115.总结
115.1 知识点

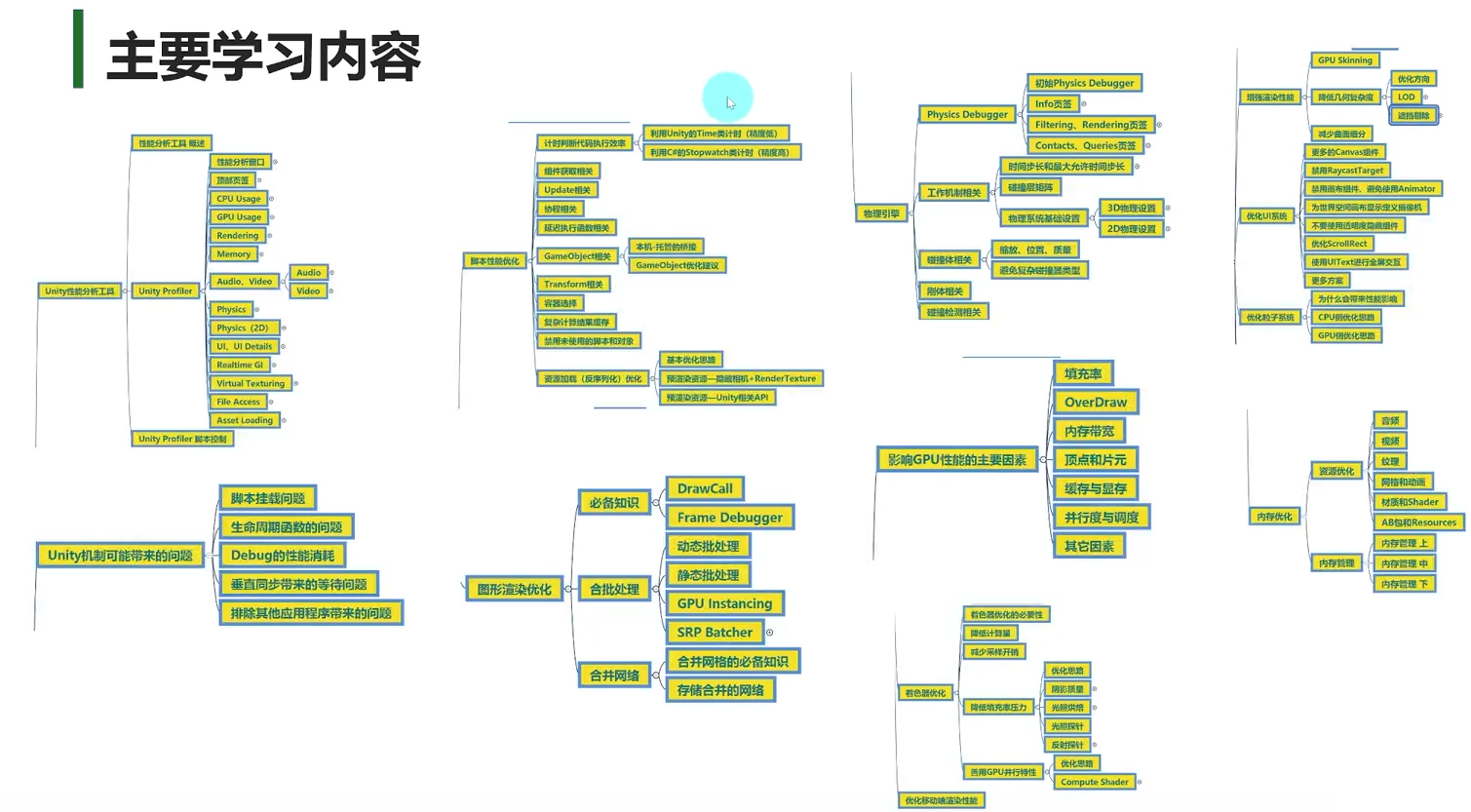
主要内容

主要学习内容
性能优化学习意义

万人同屏实践预告


总结

115.2 核心要点速览
性能分析工具概述
性能分析工具用于检测和分析 Unity 应用程序性能,帮助开发者定位性能瓶颈。
核心工具:
| 工具 | 用途 |
|---|---|
| Profiler 窗口 | 实时监控 CPU、GPU、内存、渲染等模块性能 |
| Memory Profiler | 详细分析内存快照,定位内存泄漏和资源占用 |
| Physics Debugger | 可视化调试物理系统,检查碰撞体状态 |
Profiler 主要模块:CPU Usage、GPU Usage、Memory、Rendering、Audio、Video、Physics、Physics 2D、UI 等。
使用注意事项:
- 最终性能测试不要用 Development Build(有额外开销)
- 分析时关闭其他程序,避免干扰
- 多次测试取平均值,排除偶然因素
Profiler 窗口基础
打开方式与模式
| 模式 | 打开方式 | 特点 |
|---|---|---|
| 内嵌模式 | Window → Analysis → Profiler |
集成在编辑器内,调试方便,但有采样干扰 |
| 独立进程模式 | Window → Analysis → Profiler (Standalone Process) |
独立进程运行,干扰更小,适合大型项目、真机分析 |
窗口结构
- A 模块列表:切换要观察的数据模块(CPU Usage、GPU Usage、Memory 等)
- B 顶部控制区:选择目标、控制录制/播放、切换帧
- C 帧图表区:展示各模块随时间变化的采样曲线
- D 详细信息面板:展示当前模块在选中帧上的细项数据
顶部工具栏关键功能
| 功能 | 作用 | 注意事项 |
|---|---|---|
| 模块选择 | 勾选要采集的模块 | 不需要的模块关闭,减少开销 |
| 模式下拉框 | 选择分析目标(Play/Edit/远程连接) | 真机分析需开启 Development Build |
| 录制开关 | 开始/停止采样 | 关键操作前再开,时间轴更干净 |
| 深度分析 | 对 C# 方法细粒度采样 | 开销大,仅定位问题时短时间开启 |
| 调用栈 | 记录分配相关的调用栈信息 | 增加开销,需要时再开 |
偏好设置建议:
Frame Count:建议改高(如 600),便于查看更长历史数据Default recording state:建议 Enabled,自动录制
CPU Usage 模块
作用:展示每一帧 CPU 花费的时间,按类别细分,是定位 CPU 瓶颈的核心工具。
常见 CPU 开销来源:脚本逻辑、物理系统、动画计算、渲染准备、资源加载、GC、UI 系统等。
分析窗口颜色含义:
| 颜色块 | 含义 |
|---|---|
| Rendering | 渲染准备时间(Camera.Render、生成 DrawCall) |
| Scripts | C# 脚本执行时间(Update、协程等) |
| Physics | 物理计算时间 |
| Animation | 动画相关时间 |
| GarbageCollector | GC 回收时间 |
| VSync | 垂直同步等待时间 |
| UI | Canvas 更新、重建、批处理等 |
参考线:16ms(60FPS)、33ms(30FPS)、66ms(15FPS),快速判断是否超标。
四种视图:
| 视图 | 特点 | 适用场景 |
|---|---|---|
| TimeLine | 横向时间轴,按线程显示 | 查看函数调用位置、线程并发/串行 |
| Hierarchy | 调用栈层级展示 | 快速发现耗时最多的调用分支 |
| Inverted Hierarchy | 倒置调用树 | 分析某函数被谁频繁调用 |
| Raw Hierarchy | 原始采样数据 | 查看完整调用链 |
关键列:
Total:函数含子函数占总时间百分比Self:函数自身耗时百分比Calls:调用次数GC Alloc:GC 分配量(Byte)Time ms / Self ms:总耗时 / 自身耗时
两个根节点:EditorLoop(编辑器主循环)、PlayerLoop(游戏运行时主循环)。
GPU Usage 模块
作用:分析 GPU 各渲染阶段耗时,定位渲染瓶颈。
常见 GPU 开销来源:几何处理、光照计算、渲染输出、屏幕后处理、纹理处理、特效处理等。
重要限制:
- 采集会禁用 Graphics Jobs,影响性能测试真实性
- URP/HDRP 不支持详细 GPU 时间采样
- 不支持所有平台(iOS 可用 Xcode GPU Frame Debugger)
分析窗口颜色含义:
| 颜色块 | 含义 |
|---|---|
| Opaque | 渲染不透明对象时间 |
| Transparent | 渲染透明对象时间 |
| Shadows/Depth | 阴影贴图/深度贴图时间 |
| PostProcess | 屏幕后期处理耗时 |
| Other | 其它 GPU 开销(含 SRP) |
Profiler 窗口进阶模块
Rendering 模块
作用:显示一帧渲染时的数据量(批次数、顶点数等),帮助判断 DrawCall、材质切换、几何量等渲染因素是否导致性能问题。
核心指标:
| 指标 | 含义 | 优化方向 |
|---|---|---|
| Batches Count | 批处理数量(Draw Call 次数) | 合批优化(静态/动态批处理、GPU Instancing) |
| SetPass Calls | Shader Pass 切换次数 | 减少材质和 Shader 变体数量 |
| Triangles / Vertices | 渲染的三角形/顶点数量 | 控制模型复杂度,移动端尤其注意 |
| Dynamic/Static Batching | 动态/静态批处理统计 | 评估合批是否生效 |
| Used Textures | 使用的纹理数量与内存 | 检查贴图分辨率、压缩格式 |
使用场景:怀疑 DrawCall 过高、中低端机发热掉电快、大量实时光照/粒子后掉帧。
Memory 模块
作用:监视内存使用情况,识别内存占用来源、内存泄漏、GC 频繁等问题。
常见内存开销来源:纹理贴图、网格、音频/视频、动画、材质和 Shader、C# 托管堆、GameObject 及组件。
核心指标:
| 指标 | 含义 | 关注点 |
|---|---|---|
| Total Used Memory | 已使用内存总量 | 最直观的内存压力指标 |
| Texture Memory | 贴图内存(含 Mipmap) | 通常是最大占用部分 |
| Mesh Memory | 网格内存 | 场景物体数量/模型复杂度 |
| Object Count | UnityEngine.Object 实例总数 | 过高可能资源未卸载 |
| GC Used Memory | 托管堆已使用内存 | GC 压力来源 |
| GC Allocated In Frame | 该帧分配的托管堆内存 | 频繁跳动说明有 GC 问题 |
Simple 视图关键字段:
Total Committed Memory:Unity 请求的总内存(虚拟内存)Tracked Memory:Unity 能追踪的内存(托管堆、图形资源等)Untracked Memory:无法追踪的内存(本机插件、Mono/IL2CPP 元数据)
Audio 模块
作用:分析和监控音频系统的性能表现,包括播放、混音、CPU 占用等。
核心指标:
| 指标 | 含义 | 健康值 |
|---|---|---|
| Playing Audio Sources | 正在播放的音频源数量 | 移动端建议 < 20~30 |
| Audio Voices | 使用的音频通道数 | 若 AudioSource 多但 Voices 少,说明声音被抢占 |
| Total Audio CPU | 音频 CPU 使用量 | < 10% 健康,> 20% 需排查 |
| Total Audio Memory | 音频内存量 | 持续增长可能资源未释放 |
Detailed 视图关键字段:
Priority:播放优先级(0~256,越小越高),高于 128 容易被剔除Virtual:是否因达到 Max Real Voice Count 而被虚拟化(不实际播放)
Video 模块
作用:分析视频播放性能和资源使用情况。
核心指标:
| 指标 | 含义 | 问题判断 |
|---|---|---|
| Playing Video Sources | 正在播放的视频源数量 | 为 0 说明未启动 |
| Software Video Playback | 软解码视频数量 | 不为 0 说明编码格式不被硬件支持,建议改 H.264 |
| Total Frames Dropped | 丢帧总数 | 持续增长说明播放不流畅 |
| Pre-buffered Frames | 预缓冲帧数 | 太少可能导致卡顿 |
| Total Video Memory | 视频内存 | 持续增长可能未释放资源 |
Physics 模块
作用:监控 3D 物理系统运行状态与性能开销。
核心指标:
| 指标 | 含义 | 关注点 |
|---|---|---|
| Physics Used Memory | 物理系统内存 | 持续上升可能碰撞体未销毁 |
| Active Dynamic Bodies | 活动中的动态刚体数量 | 物理运算主要开销来源 |
| Trigger Overlaps | 触发器重叠事件数 | 避免频繁进入/退出 |
| Physics Queries | 物理查询调用次数 | 频繁查询是性能瓶颈重要来源 |
| Broadphase Adds/Removes | 广义阶段添加/移除数 | 数百以上需关注对象生命周期管理 |
碰撞检测模式:
Discreet:离散检测,效率高,适用于大多数物体Continuous:连续检测,精确但开销大,仅对高速移动物体使用
Physics 2D 模块
作用:监控 2D 物理系统(基于 Box2D 引擎)的性能与行为。
核心指标:
| 指标 | 含义 | 关注点 |
|---|---|---|
| Total Contacts | 总接触点数 | 碰撞交互是否过多 |
| Total Queries | 物理查询次数 | Raycast/Overlap 调用是否频繁 |
| Total Callbacks | 物理回调次数 | OnCollision/Trigger 回调数量 |
| Continuous Bodies | 连续检测刚体数 | 仅高速物体使用,避免滥用 |
| Physics Used Memory (2D) | 2D 物理内存 | 持续上升说明资源未释放 |
常见问题排查:
- Total Queries 高:合并检测逻辑、加帧间隔、限制 Layer
- Continuous Bodies 高:只给高速刚体启用 Continuous 模式
- Physics Used Memory 持续上升:检查动态创建对象是否被销毁
UI 和 UI Details 模块
作用:分析 UGUI 系统性能,从整体统计和细节绘制层面排查 UI 问题。
核心指标:
| 指标 | 含义 | 优化方向 |
|---|---|---|
| Layout Time | 布局系统耗时 | LayoutGroup 频繁重算会拖慢主线程 |
| Render Time | Canvas 绘制耗时 | 合批失败、DrawCall 过多 |
| Cumulative Batch Count | 总批次数 | 越少越好,UGUI 性能关键 |
| Batch Breaking Reason | 合批失败原因 | 定位 DrawCall 增加的根本原因 |
Batch Breaking Reason 常见原因:
- Different Texture:多个 Image 使用不同图集 → 使用 SpriteAtlas 合并
- Different Material Instance:TMP 修改样式生成新材质 → 统一字体材质
- Mask/Clipping:Mask、ScrollRect 触发 Canvas 分离 → 减少 Mask 层级
渲染预览视图:可切换 Standard/Overdraw/Content 模式,直观查看每个 Batch 渲染内容,定位 UI 元素重叠绘制问题。
Realtime GI 模块
作用:排查实时全局光照系统的运行时性能开销(需在 Lighting 中开启)。
核心指标:
| 指标 | 含义 | 关注点 |
|---|---|---|
| Solve Tasks | 光照核心求解耗时 | 最耗性能的部分 |
| Dynamic Objects | 动态物体光照计算 | 动态发光物体是否频繁更新 |
| Blocked Command Write | 写入阻塞耗时 | 非 0 说明存在同步瓶颈 |
优化建议:
- Solve Tasks 每帧耗时过高 → 转为静态光照或减少动态发光物体
- Dynamic Objects 频繁更新 → 让动态物体远离 GI 区域或使用 Light Probe
Virtual Texturing 模块
作用:监视虚拟纹理(VT)系统的性能开销。VT 将大纹理切成 tile 按需加载,减少显存占用。
适用场景:超大贴图资源、开放世界流式加载、次世代大型项目(仅 HDRP 支持)。
核心指标:
| 指标 | 含义 | 问题判断 |
|---|---|---|
| Required Tiles | 当前视图所需的 tile 数量 | 反映纹理数据需求量 |
| Missing Streaming Tiles | 尚未加载的 tile 数量 | 过高说明流式传输瓶颈 |
| Max Cache Mip Bias | 最大 Mip 偏移 | 越高说明画质越模糊(降级渲染) |
| Total GPU Cache Size | GPU 缓存总量 | 评估显存压力 |
优化方向:
- Missing Streaming Tiles 高 → 增大缓存或优化加载策略
- Max Cache Mip Bias 高 → 显存压力大,系统在降级纹理质量
File Access 模块
作用:监控运行时文件系统访问情况,排查磁盘 I/O 导致的卡顿。
核心指标:
| 指标 | 含义 | 问题判断 |
|---|---|---|
| Files Opened | 打开的文件数量 | 频繁打开可能资源未预加载 |
| File Handles Open | 当前打开的文件句柄数 | 长期偏高可能句柄泄漏 |
| Reads in Flight | 进行中的读取操作数 | 过高说明并发读取过多 |
| File Seeks | 文件指针跳转次数 | 过多说明随机访问,I/O 性能差 |
排查方向:
- 主线程同步 I/O 耗时超过几 ms → 改用异步加载
- Files Opened/Closed 不平衡 → 检查文件句柄泄漏
- File Seeks 过多 → 优化文件访问模式
Asset Loading 模块
作用:监视运行时资源加载行为,配合 File Access 模块定位加载瓶颈。
核心指标:
| 指标 | 含义 | 问题判断 |
|---|---|---|
| Texture Reads | 纹理读取量 | 贴图加载是否过多 |
| Mesh Reads | 网格读取量 | 模型加载开销 |
| Marker Length (ms) | 加载耗时 | 定位加载慢的资源 |
| Thread | 加载线程 | 判断是否阻塞主线程 |
优化方向:
- 同一帧加载过多资源 → 分帧加载
- 主线程加载大资源 → 改用异步加载
- 重复加载同一资源 → 检查 Resources.Load 使用
Profiler 脚本控制 API
命名空间:using UnityEngine.Profiling;
常用 API:
| API | 作用 |
|---|---|
Profiler.GetMonoUsedSizeLong() |
获取当前使用的 Mono 堆内存 |
Profiler.GetMonoHeapSizeLong() |
获取 Mono 堆总大小 |
Profiler.GetTotalAllocatedMemoryLong() |
获取 Unity 正在使用的内存总量 |
Profiler.GetTotalReservedMemoryLong() |
获取从操作系统申请的内存总量 |
Profiler.GetRuntimeMemorySizeLong(obj) |
获取某对象占用内存 |
Profiler.BeginSample("name") / EndSample() |
自定义采样区段,在 CPU 模块显示标记 |
使用建议:
BeginSample/EndSample用#if UNITY_EDITOR包裹,避免打进正式包logFile+enableBinaryLog可导出 .raw 文件供离线分析
Memory Profiler 窗口
定位:比 Profiler 的 Memory 模块更细致的内存分析工具,支持快照对比和引用链追踪。
与 Profiler Memory 模块对比:
| 对比项 | Profiler - Memory | Memory Profiler |
|---|---|---|
| 实时监控 | 支持 | 主要用于快照分析 |
| 快照对比 | 不支持 | 支持 |
| 引用链分析 | 不支持 | 支持 |
| 性能开销 | 极小 | 略高(抓快照时卡顿) |
三个核心页签:
| 页签 | 作用 |
|---|---|
| Summary | 内存总体信息,快速分析和横向比较 |
| Unity Objects | Unity 引擎对象(Texture、Mesh、Material 等)的内存占用 |
| All Of Memory | 最全面的内存视图,按内存类别分类(Native、Managed、Graphics 等) |
Summary 页签
四个核心区域:
- Memory Usage On Device:设备上的内存使用情况,判断是否接近内存上限
- Allocated Memory Distribution:已分配内存分布(Native、Managed、Graphics、Untracked)
- Managed Heap Utilization:托管堆使用率(Empty Heap、VM、Objects)
- Top Unity Objects Categories:内存占用最多的 Unity 对象类型
内存溢出(OOM)参考值:
- Android 低端机:350–450MB
- Android 高端机:700MB–1.2GB
- iPhone 12+:1GB+
Unity Objects 页签
核心能力:快速定位 Unity 对象内存占用的类型与具体实例。
三种统计视角:
- Allocated Memory:理论占用的内存量
- Resident Memory:实际驻留在物理内存中的部分(决定生死)
- Allocated and Resident:综合视图
关键概念:
- 驻留内存(Resident Memory):真正对设备造成压力,超过上限会 OOM
- 已分配内存(Allocated Memory):反映健康状况和崩溃风险趋势
常见排查方向:
- 纹理内存过高 → 检查重复加载、未压缩、Read/Write 开启
- 相同资源多次加载 → Name 相同但 InstanceID 不同
- 动态资源未释放 → 材质、纹理未及时释放
All Of Memory 页签
定位:最强大、最底层、最全面的内存视图,按内存类别分类。
核心内存类别:
| 类别 | 含义 | 排查方向 |
|---|---|---|
| Native | C++ 层对象、资源、图形资源 CPU 端 | 未及时释放对象 |
| Managed | C# 托管堆、类、数组 | GC 问题、内存泄漏 |
| Graphics (Estimated) | GPU 纹理、Mesh、RT 估算 | 显存异常、Read/Write 双份内存 |
| Reserved | 已申请但未使用的内存 | 内存碎片化、场景切换后未释放 |
| Untracked | 无法追踪的内存 | 驱动/平台问题,需用平台工具排查 |
与 Unity Objects 页签区别:
- Unity Objects:按对象类型分类,找哪个资源占用最多
- All Of Memory:按内存类别分类,分析整体内存健康状况
Unity 机制问题
脚本挂载检测
重要性:继承 MonoBehaviour 的脚本必须挂载到 GameObject 上才会参与运行。
检测方法:
- 在 Hierarchy 搜索框输入
t:脚本名,快速定位挂载该脚本的对象 - 结合 Profiler 的调用次数和耗时,排查是否因挂载失误导致性能问题
常见问题:脚本误挂到多个对象,导致同一逻辑被多次执行。
生命周期函数注意事项
调用顺序问题:
- 不同脚本的
Awake、Start执行顺序默认不确定 - 若 A 依赖 B 的初始化结果,需在 Project Settings → Script Execution Order 中设置顺序
- 性能排查时不能只看 Update,也要关注 Awake、OnEnable、Start 中的初始化逻辑
空函数开销:
- 空的生命周期函数仍会被 Unity 调用,带来额外开销
- 特别注意每帧调用的函数:
Update、LateUpdate、FixedUpdate、OnGUI - 不需要时不要声明,删掉逻辑后记得删除函数本身
Debug API 性能消耗
问题:Debug.Log、Debug.LogError 等会带来额外性能开销,发布版应避免使用。
解决方案:
- 二次封装 + 开关:封装
Util.Log(),通过isDebug开关统一控制 - 条件编译:
[Conditional("UNITY_EDITOR")]:仅编辑器内编译[Conditional("DEVELOPMENT_BUILD")]:仅 Development Build 中编译
public static class Util
{
private static bool isDebug = true;
public static void Log(object info)
{
if (!isDebug) return;
Debug.Log(info);
}
}
垂直同步(VSync)
作用:强制显卡等显示器刷新完成后再提交下一帧,避免画面撕裂。
副作用:
- 输入延迟增加
- 帧率下降:帧率低于刷新率时会”降档”(如 50 FPS @ 60Hz → 30 FPS)
设置方式:
QualitySettings.vSyncCount = 0; // 关闭
QualitySettings.vSyncCount = 1; // 每帧同步
QualitySettings.vSyncCount = 2; // 隔一帧同步
使用建议:
- 开发调试时关闭,观察真实 GPU 瓶颈
- 低端机卡顿时关闭,减少帧率锁死卡顿
- 高帧率项目可开启防撕裂,低帧率项目可关闭避免降档
- 可在设置菜单中暴露 VSync 选项让玩家选择
排除其他应用程序影响
可能干扰因素:
- 系统资源争用:后台应用占用 CPU/GPU/内存/磁盘 IO
- 输入系统干扰:某些程序劫持键盘鼠标
- 音视频干扰:其他播放程序抢占资源
- 文件访问干扰:杀毒、网盘同步锁定文件
- 远程调试干扰:远程桌面、投屏影响 GPU 和输入
建议:
- 性能分析时关闭一切后台应用
- 使用独立进程 Profiler(Standalone Process)降低编辑器干扰
- 保持测试环境纯净,准确定位游戏自身问题
CPU 脚本优化
计时判断代码执行效率
为什么需要手动计时:虽然 Profiler 能排查耗时问题,但手动计时仍有价值——发布版可用于日志上报、自动分析;可做微秒级、细颗粒度比较;可批量测试、计算平均/最大耗时。
计时基本原理
耗时 = 结束时间 - 开始时间
测试建议:
- 多次执行取平均值
- 不在初始化阶段测,等消耗稳定后触发
- 不在测试循环内使用 Debug.Log
Unity Time 类计时
API:Time.realtimeSinceStartup(不受 Time.timeScale 影响)
float startTime = Time.realtimeSinceStartup;
// 执行逻辑
float spendTime = (Time.realtimeSinceStartup - startTime) * 1000f; // 毫秒
精度:毫秒级,适合一般耗时统计。
C# Stopwatch 类计时
命名空间:System.Diagnostics
常用 API:
| API | 说明 |
|---|---|
Stopwatch.StartNew() |
创建并开始计时 |
Stop() |
停止计时 |
ElapsedMilliseconds |
耗时(毫秒,long) |
Elapsed.TotalMilliseconds |
耗时(毫秒,double,微秒级) |
Restart() |
清零并重新开始 |
Stopwatch sw = Stopwatch.StartNew();
// 执行逻辑
sw.Stop();
double ms = sw.Elapsed.TotalMilliseconds;
精度:微秒级,比 Time 类更精确。
计时类封装(IDisposable + using)
利用 C# 的 using 语句块 + IDisposable,可自动调用 Dispose 计算耗时:
public class CustomTimer : IDisposable
{
private string _name;
private uint _num;
private Stopwatch _watch;
public CustomTimer(string name, uint num)
{
_name = name;
_num = num == 0 ? 1 : num;
_watch = Stopwatch.StartNew();
}
public void Dispose()
{
_watch.Stop();
double spendTime = _watch.Elapsed.TotalMilliseconds;
Debug.Log($"{_name} 共耗时{spendTime}ms,平均每次{spendTime/_num}ms");
}
}
// 使用方式
using (new CustomTimer("测试", 10000))
{
for (int i = 0; i < 10000; i++) { /* 逻辑 */ }
}
组件获取与 Update
GetComponent 优化:
三种重载方式性能对比:
| 方式 | 示例 | 性能 |
|---|---|---|
| 泛型 | GetComponent<T>() |
最快(推荐) |
| Type | GetComponent(typeof(T)) |
中等 |
| 字符串 | GetComponent("TypeName") |
最慢 |
最佳实践:
- 优先使用泛型方式
- 常用组件在 Awake/Start 中获取并缓存
- 避免在 Update 中重复调用
Update 函数优化
七大优化手段:
| 手段 | 说明 |
|---|---|
| 移除空 Update | 空函数仍会被每帧调用 |
| 缓存组件引用 | 不在 Update 中 GetComponent、Find |
| 降低执行频率 | 用计时器控制复杂逻辑间隔 |
| 减少复杂计算 | 不变结果初始化时算好 |
| 事件驱动 | 用观察者模式代替每帧轮询 |
| 分帧执行 | 大批量对象每帧只处理一部分 |
| 统一管理器 | 一个 Update 驱动所有回调,减少跨语言开销 |
降低执行频率示例:
private float timer;
void Update()
{
timer += Time.deltaTime;
if (timer >= 0.25f)
{
ComplexLogic();
timer = 0;
}
}
协程与延迟函数
协程开销分析:
额外开销:
- 启动成本约为普通函数调用的 3 倍
- 会额外分配内存保存状态
- 每次 yield 都有调度开销
- 大量并发协程带来 GC 压力
协程 vs Update 计时器:
| 对比项 | 协程 | Update 计时器 |
|---|---|---|
| 可读性 | 好,逻辑集中 | 一般,需手动管理 |
| 性能 | 有额外开销 | 无额外开销 |
| 适用场景 | 复杂异步流程 | 简单定时逻辑 |
WaitForSeconds vs WaitForSecondsRealtime:
WaitForSeconds:受Time.timeScale影响WaitForSecondsRealtime:不受影响,按真实时间
替代方案:UniTask(async/await)性能更优。
延迟函数优化:
Invoke/InvokeRepeating 问题:
- 通过字符串反射调用,性能差
- 可读性差,无法传参
- 停止需 CancelInvoke 传字符串
推荐替代方案:
- 协程 + WaitForSeconds
- UniTask.Delay + async/await
- 自定义 Timer 管理器
本机托管桥接
概念与开销:
本机-托管桥接:C#(托管)与 C++(本机)之间的调用通道。
常见触发桥接的操作:
transform.position(读/写)GetComponent<T>()gameObject.SetActive()GameObject.Find()
开销来源:
- 上下文切换:堆栈转换、线程状态保存
- 数据封送:Vector3 等结构体拷贝
- GC 压力:封送可能产生临时对象
优化方法:
| 方法 | 说明 |
|---|---|
| 缓存组件引用 | 避免重复 GetComponent |
| Transform 批量写回 | 先读到局部变量,算完再一次性写回 |
| 子物体引用缓存 | 初始化时缓存,不用 GetChild 遍历 |
| 逻辑与表现分离 | 托管侧计算完再批量同步 |
| 对象池 | 减少 Instantiate/AddComponent 的桥接开销 |
Transform 属性优化示例:
// 推荐:读一次 → 托管侧计算 → 写回一次
Vector3 pos = transform.position;
pos += moveDir * speed * Time.deltaTime;
transform.position = pos;
// 优先用本地属性
transform.localPosition += offset;
GameObject 与 Transform
GameObject 优化:
| 陷阱 | 问题 | 优化方案 |
|---|---|---|
gameObject.tag |
每次访问产生桥接 | 缓存或用 CompareTag() |
GameObject.Find() |
遍历场景,性能差 | 初始化时查找并缓存 |
SendMessage() |
字符串反射,效率低 | 缓存组件直接调用或事件中心 |
Transform 优化:
| 陷阱 | 问题 | 优化方案 |
|---|---|---|
SetParent() |
触发层级重建、批处理中断 | 避免运行时频繁修改 |
| 频繁改 position | 触发矩阵运算、通知其他组件 | 缓存后一次性写回 |
| 用世界属性 | 层级越深计算量越大 | 优先用 localPosition |
transform.Find() |
遍历层级,性能差 | 初始化时缓存引用 |
数据结构与缓存
数据结构选择:
| 数据结构 | 查找复杂度 | 特点 | 适用场景 |
|---|---|---|---|
List<T> |
O(n) | 连续存储,缓存友好 | 频繁遍历、中间插入少 |
Dictionary<K,V> |
O(1) | 哈希表,不连续 | 频繁按键查找 |
HashSet<T> |
O(1) | 无序、无键值对 | 只关心存在性 |
Queue<T> |
O(1) | 先进先出 | 对象池、按序处理 |
Stack<T> |
O(1) | 先进后出 | 状态回退、行为撤销 |
LinkedList<T> |
中间插删 O(1) | 内存不连续 | 频繁中间插删、少遍历 |
选择原则:遍历多用 List,按键查找用 Dictionary,存在性检测用 HashSet。
复杂计算结果缓存:
适合缓存的内容:
- 数学计算:三角函数预计算查表(0~359 度 Sin/Cos)
- 寻路结果:缓存起点+终点对应路径
- 配置数据:反序列化后常驻内存
- 物理投射:条件不变时复用 Raycast/Overlap 结果
- Shader 参数:仅在变化时调用
SetFloat/SetVector
核心思想:用内存换性能,避免重复计算。
禁用未使用对象
OnBecameVisible / OnBecameInvisible:
| 回调 | 触发条件 | 用途 |
|---|---|---|
OnBecameVisible |
Renderer 对任意摄像机可见 | 启用脚本/对象 |
OnBecameInvisible |
Renderer 对所有摄像机不可见 | 禁用脚本/对象 |
注意:Scene 视图摄像机也会触发;对象必须有 Renderer 组件。
距离判断优化:
// 推荐:用平方比较,避免开方
if ((posA - posB).sqrMagnitude >= threshold * threshold)
{
// 超过阈值,禁用对象
}
视锥范围检测:
Plane[] planes = GeometryUtility.CalculateFrustumPlanes(Camera.main);
if (GeometryUtility.TestPlanesAABB(planes, renderer.bounds))
{
// 在视锥内
}
资源加载与预渲染
资源加载开销来源:
| 开销类型 | 说明 |
|---|---|
| I/O 开销 | 磁盘/网络读取阻塞 CPU |
| 解析开销 | 数据解析、解压(AB 包 LZ4/LZMA)、反序列化 |
| 内存分配 | 创建 C++ 引擎对象(Mesh、Texture 等) |
优化策略:
| 策略 | 说明 |
|---|---|
| 减小序列化对象 | 预设体精简、二进制替代文本配置 |
| 公共数据配置化 | 全局只保留一份配置表,通过 ID 查数据 |
| 异步加载 + 分帧实例化 | 避免主线程阻塞,每帧实例化少量对象 |
| 缓存 | 资源字典缓存、对象池复用 |
| 预热 | 预加载、预实例化、预渲染 |
预渲染方式:
| 方式 | 适用场景 |
|---|---|
| 隐藏相机 + RenderTexture | 动画、粒子等多帧预渲染 |
| CommandBuffer | 仅需上传网格、纹理、Shader 变体 |
| Shader Variant Collection.WarmUp() | Shader 变体预热 |
CPU 图形优化
DrawCall 与批处理
DrawCall 开销来源:
每次 DrawCall 的 CPU 开销:
- 状态切换:绑定材质、贴图、Shader
- 数据绑定:上传模型矩阵、材质参数
- 命令组织:调用图形 API 生成命令缓冲
- 排序剔除:为减少状态切换做排序
增加 DrawCall 的常见原因:
- 材质/Shader 不一致
- 相同材质但纹理不同
- 不同渲染队列
- 不同透明度(透明队列按深度排序)
- 不同 Shader 变体
- UI 元素位于不同 Canvas
- Shader 多 Pass(阴影、深度、后处理)
批处理方案对比:
| 方案 | 原理 | 限制 | 适用场景 |
|---|---|---|---|
| 动态批处理 | 运行时合并网格 | 顶点 ≤225(300),属性 ≤900,相同材质 | 小型动态网格,内置管线 |
| 静态批处理 | 构建/首次运行时合并 | 勾选 Batching Static,相同材质 | 静态场景物体 |
| GPU Instancing | 一次 Draw Call 绘制多个实例 | 相同网格+相同材质 | 大量相同物体(草地、树木) |
| SRP Batcher | 缓存材质/物体数据到 GPU | 仅 SRP 管线,Shader 兼容 | URP/HDRP 项目 |
优先级:
- 内置管线:静态批处理 > GPU Instancing > 动态批处理
- SRP 管线:静态批处理 > SRP Batcher > GPU Instancing
动态批处理限制
- 顶点数限制:≤225(Unity 2021 前为 ≤300)
- 顶点属性限制:顶点数 × 属性数 ≤ 900
- 必须相同材质实例
- 不支持 SkinnedMeshRenderer
- 变换不能包含镜像(正/负缩放不能混批)
- 相同光照状态、渲染队列
静态批处理限制
- 必须勾选 Batching Static
- 相同材质、相同渲染状态
- 每批次最多 64,000 顶点
- 运行时不能修改 Transform
- 内存开销翻倍(保留原始网格 + 合并网格)
GPU Instancing 限制
- 必须相同网格
- 必须相同材质(颜色等属性可通过实例数据变化)
- 材质勾选 Enable GPU Instancing
- 不支持 SkinnedMeshRenderer
SRP Batcher 限制
- 仅 SRP 管线(URP/HDRP)
- Shader 必须兼容(Lit/Unlit Shader 支持)
- 不能使用 MaterialPropertyBlock
- 不支持粒子
手动合并网格
核心方法:
Mesh.CombineMeshes(CombineInstance[], mergeSubMeshes, useMatrices)
合并流程:
- 获取要合并的网格数据
- 构建
CombineInstance数组(设置 mesh、transform) - 创建新网格,设置顶点索引格式(UInt16/UInt32)
- 调用
CombineMeshes执行合并 - 重新计算包围盒
RecalculateBounds() - 挂载合并后的网格
变换矩阵:
// 子网格顶点从子对象本地空间转换到父对象本地空间
combineInstance.transform = parentTransform.worldToLocalMatrix * childTransform.localToWorldMatrix;
顶点索引格式:
| 格式 | 最大顶点数 |
|---|---|
| UInt16 | 65,535 |
| UInt32 | 4,294,967,295 |
CPU 物理优化
Physics Debugger
五大功能区:
| 区域 | 作用 |
|---|---|
| Info | 显示选中刚体的运行时物理属性(速度、质心、休眠状态等) |
| Filtering | 控制哪些物理对象在 Scene 视图中显示 |
| Rendering | 调整调试可视化的颜色、透明度、显示方式 |
| Contacts | 显示物体之间的接触点、冲量、分离向量 |
| Queries | 可视化射线检测、范围检测 |
用途:调试碰撞不触发、穿模、弹力异常、射线未命中等问题。
时间步长设置
固定时间步长(Fixed Timestep):
| 参数 | 默认值 | 说明 |
|---|---|---|
| Fixed Timestep | 0.02s (50Hz) | 物理更新间隔,增大可降低 CPU 开销但影响精度 |
物理更新独立于帧率:一帧可能执行 0 次、1 次或多次物理更新。
最大允许时间步长(Maximum Allowed Timestep):
| 参数 | 默认值 | 说明 |
|---|---|---|
| Maximum Allowed Timestep | 0.333s | 掉帧时最多补多少物理帧,超出的时间丢弃 |
注意:改小该值会减少物理计算,但可能导致物理对象瞬移、跳跃。
碰撞层矩阵
碰撞检测两阶段:
| 阶段 | 目的 | 方法 |
|---|---|---|
| Broadphase(粗检测) | 快速筛选可能碰撞的候选对 | AABB 边界盒检测 |
| Narrowphase(精检测) | 精确计算接触点 | 实际碰撞体形状计算 |
Layer Collision Matrix:
- 勾选:两个层的碰撞器进行碰撞检测
- 取消勾选:两个层完全不进入 Broadphase,节约 CPU
优化思路:让无关层互斥,减少无效碰撞候选对。
碰撞器性能
性能消耗排行(从低到高):
| 排名 | 碰撞器类型 | 特点 |
|---|---|---|
| 1 | Sphere Collider | 数学公式简单,最省性能 |
| 2 | Capsule Collider | 数学公式计算,常用于角色 |
| 3 | Box Collider | 矩阵与边界检测,使用最广 |
| 4 | 组合碰撞体 | 多个原始体拼接,远低于 Mesh |
| 5 | Terrain Collider | 高度图数据,大规模场景优化 |
| 6 | Mesh Collider(凸形) | 转为凸包,比凹形高效 |
| 7 | Mesh Collider(凹形) | 逐三角面检测,性能最差 |
原则:尽量用原始碰撞体,避免 Mesh Collider。
碰撞器组合消耗:
| 组合 | 消耗 |
|---|---|
| 相同简单碰撞体(Sphere-Sphere 等) | 最低 |
| 不同简单碰撞体(Sphere-Box 等) | 略高,差别不大 |
| 简单碰撞体 + Mesh Collider | 取决于网格复杂度,指数级增加 |
| Mesh Collider + Mesh Collider | 取决于网格复杂度,指数级增加 |
刚体优化
碰撞检测类型选择:
| 类型 | 原理 | 开销 | 适用场景 |
|---|---|---|---|
| Discrete | 固定步长采样点检测 | 最低 | 绝大多数常速物体 |
| Continuous | 两帧间扫掠检测 | 中等 | 高速投射物(子弹) |
| Continuous Dynamic | 更严格的连续检测 | 最高 | 关键高速物体 |
| Continuous Speculative | 预测式检测 | 中等 | 中高速物体,可能误判 |
首选 Discrete,仅高速物体用 Continuous 系列。
刚体 API 调用原则:
- 在 FixedUpdate 中调用:
MovePosition、MoveRotation、AddForce、修改velocity - 不要在 Update 中直接改 Transform:会触发强制同步、AABB 重建、接触点重建
岛屿效应:
- 岛屿:通过碰撞接触或关节相连的刚体组成独立解算单元
- 休眠:岛屿内所有刚体满足休眠条件时整体休眠
- 唤醒:岛屿内一个刚体被唤醒,整个岛屿都唤醒
优化方向:
- 减少关节绑定
- 用运动学刚体切断岛屿
- 利用碰撞层矩阵过滤无效碰撞
碰撞检测优化
射线检测 API 选择:
| API | 特点 |
|---|---|
RaycastAll |
每次分配新数组,产生 GC |
RaycastNonAlloc |
写入传入数组,无 GC(推荐) |
Broadphase 重建触发条件:
- 移动静态碰撞体
- 在 Update 中直接改刚体 Transform
- 修改 Collider 尺寸
- 启用/禁用 Collider
- 大量 Instantiate/Destroy
避免上述操作可减少 CPU 峰值。
布娃娃优化:
- 减少碰撞器数量(约 7 个即可)
- 关闭布娃娃层与自身的碰撞
- 及时禁用不活跃的布娃娃
GPU 优化
影响因素
填充率(Fill Rate):
概念:GPU 单位时间内能处理的像素数量(GPixel/s)。
造成瓶颈的原因:
| 因素 | 说明 |
|---|---|
| 高分辨率 | 像素数指数增加 |
| 全屏后处理 | 每像素多次采样计算 |
| MSAA | 4x MSAA 填充率翻倍 |
| 透明/半透明物体 | 每层都要计算片元 |
| 多 Pass Shader | 同一像素多次覆盖绘制 |
优化思路:
- 降低分辨率(动态分辨率、注视点渲染)
- 减少屏幕后处理效果
- 降低抗锯齿采样次数
- 减少半透明使用
OverDraw(过度绘制):
概念:同一屏幕像素在一帧中被重复绘制多次。
影响性能的原因:
- 片元着色器重复执行
- 带宽浪费
- 填充率压力
优化思路:
| 对象类型 | 优化方案 |
|---|---|
| 不透明物体 | 从前向后渲染、遮挡剔除 |
| 半透明物体 | 减少层数、Alpha Test 替代 Alpha Blend |
| UI 系统 | RectMask2D 替代全屏 Mask、减少叠层 |
Early-Z:片元着色器运行前先做深度测试,被遮挡的直接丢弃。
内存带宽:
概念:GPU 与显存之间单位时间的数据传输量(GB/s)。
造成瓶颈的原因:
- 高分辨率 + 高刷新率
- 超高分辨率纹理
- 缺少 Mipmap
- 未压缩纹理格式
- RenderTarget 过大/过多
优化思路:
- 使用 Mipmap + 纹理压缩(ASTC/ETC2)
- 贴图合并减少采样次数
- 降低 RT 精度
- 半分辨率渲染后处理
顶点与片元:
| 类型 | 主要开销 | 优化方向 |
| — | — |
| 顶点 | 模型顶点数、骨骼蒙皮、顶点着色器复杂度 | LOD、网格简化、蒙皮优化 |
| 片元 | 分辨率、OverDraw、片元着色器复杂度 | 降低分辨率、减少采样、避免分支 |
顶点优化:
- LOD 切换不同精度模型
- 减少骨骼数量和顶点权重
- 顶点动画烘焙到纹理(VAT)
- 顶点着色器输出精简
片元优化:
- 减少纹理采样次数
- 避免 Shader 分支(用 lerp/step 替代 if/else)
- 减少全屏 Pass
- 避免 Early-Z 失效
缓存与显存:
| 存储类型 | 特点 |
|---|---|
| 显存 | 容量大(GB级)、带宽高、延迟大 |
| 缓存 | 容量小(KB~MB级)、速度快 |
缓存优化:
- 提高局部性:UV 连续、合并图集
- 减少缓存未命中:降低 OverDraw、避免依赖采样
- 数据轻量化:用 half 替代 float
显存优化:
- 资源压缩:纹理压缩、法线压缩
- 降低资源规格:贴图分辨率、RT 数量
- Mipmap + Streaming
并行度与调度:
并行度不足:GPU 核心空转,算力浪费。
- 小批量 DrawCall
- Shader 分支导致线程分化
调度问题:等待内存时 ALU 闲置。
优化思路:
- 提高批处理力度
- 避免 Warp 内线程分化(减少 if/else)
- 控制寄存器压力
- 提高缓存命中率
增强渲染性能
GPU Skinning:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| CPU | 蒙皮在 CPU 计算 | 动画较少的项目 |
| GPU | 蒙皮在 GPU 顶点着色器 | 大量角色、高顶点模型 |
| GPU (Batched) | 多个 SMR 合并在一次 GPU Pass | 大量相同角色(群怪) |
选择建议:中高端设备优先 GPU (Batched),低端设备用 GPU 更稳。
LOD(细节层次):
作用:根据距离切换不同精度模型,减少远处物体顶点数。
Fade Mode:
| 模式 | 特点 |
|---|---|
| None | 直接切换,性能最好,可能跳变 |
| Cross Fade | 渐变过渡,平滑但 GPU 负担增加 |
| Speed Tree | 植被专用,仅 SpeedTree 资源 |
切换阈值:基于物体包围盒在屏幕上的占比。
遮挡剔除(Occlusion Culling):
作用:剔除视锥内被遮挡的物体,弥补视锥剔除的局限。
使用步骤:
- 设置遮挡物(Occluder Static)和被遮挡物(Occludee Static)
- 在 Occlusion Culling 窗口烘焙
- 摄像机开启遮挡剔除
烘焙参数:
| 参数 | 说明 |
|---|---|
| Smallest Occluder | 小于此尺寸的物体不作为遮挡者 |
| Smallest Hole | 小于此尺寸的孔洞会被填上 |
| Backface Threshold | 背面参与遮挡的比例 |
适用场景:室内、城市、森林等遮挡多的环境。
降低几何复杂度:
| 方法 | 说明 |
|---|---|
| 美术优化 | 少用高面数模型,用法线贴图代替细节 |
| 移除网格 | 删除不重要的装饰几何体 |
| LOD | 根据距离切换精度 |
| 遮挡剔除 | 剔除被遮挡物体 |
| Impostor | 远处用 2D 贴图冒充 3D 模型 |
| 网格简化 | 使用算法减少面数 |
曲面细分:
概念:将低多边形网格自动拆分成更多小三角形。
性能影响:
- 顶点处理压力成倍增加
- 片元处理间接增加
- 内存带宽开销上升
- 缓存效率下降
建议:无特殊需求时避免使用,尤其低端设备。
UI 系统优化
Canvas 组件优化
Canvas 重建机制:Canvas 内任意元素变化都会触发整个 Canvas 的网格重建。
动静分离原则:
| 类型 | 特点 | 处理方式 |
|---|---|---|
| 静态元素 | 永不改变(背景、Logo、装饰线) | 放入独立 Canvas |
| 偶尔动态 | 偶尔响应变化(按钮、进度条) | 放入独立 Canvas |
| 持续动态 | 每帧变化(血条动画、计时器) | 放入独立 Canvas |
核心思想:高频变化区域独立 Canvas,避免小元素更新导致大 Canvas 重建。
RaycastTarget 优化
作用:控制 UI 元素是否参与射线检测。
禁用原则:
| 必须禁用 | 必须保留 |
|---|---|
| 背景图、装饰图标、分割线 | Button、Toggle、Slider |
| 阴影、UI 框架图 | ScrollRect 可交互区域 |
| 纯装饰性、说明性文字 | 需要响应点击的元素 |
性能收益:减少射线检测遍历次数,降低 UI 交互开销。
Canvas 禁用与 Animator 避免
隐藏 UI 的正确方式:
- 禁用 Canvas 组件(而非 GameObject),避免重建开销
- 禁用 Canvas 不会销毁网格数据,重新启用时无需重建
避免 Animator:
- Animator 每帧都会检查属性变化,即使动画未播放
- UI 动画优先使用 DOTween、Tween 或代码控制
- 必须用 Animator 时,动画结束后禁用 Animator 组件
世界空间 Canvas 的相机定义
问题:World Space Canvas 不指定 Event Camera 时,射线检测会遍历所有相机。
优化:为每个 World Space Canvas 指定专属 Event Camera,减少射线检测范围。
隐藏 UI 元素的优化
错误方式:设置 Alpha = 0 或 Scale = 0
- 元素仍参与布局计算和绘制
- 产生不必要的 OverDraw
正确方式:
- 禁用 Canvas 组件(整体隐藏)
- 禁用 Graphic 组件(单个元素隐藏)
- 移出 Canvas 范围(临时隐藏)
ScrollRect 优化
性能问题:大量子元素导致布局计算、绘制开销大。
核心优化思想:
- 虚拟列表:只保留可见范围内的元素,利用缓存池复用
- 自定义布局:不使用 Unity 自带 LayoutGroup,自己控制布局逻辑
- 独立 Canvas:ScrollRect 内容放入独立 Canvas,动静分离
实现要点:
- 监听 ScrollRect 的 onValueChanged 事件
- 动态计算哪些元素应该显示
- 从缓存池获取/回收元素
Text 拦截全屏 UI 交互
场景:全屏 UI 背后游戏画面仍响应点击。
解决方案:
- 在全屏 UI 最底层放置一个 Text 组件
- 设置 RaycastTarget = true
- 文本内容为空,不显示任何内容
原理:Text 的射线检测会拦截点击事件,阻止穿透到游戏场景。
其他 UI 优化方案
| 方案 | 说明 |
|---|---|
| 打图集 | 多个 UI 元素共用同一材质,便于合批;不同图集元素分层显示避免打断合批 |
| 少用布局组件 | ContentSizeFitter、LayoutGroup 等自带布局组件开销大,建议自己实现布局逻辑 |
| 关闭 Mipmap | 非 3D UI 元素关闭 Mipmap,减少显存和采样开销 |
| 图集压缩 | 移动端使用 ASTC 或 ETC2,降低内存占用 |
| 九宫格拉伸 | 仅需要时启用,避免不必要计算 |
| 减少 OverDraw | 合并背景层、避免大面积半透明遮罩 |
粒子系统优化
CPU 侧优化
优化目标:少算粒子——减少每帧处理的粒子数,以及每个粒子要计算的内容。
减少粒子并发量:
| 参数 | 作用 |
|---|---|
| Start Lifetime | 缩短生命时间,降低同时存活粒子数 |
| Rate over Time | 控制发射频率,避免单位时间粒子过多 |
| Max Particles | 限制最大粒子数,防止峰值无限增长 |
| LOD/距离剔除 | 远处降低发射率或关闭 |
减少高开销模块:
| 模块 | 开销原因 | 优化建议 |
|---|---|---|
| Collision | CPU 逐粒子碰撞检测 | 能不用就不用;必须用时用简单碰撞体、关闭 Send Collision Messages |
| Triggers | 逐粒子检测 + 频繁回调 | 严格限制触发条件 |
| Noise | 每帧采样噪声函数 | 降低频率/强度,或用随机值一次性赋值 |
| Trails | 额外顶点,指数增长 | 调大 Minimum Vertex Distance,限制最大轨迹长度 |
| Sub Emitters | 粒子数指数增长 | 尽量不用,或只在关键时机触发 |
减少脚本和排序开销:
- 少用
OnParticleCollision、OnParticleTrigger回调(可能被大量粒子反复调用) - 少用
GetParticles/SetParticles(涉及托管与原生数据拷贝,不要每帧调用) - 半透明粒子需要排序,能不透明就不透明
利用剔除和对象池:
- Simulation Space 设为 Local 更容易整体剔除
- Stop Action 设为 Disable 或 Destroy,避免播完后后台模拟
- 频繁使用的粒子(技能特效、受击特效)做对象池化
减少 DrawCall:多个粒子系统共用材质或图集,开启 GPU Instancing。
GPU 侧优化
优化目标:少算像素——减少屏幕上参与计算的像素数,以及每个像素计算的内容。
控制 OverDraw:
| 方法 | 说明 |
|---|---|
| 减少粒子数量和尺寸 | 覆盖面积 ≈ 粒子数 × 粒子尺寸 |
| Trim Alpha | 裁掉贴图边缘无效透明区域 |
| 合理 Start Size | 避免大面积满屏效果 |
| LOD | 远处用雾面贴图或后处理替代 |
降低几何复杂度:
- 使用广告牌粒子(一个四边形即可)
- 合理使用 Trails(调大采样间距、限制最大顶点数)
- 网格粒子用低模
减少片元着色开销:
- 降低着色器复杂度:减少纹理采样、避免分支和高开销函数
- 粒子一般不必投射阴影,光照需谨慎
- 优化贴图:减少序列帧数量、降低分辨率、使用压缩格式
替代手段:
- 能用不透明就不用半透明(弹壳、碎屑等)
- 大范围雾、火焰用后处理替代
- 上万粒子考虑 VFX Graph(仅 URP/HDRP)
着色器优化
优化必要性:
- Shader Graph、ASE 等可视化工具生成的 Shader 往往不是最优
- 为适配各种情况会生成通用代码,可能包含冗余计算
- 手写 Shader 可做指令级优化
降低计算量:
| 方法 | 说明 |
|---|---|
| 使用移动平台 Shader | Unity 内置移动端 Shader,无需改代码即可提升性能 |
| 使用小数据类型 | 移动端优先 half、fixed,避免频繁精度转换 |
| 使用 GPU 优化辅助函数 | Unity 内置 Shader 库函数,跨平台兼容且高效 |
| 删除不必要输入数据 | 顶点/片元结构体中不用的字段不要声明 |
| 只公开所需变量 | 固定值直接写死,减少常量缓冲区传输 |
| 预计算 | 光照烘焙、LUT 纹理,避免每帧重复计算 |
| 减少逐像素计算 | 能在顶点算的就不放片元 |
| 合并多次计算 | 避免重复计算同一表达式,存结果复用 |
| 利用常量缓冲区 | 共用常量放 CBUFFER,一次传输多处使用 |
减少采样开销:
| 方法 | 说明 |
|---|---|
| 减少纹理采样 | 多张灰度图合并到一张 RGBA 的各通道 |
| 使用更少纹理数据 | 遮罩贴图用 R8 代替 RGBA32 |
| 测试压缩格式 | PC 用 BC,Android 用 ETC2/ASTC,iOS 用 PVRTC/ASTC |
| 最小化纹理交换 | 降低分辨率、复用纹理、使用图集 |
| 控制 VRAM | 移动端贴图总占用控制在 500MB 以内 |
| 使用 Mipmap | 远处物体用低分辨率 Mip,降低带宽和闪烁 |
| 采样复用 | 一次采样结果多次使用,避免重复采样 |
| 避免动态分支选纹理 | 用纹理图集、Texture2DArray、Shader 变体替代 |
| 压缩法线纹理 | 只存 RG 两通道,Shader 重建 Z,减少 50%~75% 存储 |
| 流式加载 | 虚拟纹理、Streaming Mipmap,按需加载 |
降低填充率压力:
三类思路:
- 降低要处理的像素数量:动态分辨率、降低后处理、降低 MSAA
- 减少单像素计算量:控制 Pass 数、减少半透明、合理光照模式
- 避免无效像素计算:减少 OverDraw、Occlusion Culling
具体方法:
| 方法 | 说明 |
|---|---|
| 禁用不需要的特性 | ForceNoShadowCasting、ZWrite Off 等 |
| Shader LOD | 远处用简单 SubShader,降低片元计算 |
| 光照剔除 | Culling Mask 限制受光层级 |
| 谨慎实时阴影 | 用烘焙阴影替代,降低阴影质量 |
| 烘焙光照纹理 | 静态物体用光照贴图,动态物体用 Light Probe |
| 减少 MRT | 多重渲染目标增加填充率压力,移动端谨慎使用 |
阴影质量设置:
内置管线:
- Quality 窗口:Shadowmask Mode、Shadow Resolution、Shadow Cascades 等
- Light 组件:Shadow Type、Realtime Shadows 参数
- Renderer 组件:Cast Shadows、Receive Shadows
URP 管线:
- URP Asset:Max Distance、Cascade Count、Soft Shadows Quality
- Light 组件:Shadow Type、Custom Shadow Layers
- Renderer 组件:Static Shadow Caster(静态阴影投射体)
建议:移动端用 Low/Medium 分辨率、No 或 Two Cascades;PC/主机用 High、Four Cascades。
光照烘焙:
概念:提前离线计算光照、阴影、反射、间接光照,保存为贴图或探针数据,运行时直接使用。
可烘焙:直接光照、间接光照、静态阴影、反射(Reflection Probe)
不可烘焙:随时间变化的灯光或移动的光源
烘焙步骤:
- 静态物体标记 Static 或勾选 Contribute GI
- 设置灯光模式:主光源 Mixed、静态灯 Baked、动态灯 Realtime
- Lighting 窗口配置参数,点击 Generate Lighting
混合光照模式:
| 模式 | 特点 | 适用场景 |
|---|---|---|
| Shadowmask | 烘焙静态阴影 + 实时动态阴影 | 主机/PC,静态建筑 + 动态角色 |
| Subtractive | 只允许一个主方向光实时阴影 | 移动端、卡通风、简单关卡 |
| Baked Indirect | 只烘焙间接光,直接光和阴影实时 | 室外场景、昼夜循环 |
光照探针:
作用:让动态物体在场景中通过插值获得周围环境的间接光照信息。光照烘焙为静态物体服务,动态物体无法直接使用烘焙光照,Light Probe 解决了这个问题。
原理:
- 烘焙阶段:在场景中放置探针点,Unity 对每个探针计算光照方向和强度分布,存储为球谐函数(SH)系数
- 运行阶段:对每个动态物体,Unity 找到附近的光照探针,根据位置进行三维插值,将结果应用到物体上
优点:几乎零运行时成本、光照平滑过渡、与烘焙光照无缝结合
缺点:无法产生阴影、光照数据静态、探针过少时亮度跳变
使用步骤:
- 创建 Light Probe Group,编辑探针位置
- 重新烘焙(Generate Lighting)
- 动态物体 Renderer → Light Probes 设为 Blend Probes
布局原则:覆盖动态物体活动区域、光照变化剧烈处密集、空间分布均匀连续
注意:Light Probe 只烘焙间接光,直接光需光源设为 Mixed 或 Realtime。
反射探针:
作用:捕捉某个空间内的环境反射信息,生成 Cubemap,让金属、玻璃等材质获得倒影效果。
原理:
- 烘焙阶段:以探针位置为中心渲染场景 6 个方向,生成 Cubemap
- 运行阶段:Shader 根据法线方向在 Cubemap 中查找反射颜色
- 多探针时按位置权重插值混合
三种类型:
| 类型 | 特点 | 适用场景 |
|---|---|---|
| Baked | 只在烘焙时生成,运行时不更新 | 静态场景、室内、固定反射环境 |
| Realtime | 运行中定时或每帧重新渲染 | 镜面、水面、动态光照变化 |
| Custom | 手动指定 Cubemap | 特殊效果或自定义反射 |
关键参数:
- Importance:探针优先级
- Intensity:反射亮度倍数
- Box Projection:启用盒体投影,室内更真实
- Blend Distance:探针间混合过渡距离
- Resolution:Cubemap 分辨率
使用步骤:
- 创建 Reflection Probe,设置参数
- 静态物体勾选 Reflection Probe Static 后烘焙
- URP 在管线资源启用 Probe Blending;内置管线在 Renderer 设 Blend Probes
布局技巧:室内居中、室外间隔、走廊多段、每层独立。
GPU 并行特性优化思路:
核心思想:把计算分成简单、独立、可并行的工作单元,让每个 GPU 线程做少量规则的工作。
向量化运算:GPU ALU 以 4-wide SIMD 工作,应使用向量运算而非分量逐个计算。
避免线程发散:warp/wavefront 内所有线程执行相同指令,动态分支导致线程闲置。用 saturate/lerp 替代 if,或用 Shader 关键字生成变体。
内存访问合并:连续内存访问可被合并为更少事务,随机访问严重拉低带宽效率。
预计算并行查找表:离线预计算复杂函数结果存入纹理/数组,运行时查表替代实时计算。
批处理:合并 Draw Call,让 GPU 在更大批次中并行工作。
减少昂贵的原子操作:原子操作在高并发下串行化同一地址访问,避免大量线程写同一计数器。
减少数据依赖:让每个线程独立计算,减少顺序/循环/帧间依赖,依赖逻辑移到 CPU。
ComputeShader 基础:
作用:在 GPU 上运行的通用计算程序(GPGPU),脱离渲染管线,直接利用 GPU 并行计算能力处理任意类型数据。
与普通 Shader 区别:普通 Shader 依赖渲染管线用于渲染画面;Compute Shader 不依赖渲染管线,专门用于计算数据。
基本结构:
#pragma kernel CSMain // 声明入口函数
RWTexture2D<float4> Result; // 声明输入输出资源
[numthreads(8,8,1)] // 声明线程组内线程数量
void CSMain(uint3 id : SV_DispatchThreadID) { ... }
C# 调用流程:
FindKernel("入口函数名")获取内核索引SetFloat/SetVector/SetBuffer/SetTexture传递参数Dispatch(kernel, x, y, z)启动计算GetData/AsyncGPUReadback获取结果Release()释放资源
执行模型三层结构:
- 线程:GPU 并行执行的最小计算单元
- 线程组:由
[numthreads(x,y,z)]定义,共享组内内存 - 线程组网格:C# 侧
Dispatch()定义,控制全局总线程数
总线程数计算:总线程数 = numthreads(x,y,z) × Dispatch(gx,gy,gz)
ComputeShader 数据类型:
标量类型:bool(1byte)、int(4byte)、uint(4byte)、float(4byte)、double(8byte)
向量类型:float2/float3/float4、int2/int3/int4、uint2/uint3/uint4
矩阵类型:float2x2、float3x3、float4x4
复合类型:struct、StructuredBuffer(只读)、RWStructuredBuffer(可读写)、ByteAddressBuffer、AppendStructuredBuffer、ConsumeStructuredBuffer
纹理类型:Texture2D(只读)、RWTexture2D(可读写)、TextureCube、Texture2DMS
常量缓冲区:cbuffer,按块上传更高效
注意:不建议使用 half,存在对齐问题、平台支持问题。
ComputeShader 参数传递:
标量:SetFloat、SetInt、SetBool
向量:SetVector(建议非 4 维用 SetFloats/SetInts)
矩阵:SetMatrix
缓冲区:ComputeBuffer + SetData + SetBuffer
纹理:SetTexture(RWTexture 需 enableRandomWrite = true 的 RenderTexture)
常量缓冲区:SetConstantBuffer
ComputeBuffer 创建:new ComputeBuffer(count, stride) 或 new ComputeBuffer(count, stride, ComputeBufferType.Append)
ComputeShader 三大参数语义:
| 语义 | 含义 | 说明 |
|---|---|---|
| SV_DispatchThreadID | 全局线程 ID | 每个线程在整个 Dispatch 中的唯一索引,可直接映射到数据下标 |
| SV_GroupThreadID | 组内线程 ID | 当前线程在组内的局部索引 |
| SV_GroupID | 线程组 ID | 当前线程组在整个 Dispatch 网格中的位置 |
关系:SV_DispatchThreadID = SV_GroupID × numthreads + SV_GroupThreadID
最常用:SV_DispatchThreadID,直接映射到图像像素或数组元素下标。
ComputeShader 线程组配置:
numthreads 规则:
- 每个维度 >= 1 且 <= 1024
- x × y × z <= 1024
Dispatch 规则:
- 每个维度 >= 1
- 无硬性上限
匹配规则:groupsX = CeilToInt(width / numThreadX)
推荐配置:
| 数据维度 | 推荐 numthreads |
|---|---|
| 1D 数据 | (64,1,1) 或 (128,1,1) |
| 2D 数据 | (8,8,1) 或 (16,16,1) |
| 3D 数据 | (4,4,4) 或 (8,8,8) |
原因:GPU 线程调度单位是 Warp/Wavefront(32 或 64 个线程),最好让 x×y×z 是 32 或 64 的倍数。
ComputeShader 数据获取:
同步获取:
- ComputeBuffer:
GetData(array)阻塞 CPU - RenderTexture:
RenderTexture.active+ReadPixels+Apply
异步获取(推荐):
AsyncGPUReadback.Request(computeBuffer, (request) => {
if (!request.hasError) {
NativeArray<int> data = request.GetData<int>();
}
});
注意:异步获取最快下一帧返回。
ComputeShader 常用 API:
C# 侧:
FindKernel:查找入口函数索引Dispatch:启动计算SetFloat/SetInt/SetBool/SetVector/SetMatrix/SetBuffer/SetTexture:设置参数GetKernelThreadGroupSizes:获取 numthreads 配置EnableKeyword/DisableKeyword:动态编译关键字SystemInfo.supportsComputeShaders:判断设备支持
ComputeBuffer:
new ComputeBuffer(count, stride):创建缓冲区SetData:上传数据GetData:同步读取Release:释放资源CopyCount:统计动态生成数据数量
HLSL 侧:
- 参数语义:SV_DispatchThreadID、SV_GroupThreadID、SV_GroupID
- 内置函数:lerp、step、saturate、smoothstep、dot、cross、length、normalize 等
groupshared:组内共享内存- 同步函数:
GroupMemoryBarrierWithGroupSync(最常用) - 原子操作:
InterlockedAdd、InterlockedExchange、InterlockedCompareExchange等
ComputeShader 应用场景:
图形计算:后处理效果、光照计算、粒子系统、GPU 剔除、体积渲染、地形水面模拟、程序纹理生成、GPU 蒙皮
逻辑计算:并行排序、并行扫描、矩阵向量运算、图像处理、距离场计算
物理仿真 AI:流体模拟、布料模拟、刚体粒子、AI 路径搜索、神经网络加速
编辑器拓展:大规模数据离线预计算、纹理压缩转换、网格分析处理
项目典型用法:
- 移动端:GPU 模糊、Bloom、粒子模拟、屏幕空间特效
- VR/AR:镜头畸变校正
- 开放世界:GPU Culling + LOD + Instance Batch
- 工业仿真:粒子、流体、温度场可视化
内存优化
移动端渲染性能优化
核心原则:移动设备上高 DrawCall 通常比填充率更容易造成性能瓶颈。
优化要点:
| 优化方向 | 说明 |
|---|---|
| 避免 Alpha 测试 | 低端移动设备上透明度测试特别消耗资源,优先使用透明混合 |
| 最小化 DrawCall | 利用批处理或手动合并网格降低 DrawCall,是移动平台提高性能的有效手段 |
资源优化:音频
音频加载方式优化:
| 参数 | 作用 | 优化建议 |
|---|---|---|
| Load Type | 加载类型 | 背景音乐用 Streaming,短音效用 Decompress on Load |
| Preload Audio Data | 预加载 | 常用音效勾选,大型音频取消勾选延迟加载 |
| Compression Format | 压缩格式 | 移动端背景音乐用 Vorbis,短音效用 ADPCM |
生命周期管理:通过 AudioSource.Play() / Stop() 控制播放,不用的音频资源及时卸载。
资源优化:视频
视频加载方式优化:
| 参数 | 选项 | 说明 |
|---|---|---|
| Source | URL | 外部视频文件,streaming 方式加载 |
| Source | VideoClip | 内部视频资源,可预加载 |
| Render Mode | Camera Far/Near Plane | 渲染到摄像机,消耗 GPU |
| Render Mode | Render Texture | 渲染到纹理,可复用 |
| Render Mode | Material Override | 替换材质纹理 |
| Render Mode | API Only | 仅数据,不渲染,通过脚本访问 |
优化建议:使用 H.264 编码确保硬件解码;预分配 RenderTexture 避免运行时创建;播放完毕及时释放资源。
资源优化:纹理
纹理导入设置优化:
| 参数 | 优化建议 |
|---|---|
| Max Size | 根据用途选择:UI 图标 128-256,角色纹理 1024-2048 |
| Compression | 移动端优先 ASTC,PC 用 BC7,根据平台选择 |
| Mipmap | UI 关闭,3D 物体开启 |
| Read/Write | 关闭可减少一半内存占用 |
运行时纹理管理:动态创建的 Texture2D 用完必须 Destroy();避免频繁调用 Texture2D.Apply()。
资源优化:网格和动画
网格资源优化:
| 参数 | 说明 |
|---|---|
| Mesh Compression | 压缩网格数据,Off/Low/Medium/High 权衡精度与体积 |
| Read/Write | 关闭可减少内存,但运行时无法读取顶点数据 |
| Optimize Mesh | 优化顶点顺序提升 GPU 缓存命中率 |
动画资源优化:
| 参数 | 说明 |
|---|---|
| Animation Compression | Keyframe Reduction 减少关键帧数量 |
| Curve Optimization | 移除冗余曲线 |
| Resample Curves | 关闭可减少数据量,但可能影响精度 |
资源优化:材质和 Shader
材质优化要点:
- 公共材质使用
sharedMaterial,避免material属性隐式实例化 - 动态创建的材质用完必须
Destroy()
Shader 变体控制:
| 指令 | 特点 |
|---|---|
#pragma multi_compile |
生成所有组合变体 |
#pragma shader_feature |
只生成实际使用的变体 |
优化建议:控制变体数量,避免指数级增长;使用 shader_feature 减少不必要的变体。
资源优化:AB 包和 Resources
Resources 系统局限性:
- 启动时建立索引,影响启动速度
- 无法动态更新,只能整包更新
- 内存管理困难,
UnloadUnusedAssets开销大
AssetBundle 压缩方式对比:
| 方式 | 压缩大小 | 加载速度 | 内存消耗 | 适用场景 |
|---|---|---|---|---|
| LZMA | 最小 | 最慢 | 最大 | 首次安装包、小体积下载 |
| LZ4 | 中等 | 较快 | 小 | 上线项目推荐 |
| Uncompressed | 最大 | 最快 | 小 | 大量小文件、频繁加载 |
AB 包管理要点:
- 依赖关系:加载时需同时加载依赖包
- 卸载策略:
Unload(true)卸载资源,Unload(false)仅卸载 AB 包 - 避免重复加载同一 AB 包
内存管理:基础优化技巧
垃圾回收时机选择:
- 避免频繁 GC,必要时在合适时机手动触发
- 推荐时机:游戏暂停、过场景、读条界面
GC.Collect();
Resources.UnloadUnusedAssets();
结构体传递优化:
- 大结构体传递时考虑使用
ref避免值拷贝开销
StringBuilder 替代 string:
- 多次循环拼接、大量 Replace、不确定长度的输入流 → 用 StringBuilder
- 字符串常量、几次简单拼接 → 用 string
避免装箱拆箱:
- 使用泛型避免装箱
- 注意
Debug.LogFormat("Frame {0}", Time.frameCount)会装箱
数据内存布局:
| 布局方式 | 特点 | 性能 |
|---|---|---|
| class 数组 | 引用分散,缓存命中差 | 最差 |
| struct 数组 | 数据连续,缓存友好 | 较好 |
| 数据数组(SoA) | 每字段完全连续 | 最强 |
Unity API 数组问题:
GetComponents<T>()、Mesh.vertices、renderer.materials等会分配新数组- 避免频繁调用,或缓存结果
内存管理:运行时高频操作优化
InstanceID 缓存:
GetInstanceID()有开销,初始化时获取一次并缓存
foreach 使用规则:
- 现代 Unity 版本可放心用于数组、List、Dictionary
- 遍历 Unity 自身暴露的集合(如 Transform 子物体)需警惕,用 Profiler 确认
协程优化:
- 协程本质是状态机对象,启动有内存开销
- 避免产生太多短生命周期协程
yield return new WaitForSeconds()会产生堆内存分配
闭包问题:
- 闭包会捕获外部变量生成隐藏类
- 可能延长对象生命周期、引发内存泄漏
Linq 和正则表达式:
- Linq:大量隐式堆分配、性能不透明、链式调用产生多个临时对象
- 正则:运行成本极高(解释器 + 状态机)
- 性能敏感逻辑(Update/FixedUpdate/AI/物理)不要使用
集合容量优化:
new List<int>(预计数量)提前指定容量避免扩容- 长期容器用
Clear()重用,而非每次new - Dictionary 同样建议初始化时指定容量
内存管理:资源管理与 GC 进阶
静态引用与事件退订:
- 静态字段、单例是根引用,持有对象不会被 GC
- 事件订阅必须在
OnDisable/OnDestroy中退订
资源释放方式:
| 加载方式 | 释放方法 |
|---|---|
Resources.Load |
Resources.UnloadAsset(obj) 或 UnloadUnusedAssets() |
| Addressables/AB 包 | 对应的 Release 或 Unload 方法 |
| 运行时创建资源 | Destroy() 显式销毁 |
大数组与 LOH:
- 大于 85KB 的数组进入大对象堆(LOH),GC 成本更高
- 优化:复用大数组、使用静态缓存、利用
ArrayPool<T>.Shared
非托管资源释放:
| 资源类型 | 释放方法 |
|---|---|
| NativeArray/NativeList | .Dispose() |
| ComputeBuffer/RenderTexture | .Release() 或 Destroy() |
| GCHandle | .Free() |
增量 GC(Incremental GC):
- 将单帧 GC 拆分成多帧执行,降低峰值卡顿
- Player Settings → Other Settings → Configuration → Use incremental GC
DOTS 系统预告:
- 三大核心:ECS(实体组件系统)+ Job System(作业系统)+ Burst Compiler(编译器)
- 适用场景:海量对象、大量重复计算、CPU 成为瓶颈时
115.3 面试题精选
基础题
1. Profiler 内嵌模式与独立进程模式有何区别?
题目
Profiler 的内嵌模式和独立进程模式有什么区别?分别在什么场景下使用?
深入解析
- 内嵌模式:与 Unity Editor 同进程,上手快、调试方便;采样会占用同一进程的 CPU/内存,对结果有一定干扰,适合日常开发与局部分析。
- 独立进程模式:Profiler 单独进程,与被测进程隔离,干扰更小,更适合大型场景、真机与接近发布环境的性能测试。
答题示例
内嵌:跟编辑器同进程,方便但采样有干扰。独立进程:隔离运行,干扰小,适合真机和正式向测试。
日常调试用内嵌;要数据更可信时用独立进程。
参考文章
- 3.初识Profiler窗口
2. CPU Usage 里 Total 与 Self 各表示什么?如何用来找瓶颈?
题目
Profiler CPU Usage 模块中 Total 和 Self 两列分别表示什么?如何利用它们定位性能瓶颈?
深入解析
- Total:该函数及其子调用链在本帧统计中的时间占比,反映整条路径的总开销。
- Self:仅函数自身体的时间占比,不含子调用。
- 用法:Total 高、Self 低 → 往子调用里钻;Self 高 → 本函数逻辑或 IO 可疑。结合 Calls 可看是否无意义高频调用。
答题示例
Total 是「自己+子函数」占比,Self 是「只算自己」占比。
Total 高 Self 低说明问题在子层;Self 高说明本函数要优化。配合 Calls 看是否重复调用过多。
参考文章
- 5.Profiler窗口CPUUsage
3. 脚本里哪些「看起来无害」的写法会带来持续性能损耗?
题目
为什么不应保留空的生命周期函数(如空 Update)?发布版本如何降低 Debug.Log 一类日志的开销?
深入解析
- 空生命周期:只要声明了
Update等,Unity 仍会按帧调度,大量脚本时空调用会叠加成可见开销;不需要时应删掉方法本身。 - 日志:可用二次封装 + 运行时常量开关,或用
[Conditional("UNITY_EDITOR")]/DEVELOPMENT_BUILD让正式包不编译进调用路径,避免字符串格式化与 GC。
答题示例
空 Update 仍会被每帧调用,多了会积少成多,应直接删除声明。
发布版用条件编译或封装开关,避免
Debug.Log在玩家包路径里执行。
参考文章
- 25.生命周期函数
- 26.Debug的性能消耗
进阶题
1. 开启 GPU Usage 为何会扭曲性能结论?URP/HDRP 下要注意什么?
题目
为什么开启 GPU Usage 会影响性能测试的准确性?在 URP/HDRP 项目中有什么限制?
深入解析
- 采集 GPU 数据往往会 关闭 Graphics Jobs 等并行路径,CPU/GPU 侧行为与真实玩家环境不一致,测到的帧时间可能偏悲观或偏乐观。
- SRP:GPU Usage 常无法拆到 Pass/Shader 粒度,多为汇总项;需要时用 Rendering Debugger、Xcode/Android GPU 工具等补充。
答题示例
GPU Profiler 会改调度与并行度,测出来不等于纯玩家环境。
URP/HDRP 往往看不到细粒度 GPU 时间,要换平台或 SRP 专用调试手段。
参考文章
- 6.Profiler窗口GPUUsage
2. 如何从 Rendering 与合批角度判断 DrawCall 是否是瓶颈?批处理体系怎么选?
题目
Profiler Rendering 模块里应关注哪些指标?动态批处理、静态批处理、GPU Instancing、SRP Batcher 各适合什么情形?
深入解析
- 指标:Batches、SetPass、Draw Calls 的关系;SetPass 高往往意味着状态切换多、合批难。
- 静态批处理:适合 不移动 且可标记 Static 的物体;有额外内存代价。
- 动态批处理:适合小网格、同材质等满足引擎限制的情形;顶点数等有上限。
- GPU Instancing:大量 同网格同材质 实例。
- SRP Batcher:URP/HDRP 上减 CPU 侧常量缓冲提交,不等价于减少 Draw Call 数量,Shader 需兼容且注意与 MPB 等限制。
答题示例
先看 Batches 和 SetPass,判断是 DC 多还是状态切换多。
静止场景倾向静态批;大量相同实例用 Instancing;URP/HDRP 默认用好 SRP Batcher;小动态物体再看动态批条件。
参考文章
- 7.Profiler窗口Rendering
- 45.动态批处理
- 46.静态批处理
- 47.GPU Instancing
- 48.SRP Batcher
- 49.DrawCall优化方案对比
3. Profiler Memory 与 Memory Profiler 包如何分工?驻留内存与已分配内存有何不同?
题目
Profiler 自带 Memory 模块与 Memory Profiler Package 在定位内存问题时如何配合?驻留内存(Resident)与已分配内存(Allocated)区别是什么?
深入解析
- Profiler Memory:适合 实时 看走势、快速判断是否在涨、哪类分配在动。
- Memory Profiler:适合 快照对比、引用链、泄漏路径;抓快照有成本。
- 驻留 vs 已分配:驻留更接近 物理 RAM 中实际占用,过高易 OOM;已分配含预留与虚拟地址等,可反映趋势但未必立刻触顶物理上限。
答题示例
先用 Profiler Memory 看趋势,再用 Memory Profiler 抓前后快照对比、跟引用链。
驻留决定「会不会被系统杀」;已分配更多看「是不是在持续漏或预留失控」。
参考文章
- 9.初识MemoryProfiler窗口
- 11.MemoryProfiler窗口UnityObjects
深度题
1. 如何用 Profiler API 做自定义区间采样与运行时内存查询?
题目
如何在代码中使用 Profiler API 进行自定义性能采样?常用内存相关 API 有哪些?要注意什么?
深入解析
- 命名空间
UnityEngine.Profiling:Profiler.BeginSample/EndSample成对包裹热点;建议编辑器或宏包裹,避免打进正式包。 - 内存:
GetMonoUsedSizeLong、GetTotalAllocatedMemoryLong、GetTotalReservedMemoryLong、GetRuntimeMemorySizeLong等用于 趋势与对比,不能替代快照工具做引用分析。 - 可开
enableBinaryLog导出.raw离线打开;注意采样与日志本身也有开销。
答题示例
BeginSample/EndSample标区间,成对使用,正式包用宏关掉。
GetTotalAllocatedMemoryLong等看总量趋势;要查谁持有引用还得 Memory Profiler 快照。
参考文章
- 22.Profiler窗口脚本控制
2. 用 Memory Profiler 做「泄漏」排查时,推荐的操作顺序是什么?
题目
如何使用 Memory Profiler 的快照对比定位疑似内存泄漏?典型根因有哪些?
深入解析
- 在 同一操作前后(开关 UI、切场景、跑一段时间)各抓一帧快照。
- Summary 看总量与分类涨幅;Unity Objects 按 Allocated Size 排序找异常增长类型。
- 看 Compare 模式下列出的新增/增大对象;用 Referenced By 往上追到 静态字段、单例、未退订事件 等长生命周期根。
- All Of Memory 辅助看托管堆、Reserved、Untracked 等是否异常。
答题示例
前后各抓一张,先 Summary 看哪类涨,再在 Unity Objects 里排序、对比实例,顺着引用链找根。
常见根因:静态容器、事件没
-=、资源重复加载未卸载。
参考文章
- 9.初识MemoryProfiler窗口
- 10.MemoryProfiler窗口Summary
- 11.MemoryProfiler窗口UnityObjects
- 12.MemoryProfiler窗口AllOfMemory
3. 什么是本机-托管桥接?脚本侧如何系统性减少这类开销?
题目
本机-托管桥接为什么贵?结合 Transform、GetComponent、Update 等常见 API,如何优化?
深入解析
- 桥接:托管 C# 调用引擎 C++ 的路径,涉及调度与封送,高频时每帧放大明显。
- 典型触发:
GetComponent、transform属性读写、SetActive、Find等。 - 手段:Awake/Start 缓存引用;减少
transform逐属性读写(读入局部变量、批量更新);避免在Update里Find/反复GetComponent;能用事件驱动就不用每帧轮询;必要时 集中 Update 管理器 降低调度边界次数。
答题示例
桥接就是 C# 调引擎原生层的跨界调用,次数多了 CPU 很明显。
组件和 Transform 在初始化缓存好;Update 里别 Find/GetComponent;逻辑能事件驱动就不每帧扫。
参考文章
- 31.组件获取
- 32.Update
- 35.本机托管的桥接
4. ComputeShader 的执行模型是什么?numthreads 与 Dispatch 如何决定总线程数?
题目
ComputeShader 中线程、线程组、Dispatch 网格的关系是什么?SV_DispatchThreadID 与组内 ID 何时用?
深入解析
- 层次:线程 →
[numthreads(x,y,z)]定义的 线程组 →Dispatch(gx,gy,gz)定义的 组网格;总线程数为(x*gx, y*gy, z*gz)(逐分量)。 - numthreads:每组线程数,乘积受平台限制(如每线程组不超过 1024,各维有上限)。
- 语义:
SV_DispatchThreadID最常用于 一一映射 到像素/体素/数组下标;SV_GroupID+SV_GroupThreadID适合 组内共享内存 与分块算法。关系:DispatchThreadID = GroupID * numthreads + GroupThreadID(按分量)。
答题示例
一组里有多少线程由 numthreads 定,有多少组由 Dispatch 定,乘起来是总并行度。
简单逐元素用 DispatchThreadID;要用 groupshared 或分块就用组 ID 加组内 ID。
参考文章
- 96.ComputeShader的作用和基本结构
- 100.ComputeShader组内线程数量
- 101.ComputeShader三大参数语义
5. 托管堆上哪些习惯会放大 GC 压力?非托管与 Native 资源要如何收尾?
题目
装箱、Linq、大对象堆(LOH)、增量 GC、静态引用与事件订阅各带来什么问题?NativeArray、ComputeBuffer 等如何释放?
深入解析
- 装箱与 Linq:热路径上会产生 隐式分配 与迭代器对象,引发更频的 GC;性能敏感处用 for 循环与泛型。
- LOH:大数组(如大于约 85KB)进 LOH,回收与碎片成本更高;用 复用、ArrayPool 等减少抖动。
- 增量 GC:把停顿摊到多帧,换总体 CPU 略增;
GC.Collect仍要选时机(切场景、加载屏),避免滥用。 - 泄漏感:静态字段、单例、事件未退订 会让对象达不到回收条件。
- 非托管:
NativeArray/NativeList调Dispose();ComputeBuffer/RenderTexture调Release()或Destroy();配合using或try/finally,避免异常路径泄漏。
答题示例
热路径少装箱、少 Linq;大缓冲用池化或 ArrayPool。
静态和事件长按引用要像管理资源一样在切场景或 OnDestroy 里断开;Native 侧必须 Dispose/Release,不能指望 GC。
参考文章
- 112.内存优化-内存管理-基础内存优化技巧
- 113.内存优化-内存管理-运行时高频操作内存优化
- 114.内存优化-内存管理-资源管理与GC进阶优化
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 785293209@qq.com

