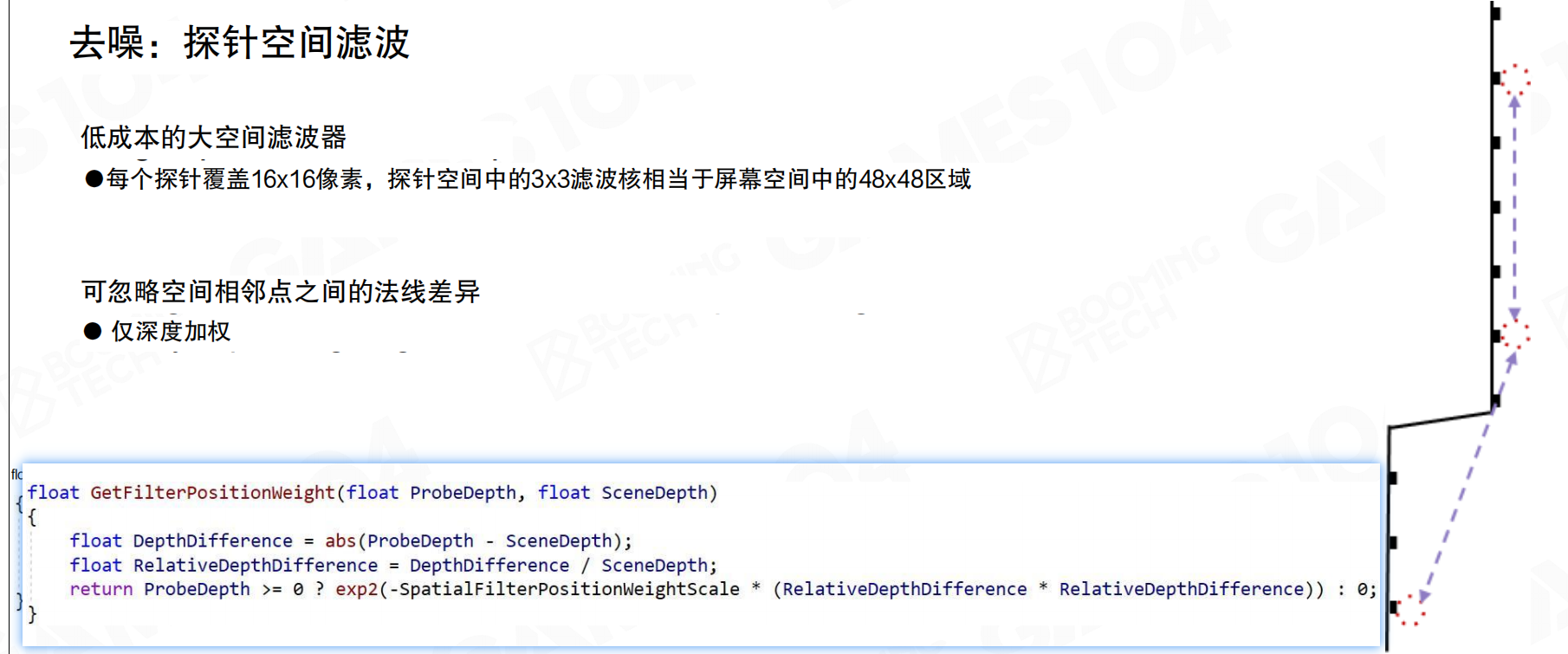
去噪:探针空间滤波:低成本的大空间滤波器。每个探针覆盖16×16像素,探针空间中的3×3滤波核相当于屏幕空间中的48×48区域。可忽略空间相邻点之间的法线差异,仅深度加权。
按16×16的screen space tile采样的probe,信息仍然不稳定,有很多noise。每个probe查找临近的一圈,使用3×3 kernel,将周边probe的光线进行filter。probe之间的filtering比预想的要复杂。

去噪:从邻近点采集辐射度:从相邻探针的匹配八面体单元中收集辐射度。误差权重:重投影相邻射线命中的角度误差(小于10度),过滤远距离光照,保留局部阴影效果。
每个probe发射64根ray。相邻probe同方向的ray,能否直接累加?实际上不行。相邻probe距离不同,它测试的ray射到的物体可能离当前probe很近,该物体在当前probe中,看过去的射线角度完全不同。例如:前面有个反射物,光源在头顶照射,该表面很亮,当前light probe需要采样。但相邻probe的那根ray方向朝下,如果直接使用该ray,结果完全错误。因为对当前probe,该方向是从上面过来的。加权这些ray时,需要检查方向,如果方向不一致,认为该ray方向不一致。
所有neighbor probe的所有ray需要进行可用性检测。如果夹角超过10度,不使用该ray。如果不处理,墙上会有很多noise,因为临近会采样错误。

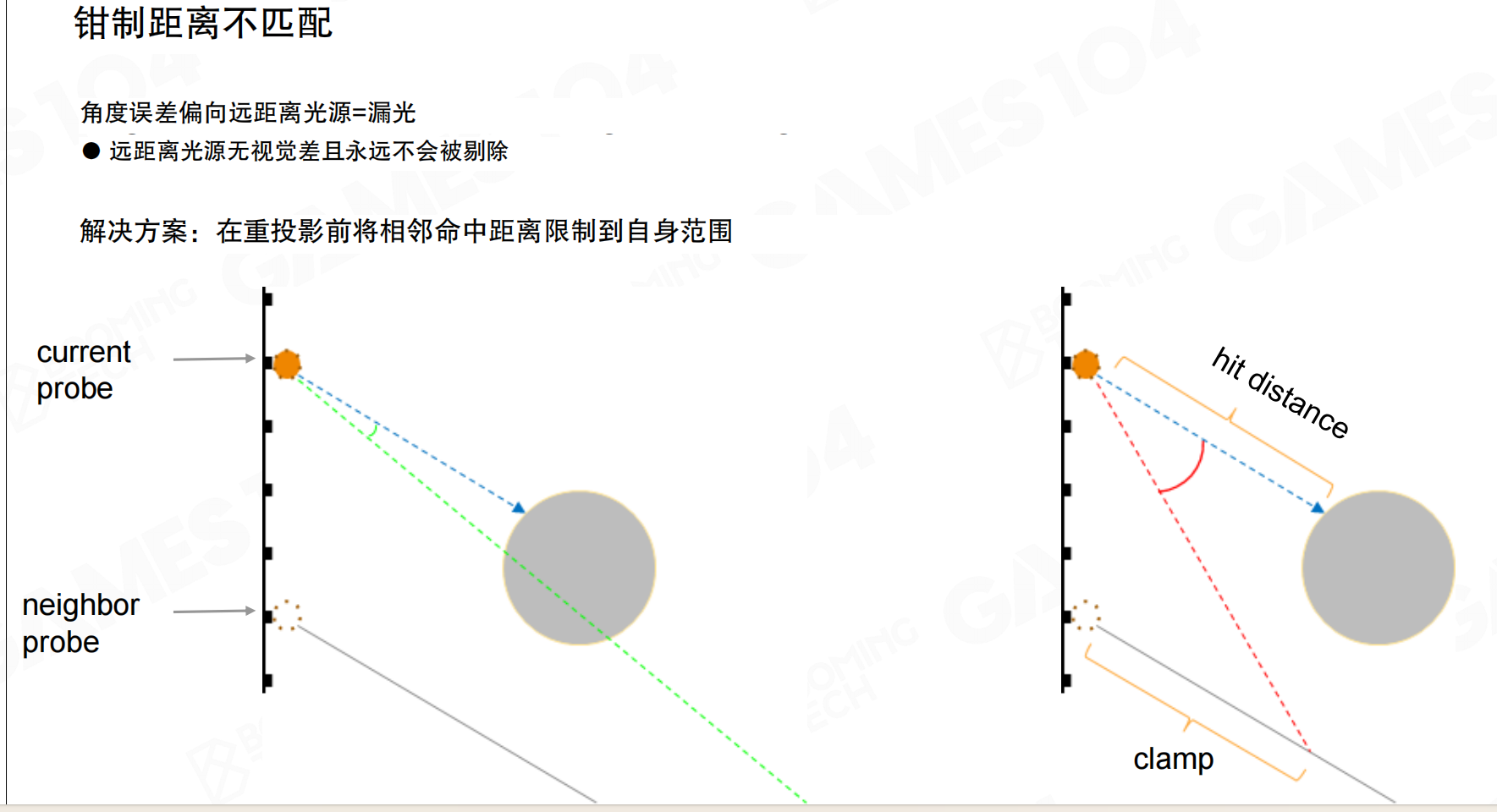
钳制距离不匹配:角度误差偏向远距离光源=漏光。远距离光源无视觉差且永远不会被剔除。解决方案:在重投影前将相邻命中距离限制到自身范围。
假设相邻ray射得很远,将远处焦点拉回,角度对了,没问题。但检查自己,发现同样角度测试的光线,射到的距离很近。两个ray之间,蓝色和绿色线的夹角虽然小于10度阈值,但hit distance差距很大。这里再次hack:虽然夹角很接近,但你在100米外打中物体,我在同方向测试时5米外就被挡住了,所以你的radiance对我无效,仍然使用自己的。这可以解决该问题。不解决的话,会出现漏光。例如毛巾内侧面靠墙处,如果不考虑这个差值,会发白很多,光被插值漏进来了。考虑这个问题后,光照会更合理。
最终过滤对比:左边没有过滤,右边有过滤。可以看到,有过滤时,墙和毛巾的细节更清晰,噪点更少。

最终过滤对比2:左边没有过滤,右边有过滤。可以看到明显的差异。
世界空间探针和光线连接

世界空间辐射度缓存:问题:远距离光照。小尺寸高亮特征产生的噪点随距离增加而加剧,长程非相干光线追踪速度较慢,远距离光照变化缓慢——存在缓存优化空间,邻近屏幕探针的冗余操作。解决方案:对远距离辐射进行独立采样。用于远距离光照的世界空间辐射度缓存,世界空间中的稳定误差——易于隐藏。
虽然可以在screen space做很多probe,但这些probe数量庞大,shading距离过远,效率不高。如果每个screen space probe的每个ray都跑得很远,效率很低。retracing性能不仅受ray数量影响,还受场景复杂度和ray距离影响。如果retracing距离很近,效率很高,但如果射得很远,如100米远,效率会很低。
在world space预先放置一些probe,这些probe缓存远处的lighting。当screen space probe需要某个方向的ray时,可以找沿途较近的world space probe,从中获取该方向的光线。这个方案很实用。如果场景不动,光源固定,主要是太阳光,相机走动时,screen space probe一直不稳定,每帧都需要更新。但如果在world space预先布置probe,使用clipmap方法部署,移动时只需在边缘增加几个probe,后面删除几个probe即可。只需更新少量probe,就可以获得远处良好的光线采集。
就像在城市里设置路标。screen space probe就像你手里的指南针,每走一步方向都在变,需要重新校准。但world space probe就像城市里的固定路标,告诉你”这个方向有什么”。当你需要知道远处的情况时,不需要自己跑过去看,只需要问附近的路标。就像用GPS:不需要每个地方都去,只需要在关键位置设置GPS点,其他地方可以查询这些点的信息。world space probe就是GI的”GPS点”,预先记录远处的光照信息。
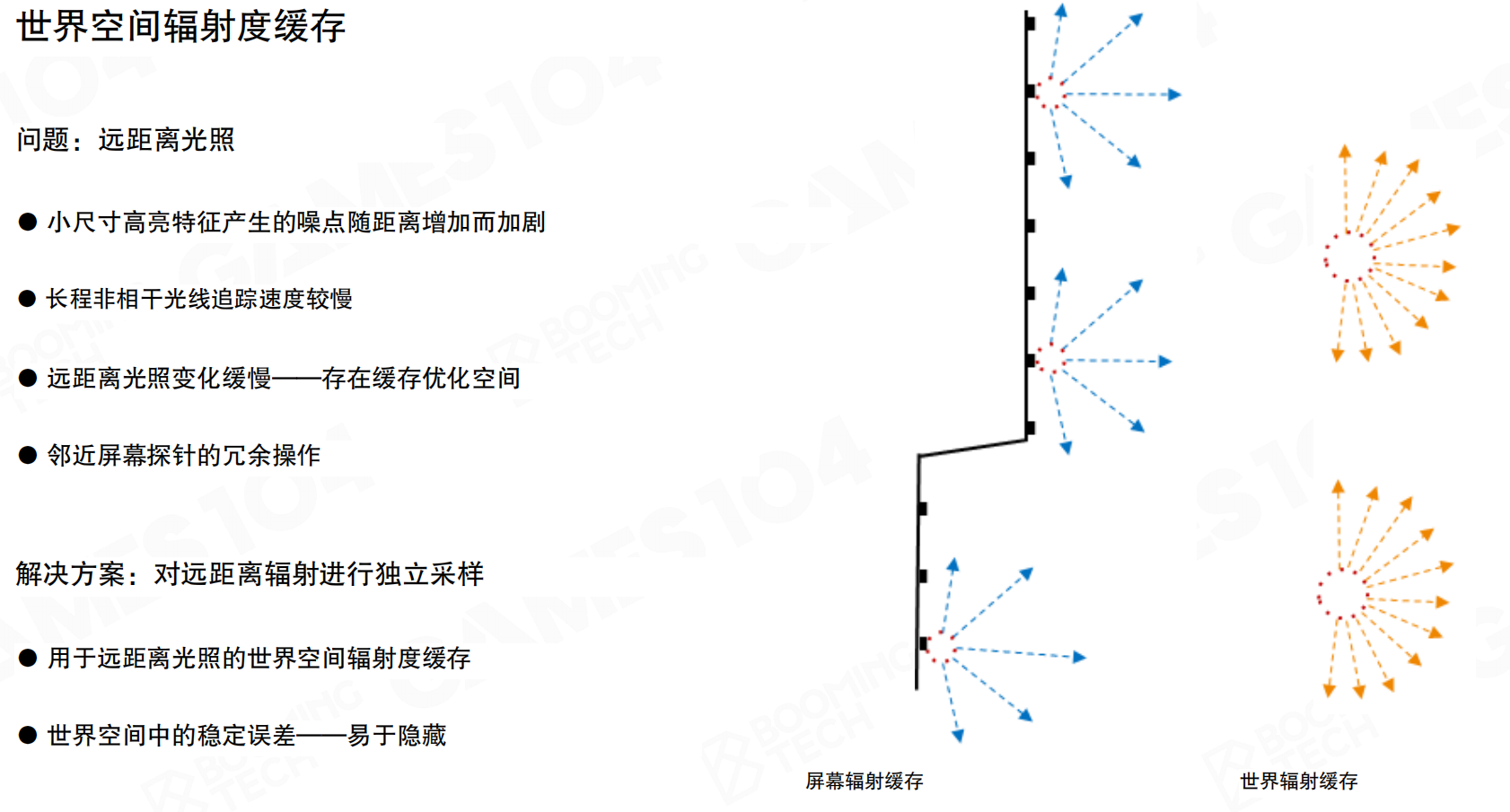
世界空间辐射缓存配置:围绕摄像机设置4级Clipmap,默认分辨率为48^3,clipmap 0尺寸为50m^3。每个探针使用32×32图集。
world space probe可能被screen space probe采用。screen space的采样角度在整个球面上是8×8,球面上8×8采样很稀疏。作为world space probe,放置在外面作为参考,作为最后的后备方案,应该采样更密。无论哪个screen space probe,无论什么方向,world space probe都能跟得上。它的采样会更密,采样到32×32,约1000多个ray。world space probe采样距离远,采样密度高。很多时候screen space probe不用跑很远,只需跑到附近的world space probe,借用它的光。
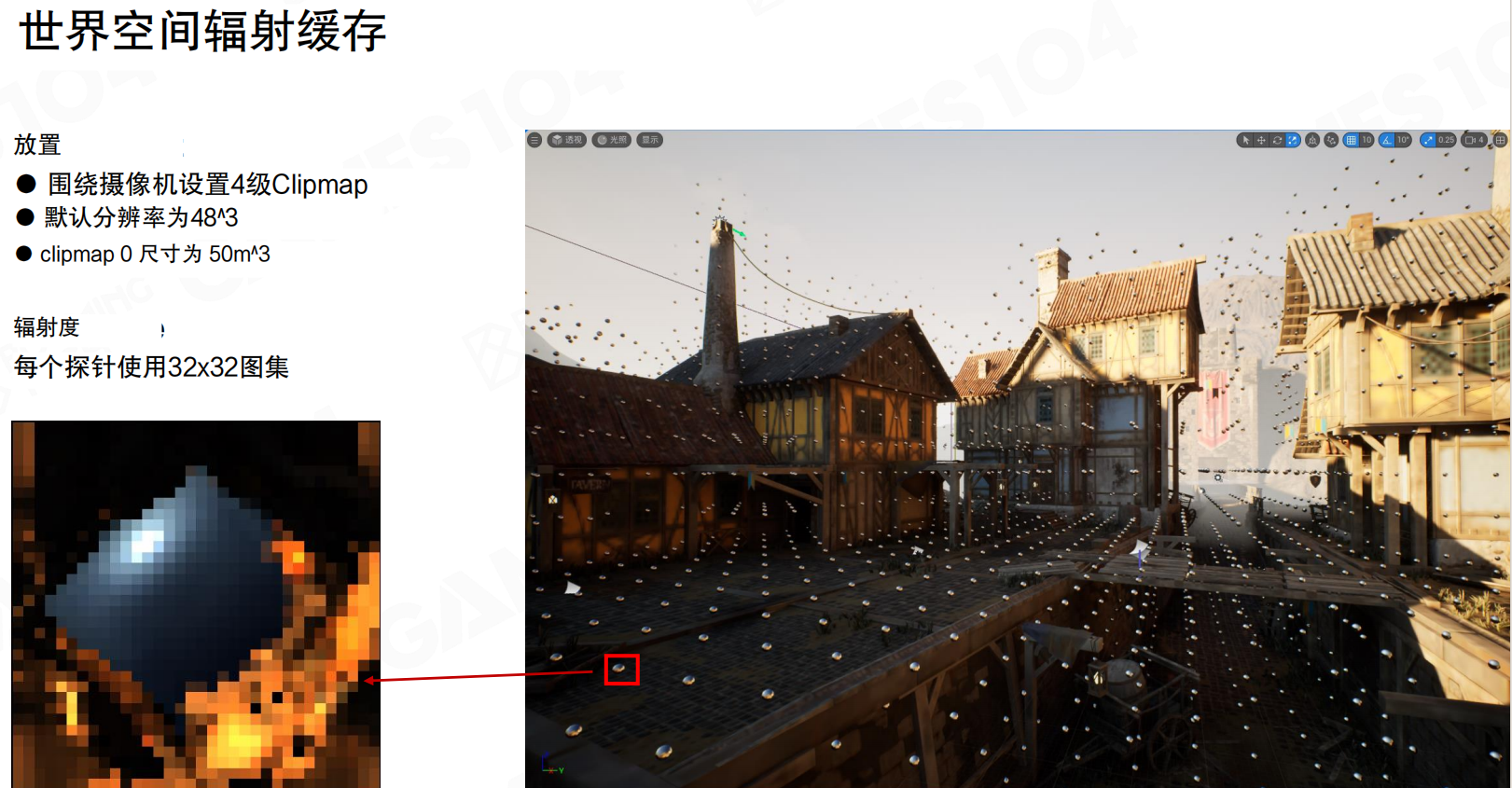
连接光线:如何连接屏幕探针光线与世界探针光线。屏幕探针光线必须覆盖插值足迹+跳跃距离。世界探针射线必须跳过插值覆盖区域。
如何连接光线?类似接骨头,光分成一节节的。screen space probe的ray只走一小段,当走到临近的world space probe时,检查该方向是否也有ray发射出去,如果有,就接上,询问远处有没有物体,如果有物体,亮度多少。这个设计合理。
就像接力传递信息。screen space probe的ray只负责近处的一段路,走到world space probe附近时,把”接力棒”传给world space probe,让它继续往远处查。就像快递:本地快递员只负责送到中转站,中转站的快递员负责送到更远的地方。这样每个probe只需要负责自己附近的范围,不需要跑太远,效率高。而且world space probe的ray采样更密集,就像中转站有更详细的路线图,可以提供更准确的信息。

连接光线2:屏幕探针射线必须覆盖插值足迹+跳跃距离。世界探针射线必须跳过插值覆盖区域。
在screen space做retracing时,大概只找最近的world space bounding,取对角线长度的两倍,其他不走。注意:screen space probe这个ray走的长度不是定长。近处的screen probe,对应的world space voxel密度高,距离约1米×1米,对角线两倍约2-3米左右。但到远处,虽然也在screen space,但远处房子距离约50米,此时world space的voxel已经很大,ray跑的距离会更远。这一点需要注意,不要写死,有很深的原因。同样,world space probe的ray采样时会skip自己对角线长的距离,没必要进出,不要采样,因为认为近处screen space probe已经采样完了,只提供采样不到地方的ray。这样recasting起点可以往外推,变相缩短距离,同时避免重复采样。
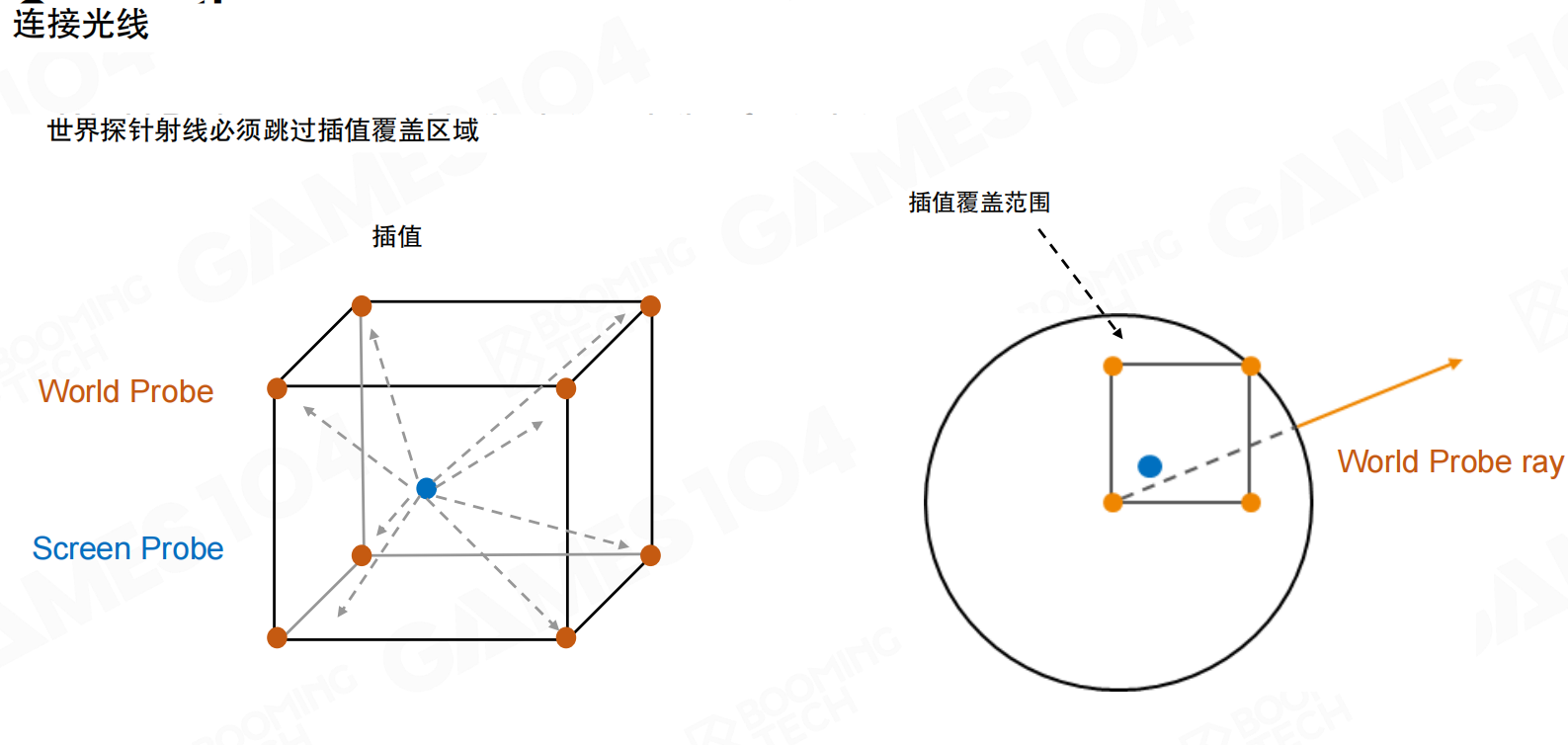
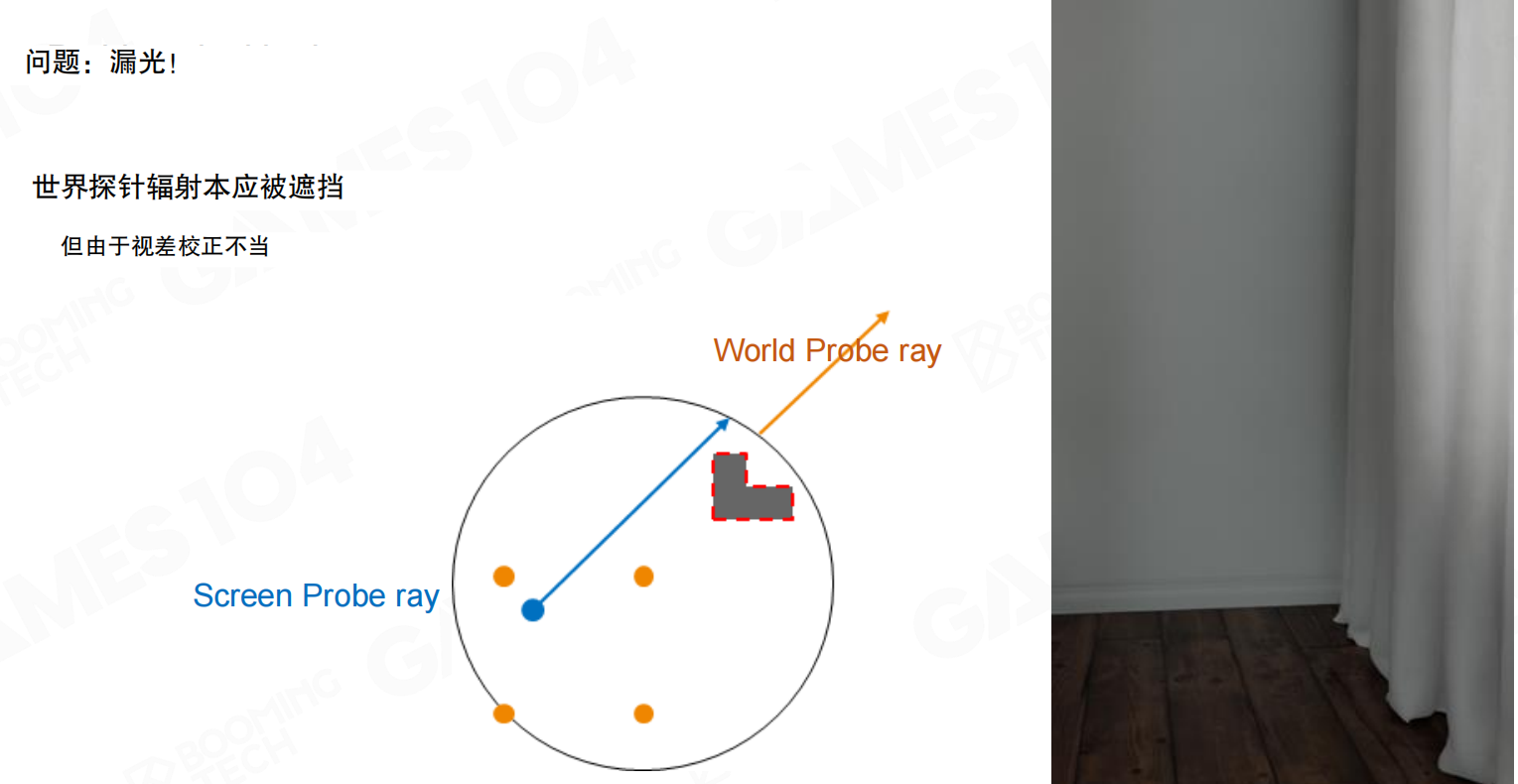
问题:漏光:世界探针辐射本应被遮挡,但由于视差校正不当。Screen Probe ray和World Probe ray在关系上出现偏差。
会有很多artifact。从screen space发射ray,很难找到正好穿过world space probe中心点的情况,ray只能沿相同方式查找,这会产生问题。这个artifact的情况:在screen space找到probe,在world space查找时,可能会跳过靠近的遮挡物,导致漏光。
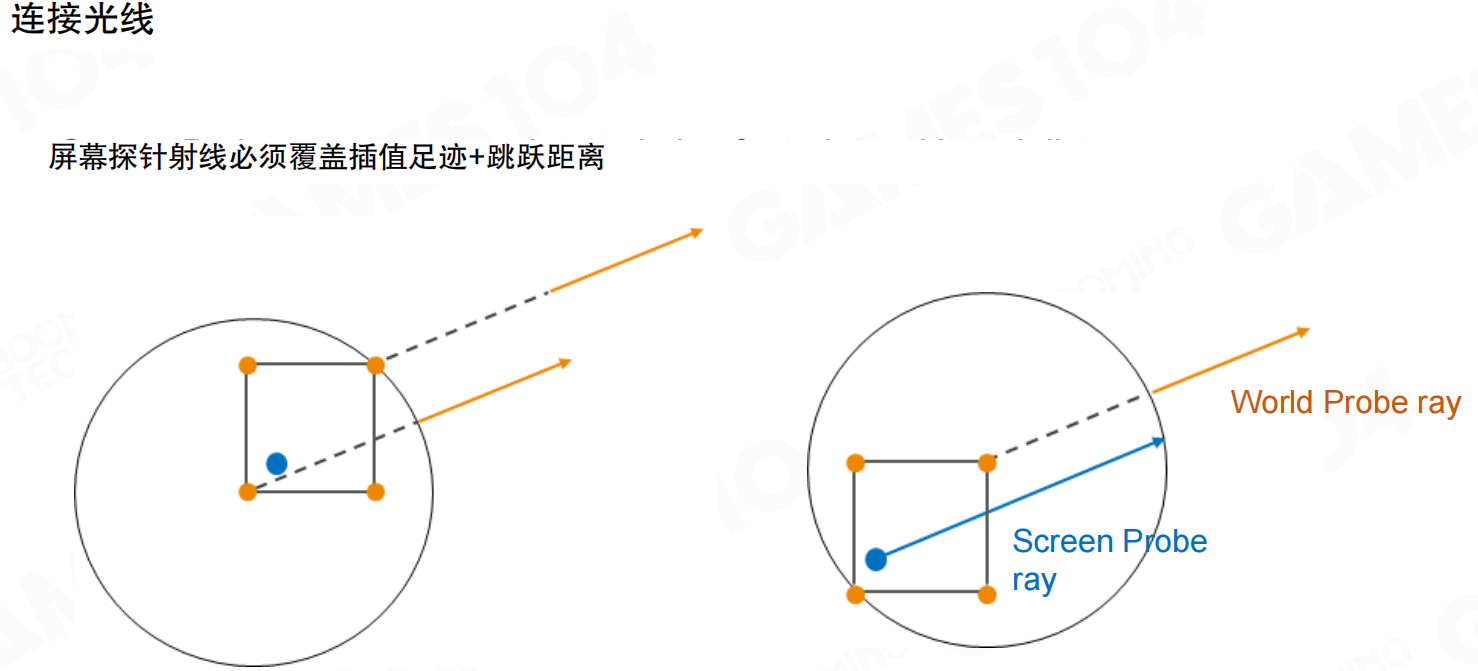
解决方案:采用简易球面视差法:将屏幕探测器光线与世界探测器球体的交点进行重投影。
rendering的hack方法:让光线弯曲。做gaming和rendering时,有时不需要完全遵循物理正确,光线需要拐弯时就让它拐弯。方法简单:求到最近的world space采样的SDF编码,找到焦点,用焦点和中心连线,然后沿该线出去,实际上光转弯了。这个转弯避免了不正确的visibility问题。这是一个hack,但能解决部分漏光问题,虽然不是所有问题。
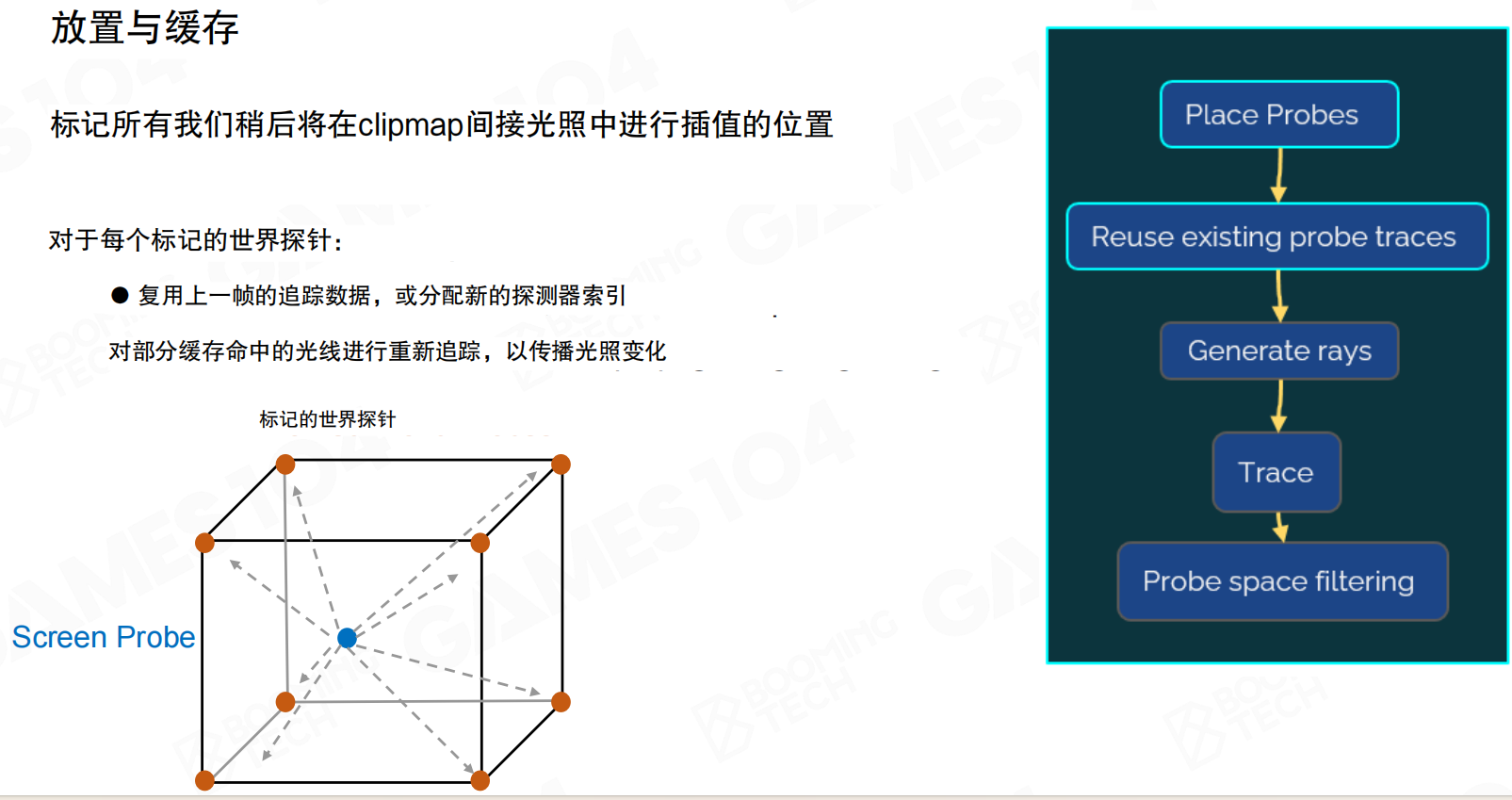
放置与缓存:标记所有稍后将在clipmap间接光照中进行插值的位置。对于每个标记的世界探针:复用上一帧的追踪数据,或分配新的探测器索引;对部分缓存命中的光线进行重新追踪,以传播光照变化。
world space这样的一个probe放在这了,每一帧到底要更新多少?其实刚才讲了这么多的probe,但在lumen至少我自己看下来它的shading,看下来shading是什么呢?它还是用屏幕空间probe,因为只有screen space这些pixel是有用的,因为去渲染它。world probe只是帮助去快速的去采集这些,帮这些在就贴近物体表面的这些probe去获取远处的光线。所以world probe去采样时,如果这个这么大的空间是没有东西,而且也没有物体,也不在screen space里面的话,其实那些地方的probe是不需要采样的。world probe只有被screen space probe有插值需求。什么叫有插值需求?那么多screen probe里面,它周围的八个screen probe它会标记为marked,只有这些被Mark的world space probe,才有必要进行采样。所以它可以采集的那么高,32×32,也可以踩得很远,就是因为它不需要48×48×48再乘4×4那么多的probe,每一次都要去更新,那个就是那么多的ray,它其实不需要了。第一个就是它只有Mark的world space probe需要被更新。第二件事情,刚才也讲到了,就是不动的时候,如果场景没有变,光没有变,它也不需要更新。

无世界空间探针 vs 有世界空间探针:左边没有世界空间探针,右边有世界空间探针。可以看到,有world space probe时,光照效果明显更好。
前2米范围内使用屏幕辐射缓存:世界辐射缓存适用于任何超出此范围的照明。
如果只是用screen space的这个probe,如果只有2米的话,看到的结果大概是这个样子的。但如果world space给它增加一下,可以看到这个光看上去就准确的多了,这个结果就看起来更加符合retracing真正一个想,GI真正想实现的效果。在没有world space probe的时候,它实际上这个光其实是很不正确的,是漏了很多东西,因为很多ray它不对。但这个时候它的光就相当于正确一点。

对比结果:左边没有world space probe,右边有world space probe。可以看到明显的差异。

对比结果2:左边没有world space probe,右边有world space probe。可以看到,有world space probe时,场景的GI效果明显更好,光照更准确,漏光问题得到解决。
21.10 Lumen:使用屏幕空间探针为全像素着色
最后一步是shading,要把屏幕上每一个像素都点亮。虽然前面做了mesh card、voxel lighting、screen space probe的adaptive sampling、world space probe连接、filtering、importance sampling,但最终还是在屏幕空间生成了无数的screen space probe。这时需要把这些probe的光照信息用于每个像素的着色。

将探头辐射度转换为三阶球谐函数:每个屏幕探针独立计算球谐函数(SH)。全分辨率像素以连贯方式加载球谐函数数据。SH漫反射积分成本低廉且质量优异。通过BRDF重要性采样获取射线方向,随后对辐射缓存进行采样。
虽然做了importance sampling,但如果对indirect lighting用单个方向采集的光,仍然很不稳定,有很多noise。将这些光投影到SH上。SH本质上对整个indirect lighting光进行低通滤波,变成低频信号。将光投影到SH后,probe用它做shading时,看起来会柔和很多。
每个screen probe的8×8采样结果转换为SH表示。SH是球面上的正交基函数,可以表示任意方向函数。三阶SH有9个系数,可以表示低频的光照变化。对于diffuse材质,SH积分有解析解,计算成本很低。
SH的作用就像用几个简单的形状来近似一个复杂的球面分布。想象一个球,表面有复杂的光照图案,直接存储需要很多数据。但用SH,就像用几个简单的”波形”叠加,用9个数字就能大致描述整个球面的光照。虽然细节会丢失(高频信息被过滤),但间接光照本身就是低频的,这种近似足够好。就像用几个简单的音符就能表达一首歌的旋律,不需要记录每个瞬间的精确频率。SH的低通滤波特性正好适合间接光照:去掉噪点,保留平滑的光照变化。

最终通过球谐函数进行积分:将probe的radiance(左上的网格点)和BRDF(左下的彩色渲染)通过SH进行积分,得到最终的shading结果(右边的洞穴图像)。
对于每个像素,从四个相邻的screen probe中采样SH系数,进行双线性插值,得到该像素位置的SH表示。然后用这个SH和该像素的法线、材质属性进行积分,得到最终的indirect lighting。这个过程很快,因为SH积分有解析解,不需要额外的ray tracing。
最终结果效果好。虽然probe采样不完全uniform(有adaptive sampling,8×8、4×4挂在下面),但通过SH的低通滤波,这些细节被平滑,得到柔和、自然的间接光照效果。
21.11 Lumen:总体性能与结果
Lumen是一个复杂的系统,集成了过去十几年real-time GI研究的成果。它要解决一个非常难的工程问题:在实战的游戏里,真的把这套GI算法变成一个real-time,而且能处理很多动态光源的复杂情况。
不同追踪方法的成本对比
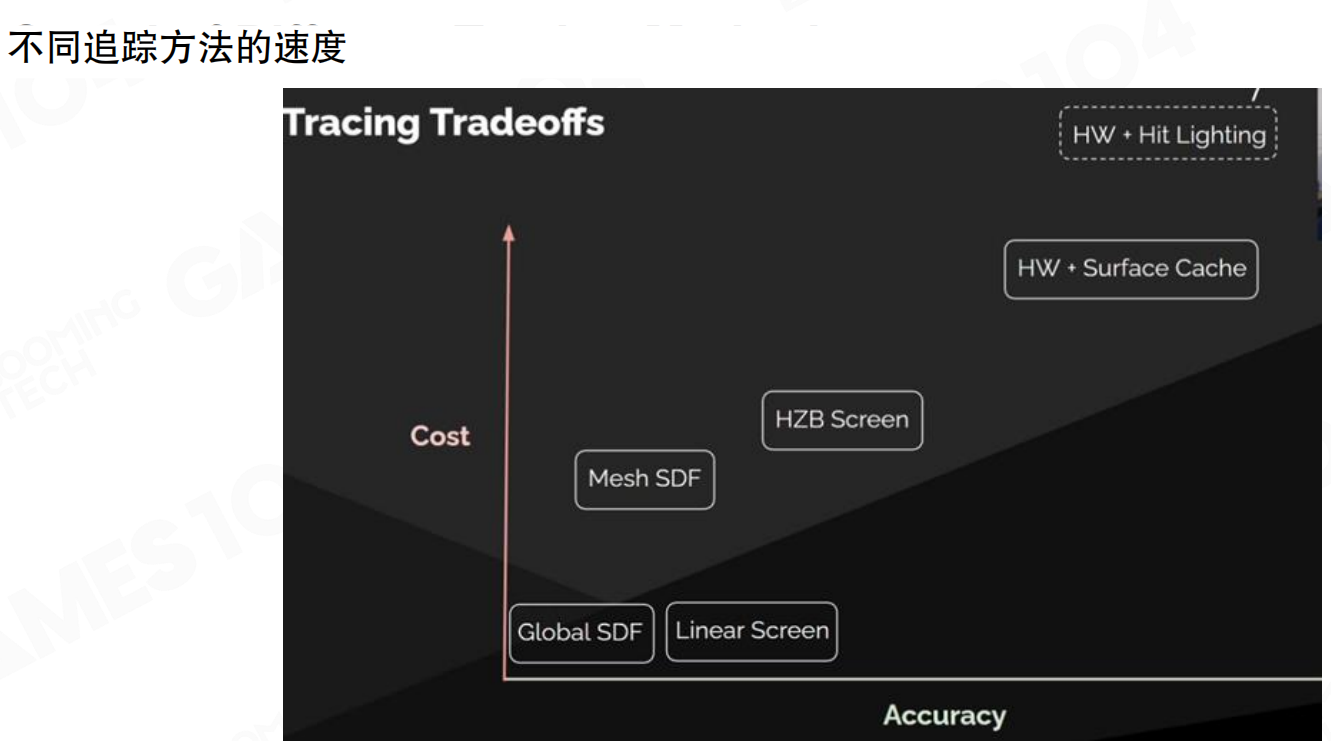
不同追踪方法的速度:成本vs准确度的权衡。最快的是基于Global SDF,其次是屏幕空间linear step,然后是mesh SDF(per-mesh SDF ray trace,但前提是跨的步骤不要太大,不要一下子involve太多的mesh,如果太多mesh的话速度非常慢),HZB screen space ray tracing稍微比linear step慢一点但准确度更高,hardware ray tracing准确度最高但cost比较大,hardware ray tracing + Surface Cache成本也很高。
Lumen的核心思想是:对于不同的ray tracing,在硬件上它的成本是不一样的。利用这个特点,可以构建一个级联的fallback机制,先用最快的,失败了再用次快的,以此类推。
追踪方法的级联机制

不同追踪方法的未命中可视化:红色-屏幕空间追踪未命中,绿色-网格SDF追踪未命中,蓝色-全局SDF追踪未命中。可以看到,不同区域使用不同的追踪方法,形成渐变的效果。
如果每个pixel的probe tracing方法是单一的话,应该看到三个颜色的图。但现在看到的是渐变图。对于每个screen probe,要踩8×8 64个方向,这64个方向里面有多少个方向用screen space trace,多少用mesh SDF trace,多少用global SDF trace,其实是有权重的。所以可以看到这样一个渐变的东西。
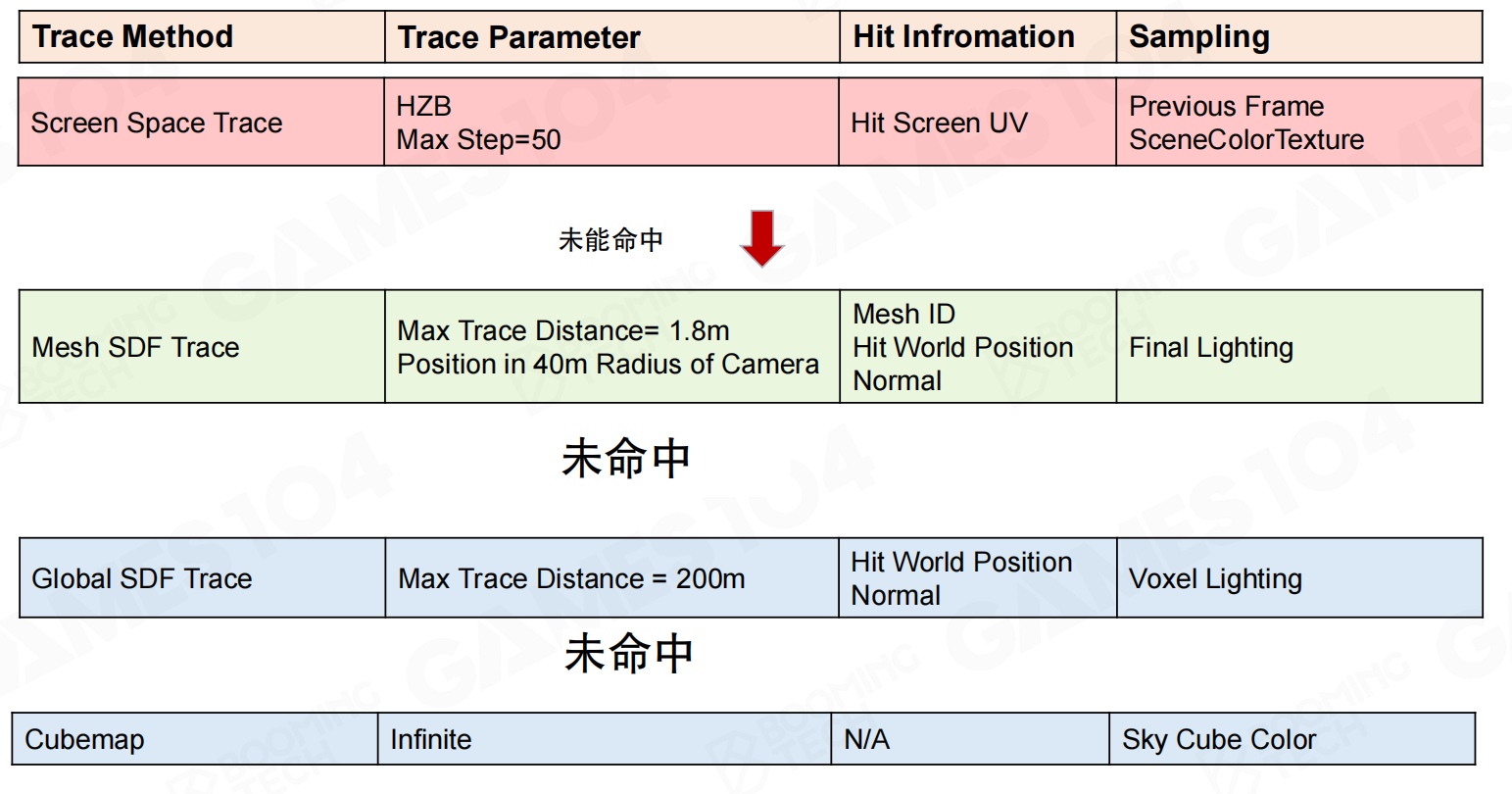
追踪方法的级联fallback机制:
Screen Space Trace:HZB,Max Step=50。如果命中,返回Hit Screen UV,采样Previous Frame SceneColorTexture。如果未命中,fallback到下一个方法。
Mesh SDF Trace:Max Trace Distance=1.8m,Position在40m半径内。如果命中,返回Mesh ID、Hit World Position、Normal,采样Final Lighting(Surface Cache)。如果未命中,fallback到下一个方法。
Global SDF Trace:Max Trace Distance=200m。如果命中,返回Hit World Position、Normal,采样Voxel Lighting。如果未命中,fallback到下一个方法。
Cubemap:Infinite,采样Sky Cube Color。
Lumen的核心是怎么快速做tracing。首先用screen space trace,基于HZB去trace,最多50步,如果能trace得到,就把结果拿过来。如果screen space trace拿不到,用mesh SDF trace。mesh SDF trace的距离非常近,只有1.8米(从代码中翻出来的),而且只在相机40米之内才会用mesh SDF。这时可以返回更详细的数据:mesh ID、hit world position、normal,可以直接送到final lighting去sample,因为有Surface Cache。
如果再远一点,比如200米,如果前两个条件都不满足(要么trace的距离太远,超过1.8米,要么position超过40米),就用global SDF,一次性走200米。但global SDF能拿过来的东西只有voxel lighting。所以voxel lighting非常重要,对于整个Lumen的光照采集。可以理解成probe是采集的结果,但采集的源头是Surface Cache和voxel lighting。
如果global SDF tracing也失败了,还有一招:踩到天球上去。天球是无穷远,采来的就是天光。这个hack其实非常有道理。对真实场景表达时,对天空的很多probe,天上有蓝天白云,这些东西可能云还在动,它对于表面的光照影响还是蛮大的。天光其实很多时候是很亮很亮的。如果写Lumen时把这一趴少写,对效果应该会影响特别大。
SSGI的重要性

SSGI关闭:可以看到场景的反射和间接光照效果较差。

SSGI开启:可以看到场景的反射和间接光照效果明显改善,特别是地面的反射和倒影。
SSGI听上去是一个hack(screen space),但Lumen中SSGI还是蛮重要的。如果只有Lumen,看到的结果中倒影看着很粗糙。但对于高频的、近处的这些东西,SSGI还是蛮重要。仔细比较这两个图的区别,可以看到SSGI对近处细节的影响。假设有人想黑Lumen,说下面用的就是SSGI,这个黑既对也错。对,Lumen确实离了SSGI的一些基础思想确实也很难work。错,Lumen本身很复杂很丰富。
性能分析
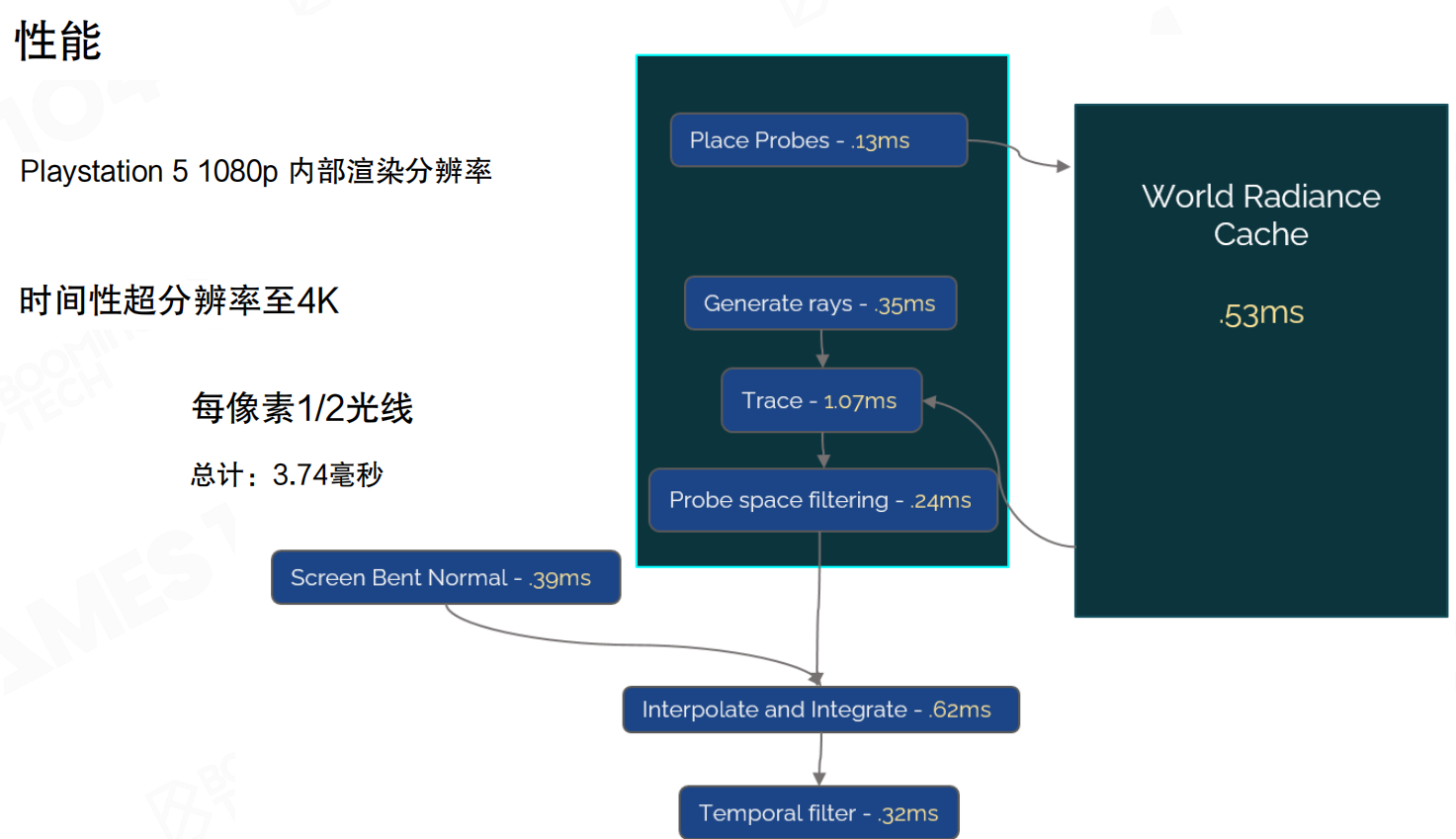
PlayStation 5性能分解:1080p内部渲染分辨率,时间性超分辨率至4K,每像素1/2光线,总计3.74ms。
- Place Probes: 0.13ms
- Generate rays: 0.35ms
- Trace: 1.07ms(最耗时)
- Probe space filtering: 0.24ms
- World Radiance Cache: 0.53ms
- Screen Bent Normal: 0.39ms
- Interpolate and Integrate: 0.62ms
- Temporal filter: 0.32ms
Lumen最了不起的地方还是在工程上,真的完成了交付。在PS5的硬件平台上,PS5的GPU还是很强的,但CPU其实一般,GPU跟现在的显卡来讲还是有一些差距,但能做到3.74ms就做完了。
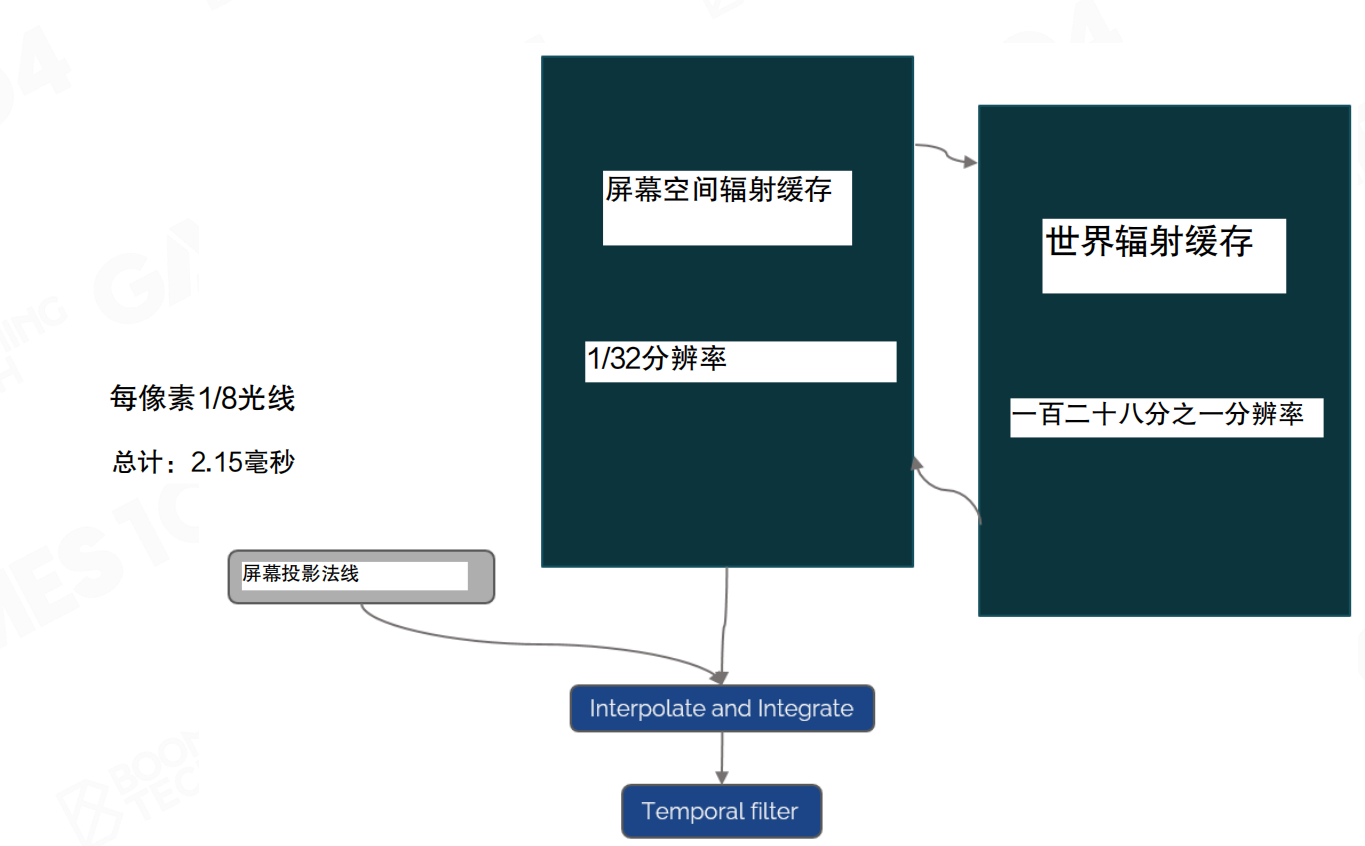
低分辨率性能分解:每像素1/8光线,总计2.15ms。屏幕空间辐射缓存1/32分辨率,世界辐射缓存1/128分辨率。
如果愿意把screen space那个光线问题最严重的节拍问题,分辨率下降四倍,效率可以更高,从3.74ms下降到2.15ms。当然,损失掉的是精度。可以看到这个里面是相对比较low resolution的screen probe,结果看上去已经非常amazing了。但如果用full resolution的时候,可以看到更多的光照细节。所以16×16的pixel的选择,作者肯定也做了大量的尝试,8×8肯定试过了,32×32肯定也试过了,这可能是他们最后觉得是一个大家最能接受的东西。而且这个东西可能和他们在UE5里面和这种复杂的场景密度去进行了一个配合,他们选择了一个最好的适配。
渲染结果

洞穴场景(1/8 ray per pixel,2.15ms):低分辨率下的渲染结果,光照效果已经非常出色。

洞穴场景(½ ray per pixel,3.74ms):高分辨率下的渲染结果,可以看到更多的光照细节。

浴室场景:展示了Lumen在室内场景中的表现,光照自然,反射准确。

卧室场景:展示了Lumen在复杂室内场景中的表现,间接光照柔和自然,细节丰富。
Lumen的结果令人瞩目。它接近过去一些offline ray tracing render的效果,是很多室内设计师、效果图公司的目标。随着硬件发展、算法进步,几乎可以实时产生这个结果。这对整个电影行业、离线渲染行业、动画电影行业都是巨大影响。这也奠定了未来10年下一代游戏引擎渲染的基础标杆。GI应该是下一代顶级引擎的标配,只要做下一代引擎,GI是必须的。
真实渲染的复杂性
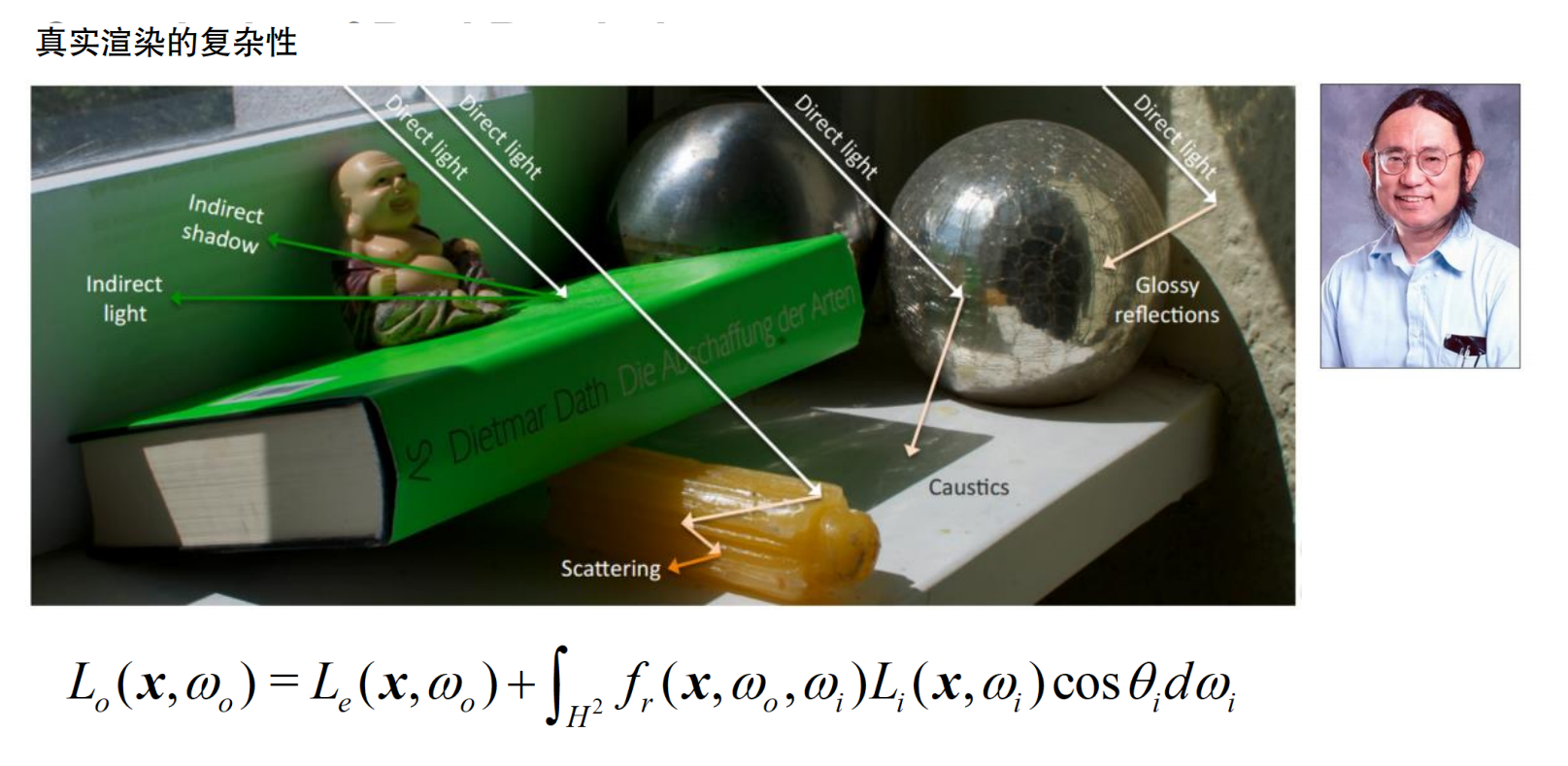
真实渲染的复杂性:展示了各种光传输现象:直接光照、间接光照、间接阴影、镜面反射、焦散、散射等。渲染方程:L_o(x, ω_o) = L_e(x, ω_o) + ∫_{H^2} f_r(x, ω_o, ω_i)L_i(x, ω_i) cosθ_i dω_i
Lumen只是这一系列工作的开始。可以看到Lumen做了大量妥协,基于这一代硬件。在未来10年随着硬件发展,real-time GI将更加成熟,可能更加简洁。Lumen是这个方向的开创者,奠定了这项技术。它的创作者必然会载入史册。作为程序员,要表达敬佩。这项工作非常了不起。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

