22.GPU驱动的几何管线Nanite
22.1 概述
Nanite是虚幻5提出的虚拟几何系统(Virtualized Geometry)。它关心的是“几何细节的交付方式”:在画质目标不变的前提下,让高密度几何在实时管线里变得可控、可扩展。
理解Nanite之前,先回顾一个更底层的问题:传统CPU驱动渲染(CPU-driven Rendering)在复杂场景里为什么会先触顶,以及GPU驱动渲染(GPU-driven Rendering)是如何被逼出来的。
传统渲染的长管线
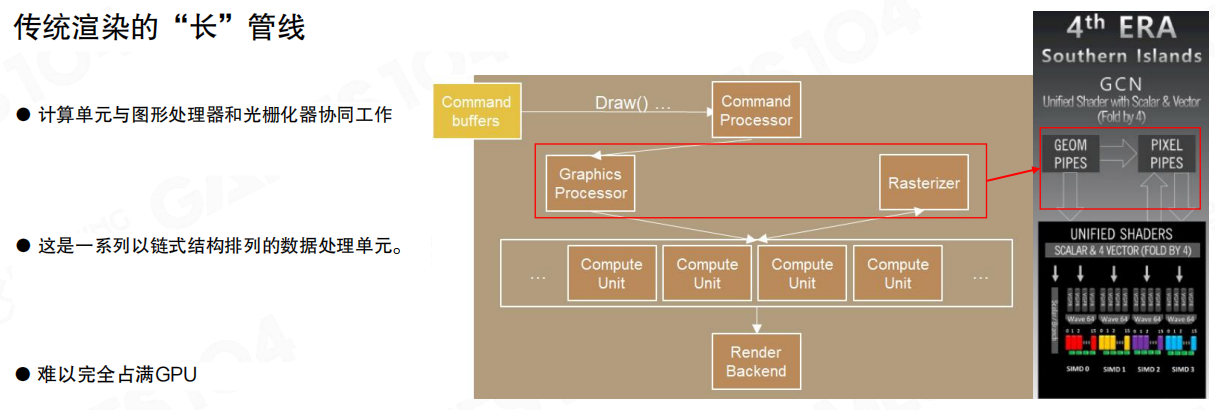
传统路径里,CPU发出 Draw(),命令写入命令缓冲(Command buffers),再由GPU的命令处理器(Command Processor)驱动图形管线(Graphics Processor → Rasterizer → Render Backend)。
链路越长,对前端供给越敏感:CPU侧一旦在状态准备、资源绑定、命令编码上卡顿,GPU端就会出现“空洞”,吞吐无法稳定拉满。
例如,同一帧里GPU可以持续以固定节奏处理像素与三角形,但CPU端若在某一批次切换材质/管线状态时抖一下,GPU就只能等待命令队列补齐。
Direct Draw 图形API的丛林

Direct Draw的问题不在“能不能画”,而在成本随复杂度快速放大。DrawCall数量通常由组合爆炸推高:
- 网格(Mesh)× 渲染状态(Render State)× 多级细节(LoD)× 材质(Material)× 动画(Animation)
两类常见代价:
- 参数准备开销:传统
DrawIndexedInstanced需要CPU侧逐次填写参数(例如IndexCountPerInstance / InstanceCount / StartIndexLocation / BaseVertexLocation / StartInstanceLocation)。对象一多,CPU时间会稳定消耗在“把参数写对、写全”上。 - 状态切换开销:绘制命令之间穿插Program/Texture/UBO/RenderTarget等切换。命令越碎,切换越频繁,驱动层的固定成本越难摊薄。
例如,一栋建筑往往不是“一个网格 + 一个材质”。窗框、屋顶、栏杆、贴花、透明材质可能对应不同的渲染状态;即使都属于同一个建筑实例,仍然会被拆成多次draw,提交开销会直接被放大。
传统渲染管线的瓶颈
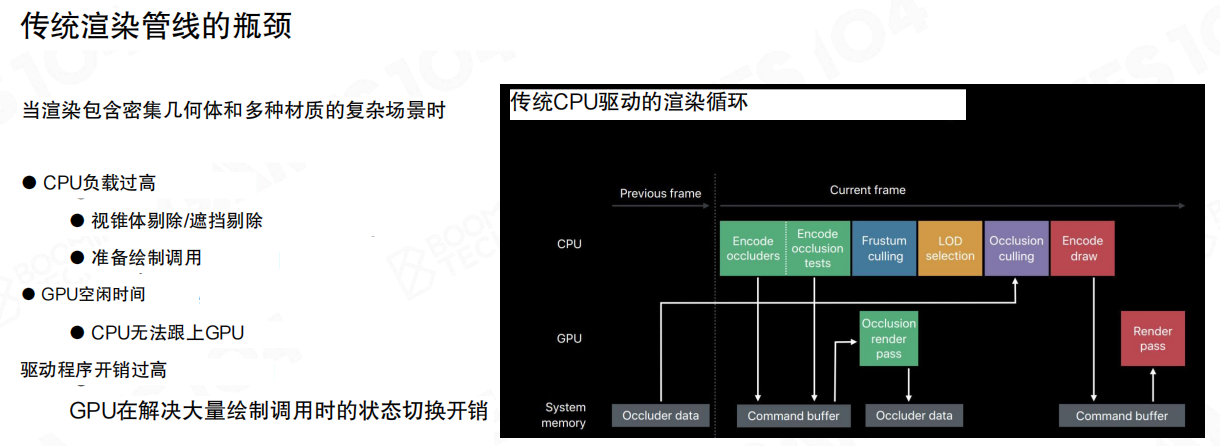
当场景进入“密集几何 + 多材质”的形态后,瓶颈往往落在CPU侧:
- CPU负载过高:视锥体剔除/遮挡剔除、LoD选择、资源绑定与draw编码。
- GPU空闲时间:CPU供给跟不上,GPU在等待命令与数据。
- 驱动程序开销过高:DrawCall碎片化放大提交与切换成本。
传统CPU驱动渲染循环可以理解为一段串行前置步骤:CPU先算可见性/LoD,再编码draw,最后交给GPU执行。前置步骤的时延波动会直接传导到GPU端。
一个常见现象是:GPU理论上还有算力空间,但帧时间被CPU端的剔除/排序/状态组织吃掉,表现为“GPU利用率不高但帧率上不去”。
Compute Shader:GPU通用计算
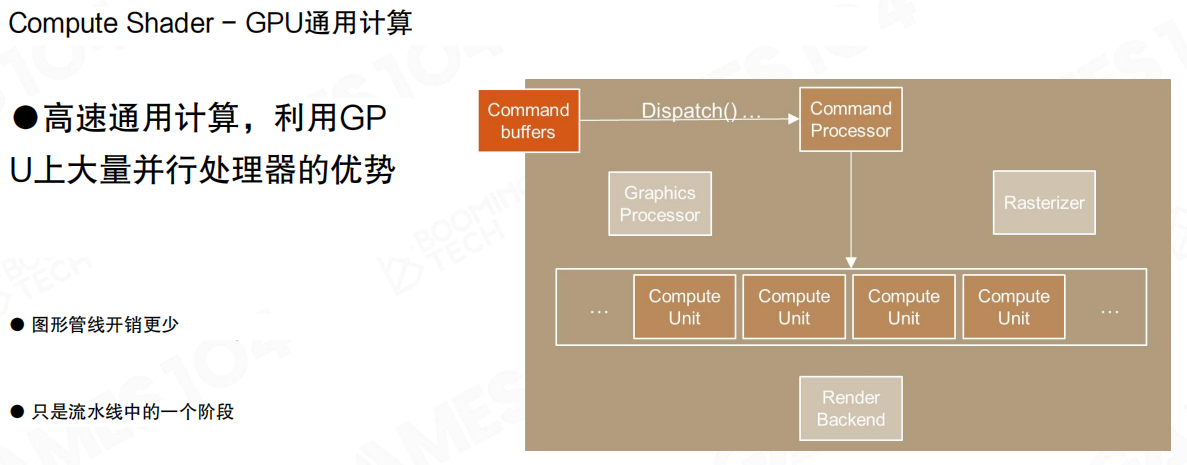
Compute Shader提供了一条可编程的GPU通用计算路径,把一部分“本来在CPU上做的数据并行任务”迁移到GPU侧:
- 吞吐更高:更适合大规模并行的筛选、归约与重排。
- 路径更短:很多工作不必走完整Graphics Pipeline。
- 工程落点明确:剔除、LoD选择、命令生成这类“数据处理”,开始可以在GPU侧闭环完成。
例如,把“对上万个对象做视锥剔除”从CPU循环改为GPU并行筛选,通常可以把这类工作从“每对象一次分支判断”变成“每线程一小段连续内存读写 + 简单算术”,更符合GPU擅长的模式。
间接绘制图形API:Draw-Indirect

在API层面,间接绘制(Indirect Draw)把“draw参数必须由CPU逐条准备”这条限制松开了:参数来自GPU缓冲区,并且可以由Compute Shader写入。
- 核心价值:把大量子绘制参数打包进一个buffer,CPU只做少量触发,GPU按表执行,提交与切换压力明显下降。
- 命名提示:不同平台叫法不同但语义一致,例如 Vulkan 的
vkCmdDrawIndexedIndirect、D3D12 的ExecuteIndirect。
可以把它看作“把draw列表当成数据”。CPU不再逐条调用draw,而是提交一次“执行这段参数表”的命令;参数表的生产过程也可以由GPU接管。
GPU驱动渲染:从DrawPrimitive到DrawScene
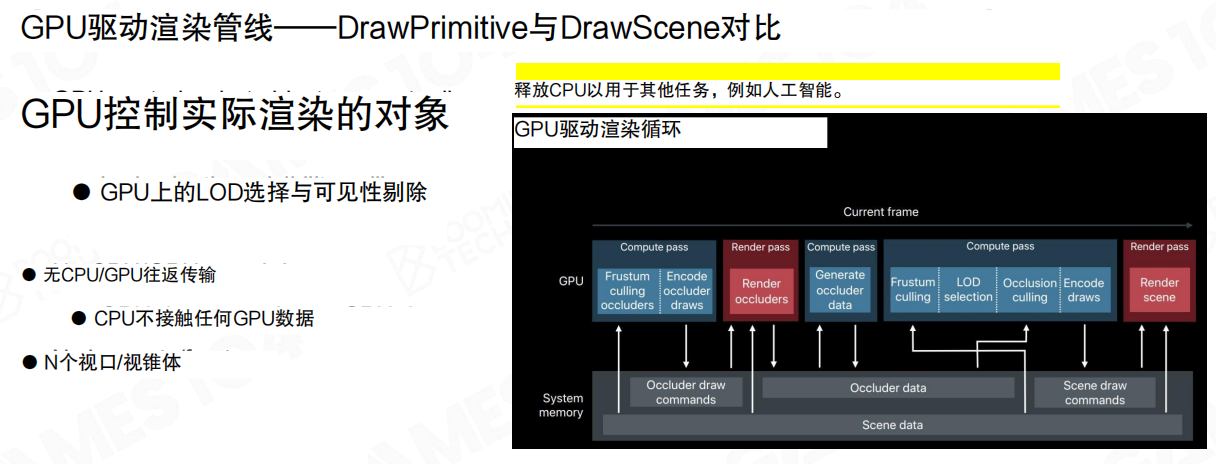
把Compute Shader与Indirect Draw拼起来,渲染组织方式就能从 DrawPrimitive 抬升到 DrawScene:
- GPU控制渲染对象:GPU侧完成LoD选择与可见性剔除(例如 Frustum Culling / Occlusion Culling)。
- 减少CPU/GPU往返:CPU主要负责相机与少量全局参数,不再逐对象组织draw参数。
- 释放CPU预算:把CPU留给游戏逻辑、AI、物理、网络等系统。
GPU驱动渲染循环的典型闭环是:GPU生成遮挡体与遮挡数据,在Compute阶段完成剔除与LoD选择,随后编码draw并渲染。
小结
- 传统模式的结构性问题不是“GPU不够快”,而是 DrawCall碎片化 与 状态切换 让CPU先成为瓶颈。
- Compute Shader 提供GPU侧通用计算路径;间接绘制(Indirect Draw)提供“GPU驱动绘制”的API通道。
- 这两者合在一起,形成“从DrawPrimitive到DrawScene”的GPU驱动几何管线(GPU Driven Geometry Pipeline),也是理解Nanite的起点。
22.2 《刺客信条》中的GPU驱动管线(GPU Driven Pipeline in Assassins Creed)

《刺客信条:大革命》把“几何复杂度”推到了一个新的量级:建筑结构细节、室内外无缝衔接、以及大规模人群同时存在。传统按对象提交draw的方式,在这里会被两件事拖垮:DrawCall数量与状态切换成本。
这套GPU驱动管线的策略很明确:剔除粒度尽量细,提交粒度尽量粗。

落地手段是网格簇渲染(Mesh Cluster Rendering)。几何不再以“整个网格/整个实例”为基本单位,而是被重编码成固定大小的簇(例如每簇64个三角形;Nanite常见是128个三角形)。
- 固定簇拓扑:把所有网格拆分并重组三角形以适配固定拓扑;不足部分用退化三角形补齐。
- 顶点获取方式变化:在着色器侧按索引/偏移手动取顶点,本质上是数据驱动的解码。
- GPU输出两类结果:可见簇列表 + 间接绘制参数。一次绘制调用中可覆盖任意数量的可见簇。
这一步解决的不是“如何画”,而是“如何把要画的东西组织成GPU更容易批处理的形态”。
例如,一栋建筑实例可能包含大量内凹结构与遮挡关系。若只按实例级剔除,只要建筑露出一个角,就会把整栋建筑的几何都送进后端;簇化之后,可见性判断可以推进到“建筑外立面一小块”,把大部分被遮挡的簇提前剔除。
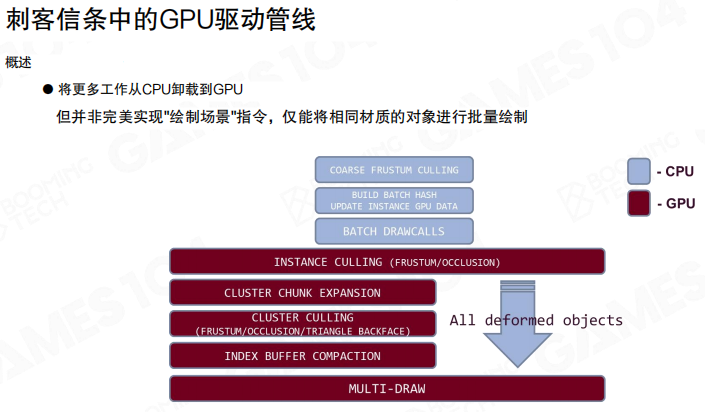
把整条流水线按阶段拆开,CPU侧只保留必要的批次组织;GPU侧把可见性与索引压缩做到底:
- CPU:
COARSE FRUSTUM CULLING→BUILD BATCH HASH / UPDATE INSTANCE GPU DATA→BATCH DRAWCALLS - GPU:
INSTANCE CULLING (FRUSTUM/OCCLUSION)→CLUSTER CHUNK EXPANSION→CLUSTER CULLING (FRUSTUM/OCCLUSION/TRIANGLE BACKFACE)→INDEX BUFFER COMPACTION→MULTI-DRAW
需要强调一点:这还不是完全意义上的DrawScene。CPU仍然要按材质/渲染状态分批(BATCH DRAWCALLS),否则后端绑定与PSO切换会把收益吃掉。

CPU端做的事情被刻意压到“粗而确定”的范围:
- 粗视锥剔除:先快速过滤明显不可见的实例。
- 批次构建:基于材质、渲染状态等非实例化数据构建哈希并组织批次。
- 实例数据更新:把变换、LoD因子等写入GPU缓冲区;静态实例数据可保持持久化,避免每帧重建。
CPU的目标不是算出“最后要画哪些三角形”,而是把“可处理的实例批次”尽快交给GPU。

GPU侧第一刀是实例剔除(Instance Culling),先按视锥/遮挡把实例层面的大头砍掉。随后做簇块扩展(Cluster Chunk Expansion):把可见实例映射成Chunk列表。
这里的设计点很工程化:每个Chunk包含固定数量的簇(这里是64簇),目的在于让工作负载更均匀,便于喂满wavefront/warp,减少线程分歧。
可以把Chunk理解为GPU侧的“工作包”:簇太小会导致任务碎片化,簇太大又会降低剔除收益。固定大小Chunk在调度与剔除粒度之间做了一个折中。
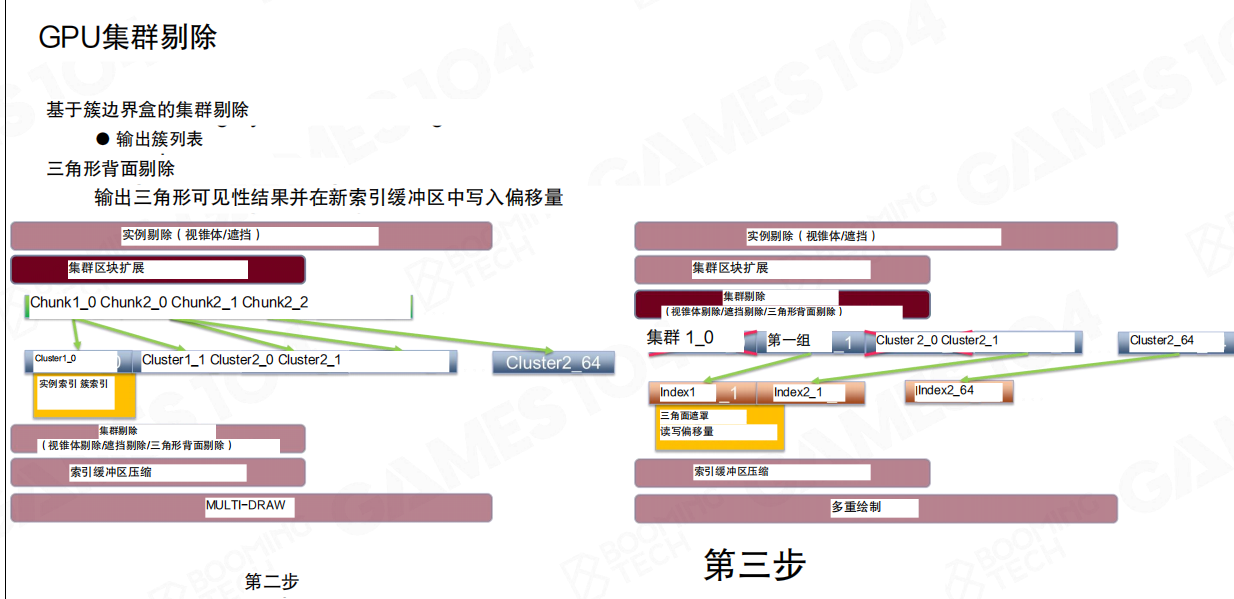
接下来是集群剔除(Cluster Culling):先在簇边界盒上做视锥/遮挡筛选,再推进到三角形级别处理,并叠加背面剔除(Triangle Backface)。
这一步的输出不止是“可见/不可见”,而是为后续索引重排准备的数据布局:把可见结果写入新的索引缓冲区偏移位置。
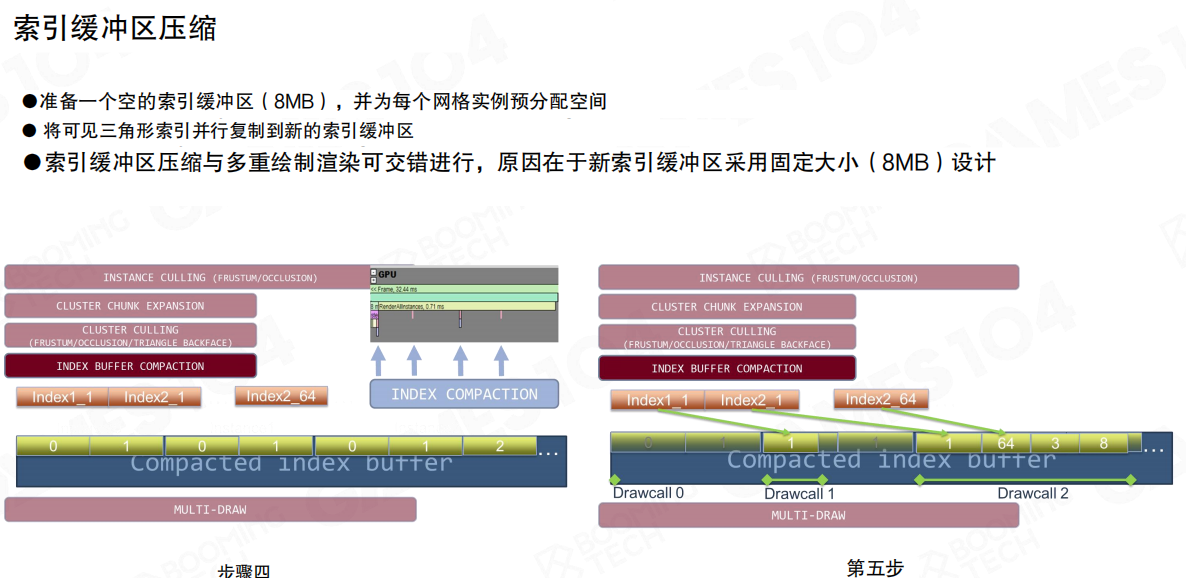
当可见三角形确定后,进入索引缓冲压缩(Index Buffer Compaction)阶段:
- 预先准备一个新的索引缓冲区(这里是固定大小8MB),并为各实例预分配写入空间。
- 可见三角形索引并行拷贝到新缓冲区。
- 压缩可以与
MULTI-DRAW交错执行:固定大小缓冲区的设计,使得“边压缩边提交”成为可能。
这一步把“可见性收益”兑现成“更少的真实光栅化工作量”。
例如,遮挡很强的街区视角里,最终可见三角形往往只占全量几何的一小部分。前面花在剔除与重排上的GPU计算,换回来的是Rasterizer/PS阶段的确定性减负。

三角形级可见性在这里还有一个典型编码方式:以簇为中心做立方体贴图(Cubemap)离散化,得到簇内三角形的可见性位图。
- 基于簇中心的立方体贴图像素视锥体烘焙三角形可见性。
- 运行时按相机视角查询立方体贴图。
- 用64位数据表达一个簇内所有三角形的可见性(对应“每簇64三角形”的固定拓扑)。
这种表达把“逐三角形判断”压缩为位运算友好的形式,适合在GPU侧继续做筛选、写入与重排。
小结
- 这条管线把可见性链路拆成实例→簇→三角形,并用索引缓冲压缩把结果收敛成少量
MULTI-DRAW。 - CPU侧做粗剔除与按材质分批;GPU侧负责细粒度可见性、索引重排与提交准备。
- 网格簇渲染(Mesh Cluster Rendering)提供了“把几何组织成GPU友好数据流”的范式,是后续理解Nanite的起点之一。
22.3 面向相机与阴影的遮挡剔除(Occlusion Culling for Camera and Shadow)
簇化与索引压缩解决的是“画什么、怎么打包来画”,但还缺一块决定性能力:把被遮挡(Occluded)的几何从流水线里剔出去。现实场景里,视锥内的几何往往远多于最终可见几何;如果只做视锥剔除,后方层层叠叠的簇仍会进入后续阶段,代价会直接体现在Rasterizer与G-buffer填充上。
对GPU驱动几何管线而言,遮挡剔除(Occlusion Culling)不是“锦上添花”,而是能否稳定扩展到城市级场景的前提。与此同时,阴影贴图(Shadow Map)从光源视角再渲一遍场景,几何成本几乎只由“要投影的几何量”决定,因此同一套思路必须能复用到阴影路径上。
遮挡深度生成:用最低成本构建可信的Hi-Z

遮挡剔除的基础设施是层次深度缓冲(Hierarchical Z-Buffer,Hi-Z/HZB):先有一张深度图,再构建深度金字塔,后续对任意簇/实例的包围盒可以做快速测试。
一个更工程化的做法是:只渲染“最佳遮挡物”的深度,而不是渲整个场景。
- 遮挡物选择:通过美术标注或启发式算法选出一小组遮挡物(例如限制到300个)。这类对象通常是大体积、稳定、对遮挡贡献高的几何。
- 特殊情况:来自“本该被剔除”的遮挡物会造成深度空洞;Alpha Test几何也可能成为错误遮挡源,需要在选择阶段规避。
- 降采样:最佳遮挡物的深度图降采样到 (512 \times 256)。
- 时序补洞:结合上一帧 (1/16) 低分辨率深度图的重新投影(Reprojection)填补空洞,并为后续GPU剔除生成层级缓冲。
例如,相机在街道里平滑移动时,大部分遮挡体(墙体/楼体)在屏幕空间的投影变化并不剧烈;上一帧的深度在重投影后能很好地填补“本帧遮挡物没覆盖到的像素”,从而让Hi-Z更连续。
两阶段遮挡剔除:先快后准
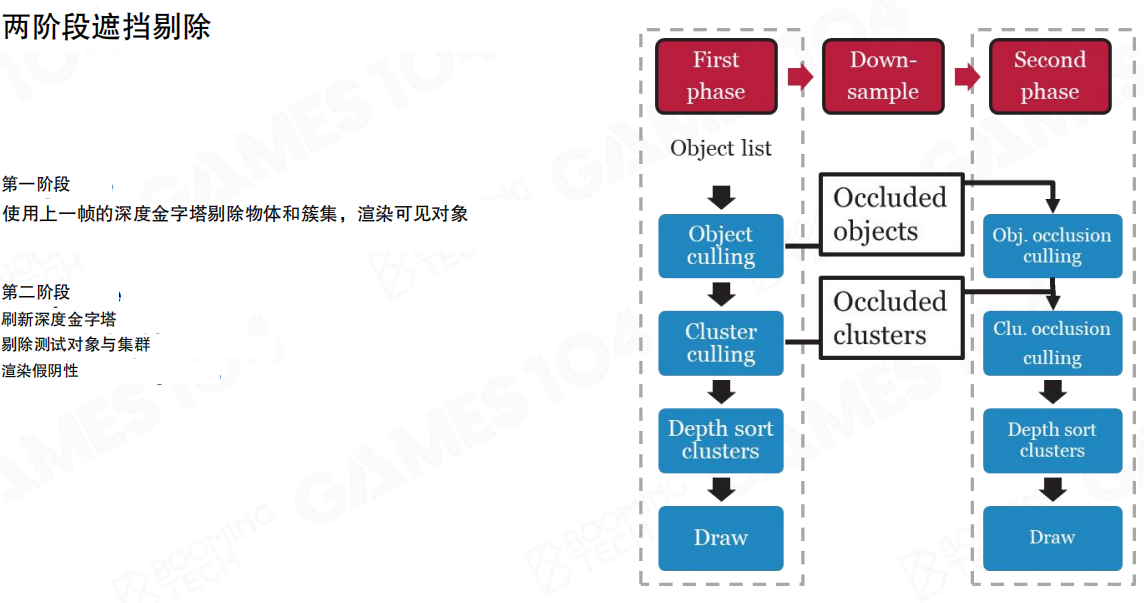
单次依赖“上一帧深度重投影”的遮挡剔除,遇到高速运动或遮挡关系突变时会产生误判。常见解法是两阶段(Two-Phase)策略:
- 第一阶段:使用上一帧深度金字塔剔除物体与簇,渲染“可能可见”的对象(Object/Cluster culling → Depth sort clusters → Draw)。
- Down-sample:生成当前阶段的深度表示。
- 第二阶段:使用本帧深度金字塔,对第一阶段被剔除的对象/簇再次做遮挡测试(Obj. occlusion culling / Clu. occlusion culling),把被误杀的部分补回来。
它的直觉是:第一阶段追求“快速缩小候选集”,第二阶段用“当前帧更可信的深度”修正误判。对于动态物体比例更高的场景,这种策略更稳定。
压测结果:遮挡剔除与GPU驱动并行链路可以跑满

这里给了一个“折磨”级别的压测:单元测试场景包含 25万 个独立移动对象,网格数据 1GB(超过1万个网格),并且在DX11路径下不支持 ExecuteIndirect/MultiDrawIndirect,只用两次 DrawInstancedIndirect 完成提交。
在 Xbox One(1080p)上,GPU侧时间分解(两阶段)大致为:
- Object culling + LoD:0.28ms / 0.26ms
- Cluster culling:0.09ms / 0.04ms
Draw(G-buffer):1.60ms / <0.01ms- Pyramid generation:0.06ms(用于深度金字塔生成)
- Total:2.3ms
并且 CPU 时间约 0.2ms(单个 Jaguar CPU 核心)。这类数据的意义不在“数字有多好看”,而在于证明:遮挡剔除+簇化链路可以把“几何规模”从CPU端彻底搬走,CPU不再是扩展的硬瓶颈。
阴影遮挡:低分辨率、可复用、够用

阴影路径的核心问题是“光源视角也要做遮挡剔除”。一种极简但有效的实现是:
- 对每个级联(Cascade),生成相机深度重投影((64 \times 64) 像素)。
- 结合上一帧的阴影深度重投影。
- 构建层级缓冲,供GPU侧剔除使用。
这里选低分辨率的原因很务实:阴影剔除的目标是把“明显不可能影响当前可见阴影”的对象尽快踢掉,而不是在遮挡测试阶段追求像素级精确。
用相机深度重投影剔除阴影投射者

阴影剔除还有一层更直接的过滤:如果某个对象不可能对“相机可见区域”产生可见阴影,那么它就不应进入Shadow Map渲染。
构造方式可以写成:
- 将屏幕按 (16 \times 16) 的tile划分。
- 对每个tile,基于该tile的最小/最大深度构建一个三维体(黄色视锥体/棱柱)。
- 在光照视角下渲染这些体的“最大深度”,得到可能产生可见阴影的空间区域。
- 所有比这个深度更远的物体都可以剔除,因为它们不可能对可见阴影产生贡献。
例如,在一条狭窄街巷里,前方建筑形成的遮挡会把后方大部分Shadow Caster剪掉;从光源视角渲巴黎城一整遍,既不必要也不可承受。

“长廊/街巷”是最典型的受益场景:相机可见区域被近处几何强烈限制,阴影投射者集合天然稀疏。把“相机可见性”引入阴影剔除,相当于先做一次“阴影空间的AOI”,能显著降低Shadow Map阶段的几何压力。
小结
- 相机遮挡剔除的核心是构建可用的Hi-Z(HZB),并通过重投影(Reprojection)与两阶段策略在“性能/误判”之间做工程折中。
- 对阴影而言,目标不是像素级精确遮挡,而是用低分辨率深度与相机可见区域,快速缩小Shadow Caster集合。
- 在GPU驱动几何管线里,遮挡剔除是决定“城市级几何”是否可扩展的关键模块之一。
22.4 可见性缓冲(Visibility Buffer)
Nanite相关的另一个关键拼图,是可见性缓冲(Visibility Buffer)。它解决的不是“几何怎么剔除”,而是“确认可见之后再花钱着色”:当超密集几何遇到高分辨率时,传统延迟渲染往往不是算力先爆,而是G-buffer先把显存带宽打穿。
延迟渲染在复杂几何里为什么会贵

前向渲染(Forward Rendering)按三角形提交顺序直接着色。遮挡关系复杂时,同一个像素可能被覆盖十几次:每次都要做纹理采样、BRDF、光照累加;最后真正“露出头”的只是一层,被挡住的那堆计算基本没有回收机制。
延迟着色(Deferred Shading)把流程拆成两步:几何阶段只记录可见片段的表面属性到G缓冲(G-buffer),光照阶段再对屏幕像素做着色。它把“动态光源的叠加”从几何阶段解耦出来,也避免了对不可见片段做完整光照。
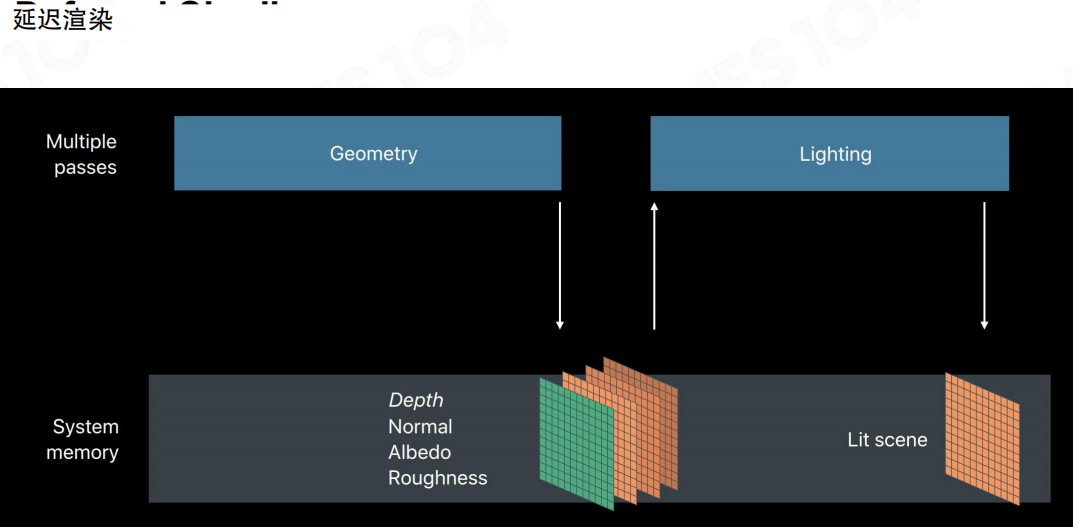
问题在于:G-buffer很容易变得过“肥”。为了在光照阶段重建表面,通常需要存法线、深度、基色、粗糙度、材质ID等一堆字段;分辨率越高,RT读写带宽越紧张,缓存也越难命中。
例如,典型布局里单像素可能要读写多张RT:Normal / BaseColor / Smoothness / MaterialId / AO / ...。当分辨率从1080p提升到4K,几何复杂度没变,但G-buffer的带宽成本会按像素数近似线性放大——很多时候就是在这里先撑不住。

复杂场景会把这件事放大到肉眼可见:植被/细碎结构通常过度绘制(Overdraw)很重,提交顺序也难以强制“近到远”。结果是同一像素反复被覆盖,G-buffer反复写入,材质采样与带宽一起堆到最坏情况。

Visibility Buffer:先记“看到谁”,再决定“怎么着色”
Visibility Buffer的出发点很朴素:第一遍几何pass不急着写一堆材质属性,只写“这个像素最终看见的是谁”(图元/实例/材质的编号)。可以把它理解成:先在屏幕上写一张“快递单号表”,第二遍再拿着单号去仓库(材质/纹理)取货、做计算。

可见性缓冲的生成阶段只做两件事:
- 写入可见性元组:把(Alpha蒙版位、绘制ID、图元ID)打包成一个32位无符号整数。
- 写入屏幕大小的缓冲:它表达的是编号,不是颜色;所以“色彩斑斓但不可读”是正常现象。
这一步的关键收益是:几何阶段的成本基本只和屏幕像素数相关,不再和G-buffer字段数量强绑定。
着色阶段:几何重建 + 材质计算

着色时对每个屏幕像素执行:
- 从可见性缓冲取绘制ID/三角形ID。
- 从顶点缓冲(VB)加载该三角形的3个顶点数据。
- 计算三角形梯度,得到像素位置的插值系数;属性插值用位置坐标中的w分量保证透视正确;位置变换用MVP矩阵。
这等价于把光栅化阶段“硬件自动插值”这件事,挪到着色阶段显式完成。它之所以在工程上跑得动,一个重要原因是访问局部性通常不错:屏幕上的连通区域往往对应同一三角形或相邻三角形,顶点数据会被高频复用,缓存命中率更高。
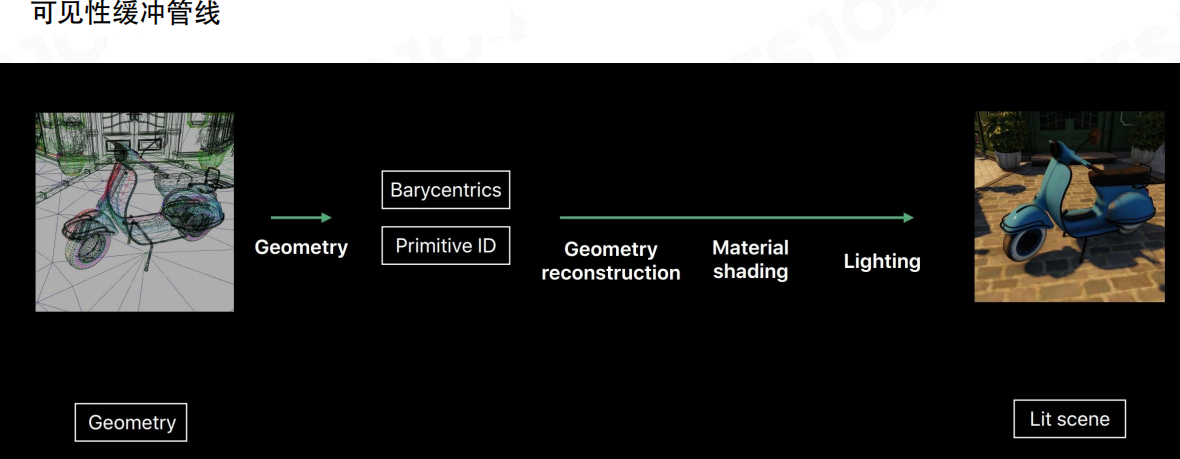
把流水线压成一句话:Geometry → (Barycentrics + Primitive ID) → Geometry reconstruction → Material shading → Lighting。
核心变化在于:材质采样发生在“确认可见之后”。过度绘制再严重,真正做材质与光照的像素数量仍然受屏幕分辨率上限约束。
与延迟渲染融合:用V-buffer驱动G-buffer回填

Visibility Buffer并不排斥延迟渲染,反而更像它的一个“前端替换件”:先输出可见性(对象/三角形),再按需重建材质属性回填到G-buffer,最后走统一的Lighting pass。
工程上的好处是混合路径更自然:过度绘制极重的几何(例如foliage)走可见性缓冲,普通几何仍可走常规G-buffer写入;最终都在同一套光照管线汇合。
纹理梯度与Mip选择:绕不过的细节

可见性缓冲把插值工作后移,会直接踩到一个硬问题:硬件纹理采样需要屏幕空间梯度来选择Mip(通常来自自动微分 ddx/ddy)。当在着色阶段“手动重建几何”时,这些梯度就不能指望硬件白送了,必须自己算;否则很容易出现边缘闪烁、Mip选择错误(示例里圈出的伪影就是典型后果)。
因此实践里会用 SampleGrad,显式提供 (\partial u/\partial x, \partial u/\partial y, \partial v/\partial x, \partial v/\partial y),把Mip选择拉回可控范围。
结果:几何再复杂,着色成本更稳定
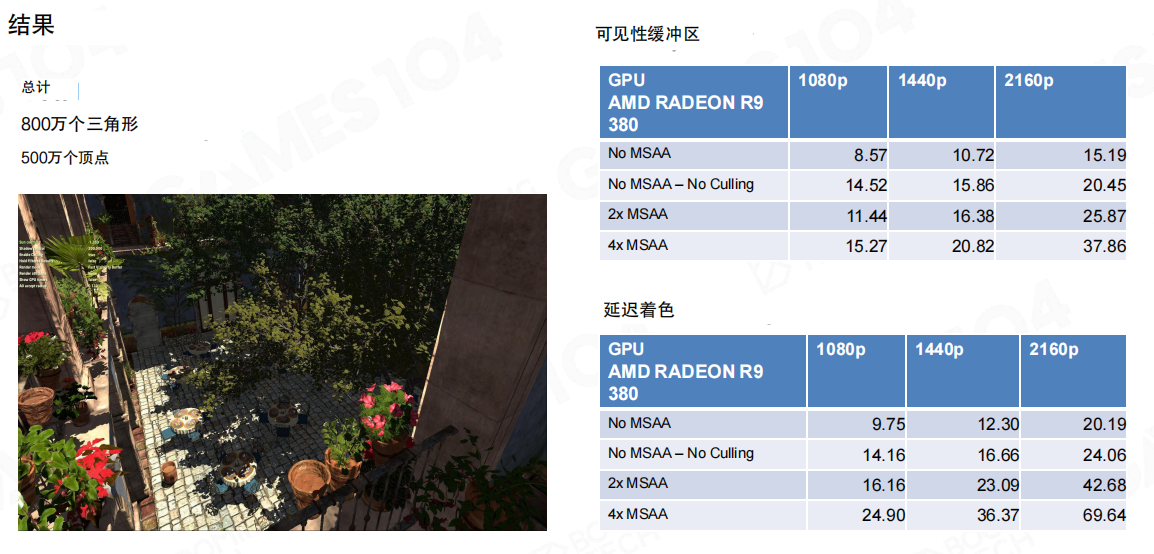
场景规模是 800万 个三角形、500万 个顶点;对比可见性缓冲与延迟着色在不同分辨率与MSAA配置下的GPU耗时。
对Nanite而言,这个结论比数字本身更重要:当几何密度与过度绘制成为常态,把“材质属性的大带宽读写”换成“先记ID、后重建”,能让着色阶段更接近“按分辨率线性扩展”,而不是被几何复杂度拖成不可控的带宽瓶颈。
小结
- 可见性缓冲(Visibility Buffer)用“瘦ID-buffer”替换“肥G-buffer”的前端写入,把材质采样推迟到确认可见之后。
- 它把过度绘制的主要代价从“反复做材质采样 + 反复写G-buffer”转为“廉价写ID”,并利用重建阶段的局部性提高缓存命中。
- 真正的坑在细节:纹理梯度/Mip选择必须显式处理(例如
SampleGrad),否则很容易出现伪影。
22.5 Nanite概述(Nanite Overview)

Nanite要解决的核心问题,是把“电影级资产”(Cinematic Assets)带进实时管线,但把成本锁进预算里:帧时间、显存带宽、以及流式I/O都必须可预测、可控。
对渲染侧来说,“电影级”首先意味着几何细节密度上去了;对运行时来说,意味着不能把这堆细节原封不动推给GPU,而是要在当前视图下做裁剪、选择与按需加载。
真实世界的难点在于:细节不仅多,而且会通过轮廓、遮挡与自阴影直接暴露出来。岩壁裂隙、碎石堆叠这种高频结构,贴图可以补一部分法线响应,但轮廓与遮挡关系补不了。
一个很直观的例子:同一块“石头”,法线贴图能让正视角看起来更粗糙;但镜头掠过边缘时,轮廓仍然是那条平滑曲线,强侧光下的自遮挡也对不上,破绽会被放大。
把目标翻译成工程语言,就是两句话:可见几何的遮挡关系要正确;每帧进入光栅化/着色的几何数量必须受屏幕分辨率与预算约束,增长是可控的。
这一节先不钻细节,先把Nanite看成一个系统:它不是“某个更强的LoD算法”,而是一套从表示到渲染、再到流式的闭环。落地可以拆成三块:
- 几何表示:基于集群的LoD(Cluster-based LoD)、以及用于运行时选择的包围体层级结构(Bounding Volume Hierarchy, BVH)。
- 渲染:软硬件协同光栅化、可见性缓冲(Visibility Buffer)、延迟材质、基于区块的加速,以及配套的虚拟阴影贴图(Virtual Shadow Map)。
- 工程化:流式处理与压缩,把“海量数据”变成“可按需拉取的预算系统”。
“虚拟几何”(Virtualized Geometry)的含义也落在这里:几何不再被当成“一次性加载、整网格渲完”的资源,而是被分页、被裁剪、被按需拉取,并且能在GPU侧快速选择合适的LoD与可见集合。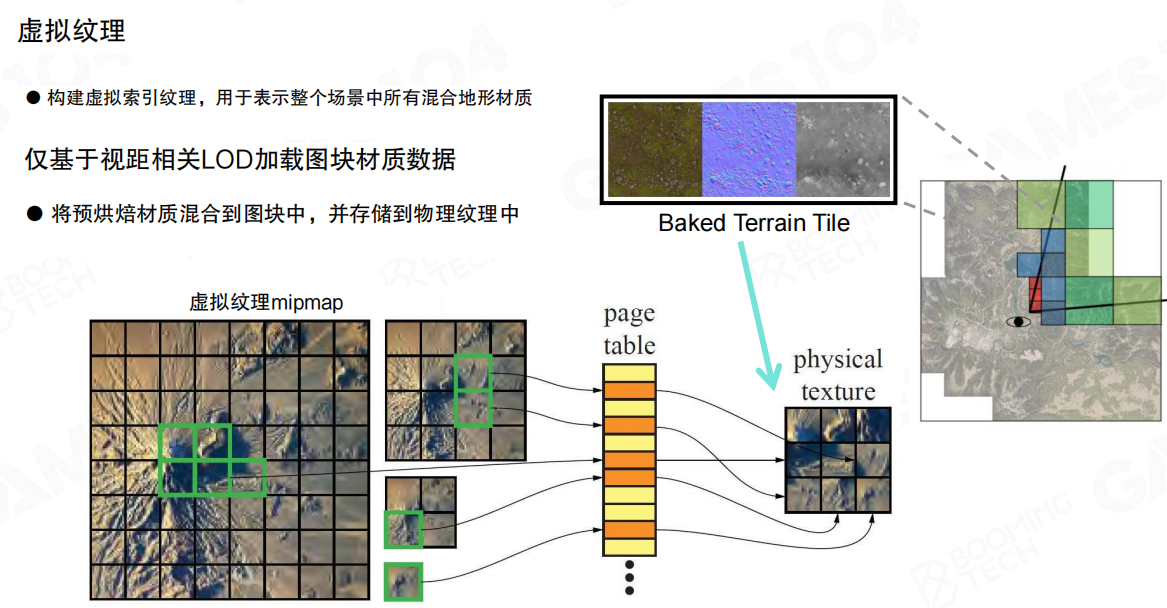
这套直觉最容易从虚拟纹理(Virtual Texture)类比出来:纹理切成固定大小的Tile,用页表(Page Table)把“虚拟地址空间”映射到“物理纹理缓存”。渲染时只把当前视图真正需要的Tile拉进来,其它部分留在磁盘/系统内存里。
例如,一张巨大的地表材质可以覆盖整张地图,但玩家当前只看得到相机附近的一小片;虚拟纹理让GPU只采样那一小片对应的物理页,其它区域不占用显存带宽与缓存空间。
Nanite的直觉非常接近:屏幕像素数是固定上限,“当前视图真正需要的几何细节”也是一个可预算的集合。如果几何也能被切块、分页、按需拉取并快速选择LoD,那么“无限细节”就能落到可执行的工程约束上。
于是目标可以被写成一张“规格表”:
- 资产侧:尽量少做手工LoD与烘焙,把源数据直接喂给引擎。
- 运行时:成本按预算结算(可见集合大小、带宽、I/O),而不是按“资产总面数”结算。
- 画质侧:近景不爆、远景不糊,LoD切换不抖,误差能被控制在可接受范围内。
这套愿景对工程的要求非常苛刻:不仅要能渲,还要能流、能裁剪、能筛选,并且要和材质/阴影体系对齐,否则“几何很细”会把阴影与带宽直接拖垮。
现实约束主要来自两件事:
- 几何比纹理难管理得多:纹理是规则栅格数据,天然可降采样、可过滤;几何是典型的不规则数据(Irregular Data),索引跳转、拓扑变化、局部细节分布都不服从规则缓存。
- 几何细节直接决定渲染成本:多一层遮挡、多一片细碎轮廓,就意味着更多的可见性测试、更多的光栅化工作量,以及更难的阴影一致性问题。
可以把这理解为几何版的“没有MipMap”:纹理有mipmap,硬件还能自动过滤;几何没有这种天然过滤链路,必须自行构建层级、定义误差,并保证运行时选择稳定可用。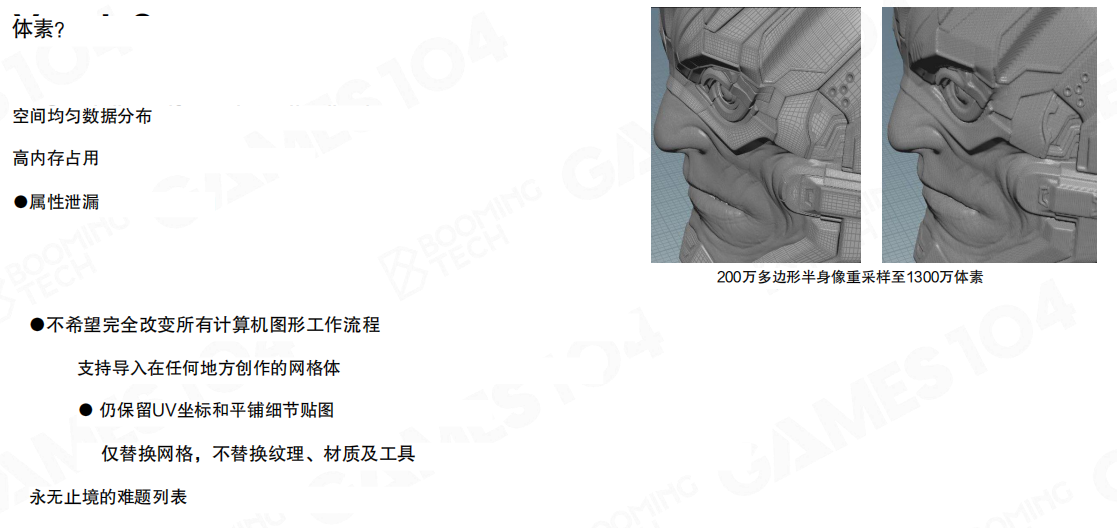
第一个最“规范”的候选是体素(Voxel):数据结构规则,很多操作容易定义。但它很快会撞上三道墙:
- 空间均匀分布:对“细节集中在表面”的资产极不友好。
- 内存占用高:为了保住高频边界,体素分辨率必须上去,数据量增长极快(示例里,200万多边形的半身像采样到1300万体素)。
- 属性泄漏:边界处的属性混叠难避免。
更致命的是内容生产:工业资产管线本质上是网格(加UV、贴图、材质工具链)。把所有资产强行体素化,相当于重写一遍整个行业工作流,工程上不可接受。
另一类路线是曲面细分(Surface Subdivision)。它擅长“把粗模refine到更细”,近景效果很强;但Nanite需要的是“往上也要往下”,而细分在降采样与稳定LoD上先天不占优势:
- 细分本质上是refine,难以从高精度曲面稳定得到低精度表示。
- 对硬表面(Hard-surface)与带锐边的资产,控制特征会变成长期负担。
- 细分过程会在不经意间制造大量三角形,渲染侧仍要为其付账。

位移贴图(Displacement Map)/基于高度图的方法也类似:对于已均匀采样的有机表面往往很好用,但对硬表面特征很难控;并且在复杂拓扑与不连续表面上,很容易出现“贴图能表达,但几何语义对不上”的问题。
这类方法更像“把几何细节寄存在纹理中”,而Nanite要的是“几何细节本身参与遮挡与投影”,两者目标不一致。
例如,一个带锐边的金属零件,位移可以把表面凹凸做出来,但轮廓仍由基网格决定;当轮廓参与投影/阴影时,基网格的粗糙会直接体现在阴影边界上,很难靠贴图补救。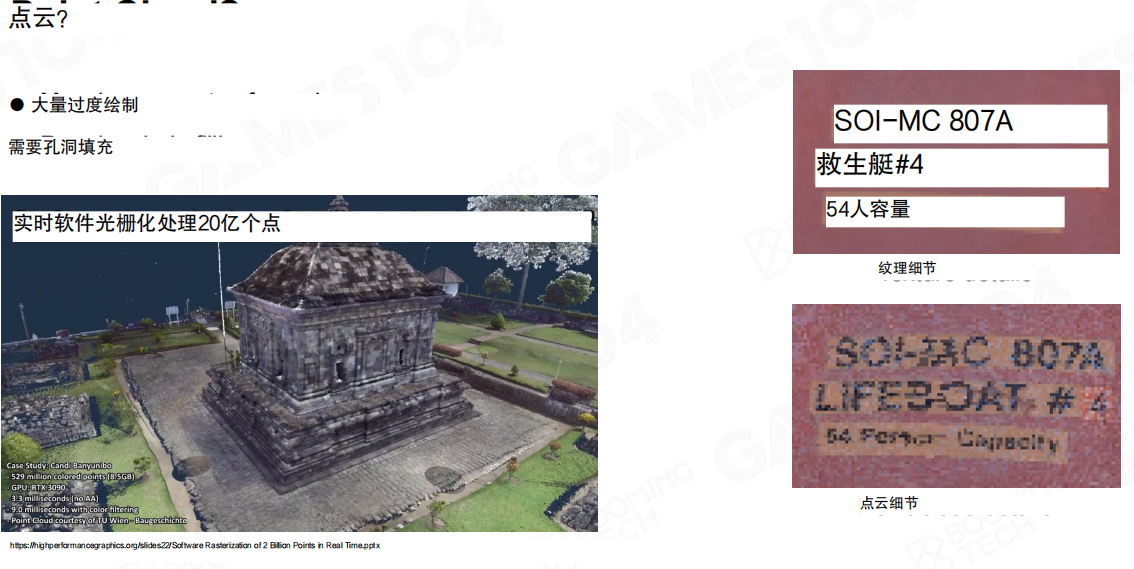
点云(Point Cloud)有天然的采集来源,也更容易“堆密度”。但对实时渲染而言,它会把问题搬到另一个角落:
- 渲染时需要大量过度绘制(Overdraw),并且还要处理孔洞填充。
- 点本身并不提供稳定的表面参数化,材质与滤波会更难做。
“实时软件光栅化处理20亿个点”可以证明吞吐,但要把它变成可控的游戏级管线,仍然不够。
回到工程现实:三角形依然是实时渲染里最成熟的表面基本单元。它的优势不在“表达力更强”,而在生态与硬件支持足够完整——内容生产、UV与贴图、渲染硬件、碰撞与工具链都围绕它建立。
因此Nanite最终的选择也就清晰了:继续使用三角网格(Triangle Mesh)作为几何表达,但用更复杂的数据结构与渲染流程,把“海量三角形”变成“每帧按需可见的一小撮三角形”。
小结
- Nanite想做的不是“无限面数”,而是把电影级几何纳入可预算、可流式、可裁剪的实时系统。
- 虚拟纹理提供了范式:固定粒度切块 + 页表映射 + 按需加载;Nanite试图把这个范式搬到几何上。
- 体素、细分、位移贴图、点云各有优势,但要么数据量/过滤难题过重,要么破坏内容生产管线;最终仍回到三角网格,并在其上构建虚拟几何体系。
22.6 Nanite几何表示(Nanite Geometry Representation)

Nanite的几何表示先钉死一个“预算观”:实例数量随场景线性增长是可以接受的(更多对象、更多实例数据);但三角形数量跟着线性增长就不可接受——因为它会把光栅化、可见性测试、阴影、带宽一起拖进线性爆炸。
这里有个容易被误解的问题:为什么常见情况会“画了比屏幕像素更多的三角形”?核心原因不是“大家喜欢浪费”,而是几何细节往往以轮廓与遮挡的形式出现,必须通过足够密的三角形去表达。
一个很直观的例子:链条/栏杆这种细长物体,在屏幕上可能只占几条像素宽,但如果三角形太粗,它的轮廓会在视角变化时出现明显的台阶与跳变。可以把它当成“用太粗的折线去拟合曲线”——屏幕看见的不是“点够不够多”,而是拟合误差有没有跨过像素阈值。
Nanite要做的不是“保证三角形 ≤ 像素”,而是把“每帧真正进入渲染的三角形数量”收敛到与分辨率相关、可预测的量级。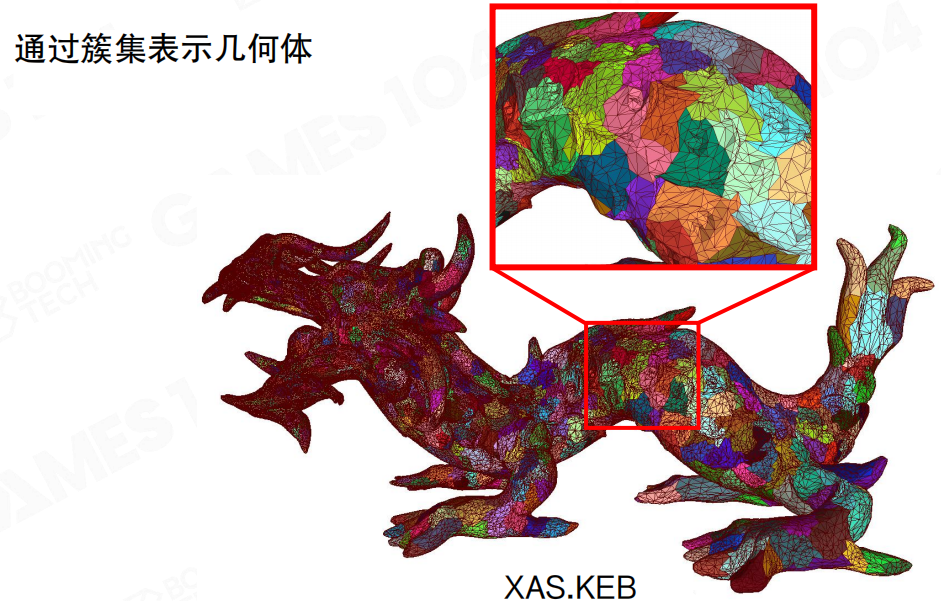
为了让几何可裁剪、可流式、可并行处理,Nanite沿用了前面提到的簇(Cluster)思路:把网格切成很多小块,每块内部是固定规模的三角形集合(课程里反复出现的典型规模是128三角形)。
簇在这里的定位很明确:
- 是渲染与剔除的最小“可工作单元”:可见性、LoD、流式都围绕簇做决策。
- 是几何“分页”的粒度:不会按“整网格”去加载,而是按簇去拉取/淘汰。
这一步把“一个巨大网格”的问题分解成“很多个独立小块”的问题,后面的LoD与选择才能在GPU侧做成数据并行。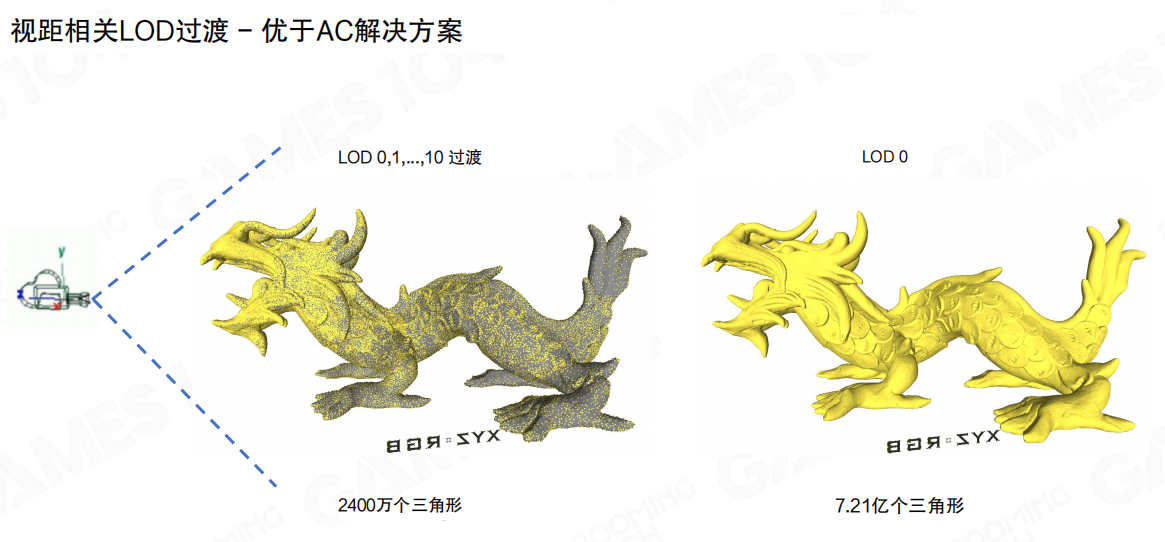
接下来是Nanite和《刺客信条:大革命》那套方案最本质的差异:视点相关细节层级(View-dependent LoD)可以细到簇级别,甚至同一个实例内部不同区域使用不同LoD。
一个很极端但很说明问题的对比:如果强制用LOD0去画,三角形规模可以到 (7.21 \times 10^8);而允许视距相关的LoD过渡后,能把渲染三角形压到约2400万量级。
它想表达的是:LoD不应该只在“物体级/实例级”做一次选择,而应当在“局部几何块”上持续做选择,否则预算根本锁不住。
同一个结论换个角度说,就是“以约1/30的渲染成本实现相近的视觉效果”。这里的“相近”依赖一个关键事实:屏幕最终只看得到像素级结果;只要把几何误差控制在像素阈值以内,视觉就很难区分“原始超高面数”和“按视点裁剪后的可见簇集合”。
这也是Nanite后面误差度量(Error Metric)要做得很认真的原因:LoD切换不是“差不多就行”,它必须能在运动镜头里保持稳定。
一个最直接的实现方式,是构建簇的层级(Cluster LoD Hierarchy):把簇组织成树,每层代表一个更粗的几何近似(父节点是子节点的简化版)。
这套结构给两个能力:
- 层级化细节:从LOD0到LOD2…逐级变粗。
- 可计算误差:每次简化都会引入误差,误差随层级单调增加,便于运行时做阈值判断。
“父母是孩子的简化版”这句虽然朴素,但它决定了运行时选择可以写成一个非常稳定的过程:从粗到细逐步细化,直到误差满足屏幕阈值。
运行时决策可以抽象成“在树上找切割点”:对当前视点,在哪一层停下最合适。
课程里用的是一个直观阈值:把簇投影到屏幕后,若误差小于1px就接受当前LoD,否则继续向下选更细的LoD。这就是所谓的视点相关裁切(View-dependent cut)。
它和纹理的Mip选择在思想上是一致的:纹理用屏幕梯度选Mip;几何用屏幕误差选LoD。区别在于:纹理的过滤链路由硬件自动提供,几何必须自己构建层级,并保证误差在层级上单调、可用。
有了树结构与视点裁切,流式(Streaming)就顺理成章了:整棵树不需要一次性全部载入内存。
- 先保证粗层(高层LoD)常驻:它能覆盖“远景/预览/遮挡体”的基本需求。
- 把需要的分支当作叶子展开:相机推进时按需请求更细的节点;相机远离时允许丢弃细节节点。
这套机制和虚拟纹理的“按需请求页”是同一个套路:远处先用粗页顶住,靠近再补细页。
到这里会遇到一个硬问题:细节层级裂缝(LoD Cracks)。
如果每个簇独立决定LoD而不与邻簇协调,它们在共享边界处会选到不同的几何近似,局部就会出现缝隙(Watertight被破坏)。这在大规模簇化场景里是必现问题。
一个“原始方案”是锁定共享边界:简化时固定边界顶点/边,使得不同LoD之间边界仍然能对齐。
但边界锁定的工程效果并不好:会在边界处积累大量碎片化约束,尤其在深层树结构之间,锁定边界会让可简化的自由度越来越少。
直觉上就是:把“最难简化的地方”固定住后,简化只能在内部硬挤,最终既保不住画质,又得不到足够的三角形节省,反而会制造高频噪声与不均匀的细节密度。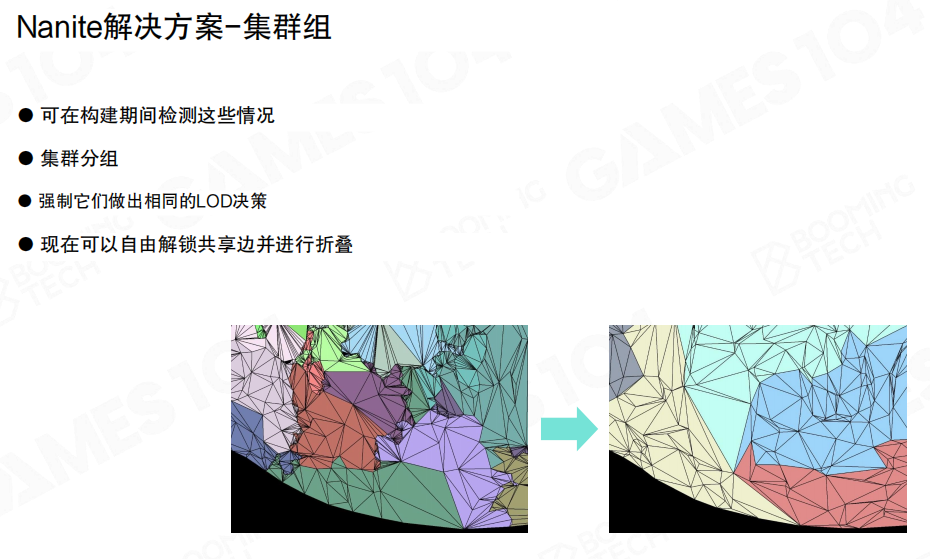
Nanite的关键改动是引入簇群(Cluster Group):锁边不再以“簇”为单位,而是以“簇群”为单位。
- 构建期检测容易出裂缝的情况,把相邻簇分组。
- 让一个簇群内部的簇在LoD上做一致决策(强制同一层级)。
- 簇群外边界被锁定;簇群内部的共享边界允许解锁并折叠(内部自由简化)。
直觉上,它把“锁边的代价”从“到处锁、处处碎”收敛到“只锁大块边界”,把简化自由度留给内部。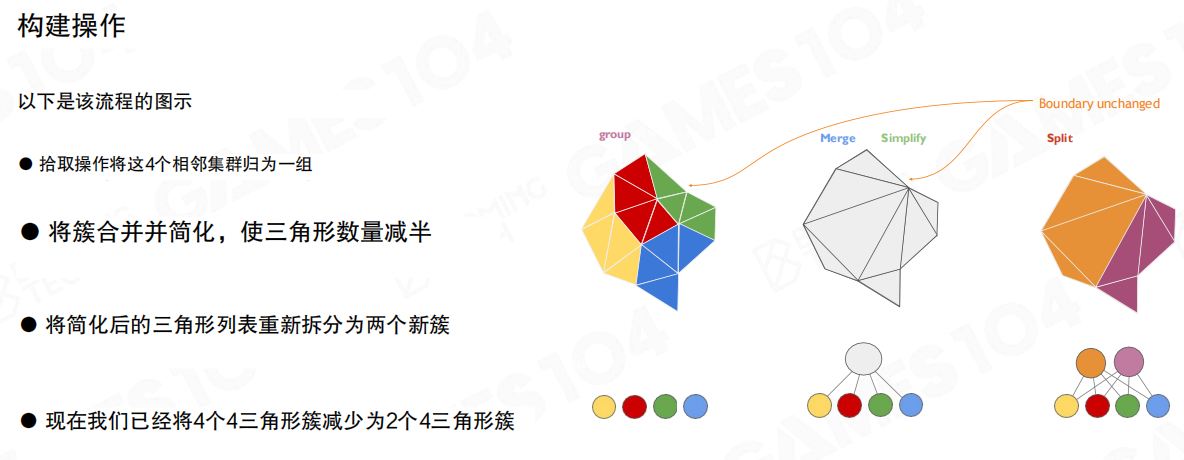
簇群的构建操作可以概括成三步(边界保持不变):
- Pick group:挑选一组相邻簇作为一个group(示意里是4个簇)。
- Merge & Simplify:把簇合并后做简化,使三角形数量减半。
- Split:把简化后的三角形列表重新拆分成更少的簇(示意里4簇变2簇)。
关键点不是“减半”这个数字,而是“简化发生在group内部”,并且最终仍回到固定规模的簇,保持渲染侧的规则性。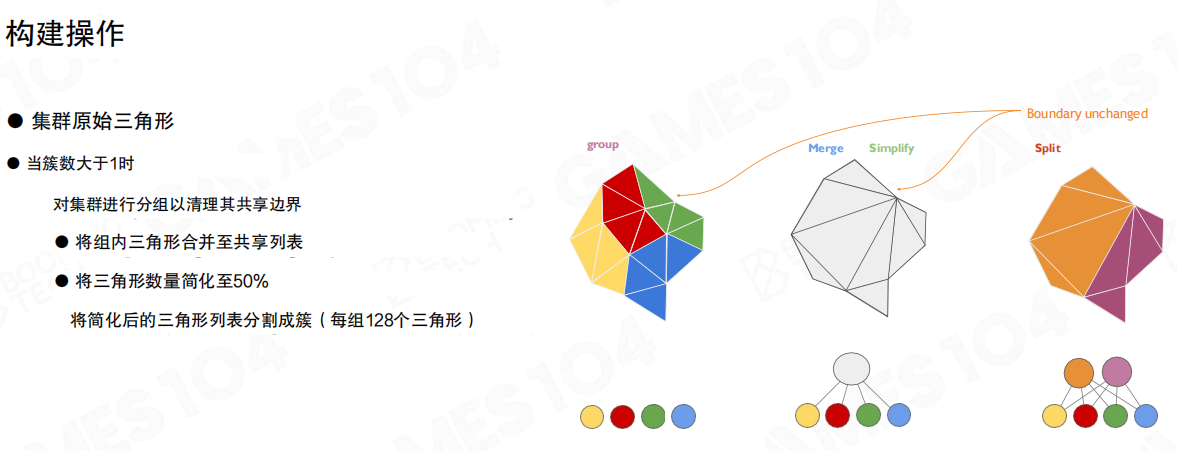
更贴近实现的描述是:当簇群规模大于1时,先清理共享边界,把组内三角形合并到共享列表;对合并后的几何做简化到50%;再把简化结果按固定簇规模切回去(例如每簇128三角形)。
这个“Merge→Simplify→Split”会反复出现在Nanite的构建链路里:它保证运行时仍然只面对“固定大小簇”,但离线构建阶段可以在更大范围内自由优化。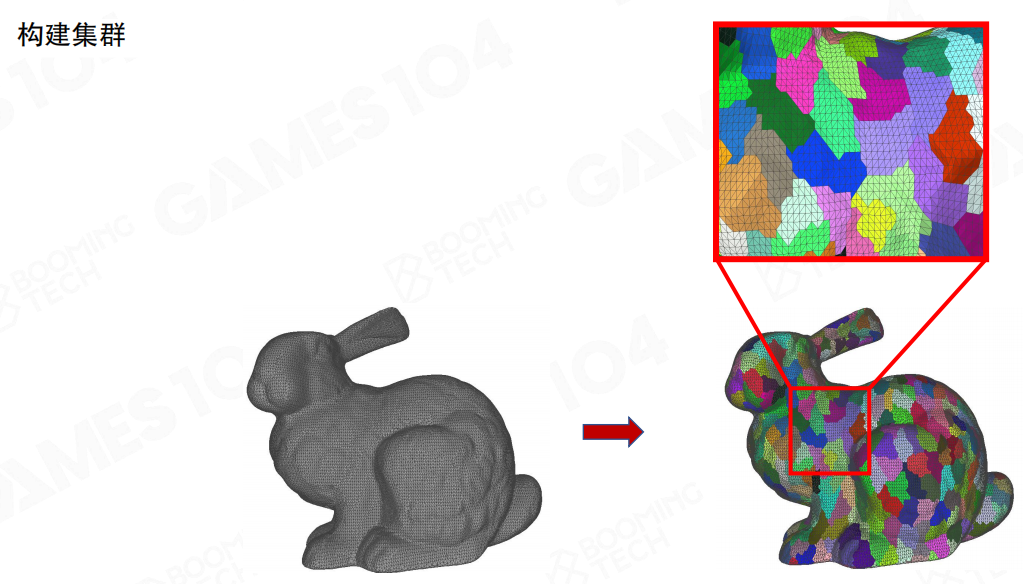
这里用兔子举例,先把原始网格切成很多簇。右图的彩色块就是簇的分块结果:每块形状不规则,但规模可控。
通俗一点理解:这一步相当于把“整只兔子”切成很多“可独立处理的小零件”。后面无论做裁剪、LoD还是流式,操作对象都变成这些小零件,而不是整网格。
接着把簇聚合成簇群。示例里LOD0有18个簇;簇群把其中一部分簇打包在一起(红色轮廓标出了一个group的范围)。
这一步的价值在于:后续LoD切换时,裂缝处理不再是“簇与簇之间”零碎博弈,而是“簇群与簇群之间”做边界约束。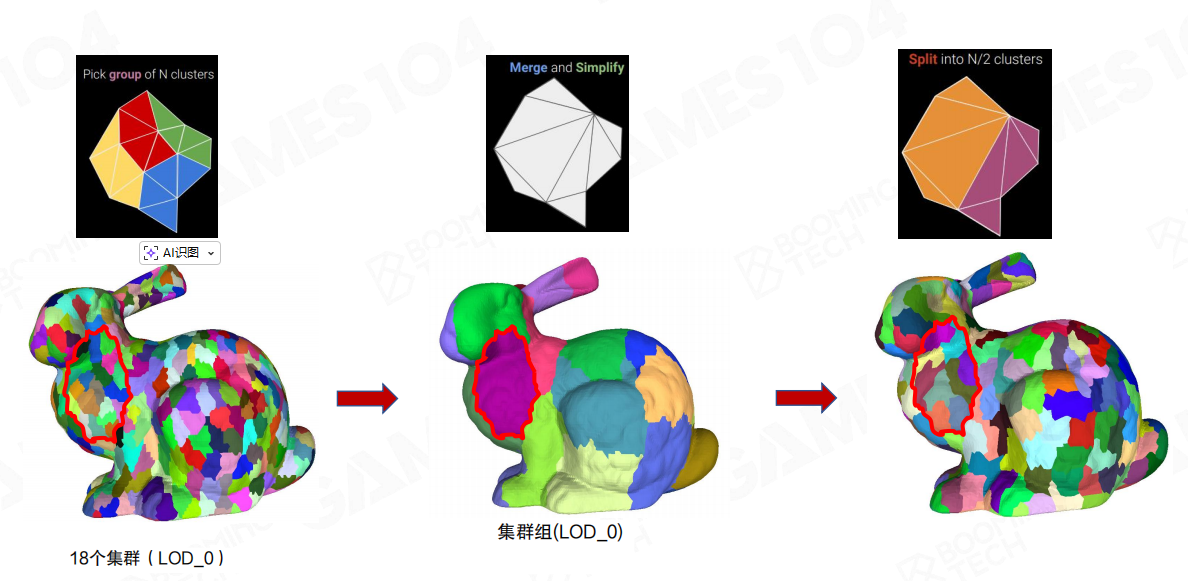
构建期的一次迭代可以概括为:
- 选取包含N个簇的group;
- 合并并简化(Merge and Simplify);
- 分裂为N/2个簇(Split into N/2 clusters)。
这也解释了为什么后面不是一棵“干净的树”:合并与分裂会打破一对一父子关系,结构必然更像图。
簇群的另一个关键设计是层级间替代边界:不同LoD层的簇群分组不保持一致。
- 某一层的簇群边界,在下一层里会变成内部区域。
- “锁定一级,解锁下一级”:避免某条边界在所有层级都被永久锁死。
通俗一点:如果一条“缝线”每一层都出现在同一个位置,人眼会稳定捕捉到那条高频线;让边界在层级间轮换,相当于把高频噪声打散,不让它在固定位置累积。
LOD0时可以把簇群边界看成一张“红色网格”。此时锁的是这一层的外边界,保证同层内部拼接一致。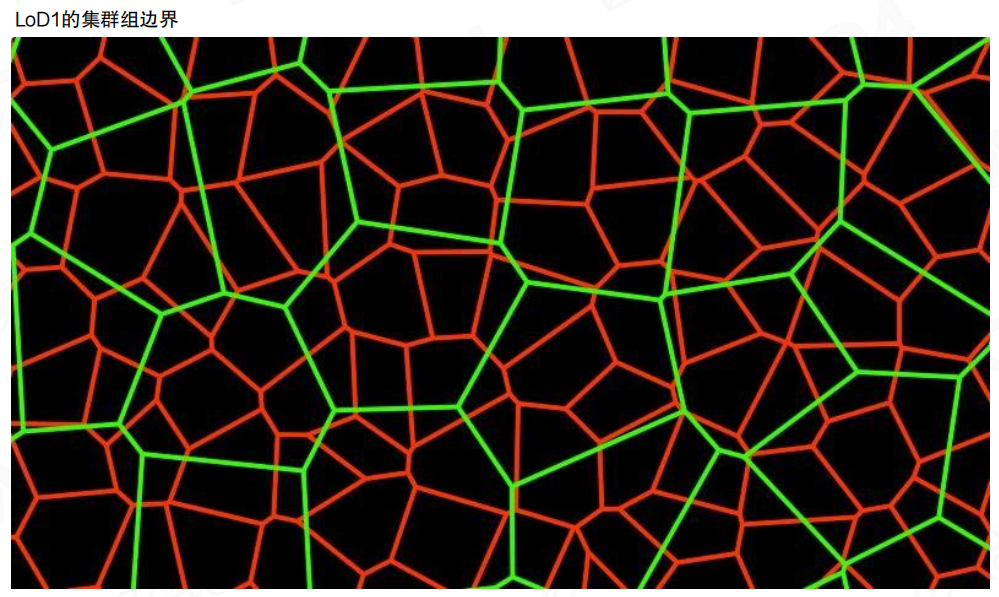
到LoD1,簇群边界换了一套(绿色)。红色边界的一部分被吞进了更大的group内部,变成可自由简化的区域。
到LoD2,边界再次轮换(蓝色)。如果把三层叠在一起看,会发现“被锁定的边”不会在空间里形成一条长期存在的高频结构,这是它能抑制伪影的重要原因。
“合并+拆分”把层级结构从树推向了有向无环图(Directed Acyclic Graph, DAG)。
这有两个直接收益:
- 结构表达更接近真实构建过程:上层簇来源于多个下层簇的重排与简化,自然会出现“多父节点”。
- 避免“锁边约束在层级上单调累积”:如果把结构硬做成树,很容易把一些边界约束长期固定在同一条路径上,导致冗余数据越攒越多。
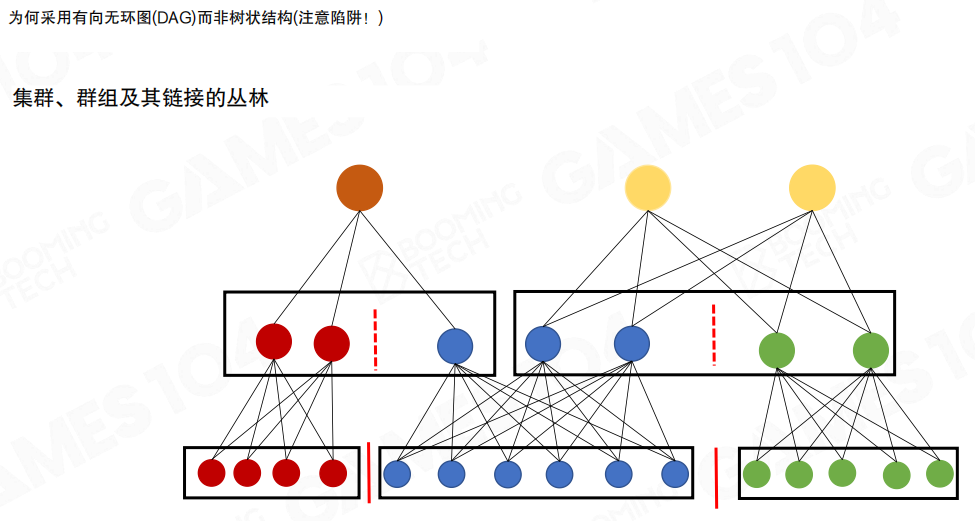
这页把“为什么不是树”画得更直观:底层簇按簇群聚合,上层簇群的划分边界会穿过下层簇群;因此同一个下层簇可以被不同的上层节点复用,连接关系必然交织成“丛林”。
把它当成“几何的版本控制”会更好理解:上层并不是某个下层的单纯删减,而是对一组下层的合并、简化与重新切块;重新切块之后,复用关系自然会交叉。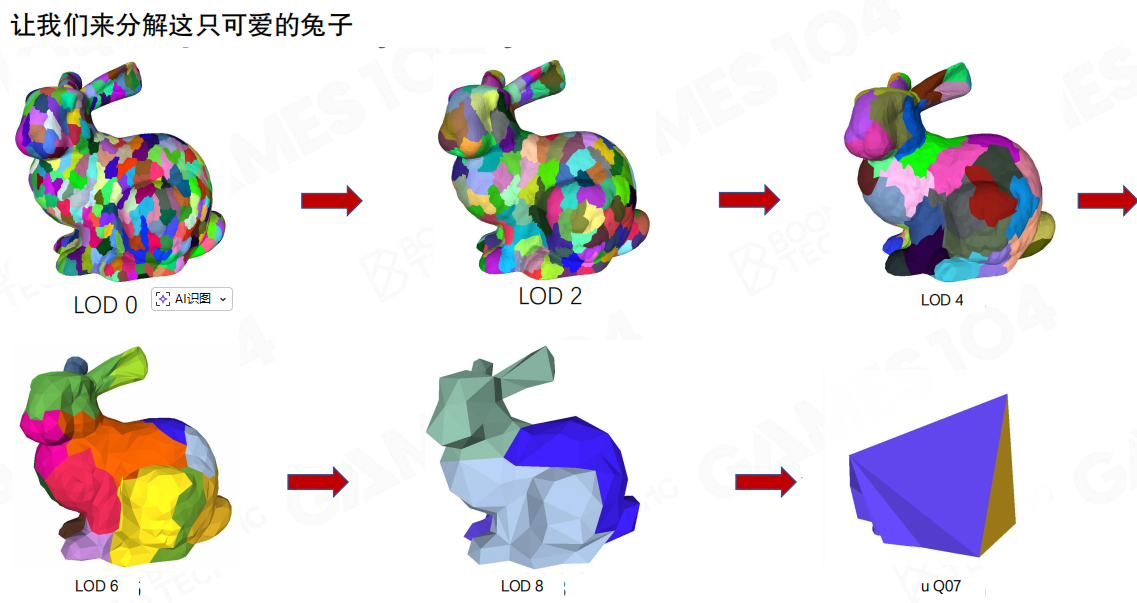
还是回到兔子,从LOD0一路到LOD8,形态逐层变粗。这里展示的重点不是“越远越粗”本身,而是:LoD是由簇群/簇在层级里逐步收敛出来的,而不是传统意义上“每个物体准备几套离线网格”。
这也解释了Nanite为什么能做视点相关裁切:它的基本单元是簇,层级结构又是可随机访问的图结构,允许在一个实例内部按局部误差做不同深度的展开。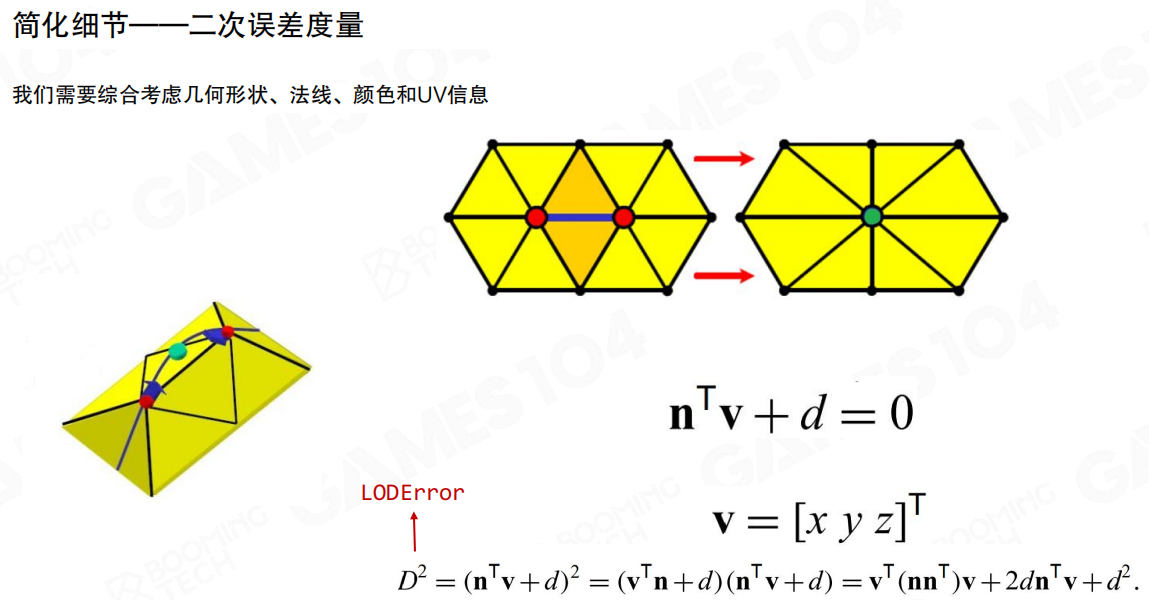
构建LoD时最核心的事情其实是“误差怎么量”。Nanite需要一个能在简化中稳定工作的度量:既要考虑几何形状(位置/法线),也要兼顾颜色与UV带来的外观差异。
这里对应的是经典的二次误差度量(Quadratic Error Metrics, QEM):把“顶点到一组平面”的偏离累计成一个二次型,用它来评估边折叠/顶点合并的代价。直觉上就是:可以允许表面稍微挪动,但不能让法线与轮廓发生肉眼可见的漂移;否则LoD切换会抖。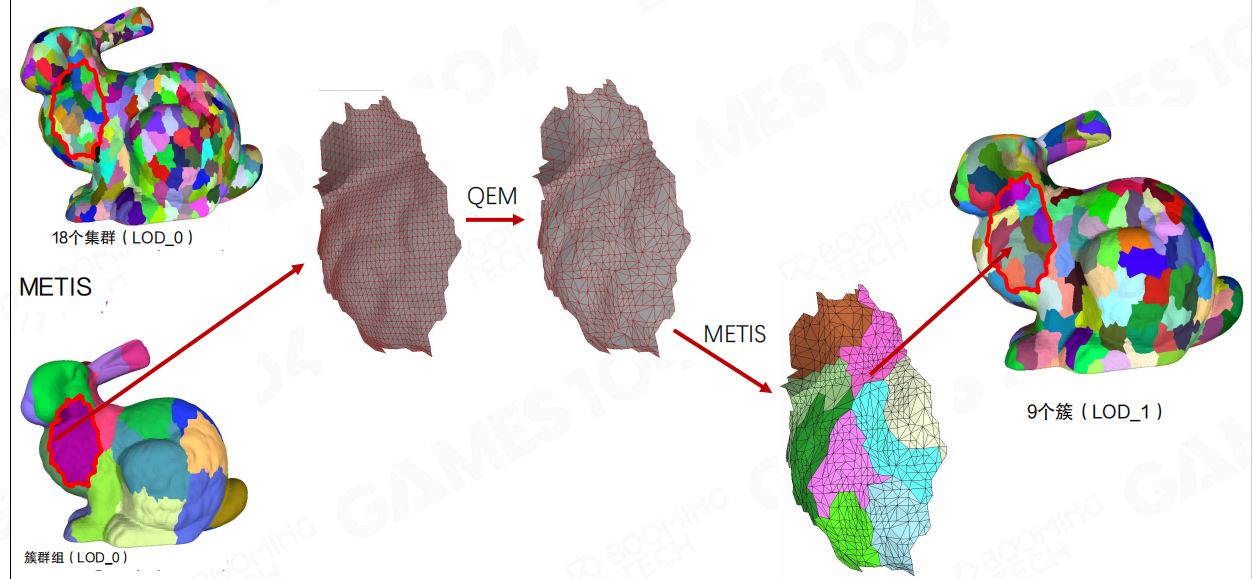
最后把构建链路串起来(这页的信息密度很高):
- 用METIS做图划分,把簇组织成簇群(尽量让组内连接紧密、边界更短)。
- 在簇群内部用QEM做简化(Merge & Simplify)。
- 简化后再用METIS/切块策略重新分簇/分组,生成下一层(示例:LOD0的18个簇收敛成LOD1的9个簇)。
这里最值得记住的是“多对多”:下一层的一个簇不对应上一层的某一个簇,它对应的是上一层簇群内部的重排结果;因此层级结构天然就是DAG,而不是传统LoD里那种一对一的树。
小结
- Nanite的几何表示把“预算”落实到簇:簇是裁剪、LoD、流式的共同粒度。
- 视点相关裁切用“屏幕误差阈值”(常见直觉是1px)把每帧可见三角形收敛到可预测范围。
- 裂缝问题不能靠“全局锁边”硬扛;Nanite用簇群(Cluster Group)与“层级间替代边界”把锁边代价收敛并打散高频伪影。
- 构建过程由“Merge→Simplify→Split”驱动,层级结构天然形成有向无环图(DAG);简化的误差度量依赖QEM,分组/划分常用METIS。
22.7 运行时LoD选择(Runtime LoD Selection)
进行渲染时,需要根据相机位置选择合适的LoD。对于传统“树状LoD”,从根往下走一遍并不难;但Nanite的层级结构是有向无环图(DAG),节点存在复用关系,运行时做视点相关切割(view dependent cut)会复杂不少。
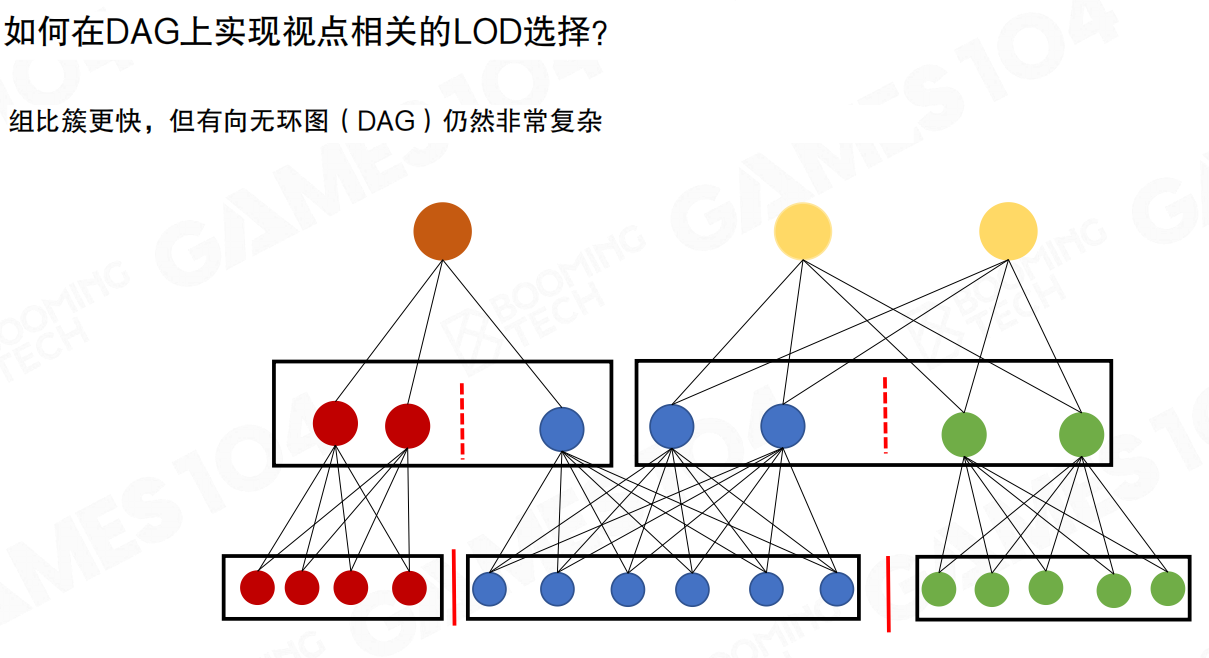
最直接的做法是:从根节点开始,基于视点误差(屏幕空间误差)一路往下展开,直到误差足够小为止。困难在于DAG不是树,traverse时要处理多父节点与复用关系,写起来既费劲也不快。
以集群组(Cluster Group)为单位统一LoD决策
Nanite在运行时做了一个关键约束:LoD选择以集群组(Cluster Group)为单位——同一个group里所有簇必须做出相同的LoD决策。

这背后的直觉很直接:相邻子网格可能共享边界,但使用不同LoD时三角形数量不同。如果边界两侧各自独立切换,就容易在边界处出现裂缝或闪烁。因此“组内同决策”把一致性问题收敛到group级别。
同时,这个一致性不能依赖“组内通信”去协商(通信会导致串行化、且容易引入不确定性)。理想形态是相同输入 → 相同输出,让每个group自己就能得出同一个结论。
并行LoD选择:先保证切割线是唯一解
LoD选择本质是在层级结构里找一条“切割线”(view dependent cut)。
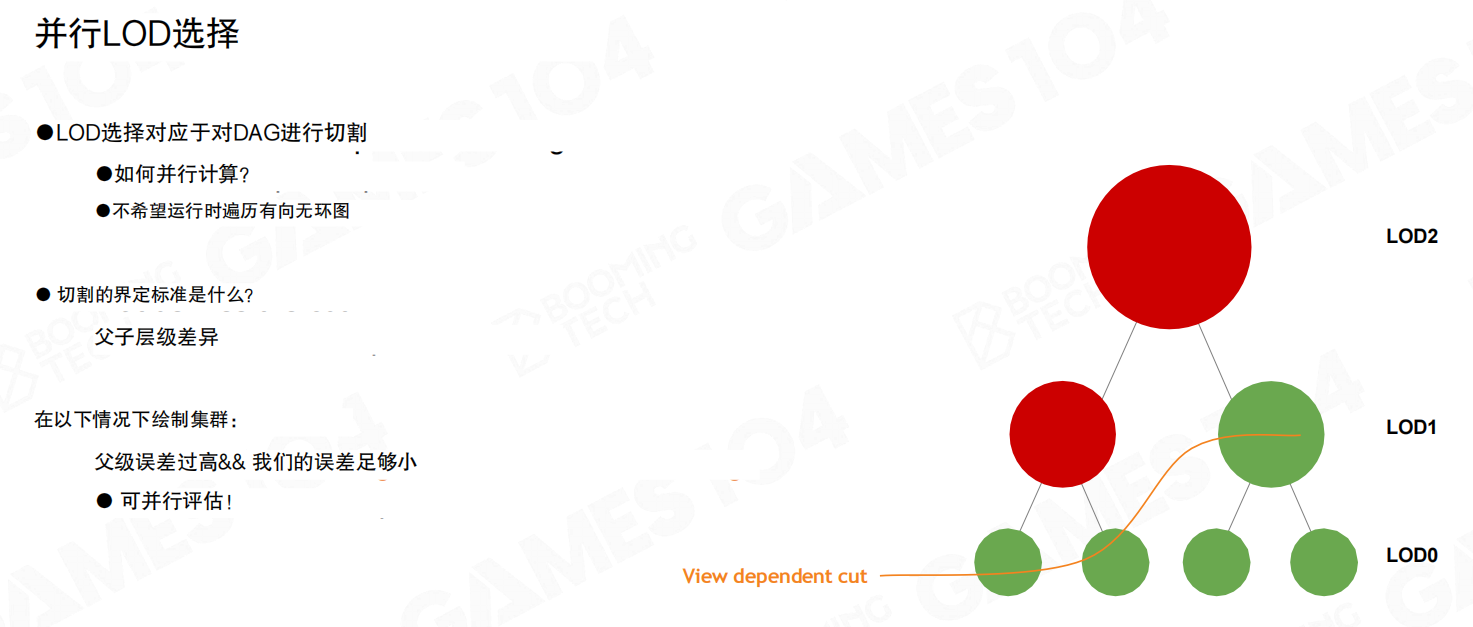
如果希望LoD选择能彻底并行化,那么每个节点最好都能“独立决定是否被渲染”,最终拼出那条切割线(橙色曲线)。
但并行化的前提是切割线必须是唯一且确定的。否则相机不动时,仅因为遍历顺序或浮点抖动,上一帧/下一帧的cut就可能不同,导致popping/fighting。
Nanite的解法是让误差满足单调性:父层误差不小于子层误差(父视图误差 (\ge) 子视图误差)。

一旦误差单调,给定任意阈值,对应的cut就会变成唯一解;运行时即使做“校正”,也不会破坏这种单调性。
核心方程:把“遍历DAG”变成“拍平后的独立测试”
有了单调性以后,就可以把“从root往下走”的遍历逻辑,改写成一个更GPU友好的形式:把所有候选节点拍平成数组,让每个节点做一次独立测试。

对一个集群组(更精确地说:对集群组里的每个簇),渲染条件可以写成:
\[
\text{Render} = (ParentError > \tau) \land (ClusterError \le \tau)
\]
对应的剔除条件是:
- 父级误差 (\le \tau):父层已经足够精确,无需展开到子层。
- 或 集群误差 (> \tau):当前簇还不够精确,需要更细一级来满足阈值。
这个判定非常巧妙:它让每个簇的LoD决策变成isolated,不需要再按DAG结构去递归遍历,因此天然适合并行。
例子:阈值为1.0时的逐级选择(并不需要“激活子层”)
下面用阈值 (\tau=1.0) 的例子,把“独立测试”这件事讲清楚。
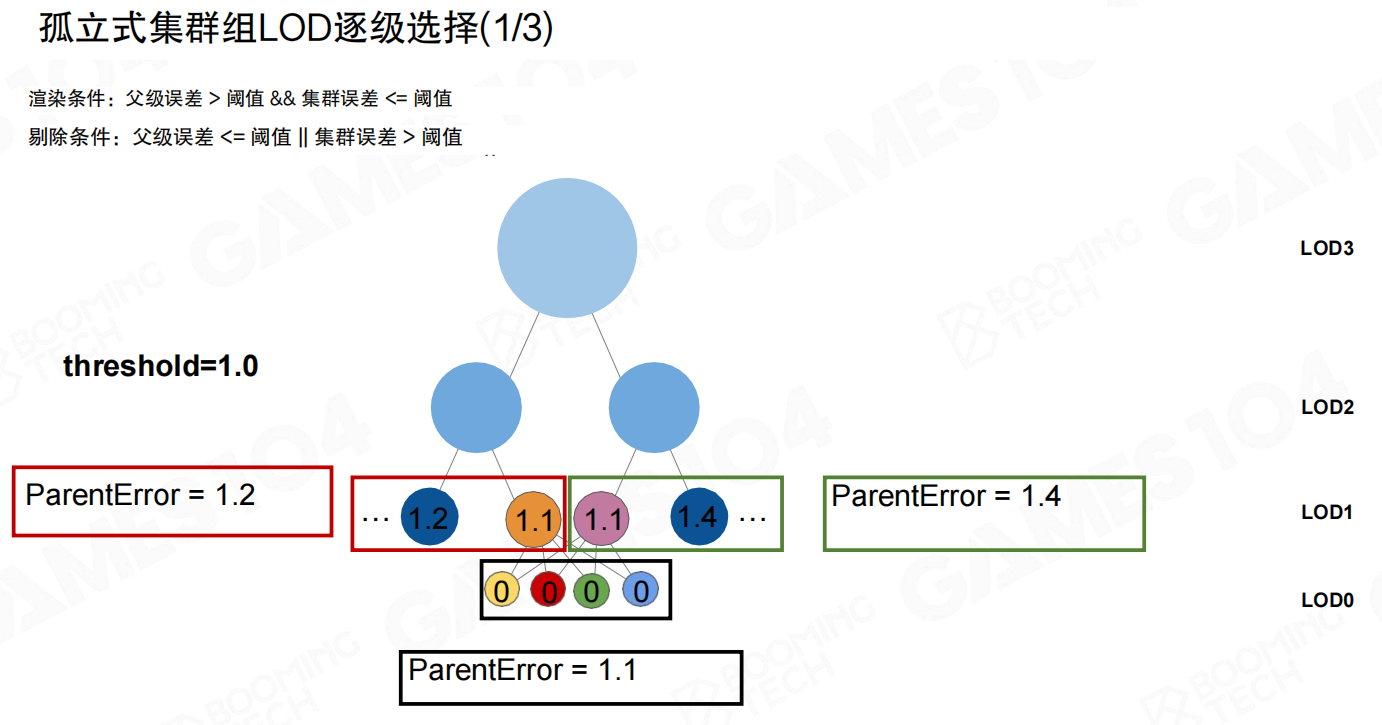
可以看到多个候选的 ParentError 都大于 1.0,因此它们都有资格被考虑;但是否真正渲染,还取决于各自的 ClusterError 是否 (\le 1.0)。
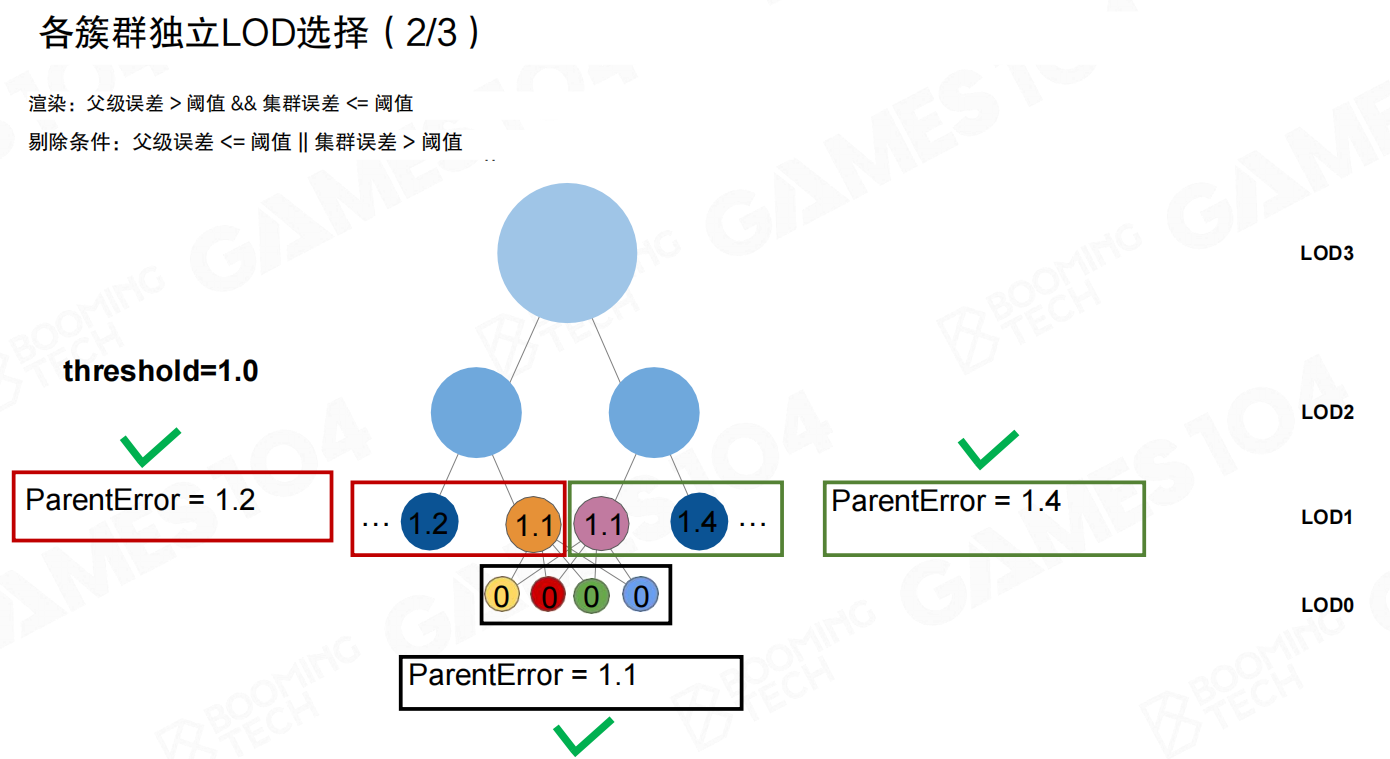
当某个LoD1簇的 ClusterError 仍然大于阈值,它不会被渲染。一个常见误解是:这时需要由父节点“激活它的孩子”。Nanite这里不是这种控制流。
因为误差单调,父层不满足(误差太大)意味着更细一级的候选,其 ParentError 一定也会大于阈值;与此同时更细一级的 ClusterError 更小,更容易满足阈值,于是它们会在同一轮并行判定里自然“浮出来”。
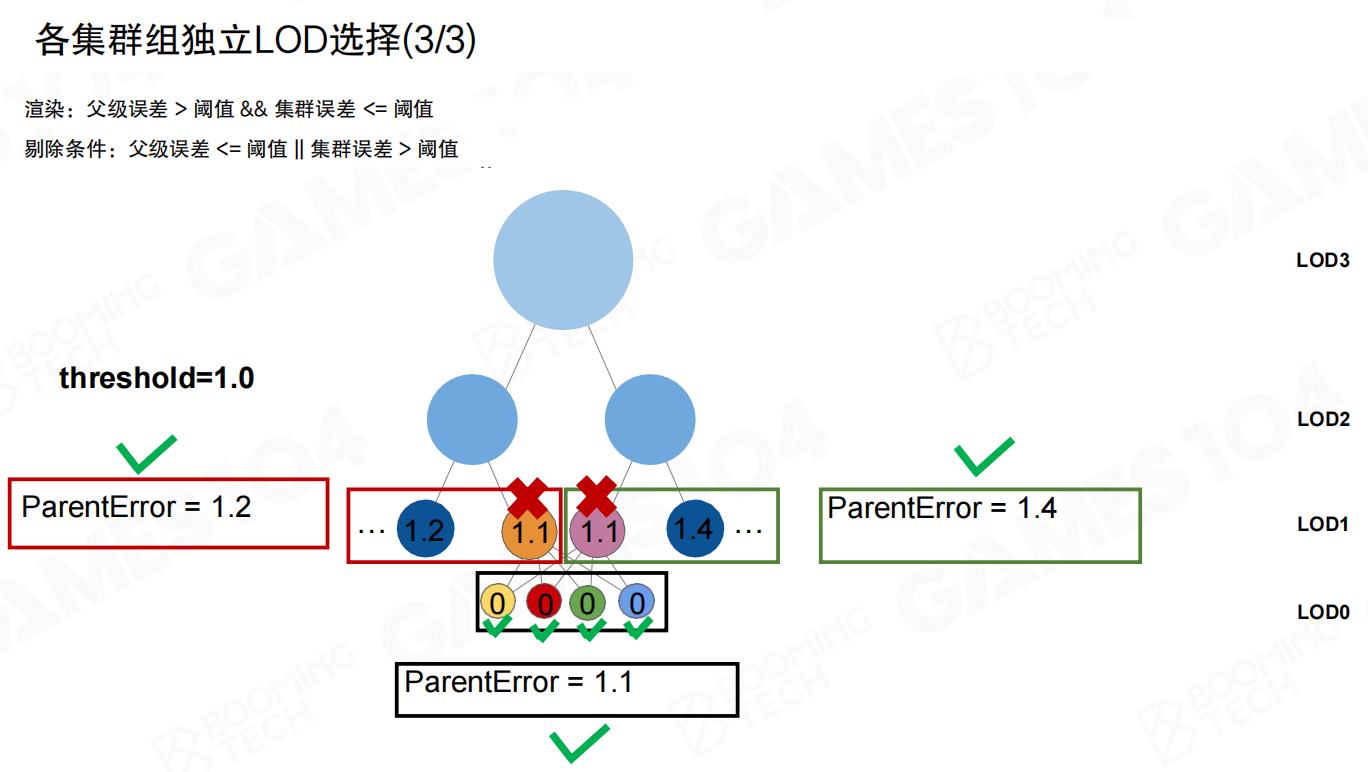
最终效果是:几何既不会被渲染两次,也不会漏掉;而且cut是确定的,不会因为遍历顺序变化而抖动。
BVH加速:避免对所有集群组做全量测试
即使把判定拍平并行化,候选数量仍然可能很大。更现实的做法是先做空间裁切:用层次包围体(Bounding Volume Hierarchy, BVH)把远处或不可见的大块候选先裁掉。

这里用的是BVH4(内部节点4个孩子):内部节点可以存“子节点父级误差的最大值”,叶子节点挂“组内簇的列表”。
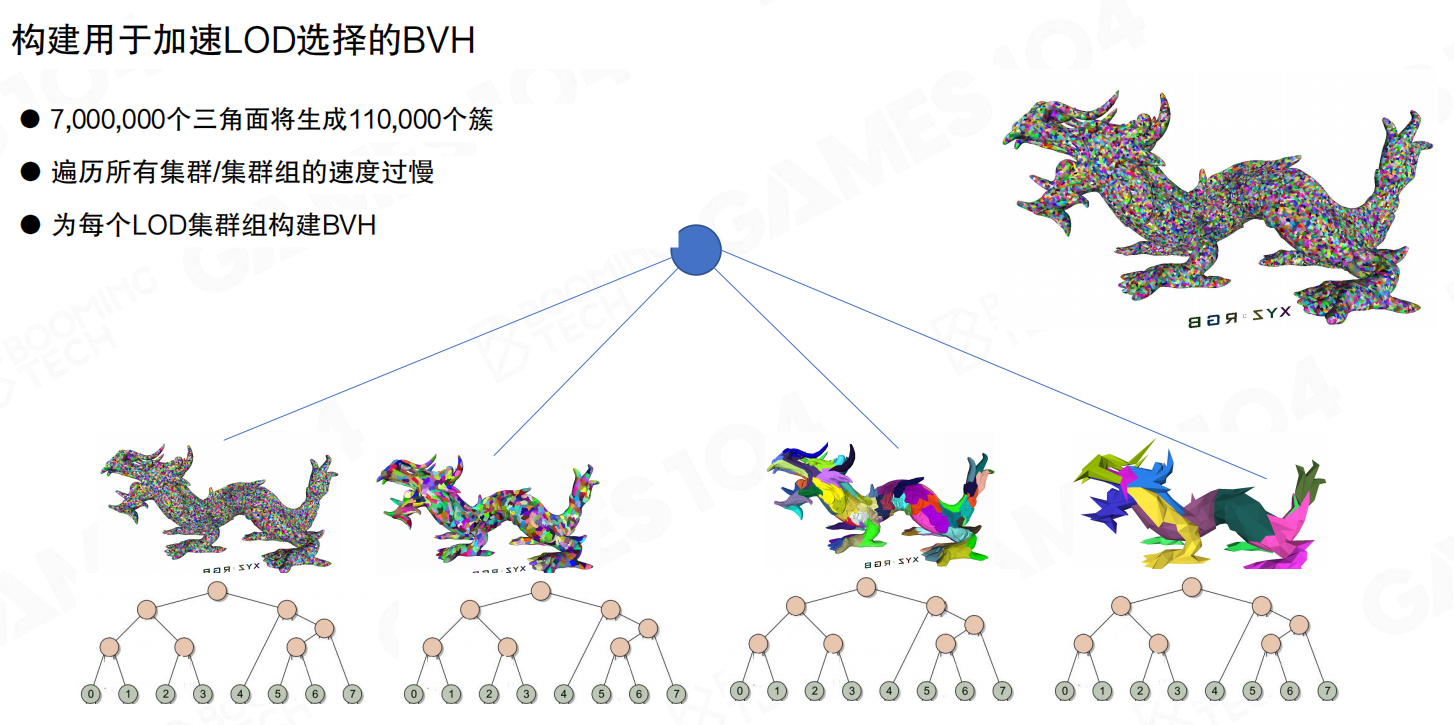
对每个LoD层的集群组构建BVH后,LoD选择的流程就变成:先遍历BVH筛出少量候选叶子,再对叶子里的簇做 ParentError/ClusterError 判定。
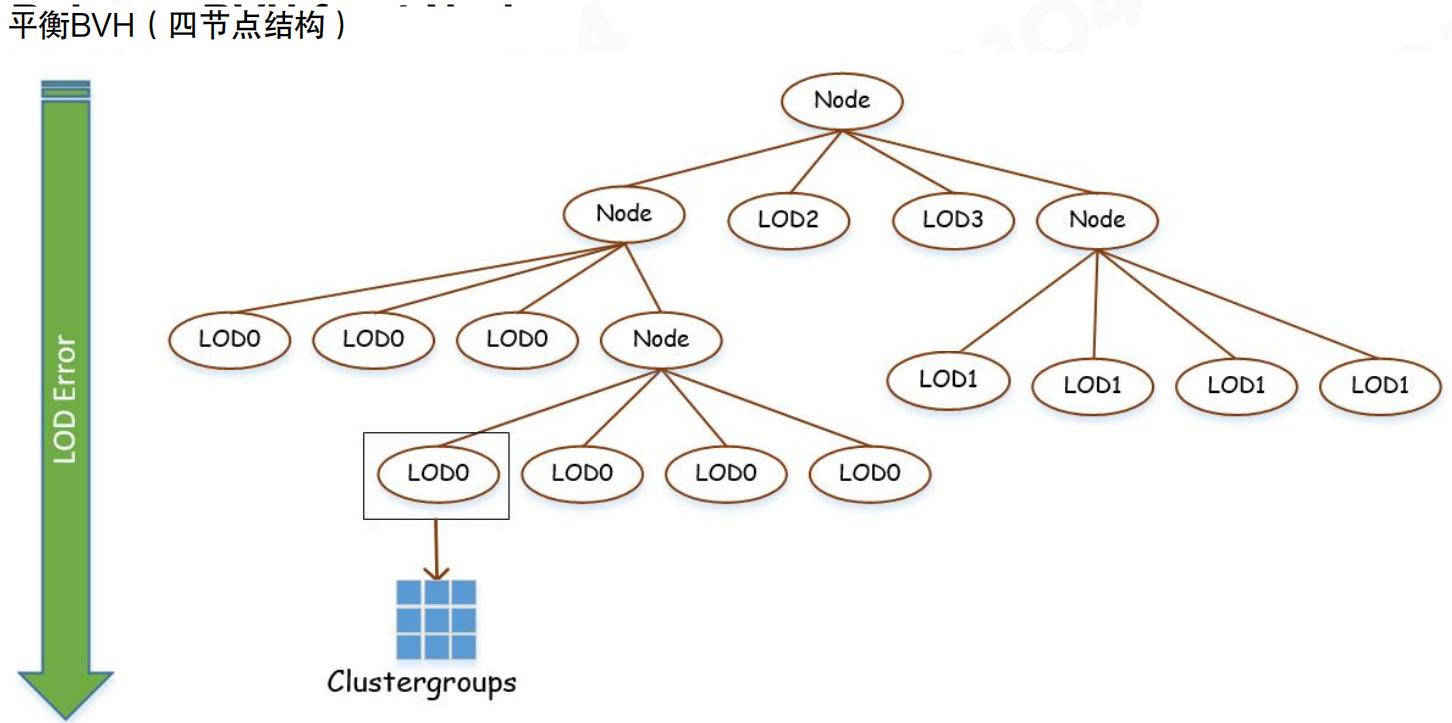
为了让遍历更稳定,BVH会尽量做得更“平衡”。注意:叶子上挂的是集群组(Cluster groups),不是单个簇——这与前面“以集群组为单位统一决策”的约束一致。
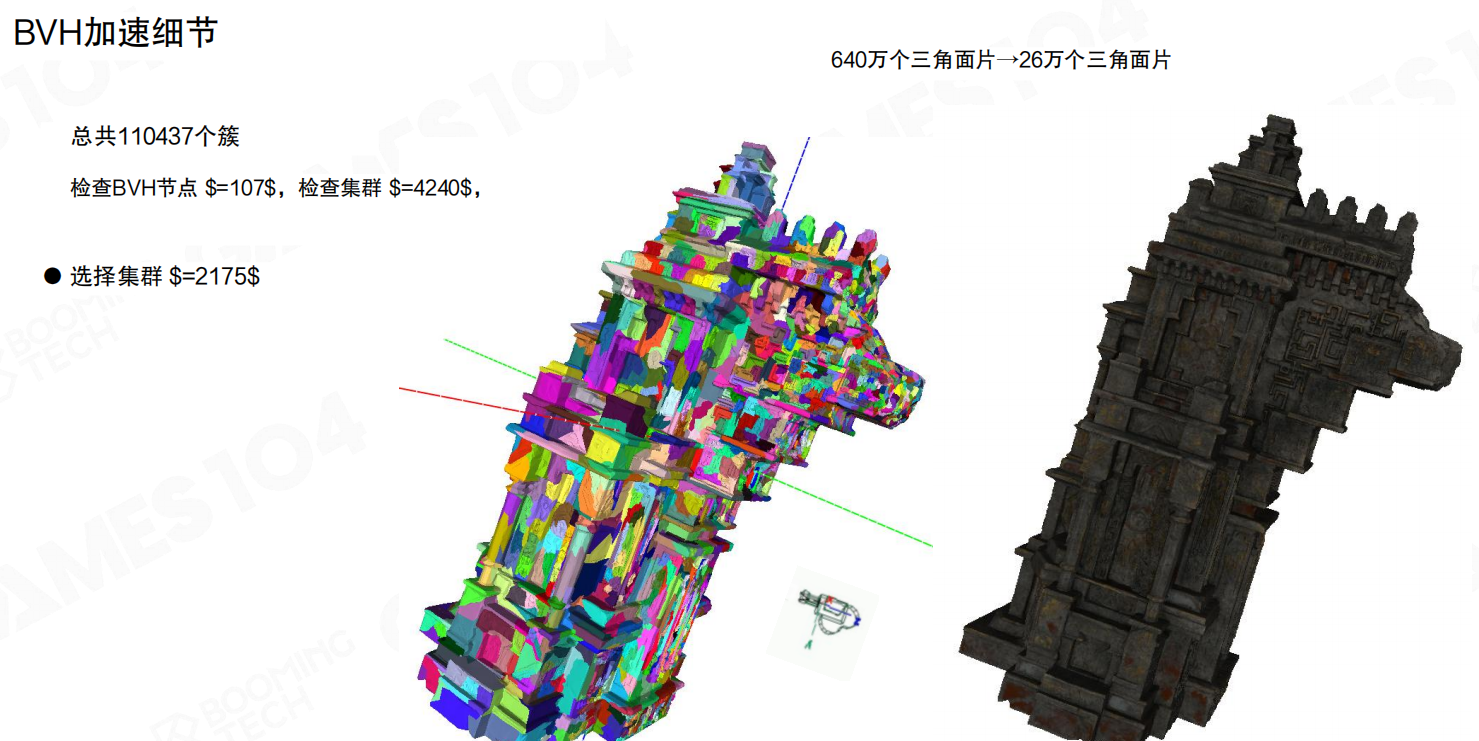
量级对比也很直观:总簇数 110,437。引入BVH后,检查BVH节点约 107 次,检查集群组约 4,240 个,最终选出的可见集群组约 2,175 个;三角形数量从 640 万收敛到 26 万。
并行遍历的调度:从“分层同步”到“持久线程 + MPMC队列”
BVH遍历最朴素的实现是“分层剥离”:一层一个dispatch,每层之间全局同步;最坏情况下层数很多,会出现明显的尾部空洞调度。

增加扇出(fanout)能缓解一部分问题,但根因仍在:负载不可预测,层间同步会频繁空等。
因此Nanite更接近任务系统(Job System)的做法:用持久线程(Persistent Threads)让工作线程常驻,用一个简单的多生产者多消费者(MPMC)队列做分发。
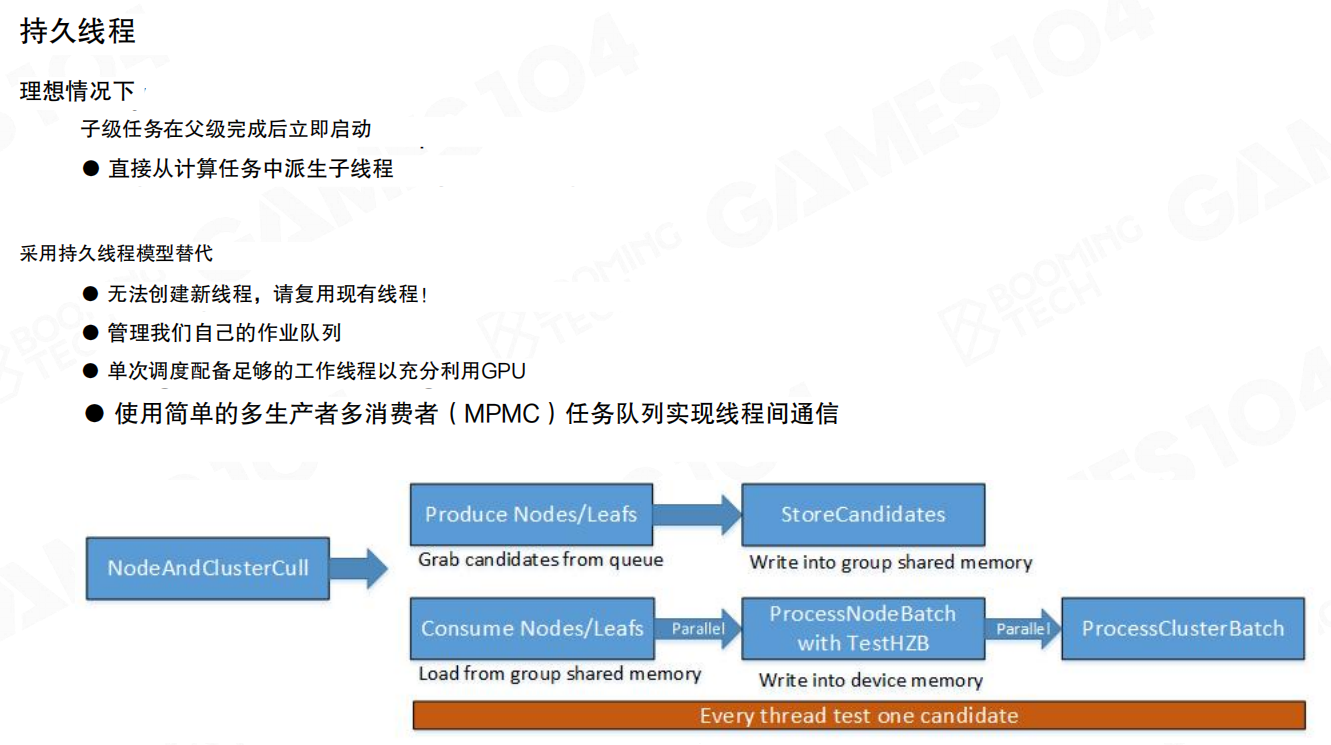
可以把这条流水线理解为:不断产生候选(Produce),把候选写入队列/共享内存(Store),工作线程持续从队列取活并批处理(Consume/Process)。只要队列里有任务,线程就不会因为“等下一层dispatch”而空转,整体吞吐会更稳定。
小结
- LoD选择的本质是寻找视点相关cut;在DAG上直接traverse会很复杂。
- Nanite把决策单位收敛到集群组(Cluster Group),并用误差单调性保证cut的唯一性与确定性。
- 用
ParentError/ClusterError的判定方程,把“遍历结构”改写成“拍平后的独立测试”,从而天然并行化。 - 进一步用BVH4做空间加速,并用“持久线程 + MPMC队列”提升遍历与筛选的吞吐。
22.8 Nanite光栅化(Nanite Rasterization)
Nanite之所以必须“重做一遍光栅化”,核心原因很简单:它把几何细分推到了极致,很多三角形的投影尺寸已经接近屏幕上的一个像素。这个尺度下,传统光栅管线里那些“为了大三角形优化”的假设,会反过来变成浪费与瓶颈。

先抛出一个很直观的问题:能不能用“远大于1像素”的三角形去表达像素级细节?通常做不到——细节的上限取决于曲面/轮廓的变化频率,最终仍然要落回“像素大小的几何粒度”,否则轮廓会抹平,细节会糊成一坨。
硬件光栅化对微小三角形并不友好
硬件光栅化的速度很快,但它有一个基本事实:很多设计都是围绕“以像素为单位并行”展开的,而不是围绕“三角形数量”。
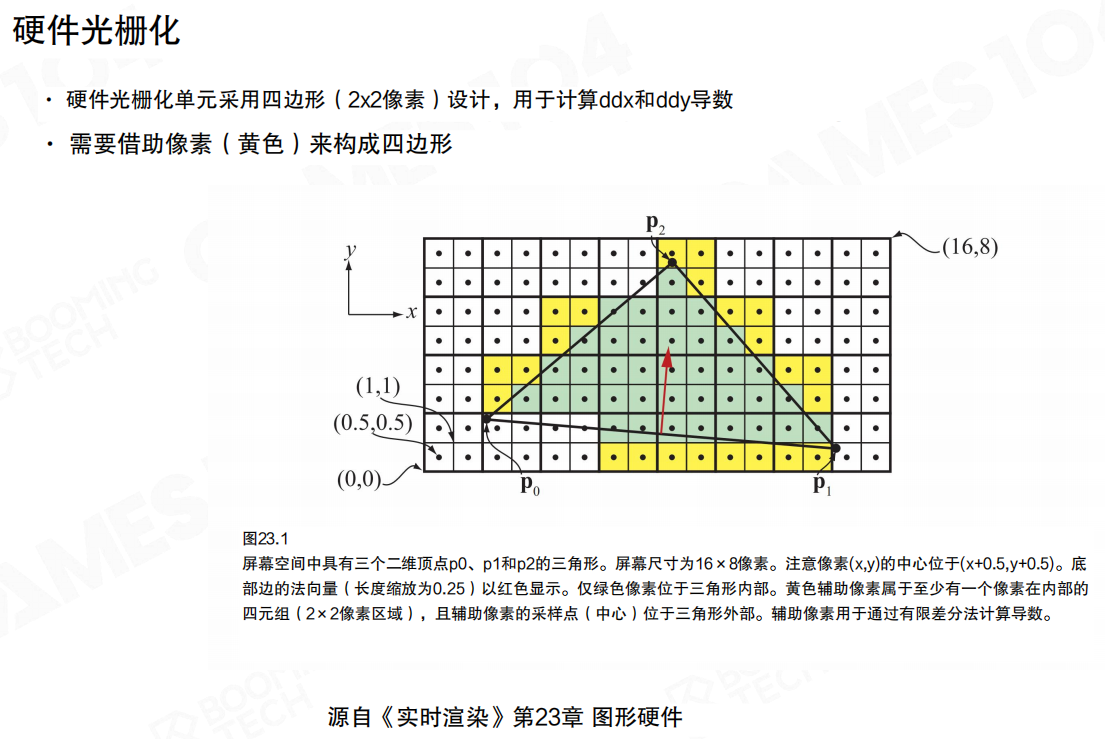
这里的关键点是2×2像素四元组(quad)。硬件需要用 quad 来计算 ddx/ddy 等导数(纹理采样、各向异性过滤、法线贴图等都依赖它),所以即使一个三角形只覆盖了1个像素,也可能要“借用”(黄色区域)额外像素来凑齐 quad。
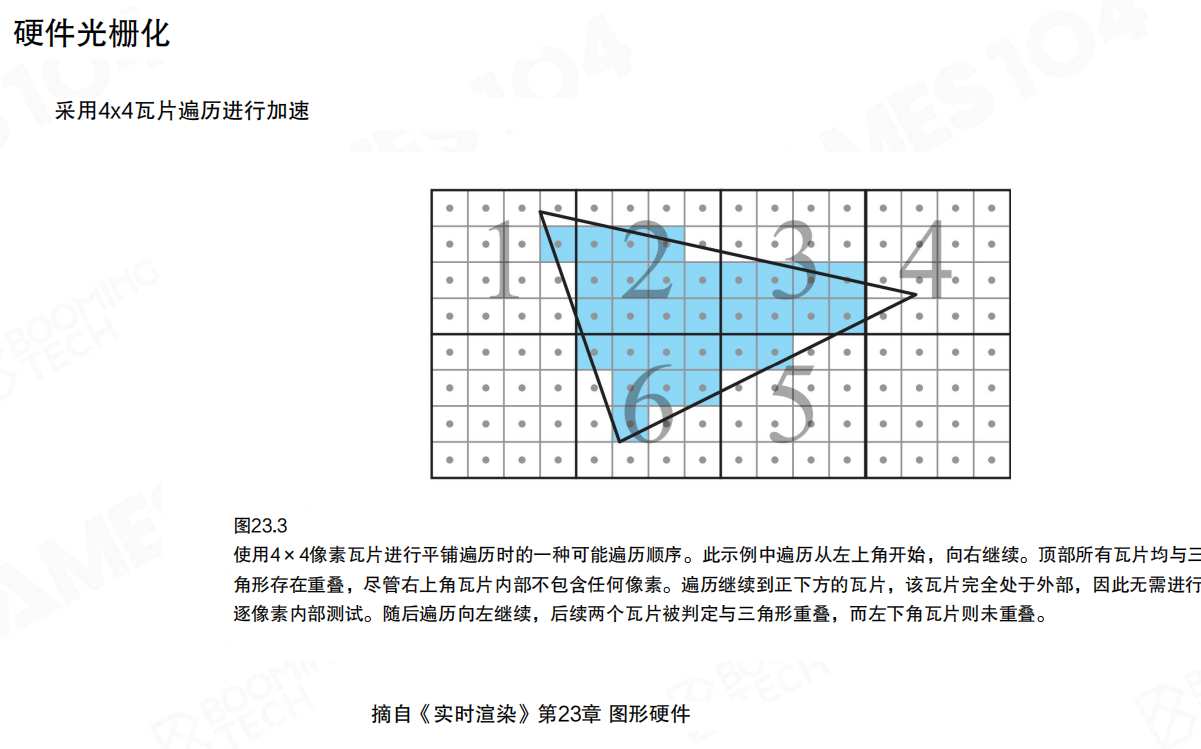
为了减少逐像素扫描的开销,硬件还会做分块遍历(例如4×4 tile)。在“大三角形时代”这很聪明:先判断 tile 是否相交,不相交就整块跳过。但当三角形小到接近像素时,tile/quad 这些“批处理”的粒度反而变大了,许多计算会变成纯浪费。
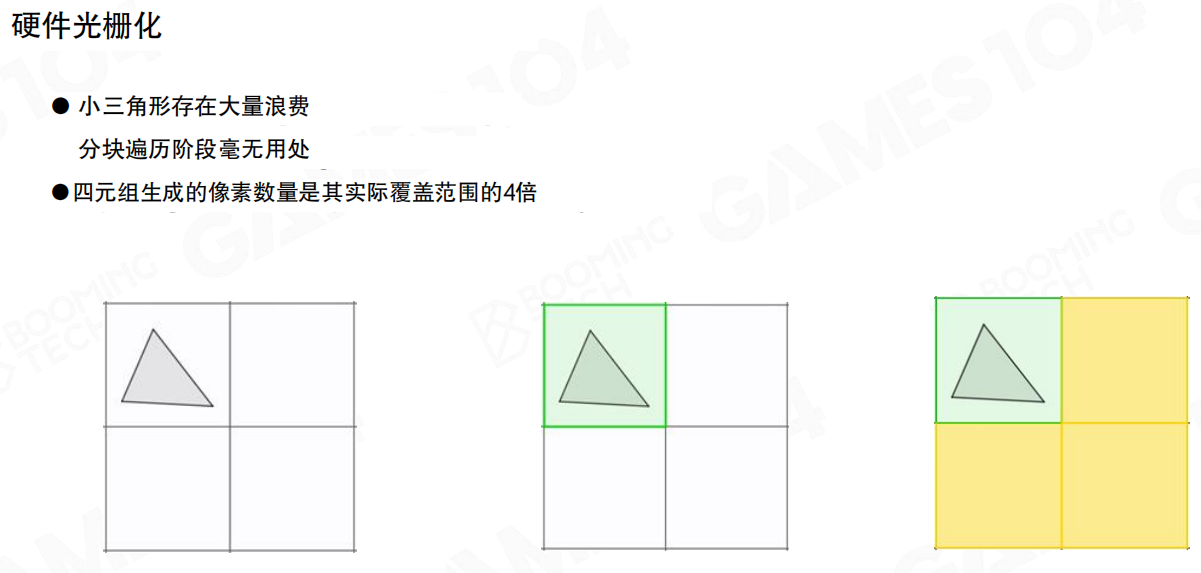
这页把浪费讲得很直白:
- 小三角形会让分块遍历阶段贡献不大。
- quad 会让实际生成的像素数接近“真实覆盖”的4倍。
微小三角形:用Compute做软件光栅化更划算
Nanite的选择是:对“足够小”的三角形(或簇),把光栅化从固定管线里拿出来,交给 compute shader 去做。

“典型光栅化器路径”很重要:宏块 → 微块4×4 → 输出2×2像素块,本质上是把并行粒度绑定在像素上。微小三角形在这条路径里是典型的“反例”:硬件能跑,但效率会被 quad/tile 吃掉。

Nanite的一个关键优化点是:当三角形在着色器空间里已经小于1像素时,完全没必要按硬件路径生成整套 quad——它可以只光栅化命中的那1个像素,并且在需要时自行重建 ddx/ddy 的导数。覆盖 1 个像素就只算 1 个像素,理论上能直接省下 3/4 的像素工作量。
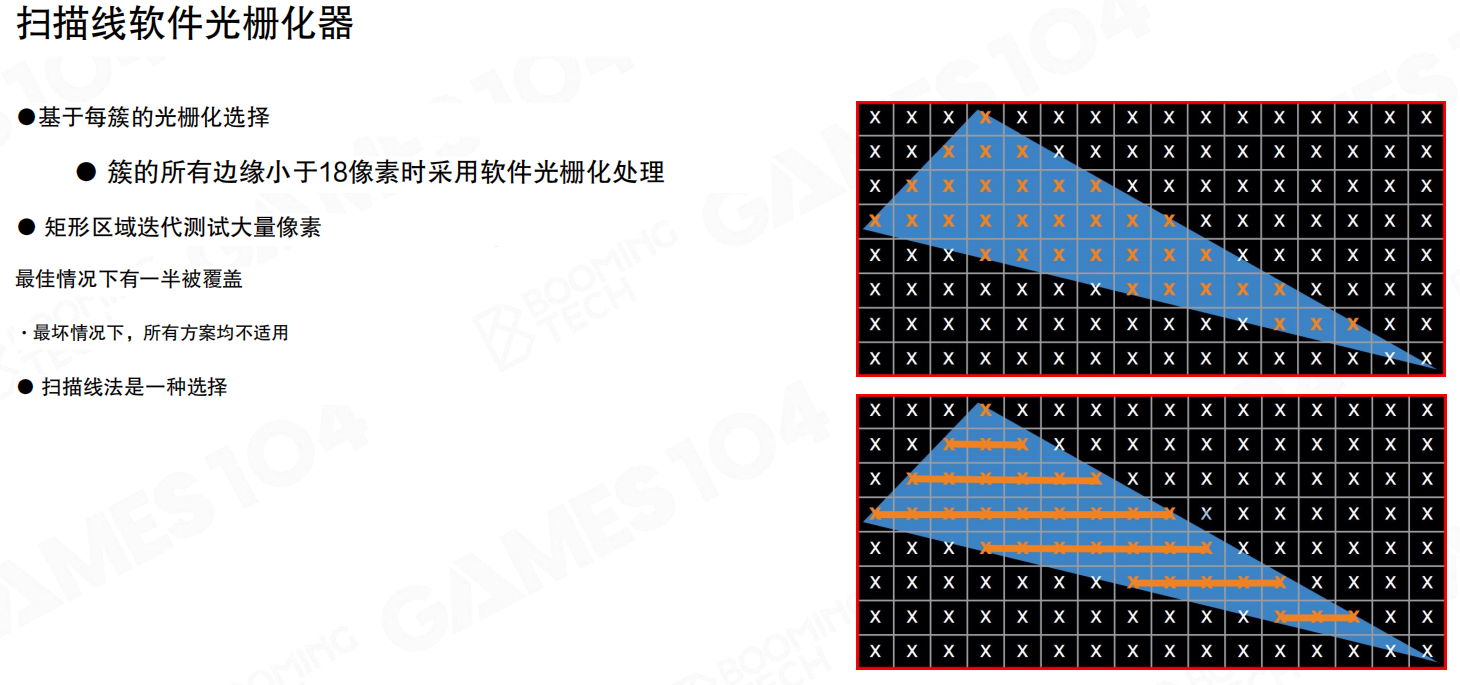
扫描线的软件光栅化只是其中一种实现:对一个簇做矩形区域迭代,找到可能覆盖的像素,再做更精细的内部测试。这里的要点是“让并行粒度更贴近真实覆盖”,而不是被 quad/tile 粒度绑死。
深度测试:用64位原子操作手动“模拟”Z-Test
compute 接管光栅化后,一个立刻冒出来的问题是:深度测试怎么办?固定管线里有 ROP/Z-Test/Early-Z,这套硬件机制在 compute 里并不会自动发生。

Nanite这里用了一个很工程的hack:使用64位原子操作,把深度和“是谁赢了这个像素”打包到同一个64位值里,并用 InterlockedMax 之类的原子比较更新。一种常见的位宽分配是:
- 32位:Depth
- 25位:Visible cluster index
- 7位:Triangle index
只要把 Depth 放在高位,就可以通过一次原子比较确定“更靠近相机的片元”胜出,同时把对应的簇/三角形索引一起写进缓冲区。
V-Buffer:先把几何“答对”,再做材质与光照
当能稳定地产生“每个像素看到的是哪一个三角形”,后面的材质与光照就好办了——这也是 Nanite 延续 V-Buffer(可见性缓冲)思路的原因。
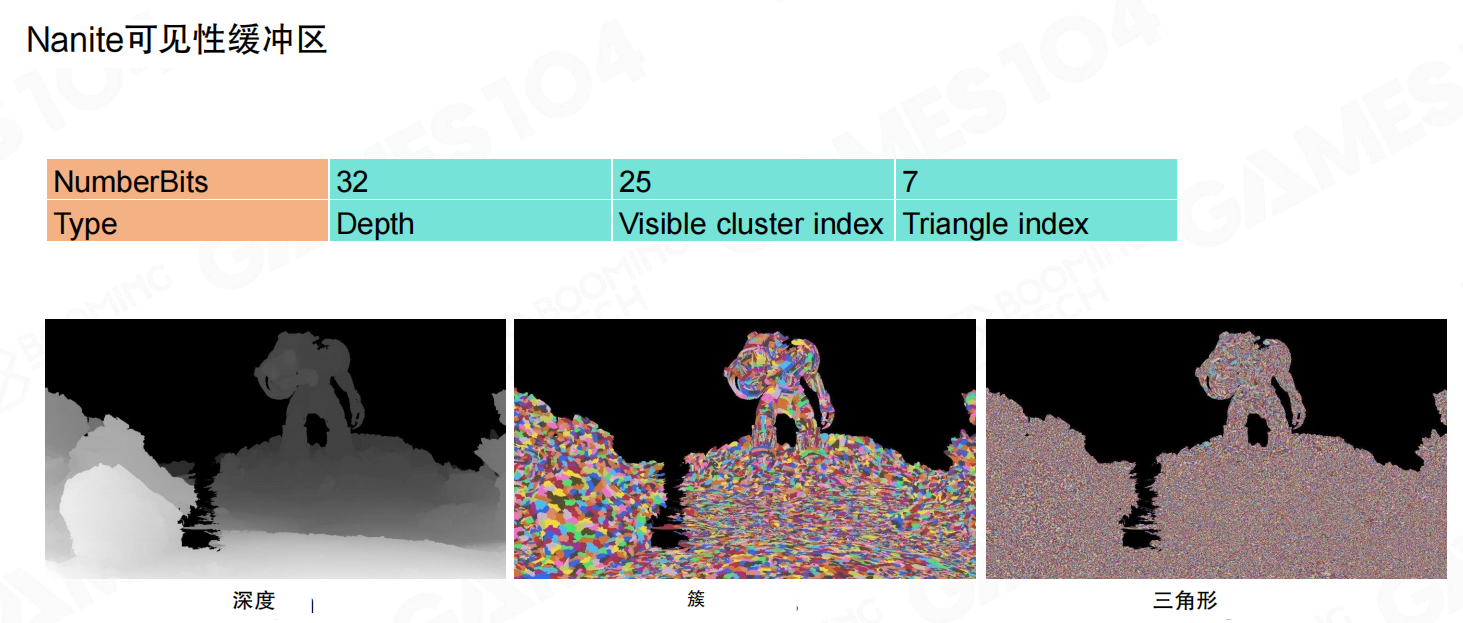
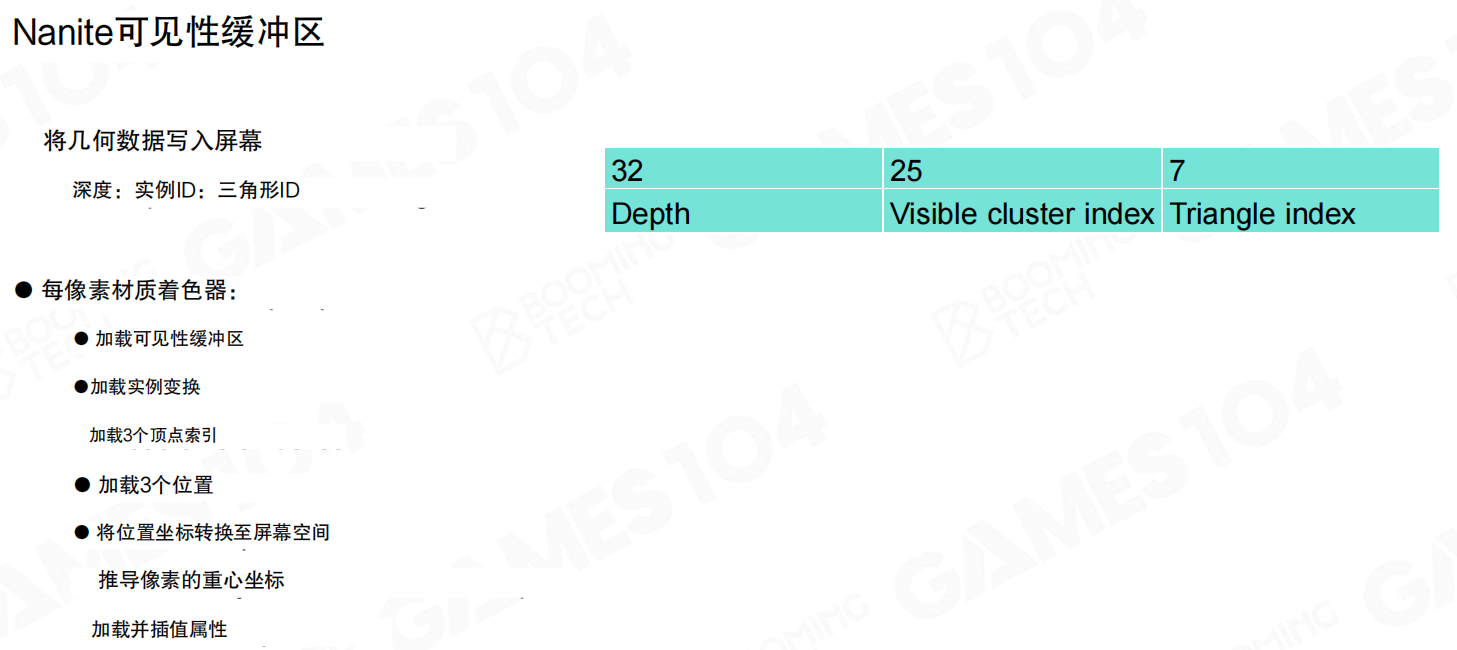
两张图合起来可以这样理解:
- 先把“几何信息写入屏幕”:深度 + 可见簇ID + 三角形ID。
- 每像素材质着色时,再根据这些ID去加载实例变换、三顶点数据,推导重心坐标,插值属性(UV/法线等),最后把材质通道写入GBuffer。
这一步的价值是“解耦”:前半段只关心可见性与几何;后半段才关心材质与光照。整体结构非常像前面介绍的可见性缓冲渲染,只不过 Nanite 把几何那一段做到了极端。

这里也回应了一个直觉疑问:听起来这么多间接加载/插值/原子操作,会不会慢到离谱?作者的结论是“并没有看起来那么慢”,主要靠缓存命中与避免过度生成 quad 的像素工作量。
软硬件混合:大三角形仍然交给硬件更合算
compute 不是银弹。对于屏幕上很大的三角形,硬件光栅化仍然更划算;Nanite会为每个簇选择“软件 or 硬件”的路径。

核心策略很朴素:小的用软件(避免 quad/tile 浪费),大的用硬件(吃满固定管线吞吐)。
微小实例:极远处用替代渲染更划算
当实例远到“即使最小簇也显得过于精细”时,Nanite也会回到传统LoD里很实用的武器:替代渲染(impostor)。

一个典型做法是:对每个小实例预先采样多个视角方向(例如12×12),每个方向存小尺寸的像素块,并保留必要的深度/ID信息;运行时直接在实例剔除通道里绘制,省掉完整Nanite几何管线的成本。
过度绘制(Overdraw):代价来源与瓶颈分布
最后总结一个现实问题:即使把光栅化做得很聪明,过度绘制仍然存在,而且不同三角形尺度下瓶颈并不相同。

这里强调的几个点很关键:
- 不需要逐三角形剔除,也不依赖硬件HiZ像素剔除;软件 HZB 可以继承上一帧。
- 剔除的是簇而不是像素:基于簇的屏幕尺寸做分辨率决策。
- 过度绘制主要来源:大型集群、重叠簇、聚合体、快速运动。
- 性能开销的瓶颈会随三角形尺寸变化:小三角形更像是顶点/设置成本,中等三角形更像是覆盖测试边界,大三角形更容易被原子/同步开销卡住。
小结
- Nanite把几何推到像素尺度后,硬件光栅化的quad/tile假设会带来明显浪费,因此引入compute做软件光栅化。
- 软件光栅化的关键不是“自己写个光栅器”,而是配套解决:
ddx/ddy、深度测试、以及和后续材质/光照的管线集成(V-Buffer → GBuffer)。 - 最终是一个软硬件混合系统:小的走软件,大的走硬件;极远处的微小实例则用替代渲染把成本压到更低。
22.9 Nanite延迟材质(Nanite Deferred Material)
到这一节,已经能把“屏幕上每个像素命中的是哪个三角形”稳定地算出来了(V-Buffer)。接下来才轮到真正影响画面质感的那一半:材质。
这里的难点不在“算一次材质”本身,而在于:一个真实场景里材质数量会非常多,而且艺术家不会接受“只能用几种材质”的约束。Nanite如果想进实战,就必须在“材质丰富”和“GPU成本可控”之间找到平衡点。

把场景按材质做伪彩色分区之后,材质会被切成一块块碎片分布在整屏。现实项目里材质数量上来后,这种“材质碎片化”是常态——所以 Nanite 如果只把几何做漂亮,最后还是会在材质阶段被拖回地面。
朴素做法:每种材质画一次全屏四边形
最直接的方案是:对每一种材质做一次全屏 pass,着色器里只处理属于该材质的像素,其它像素直接跳过。

这种方式的好处是实现简单:每种材质都画一个全屏四边形(Full Screen Quad),不匹配的像素在着色器里早退。缺点也很现实:CPU并不知道某个材质“这一帧到底有没有出现在屏幕上”,于是仍然会提交大量实际上没有意义的绘制指令——GPU驱动的优点没吃到,开销却已经先付出去了。
用硬件深度测试把“材质筛选”从像素着色里挪出去
Nanite这里用了一个很聪明的等价变换:把“材质ID”变成“深度值”,让硬件深度测试筛掉不匹配的像素。
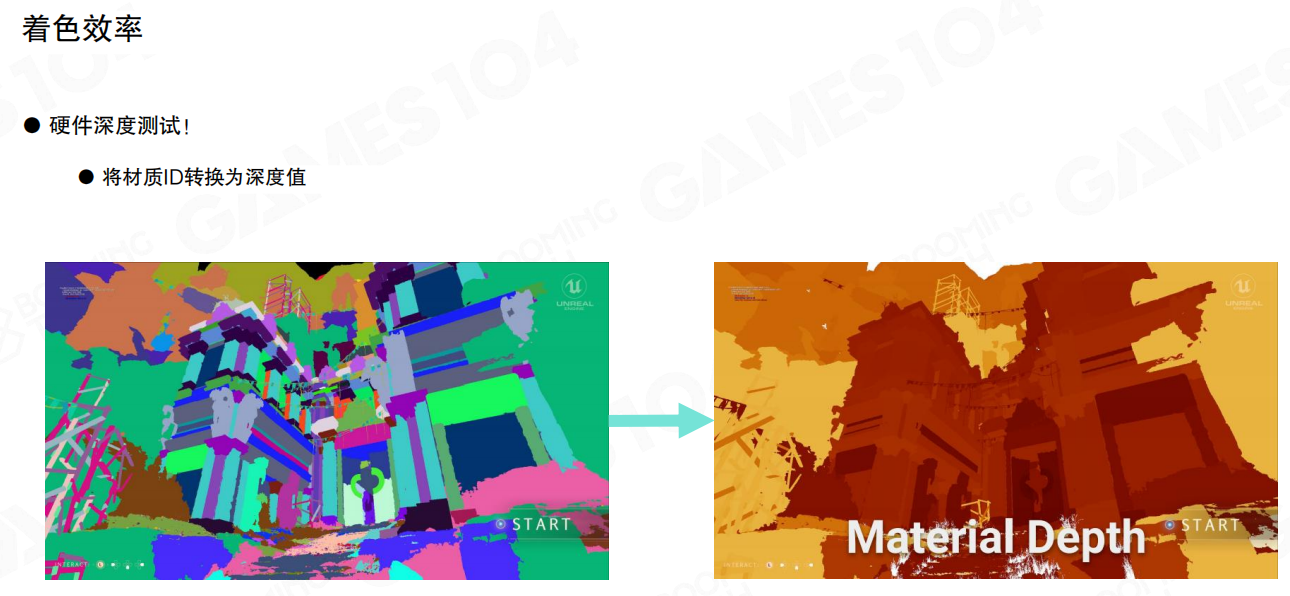
思路是把材质ID编码进一张 Material Depth 深度纹理中,然后把材质筛选交给深度测试:
- 先生成一张“材质深度图”:每个像素写入该像素对应的材质ID(编码为深度)。
- 之后绘制某个材质时,把深度测试函数设为相等(Equal):只有
Material Depth == 当前材质ID的像素会通过,其余像素被深度测试直接丢弃。
这样做的价值是:昂贵的像素着色不会被无意义地执行,筛选成本主要落在硬件深度测试上。
举个更直白的例子:假设这一帧屏幕上可见材质ID里包含 37。绘制材质 37 的 pass 时把深度测试设为 Equal,并把参考深度写成“37”。于是屏幕上只有 Material Depth == 37 的像素会跑材质 37 的像素着色器,其它像素连进入 PS 的机会都没有。

但问题也很明显:如果屏幕里材质数量是 50、100,甚至更多,那就意味着要画 50、100 次全屏四边形——即使大部分像素会被深度测试丢弃,这个“反复扫全屏”的开销仍然不小。所以全屏四边形并非必需,后面自然会往 tile-based 走。
Tile-based 材质分类:只画“真的出现过材质”的图块
更进一步的优化,是把屏幕切成若干 tile(图块),先统计每个 tile 里出现过哪些材质,然后按材质只处理“包含该材质的tile”。

把屏幕切成 tile 后,对于某个材质做 Equal 深度测试时,只有少量 tile 会有像素通过测试。直觉上一个材质通常只覆盖屏幕的一小部分区域——那就没必要为它把全屏扫一遍。
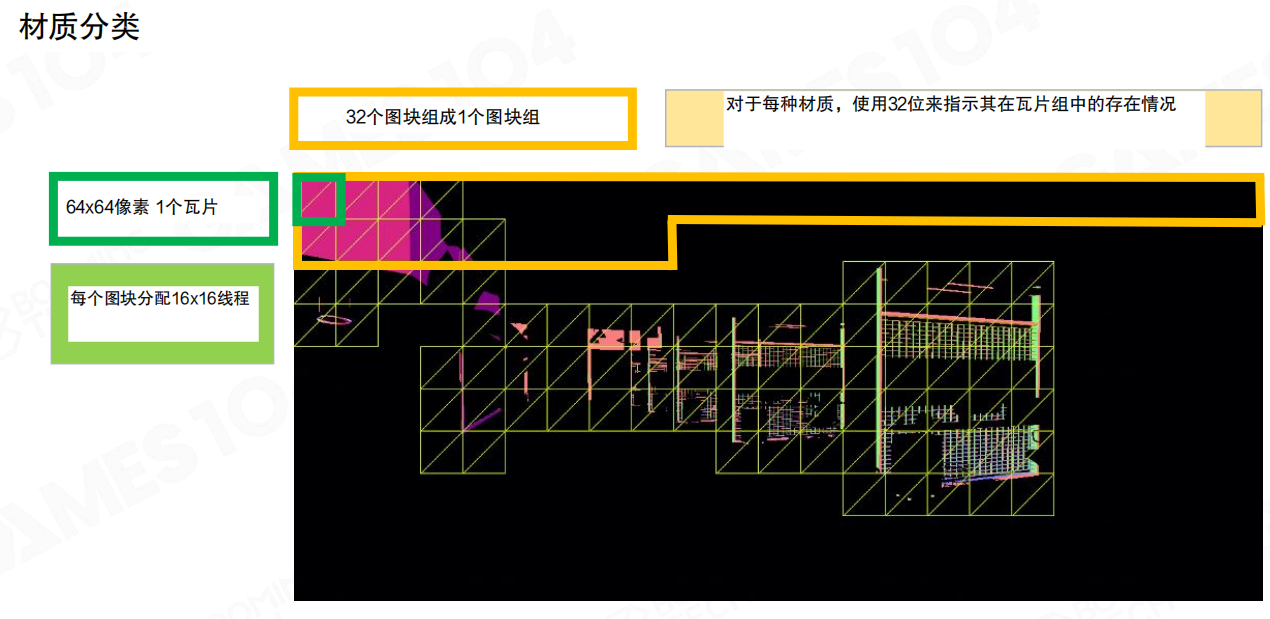
图块分类的组织方式也很工程化:
- 64×64 像素作为一个 tile。
- 32 个 tile 组成一个 tile group。
- 对每种材质,用 32 位位图标记“该材质在这个 tile group 里出现在哪些 tile”。
这样就能把“材质是否存在”的判断压缩成位运算:对某个材质而言,可以跳过大量完全不相关的tile group。
材质瓦片重映射表:用 MaterialRemapCount 把工作列表变短
当把“每个材质会落在哪些 tile”收集起来之后,就可以生成一张重映射表,让后续的绘制按“真实工作量”走,而不是按“理论最大范围”走。
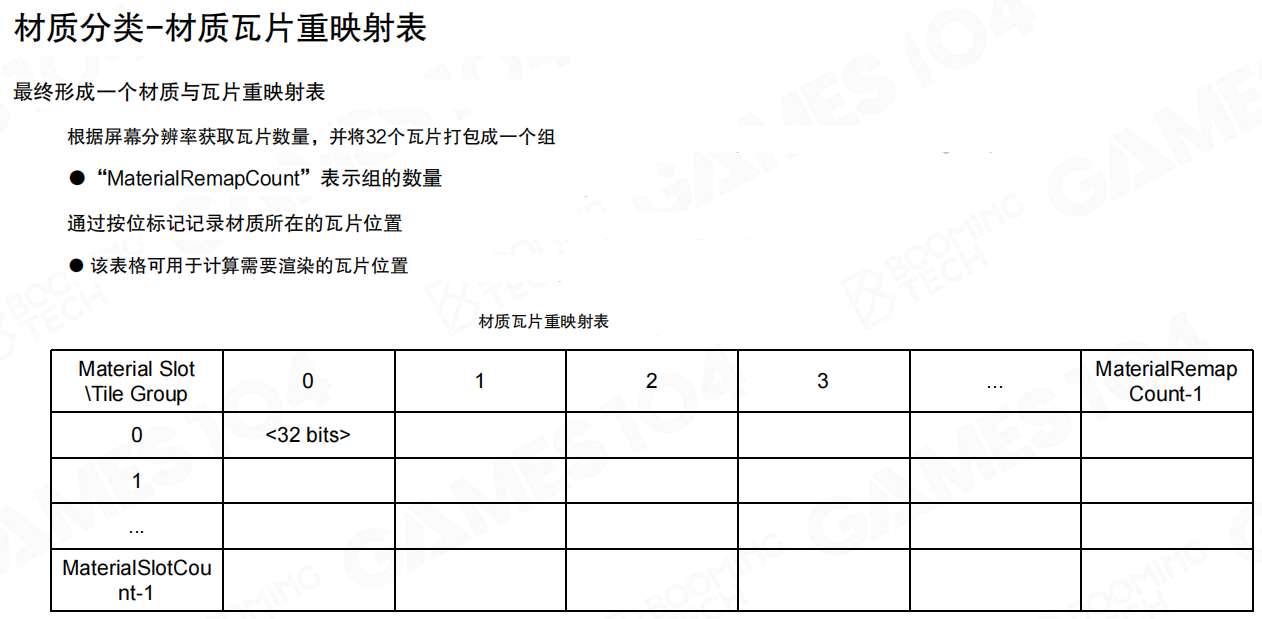
这里有两个关键名词需要记住:
MaterialRemapCount:表示 tile group 的数量(也可以理解为“这帧需要处理多少组图块”)。- 材质瓦片重映射表:用按位标记记录材质所在的 tile 位置,用来快速计算“需要渲染的tile列表”。
到这里,材质绘制的控制流就从“每个材质扫全屏”变成了“每个材质只扫自己出现过的tile”,这是吞吐和可扩展性差异最大的地方。
延迟材质整体流程
把这一节的步骤串起来,其实就是一条很干净的管线:先把几何可见性固定住,再把材质绘制变成tile级别的稀疏工作。
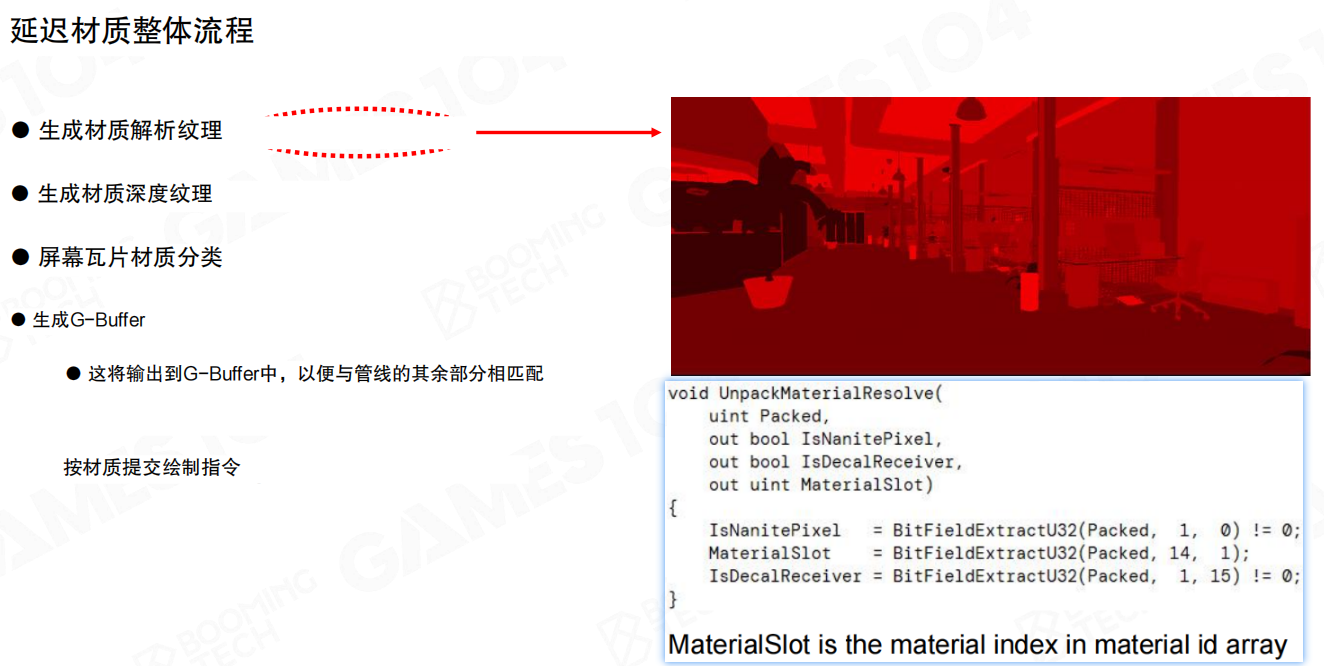
按这个流程:
- 生成材质解析纹理。
- 生成材质深度纹理(Material Depth,用于 Equal 深度测试)。
- 屏幕瓦片材质分类(tile/tile group)。
- 生成G-Buffer(把材质属性写到延迟渲染管线里)。
- 按材质提交绘制指令:借助 tile 分类结果,只处理“出现过的tile”。
实现上一般会有一个解包函数 UnpackMaterialResolve(...),用来从打包的像素信息里恢复 MaterialSlot(注释里也写得很直白:MaterialSlot is the material index in material id array),再去索引材质表完成后续着色。
小结
- Nanite要支持“艺术家随便用材质”,就必须把材质绘制从“全屏重复扫”优化成“tile级稀疏工作”。
- 把材质ID编码成 Material Depth 并用深度测试函数设为“相等”,能把大量无关像素在深度阶段就丢掉。
- 再配合 tile/tile group 的材质分类与
MaterialRemapCount重映射表,材质绘制才能在材质数量很多时仍保持可控的性能。
22.10 虚拟阴影贴图(Virtual Shadow Map)
当几何密度被推到“像素级”的时候,阴影会立刻变成整条管线里最难啃的一环:阴影本质是高频信号,阴影边界的几何精度如果跟不上,看到的就不是“糊”,而是各种抖动、破碎、脏边(artifact)。

为什么阴影在 Nanite 上更难
阴影对几何细节的“挑剔程度”,甚至高过很多材质细节:可以在远处把法线、粗糙度糊一糊,但阴影边界一旦锯齿/跳变,人眼会第一时间抓到。

一个购物车这种细线结构就是典型例子:阴影里要是丢掉“微多边形级别”的细节,影子会瞬间从“线框感”退化成一坨黑。
不是不想光追,是阴影光线数量太吓人
一个自然的问题是:为什么不直接 光线追踪(Ray Tracing)把阴影算了?核心矛盾有两个:
- 光线数量:主光线(view ray)一像素一条;阴影光线(shadow ray)是一像素乘以光源数。一个像素平均受多个光源影响时,阴影光线数量远超主光线。
- 数据表达:Nanite 的几何是高度定制化编码的;要走硬件 RT,需要提供它能直接消费的加速结构(例如 BLAS)。课上也提到一个很现实的比例:硬件三角形格式 + 底层加速结构(BLAS)目前可能是 Nanite 数据大小的 3–7 倍——不仅内存吃不消,更新/构建成本也会很夸张。

所以至少在目前这个时间点,Nanite 的阴影还是更适合沿着“经典阴影贴图”这条路继续演进,而不是硬拐进实时光追。
回到经典:基于视角的采样(CSM)与它的天花板
如果实现过级联阴影映射(Cascade Shadow Map),就会知道它背后的本质其实挺朴素:视空间(View Space)近处需要更密的采样,远处允许更粗的采样——典型的 view-dependent sampling。
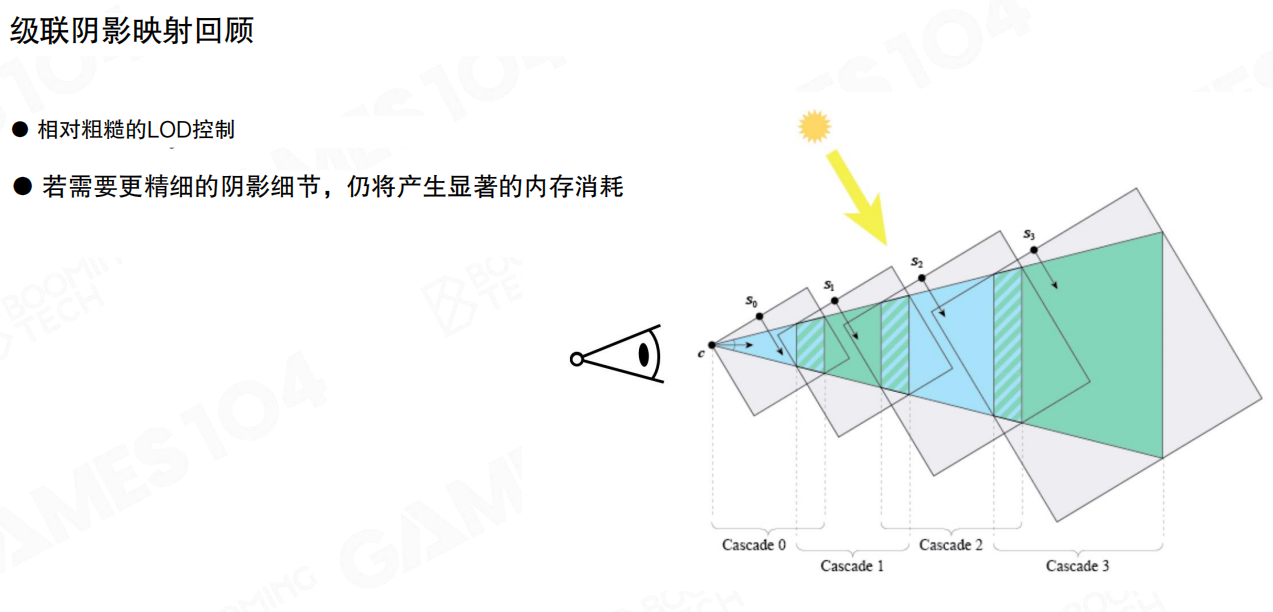
但 CSM 的问题也很明显:
- LoD 控制相对粗糙:分层是离散的,层与层之间容易出现边界/跳变。
- 要精细就要内存:级联层数、分辨率一加,阴影贴图很快就爆炸。
采样分布阴影贴图:更聪明地“把分辨率用在刀刃上”
CSM 常见的浪费是:围绕相机“无脑铺大块阴影贴图”,但真正会落到屏幕里的区域,往往只占光空间的一条带状切片。于是就有了更偏工程取向的改良:先分析屏幕像素深度范围,估计在光空间真正会用到的区域,再把阴影资源集中投到这块区域上。

这种思路的核心就是:不再按“世界空间的大圈圈”去分配,而是尽量贴着相机真正会用到的投影带去分配。
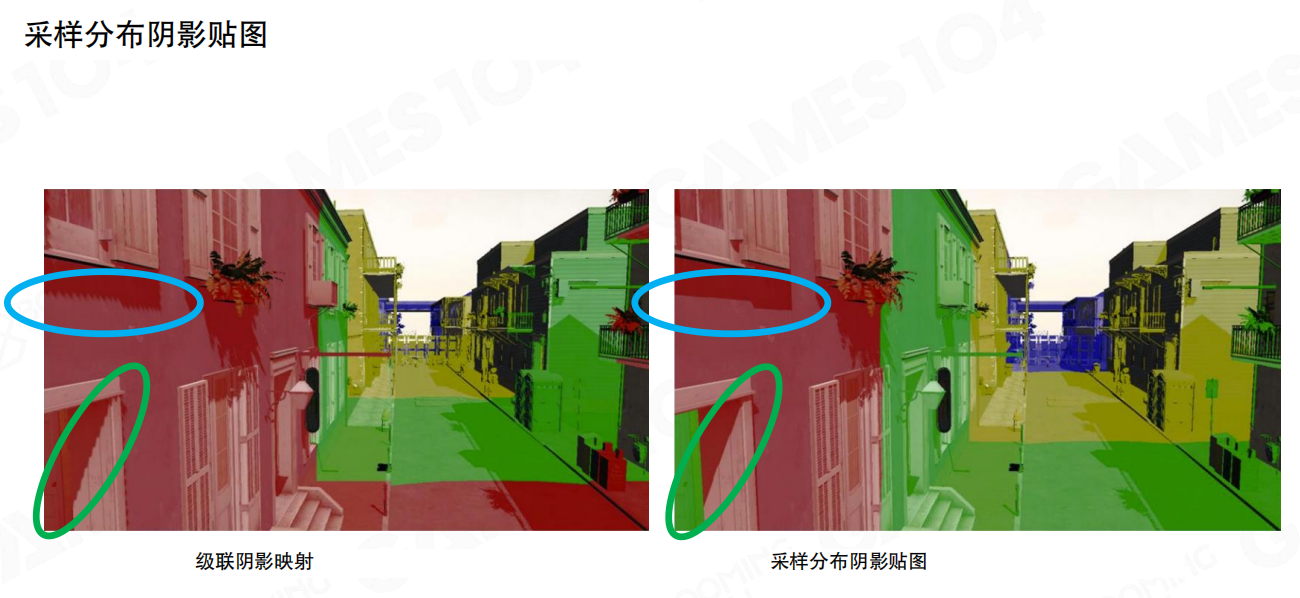
它能缓解浪费,但仍然没有解决一个根本矛盾:阴影资源依然是“按大块连续纹理”分配的,LoD 与更新粒度还是偏粗。
虚拟阴影贴图:把阴影当成“可缓存的虚拟纹理”
到 UE5 这代,真正的质变是 虚拟阴影贴图(Virtual Shadow Map):它不再把阴影贴图当作“一张必须完整渲染的大纹理”,而是把它切成很多页(page),按需分配、按需更新、尽量复用上一帧的结果。

大多数项目里主光源是相对稳定的(比如太阳角度变化很慢),那阴影也应该尽可能缓存。不需要每帧重画整张阴影贴图,只需要更新“这一帧真的变了 / 真的会用到”的那些页。
一个最常见的场景:相机平滑前进 1 米,屏幕里只有近处一条区域的投影 footprint 发生了变化。VSM 的目标就是把更新限制在这条区域对应的少量页上,而不是把整张阴影贴图全部推倒重来。

实现上通常会给每个光源一个很大的虚拟地址空间(例如 16k×16k),点光源例外,会用 6 个 VSM。不同区域采样密度不同,页的分配也会随之变化。
不同光源,不同的 VSM 布局
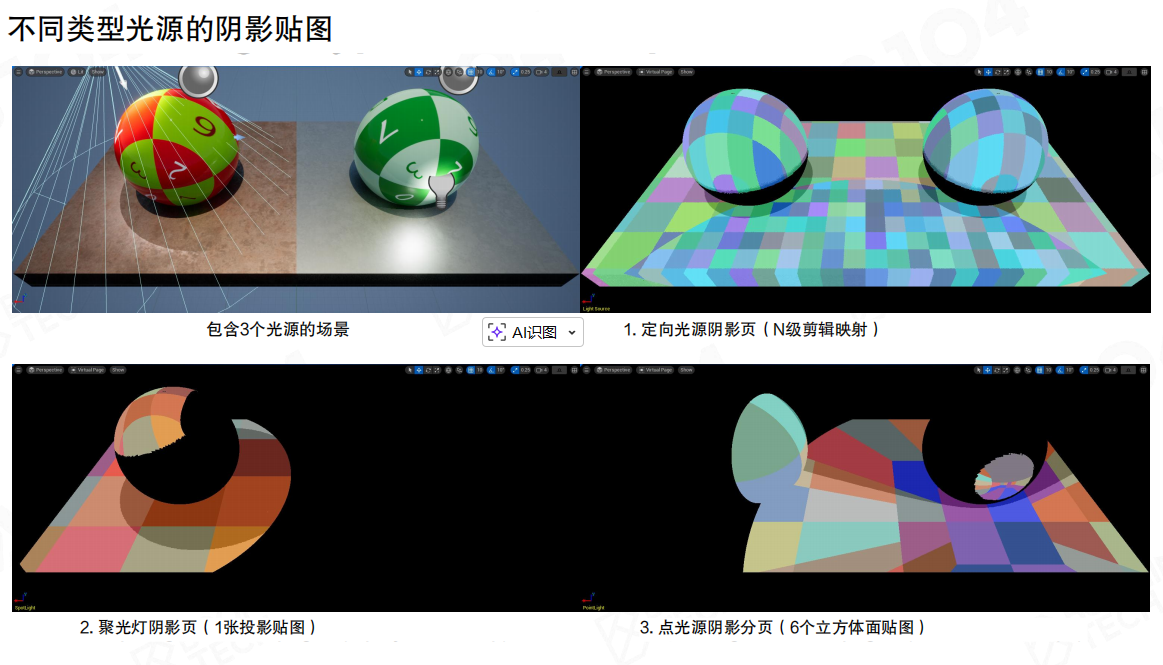
方向光、聚光灯、点光源的光空间参数差异很大,因此 VSM 的划分方式也不一样:
- 方向光:更像 clipmap/分层覆盖;
- 聚光灯:匹配光锥;
- 点光源:六个面(立方体贴图),代价最重。
页分配:只缓存“屏幕真正看得到的阴影像素”
VSM 的关键不是“页表长什么样”,而是“页是怎么被需求驱动出来的”。这页给的流程非常像虚拟纹理:
- 对屏幕上的每个像素,找出会影响它的所有光源;
- 把像素位置投影到对应的阴影贴图空间;
- 选择与像素 footprint 匹配的 mip 级别;
- 标记需要的页;缺页则从物理页池分配;
- 只对这些页进行更新渲染,然后在主渲染中采样。

页表与物理页池:索引到“哪一页、哪个 mip”
结构上会拆成两层:上层是 PageTableBuffer(按 VSM 组织),下层是物理阴影页缓存。页表项里会存页地址、LOD 偏移等信息,最终通过 indexing 找到“该采样哪一页、哪个 mip”。
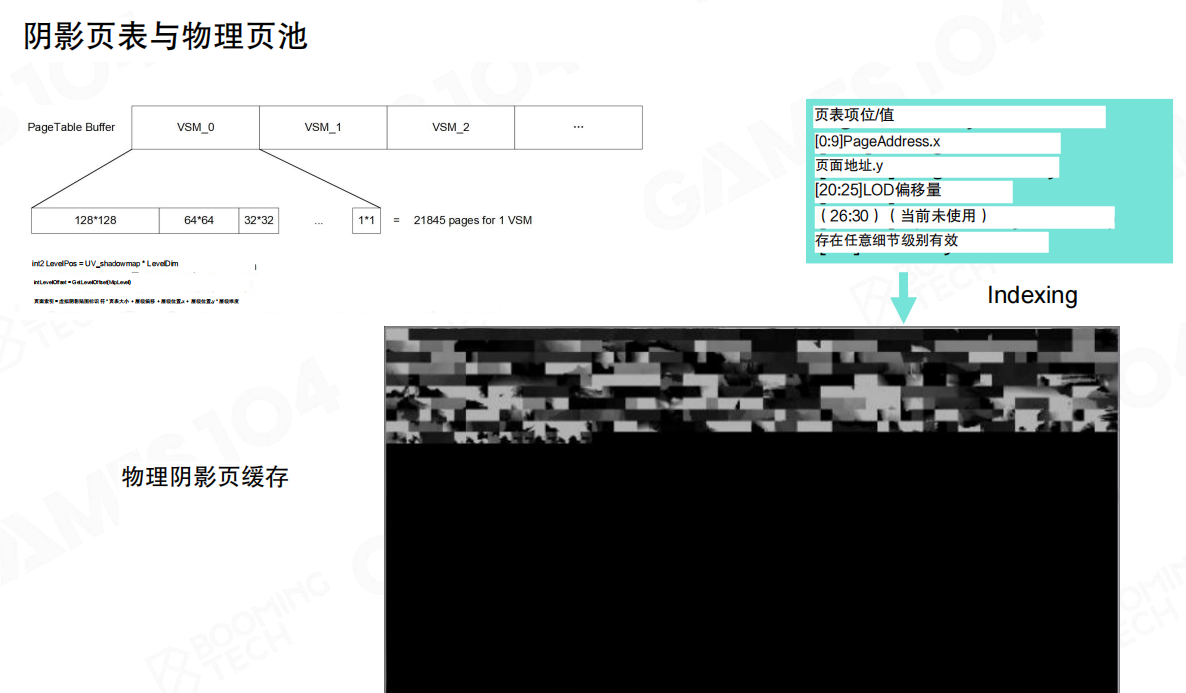
可能会看到类似 1*1 = 21845 pages for 1 VSM 这样的数字。重点不是背页数,而是理解:VSM 的虚拟空间很大,但真正驻留的物理页必须是稀疏的、按需的,否则就又退化回“画一整张大贴图”。
页缓存失效:什么时候不得不更新
缓存系统最怕“失效条件没讲清”。常见 invalidation case 很直白:
- 相机移动:如果移动比较平滑,需要更新的页不会很多;
- 光源移动/旋转:通常会导致该光源的缓存页大面积失效(最伤);
- 投影阴影的几何体发生移动/增删:从光源视角看,受影响包围盒覆盖的页表会失效;
- 使用会修改网格位置的材质:同样会导致失效范围扩大。

演示:更新的页其实很少
在调试视图 Shadow Page Cache Update 里,通常会把本帧更新过的页涂成绿色。主光源不动、相机平滑移动时,绿色区域会非常局部——这就是页缓存的意义:更新粒度被压到“该动的那几页”。

小结

- 阴影是高频信号;几何越精细,阴影越容易暴露采样不足带来的 artifact。
- 目前 Nanite 的几何表达与硬件 RT 的数据结构并不天然契合;加上阴影光线数量爆炸,实时光追阴影很难成为默认解。
- 虚拟阴影贴图(Virtual Shadow Map)把阴影当作“虚拟纹理”:大虚拟空间 + 稀疏物理页 + 缓存复用 + 按需更新。
- 阴影成本与分辨率、以及每像素受影响的光源数量强相关;因此它特别适合“主光源基本不动”的场景。
22.11 流式与压缩(Streaming and Compression)
前面把 LoD、剔除、软件光栅化、延迟材质和 VSM 都串起来之后,还有一个“落地到开放世界”绕不过去的问题:这么多几何数据,总不能一股脑塞进显存里。
Nanite 的答案其实很朴素——把几何也做成虚拟化资源,像虚拟纹理一样用到才加载;同时对内存/磁盘两端分别做压缩,把吞吐和容量都压到可用的范围。

核心概念很简单:
- 在固定内存预算下实现“无限几何”(更准确说是:让可见几何在预算内稳定运行)。
- 概念上类似虚拟纹理(Virtual Texture):GPU 发起所需数据请求,CPU 侧响应并把数据喂回来。
- 独特挑战是:几何必须无裂缝(Seamless)。不能像贴图那样缺一块先糊过去,网格缺页会直接在轮廓上炸出洞。
- 运行时对 DAG 做有效切割,只加载可见几何;这一步的约束很像 LoD cut:既要 view-dependent,又要无裂缝。
分页:Root 常驻 + Streaming Pages 按需换入
实现“用到才加载”的关键是分块。Nanite 把几何数据切成固定大小的页(page),并把“永远需要的那一点”留在 GPU 上。

这里有几个关键的工程取舍:
- 根页(Root,64k):第一页包含 DAG 的最高 LoD 层级,始终驻留在 GPU 上,这样即使还没来得及流式加载,至少永远有内容可渲染,不会出现“镜头一动就全黑”的尴尬。
- 流式处理页(Streaming Pages,128k):承载集群组的其它 LoD 层级;生命周期在 CPU 端用 LRU(最近最少使用)算法管理。
- 最小化运行时页数:按 mip 级别和空间局部性对 group 进行排序,让一次相机移动带来的缺页更“集中”,更像顺序 IO。
- 页内容:索引数据、顶点数据、边界框、LoD 信息、材质表等都会被打包进页里。
如果把它类比成虚拟纹理:Root 像常驻的最低 mip;Streaming Pages 像更细的 mip tile,只在需要时换入。只不过贴图缺一块还能糊过去,几何缺一块会直接“破相”。
内存表示:量化 + 变长编码,GPU 侧解码
页加载进来只是第一步,页内的数据怎么存也决定了吞吐和容量。

内存中的表示更偏“显存友好”:
- 量化(Quantization):把原本的浮点(例如顶点位置、UV)转成定点。典型做法是利用 cluster 的边界框(BBox)把坐标映射到局部坐标系,再用更少的比特存储。
- 每簇自定义顶点格式:不同 cluster 的取值范围不同,所以每个分量用多少比特也不同(常见写法是
ceil(log2(取值范围)),表示“按范围分配最少比特数”)。 - 只是一串比特流:为了省空间,甚至不按字节对齐。
- GPU 位流读取器解码:因为簇与簇的编码格式可能不同,必须在 GPU 上做解码,否则 CPU 侧转码会把吞吐和线程都拖死。
直观例子:近处岩壁的 cluster 需要更细的坐标量化;远处大地形用更粗的量化也看不出来。每簇自适应,才不会被“全局统一格式”强行拉高成本。
磁盘表示:硬件 LZ + DirectStorage,把 IO 变成显存吞吐
内存里用量化解决的是“常驻成本”;磁盘上解决的是“海量数据怎么搬得动”。

可以总结成三句话:
- 磁盘侧用硬件 LZ 解压(通用型、速度几乎跟 IO 绑定),并通过
DirectStorage这类路径把数据更直接地送往 GPU。 - 为了更好的压缩率,会做一些领域相关的整理:例如字符串去重/熵编码,以及针对 LZ 不擅长捕获的冗余进行“对齐/填充”(padding)来提高字典命中率。
- 在 GPU 上并行转码:例如 PS5 上给过约 50GB/s 的量级,想表达的重点是——一旦把解码/转码并行化,流式就能跟上镜头推进。
结果:几何“看起来无穷”,但代价可控
最后两张基本就是“结账单”和“展示视频”。
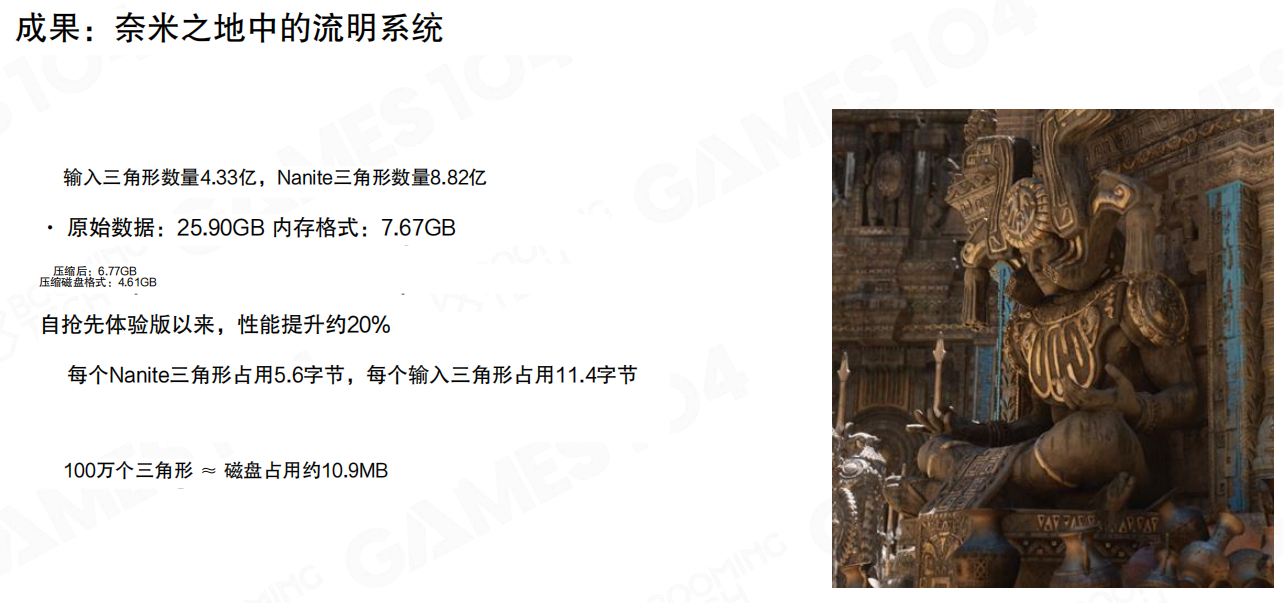
在“奈米之地”的统计里:
- 输入三角形数量 4.33 亿,Nanite 三角形数量 8.82 亿。
- 原始数据 25.90GB,内存格式 7.67GB。
- 自抢先体验版以来,性能提升约 20%。
- 平均每个 Nanite 三角形占用 5.6 字节,每个输入三角形占用 11.4 字节。
- 100 万个三角形 ≈ 磁盘占用约 10.9MB。
这些数字背后的信号很明确:Nanite 的“无限细节”不是靠魔法,而是靠 分页 + 压缩 + 高吞吐 IO,把大数据从“不可用”压到“可实时”。

最后的“几何丛林”镜头更像是在验收:相机钻进地形缝隙里仍然能维持高帧率,说明运行时确实把“该来的页”按时送到了 GPU。
小结
- 虚拟化几何的本质:像虚拟纹理一样按需请求与加载,但必须保证几何无裂缝。
- Root 常驻保证“永远有内容可渲染”;Streaming Pages 用 LRU 在 CPU 侧管理,并按 mip/空间局部性排序以降低缺页数量。
- 内存侧靠 量化(Quantization)+ 变长比特编码节省空间,并用 GPU 位流读取器解码。
- 磁盘侧用硬件 LZ +
DirectStorage把 IO/解压吞吐变成可用的显存带宽,配合一些 padding/trick 提升压缩效率。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

