66.性能优化-GPU-影响因素-内存带宽
66.1 知识点
内存带宽的基本概念
内存带宽指的是 GPU 在单位时间内,显存(VRAM)和 GPU 内部之间能传输的数据量。
常用单位:GB/s(每秒多少 GB)。
| 平台 | 典型内存带宽 |
|---|---|
| PC 显卡 | 100 GB ~ 1 TB/s |
| 游戏主机 | 200 ~ 600 GB/s |
| 移动设备 | 30 ~ 200 GB/s |
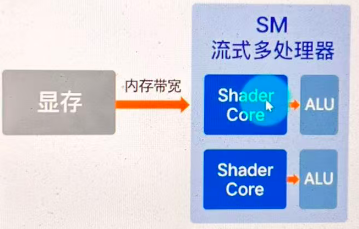
GPU 内部
1. ALU(算术逻辑单元,Arithmetic Logic Unit)
最基础的计算单元,负责加减乘除、位运算、逻辑运算等。
比如着色器中的数学计算,就是由它来处理的。
它是 GPU 的最小”工人”,做具体数学计算的。
2. SM(流式多处理器,Streaming Multiprocessor)
NVIDIA 架构里的术语(AMD 里叫 CU,即计算单元 Compute Unit)。
一个 SM 中包含很多 ALU(算术逻辑单元)、寄存器、共享内存、调度器等。
它的主要功能就是负责调度和并行执行成千上万个线程。
它是 GPU 里的一个小工厂,里面有很多工人(ALU)和管理员(调度器)以及仓库(寄存器、缓存)。
3. 着色器核心
厂商宣传时最常说的单位:
- NVIDIA 叫 CUDA Core(统一计算设备架构核心)
- AMD 叫 Stream Processor(流处理器)
- Intel 或移动设备 GPU 叫 Shader Core(着色器核心)
它是 ALU(算术逻辑单元)集合体,负责运行着色器指令(顶点、片元、计算等)。
它是 GPU 对外宣传的工人数目,里面的工人就是 ALU(算术逻辑单元)。
GPU 外部
显存(VRAM)一般是 GPU 封装在一起的独立芯片:
- 独显:显存独立,紧贴 GPU 芯片。
- 集显/移动端:显存 = 系统内存,GPU 和 CPU 共用同一内存池。
显存是 GPU 外部的大仓库,里面存储着顶点数据、纹理、Shader 常量、渲染目标(RenderTarget)、深度/颜色缓冲等。
SM(流式多处理器)需要从显存中搬运数据过来(会放在寄存器或共享内存中),然后把数据分给着色器核心进行计算。
着色器核心中的 ALU(算术逻辑单元)需要不断从寄存器、缓存,必要时还会直接从显存中拿数据进行计算。
通俗理解
- ALU(算术逻辑单元)是一个工人,只会做加减乘除、逻辑运算。
- Shader Core(着色器核心)是一组工人,负责跑一条着色器指令。
- SM(流式多处理器)是一个小工厂,里面有成百上千个工人,还有仓库(寄存器、共享内存)、管理器(调度器)。
- GPU 就是一个大工厂,里面有几十到上百个小工厂(SM),可以同时开工。
- 显存就是存储原料(各种数据)的一个大仓库。
内存带宽就是一条从大仓库运原料到小工厂的输送带,决定单位时间内可以运送多少原料(数据)。
为什么内存带宽会影响性能
GPU 渲染过程中会频繁地访问显存读取或写入数据:
- GPU 会读取:顶点数据、纹理、贴图、深度缓冲等。
- GPU 会写入:颜色缓冲、深度缓冲、后处理结果等。
GPU 内部的计算单元(ALU、SM、着色器核心)执行速度是很快的,但它们需要不断从显存中存取数据。
如果内存带宽不足,数据就不能及时送到计算单元,让内存带宽成为性能瓶颈。
相当于 GPU 中计算单元计算很快,但迟迟拿不到数据,GPU 就会游手好闲地等待数据。
其实并不是 GPU 算力不足,而是由于内存带宽造成了 GPU 的性能浪费,不能达到最好的状态。
说人话:
内存带宽带来性能影响的原因是输送带(内存带宽)数据搬运速度跟不上工厂工人(Shader Core / ALU)的计算处理速度,导致 GPU(大工厂)算力浪费。
什么原因可能造成内存带宽瓶颈
1. 分辨率和填充率过高
- 高分辨率渲染(4K、8K):像素数巨增,颜色缓冲、深度缓冲数据量暴涨。
- 多重采样抗锯齿(MSAA
2x/4x/8x):每像素要写多份数据,带宽需求成倍增加。 - 大量 OverDraw:一个像素被写多次,重复读写显存。
一般 UI 半透明、粒子特效、后处理效果叠加都会导致带宽消耗剧增。
2. 纹理访问压力大
- 使用超高分辨率纹理,GPU 每次采样需要从显存搬很多数据。
- 缺少 Mipmap 或错误采样(远处物体还用 4K 贴图)。
- 未压缩纹理格式(
RGBA32:4 字节/像素,ASTC压缩:可能 < 1 字节/像素)。 - 多贴图采样(法线、粗糙度、金属度分开存,采样次数多)。
移动 GPU 尤其容易因此卡死。
3. RenderTarget 过大/过多
RenderTarget 指 GPU 渲染管线里片元着色器输出结果要写入的缓冲区,Unity 里常用的就是 RenderTexture。
任何 GPU 可以写入的缓冲区都可以称为 RenderTarget。
- 使用高精度 RT,每像素字节数非常高。
- 延迟渲染,一次写多个缓冲(法线、深度、材质参数)。
- 屏幕后处理频繁 Blit 全屏,每一步都要读写一整张 RT。
4. 硬件和系统限制
- 显存位宽不足。
- 显存频率较低。
总结:
只要游戏中单位时间内 GPU 的数据读写需求大于显存带宽承载能力时,就会形成内存带宽瓶颈。
带宽消耗举例
以 4K 显示器(830 万像素)、60FPS 为例,仅颜色缓冲一项的带宽需求:
| 渲染目标格式 | 每像素字节数 | 一帧数据量 | 1 秒带宽需求 |
|---|---|---|---|
RGBA8 |
4 字节/像素 | 33 MB | 2 GB/s |
RGBA16F |
8 字节/像素 | 66 MB | 4 GB/s |
RGBA32F |
16 字节/像素 | 133 MB | 8 GB/s |
高画质游戏的各种缓冲区就可能吃掉几十 GB/s 内存带宽,再加上纹理、深度、后处理等渲染处理内容,轻轻松松超过 100 GB/s。
关于内存带宽的优化思路
内存带宽的主要优化思路就是:减少显存的读写量,让 GPU 少搬运、多干活。
减少分辨率和像素相关的开销
- 降低渲染分辨率(动态分辨率、注视点渲染)。
- 降低抗锯齿采样。
- 减少 OverDraw。
优化纹理相关的开销
- 使用 Mipmap
远处物体采样低分辨率贴图,减少带宽浪费。 - 压缩纹理格式
ASTC / ETC2 等压缩格式,可以显著减少带宽占用。 - 贴图合并
可以把粗糙度、金属度纹理合并,减少采样次数。 - 合理分辨率
角色贴图、UI 纹理尽量在满足需求的情况下使用小分辨率图片。
提高缓存利用率
- 访问连续化
避免 Shader 中随机纹理采样,尽量连续访问,增加缓存命中率。 - 减少冗余读取
能一次采样合并的就合并;不要重复读取深度、颜色等数据。 - 前向渲染排序
不透明物体从前到后排序,让 Early-Z(提前深度测试)提前丢掉被挡片元,减少显存读写。
减少不必要的数据存储
- 避免冗余拷贝
有时项目里会把同一贴图拷到多个 RT,检查是否必要。 - 利用 GPU 共享内存
一些重复计算的数据,可以在共享内存里缓存,避免回显存。可以在 Shader 代码中声明共享内存。 - 压缩 G-Buffer
G-Buffer 是延迟渲染阶段 GPU 用来存储几何信息的一组缓冲区。通过编码/优化,把原来需要 4~6 张全精度 RT 的数据,压缩到更少的通道/更低的位宽里,从而减少显存和带宽开销。
比如法线压缩、八面体编码、位置压缩、材质参数压缩、降低精度等。
优化 RenderTarget
- 降低精度
使用RenderTexture时可以用低精度格式替代。SRP 项目中可以设置缓冲区精度,也可以在 Shader 中设置更低精度缓冲区。 - 半分辨率渲染屏幕后处理效果
屏幕后处理效果可以用 1/2、1/4 分辨率处理后放大。 - 减少全屏 Blit
多个后处理效果尽量合并到一个 Pass,避免重复拷贝整屏。
平台相关优化
- 移动端:纹理压缩、半分辨率后处理、避免大面积透明 UI 等。
- PC / 主机:带宽相对高,但高分辨率、高精度 HDR、高 MSAA 下仍容易成为瓶颈,可通过降低 RT 精度 + 减少全屏 Pass(屏幕后处理效果)缓解。
66.2 知识点代码
Lesson66_性能优化_GPU_影响因素_内存带宽.cs
public class Lesson66_性能优化_GPU_影响因素_内存带宽
{
#region 知识点一 内存带宽的基本概念
//内存带宽指的是
//GPU 在单位时间内,显存(VRAM)和 GPU 内部之间能传输的数据量
//常用单位:GB/s(每秒多少 GB)
//PC显卡:100GB~1TB/s
//游戏主机:200~600GB/s
//移动设备:30~200GB/s
//GPU内部
//1.ALU(算术逻辑单元,Arithmetic Logic Unit)
// 最基础的计算单元,负责加减乘除、位运算、逻辑运算等
// 比如着色器中的数学计算,就是由它来处理的
// 它 是 GPU 的最小"工人",做具体数学计算的
//2.SM(流式多处理器,Streaming Multiprocessor)
// NVIDIA 架构里的术语(AMD 里叫 CU(计算单元, Compute Unit) )
// 一个SM中包含很多ALU(算术逻辑单元)、寄存器、共享内存、调度器 等等
// 它的主要功能就是负责调度和并行执行成千上万个线程
// 它 是 GPU 里的一个小工厂,里面有很多工人(ALU) 和 管理员(调度器) 以及仓库(寄存器、缓存)
//3.着色器核心
// 厂商宣传时最常说的单位
// NVIDIA 叫 CUDA Core(统一计算设备架构核心)
// AMD 叫 Stream Processor(流处理器)
// Intel或移动设备GPU 叫 Shader Core(着色器核心)
// 它是ALU(算术逻辑单元)集合体,负责运行着色器指令(顶点、片元、计算等)
// 它 是 GPU 对外宣传的工人数目,里面的工人就是 ALU(算术逻辑单元)
//GPU外部
//显存(VRAM)一般是 GPU 封装在一起的 独立芯片
//独显:显存独立,紧贴 GPU 芯片
//集显/移动端:显存 = 系统内存,GPU 和 CPU 共用同一内存池
//它是GPU外部大仓库
//里面存储着 顶点数据、纹理、Shader常量、渲染目标(RenderTarget)、深度/颜色缓冲等
//SM(流式多处理器)需要从显存中搬运数据过来(会放在寄存器或共享内存中)
//然后把数据分给 着色器核心 进行计算
//着色器核心中的ALU(算术逻辑单元)需要不断从
//寄存器、缓存,必要时还会直接从显存中拿数据进行计算
//说人话:
//ALU(算术逻辑单元)是一个工人,只会做加减乘除、逻辑运算
//Shader Core (着色器核心) 是一组工人,负责跑一条着色器指令
//SM(流式多处理器)是一个小工厂,里面有成百上千个工人,还有仓库(寄存器、共享内存),管理器(调度器)
//GPU 就是一个大工厂,里面有几十到上百个小工厂(SM),可以同时开工
//显存 就是存储原料(各种数据)的一个大仓库
//内存带宽 就是一条从大仓库运原料到小工厂的输送带,决定单位时间内可以运送多少原料(数据)
#endregion
#region 知识点二 为什么内存带宽会影响性能
//GPU渲染过程中会频繁的访问显存读取或写入数据
//GPU会读取:顶点数据、纹理、贴图、深度缓冲 等等数据
//GPU会写入:颜色缓冲、深度缓冲、后处理结果 等等数据
//GPU 内部的计算单元(ALU、SM、着色器核心)执行速度是很快的
//但它们需要不断从显存中存取数据
//如果内存带宽不足,数据就不能及时送到计算单元
//让内存带宽成为性能瓶颈
//相当于
//GPU中计算单元计算很快,但是迟迟拿不到数据,GPU就会游手好闲的等待数据
//其实并不是GPU算力不足,而是由于内存带宽造成了GPU的性能浪费,不能达到最好的状态
//说人话:
//内存带宽带来性能影响的原因是
//输送带(内存带宽)数据搬运速度跟不上 工厂 工人( Shader Core/ALU )的计算处理速度
//导致 GPU(大工厂) 算力浪费
//什么原因可能造成内存带宽瓶颈
//1.分辨率和填充率过高
// 1-1.高分辨率渲染(4k、8k)
// 像素数巨增,颜色缓冲、深度缓冲数据量暴涨
// 1-2.多重采样抗锯齿 (MSAA 2×/4×/8×)
// 每像素要写多份数据,带宽需求成倍增加
// 1-3.大量 OverDraw
// 一个像素被写多次,重复读写显存
// 一般UI半透明、粒子特效、后处理效果叠加都会导致带宽消耗剧增
//2.纹理访问压力大
// 2-1.使用 超高分辨率纹理,GPU 每次采样需要从显存搬很多数据
// 2-2.缺少 Mipmap 或 错误采样(远处物体还用 4K 贴图)
// 2-3.未压缩纹理格式(RGBA32:4 字节/像素,ASTC 压缩:可能 <1 字节/像素)
// 2-4.多贴图采样(法线、粗糙度、金属度分开存,采样次数多)
// 移动 GPU 尤其容易因此卡死
//3.RenderTarget过大/过多
// RenderTarget指 GPU 渲染管线里 片元着色器输出结果要写入的缓冲区,Unity 里常用的就是 RenderTexture
// 任何 GPU 可以写入的缓冲区都可以称为 RenderTarget
// 使用 高精度 RT,每像素字节数非常高
// 延迟渲染,一次写多个缓冲(法线、深度、材质参数)
// 屏幕后处理频繁 Blit 全屏,每一步都要读写一整张 RT
//4.硬件和系统限制
// 显存位宽不足
// 显存频率较低
//说人话:
//只要是游戏中单位时间内的 GPU 的数据读写需求大于显存带宽承载能力时
//就会形成内存带宽瓶颈
//4K显示器:830万像素
//帧率:60FPS
//渲染目标格式(一帧的颜色缓冲):
//RGBA8:4字节/像素 = 33MB
//RGBA16F:8字节/像素 = 66MB
//RGBA32F:16字节/像素 = 133MB
//1s带宽需求
//RGBA8:33MB * 60 = 2GB/s
//RGBA16F:66MB = 4GB/s
//RGBA32F:133MB = 8GB/s
//高画质游戏、各种缓冲区就可能吃掉 几十GB/s 内存带宽
//再加上 纹理、深度、后处理等等 渲染处理内容的话
//轻轻松松的 超过100GB/s
#endregion
#region 知识点三 关于内存带宽的优化思路
//内存带宽的主要优化思路就是
//减少显存的读写量,让GPU 少搬运,多干活
//1.减少分辨率和像素相关的开销
// 1-1.降低渲染分辨率(动态分辨率、注视点渲染)
// 1-2.降低抗锯齿采样
// 1-3.减少 OverDraw
//2.优化纹理相关的开销
// 2-1.使用 Mipmap
// 远处物体采样低分辨率贴图,减少带宽浪费
// 2-2.压缩纹理格式
// ASTC / ETC2等压缩格式,可以显著减少带宽占用
// 2-3.贴图合并
// 可以把粗糙度、金属度纹理合并,减少采样次数
// 2-4.合理分辨率
// 角色贴图、UI纹理尽量在满足需求的情况下使用小分辨率图片
//3.提高缓存利用率
// 3-1.访问连续化
// 避免 Shader 中随机纹理采样,尽量连续访问,增加 缓存 命中率
// 3-2.减少冗余读取
// 能一次采样合并的就合并;不要重复读取深度、颜色等数据
// 3-3.前向渲染排序
// 不透明物体 从前到后 排序,让 Early-Z (提前深度测试)提前丢掉被挡片元,减少显存读写
//4.减少不必要的数据存储
// 4-1.避免冗余拷贝
// 有时项目里会把同一贴图拷到多个 RT,检查是否必要
// 4-2.利用 GPU 共享内存
// 一些重复计算的数据,可以在共享内存里缓存,避免回显存
// 可以在Shader代码中声明共享内存
// 4-3.压缩 G-Buffer(延迟渲染阶段 GPU 用来存储几何信息的一组缓冲区)
// 通过编码/优化,把原来需要 4~6 张全精度 RT 的数据,压缩到更少的通道/更低的位宽里,从而减少显存和带宽开销
// 比如法线压缩、八面体编码、位置压缩、材质参数压缩,降低精度等等
//5.优化 RenderTarget
// 5-1.降低精度
// 使用RenderTexture时可以用低精度格式替代
// SRP项目中可以设置缓冲区精度
// 可以在Shader中设置更低精度缓冲区
// 5-2.半分辨率渲染屏幕后处理效果
// 屏幕后处理效果可以用1/2、1/4分辨率处理后放大
// 5-3.减少全屏 Blit
// 多个后处理效果尽量合并到一个 Pass,避免重复拷贝整屏
//6.平台相关优化
// 移动端:纹理压缩、半分辨率后处理、避免大面积透明UI等等
// PC/主机:带宽相对高,但高分辨率、高精度 HDR、高 MSAA 下仍容易成为瓶颈
// 可通过 降低 RT 精度 + 减少全屏 Pass(屏幕后处理效果) 缓解
#endregion
}
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

